[置顶] C/C++超级大火锅
写在前面
最近接触到一些基础知识,平时遇到的编程困惑也加入其中。准确说是写给自己看的,但是如果大家可以借鉴就更好。多数是c/c++,也有少量Java基础和其他知识,貌似应该叫《计算机基础问题汇总》比较好。不断更新~~
一、new 跟 malloc 的区别是什么?
1.malloc/free是C/C++语言的标准库函数,new/delete是C++的运算符
2.new能够自动分配空间大小
3.对于用户自定义的对象而言,用maloc/free无法满足动态管理对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。因此C++需要一个能对对象完成动态内存分配和初始化工作的运算符new,以及一个能对对象完成清理与释放内存工作的运算符delete—简而言之 new/delete能进行对对象进行构造和析构函数的调用进而对内存进行更加详细的工作,而malloc/free不能。
new 是一个操作符,可以重载
malloc 是一个函数,可以覆盖
new 初始化对象,调用对象的构造函数,对应的delete调用相应的析构函数
malloc 仅仅分配内存,free仅仅回收内存
二、写时拷贝
有一定经验的程序员应该都知道Copy On Write(写时复制)使用了“引用计数”,会有一个变量用于保存引用的数量。当第一个类构造时,string的构造函数会根据传入的参数从堆上分配内存,当有其它类需要这块内存时,这个计数为自动累加,当有类析构时,这个计数会减一,直到最后一个类析构时,此时的引用计数为1或是0,此时,程序才会真正的Free这块从堆上分配的内存。
引用计数就是string类中写时才拷贝的原理!
什么情况下触发Copy On Write(写时复制)
很显然,当然是在共享同一块内存的类发生内容改变时,才会发生Copy On Write(写时复制)。比如string类的[]、=、+=、+等,还有一些string类中诸如insert、replace、append等成员函数等,包括类的析构时。
三、使用引用应该注意什么?
《C++高级进阶教程》中指出,引用的底层实现由指针按照指针常量的方式实现,见:C++引用的本质。非要说区别,那么只能是使用上存在的区别。
-
引用就是对某个变量其别名。对引用的操作与对应变量的操作的效果完全一样。
-
申明一个引用的时候,切记要对其进行初始化。 引用声明完毕后,相当于目标变量名有两个名称,即该目标原名称和引用名,不能再把该引用名作为其他变量名的别名。声明一个引用,不是新定义了一个变量,它只 表示该引用名是目标变量名的一个别名,它本身不是一种数据类型,因此引用本身不占存储单元,系统也 不给引用分配存储单元。
-
不能建立数组的引用。 // 数组的元素不能是引用
-
定义引用的类型,是编译时确定的, int a = 6; double &b = a;
详见:http://blog.csdn.net/scythe666/article/details/50976449
四、如何和一个函数共享一块内存地址
如果不用修改指针,只要传指针过去,那边用指针接收,如果需要修改指针。
指针的引用方法如下:
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
还有一种方法是利用指针的指针。
五、c++中多态体现
编译时多态:编译期确定,重载,模板元编程
运行时多态:虚函数,晚绑定
六、虚函数表存放的位置,一个类有多少个虚函数表?
详见:http://blog.csdn.net/scythe666/article/details/50977593
虚函数表的指针存在于对象实例中最前面的位置。虚函数表是类所拥有的,程序运行过程中不能够修改,它存放在常量区。
一个类若继承了多个含有虚函数的基类,那么该类就有对应数量的虚函数表。
七、vector、deque、list、set、map区别
1、vector
相当于数组。在内存中分配一块连续的内存空间进行存储。支持不指定vector大小的存储。STL内部实现时,首先分配一个非常大的内存空间预备进行存储,即capacituy()函数返回的大小,当超过此分配的空间时再整体重新放分配一块内存存储,这给人以vector可以不指定vector即一个连续内存的大小的感觉。通常此默认的内存分配能完成大部分情况下的存储。
优点:
(1) 不指定一块内存大小的数组的连续存储,即可以像数组一样操作,但可以对此数组进行动态操作。通常体现在push_back() pop_back()
(2) 随机访问方便,即支持[ ]操作符和vector.at()
(3) 节省空间。
缺点:
(1) 在内部进行插入删除操作效率低。
(2)只能在vector的最后进行push和pop,不能在vector的头进行push和pop。
(3) 当动态添加的数据超过vector默认分配的大小时要进行整体的重新分配、拷贝与释放
2、list
双向链表。每一个结点都包括一个信息块Info、一个前驱指针Pre、一个后驱指针Post。可以不分配必须的内存大小方便的进行添加和删除操作。使用的是非连续的内存空间进行存储。
优点:
(1) 不使用连续内存完成动态操作。
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:
(1)不能进行内部的随机访问,即不支持[]操作符和vector.at()
>
(2)相对于verctor占用内存多
3、deque
双端队列 double-end queue
deque是在功能上合并了vector和list。
优点:
(1) 随机访问方便,即支持[ ]操作符和vector.at()
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:
(1) 占用内存多
使用区别:
(1)如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
(2)如果你需要大量的插入和删除,而不关心随即存取,则应使用list
(3)如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque
4、map是,key-value对集合
5、set,就是key=value的map
八、线程、进程、协程区别和联系
力荐插图神作:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
1、进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体。它不只是程序的代码,还包括当前的活动,通过程序计数器的值和处理寄存器的内容来表示。
进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
2、通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。由于线程比进程更小,基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序间并发执行的程度。
3、线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。多线程主要是为了节约CPU时间,发挥利用,根据具体情况而定。线程的运行中需要使用计算机的内存资源和CPU。
4、线程与进程的区别归纳:
a.地址空间和其它资源:进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
b.通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
c.调度和切换:线程上下文切换比进程上下文切换要快得多。
d.在多线程OS中,进程不是一个可执行的实体。
5、优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP机器上运行,而进程则可以跨机器迁移。
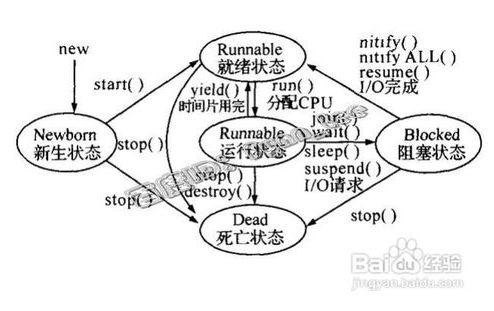
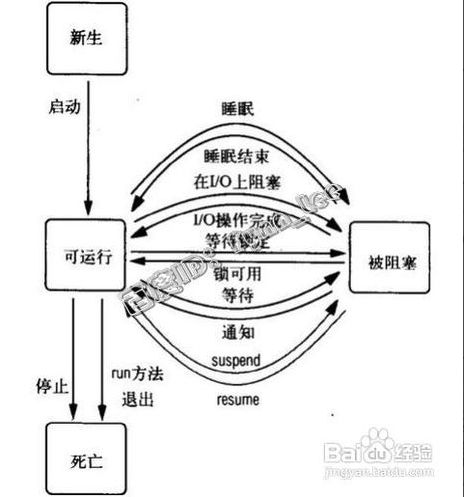
协程详见:http://blog.csdn.net/scythe666/article/details/50987055
九、MySQL innodb myisam 区别
十、堆空间、栈空间区别
十一、64位程序指针多大
8字节
十二、函数内、函数外 static 区别
十三、TCP三次握手和四次挥手
详见http://blog.csdn.net/scythe666/article/details/50967632
十四、守护进程和服务
十五、mysql跑了很久都没有出结果,排除逻辑问题,请问如何检测?
十六、session有什么缺点
十七、数据库范式
十八、java反射机制
十九、java内存回收,是否可以强制内存回收
二十、c++有没有内存回收?
二十一、函数入口地址
如果你在调试程序时查看程序的汇编码,可以发现,调用函数的语句对应的汇编码是
jmp 函数名(入口地址)
- 1
- 1
这样的形式,函数在内存中的存在形式就是一段代码而已,入口地址即函数代码段在内存中的首地址。
二十二、如何判断一个数是2的整数次方
我的分析过程是:
这个肯定是从二进制入手,因为计算机是二进制处理,而且最关键的是2的整数次方是很特殊的 –> 二进制中只有一个1。所以我想可以用二进制来判断1的个数,写函数
x = x&(x-1); //每次减少一个1
cnt++;
- 1
- 2
- 1
- 2
如果cnt为1,这是2的整数次方。这样的方法还不是最简单的方法,可以直接看 x&(x-1) 是否为0即可。
二十三、两个数,如何判断其中一个数的二进制需要变换多少位才能到另一个数
分析:这题比较直接,很明显也是到二进制来处理,相同位放过,不同就标识为1,这样自然联想到异或操作,这就是异或操作的定义。
二十四、给10^8数量级的数组,其他数都是偶数次,只有一个数出现一次。如何快速找到这个数?
将所有数异或起来,结果就是那个数。
二十五、10个文件,每个文件1G,如何排序?
分桶,桶与桶之间一定有大小关系,比如按照大小分100个桶,每个文件遍历,分到桶里,桶内排序,然后合起来就好。
二十六、c++ volatile
volatile 的意思是,“这个数据不知何时会被改变”,可能当时环境正在被改变(可能有多任务、多线程或者中断处理),所以 volatile 告诉编译器不要擅自做出有关该数据的任何假定,优化期间尤其如此。
volatile 的确切含义与具体机器相关,可以通过阅读编译器文档来理解,使用volatile的程序在移到新的机器或编译器时通常必须改变。
与 const 限定符相同的,volatile 也是类型限定符。
与 const 类似的是,只能将 volatile 对象的地址赋给指向 volatile 的指针,或者将指向 volatile 类型的 volatile 类型的指针复制给指向 volatile 的指针。只有当引用为 volatile 时,才可以使用 volatile 对象对引用进行初始化。
二十七、内存对齐
以最大单位大小对齐,比如一个 struct 中有 int[4]; 和 char
详见:http://blog.csdn.net/scythe666/article/details/50985461
二十八、lib和dll的区别
obj:目标文件(二进制)、通过链接器生成exe,obj给出程序的相对地址;exe给出绝对地址。
lib(编译时):若干obj集合。
静态lib:导出声明与实现都在lib中,编译后代码嵌入宿主程序。
动态lib:相当于.h文件,是对实现部分(.dll)的导出部分的声明,运行时需dll支持。
dll(运行时):可实际执行的二进制代码,包含可由多个程序同时使用的代码和数据的库。
不是可执行文件,若知道dll函数原型,程序中LoadLibrary载入,getProAddress();
静态链接使用静态链接库:链接库从静态lib获取引用函数,应用程序较大。
动态链接:lib包含被dll导出的函数名和位置,dll包含实际函数和数据,应用程序用lib文件链接到dll文件。
区别总结:
.dll用于运行阶段,如调用SetWindowText()函数等,需要在user32.dll中找到该函数。DLL可以简单认为是一种包含供别人调用的函数和资源的可执行文件。
.lib用于链接阶段,在链接各部分目标文件(通常为.obj)到可执行文件(通常为.exe)过程中,需要在.lib文件中查找动态调用函数(一般为DLL中的函数)的地址信息,此时需要在lib文件中查找,如查找SetWindowText()函数的地址偏移就需要查找user32.lib文件。(.lib也可用于静态链接的内嵌代码)
二十九、如何看到系统端口占用情况?这个方法底层实现是怎样的?
三十、C++中的骤死式
如果 || 或者 && 如果判断前面不符合要求,后面不会进行计算
三十一、常见网络错误代码
三十二、c++运算符优先级
三十三、c++运算符重载
《剑指offer》上赋值运算符重载
class whString
{
public:
whString& operator = (const whString &str);
whString () {m_pData = NULL;};
whString(const char *s) {
m_pData = new char[strlen(s) + 1];
strcpy(m_pData,s);
}
~whString() {
delete []m_pData;
m_pData = NULL;
}
void stringPrint() {
cout<private:
char *m_pData;
};
whString& whString::operator = (const whString &str) {
cout<<"enter whString::operator =()"<if( &str == this ) //传入的是否是同一个实例
return *this;
delete []m_pData;
m_pData = NULL;
m_pData = new char[strlen(str.m_pData) + 1];
strcpy(m_pData,str.m_pData);
return *this;
}
int main()
{
//freopen("input.txt","r",stdin);
whString a = "abc";
whString b;
b = a;
b.stringPrint();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
注意点:
1、是否把返回值类型声明为该类型引用,并返回实例自身引用(*this),这样才允许连续赋值。
2、传入参数声明为const。
3、是否释放自身内存。
4、检测是否传入同一个参数。
如上代码有更好的形式:
whString& whString::operator = (const whString &str) {
cout<<"enter whString::operator =()"<if( &str != this ) {
whString strTmp(str);
char* pTmp = strTmp.m_pData;
strTmp.m_pData = m_pData; //自动调用析构
m_pData = pTmp;
}
return *this;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
避免了异常安全性。
三十四、c++ 模板元编程
详见:http://blog.csdn.net/scythe666/article/details/50899345
三十五、环境变量作用
三十六、包含目录 库目录 附加依赖项【编译器 参数详解】
三十七、GPL LGPL 等开源协议小览
三十八、常说的sdk、ide、jdk、jre、java runtime 区别
http://www.2cto.com/kf/201212/178270.html
SDK(Software Develop Kit,软件开发工具包),用于帮助开发人员的提高工作效率。各种不同类型的软件开发,都可以有自己的SDK。Windows有Windows SDK,DirectX 有 DirectX 9 SDK,.NET开发也有Microsoft .NET Framework SDK。JAVA开发也不含糊,也有自己的Java SDK。
java SDK最早叫Java Software Develop Kit,后来改名为JDK,即Java Develop Kit。
JDK作为Java开发工具包,主要用于构建在Java平台上运行的应用程序、Applet 和组件等。
JRE(Java Runtime Environment,Java运行环境),也就是Java平台。所有的Java程序都要在JRE下才能运行。JDK的工具也是Java程序,也需要JRE才能运行。为了保持JDK的独立性和完整性,在JDK的安装过程中,JRE也是安装的一部分。所以,在JDK的安装目录下有一个名为jre的目录,用于存放JRE文件。
JVM(Java Virtual Machine,Java虚拟机)是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。
下图清晰地展示了JDK(Java SDK)、JRE和JVM之间的关系:

三十九、注册表详细理解
四十、c++ 函数指针 指针函数
四十一、inline关键字
四十二、Lambda表达式
四十三、c++ 关键字整理
四十四、类的初始化列表
1、作用
2、什么样的成员必须在初始化列表中初始化
3、初始化列表执行时间
四十五、c++ 函数签名
四十六、c++ 基本类型、复合类型
四十七、qmake 小览
四十八、c++多重继承 虚基类
四十九、cpu发展史
五十、域名解析过程
五十一、ebp esp 等寄存器作用
五十二、c++ 中隐藏、重写、覆盖、重载区别
五十三、委托机制
五十四、extern关键字
五十五、DDos、SYNFLOOD攻击
五十六、OS 主分区
五十七、宏函数
五十八、java类是什么负责创建的
五十九、邮件协议
http://www.tuicool.com/articles/MviQv2
1 邮件收发过程
电子邮件发送协议 是一种基于“ 推 ”的协议,主要包括 SMTP ; 邮件接收协议 则是一种基于“ 拉 ”的协议,主要包括 POP协议 和 IMAP协议 ,在正式介绍这些协议之前,我们先给出邮件收发的体系结构:
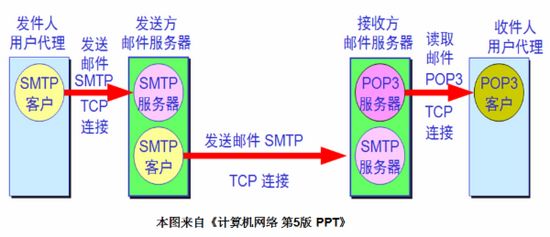
从上图可以看出邮件收发的整个过程大致如下:
(1)发件人调用PC机中的用户代理编辑要发送的邮件。
(2)发件人点击屏幕上的”发送邮件“按钮,把发送邮件的 工作全部交给用户代理来完成。用户代理通过SMTP协议将邮件发送给发送方的邮件服务器( 在这个过程中,用户代理充当SMTP客户,而发送方的邮件服务器则充当SMTP服务器 )。
(3)发送方的邮件服务器收到用户代理发来的邮件后,就把收到的邮件临时存放在邮件缓存队列中,等待时间成熟的时候再发送到接收方的邮件服务器( 等待时间的长短取决于邮件服务器的处理能力和队列中待发送的信件的数量 )。
(4)若现在时机成熟了,发送方的邮件服务器则向接收方的邮件服务器发送邮件缓存中的邮件。在发送邮件之前,发送方的邮件服务器的SMTP客户与接收方的邮件服务器的SMTP服务器需要事先建立TCP连接,之后再将队列中 的邮件发送出去。 值得注意的是,邮件不会在因特网中的某个中间邮件服务器落地 。
(5)接收邮件服务器中的SMTP服务器进程在收到邮件后,把邮件放入收件人的用户邮箱中,等待收件人进行读取。
(6)收件人在打算收信时,就运行PC机中的用户代理,使用POP3(或IMAP)协议读取发送给自己的邮件。 注意,在这个过程中,收件人是POP3客户,而接收邮件服务器则是POP3客户,箭头的方向是从邮件服务器指向接收用户,因为这是一个“ 拉 ”的操作 。
2 电子邮件协议
http://server.zzidc.com/fwqfl/312.html
电子邮件在发送和接收的过程中还要遵循一些基本协议和标准,这些协议主要有SMTP、POP3、IMAP、MIME等。
(1)SMTP协议
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)是Internet上基于TCP/IP的应用层协议,使用于主机与主机之间的电子邮件交换。SMTP的特点是简单,它只定义了邮件发送方和接收方之间的连接传输,将电子邮件有一台计算机传送到另一台计算机,而不规定其他任何操作,如用户界面的交互、邮件的接收、邮件存储等。Internet上几乎所有主机都运行着遵循SMTP的电子邮件软件,因此使用非常普通。另一方面,SMTP由于简单,因而有其一定的局限性,它只能传送ASCII文本文件,而对于一些二进制数据文件需要进行编码后才能传送。
(2)POP3协议和IMAP协议
电子邮件用户要从邮件服务器读取或下载邮件时必须要有邮件读取协议。现在常用的邮件读取协议有两个,一个是邮局协议的第三版本(POP3,Post Office Protocol Version 3),另一个是因特网报文存取协议(IMAP,Internet Message Access Protocol)。
POP3是一个非常简单、但功能有限的邮件读取协议,大多数ISP都支持POP3。当邮件用户将邮件接收软件设定为POP3阅读电子邮件时,每当使用者要阅读电子邮件时,它都会把所有信件内容下载至使用者的计算机,此外,他可选择把邮件保留在邮件服务器上或是不保留邮件在服务器上。无IMAP是另一种邮件读取协议。当邮件用户将邮件接收设定IMAP阅读电子邮件时,它并不会把所有邮件内容下载至计算机,而只下载邮件的主题等信息。
(3)多途径Internet邮件扩展协议
多用途Internet邮件扩展协议(MIME,Multipose Internet Mail Extensions)是一种编码标准,它解决了SMTP只能传送ASCII文本的限制。MIME定义了各种类型数据,如声音、图像、表格、二进制数据等的编码格式,通过对这些类型的数据编码并将它们作为邮件中的附件进行处理,以保证这些部分内容完整、正确地传输。因此,MIME增强了SMTP的传输功能,统一了编码规范。
六十、c++用struct和class定义类型,有什么区别
如果没有标注成员函数或者成员变量的访问权限级别,在struct中默认的是public,而在class中默认的是private。
六十一、map reduce 基本知识
六十二、管程
管程 (英语:Monitors,也称为监视器) 是一种程序结构,结构内的多个子程序(对象或模块)形成的多个工作线程互斥访问共享资源。这些共享资源一般是硬件设备或一群变量。管程实现了在一个时间点,最多只有一个线程在执行管程的某个子程序。与那些通过修改数据结构实现互斥访问的并发程序设计相比,管程实现很大程度上简化了程序设计。
简单点说就是只能被单个线程执行的代码了,举个例子假如一个管程类叫atm(取款机),里面有两个方法叫提款 取款,不同的人为不同的线程,但是atm只允许一个人在一个时间段中进行操作,也就是单线程,那么这个atm就需要一个锁,单一个人在使用时,其他的人只能wait。再者一个人如果使用的时间太长也不行,所以需要一个条件变量来约束他
条件变量可以让一个线程等待时让另一线程进入管程,这样可以有效防止死锁
六十三、子进程可以访问父进程的变量吗?
答:
子进程可以访问父进程变量。子进程“继承”父进程的数据空间,堆和栈,其地址总是一样的。
因为在fork时整个虚拟地址空间被复制,但是虚拟地址空间所对应的物理内存开始却没有复制,如果有写入时写时拷贝。比如,这个时候父子进程中变量 x对应的虚拟地址和物理地址都相同,但等到虚拟地址空间被写时,对应的物理内存空间被复制,这个时候父子进程中变量x对应的虚拟地址还是相同的,但是物理地址不同,这就是”写时复制”。还有父进程和子进程是始终共享正文段(代码段)。
六十四、进程间通信(IPC)的几种方式?哪种效率最高?
答:
(1)管道PIPE和有名管道FIFO – 比如shell的重定向
(2)信号signal – 比如杀死某些进程kill -9,比如忽略某些进程nohup ,信号是一种软件中断
(3)消息队列 – 相比共享内存会慢一些,缓冲区有限制,但不用加锁,适合命令等小块数据。
(4)共享内存 – 最快的IPC方式,同一块物理内存映射到进程A、B各自的进程地址空间,可以看到对方的数据更新,需要注意同步机制,比如互斥锁、信号量。适合传输大量数据。
(5)信号量 – PV操作,生产者与消费者示例;
(6)套接字 – socket网络编程,网络中不同主机间的进程间通信,属高级进程间通信。
六十五、Linux多线程同步的几种方式 ?
答:
(1)互斥锁(mutex) (2)条件变量 (3)信号量。 如同进程一样,线程也可以通过信号量来实现同步,虽然是轻量级的。
这里要注意一点,互斥量可通过pthread_mutex_setpshared接口设置可用于进程间同步;条件标量在初始化时,也可以通过接口pthread_condattr_setpshared指定该条件变量可用于进程进程间同步。
六十六、多核与多个CPU的区别?
我们首先来了解下二者:
何为多核CPU?简单理解就是,我们将多个核心装载一个封装里,让用户理解成这是一个处理器。这样好处就是原本运行在单机上跑的程序基本不需要更改就能够获得非常不错的性能。多核心发展趋势也是英特尔一直坚持的方式。
何为多个CPU运行呢?了解服务器的人都知道有单路,双路,多路之分,而ARM针对服务器市场推出的处理器也是呈现这种方式,最终能够形成分布式系统,其实跟多核CPU内部的分布式结果是一样的,只不过那个从外部看是单个处理器。这种方式在软件支持、运行、故障方面的问题较多。
下面我们举一个例子来形象的比喻一下:
例如,你需要搬很多砖,你现在有一百只手。当你将这一百只手全安装到一个人身上,这模式就是多核。当你将这一百之手安装到50个人身上工作,这模式就是多CPU。
那么多核跟多CPU在应用中有什么区别呢?首先我们看多核的模式,就是一个人身上安一百个手的方式,这个即使这个人再笨,干活速度也要比只有两只手的人要快。
但是将一百只手放在一个人身上,同样会带来一些问题,例如一百只手搬砖太多了,这样身体的脊柱就受不了了,就会顶不住。这就是CPU的多核的极限。于是,当搬砖数量较多的时候,多CPU的方式就显现出来了。人多力量大呀。
六十七、软中断和硬中断的区别?
答:
从本质上来讲,中断是一种电信号,当设备有某种事件发生时,它就会产生中断,通过总线把电信号发送给中断控制器。
如果中断的线是激活的,中断控制器就把电信号发送给处理器的某个特定引脚。处理器于是立即停止自己正在做的事,
跳到中断处理程序的入口点,进行中断处理。
①硬中断是由外部设备对CPU的中断,具有随机性和突发性;软中断由程序控制,执行中断指令产生的、无外部施加的中断请求信号,因此不是随机的而是安排好的。如信号就是软件中断,键盘输入、鼠标点击就是硬件中断。
②硬中断的中断响应周期,CPU需要发中断回合信号(NMI不需要),软中断的中断响应周期,CPU不需发中断回合信号。
③硬中断的中断号是由中断控制器提供的(NMI硬中断中断号系统指定为02H);软中断的中断号由指令直接给出,无需使用中断控制器。
④硬中断是可屏蔽的(NMI硬中断不可屏蔽),软中断不可屏蔽。
六十八、cpu指令集
指令集是存储在CPU内部,对CPU运算进行指导和优化的硬程序。拥有这些指令集,CPU就可以更高效地运行。Intel有x86,EM64T,MMX,SSE,SSE2,SSE3,SSSE3 (Super SSE3),SSE4.1,SSE4.2,AVX。AMD主要是x86,x86-64,3D-Now!指令集。
六十九、UDP和TCP可以绑定同一个端口?
答:
网络中可以被命名和寻址的通信端口,是操作系统可分配的一种资源。
按照OSI七层协议的描述,传输层与网络层在功能上的最大区别是传输层(第四层)提供进程通信能力。从这个意义上讲,网络通信的最终地址就不仅仅是主机地址了,还包括可以描述进程的某种标识符。为此,TCP/IP协议提出了协议端口(protocol port,简称端口)的概念,用于标识通信的进程。
端口是一种抽象的软件结构(包括一些数据结构和I/O缓冲区)。应用程序(即进程)通过系统调用与某端口建立连接(binding)后,传输层传给该端口的数据都被相应进程所接收,相应进程发给传输层的数据都通过该端口输出。在TCP/IP协议的实现中,端口操作类似于一般的I/O操作,进程获取一个端口,相当于获取本地唯一的I/O文件,可以用一般的读写原语访问之。
也就是说:一个端口只能同时被分配给一个进程
类似于文件描述符,每个端口都拥有一个叫端口号(port number)的整数型标识符,用于区别不同端口。由于TCP/IP传输层的两个协议TCP和UDP是完全独立的两个软件模块,因此各自的端口号也相互独立,如TCP有一个255号端口,UDP也可以有一个255号端口,二者并不冲突。
端口号的分配是一个重要问题。有两种基本分配方式:第一种叫全局分配,这是一种集中控制方式,由一个公认的中央机构根据用户需要进行统一分配,并将结果公布于众。第二种是本地分配,又称动态连接,即进程需要访问传输层服务时,向本地操作系统提出申请,操作系统返回一个本地唯一的端口号,进程再通过合适的系统调用将自己与该端口号联系起来(绑扎)。TCP/IP端口号的分配中综合了上述两种方式。TCP/IP将端口号分为两部分,少量的作为保留端口,以全局方式分配给服务进程。因此,每一个标准服务器都拥有一个全局公认的端口(即周知口,well-known port),即使在不同机器上,其端口号也相同。剩余的为自由端口,以本地方式进行分配。TCP和UDP均规定,小于256的端口号才能作保留端口。
再讨论一下,一个服务器监控一个端口,比如80端口,它为什么可以建立上成千上万的连接?
首先, 一个TCP连接需要由四元组来形成,即(src_ip,src_port,dst_ip,dst_port)。当一个连接请求过来的时候,服务端调用accept函数,新生成一个socket,这个socket所占用的本地端口依然是80端口。由四元组就很容易分析到了,同一个(src_ip,src_port),它所对应的(dst_ip,dst_port)可以无穷变化,这样就可以建立很多个客户端的请求了。

七十、如何解决哲学家进餐问题?
答:
哲学家进餐问题是由荷兰学者Dijkstra提出的经典的线程和进程间步问题之一。产生死锁的四个必要条件是:
(1)互斥条件;
(2)请求和保持条件;
(3)不可剥夺条件;
(4)环路等待条件。
筷子是绝对互斥的,我们可以破坏其它三种条件来解决哲学家进餐问题。解决办法如下:
(1)破坏请求保持条件
利用原子思想完成。即只有拿起两支筷子的哲学家才可以进餐,否则,一支筷子也不拿。(2)破坏不可剥夺条件
当哲学家相互等待时,选择一个哲学家作为牺牲者,放弃手中的筷子,这样就保证有一位哲学家可以就餐了。(3)破坏环路等待条件
解法一:奇数号哲学家先拿他左边的筷子,偶数号哲学家先拿他右边的筷子。这样破坏了同方向环路;
解法二:至多允许N-1位哲学家进餐,将最后一个哲学家停止申请资源,断开环路。最终能保证有一位哲学家能进餐,用完释放两只筷子,从而使更多的哲学家能够进餐。
七十一、堆排序和快速排序的区别?
答:
堆排序和快速排序都是比较类非线性比较类排序中较优的排序方法,均是不稳定排序,且平均时间复杂度均为O(nlogn)。区别有二:
(1)堆属于选择类排序,快速排序属于交换类排序;
(2)堆排序一般优于快速排序的重要一点是,数据的初始分布情况对堆排序的效率没有大的影响。
具体实现参考:十种常见排序算法。
七十二、反转单链表
答:
ListNode* reverseList(ListNode* pHead){
ListNode* pReverseHead=NULL;
ListNode* pNode=pHead;
ListNode* pPrev=NULL;
while(pNode){
ListNode* next=pNode->m_next; //先保存当前被处理节点的下一个节点
if(NULL==next){//原链表的最后一个节点
pReverseHead=pNode;
break;
}
pNode->m_next=pPrev;//该节点的前一个节点
pPrev=pNode;
pNode=next;
}
return pReverseHead;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
七十三、如何判断单链表是否存在环?
答:
算法的思想是设定两个指针p, q,其中p每次向前移动一步,q每次向前移动两步。那么如果单链表存在环,则p和q相遇;否则q将首先遇到null。
七十四、打印杨辉三角
#include 1][j]+a[i-1][j-1];
}
for(i=0;i<10;i++)
{
for(j=0;j<(10-i-1);++j)
printf(" "); //每行前需要空的数的位置,每个数占4个空格
for(j=0;j<=i;j++)
printf("%4d ",a[i][j]);
printf("\n");
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
七十五、虚基类的作用是什么,虚基类的实现机制就是什么呢?
答:
虚基类的作用是在C++多重继承的情况下,如果出现菱形继承的话,为了消除在子类中出现父类数据实体的多份拷贝。
虚基类的实现机制这个有点复杂。不同编译器内部实现的机制也不相同。其主要有两种实现方案:
(1)是引入virtual base class table,不管多少个虚基类,总是只有一个指针指向它,这个virtual base class table(VBTBL)包括真正的 virtual base class 指针。
(2)Bjarne的办法是在virtual function table中放置virtual base class的offset,而非地址,这个offset在virtual function table 的负位置(正值是索引virtual function,而负值则将方向盘引到virtual base class offsets)。
在VC++中,采用的是类似第一种方案。对每个继承自虚基类的类实例,将增加一个隐藏的“虚基类表指针”(vbptr)成员变量,从而达到间接计算虚基类位置的目的。该变量指向一个全类共享的偏移量表,表中项目记录了对于该类而言,“虚基类表指针”与虚基类之间的偏移量”,而不是真正的 virtual base class 指针,这就是说类似于上面的第一种方案,而非严格按照该方案。具体参见C++虚继承对象的内存布局。
对于g++,实现上和VC++不同,它并没有生成独立的虚基类表和虚基类表指针来指明虚基类的偏移地址,具体实现细节我还不太清楚,可能《深度探索c++对象模型》会有说明。这是只是测试了当子类存在虚函数表指针和虚函数表时,编译器并不会为子类对象实体生成额外的一个虚基类表指针。
但是当子类没有虚函数表指针时,编译器会为子类对象生成一个指针变量,这个指针变量很可能就是指向虚基类表。种种迹象表明g++的实现方案和上面提到的第二种方案很相似,具体我没有深入研究其对象布局,以后再探讨我猜测的真伪。
七十六、C++的单例模式
class CSingleton
{
private:
CSingleton() //构造函数是私有的
{
}
static CSingleton *m_pInstance;
public:
static CSingleton * GetInstance()
{
if(m_pInstance == NULL) //判断是否第一次调用
m_pInstance = new CSingleton();
return m_pInstance;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
七十七、数按位颠倒

七十八、TCP/IP 流量控制和拥塞控制
七十九、arp攻击
arp 攻击是:
ARP攻击就是通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断的发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。
八十、KMP的时间复杂度
O(m+n)
八十一、并查集
原问题描述:有A、B两个犯罪团伙,给定n个人,然后给定m组关系,比如:r(1,2),代表1和2号犯人不在一个团伙中,会随机问给定的两个人在不在一个组织中,比如:q(x1,x2)。回答:是就是,不是就不是,不知道就不知道
八十二、如何在O(1)时间下,不申请空间前提下,删除链表的某个节点。
交换后面的节点和当前节点,删除下一个节点。但是对于最后一个节点,只能从前往后找到pre节点,这样的复杂度是O(n),但是平均复杂度是O(1)
八十三、交换值
a = a^b;
b = a^b;
a = a^b;
- 1
- 2
- 3
- 1
- 2
- 3
或者如下:
a = a + b;
b = a - b;
a = a - b;
- 1
- 2
- 3
- 1
- 2
- 3
八十四、如果socket建立连接后,发送50000字节,那边可以接收到多少个?
根据真实的网络环境,那边可能会接收到不定的字节。
八十五、为什么拷贝构造函数要用引用
不然会一直无限传值,直到栈溢出。
八十六、如何让一个类不能被继承
构造函数私有化
八十七、分页算法和页内组织形式
八十八、如何判断大端小端模式
八十九、如下代码有什么问题?
class CTest
{
public:
int a;
CTest() {memset(this,0,sizeof(*this)); }
void printSize() {cout<<sizeof(*this)<int main()
{
//freopen("input.txt","r",stdin);
CTest t;
//t.printSize();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
引申:this指针放在哪里?
九十、strcpy、memcpy、memmove区别?strcpy的结束标志是什么?
九十一、new做了什么?重载operator new应该注意什么?
new分配内存+调用构造函数
注意事项:
(1)重载 operator new 的同时也需要一并重载 operator delete,因为如果调用 delete 是默认的delete,这样你在new重载里面做的事情只有你自己知道,默认的不会去做,就会付出惨重的代价。
//这不是个很简单的事(详细参考《Effective C++ Third Edition》 Item 51)。operator new 通常这样编写:
// 这里并没有考虑多线程访问的情况
void* operator new(std::size_t size) throw(std::bad_alloc)
{
using namespace std;
// size == 0 时 new 也必须返回一个合法的指针
if (size == 0)
size = 1;
while (true) {
//尝试进行内存的分配
if (内存分配成功)
return (成功分配的内存的地址);
// 内存分配失败时,查找当前的 new-handling function
// 因为没有直接获取到 new-handling function 的办法,因此只能这么做
new_handler globalHandler = set_new_handler(0);
set_new_handler(globalHandler);
// 如果存在 new-handling function 则调用
if (globalHandler) (*globalHandler)();
// 不存在 new-handling function 则抛出异常
else throw std::bad_alloc();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
(2)不要轻易重载全局 new(文件作用域)
重载 ::operator new() 的理由
Effective C++ 第三版第 50 条列举了定制 new/delete 的几点理由:
检测代码中的内存错误
优化性能
获得内存使用的统计数据
这些都是正当的需求,但是不重载 ::operator new() 也能达到同样的目的。
http://www.360doc.com/content/12/1211/17/9200790_253442412.shtml
九十二、如下代码sizeof输出多少?如何强制内存对齐?
struct TStruct
{
int a;
char b;
double c;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
跟顺序相关。。。
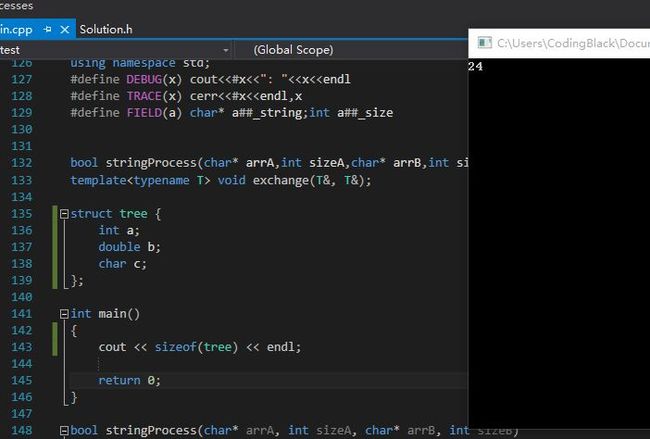
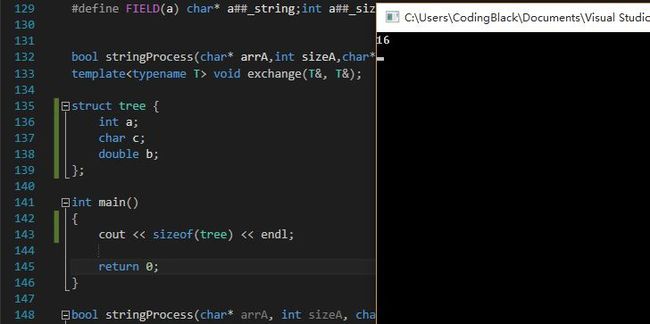
1、结构体成员变量相对于结构体对象的首地址的偏移量是该成员变量类型大小的整数倍。
2、整个结构体对象的最终大小是结构体成员变量中类型大小最大的整数倍。
struct tmp {
int aa;
int bb;
int cc;
};
struct tree {
char c;
double b;
int a;
tmp ss;
};
int main()
{
cout << sizeof(tmp) << endl;
cout << sizeof(tree) << endl;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
结果显示:
12
32
1+7+8+4+4+4+4 = 32
另:不要把被嵌套的结构体当成一个整体
如下代码:
struct tmp {
int aa;
char bb;
double cc;
};
struct TStruct
{
char c;
double b;
int a;
tmp ss;
};
int main()
{
cout << sizeof(tmp) << endl;
cout << sizeof(TStruct) << endl;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出:
16
40
1+7+8+4+4+1+7+8 = 40
九十三、int a[100]; a+3是加了多少?
int a[100];
cout<<a<;
cout<<a+3<;
- 1
- 2
- 3
- 1
- 2
- 3
实测加了12
九十四、__stdcall、fastcall、__cdecl
调用规范简介
首先,要实现函数调用,除了要知道函数的入口地址外,还要向函数传递合适的参数。向被调函数传递参数,可以有不同的方式实现。这些方式被称为“调用规范”或“调用约定”。C/C++中常见的调用规范有__cdecl、__stdcall、__fastcall和__thiscall。
__cdecl调用约定
又称为C调用约定,是C/C++默认的函数调用约定,它的定义语法是:
int function (int a ,int b) // 不加修饰就是C调用约定
int __cdecl function(int a,int b) // 明确指出C调用约定
- 1
- 2
- 1
- 2
约定的内容有:
(1)参数入栈顺序是从右向左;
(2)在被调用函数 (Callee) 返回后,由调用方 (Caller)调整堆栈。
由于这种约定,C调用约定允许函数的参数的个数是不固定的,这也是C语言的一大特色。因为每个调用的地方都需要生成一段清理堆栈的代码,所以最后生成的目标文件较__stdcall、__fastcall调用方式要大,因为每一个主调函数在每个调用的地方都需要生成一段清理堆栈的代码。
__stdcall调用约定
又称为标准调用约定,申明语法是:
int __stdcall function(int a,int b)
- 1
- 1
约定的内容有:
(1)参数从右向左压入堆栈;
(2)函数自身清理堆栈;
(3)函数名自动加前导的下划线,后面紧跟一个@符号,其后紧跟着参数的尺寸;
(4)函数参数个数不可变。
__fastcall调用约定
又称为快速调用方式。和__stdcall类似,它约定的内容有:
(1) 函数的第一个和第二个DWORD参数(或者尺寸更小的)通过ecx和edx传递,其他参数通过从右向左的顺序压栈;
(2)被调用函数清理堆栈;
(3)函数名修改规则同stdcall。
其声明语法为:
int __fastcall function(int a,int b);
- 1
- 1
注意:不同编译器编译的程序规定的寄存器不同。在Intel 386平台上,使用ECX和EDX寄存器。使用__fastcall方式无法用作跨编译器的接口。
__thiscall调用约定
是唯一一个不能明确指明的函数修饰,因为thiscall不是关键字。它是C++类成员函数缺省的调用约定。由于成员函数调用还有一个this指针,因此必须特殊处理,thiscall意味着:
(1) 参数从右向左入栈;
(2) 如果参数个数确定,this指针通过ecx传递给被调用者;如果参数个数不确定,this指针在所有参数压栈后被压入堆栈;
(3)对参数个数不定的,调用者清理堆栈,否则函数自己清理堆栈。
http://blog.csdn.net/K346K346/article/details/47398243
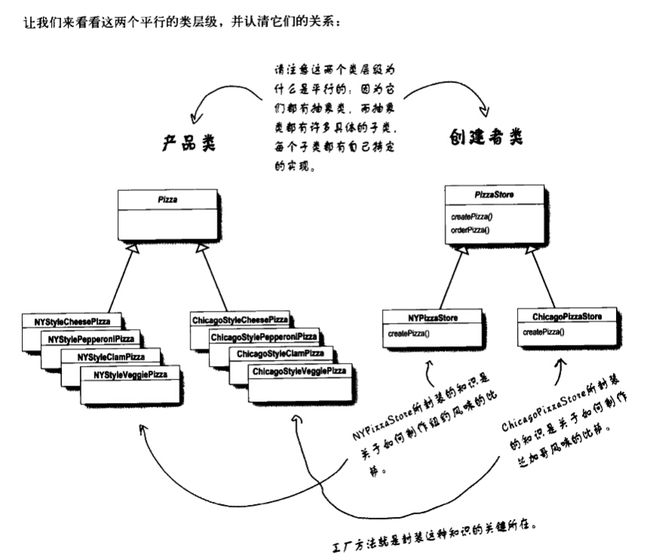
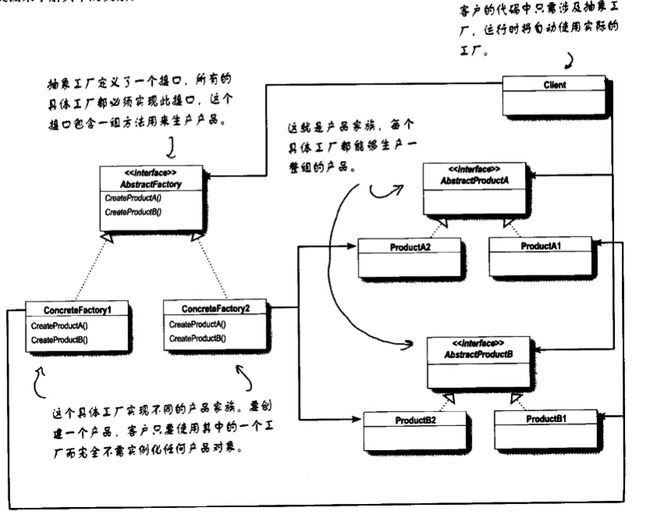
九十五、工厂模式、装饰者模式、观察者模式类图?MVC中M、V、C是单向的还是双向
1、工厂模式
抽象工厂
九十六、编译器断点如何实现的
九十七、debug和release的区别是什么?为什么有时候在debug模式下运行无误,但在release模式下出错?编译器debug模式在可执行文件中加入了什么信息
(1)debug 中放入调试信息,比如符号表
(2)debug 是代码直译,release 可能有优化,比如寄存器易失问题。不用的变量去掉
九十八、如何最快把一个整数拆成3个小于它的 c 整数
九十九、ipc的几种方式
(1)管道PIPE和有名管道FIFO – 比如shell的重定向
(2)信号signal – 比如杀死某些进程kill -9,比如忽略某些进程nohup ,信号是一种软件中断
(3)消息队列 – 相比共享内存会慢一些,缓冲区有限制,但不用加锁,适合命令等小块数据。
(4)共享内存 – 最快的IPC方式,同一块物理内存映射到进程A、B各自的进程地址空间,可以看到对方的数据更新,需要注意同步机制,比如互斥锁、信号量。适合传输大量数据。
(5)信号量 – PV操作,生产者与消费者示例;
(6)套接字 – socket网络编程,网络中不同主机间的进程间通信,属高级进程间通信。
一百、线程同步的方式
(1)互斥量(mutex)、(2)条件变量、(3)信号量。 如同进程一样,线程也可以通过信号量来实现同步,虽然是轻量级的。
这里要注意一点,互斥量可通过pthread_mutex_setpshared接口设置可用于进程间同步;条件标量在初始化时,也可以通过接口pthread_condattr_setpshared指定该条件变量可用于进程进程间同步。
一百零一、Unicode utf ansi具体是如何编码的
utf-8 中文字符有些字符占2个有些3个,英文字符都是1个;ucs2 统一是2个
一百零二、冒泡复杂度、改进冒泡
一百零三、计算快排和堆排复杂度?最好的排序算法?
一百零四、如何检测内存泄漏?
借鉴java的引用计数器
一百零五、如下 a 和 b 哪个地址大?
int main()
{
int a;
int b;
cout<<&a<cout<<&b<return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
a地址更大,a先入栈。
一百零六、define 和 typedef 的区别
1、定义
define是宏定义,在预处理阶段进行字符串替换。
typedef是关键字,声明类型别名,在编译时处理(增加可读性)。
2、define相当于单纯的字符串替换
#define int_ptr int* //不能颠倒位置
int_ptr a,b; //相当于 int *a,b; a是复合类型int *,b 只是int
- 1
- 2
- 1
- 2
#typedef int* int_ptr //不能颠倒位置
int_ptr a,b; //相当于 int *a,b; a是复合类型int *,b 只是int
- 1
- 2
- 1
- 2
3、跟const连用
typedef int* pint;
#define PINT int*
const pint P; //相当于int* const P(const 修饰 int *),P的指向不能改
const PINT P; //相当于const int* P,P指向的内容不能改
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
4、typedef 语法上是一个存储类的关键字,如 static、auto、extern、mutable、register。
typedef static int INT2; //编译失败,指定了一个以上的存储类
- 1
- 1
一般遵循:
define 定义“可读”的变量以及一些宏语句任务(包括无参和带参)
typedef 常用来定义关键字,冗长的类型的别名
一百零七、ofstream
一百零八、32位/64位 基本类型变量会不同吗
是的,c++基本数据类型的变量占据内存字节数的多少根运行平台有关。
一百零九、如果用0-9、a、b、c表示32进制的整数,那10进制数873085表示的是什么?
一百一十、如果父类指针指向子类,开始运行没错,但是后来崩溃了,可能原因是什么?
可能这个指针指向的空间已被释放,或者是这个函数里面出错了。
一百一十一、可否写一个程序扫描整个内存空间?
一百一十二、编译链接做了什么
目标程序又称“目的程序”
由编译程序将源程序编译成与之等价的由机器码构成的,计算机能直接运行的程序,该程序叫目标程序。
链接器 (linker)
将一个个的目标文件 ( 或许还会有若干程序库 ) 链接在一起生成一个完整的可执行文件。
在符号解析 (symbol resolution) 阶段,链接器按照所有目标文件和库文件出现在命令行中的顺序从左至右依次扫描它们,在此期间它要维护若干个集合 :
(1) 集合 E 是将被合并到一起组成可执行文件的所有目标文件集合;
(2) 集合 U 是未解析符号 (unresolved symbols ,比如已经被引用但是还未被定义的符号 ) 的集合;
(3) 集合 D 是所有之前已被加入到 E 的目标文件定义的符号集合。一开始, E 、 U 、 D 都是空的。
链接器的工作过程:
(1): 对命令行中的每一个输入文件 f ,链接器确定它是目标文件还是库文件,如果它是目标文件,就把 f 加入到 E ,并把 f 中未解析的符号和已定义的符号分别加入到 U 、 D 集合中,然后处理下一个输入文件。
(2): 如果 f 是一个库文件,链接器会尝试把 U 中的所有未解析符号与 f 中各目标模块定义的符号进行匹配。如果某个目标模块 m 定义了一个 U 中的未解析符号,那么就把 m 加入到 E 中,并把 m 中未解析的符号和已定义的符号分别加入到 U 、 D 集合中。不断地对 f 中的所有目标模块重复这个过程直至到达一个不动点 (fixed point) ,此时 U 和 D 不再变化。而那些未加入到 E 中的 f 里的目标模块就被简单地丢弃,链接器继续处理下一输入文件。
(3): 如果处理过程中往 D 加入一个已存在的符号 ,或者当扫描完所有输入文件时 U 非空,链接器报错并停止动作。否则,它把 E 中的所有目标文件合并在一起生成可执行文件。
这种”翻译”通常有两种方式,即编译方式和解释方式。编译方式是指利用事先编好的一个称为编译程序的机器语言程序,
作为系统软件存放在计算机内,当用户将高级语言编写的源程序输入计算机后,编译程序便把源程序整个地翻译成用
机器语言表示的与之等价的目标程序,然后计算机再执行该目标程序,以完成源程序要处理的运算并取得结果。
解释方式是指源程序进入计算机后,解释程序边扫描边解释,逐句输入逐句翻译,计算机一句句执行,并不产生目标程序。
http://blog.chinaunix.net/uid-11572501-id-2868702.html
一百一十三、可变参函数
#include // 必须包含的头文件
int Add(int start,...) // ...是作为占位符
{
va_list arg_ptr; // 定义变参起始指针
int sum=0; // 定义变参的和
int nArgValue =start; //
va_start(arg_ptr,start); // arg_ptr指向第一个变参
do
{
sum+=nArgValue; // 求和
nArgValue = va_arg(arg_ptr,int); // arg_ptr指向下一个变参
}
while(nArgValue != 0); // 判断结束条件;结束条件是自定义为=0时结束
va_end(arg_ptr); // 复位指针
return sum;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
函数的调用方法为Add(1,2,3,0);这样,必须以0结尾,因为变参函数结束的判断条件就是读到0停止。
解释:
所使用到的宏:
void va_start( va_list arg_ptr, prev_param );
type va_arg( va_list arg_ptr, type );
void va_end( va_list arg_ptr );
typedef char * va_list;
#define _INTSIZEOF(n) ((sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
#define va_start(ap,v) ( ap = (va_list)&v + _INTSIZEOF(v) )
#define va_arg(ap,t) ( (t )((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
#define va_end(ap) ( ap = (va_list)0 )
1、首先把va_list被定义成char*,这是因为在我们目前所用的PC机上,字符指针类型可以用来存储内存单元地址。而在有的机器上va_list是被定义成void*的
2、定义_INTSIZEOF(n)主要是为了某些需要内存的对齐的系统.这个宏的目的是为了得到最后一个固定参数的实际内存大小。在我的机器上直接用sizeof运算符来代替,对程序的运行结构也没有影响。(后文将看到我自己的实现)。
3、va_start的定义为 &v+_INTSIZEOF(v) ,这里&v是最后一个固定参数的起始地址,再加上其实际占用大小后,就得到了第一个可变参数的起始内存地址。所以我们运行va_start(ap, v)以后,ap指向第一个可变参数在的内存地址,有了这个地址,以后的事情就简单了。
这里要知道两个事情:
⑴在intel+windows的机器上,函数栈的方向是向下的,栈顶指针的内存地址低于栈底指针,所以先进栈的数据是存放在内存的高地址处。
(2)在VC等绝大多数C编译器中,默认情况下,参数进栈的顺序是由右向左的,因此,参数进栈以后的内存模型如下图所示:最后一个固定参数的地址位于第一个可变参数之下,并且是连续存储的。
|--------------------------|
| 最后一个可变参数 | ->高内存地址处
|--------------------------|
|--------------------------|
| 第N个可变参数 | ->va_arg(arg_ptr,int)后arg_ptr所指的地方,
| | 即第N个可变参数的地址。
|--------------- |
|--------------------------|
| 第一个可变参数 | ->va_start(arg_ptr,start)后arg_ptr所指的地方
| | 即第一个可变参数的地址
|--------------- |
|------------------------ --|
| |
| 最后一个固定参数 | -> start的起始地址
|-------------- -| .................
|-------------------------- |
| |
|--------------- | -> 低内存地址处
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
(4) va_arg():有了va_start的良好基础,我们取得了第一个可变参数的地址,在va_arg()里的任务就是根据指定的参数类型取得本参数的值,并且把指针调到下一个参数的起始地址。
因此,现在再来看va_arg()的实现就应该心中有数了:
#define va_arg(ap,t) ( (t )((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
这个宏做了两个事情,
①用用户输入的类型名对参数地址进行强制类型转换,得到用户所需要的值
②计算出本参数的实际大小,将指针调到本参数的结尾,也就是下一个参数的首地址,以便后续处理。
(5)va_end宏的解释:x86平台定义为ap=(char*)0;使ap不再 指向堆栈,而是跟NULL一样.有些直接定义为((void*)0),这样编译器不会为va_end产生代码,例如gcc在Linux的x86平台就是这样定义的. 在这里大家要注意一个问题:由于参数的地址用于va_start宏,所以参数不能声明为寄存器变量或作为函数或数组类型. 关于va_start, va_arg, va_end的描述就是这些了,我们要注意的 是不同的操作系统和硬件平台的定义有些不同,但原理却是相似的.
一百一十四、函数签名
C++函数签名包括 函数名、参数个数、参数类型
不包括返回类型
c语言函数签名只包含函数名
一百一十五、要实现一个云盘,应该如何分模块?
个人观点:
按照用户动作流来划分是最直观的。
client端有:文件安全监测模块,md5生成模块
传输模块
server端有:存储模块(包括文件副本计数器+冗余备份)、用户模块(用户管理+用户文件对应表)
一百一十六、云盘如何判断一个文件安全性?
后缀名+病毒特征码
一百一十七、云盘传输过程中,应该选择TCP还是UDP?如何选择第5层协议?
udp可以手工实现重传。
一百一十八、给一个10T硬盘空间,在没有文件系统的情况下,云盘文件应该如何组织?最好不要用到db。
这里需要说明一下,有没有文件系统,跟程序得到的地址是不是虚拟地址没有关系。虚拟地址和物理地址的映射关系是内核做的。
一百一十九、用户和文件如何组织?还有用户可能对应目录和文件,目录可以嵌套,应该如何组织?
一百二十、用户云盘上传下载慢,可能原因有哪些?
1、没充会员
2、运营商不同
3、ddos攻击
4、服务器和用户太远,路由跳数太多
5、服务器访问量太大
一百二十一、如何监测磁盘瞬时读写量过大?
一百二十二、STL容器
(1)标准STL序列容器:vector、string、deque(双向)、list(双向)
(2)标准STL关联容器:set(值唯一)、multiset、map、multimap
(3)非标准序列容器:slist(单向)和 rope
(4)非标准的关联容器:hash_set、hash_multiset、hash_map、hash_multimap
(5)几种标准的非STL容器:数组、bitset、stack、queue 和 priority_queue
关于容器内存存储方式
(1)连续内存容器:元素放在一或多块内存,每块内存多个元素,插入或删除时,同一内存块其他元素也会发生移动, vector,string,deque,rope
(2)基于节点的容器:内个内存块只放一个元素,list,slist,标准关联容器,非标准的哈希容器。
建议:
(1)vector、deque、list:vector默认,序列中间频繁插入删除,用list,头尾插入删除,用deque。
(2)任意位置插入:选择序列容器
(3)随机访问迭代器:用vector、deque、string、rope
(4)考虑元素查找速度:hash容器、排序vector,标准关联容器
(5)插入删除,需要事务语义:基于节点(每个内存块只放一个元素,list、slist)
一百二十三、struct和class
struct:默认public(成员/继承),编译器不为struct保留内存空间。
class:默认 private(成员/继承),为类保留
两者都可以继承、构造/析构、多态
一百二十四、cpu的位数,操作系统的位数,编译器中编译的位数有什么关联
一百二十五、一共有10t货物,装到若干箱子中,箱子最多装1t货物(不考虑箱子数量)。现在有载重3t的货车,问至少要多少辆车一定能装完这些货物?
http://www.mofangge.com/html/qDetail/02/c0/201310/b88kc002360282.html
有几个地方要想通:
(1)不是4就是5
(2)每个箱子平均比不平均更容易造成4辆车装不完的局面
(3)在(2)成立的条件下,如果分的箱子越少,越容易造成4辆车装不完,因为颗粒越小越容易匀开。
(4)在(2)成立条件下,必须不能被4整除,否则每辆车2.5吨一定可以搞定。
这样就可以列出下面的编程公式:
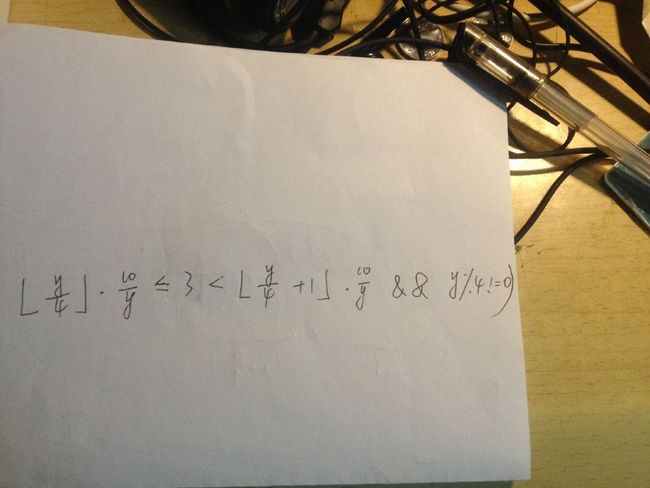
y代表箱子的个数,那么 10/y 代表每个箱子重量。
通过编程累加y到一个上限(个人感觉100足以),如果存在y,就证明4辆装不完。
可以求出,y为13的时候成立
一百二十六、树和hash_map的优缺点
一百二十七、效率优先的情况下,输入一些0-99999的数,实现一个数据结构,高效完成删除、插入、查找、遍历、计数个数
一百二十八、MIN_INT
今天在看《深入理解计算机系统》的时候,在p105页作者给出了INT_MIN在标准头文件limits.h中的定义
#define INT_MAX 2147483647
#define INT_MIN (-INT_MAX - 1)
- 1
- 2
- 1
- 2
这里没有简单地将INT_MIN赋值成-2147483647,是因为-2147483648对于编译器而言是个表达式,而2147483648对于32-bit整数是无法表示的,所以经过这个表达式的结果是未定义的。在GCC上直接写-2147483648后,编译器给出了警告,说结果是unsigned。
这里有一篇文章提到了其中的缘由,可以参考:INT_MIN
十六进制输入,应该输入的就是计算机的存放方式,是补码存放。
比如:
int main()
{
//freopen("input.txt","r",stdin);
int a = INF;
int maxInt = 0x7fffffff; //最大int
int minusOne = 0xffffffff; //-1
int minInt = 0x80000000; //最小int
int minusMaxInt = 0x80000001; //-maxInt
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
http://blog.csdn.net/seizef/article/details/7605010
一百二十九、如何传入一个数组,而不退化为指针?
void func(int (&b) [20][10]) {
//通过数组的引用
}
void func(int *b) {
}
int main()
{
//freopen("input.txt","r",stdin);
int a[20][10];
a[2][1] = 5;
func(a);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
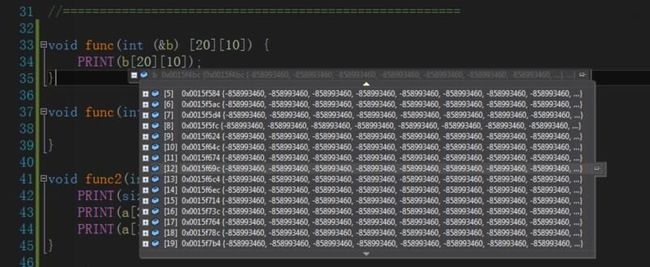
现在又有一个问题:如果构成指针和引用数组这样的重载,到底先进哪一个?
我的思考是,应该进引用那个,因为类似于 int 和 double ,func(5) 会优先选用 int,就在于数组a类型原本是数组,所以会优先用原类型。
引用的确是传的数组,而传值是传递的指针,编译器将其退化了
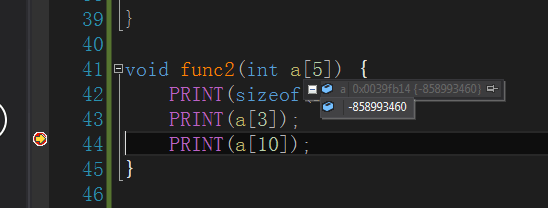
如果是传引用,调试的时候有宽度限制(行下标从0-19),这就证明是数组,打印sizeof是20*10*4= 800
如果是指针,只有一个指针的地址,而且打印sizeof也是一个指针的值:
一百三十、如何返回一个数组?
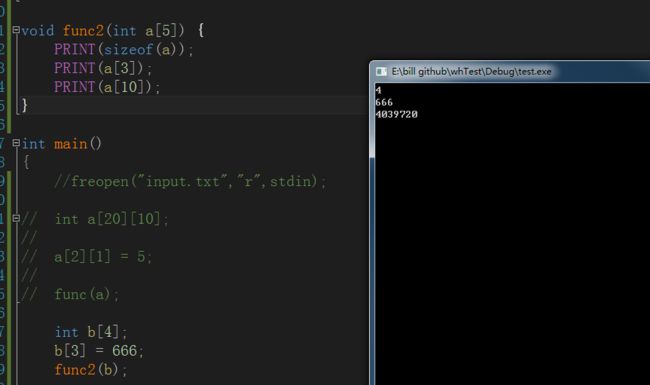
一百三十一、可不可以将int b[4]传给参数int a[5]
答案是:传值可以,引用不行
数组传值那边退化为指针
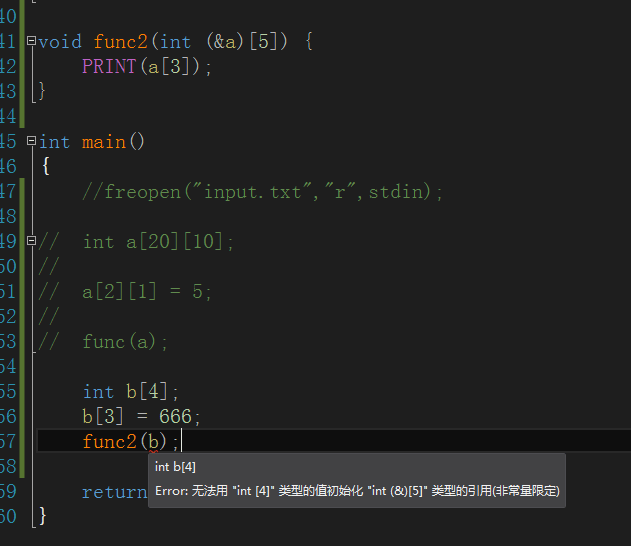
一百三十二、关于数组越界
不论读写都不会报错,测试平台vs2012
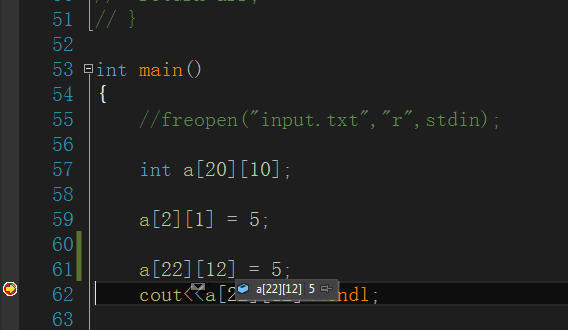
那当数组影响到其他变量的时候会不会报错呢,比如在函数栈中定义一些其他变量,数组越界写到别的地方。
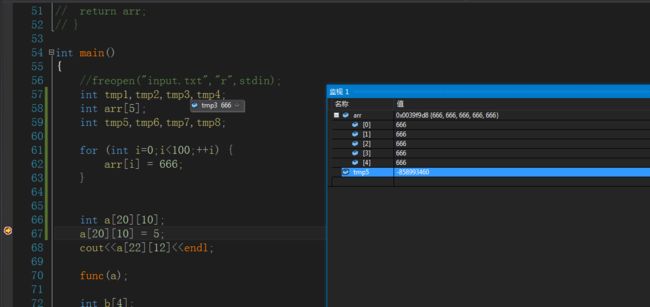
还真写进去了(可能会崩溃),也就是说,数组底层跟指针是类似的,可以任意访问非法空间。
一百三十三、一个程序一直进不了main函数,可能原因是什么?
main函数不一定是第一个运行的函数,比如全局类的构造函数。
一百三十四、c++中可以打印当前函数地址吗?
一百三十五、vs中条件断点+内存断点
一百三十六、什么是线程安全
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
1.局部变量局部使用是安全的
为什么?因为每个thread 都有自己的运行堆栈,而局部变量是生存在堆栈中,大家不干扰。
所以代码1
int local1;
++local1;
是安全的
2.全局原生变量多线程读写是不安全的
全局变量是在堆(heap)中
long global1 = 0;
++global2;
++这个操作其实分为两部,一个是读,另外一个是写
mov ecx,global
add ecx,1
mov global,ecx
所以代码3处是不安全的
3.函数静态变量多线程读写也是不安全的
道理同2
所以代码2处也是不安全的
4.volatile能保证全局整形变量是多线程安全的么
不能。
volatile仅仅是告诫compiler不要对这个变量作优化,每次都要从memory取数值,而不是从register
所以代码4也不是安全
5.InterlockedIncrement保证整型变量自增的原子性
所以代码5是安全的
6.function static object的初始化是多线程安全的么
不是。
著名的Meyer Singleton其实不是线程安全的
Object & getInstance()
{
static Object o;
return o;
}
可能会造成多次初始化对象
所以代码6处是不安全的
7.在32机器上,4字节整形一次assign是原子的
比如
i =10; //thread1
i=4; //thread2
不会导致i的值处于未知状态,要么是10要么是4
写好多线程安全的法宝就是封装,使数据有保护的被访问到
安全性:
局部变量>成员变量>全局变
一百三十七、RTTI
一百三十八、java循环左移、右移
此题在编程之美中用到,截图留念:

byte a=112,用程序实现,将其循环左移三位和右移三位。
112的二进制原码:0111 0000
112循环左移3位后的二进制码:1000 0011
112循环右移3位后的二进制码:0000 1110
先将循环左移的程序代码告诉大家:
public class TestCircle{
public static void main(String args[]){
byte x=112;
System.out.println((byte)(x<<3|x>>5));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
程序的输出结果是-125,它的原码为1111 1101,补码为1000 0011(正好是112循环左移三位后的数字)
再看循环右移的程序代码:
public class TestCircle{
public static void main(String args[]){
byte x=112;
System.out.println((byte)(x>>3|x<<5));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
程序的输出结果是14,他的原码、补码相同都是0000 1110(正好是112循环右移三位后的数字)
总结:对于一个数据类型长度为L的数据n,对其进行循环左移m位(或右移m位),只需将数据n左移(或右移)m位的结果和数据n右移(或左移)L-m位的结果进行或运算,再将或运算的结果强制转换为原类型即可。
一百三十九、printf(“abc”+1);
答案是输出”bc”,可能是一个字符数组收地址,后面加的数字代表移动的位数
一百四十. 遍历删除stl迭代器引发的错误
(1)对于节点式容器(map, list, set)元素的删除,插入操作会导致指向该元素的迭代器失效,其他元素迭代器不受影响;
(2)对于顺序式容器(vector,string,deque)元素的删除、插入操作会导致指向该元素以及后面的元素的迭代器失效。
http://ivan4126.blog.163.com/blog/static/209491092201351441333357/
正确删除法一:
(1)当删除特定值的元素时,删除元素前保存当前被删除元素的下一个元素的迭代器。
map<string,int >::iterator nextIt=countMap.begin();
for(map<string,int>::iterator it=countMap.begin(); ; ){
if(nextIt!=countMap.end())
++nextIt;
else break;
if(it->second==2){
countMap.erase(it);
}
it=nextIt;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(2)如何更加简洁的实现该方法呢?下面给出该方法的《Effective STL》一书的具体实现:
for(auto iter1 = theMap.begin(); iter1 != theMap.end(); )
{
if(iter1->second == xxx)
{
theMap.erase(iter1++); //#1
}else
{
++iter1;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(3)也可以实现如下,利用函数返回值(返回下一个iterator)
for(map<string,int>::iterator it=countMap.begin();it!=countMap.end();){
if(it->second==2){
it=countMap.erase(it);
}else
++it;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
正确删除法二:
使用 remove_copy_if 实现
当删除满足某些条件的元素,可以使用remove_copy_if & swap方法。当然,方法一的满足特性值是满足某些条件的特例,因此,也可以应用此方法。
那么如何通过remove_copy_if 删除 map< string,int>中的元素呢?网上很少有给出map的实现,一般都是以vector为例。所以这里给出我的实现。
在通过remove_copy_if 按照条件拷贝了需要的元素之后,如何实现两个map的交换,可以直接调用map的成员函数swap。参考代码:
#include
using namespace std;
map<string,int> mapCount;
//不拷贝的条件
bool notCopy(pair<string,int> key_value){
return key_value.second==1;
}
int main(){
mapCount.insert(make_pair("000",0));
mapCount.insert(make_pair("001",1));
mapCount.insert(make_pair("002",2));
mapCount.insert(make_pair("003",1));
map<string,int> mapCountTemp;//临时map容器
//之所以要用inserter()函数是因为通过调用insert()成员函数来插入元素,并由用户指定插入位置
remove_copy_if(mapCount.begin(),mapCount.end(),inserter(mapCountTemp,mapCountTemp.begin()),notCopy);
mapCount.swap(mapCountTemp);//实现两个容器的交换
cout<//输出2
cout<//输出4
//验证
//正确输出:
//000 0
//002 2
for(map<string,int>::iterator it=mapCount.begin();it!=mapCount.end();++it){
cout<first<<" "<second<
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
这种方法的缺点:虽然实现两个map的交换的时间复杂度是常量级,一般情况下,拷贝带来的时间开销会大于删除指定元素的时间开销,并且临时map容器也增加了空间的开销。
总结:
关于容器的删除,有篇blog总结的很好,现在转贴如下:
删除容器中具有特定值的元素:
(1)如果容器是vector、string或者deque,使用erase-remove的惯用法。如果容器是list,使用list::remove。如果容器是标准关联容器,使用它的erase成员函数。
删除容器中满足某些条件的元素:
(2)如果容器是vector、string或者deque,使用erase-remove_if的惯用法。如果容器是list,使用list::remove_if。如果容器是标准关联容器,使用remove_copy_if & swap 组合算法,或者自己协议个遍历删除算法。
参考资料:李健《编写高质量C++代码》第七章,用好STL这个大轮子。
一百四十一、auto关键字
一百四十二、程序中分配的地址都是逻辑地址,那有没有办法用一个指针指向一个物理地址呢?
一百四十三、inline函数必须在头文件中定义吗?
所谓内联函数,就是编译器将函数定义({…}之间的内容)在函数调用处展开,藉此来免去函数调用的开销。
如果这个函数定义在头文件中,所有include该头文件的编译单元都可以正确找到函数定义。然而,如果内联函数fun()定义在某个编译单元A中,那么其他编译单元中调用fun()的地方将无法解析该符号,因为在编译单元A生成目标文件A.obj后,内联函数fun()已经被替换掉,A.obj中不再有fun这个符号,链接器自然无法解析。
所以,如果一个inline函数会在多个源文件中被用到,那么必须把它定义在头文件中。在C++中,这意味着如果inline函数具有public或者protected访问属性,你就应该这么做。
一百四十四、vector.clear() 函数
因为对于 vector.clear() 并不真正释放内存(这是为优化效率所做的事),clear实际所做的是为vector中所保存的所有对象调用析构函数(如果有的话),然后初始化size这些东西,让你觉得把所有的对象清除了。。。
真正释放内存是在vector的析构函数里进行的,所以一旦超出vector的作用域(如函数返回),首先它所保存的所有对象会被析构,然后会调用allocator中的deallocate函数回收对象本身的内存。。。
所以你clear后还能访问到对象数据(因为它根本没清除),至于上面这位仁兄所指出的也有道理,在一些比较新的C++编译器上(例如VS2008),当进行数组引用时(例如a[2]这种用法),STL库中会有一些check函数根据当前容器的size值来判断下标引用是否超出范围,如果超出,则会执行这样一句:
_THROW(out_of_range, “invalid vector subscript”);
即抛出一个越界异常,你clear后没有捕获异常,程序在新编译器编译后就会崩溃掉。。。。
一百四十五、变参函数
一百四十六、能否实现:函数指针作为参数,但传递过去的函数不一样
因为在写项目的时候,完成了很多诸如,void recurs_GetId(logic_TreeNode *some,std::vector 的函数,但是不具有一般性。现在希望完成一个函数,void recurs_DoSth(); 可以传递进一个简单操作的函数,就可以完成任务?
一百四十七、宏函数可以有返回值吗?
以下代码在vs下无法编译,未在gcc平台编译:
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
输出结果:7,10
上面的这段代码定义了一个名叫KADDR的宏,它可以跟据输入的addr数据,对其进行不同的偏移,但是最巧妙的是,这样子写可以有把这个值返回到调用该宏的语句中。
一百四十八、net 命令
一百四十九、在程序中能够使用指针获取内存的绝对物理地址吗
一百五十、默认参数是否只能在声明处写
默认参数,在C++中,只要是函数都可以有默认参数,默认参数是写在函数声明里面的。
如:
void swap(int a = 10, int b= 20);//声明
//实现
void swap(int a, int b) {
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
一百五十一、构造函数会为对象分配空间吗?
不会,构造函数是在已经分配好的空间上初始化对象成员。分配空间是在new的时候运行时分配的。
一百五十二、重载 new 时,需要实现函数的构造函数吗?
这条跟 91 条有重合,重载new 会调用两次构造函数
(1)重载的成员函数 new 里面只能::new其他的类型,不能new这个类本身。
(2)如果需要创建这个类本身的话,应该要用malloc, malloc在分配完内存后,并不会初始化。
可能跟 placement new 有关。
一百五十三、placement new
一百五十四、debug 和 release 的区别,为什么有时 debug 可以跑,但是 release 下崩溃?
一百五十五、VC编译选项 /ML /MLd /MT /MTd /MD /MDd之间的区别
一百五十六、内存断点 && 条件断点
一百五十七、c++重载运算符
一百五十八、A* 算法
一百五十九、c++流
一百六十、maze && 八皇后 — 回溯 && 深搜 && 广搜
http://blog.csdn.net/K346K346/article/details/51289478
一百六十一、函数指针作为参数,可以接收签名完全不同(参数个数、类型都不定)的函数地址吗?
一百六十二、参数个数不定的函数(类似 printf)
http://www.cnblogs.com/VRS_technology/archive/2010/05/10/1732006.html
一百六十三、类成员变量定义为引用,注意事项
http://blog.csdn.net/aore2010/article/details/5870928
一百六十四、multimap 允许 key 相同
适用于多对一关系
一百六十五、Qt 资源
http://download.qt.io/
一百六十六、实时传输协议 RTP
一百六十七、c++ 复合数据类型
一百六十八、c++ 如何实现一个无法被继承的类
一百六十九、二叉排序树 BST
一百七十、KMP
一百七十一、TCP的流量控制和拥塞控制
一百七十二、TSP 旅行商问题(dp + 递归)
一百七十三、如何使经过指定节点集的路径最短
一百七十四、c++中的函数重载、隐藏、覆盖、重写的区别
一百七十五、卡特兰数
一百七十六、电子邮件协议以及工作原理
一百七十七、注册表详解
一百七十八、setjmp longjmp
一百七十九、千万不要重载 || &&
一百八十、c++对象模型 && 内存布局
一百八十一、守护进程
一百八十二、虚调用
一百八十三、c++为什么不加入垃圾回收?
一百八十四、main 函数参数中字符数组指向的空间在哪
https://www.quora.com/In-C-the-main-function-takes-a-pointer-to-an-integer-and-a-pointer-to-a-pointer-to-a-char-To-where-does-the-latter-point
一百八十五、进程 vs. 线程
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000
一百八十六、HTTP 400/401/403/404/500 网页错误代码
http://blog.csdn.net/stuartjing/article/details/7579427
一百八十七、环境变量
一百八十八、include 命令包含头文件时,会不会包含头文件过多,生成空间过大
一百八十九、nginx
一百九十、4K对齐
一百九十一、C++中POD类型
一百九十二、预编译指令 #pragma
一百九十三、赋值语句返回值
http://blog.csdn.net/jackbai1990/article/details/7467030
赋值语句的返回值是所赋的值,于是在C/C++中,就可以有如下的连续赋值语句:
b = a = 10;
- 1
- 1
一百九十四、SYN Flood攻击
一百九十五、Java学习计划(不断给更新)
一百九十六、Java反射机制
什么是反射
一般在开发针对java语言相关的开发工具和框架时使用,比如根据某个类的函数名字,然后执行函数,实现类的动态调用!
反射实例:
package test;
import java.lang.reflect.*;
/**
* 基类Animal
*/
class Animal {
public Animal() {
}
public int location;
protected int age;
private int height;
int length;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
private int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
}
/**
* 子类 —— Dog
*/
class Dog extends Animal {
public Dog() {
}
public String color;
protected String name;
private String type;
String fur;
}
public class test {
public static void main(String[] args) {
System.out.println("Hello World!");
testRefect();
}
private static void testRefect() {
try {
//返回类中的任何可见性的属性(不包括基类)
System.out.println("Declared fileds: ");
Field[] fields = Dog.class.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
System.out.println(fields[i].getName());
}
//获得类中指定的public属性(包括基类)
System.out.println("public fields: ");
fields = Dog.class.getFields();
for (int i = 0; i < fields.length; i++) {
System.out.println(fields[i].getName());
}
//getMethod()只能调用共有方法,不能反射调用私有方法
Dog dog = new Dog();
dog.setAge(1);
Method method1 = dog.getClass().getMethod("getAge", null);
Object value = method1.invoke(dog);
System.out.println("age: " + value);
//调用基类的private类型方法
/**先实例化一个Animal的对象 */
Animal animal = new Animal();
Class a = animal.getClass();
//Animal中getHeight方法是私有方法,只能使用getDeclaredMethod
Method method2 = a.getDeclaredMethod("getHeight", null);
method2.setAccessible(true);
//java反射无法传入基本类型变量,可以通过如下形式
int param = 12;
Class[] argsClass = new Class[] { int.class };
//Animal中getHeight方法是共有方法,可以使用getMethod
Method method3 = a.getMethod("setHeight", argsClass);
method3.invoke(animal, param);
//Animal中height变量如果声明为static变量,这样在重新实例化一个Animal对象后调用getHeight(),还可以读到height的值
int height = (Integer) method2.invoke(animal);
System.out.println("height: " + height);
/**不用先实例化一个Animal,直接通过反射来获得animal的class对象*/
Class anotherAnimal = Class.forName("test.Animal");
//Animal中getHeight方法是私有方法,只能使用getDeclaredMethod
Method method4 = anotherAnimal.getDeclaredMethod("getHeight", null);
method4.setAccessible(true);
//java反射无法传入基本类型变量,可以通过如下形式
int param2 = 15;
Class[] argsClass2 = new Class[] { int.class };
//Animal中setHeight方法是共有方法,可以使用getMethod
Method method5 = anotherAnimal.getMethod("setHeight", argsClass2);
method5.invoke(anotherAnimal.newInstance(), param2);
//Animal中height变量必须声明为static变量,这样在重新实例化一个Animal对象后调用getHeight()才能读到height的值
// 否则重新实例化一个新的Animal对象,读到的值为初始值
int height2 = (Integer) method4.invoke(anotherAnimal.newInstance());
System.out.println("height:" + height2);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
详见:http://blog.csdn.net/scythe666/article/details/51704809
一百九十七、C++反射机制
C++原生不支持反射机制,但是可以手动实现:
#include
#include int main(int argc,char* argv[]){
TestClass* ptrObj=(TestClass*)ClassFactory::getInstance().getClassByName("TestClass");
ptrObj->m_print();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
详见:http://blog.csdn.net/scythe666/article/details/51718864
一百九十八、JVM内存模型
JVM内存模型分区见下图:
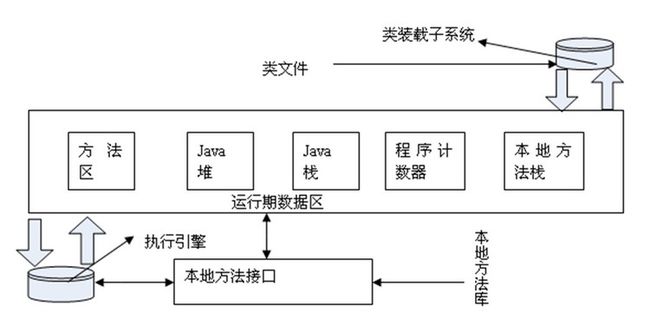
(1)方法区:用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。对于习惯在HotSpot 虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价。
(2)堆区:Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。由于逃逸分析等分析或优化技术,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”
(3)栈区:与程序计数器一样,Java 虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。栈中主要存放一些基本类型的变量(,int, short, long, byte, float,double, boolean, char)和对象句柄。
(4)程序计数器:程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。
由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
(5)本地方法栈:本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native 方法服务。
详见:http://blog.csdn.net/scythe666/article/details/51700142
一百久十久、阻塞VS非阻塞,同步VS异步
同步异步是针对整个IO的过程,阻塞非阻塞是针对单次操作
用很贴切的比喻来说明同步异步:
回调的比喻:A委托B做事,但是B现在忙,于是A告诉B如何去做,A就回去了,B做完手头事情后把A的事情做完了
通知的比喻:水壶烧水,如果一直看着水壶,是否冒烟,就是同步
如果烧好水壶响了才去管就是异步。
同步异步是一种动作,阻塞和非阻塞是一种状态
1、同步和异步是针对应用程序和内核的交互而言的。
(1)同步:用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪;
(2)异步:用户进程触发IO操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知(异步的特点就是通知)。
2、阻塞和非阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式
(1)阻塞方式下读取或者写入函数将一直等待
(2)非阻塞方式下,读取或者写入函数会立即返回一个状态值。
一般来说I/O模型可以分为:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞IO
(1)同步阻塞IO:
在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,用户进程才能运行。JAVA传统的IO模型属于此种方式!
(2)同步非阻塞IO:
在此种方式下,用户进程发起一个IO操作以后边可返回做其它事情,但是用户进程需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。其中目前JAVA的NIO就属于同步非阻塞IO。
(3)异步阻塞IO:
此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select属于同步操作。因为select之后,进程还需要读写数据),从而提高系统的并发性!
(4)异步非阻塞IO:
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。目前Java中还没有支持此种IO模型。
(其实阻塞与非阻塞都可以理解为同步范畴下才有的概念,对于异步,就不会再去分阻塞非阻塞。对于用户进程,接到异步通知后,就直接操作进程用户态空间里的数据好了。)
详见:http://blog.csdn.net/scythe666/article/details/51701360
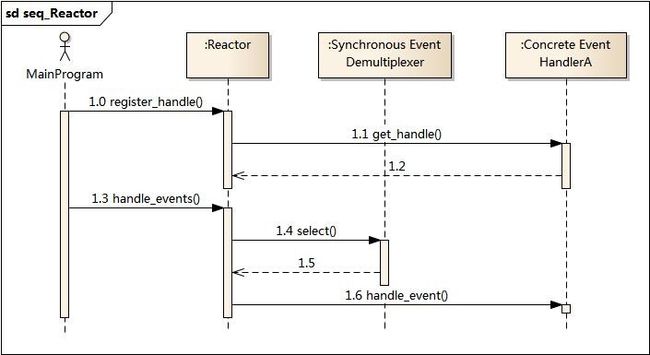
二百、高性能IO设计的Reactor和Proactor模式
首先来看看Reactor模式,Reactor模式应用于同步I/O的场景。我们分别以读操作和写操作为例来看看Reactor中的具体步骤:
读取操作:
1. 应用程序注册读就绪事件和相关联的事件处理器
2. 事件分离器等待事件的发生
3. 当发生读就绪事件的时候,事件分离器调用第一步注册的事件处理器
4. 事件处理器首先执行实际的读取操作,然后根据读取到的内容进行进一步的处理
写入操作类似于读取操作,只不过第一步注册的是写就绪事件。
下面我们来看看Proactor模式中读取操作和写入操作的过程:
读取操作:
1. 应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
2. 事件分离器等待读取操作完成事件
3. 在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作(异步IO都是操作系统负责将数据读写到应用传递进来的缓冲区供应用程序操作,操作系统扮演了重要角色),并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
4. 事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
Proactor中写入操作和读取操作,只不过感兴趣的事件是写入完成事件。
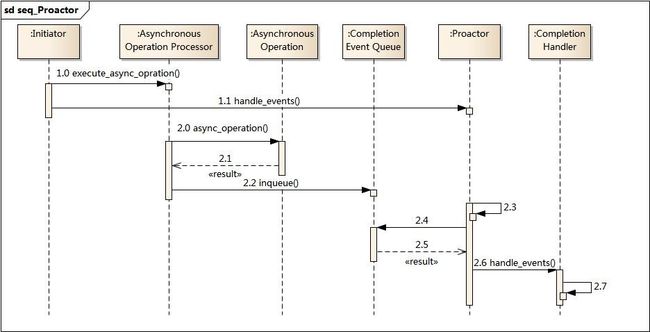
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备.
综上所述,同步和异步是相对于应用和内核的交互方式而言的,同步 需要主动去询问,而异步的时候内核在IO事件发生的时候通知应用程序,而阻塞和非阻塞仅仅是系统在调用系统调用的时候函数的实现方式而已。
详见:https://segmentfault.com/a/1190000002715832
二百零一、秒懂乐观锁和悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
原文:http://blog.csdn.net/hongchangfirst/article/details/26004335
二百零二、序列化和反序列化
1、什么是序列化
序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。之后可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
也可以理解为:将对象转换为容易传输的格式的过程。例如,可以序列化一个对象,然后使用 HTTP 通过 Internet 在客户端和服务器之间传输该对象。在另一端,反序列化将从该流重新构造对象。
2、Java序列化的实现
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流
3、什么时候使用序列化
(1)对象序列化可以实现分布式对象。主要应用例如:RMI要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
(2)java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的”深复制”,即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
二百零三、关于RPC
首先了解什么叫RPC,为什么要RPC,RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
详见:http://blog.csdn.net/scythe666/article/details/51719408
二百零四、非阻塞同步算法与CAS(Compare and Swap)无锁算法
要实现无锁(lock-free)的非阻塞算法有多种实现方法,其中CAS(比较与交换,Compare and swap)是一种有名的无锁算法。CAS, CPU指令,在大多数处理器架构,包括IA32、Space中采用的都是CAS指令,CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。CAS无锁算法的C实现如下:
int compare_and_swap (int* reg, int oldval, int newval)
{
ATOMIC();
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return old_reg_val;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
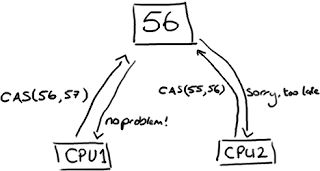
(上图的解释:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。)
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
详见:http://www.cnblogs.com/Mainz/p/3546347.html?utm_source=tuicool&utm_medium=referral
二百零五、spring框架学习
基本学习Java,spring是必学的,这个框架是Java集大成者,活用各种Java特性和设计模式,实在是牛逼的不行,如果可以的话最好读源码。
详见:http://blog.csdn.net/scythe666/article/details/51706041
二百零六、static块的本质
Java静态变量的初始化
详见:http://blog.csdn.net/darxin/article/details/5293427
二百零七、Java的override注解写与不写
/*
Java 中的覆盖@Override注解 写与不写的一点点理解
一般来说,写与不写没什么区别,JVM可以自识别
写的情况下:即说明子类要覆盖基类的方法,基类必须存在方法
(控制类型public,protected,返回值,参数列表类型)与子类方法完成一致的方法,否则会报错(找不到被Override的方法)。
在不写@Override注解的情况下,当基类存在与子类各种条件都符合的方法是即实现覆盖;
如果条件不符合时,则是当成新定义的方法使用。
所以如果想覆盖基类方法时,最好还是写上@Override注解,这样有利于编译器帮助检查错误
*/
public class OverrideTest extends Test{
@Override//此处写与不写都能覆盖基类的t(String)方法
public void t(String s){
System.out.println("OverrideTest.t(String):" + s);
}
//此处不能写@Override注解,因为方法参数类型与基类的t2方法的参数类型不同
//所以此处只能新定义了一个t2(float)方法,并不能实现覆盖
public void t2(float f){
System.out.println("OverrideTest.t2(float):" + f);
}
public static void main(String[] args){
OverrideTest ot = new OverrideTest();
ot.t("china34420");
ot.t2(1.0f);
ot.t2(1);
ot.t3();
}
}
/*输出:
OverrideTest.t(String):china34420
OverrideTest.t2(float):1.0
Test.t2(int):1
OverrideTest.t(String):override
*/
class Test{
public void t(String s){
System.out.println("Test.t(String):" + s);
}
public void t2(int i){
System.out.println("Test.t2(int):" + i);
}
public void t3(){
t("override");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
二百零八、进程VS端口
一个进程可以监听多个端口
nginx可以配置多个server,每个server监听不同的端口.
PHP-fpm可以配置多个pool,每个pool监听不同的端口.
httpd可以用Listen监听多个端口(Listen监听了这些端口,VirtualHost里才能使用这些端口)
二百零九、有用过Linux中的epoll吗?它的作用是什么?
答:
epoll是linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
二百一十、epoll和select的区别在哪,或者说优势在哪?
答:
(1)epoll除了提供select/poll那种IO事件的水平触发(Level Triggered)外,还提供了边缘触发(Edge Triggered);
(2)select的句柄数目受限,在linux/posix_types.h头文件有这样的声明:#define __FD_SETSIZE 1024,表示select最多同时监听1024个fd。而epoll没有,epoll的最大并发的连接数的理论值无上限,但由于实际内存资源有限,实际并发的连接数受到资源的限制和最大的打开文件句柄数目的限制;
(3)epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构类似一个数组的数据结构,而epoll 是维护一个队列,直接看队列是不是空就可以了。
(4)使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
此外,epoll创建时传入的参数是什么?
epoll对象可通过int epoll_create(int size)来创建一个epoll的实例,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值。所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。但是自从linux2.6.8之后,size参数是被忽略的。
此外,创建epoll实例,还可以通过int epoll_create1(int flags)。
这个函数是在linux 2.6.27中加入的,其实它和epoll_create差不多,不同的是epoll_create1函数的参数是flags,当flag是0时,表示和epoll_create函数完全一样,不需要size的提示了。
当flag = EPOLL_CLOEXEC,创建的epfd会设置FD_CLOEXEC;
当flag = EPOLL_NONBLOCK,创建的epfd会设置为非阻塞。
一般用法都是使用EPOLL_CLOEXEC。关于EPOLL_CLOEXEC,网上资料说明是对epfd的一个标识说明,用来设置文件close-on-exec状态的。当close-on-exec状态为0时,调用exec时,fd不会被关闭;状态非零时则会被关闭,这样做可以防止fd泄露给执行exec后的进程。关于exec的用法,大家可以去自己查阅下,或者直接man exec。
二百一十二、写出一个程序,让CPU成正弦曲线
http://www.cnblogs.com/matrix-r/p/3246838.html
二百一十三、什么是编程语言的自举?
就是自己的编译器可以自行编译自己的编译器。
实现方法就是这个编译器的作者用这个语言的一些特性来编写编译器并在该编译器中支持这些自己使用到的特性。
首先,第一个编译器肯定是用别的语言写的(不论是C还是Go还是Lisp还是Python),后面的版本才能谈及自举。
至于先有鸡还是先有蛋,我可以举个这样的不太恰当的例子:比如我写了一个可以自举的C编译器叫作mycc,不论是编译器本身的执行效率还是生成的代码的质量都远远好于gcc(本故事纯属虚构),但我用的都是标准的C写的,那么我可以就直接用gcc编译mycc的源码,得到一份可以生成高质量代码但本身执行效率低下的mycc,然后当然如果我再用这个生成的mycc编译mycc的源码得到新的一份mycc,新的这份不光会产生和原来那份同等高质量的代码,而且还能拥有比先前版本更高的执行效率(因为前一份是gcc的编译产物,后一份是mycc的编译产物,而mycc生成的代码质量要远好于gcc的)。故事虽然是虚构的,但是道理差不多就是这么个道理。这也就是为什么如果从源码编译安装新版本的gcc的话,往往会“编译——安装”两到三遍的原因。
二百一十四、内存为什么要分页
假设内存是连续分配的(也就是程序在物理内存上是连续的)
1.进程A进来,向os申请了200的内存空间,于是os把0~199分配给A
2.进程B进来,向os申请了5的内存空间,os把200~204分配给它
3.进程C进来,向os申请了100的内存空间,os把205~304分配给它
4.这个时候进程B运行完了,把200~204还给os
但是很长时间以后,只要系统中的出现的进程的大小>5的话,200~204这段空间都不会被分配出去(只要A和C不退出)。
过了一段更长的时间,内存中就会出现许许多多200~204这样不能被利用的碎片……
而分页机制让程序可以在逻辑上连续、物理上离散。也就是说在一段连续的物理内存上,可能0~4(这个值取决于页面的大小)属于A,而5~9属于B,10~14属于C,从而保证任何一个“内存片段”都可以被分配出去。
二百一十五、高级语言为什么不直接编译成机器码,而编译成汇编代码
1.一般的编译器,是先将高级语言转换成汇编语言(中间代码),然后在汇编的基础上优化生成OBJ目标代码,最后Link成可执行文件。
2.Que:高级语言为什么不直接编译成机器码,而编译成汇编代码?
ACK:1)其中有一个好处是方便优化,因为,编译器也是工具,也是机器,毕竟是机器生成的程序,不可以非常 完美的,而汇编是机器指令的助记符,一个汇编指令就对应一条机器指令(特殊指令除外)调试起来肯定会比 机器指令方便的方便,这样优化起来也方便。
2)高级语言只需要编译成汇编代码就可以了,汇编代码到机器码的转换是由硬件实现即可,有必要用软件实 现这样分层可以有效地减弱编译器编写的复杂性,提高了效率.就像网络通讯的实现需要分成很多层一样,主要 目的就是为了从人脑可分析的粒度来减弱复杂性.
3)如果把高级语言的源代码直接编译成机器码的话,那要做高级语言到机器码之间的映射,如果这样做的 话,每个写编译器的都必须熟练机器码。这个不是在做重复劳动么。
二百一十六、全双工 VS 半双工
全双工(Full Duplex)是指在发送数据的同时也能够接收数据,两者同步进行,这好像我们平时打电话一样,说话的同时也能够听到对方的声音。目前的网卡一般都支持全双工。
半双工(Half Duplex),所谓半双工就是指一个时间段内只有一个动作发生,举个简单例子,一条窄窄的马路,同时只能有一辆车通过,当目前有两量车对开,这种情况下就只能一辆先过,等到头儿后另一辆再开,这个例子就形象的说明了半双工的原理。早期的对讲机、以及早期集线器等设备都是基于半双工的产品。随着技术的不断进步,半双工会逐渐退出历史舞台.
单工通信是指通信线路上的数据按单一方向传送
TCP/UDP都是全双工的
二百一十七、MSS
在有些书中,将它看作可“协商”选项。它并不是任何条件下都可协商。当建立一个连
接时,每一方都有用于通告它期望接收的MSS选项(MSS选项只能出现在SYN报文段中)。如果一方不接收来自另一方的MSS值,则MSS就定为默认值536字节(这个默认值允许20字节的IP首部和20字节的TCP首部以适合576字节IP数据报)。
一般说来,如果没有分段发生,MSS还是越大越好(这也并不总是正确,参见图24-3和
图24-4中的例子)。报文段越大允许每个报文段传送的数据就越多,相对IP和TCP首部有更高的网络利用率。当TCP发送一个SYN时,或者是因为一个本地应用进程想发起一个连接,或
者是因为另一端的主机收到了一个连接请求,它能将MSS值设置为外出接口上的MTU长度减
去固定的IP首部和TCP首部长度。对于一个以太网,MSS值可达1460字节。使用IEEE802.3的
封装(参见2.2节),它的MSS可达1452字节。

二百一十八、Linux配色修改
http://blog.csdn.net/hexinzheng19780209/article/details/45539431
https://www.zhihu.com/question/20110072
二百一十九、网络传输包大小是否固定问题
IP、TCP、UDP报头详见:http://blog.csdn.net/Scythe666/article/details/51909186
TCP/IP协议定义了一个在因特网上传输的包,称为IP数据包,而IP数据报(IP Datagram)是个比较抽象的内容,是对数据包的结构进行分析。 由首部和数据两部分组成,其格式如图所示。首部的前一部分是固定长度,共20字节,是所有IP数据报必须具有的。在首部的固定部分的后面是一些可选字段,其长度是可变的。首部中的源地址和目的地址都是IP协议地址。
总长度指首部和数据之和的长度,单位为字节。总长度字段为16位,因此数据报的最大长度为2^16-1=65535字节。
在IP层下面的每一种数据链路层都有自己的帧格式,其中包括帧格式中的数据字段的最大长度,这称为最大传送单元MTU(Maximum Transfer Unit)。当一个数据报封装成链路层的帧时,此数据报的总长度(即首部加上数据部分)不能超过下面的数据链路层的MTU值。
深入浅出好文:http://www.cnblogs.com/maowang1991/archive/2013/04/15/3022955.html
二百二十、以太网 VS 令牌环网
以太网是这样通信的,每台电脑位于同一个主干中都可以向主干线路中发信息串。假如a吧,它先监听主干线路上有没有人在发信息,如果有它就等一会儿,在它发现没有人发言后它将发言,但这时有可能另一台电脑也和它同时发言(想象一下在课堂上两个学生向老师同时提问),这样它们会同时停止发言,并在等待了一个随机时间后继续发言,当然它们的随机时间是不同的,并且在再次发言前仍需监听主干上是否有其它主机在发言。其它的电脑读取数据包,检查mac地址和ip地址乃至端口号看是不是发给自已的,如果不是便丢弃。它的mac 算法是csma/cd算法
令牌环网的结构是组成一个环形,环形的一圈是主机,主机中存在一个令牌,由一号机向下传,每个主机只有在自已有令牌时才能向主线路中发数据。
二百二十一、MSS与MTU的关系(TCP分段和IP分割和重组报文)
MSS 指的是 TCP payload 的长度,MSS让主机限制另一端发送数据报的长度。加上主机也能控制它发送数据报的长度,这将使以较小 MTU连接到一个网络上的主机避免分段。
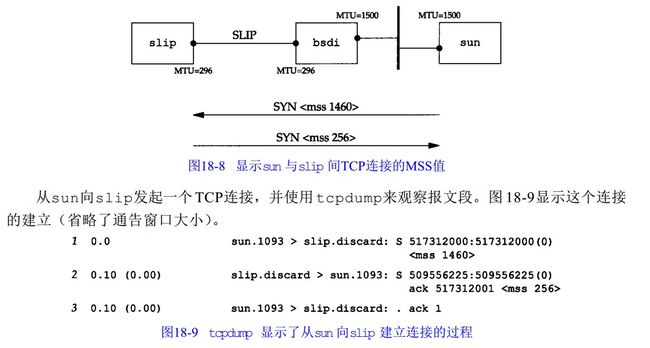
为什么 L3 有 MTU 后 L4 还要 MSS 呢?
MTU 和 MSS 的功能其实基本一致, 都可以根据对应的包大小进行分片, 但实现的效果却不太一样.
L3 (IP) 提供的是一个不可靠的传输方式, 如果任何一个包在传输的过程中丢失了, L3 是无法发现的, 需要靠上层应用来保证. 就是说如果一个大 IP 包分片后传输, 丢了任何一个部分都无法组合出完整的 IP 包, 即是上层应用发现了传输失败, 也无法做到仅重传丢失的分片, 只能把 IP 包整个重传. 那 IP 包越大的话重传的代价也就越高.
L4 (TCP) 提供的是一个可靠的传输方式, 与 L3 不同的是, TCP 自身实现了重传机制, 丢了任何一片数据报都能单独重传, 所以 TCP 为了高效传输, 是需要极力避免被 L3 分片的, 所以就有了 MSS 标志, 并且 MSS 的值就是根据 MTU 计算得出, 既避免了 L3 上的分片, 又保证的最大的传输效率.
http://networkengineering.stackexchange.com/questions/8288/difference-between-mss-and-mtu
http://blog.apnic.net/2014/12/15/ip-mtu-and-tcp-mss-missmatch-an-evil-for-network-performance/
二百二十二、都说路由器可以设置MTU,为什么是第三层设备设置呢
最大传输单元,即物理接口(数据链路层)提供给其上层(通常是IP层)最大一次传输数据的大小
二百二十三、不是说TCP报头没有长度限制吗,MSS又是什么
详见两篇超好的知乎文章,车小胖:https://zhuanlan.zhihu.com/p/21268782
https://www.zhihu.com/question/48454744
二百二十四、TCP/IP 协议栈为什么有粘包问题,如何解决
如何解决
(1)加入分隔符字段,自己定义结束标志
(2)加入payload长度字段(注意是加入一个字段),比如http应用层协议就是这样做的
二百二十五、网络传输的时候有大小端的问题,如何解决
二百二十六、为什么TCP要三次握手

二百二十七、TCP四次挥手,为什么要等待2MSL
什么是MSL


二百二十八、TCP有限状态机

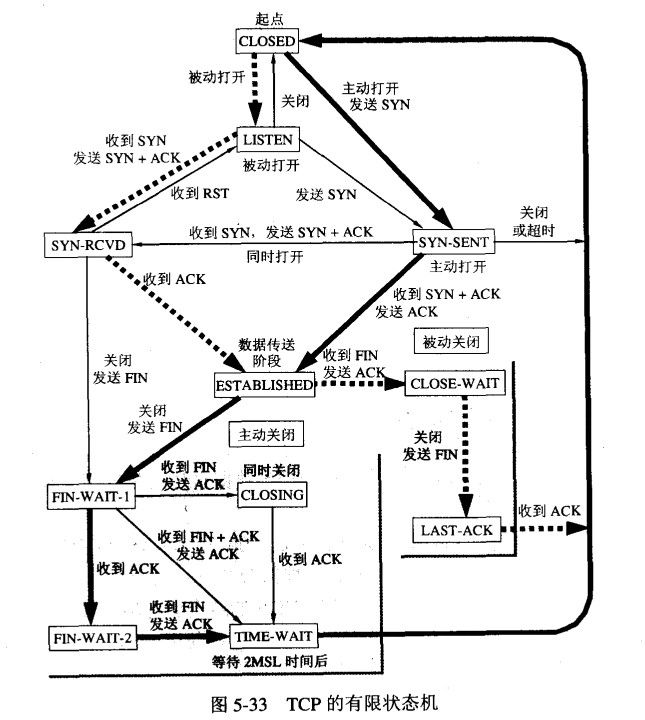
三次握手、四次挥手中发起端(左边)是粗实线状态
右边是粗虚线状态
二百二十九、装饰器模式与代理的区别
实现手段差不多,但是目的有微妙的差别
装饰器模式:基于原有功能的加强,主要是功能的差别,而且功能只能加强,例子Java IO流
代理:由另一个类去执行,主要是执行者的差别,当然功能可以加强可以减弱
二百三十、Linux系统uid
用户的UID大于500的都是非系统账号,500以下的都为系统保留的账号,比如root账号,至高权限的账号的UID为0,我们创建用户的时候默认的账号的UID都是大于500,如果你要指定账号的UID可以使用-u这个参数来指定。其它没什么大的意义。
二百三十一、什么是驱动
驱动程序虽然在你打开电脑进入系统之后就不断地在为你服务了,但是它不像电脑硬件那样触手可及,也不像操作系统那样一目了然,更不像游戏或者多媒体应用那样引人注目,它只是默默无闻的在后台做着自己该做的事情,因此总是被很多朋友忽略。
那么驱动是什么呢?驱动的英文就是Driver,简单的说来驱动程序就是用来向操作系统提供一个访问、使用硬件设备的接口,实现操作系统和系统中所有的硬件设备的之间的通信程序,它能告诉系统硬件设备所包含的功能,并且在软件系统要实现某个功能时,调动硬件并使硬件用最有效的方式来完成它。
说的形象一点,驱动程序就是软件与硬件之间的“传令兵”,这个环节可是大大的重要,一旦出现了问题,那么软件提出的要求就要无人响应,而硬件却空有一身力气但无从发挥,那种状况下朋友们会发现自己那本来性能强大且多姿多彩的电脑竟然如同一洼死水,什么都做不来了。因此有人说驱动是硬件的灵魂,可毫不为过。
二百三十二、CPU使用分时间片,会不会很浪费资源
时间片轮转调度中特别需要关注的是时间片的长度。从一个进程切换到另一个进程是需要一定时间的–保存和装入寄存器值及内存映像,更新各种表格和队列等。假如进程切换(process switch) - 有时称为上下文切换(context switch),需要5毫秒,再假设时间片设为20毫秒,则在做完20毫秒有用的工作之后,CPU将花费5毫秒来进行进程切换。CPU时间的20%被浪费在了管理开销上。
为了提高CPU效率,我们可以将时间片设为500毫秒。这时浪费的时间只有1%。但考虑在一个分时系统中,如果有十个交互用户几乎同时按下回车键,将发生什么情况?假设所有其他进程都用足它们的时间片的话,最后一个不幸的进程不得不等待5秒钟才获得运行机会。多数用户无法忍受一条简短命令要5秒钟才能做出响应。同样的问题在一台支持多道程序的个人计算机上也会发生。
结论可以归结如下:时间片设得太短会导致过多的进程切换,降低了CPU效率;而设得太长又可能引起对短的交互请求的响应变差。
二百三十三、主分区、扩展分区、逻辑分区
一个硬盘的主分区也就是包含操作系统启动所必需的文件和数据的硬盘分区,要在硬盘上安装操作系统,则该硬盘必须得有一个主分区。
扩展分区也就是除主分区外的分区,但它不能直接使用,必须再将它划分为若干个逻辑分区才行。逻辑分区也就是我们平常在操作系统中所看到的D、E、F等盘。
不管使用哪种分区软件,我们在给新硬盘上建立分区时都要遵循以下的顺序:建立主分区→建立扩展分区→建立逻辑分区→激活主分区→格式化所有分区。