2021-12-29大数据学习日志——Hadoop离线阶段——大数据导论、Apache Zookeeper
00_课程内容大纲:
(1)大数据导论
数据与数据分析
数据分析作用和方向(商业领域):离线分析、实时分析、ML机器学习
数据分析的基本步骤 (重要)
大数据时代海量数据处理场景 (重要)如何存储?分布式存储;如何处理?分布式计算
大数据5V特征
大数据应用
分布式、集群
(2)Apache Zookeeper (重要)
zk概念介绍 分布式协调服务软件
zk是分布式小文件存储系统
zk特性:全局数据一致性
zk角色 主从架构
zk集群的搭建
zk的数据模型
zk的操作:shell command
zk watcher监听机制
zk典型应用场景
zookeeper的ZAB协议
脑裂问题
01_大数据导论:数据、数据分析
(1)数据如何来的?
数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的原始素材。
通过对客观事件进行计量和记录就会产生数据 数据量化
(2)数据分析
所谓的数据分析就是通过工具或者方法把隐藏在数据背后的规律和价值提取处理的过程
(3)数据分析的目的(在商业中)
数据分析的结果给企业的决策提供支撑 支持决策
数据仓库的出现也是集成的数据分析平台 分析的结果支撑决策
02_大数据导论:数据分析的作用、方向
2.1 数据分析的作用
各行各业可能都需要开展数据分析,我们重点关注商业领域。也就是说企业为什么需要数据分析
(1)原因分析--对应历史数据
(2)现状分析--对应当下数据
(3)预测分析--结合数据预测未来
2.2 数据分析的方向
(1)离线分析(批处理 batch processing)
分析已有的数据 历史数据,面向过去分析
在时间维度明显成批次性变化。一周一分析(T+7),一天一分析(T+1)
(2)实时分析(Real Time Processing 流处理 Streaming)
分析实时产生的数据 当下的数据 面向当下分析
所谓的实时从数据产生到分析到应用 时间间隔 秒级(spark streaming) 毫秒级(storm flink)
(3)机器学习(Machine Learning,ML)
基于历史数据和当下产生的实时数据预测未来发生的事情
侧重于数学算法的运用。 分类 聚类 关联 预测
03_大数据导论:数据分析基本流程步骤【重要】
数据分析的步骤和流程不仅对我们开展分析提供支撑,同时也对我们去沟通阐述数据分析项目的流程有非常大的支撑。面试时:介绍一下你最近做的项目?如何介绍?介绍什么?
3.1 明确分析的目的和思路
(1)目的:分析方向 分析的主题 要解决什么问题
(2)思路:如何去开展数据分析 关键分析具有体系
体系化也就是逻辑化,简单来说就是先分析什么,后分析什么,使得各个分析点之间具有逻辑联系;需要营销、管理类理论进行支撑 叫做数据分析方法论。 偏向于战略层面 从宏观角度指导
3.2 数据收集
企业常见数据源:
(1)业务数据(RDBMS 关系型数据库 比如:Mysql oracle 事务支持)
(2)日志数据、日志文件(服务器日志、应用日志、用户行为日志)
(3)爬虫数据
(4)其他事数据
3.3 数据预处理
(1)结构化数据、半结构化数据、非结构化数据
(2)大数据青睐什么?结构化数据。
所谓的结构化数据指的是具有schema约束信息的数据。 通俗理解易于程序处理解读的数据。
半结构化数据(json xml)
经过预处理把数据变成干净规则统一整洁的结构化数据
3.4 数据分析
利用技术和软件 基于指标开展分析
3.5 数据应用
(1)数据展现、数据可视化(Data Visualization)
(2)即席查询
(3)数据挖掘
(4)数据接口对外
04_大数据导论:大数据时代(概念、5V特征)
思考:数据为什么会爆炸?
(1)数据大爆炸和面临的挑战
挑战1:海量数据如何存储?
挑战2:海量数据如何高效计算?
(2)大数据5V特点
05_大数据导论:大数据应用
(1)电商领域 传媒领域
(2)金融领域
(3)交通领域 电信领域
(4)安防领域 医疗领域
06_大数据导论:分布式技术
6.1分布式与集群
(1)共同点:多台机器,不是单独的
(2)不同点:
集群:每台机器上的服务是一样的
分布式:每台集群上的服务、组件是不一样的
(3)提醒:口语上,经常会混淆二者概念,都是汲取两者的共同点
搭建一个分布式Hadoop集群,多台机器部署不是单机部署
(4)数据大爆炸和面临的挑战解决方案
如何存储海量数据?存储得下 ---> 分布式存储
如何计算海量数据?高效计算 ---> 分布式计算
(5)扩展:大数据、云计算两个名词如何区分?
大数据侧重于海量数据的分析
云计算侧重于硬件资源的虚拟机技术。云cloud. 阿里云服务器。vmware
公有云:把云资源当做产品卖
私有云:自己公司内部搭建云服务器
混合云:结合上面两点
(6)主从架构集群(master/slave架构)
指的是集群中的角色分类。分为两类:主角色,从角色
主角色:master(主宰; 主人; 有控制力的人) 、leader 、大哥
从角色:slave(奴隶) 、follower、小弟
作用:主从角色各司其职,互相共同配合 对外提供完整的服务
对于主从架构,常见的是一主多从。也就是所谓的一个大哥带领多个小弟
(7)主备架构集群
解决单点故障问题。 所谓的单点故障指的是一个服务当中某个组件出现故障,导致整体服务不可用
局部故障导致整体不可用
主角色: active(活跃的角色)
备份角色:standby(备用物品; 后备人员)
对于主备架构,常见的是一主一备。也可以一主多备,浪费资源
07_Apache Zookeeper 概述、定位、功能
提示:学习任何一款软件框架,都需要首先搞清楚几个问题:
这个软件是什么?(定位问题)这个软件能用来干什么?这个软件怎么用?
这个软件有什么特性和优缺点?
7.1 zookeeper是一个分布式的协调服务软件(distributed coordination)
zookeeper是一个提供分布式协调的开源服务,集群的管理者,监视整个集群各个节点的状态,给用户提供一个简单易用的接口和性能高效、功能稳定的系统(雅虎公司)
分布式:多台机器的环境。
协调服务:在分布式环境下,如何控制大家有序的去做某件事( 顺序、一致、共同、共享),zookeeper 各个组件都会部署在不同的机器上,大家共同配合对外提供服务
7.2 zookeeper的本质:分布式的小文件存储系统
存储系统:存储数据、存储文件 目录树结构
小文件:上面存储的数据有大小限制
分布式:可以部署在多台机器上运行,对比单机来理解
问题:zk这个存储系统和我们常见的存储系统不一样。基于这些不一样产生了很多应用
7.3 zookeeper是一个标准的主从架构集群
主角色、从角色
主从各司其职 共同配合 对外提供服务
08_Apache Zookeeper 全局数据一致性

zk集群中每个服务器保存一份相同的数据副本,客户端无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征
09_Apache Zookeeper 集群的架构与角色职责
zk是标准的主从架构,只不过为了扩大集群的读写能力,同时又不增加选举复杂度,又提供了观察者角色
9.1 主角色 leader
事务性请求的唯一调度和处理者
9.2 从角色 follower
处理非事务性操作 转发事务性操作给leader
参与zk内部选举机制
9.3 观察者角色 observer
处理非事务性操作 转发事务性操作给leader
不参与zk内部选举机制
通俗话:是一群被剥夺政治权利终身的follower,他的作用是在不影响写性能的情况下提升集群的读性能,他只是单纯的提供读取数据的功能
10_Apache Zookeeper 集群搭建、配置文件讲解
10.1 zk集群在搭建部署的时候,通常选择2n+1奇数台。底层 Paxos 算法支持(过半成功)
10.2 zk部署之前,保证服务器基础环境正常、JDK成功安装
(1)服务器基础环境
IP
主机名
hosts映射
防火墙关闭
时间同步
ssh免密登录
(2)JDK环境
jdk1.8
配置好环境变量
10.3 zk具体安装部署(选择node1安装 scp给其他节点)
(1)安装包:zookeeper-3.4.6.tar.gz
(2)上传解压重命名
(3)修改配置文件
(4)把安装包同步到其他节点上
(5)创建其他机器上myid和datadir目录
10.4 Paxos算法
(1)概念
基于消息传递且具有高容错性的一种算法,是目前公然的解决分布式数据一致性问题的最有效的算法,解决了在分布式系统中,如果产生宕机或者网络异常情况,快速的正确的在集群内部对某个数据的值达成一致,并且不管发生任务异常,都不会破坏整个系统的一致性
(2)重要概念:半数原则:少数服从多数
(3)Paxos算法中的四种角色
client:请求发起者,不参与决策,相当于 老板提出了一个项目
proposer:提案提议者, 相当于 秘书把这个项目分发给acceptor
acceptor:提案表决者,只要过半的以上的的acceptor接收了提案,该提案才被认为被选定,相当于 董事会 去 表决这个项目 是否通过
learners:提案的学习者,不参与决策,但提案被选定后,其同步执行提案, 项目执行的人
(4)Paxos算法分为2个阶段
第一阶段:prepare阶段:准备解决
第二阶段:accept阶段:同意阶段
11_Apache Zookeeper 集群启停、进程查看、日志查看
11.1 每台机器上单独启动服务zk集群
#在哪个目录执行启动命令 默认启动日志就生成当前路径下 叫做zookeeper.out
/export/server/zookeeper/bin/zkServer.sh start|stop|status
#3台机器启动完毕之后 可以使用status查看角色是否正常。
#还可以使用jps命令查看zk进程是否启动。
[root@node3 ~]# jps
2034 Jps
1980 QuorumPeerMain #看我,我就是zk的java进程11.2 扩展:编写shell脚本 一键脚本启动
(1)本质:在node1机器上执行shell脚本,由shell程序通过ssh免密登录到各个机器上帮助执行命令
(2)一键启动脚本:
[root@node1 ~]# vim startZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start"
done(3)一键关闭脚本
[root@node1 ~]# vim stopZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "/export/server/zookeeper/bin/zkServer.sh stop"
done(4)注意:关闭java进程时候 根据进程号 直接杀死即可就可以关闭。启动java进程的时候 需要JDK
(5) shell程序ssh登录的时候不会自动加载/etc/profile 需要shell程序中自己加载
12_Apache Zookeeper 数据模型、znode类型(4种)

(1)永久节点(PERSISTENCE)
(2)临时节点(EPHEMERAL)
(3)永久节点序列化(PERSISTENCE_SEQUENTIAL)
(4)临时节点序列化(EPHEMERAL_SEQUENTIAL)
13_Apache Zookeeper Shell命令行操作(CRUD)
13.1 zk的操作页面:自带shell客户端
/export/server/zookeeper/bin/zkCli.sh -server ip
#如果不加-server 参数 默认去连接本机的zk服务 localhost:2181
#如果指定-server 参数 就去连接指定机器上的zk服务
#退出客户端端 ctrl+c13.2 基本操作
(1)创建查看
[zk: node2(CONNECTED) 28] ls /itcast #查看指定路径下有哪些节点
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 29] get /
help
zookeeper itcast
[zk: node2(CONNECTED) 29] get /itcast #获取znode的数据和stat属性信息
1111
cZxid = 0x200000003 #创建事务ID
ctime = Fri May 21 16:20:37 CST 2021 #创建的时间
mZxid = 0x200000003 #上次修改时事务ID
mtime = Fri May 21 16:20:37 CST 2021 #上次修改的时间
pZxid = 0x200000009
cversion = 3
dataVersion = 0 #数据版本号 只要有变化 就自动+1
aclVersion = 0
ephemeralOwner = 0x0 #如果为0 表示永久节点 如果是sessionID数字 表示临时节点
dataLength = 4 #数据长度
numChildren = 3 #子节点个数(2)更新节点数据
set path data(3) 删除节点
[zk: node2(CONNECTED) 43] ls /itcast
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 44] delete /itcast/bbbb0000000002
[zk: node2(CONNECTED) 45] delete /itcast
Node not empty: /itcast
[zk: node2(CONNECTED) 46] rmr /itcast #递归删除14_Apache Zookeeper 监听机制watch
14.1 监听实现需要几步?
step1:设置监听
step2:执行监听
step3:事件发生,触发监听 通知给设置监听的 回调callback
14.2 zk中的监听是什么?
(1)谁监听谁? 客户端监听zk服务
(2)监听什么事? 监听zk上目录树znode的变化情况:znode增加了、删除了、增加子节点了、不见了
14.3 zk中监听实现步骤
(1)设置监听 然后zk服务执行监听
ls path [watch]
没有watch 没有监听 就是查看目录下子节点个数
有watch 有监听 设置监听子节点是否有变化
get path [watch]
监听节点数据是否变化
e.g: get /itheima watch
(2)触发监听
set /itheima 2222 #修改了被监听的节点数据 触发监听
(3)回调通知客户端
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/itheima
14.4 zk的监听特性
(1)先注册、再触发
(2)一次性的监听
(3)异步通知
(4)通知是使用event事件来封装的
state:SyncConnected type:NodeDataChanged path:/itheima
type:发生了什么
path:哪里发生的
14.5 zk中监听类型
(1)连接状态事件监听 系统自动触发 用户如果不关心可以忽略不计
(2)上述所讲的是用户自定义监听 主要监听zk目录树的变化 这类监听必须先注册 再监听
14.6 总结:zk的很多功能都是基于这个特殊文件系统而来的
特殊1:znode有临时的特性
特殊2:znode有序列化的特性,顺序
特殊3:zk有监听机制 可以满足客户端去监听zk的变化
特殊4:在非序列化节点下,路径是唯一的,不能重名
15_Apache Zookeeper 典型应用场景
(1)数据发布与订阅
(2)提供集群选举
(3)分布式锁服务
一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性,多台服务器运行着同一种服务。当多个服务在运行时就需要协调各服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁,如果当前机器挂掉后,并释放fail over到其他的机器继续执行该服务
排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写
共享锁 (Shared Locks),又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都释放
(4)维护配置信息
比如在连接数据库的时候我们需要配置 url,schema,suer和password等等,一般都有一个统一的文件用来存放,但因为分布式许多服务器都需要配置,这时候为了不一个一个去单独配置,我们可以使用zk中的ZAB的一致性协议,来保证每台服务器都有这个配置文件,使用了zk数据一致性的特点
(5)集群管理
一个集群有时会因为各种软硬件故障或者网络故障,出现某种服务器挂掉而被移除集群,而某些服务器加入到集群中的情况,zookeeper会将这些服务器加入/移出的情况下通知给集群汇总的其他正常工作的服务器,以及时调用存储和计算等任务的分配和执行等。此外zookeeper还会对故障的服务器做出诊断并尝试修复
16_zookeeper的ZAB协议
16.1 ZAB协议概述
ZAB(Zookepper Actomic Broadcast) 是专为zk 设计的支持崩溃恢复的原子广播协议。是保证数据一致性的核心算法。ZAB基于2PC算法进行设计,利用了过半性和PAXOS算法进行了改进
16.2 协议状态
ZAB协议中存在着三种状态,每个节点都属于以下三种中的一种:
Looking :系统刚启动时或者Leader崩溃后正处于选举状态
Following :Follower节点所处的状态,Follower与Leader处于数据同步阶段
Leading :Leader所处状态,当前集群中有一个Leader为主进程
16.3 ZAB协议两种模式:崩溃恢复和消息广播
16.3.1 原子广播(Atomic Broadcast)
(1)作用:保证数据一致性。(强一致性+最终一致性)
(2)原子广播基于2PC加入了过半性来进行改进进行设计的
(3)Leader 服务器会为每一个 Follower 服务器都各自分配一个单独的队列,然后将需要广播的事务 Proposal 依次放入这些队列中去,并且根据 FIFO策略进行消息发送。每一个 Follower 服务器在接收到这个事务 Proposal 之后,都会首先将其以事务日志的形式写入到本地磁盘中去,并且在成功写入后反馈给 Leader 服务器一个 Ack 响应。当Leader 服务器接收到超过半数 Follower 的 Ack 响应后,就会广播一个Commit 消息给所有的 Follower 服务器以通知其进行事务提交,同时 Leader 自身也会完成对事务的提交。
16.3.2 崩溃恢复 (Fail Over)
(1)在Zookeeper中,当leader宕机之后,这个Zookeeper不会停止服务,而是会选举出一个新的leader,这个过程称之为崩溃恢复
(2)作用:保证集群的高可用 - 分区容忍性
(3)Zookeeper会给每一个leader分配一个全局递增的编号,称之为epochid。当leader被选举出来之后,这个leader会将自己的epochid分发给每一个follower。每一个follower收到epochid之后,会将这个epochid存储到本地文件acceptedEpoch中
(4)在Zookeeper集群中,事务id实际上由64位二进制(16位十六进制)构成。其中前32位对应的epochid,后32位对应的是实际的事务id。例如事务id为0x400000002表示第4任执行的第2个写操作
(5)当集群启动时,或者leader服务器出现网络中断,崩溃推出或者重启等异常时,zab协议会进入崩溃恢复模式,选举产生新leader,选举成功后,进入消息广播模式。
17_脑裂问题
17.1 产生原因:
集群无主、集群多主
17.2 解决方法
保证任意时刻系统有且只有一个主角色
17.3 QJM
QJM全称Quorum Journal Manager(仲裁日志管理器),是Hadoop官方推荐的HDFS HA解决方案之一
使用zookeeper中ZKFC来实现主备切换
使用Journal Node(JN)集群实现edits log的共享以达到数据同步的目的
17.4 主备切换方法
17.4.1 ZKFC(ZKFailoverController)
ZKFC通过命令监视的NameNode节点及机器的健康状态
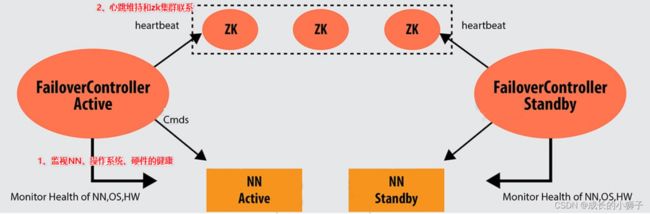
维持和ZK集群联系
通俗的来讲:就是抢锁,
具体操作是,2个NN去争抢去创建一个临时节点(临时节点特性),当其中一个创建成功后,根据znode具有唯一的特性。另一个NN就不可能创建成功了,那么它只能设置监听这个临时节点,直到临时节点消失,再重新争抢
17.4.2 Fencing(隔离)机制
Fencing机制来避免,将先前的Active节点隔离,然后将Standby转换为Active状态
两种实现办法
sshfence**是指通过ssh登陆目标节点上,使用命令fuser将进程杀死(通过tcp端口号定位进程pid,该方法比jps命令更准确);通常都是用这种
shellfence是指执行一个用户事先定义的shell命令(脚本)完成隔离
17.5 数据同步方法
Journal Node(JN)集群是轻量级分布式系统,主要用于高速读写数据、存储数据。
通常使用2N+1台JournalNode存储共享Edits Log(编辑日志)。--底层类似于zk的分布式一致性算法
任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录edits log到至少半数以上的JN中,这时Standby NN 监测到JN 里面的同步log发生变化了会读取JN里面的edits log,然后重演操作记录同步到自己的目录镜像树里面

18_附:随着zk集群的增多,读写的性能会发生什么样的变化?
读的性能会随着机器的增加的而增加,因为读操作 leader和follower都可以操作,如果一开始是三台。那么只能从3台上去读取,当增加到5台时,就能从5台上去读取,性能就会增加,这里有个概念 就是 高并发,理解高并发就知道为什么会随着机器的增加而读性能就会增加,因为高并发会导致 性能的下降,因此增加机器可以有效的减少并发量
写的性能会随着机器的增加而减少,因为写操作只能有leader来操作。leader接收到客户端写的请求的时候,会进行广播,发送给follower,然后follower会根据自己的情况进行ACK响应,只要过半就执行写的操作,比如:一个三台机器,1个leader和2个folloer,那么只要1个leader和1个follower能执行,那就直接执行写操作,不用管另一个follower是否可以执行,因为过半机制。那么现在增加到5台机器,就需要3台机器响应能执行,才能执行写操作,相对来说跟之前比较多出来的1台,就多一次判断,在leader进行广播后,是将数据放在一个地方,follower去读取数据,5台去读取和3台去读取,因为这是读取操作是并行的,因为随着机器的增加并发量也会增加,从而导致写性能下降。
特别注意:上述所增加机器,增加的都是follower,如果增加的是observer,那么写的性能就不会随着机器的增加而减少,因为observer不参加过半机制
zk 3.5 版本开始支持动态扩容