Mybatis的深入浅出(zz的理解)
Mybatis是什么,用来干什么,怎么实现的,有什么优点,有什么缺点
那么,这篇文章会比较系统性的梳理以上几点问题
First Of All : Mybatis 是什么个东西
MyBatis是一款优秀的基于java的持久层框架,它内部封装了jdbc,使开发者只需要关注sql语句本身,而不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程 -- 网上偷来的话
Mybatis是当前我唯一使用的与数据库交互的框架(菜鸡如我),内部封装了JDBC(因为苦活累活都是它来干),那么mybatis做了什么呢,其实是对JDBC这一套流程的优化,从数据库连接->sql语句生成->sql参数注入->sql执行->sql结果映射与缓存。总而言之,Mybatis让数据库的增删改查变得更加便捷了 -- 我自己的话
Second .. 用来干啥的
我刚刚是不是已经说完这个问题了 --- pass
Third 怎么实现的
那么,这个问题,得先从他的干活小弟JDBC说起了。
JDBC怎么做的
基本的JDBC查询数据的七个步骤
1 加载JDBC驱动;
2 建立并获取数据库连接;
3 创建 JDBC Statements 对象;
4 设置SQL语句的传入参数;
5 执行SQL语句并获得查询结果;
6 对查询结果进行转换处理并将处理结果返回;
7 释放相关资源(关闭Connection,关闭Statement,关闭ResultSet);
具体的代码实现 此处 参考终结篇:MyBatis原理深入解析(一)
public static List> queryForList(){
Connection connection = null;
ResultSet rs = null;
PreparedStatement stmt = null;
List> resultList = new ArrayList>();
try {
// 加载JDBC驱动
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
String url = "jdbc:oracle:thin:@localhost:1521:ORACLEDB";
String user = "trainer";
String password = "trainer";
// 获取数据库连接
connection = DriverManager.getConnection(url,user,password);
String sql = "select * from userinfo where user_id = ? ";
// 创建Statement对象(每一个Statement为一次数据库执行请求)
stmt = connection.prepareStatement(sql);
// 设置传入参数
stmt.setString(1, "zhangsan");
// 执行SQL语句
rs = stmt.executeQuery();
// 处理查询结果(将查询结果转换成List 那么针对于以上的JDBC对数据库的操作,我们可以发现好几个方面的问题:
加载驱动创建连接,查询结果后,连接终端
在每一个需要进行数据库操作的位置都需要编写对应的sql查询语句
sql参数再注入的过程中需要按照占位符的顺序匹配,但是如果入参数量不确定,等等问题,会导致代码的兼容性很差 -- 需要在java代码中拼接sql语句
查询完的数据需要手动的去映射到对应的javaBean中,麻烦;同时查询不具备缓存,浪费资源
Mybatis怎么做的
那么,我们知道,Mybatis内部封装了JDBC,并做出了卓越的改进,做了那些个改进呢?
上图
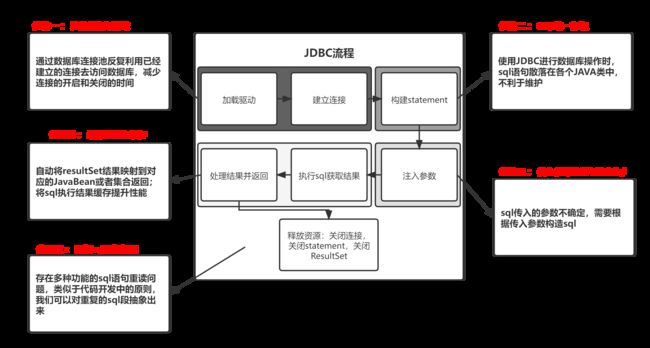
有五大优化点,均是基于咱们之前所提的那几个缺点而做出的改进;
有人会说,你这张图太泛泛了,到底做了什么嘛?
我们可以从Mybatis与sql交互的流程来理解Mybatis的优化,到底做了什么
Mybatis与数据库交互的方式
- 传统Mybatis提供的API
- 使用Mapper接口
传统的API方式::
通过传递Statement Id 和查询参数给SqlSession对象,使用SqlSession对象完成数据库的交互
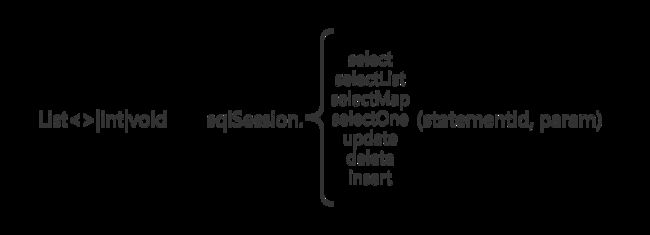
以上通过创建一个SqlSession对象,结合对应的Statement Id 和参数来与数据库交互,但是不符合面向对象语言的概念和面向接口编程的编程习惯(啥子意思嘞)
因此,Mybatis新增了一种与数据库交互的方式 -- 支持接口方式调用
使用Mapper接口::
Mybatis将配置文件中的每一个
根据MyBatis 的配置规范配置好后,通过SqlSession.getMapper(XXXMapper.class)方法,MyBatis 会根据相应的接口声明的方法信息,通过动态代理机制生成一个Mapper 实例,我们使用Mapper接口的某一个方法时,MyBatis会根据这个方法的方法名和参数类型,确定Statement Id,底层还是通过SqlSession.select("statementId",parameterObject);或者SqlSession.update("statementId",parameterObject); 等等来实现对数据库的操作,MyBatis引用Mapper 接口这种调用方式,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是在于,面向接口的编程,使得用户在接口上可以使用注解来配置SQL语句,这样就可以脱离XML配置文件,实现“0配置”)
以上两种实现方式其实究其源头还是一家,那么作为家族的老祖宗SqlSession,是怎么做到与数据库交互的呢???
上图 -----
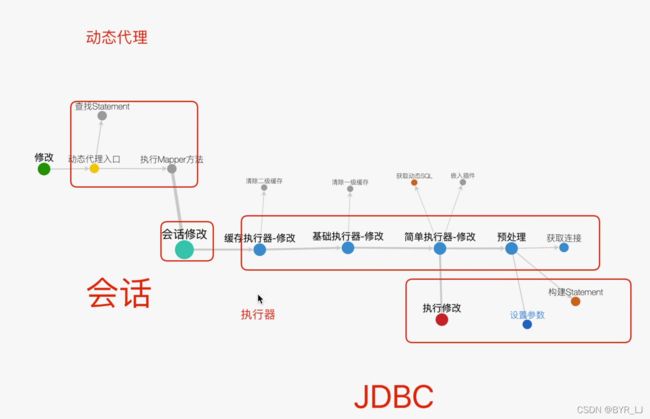
以上是修改时的流程
主要的四个部分 :
- 动态代理 MapperProxy
- SQL会话 SqlSession
- 执行器 Executor
- JDBC处理器 StatementHandler
那么接下来我们将从以上四块对Mybatis进行纵向的剖析
我们通过一个真实案例为索引一层一层剖析Mybatis的底层实现
mapper 接口
package com.example.mybatisdemo.Mapper;
import com.example.mybatisdemo.Entity.User;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper//指定这是一个操作数据库的mapper
public interface UserMapper {
List findAll();
}
mapper.xml
测试方法中的调用(注意要启动spring,要不然mapper无法扫描到)
@Test
public void mapperTest() {
userMapper.findAll();
}动态代理
有个疑问,为啥要用到基于接口的实现呢,有什么好处:
答案我已经帮你们找到了,自己理解
使用 Mapper 接口编程可以消除 SqlSession 带来的功能性代码,提高可读性,而 SqlSession 发送 SQL,需要一个 SQL id 去匹配 SQL,比较晦涩难懂。使用 Mapper 接口,类似 roleMapper.getRole(1L)则是完全面向对象的语言,更能体现业务的逻辑。
使用 Mapper.getRole(1L)方式,IDE 会提示错误和校验,而使用 sqlSession.selectOne(“getRole”,1L)语法,只有在运行中才能知道是否会产生错误
那么,为什么Mybatis的接口不需要实现就能执行呢,那这个,就是我们今天要剖析的东西--Mybatis之动态代理
首先挪出几个类来 --
MapperRegistry MapperProxyFactory MapperProxy MapperMethod
接下来的debug过程将会贯彻落实以上几个类
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);这就是代理类的获取方法,那么在正常使用时,Spring已经将代理类生成好后,通过注入的方式注入到需要的位置@Todo,怎么实现的?
紧接下来,DefaultSqlSession中
this.configuration.getMapper(type, this);Configuration中又调用了MapperRegistry中getMapper方法
this.mapperRegistry.getMapper(type, sqlSession);终于到正主了
public T getMapper(Class type, SqlSession sqlSession) {
// 根据当前的type类型获取mapperProxyFactory,用以生成代理对象
MapperProxyFactory mapperProxyFactory = (MapperProxyFactory)this.knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
} else {
try {
// 构建代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception var5) {
throw new BindingException("Error getting mapper instance. Cause: " + var5, var5);
}
}
} 我们可以发现当存在mapperProxyFactory时会调mapperProxyFactory.newInstance(sqlSession)用以构建代理对象。
public T newInstance(SqlSession sqlSession) {
MapperProxy mapperProxy = new MapperProxy(sqlSession, this.mapperInterface, this.methodCache);
return this.newInstance(mapperProxy);
}
protected T newInstance(MapperProxy mapperProxy) {
return Proxy.newProxyInstance(this.mapperInterface.getClassLoader(), new Class[]{this.mapperInterface}, mapperProxy);
} 到这里,代理对象已经生成,当调用
userMapper.findAll();会去调用mapperProxy对象中的invoke方法,那么我们查看其invoke方法怎么实现的
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
//首先判断是否为Object本身的方法,是则不需要去执行SQL 比如:toString()、hashCode()、equals()等方法
return Object.class.equals(method.getDeclaringClass()) ? method.invoke(this, args) : this.cachedInvoker(method).invoke(proxy, method, args, this.sqlSession);
} catch (Throwable var5) {
throw ExceptionUtil.unwrapThrowable(var5);
}
}
private MapperProxy.MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
return (MapperProxy.MapperMethodInvoker)MapUtil.computeIfAbsent(this.methodCache, method, (m) -> { 判断是否JDK8及以后的接口默认实现方法。
if (m.isDefault()) {
try {
return privateLookupInMethod == null ? new MapperProxy.DefaultMethodInvoker(this.getMethodHandleJava8(method)) : new MapperProxy.DefaultMethodInvoker(this.getMethodHandleJava9(method));
} catch (InstantiationException | InvocationTargetException | NoSuchMethodException | IllegalAccessException var4) {
throw new RuntimeException(var4);
}
} else {
return new MapperProxy.PlainMethodInvoker(new MapperMethod(this.mapperInterface, method, this.sqlSession.getConfiguration()));
}
});
} catch (RuntimeException var4) {
Throwable cause = var4.getCause();
throw (Throwable)(cause == null ? var4 : cause);
}
}
private static class PlainMethodInvoker implements MapperProxy.MapperMethodInvoker {
private final MapperMethod mapperMethod;
public PlainMethodInvoker(MapperMethod mapperMethod) {
this.mapperMethod = mapperMethod;
}
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
return this.mapperMethod.execute(sqlSession, args);
}
}this.cachedInvoker(method) 返回 PlainMethodInvoker 并调用了其invoke方法
最后调用了mapperMethod.execute(sqlSession)
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
Object param;
switch(this.command.getType()) {
case INSERT:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.insert(this.command.getName(), param));
break;
case UPDATE:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.update(this.command.getName(), param));
break;
case DELETE:
param = this.method.convertArgsToSqlCommandParam(args);
result = this.rowCountResult(sqlSession.delete(this.command.getName(), param));
break;
case SELECT:
if (this.method.returnsVoid() && this.method.hasResultHandler()) {
this.executeWithResultHandler(sqlSession, args);
result = null;
} else if (this.method.returnsMany()) {
result = this.executeForMany(sqlSession, args);
} else if (this.method.returnsMap()) {
result = this.executeForMap(sqlSession, args);
} else if (this.method.returnsCursor()) {
result = this.executeForCursor(sqlSession, args);
} else {
param = this.method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(this.command.getName(), param);
if (this.method.returnsOptional() && (result == null || !this.method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + this.command.getName());
}
if (result == null && this.method.getReturnType().isPrimitive() && !this.method.returnsVoid()) {
throw new BindingException("Mapper method '" + this.command.getName() + " attempted to return null from a method with a primitive return type (" + this.method.getReturnType() + ").");
} else {
return result;
}
}发现绕来绕去,还是通过sqlSession的api来执行
SQL会话 与 执行器
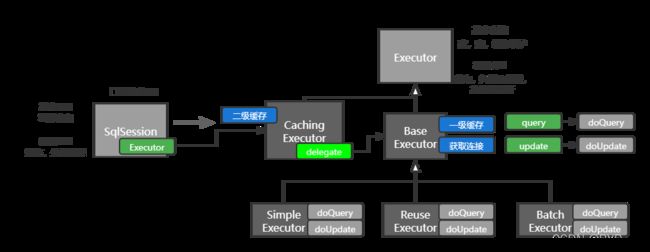
代码执行到SqlSession处会执行
selectList("com.example.mybatisdemo.Mapper.UserMapper.findAll", parameter)具体的selectList方法中会根据当前的“com.example.mybatisdemo.Mapper.UserMapper.findAll” statementId获取MappedStatement
private List selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
List var6;
try {
// 根据StatementId获取对应的MappedStatement
MappedStatement ms = this.configuration.getMappedStatement(statement);
var6 = this.executor.query(ms, this.wrapCollection(parameter), rowBounds, handler);
} catch (Exception var10) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var10, var10);
} finally {
ErrorContext.instance().reset();
}
return var6;
} 那么这个MappedStatement是什么呢
在之前我们提到过mapper.xml文件,该文件加载到内存会
生成一个对应的MappedStatement对象,然后会以key="com.example.mybatisdemo.Mapper.UserMapper.findAll" ,value为MappedStatement对象的形式维护到Configuration(Mybatis的配置信息实例)的一个Map中。当以后需要使用的时候,只需要通过Id值来获取就可以了。
获取到MappedStatement后就直接通过实例中的Executor,调用query方法来执行了。
调用query()方法的Executor是CachingExecutor(如果使能了二级缓存)
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 先获取buoudSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 生成对应的缓存key
CacheKey key = this.createCacheKey(ms, parameterObject, rowBounds, boundSql);
return this.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
this.flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
this.ensureNoOutParams(ms, boundSql);
// 查询缓存
List list = (List)this.tcm.getObject(cache, key);
if (list == null) {
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
this.tcm.putObject(cache, key, list);
}
return list;
}
}
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} CachingExecutor中会先去查询缓存是否命中,如果未命中 则通过 delegate.query()(装饰器模式)查询 ,这里的 delegate 对应的是 BaseExecutor。
在BaseExecutor中实现了一级缓存
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
return this.query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (this.closed) {
throw new ExecutorException("Executor was closed.");
} else {
if (this.queryStack == 0 && ms.isFlushCacheRequired()) {
this.clearLocalCache();
}
List list;
try {
++this.queryStack;
list = resultHandler == null ? (List)this.localCache.getObject(key) : null;
if (list != null) {
this.handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = this.queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
--this.queryStack;
}
if (this.queryStack == 0) {
Iterator var8 = this.deferredLoads.iterator();
while(var8.hasNext()) {
BaseExecutor.DeferredLoad deferredLoad = (BaseExecutor.DeferredLoad)var8.next();
deferredLoad.load();
}
this.deferredLoads.clear();
if (this.configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
this.clearLocalCache();
}
}
return list;
}
} 代码中有个变量 queryStack 指的是嵌套的查询 ,我们观察到其中会对一级缓存中查询,如果未命中则调用queryFromDatabase() 方法
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);
List list;
try {
list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
this.localCache.removeObject(key);
}
this.localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
this.localOutputParameterCache.putObject(key, parameter);
}
return list;
} 接下来会调度抽象方法doQuery(), 具体的实现在三个实现类中 -- SimpleExecutor、ReuseExecutor、 BatchExecutor,我们这里仅用SimpleExecutor来演示
(ReuseExecutor中会复用同样的sql,对于同一条查询,不会对sql进行两次解析;BatchExecutor中则是对于插入操作,会对于单次的插入会合并进行批量化)
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
List var9;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = this.prepareStatement(handler, ms.getStatementLog());
var9 = handler.query(stmt, resultHandler);
} finally {
this.closeStatement(stmt);
}
return var9;
} 我们可以发现,这里构建了StatementHander , 并加工了Statement(创建,参数注入),然后便调用Hanlder.query()方法。
JDBC处理器
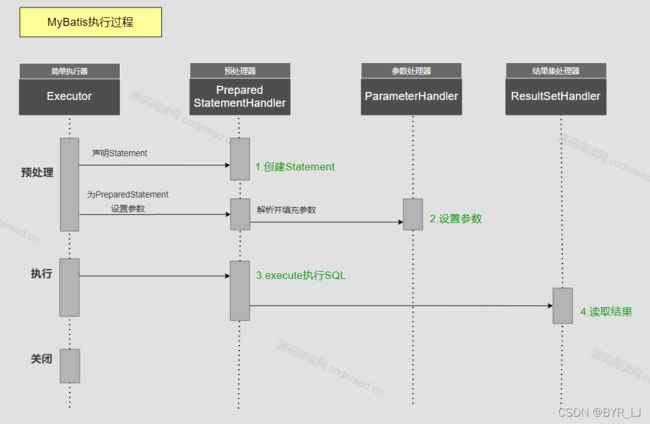
在SimpleExecutor.doQuery()代码中, 会调用
stmt = this.prepareStatement(handler, ms.getStatementLog());
来构建statement,那么其中的细节是什么呢?
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Connection connection = this.getConnection(statementLog);
Statement stmt = handler.prepare(connection, this.transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}大体上包括,构建连接,创建Statement,参数注入;
我们最关心的就是参数注入了,因为我们平时在编写Mapper接口时,有很多种入参的方法,那么我们先看看参数是怎么被注入进来的:
public void parameterize(Statement statement) throws SQLException {
this.parameterHandler.setParameters((PreparedStatement)statement);
}
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(this.mappedStatement.getParameterMap().getId());
List parameterMappings = this.boundSql.getParameterMappings();
if (parameterMappings != null) {
for(int i = 0; i < parameterMappings.size(); ++i) {
ParameterMapping parameterMapping = (ParameterMapping)parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
String propertyName = parameterMapping.getProperty();
Object value;
if (this.boundSql.hasAdditionalParameter(propertyName)) {
value = this.boundSql.getAdditionalParameter(propertyName);
} else if (this.parameterObject == null) {
value = null;
} else if (this.typeHandlerRegistry.hasTypeHandler(this.parameterObject.getClass())) {
// 这里代表参数只有一个
value = this.parameterObject;
} else {
MetaObject metaObject = this.configuration.newMetaObject(this.parameterObject);
// 根据参数名获取入参中的值
value = metaObject.getValue(propertyName);
}
// 根据当前的参数类型找到对应的TypeHander
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = this.configuration.getJdbcTypeForNull();
}
try {
// 根据合适的typeHader来给ps注入参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (SQLException | TypeException var10) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + var10, var10);
}
}
}
}
}
那么再解释以上代码之前,我们需要知道参数传过来是怎样的,是哪个函数设置的参数:
在动态代理的的过程中,继承了InvocationHandle的MapperProxy类实现的invoke方法中会调度MapperMethod类中的execute方法,execute方法会去处理mapper接口的入参,最终调用的就是ParamNameResolver.getNameParams方法
public Object getNamedParams(Object[] args) {
int paramCount = this.names.size();
if (args != null && paramCount != 0) {
if (!this.hasParamAnnotation && paramCount == 1) {
Object value = args[(Integer)this.names.firstKey()];
return wrapToMapIfCollection(value, this.useActualParamName ? (String)this.names.get(0) : null);
} else {
Map param = new ParamMap();
int i = 0;
for(Iterator var5 = this.names.entrySet().iterator(); var5.hasNext(); ++i) {
Entry entry = (Entry)var5.next();
param.put(entry.getValue(), args[(Integer)entry.getKey()]);
String genericParamName = "param" + (i + 1);
if (!this.names.containsValue(genericParamName)) {
param.put(genericParamName, args[(Integer)entry.getKey()]);
}
}
return param;
}
} else {
return null;
}
} 以上代码通过传入的参数,将参数转化
case1 :入参只有一个 -- 那么不做变化 直接将入参返回
case2 : 入参多个,且没有用@Param -- 将参数转化为Map的形式 key值为Param1,Parma2 ···
case3 : 入参多个,使用@Param -- 同样将参数转化为Map的形式 ,key值为@Param中的值
以上流程后,原来的含有“?”的sql已经将对应的参数注入。
注入完参数后则通过StatementHandle执行调度执行PreparedStatement.execute()
执行完毕后将会调用handleResultSets(ps)处理结果
查询到结果后,如何将JDBC的数据转换成JavaBean呢,就要用到ResultSetHander的方法了
public List上面的这个handleResultSets方法是用于处理结果集的逻辑,我们一般只会有单个结果集,因此,我们关注与处理单个结果集的方法:handleResultSet
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List在其中的核心处理方法就是this.handleRowValues()
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
this.ensureNoRowBounds();
this.checkResultHandler();
// 是否是嵌套映射
this.handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 简单映射
this.handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}其中有个判断是否为嵌套映射的逻辑,我们关注于简单映射
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
DefaultResultContext上段代码中就是在依次的对结果集的每一行进行映射存储,核心主要在于getRowValue代码,将每一行数据映射成对应的JavaBean
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 根据xml配置文件中的type生成一个空的目标对象
Object rowValue = this.createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !this.hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
MetaObject metaObject = this.configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (this.shouldApplyAutomaticMappings(resultMap, false)) {
// 自动注入
foundValues = this.applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 手动注入
foundValues = this.applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = !foundValues && !this.configuration.isReturnInstanceForEmptyRow() ? null : rowValue;
}
return rowValue;
}首先根据RequestMap中的type类型生成一个空对象,再进行手动映射或者是自动映射,判断条件就是autoMapping 是否为 ture。那么映射是依据什么,分为手动映射和自动映射
手动映射结果集
我们都写过xml文件中的RequestMap
其中RequestMap下还有一层 RequestMapping 对应的是一对多的关联关系
RequestMapping有哪些呢 ---constructor id result associate collection
可以实现简单的映射,或者是嵌套的映射
自动映射结果集
要求 :
1. 列名和属性名同时存在(忽略大小写)
2. 当前类为手动设置映射
3. 属性类别存在TypeHandler
4. 开启了autoMapping
那么手动注入和自动注入是怎么实现的 -- 核心在于metaObject(基于反射实现的一个工具),大家有空可以再去查别的博客,后续这段源码剖析会跟进。
以上基本是Mybatis与数据库交互的一整套流程,最后再上一幅图:
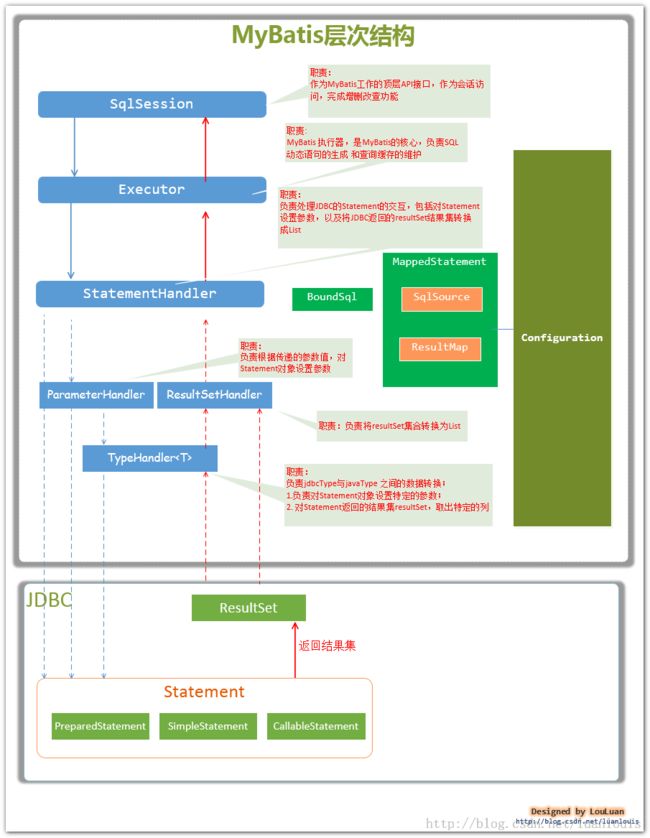
参考文献:
终结篇:MyBatis原理深入解析(一) - 简书 (jianshu.com) MyBatis源码解析大合集_哔哩哔哩_bilibili