表情识别论文《OAENet Oriented Attention Ensemble for Accurate FacialExpression Recognition》中文翻译
本篇博客为论文OAENet: Oriented Attention Ensemble for Accurate Facial Expression Recognition的中文翻译,如有翻译错误请见谅,同时希望您能为我提出改正建议,谢谢!
论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0031320320304970
表情识别论文《OAENet Oriented Attention Ensemble for Accurate FacialExpression Recognition》中文翻译
- 1. 简介
- 2. 近期研究
-
- 2.1 基于深度学习的FER
- 2.2 带注意力机制的CNN
- 3. 方法
-
- 3.1 网络架构
- 3.2 加权掩膜(Weighted Mask)
- 3.3 训练细节
- 4. 实验结果
-
- 4.1 数据集
- 4.2 比较
- 4.3 消融实验
-
- 4.3.1 区域测试
- 4.3.2 面部区域划分
- 4.3.3 加权掩膜评估
- 4.3.4 注意力+加权掩膜
- 5. 结论
摘要:人脸表情识别具有重要的学术意义和商业潜力,是一个具有挑战性的重要研究课题。在这项工作中,我们提出了一种面向注意力的伪孪生网络,它利用了全局和局部的面部信息来实现高精度的FER。我们的网络由两个分支组成,一个是由几个卷积块组成的维护分支,以利用高级语义特征,一个是具有类似unet架构的注意分支,以获取局部突出信息。具体来说,我们首先将人脸图像输入到维护分支;对于注意分支,我们计算了人脸与其子区域之间的相关系数。然后,我们将人脸标志和相关系数相关联来构造加权掩膜,并发送到注意分支。最后,融合两个分支输出分类结果。因此,我们建立了一个方向依赖的注意力机制来弥补局部信息利用不足的局限性。在我们的注意力机制的帮助下,我们的网络不仅可以抓取全局的图片信息,也可以集中关注于重要的局部区域。我们在4个领先的面部表情数据集上进行了实验,与其他最先进的方法相比,我们的方法取得了非常吸引人的性能。
1. 简介
从面部和身体的细节中理解未说出口的信息是人类的基本特征,这种能力在我们的日常交流和社会互动中至关重要。到目前为止,面部表情是最受欢迎的一种输入方式。Paul Ekman 的先驱作品之一[10]指出了6种情感(惊喜、快乐、悲伤、愤怒、恐惧和厌恶),它们在不同文化中是普遍存在的。本发明的面部动作编码系统(FACS)使面部表情分析更加方便。
为了促进面部表情识别技术的发展,研究人员进行了多年的努力,一些方法已经被提出来解决标签不一致问题[37],其中模型微调和多数据集交叉训练是两种流行的策略。然而,它们也有一些缺点。FER不同于一般的分类任务,如对猫、狗、人的识别,FER中各种表情之间的差异较小,而上述提到的方法可能会忽略这些差异,并且随着网络的深入,这些显著的特征可能会在训练过程中消失,导致特征退化的问题。
为了解决这一问题,我们重新思考了注意力机制对细粒度类别的影响。细粒度分类(如鸟类种类)的识别高度依赖于区分部分定位和基于部分细粒度的特征学习。此外,局部定位和细粒度特征学习是相互关联的,可以相互增强[11]。因此,将图像的局部位置信息与特征信息融合并相互促进,从而大大提高了识别的准确性。Fu等人[6]提出了一种新的循环注意卷积神经网络(RA-CNN),在多个尺度上递归学习区分区域注意和基于区域的特征表示,并相互加强。Wang等人[32]提出了一种残差注意网络,这是一种利用注意力机制的卷积神经网络,它结合了一般的CNN体系结构来提高分类精度。对于同一个人的不同表达之间的差异很小,导致类之间的距离很近,使得传统的度量方法难以区分这些类别。为了解决这一问题,Cai等人[3]提出了一种新的损失函数叫做隔离损失(island loss)。通过增加不同表达类别之间的类间距,隔离损失网络可以学习到更多的识别特征。
传统的表情识别算法更倾向于识别整个表情图像的全局特征。最近,一些算法[5]开始将人脸不同部分的区域斑块(如眼圈、鼻子、嘴巴区域)输入网络进行训练,目的是同时捕捉全局特征和局部特征。这些方法明显学习不到面部表情其他区域的特征,导致图像信息利用不足。而且,在决定表达方式时,人们更多地关注重要的方面,而较少关注其他方面,因此,完全放弃关键区域之外的局部信息是有问题的。另一方面,这些基于多区域的算法只是将单个子区域卷积得到的特征在最后的卷积层上进行拼接,导致面部表情图像的空间位置信息丢失。
Li等人[15]提出了带有注意力机制的CNN网络结构来解决FER中的遮挡问题。他们将注意力集中在关键点区域,脸部的其他部分则被忽略。Sun等人[30]也利用注意力机制提高了FER的准确性。然而,他们的关键点信息是用来对齐人脸姿态的,而不是用于局部注意信息提取的。Liu等人[18]提出了一种新的FER框架,身份脱离—面部表情识别机器(IDFERM),该框架将表情视为人的表情成分和中性成分的结合,生成的归一化面被用作度量学习的硬负样本,以提高FER性能,然而,这取决于自然面孔的生成质量。
本文中,我们研究了一种带有定向注意群的伪孪生(pseudo-siamese )网络来识别面部表情,该网络包括两个分支:维护分支和注意分支。为了提高输入人脸图像的关键点权重,我们设计了一种新的基于特征点和相关系数的加权掩膜,对每个表情在测试数据集上进行了广泛的区域测试实验,估计不同子区域对每个表情的影响。在对细粒度目标识别和分类中的注意力机制进行重新思考后,我们将方向依赖的注意力机制引入到网络中,通过注意分支更有效地利用局部突出特征。
此外,为了保留位置分配信息,我们将网络的两个分支的输出特征图结合起来进行深度卷积。为此目的,我们的主要贡献总结如下:
- 我们为FER提出了一个面向关注的网络(OAENet)体系结构,它聚合了ROI感知和关注机制,确保了全局和局部特征的充分利用。
- 我们提出了一种结合了人脸关键点和相关系数的加权掩膜,该方法能有效提高对局部区域的注意力。
- 我们的方法已经在几个热门的数据集上取得了较好的性能,如Ck+、RAF-DB和AffectNet
2. 近期研究
近年来,许多研究者对基于静态图像的面部表情识别进行了研究,并提出了一些行之有效的方法。我们回顾了与我们的工作相关的两个方面,即相似的网络架构设计(多任务学习和网络集成)和相关技术(注意力机制)。
2.1 基于深度学习的FER
近年来,深度卷积神经网络在计算机视觉领域取得了巨大的成功。受深度神经网络应用的启发,Jung等人的[11]分别训练了两个带有人脸关键点和图像序列的小型深度网络。为了获得更好的结果,他们采用了一种联合微调的方法来融合这两个网络。Liu等人[19]在无约束环境下为FER引入了一种新的条件卷积神经网络增强随机森林(CoNERF),利用条件概率学习对不同角度的面部表情进行编码。所提出的方法取得了较好的效果。
Ding等人在此结构的基础上,利用一个大型的预训练过的人脸识别网络,通过正则化机制训练出一个简单的人脸表情识别网络。Bozorgtabar等人[2]使用了一个小型深度编码解码器网络ExprADA,该网络在人脸数据库上进行了预先训练,获得了表情脸和中性脸之间的对比表示,这有助于区分表情。对于模糊标注问题,Shahet al.[27]采用线性判别分析(LDA)和三重支持向量机(SVM)来降低复杂度,最小化虚假标注。Ganet al.[7]建议使用软标签,将多种情绪与每个表情联系起来。为了解决分类相似性问题,liu等人将生成的面部表情作为硬否定标签处理。Xie等[34]通过DAMCNN结合局部-全局信息,自动为FER生成鲁棒的图像表示。Yu等人提取了局部-全局和时空信息,用于区分和鲁棒地表达面部表情。
2.2 带注意力机制的CNN
注意力机制已成功应用于许多计算机视觉任务,包括细粒度图像识别[38]、图像字幕[35]和视觉问答[40]。Liu等人[17]提出了一种有效的注意引导的深度音频-人脸融合方法来检测有源扬声器。Rodrguez等人[24]运用注意力机制发现关键信息来进行年龄和性别分类。Shiet al.[28]提出了一种新的用于年龄合成的条件注意规范化GAN (CAN-GAN),在这篇论文中,注意力被用来提供图像的视觉显著性。
对于人脸识别,首先将人脸图像分割成块,然后通过强化学习对块进行空间注意力控制策略。Liet al.[15]提出了一种结合CNN和注意力机制的遮挡感知方法。Sun等人[30]引入了视觉注意和ROI检测来解决可变头部姿态问题。值得一提的是,先前的研究忽略了除ROI以外的面部部分的注意力机制。
我们的方法受这些研究启发,考虑到表情识别比传统分类任务需要更多的关注细节,我们重新思考了注意力机制对细粒度分类的影响,然后将注意力机制引入到我们的网络中。为了获得更有效的注意,我们在网络中设计了单独的注意分支。同时,我们建立了基于方向梯度的加权掩模作为该分支的输入。根据有向梯度统计信息在子区域与全局图像之间的分布,制定相应的加权策略。为了保证图像信息的完整性,设计了单独的维护分支来获取原始图像的高级语义特征。深度网络处理实现了高级语义特征与局部突出的注意信息的融合。这些方法的组合促使网络达到较高性能。
3. 方法
3.1 网络架构
如前所述,多任务和集成网络在表情识别任务上的性能优于单一的端到端网络。基于此,我们的网络主流遵循一个伪孪生网络结构[8],网络概况如图1所示。网络的前半部分分为维护分支和注意分支。通过维护分支获得原始表情图像的全局高级语义信息,通过注意分支获得注意掩蔽增强的局部亮点信息。
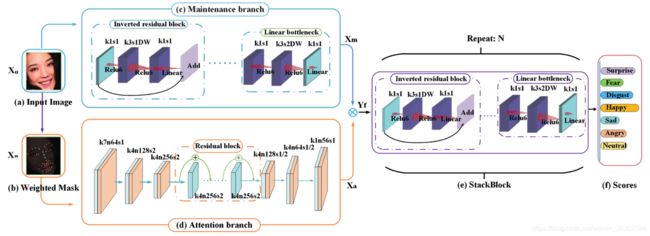
图1:网络结构图。(a)输入图像。(b)基于方向梯度计算加权掩模。我们的网络由一个©维护分支和(d)注意分支组成,其中©由几个反向残留和线性瓶颈结构组成,(d)是一个类似unet的架构。维护分支以原始人脸图像为输入,卷积为56 × 56 × 32。注意分支将加权掩膜作为输入。通过下采样和上采样,最终得到的feature map大小也为56 × 56 × 32。采用深度积的方法将两个分支的特征图进行融合。(e)是由几个CNN块组成的stackblock,产生最终的分数(f)。
我们的网络是完全卷积的。在图1中,蓝色矩形代表维护分支(图1 ©),橙色矩形代表注意分支(图1 (d))。维护分支由步幅为2的卷积层、2个反向残留块和1个线性瓶颈块组成,源自MobileNetV2[26]。维护分支的输入为224 × 224 × 3形状的人脸图像。随着卷积层数的增加,卷积核数也随之增加。经过几步卷积,输入被缩放到56 × 56 × 32。对于注意力分支,我们将其设计为一个非网状结构[25]。首先计算子区域与全局图像的相关系数,然后结合关键点构造加权矩阵。然后,将加权矩阵与原始人脸图像相乘,建立加权掩模作为注意分支的输入。关于加权掩模的具体细节将在3.2节进行阐述。
加权掩模的形状为224 × 224 × 3,首先通过一个步长为2的卷积层将其缩放到112 × 112 × 3,然后向下采样特征映射到14 × 14 × 512 × 3的卷积层。然后将6个残差块拼接得到语义信息,再通过3个反褶积层将残差块的特征图上采样至56 × 56 × 32。为了有效地融合这两个分支的信息,我们对这两个分支的输出进行了深度积。然后,融合后的特征被传递到后续网络,后续网络由几个连接的反向剩余块和线性瓶颈块(图1 (e)中的StackBlock)组成。分类结果(图1 (f))最终通过平均池化层输出。
我们定义变量Wm来表示加权矩阵,该变量Xw代表输入的加权掩膜的分支,注意维护分支的Xo作为输入,Xm作为维护分支的输出,Xa作为关注的输出分支用于突出Xo的关键位置信息,和Yf作为信息融合的结果,信息融合是由以下公式:
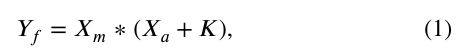

其中∗是深度卷积。具体来说,Xo的尺寸为224 × 224 × 3, Xm通过多个卷积层缩放为56 × 56 × 32。我们把Xw作为注意分支的输入,这是根据公式(2)计算的。注意分支下采样 14×14×512,然后恢复到56 56×32通过反卷积,然后我们通过深度方法合并这两个分支的输出。在公式1中,我们定义了非零常数K,以避免Xa中零值的影响。在我们的实验中,我们设K为1。
通过这种方式,该网络可以专注于定义面部运动的像素,导致更敏锐和集中注意力在表情图像的重要区域,这将原始图像中非注意力区域的高层次语义信息最大化。
在loss函数方面,我们选择lovasz-softmax loss[1]作为注意分支,它已经被证明是语义分段[29]的执行loss。

其中m( c )为类c∈C的像素误差向量。c为类号。△Jc为m( c )损失的替代量。
隔离损失[3]能同时减小类内差异,扩大类间差异。为了提高深度学习特征的判别能力,我们结合了island loss和softmax loss作为我们骨干网的整体loss方法。我们定义Ls表示softmax损失,LIL表示island损失。IL[3]公式为:
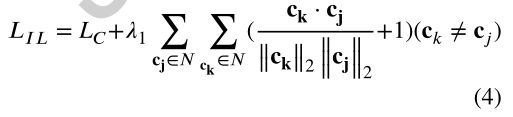
在上式中,其中Lc是[33]引入的中心损耗,主要关注的是类内分布的均匀性。它使数据点均匀地分布在类的中心,这已经被证明对最小化类内差异是有效的。N为表达式标号的集合;ck 和 cj 分别表示 ktℎ 和 jtℎ 中心,L2 norm分别为 ‖ ck ‖2 和 ‖ cj ‖2 ; (·) 表示点数积。具体来说,第一项惩罚样本之间的距离,其对应的中心和第二项惩罚表达式之间的相似性。λ1平衡了这两项。通过最小化孤岛损失,同一表情的样本会变得更接近,不同表情的样本会被分开。将 LS 和 LIL 与一个平衡因子 λ 结合,定义了总损失函数:
![]()
3.2 加权掩膜(Weighted Mask)
如相关著作(第2.2节)所述,一些多任务网络被用来利用面部标志进行面部表情识别。[9]已经证明,将人脸标志作为辅助输入输入到网络中可以提高网络性能。然而,这些方法只考虑关键点本身的空间关系,而关键点与周围区域的关系被忽略,更不用说关键点之外的区域与整个图像的关系了。
 图3:不同加权掩模的比较。(a)带有关键点的人脸图像。(b)关键点构造的加权掩模。©结合关键点和相关系数构造加权掩膜。(W/M:加权掩膜)。
图3:不同加权掩模的比较。(a)带有关键点的人脸图像。(b)关键点构造的加权掩模。©结合关键点和相关系数构造加权掩膜。(W/M:加权掩膜)。
在软注意的基础上,我们根据人脸标志的分布将整个人脸分为四个水平的部分。图2给出了一个示例。我们首先计算每个小区域的方向梯度:

根据统计概率将每个区域内的像素划分为几个间隔。我们将角度值分成k个bins,因此,有k个样本在itℎ 部分 Si,(i = 0,1,2,3)。我们将各部分的样本值定义为Vj,(j = 0,1,⋯,k−1),由公式10计算得到。Nj为jtℎ bin中的像素数。Ni是其中的像素总数ℎ部分。在我们的实验中,我们设k = 8。

根据式(11)计算A、B的联合概率分布,表示子区域与整个人脸图像的关系。B是一个统计随机变量,代表人脸分割的4个部分。A表示全局表情图像。我们定义Ei (i = 0,1,2,3)来表征 itℎ 分数的均值,Di (i = 0,1,2,3)表示itℎ子区域的方差。E0和D0分别描述了全局表达图像的均值和方差。pi,(i = 0,1,2,3)是部分Si相对于整个图像的相关系数。

同时,对于每个关键点,计算周围M × M邻域内像素与中心关键点之间的欧几里得距离,构造距离矩阵。
![]()
其中Ds为距离矩阵,Pi, Pj表示水平坐标和垂直坐标,i, j∈{0,⋯,M−1}。Pm, Pn是关键点的坐标。
现在,我们已经建立了与原始图像大小相同的加权矩阵。我们定义加权矩阵为Wm。矩阵Wm中关键点及其邻域的权值即为对应的距离矩阵(式14)。矩阵中其他位置的权值为相应的。然后,将加权矩阵与原始人脸图像相乘,得到注意分支的加权掩模。更多细节见消融II。
3.3 训练细节
我们采用了两阶段的培训策略。首先,我们从AffectNet[21]中选取150,000张裁剪过的人脸图像进行注意力分支训练。以已发表的关键点信息作为注意分支输入的样本。对于注意力分支的训练,我们设置总轮数为40,当验证数据集上的精度大于前一轮时,学习速率下降。这种自适应学习率调整策略被证明是有效的。在训练完注意力模型后,我们将模型合并到骨干网中。然后,我们在影响网的其他图像上训练骨干网。在训练过程中,我们冻结注意分支中的网络参数,只更新骨干网中各层的参数。初始学习率设置为1e-5,网络中每个卷积层的参数采用he-init方法。在实验中,我们将总纪元数设置为30。我们保存了验证集在每轮的损失和准确性。对于每6个epoch,我们将当前epoch验证集上的损失与之前的记录进行比较。如果在当前时代的损失没有继续减少,学习率更新为lr = lr/10。否则,学习速率保持不变。优化是使用动量0.9的同步SGD和batchsize=64的小批量执行的。所有模型在4个NVIDA 1080ti gpu上进行训练。
4. 实验结果
实验由两部分组成。第一部分介绍领先数据集的性能,并与最先进的方法进行比较。第二部分论述了消融研究。我们设计了两个消融研究,消融I和消融II,前者探究人脸不同区域的影响,用于展示面部各部分对FER任务的影响;后者通过将注意力分支从网络中移除来研究其重要性。
4.1 数据集
为了验证四种方法在不同场景下的鲁棒性和有效性,我们手动评估我们的性能。使用数据集包括两个自然场景下的FER数据集(RAF-DB[14],AffectNet[21])和两个实验室场景下的数据集(CK+ [20], MMI[31])。我们使用Dlib3库提取RAF-DB和MMI数据集的68个面部关键点,而AffectNet 和 CK +数据集已经提供了面部关键点信息,这确保了数据集中样本的完整关键点提取。图6显示了一些带有关键点的样本。
因为AffectNet是最流行和最大的面部表情识别基准数据集,所以我们选择它进行消融研究。所有的数据集都是与最先进的研究进行比较的。
RAF-DB包含12271个训练样本和3068个测试样本,分别标注了6个基本情绪类别(愤怒、厌恶、恐惧、快乐、悲伤、惊讶)和中性。RAF-DB中的图像标签是由315名编码人员标记的,最终的注释是通过众包确定的。
AffectNet包含大约40万张注释图像。我们选取了约28万幅图像作为训练样本,3500幅图像作为验证样本,分别带有中性情绪和6种基本情绪。
CK+包含来自123名被试的593条序列,其中327条被试被标注了7种情绪标签(6种基本情绪和蔑视情绪)。我们只选取了具有基本情绪标签的序列,并选择每个序列的第一帧作为中性脸,最后一帧作为情绪脸。因此,总共选取了636张图像。
MMI包含30名受试者,213个视频。在每个视频中,我们选择前两张为中性的面孔,中间三分之一为情绪化的面孔。
4.2 比较
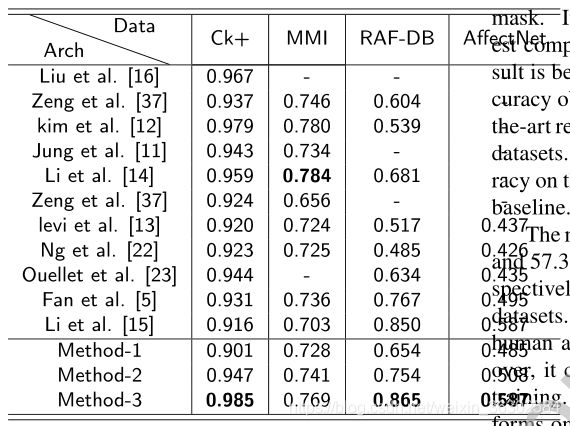
在本节中,我们将我们的模型与CK+、MMI、RAF-DB、AffectNet上的最新方法进行比较。表1给出了结果。总的来说,我们在这些数据集上实现了STOA性能。对于MMI数据集,我们的方法与其他竞争对手相当。
在CK+数据库中,包含了7个表情和一张中性图像。我们对除蔑视表情外的7种表情进行了实验。与基于RBM的方法[16,37]、基于序列信息的方法[11,5]、基于潜在标签估计的方法[37]和微调方法[13]相比,本文提出的方法具有更好的识别性能。
与CK+数据库设置类似,我们将MMI数据库划分为10个不同的独立子集,进行10折交叉验证。值得注意的是,在[12]中,输入是图像序列,这可以提高精度。我们在表1中展示了其结果。
与CK+、RAF-DB、AffectNet等数据库相比,该方法在MMI数据库上的识别精度不是最好的。由于MMI数据库的身份内部变化较大,局部选择的基于补丁的方法CSPL[39]比其他竞争对手表现出相对更好的性能。
在RAF-DB上有一些有竞争力的方法,如DLP-CNN[14],其目的是通过保持局部贴近度来增强深层特征的判别能力,同时最大化类间散射点来实现准确的面部表情识别。基于区域的方法MRE[5]以多对完整的人脸图像和子区域作为网络的输入。在RAF-DB上,MRE的精度为76.73%,是目前最先进的。
如[21]所述,AffectNet数据集上的7个类别的面部表情识别的正确性基线为40%,这是经过AlexNet训练的。作为比较,人类在AffectNet上的最佳表现是60.7%[21]。根据签名协议度量(SAGR)记录,这一数据集是通过用不同的人类标签标记同一批图像来收集的。
表1不仅列出了在四个基准上的FER相关方法,还展示了我们的三种不同的实验方法。我们使用Method1 (w / o。A)表示没有注意的网络,方法2 (w/o。W/M)表示有注意分支且不带加权掩膜的网络,Method-3 (A W . W/M)表示有注意分支且带加权掩膜的网络。可以看出,与其他两种方法相比,方法-1的结果是最差的,方法-2的结果更好,其精度明显提高。该方法-3在CK+、RAF-DB和affectnet数据集上取得了最先进的结果。我们的网络在AffectNet基准上达到了58.86%的精度,远远超过基线。
[37]方法在RAF-DB和AffectNet数据集上的准确率分别为86.77%和57.31%。然而,它是在不一致的数据集上训练的。具体来说,该模型是针对人工注释数据和未标记数据进行训练的。此外,它结合了几个不同的数据集进行训练。相反,我们的训练只在上面列出的基准的手工标记的训练数据上进行,我们的训练数据远远小于[37]中提出的方法。因此,为了进行公平比较,我们在表中不展示[37]的结果。我们认为我们的结果在RAF-DB和AffectNet数据集上仍然是相当有竞争力的
表1:与目前最先进的方法相比,表中的值精度最高为Top-1,在相应的数据集上,粗体的值最好。方差为±0.03。方法1:模型 w / o。A、方法二:A w/o。W/M,方法3:A w . W/M
4.3 消融实验
消融研究分为两部分。首先,将人脸图像中的眼睛、鼻子和嘴巴区域覆盖起来,探讨这些区域对面部表情识别的影响。第二部分对方法1和方法2进行了比较,证明了注意分支的加入确实产生了竞争性能,并进一步研究了加权掩模的必要性。
4.3.1 区域测试
本部分包括四组实验:分别对人脸图像的眼睛、鼻子、嘴巴和除这三个子区域以外的其他区域进行覆盖。具体操作如图4所示。这四个对比实验的结果如图5所示
 图4:消融I:探索不同子区域对每个表达的重要性。(a) (b)及©分别覆盖眼、鼻及口,d)覆盖所有区域
图4:消融I:探索不同子区域对每个表达的重要性。(a) (b)及©分别覆盖眼、鼻及口,d)覆盖所有区域

 图5:不同子区域对七种面部表情类别(惊喜、恐惧、厌恶、快乐、悲伤、愤怒、中性)识别的影响从左到右,测试结果的子区域(眼、鼻、嘴,全部:除眼、鼻、嘴之外的区域)上表现出了不同的表情。在每个子图中,有颜色的符号代表每个表情在1000张测试图像上的区分精度
图5:不同子区域对七种面部表情类别(惊喜、恐惧、厌恶、快乐、悲伤、愤怒、中性)识别的影响从左到右,测试结果的子区域(眼、鼻、嘴,全部:除眼、鼻、嘴之外的区域)上表现出了不同的表情。在每个子图中,有颜色的符号代表每个表情在1000张测试图像上的区分精度
为了保证实验的公平性,对于每一种情况,我们都保证被覆盖部分的面积相同,避免被覆盖面积不一致造成的影响。我们选择VGG作为基础网络进行消融实验,在AffectNet上进行训练。然后,我们为每个表达分别从AffectNet中选取1000张表达图像。最后,我们在选取的数据集上对模型进行了测试。
图5为各表情在4种条件下的识别准确率。在每个子图中,横轴代表数字,纵轴代表精度。选取5个分别保存在第5、15、25、35、45次的模型进行精度测试。这种选择包括了模型从初始阶段到稳定阶段的状态,可以帮助我们对模型进行综合评价。紫色的十字符号代表了该表达的基线,其余四种颜色符号代表了图4所示条件下的结果。如图所示,我们注意到子区域对每个表达的影响是歧视性的。当我们分析子图时,参考是基线,从基线到相应的彩色符号的距离代表每个子区域的推断。影响越大,离紫十字就越远。
有趣的是,眼睛对惊讶、恐惧、悲伤和愤怒类别的影响更大,但对厌恶、快乐和中性类别的影响相对较小。因为相对距离紫色交叉的黄色固体加号(a)、(b)、©, (f)比(d), ©, (g),相对而言,鼻子上有更大的影响类别的厌恶、愤怒和对其他5类表情的影响相对较小。很容易看出©和(f)中基线和鼻子验证结果(红色立体三角)之间的相对距离比其他子图要远。从相应的子数字中可以看出,嘴部对悲伤、快乐、中性类别的影响更大。
通过消融实验,我们发现嘴巴对面部表情识别的影响并不大于眼睛,而鼻子的影响较小。一个可能的原因是,嘴和鼻子包含的语义信息较少,以区分微观差异的任务,如表情识别。这也可以从表情的作用单元的分布中找到。从第四组实验的结果可以看出,眼睛、鼻子、嘴巴以外的区域对面部的影响是不可忽视的。在这种情况下,识别准确率大于50%。这也是加权掩模设计的现实依据。
我们也认为对于像表情识别这样的任务,我们应该探索像动作单元(AUs)这样的连续表示方法,它用不同的长度向量来描述面部行为的变化,这比离散标签(如0,1,2,⋯)更准确。在未来,我们将探索带有动作单元的识别方法。
4.3.2 面部区域划分
在本节中,我们将讨论面向区域划分的细节。我们从CK+和AffectNet中选取1000个样本作为实验数据集,分别命名为pose-sample、sponta-sample。利用三种不同的聚类算法,揭示了人脸标志的分布。这些聚类实验的结果为设计加权掩模时如何划分人脸区域提供了可靠的依据。
与实验室场景相比,自发数据集中的数据更加多样化,这在头部姿态和面部遮挡方面尤为突出。图6列出了几张具有代表性的面部表情图像(偏转、旋转等),不同的仰角和偏角构成了不同的表情图片。在实验过程中,我们使用c++ Dlib3来提取这些情况下的人脸关键点。接下来我们以在sponse -sample上的实验为例来进行描述,我们用了三种聚类算法:亲和传播算法、k -均值算法和Mean-shift算法进行了聚类实验。
 图6:不同姿势下的面部表情图像
图6:不同姿势下的面部表情图像
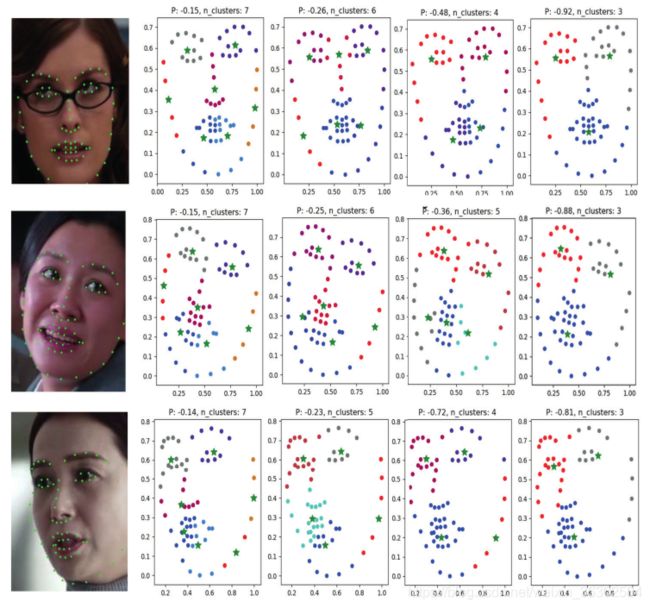 图7:AP的聚类结果。绿色立体五角形代表聚类中心,P越大表示聚类中心越多
图7:AP的聚类结果。绿色立体五角形代表聚类中心,P越大表示聚类中心越多
图7为亲和传播聚类结果。我们选择了三种有代表性的图片类型:闭合的、旋转的和偏转的。对于图7所示的每一行,第一幅图像是带有关键点的原始表情图,接下来的四个子图是对不同AP参数下关键点的聚类进行解释。如图所见,面部标志被划分为不同的部分,每个部分的聚集中心被标记为一个实心的绿色五角星。在图7中,P代表偏好,是衡量给定样本点成为聚类中心点概率的指标。P值越大,算法聚类的中心点越多,反之亦然。通过观察聚类中心在不同P值下的分布,我们发现无论P值如何变化,AP聚类算法都会在人脸的左右眼和嘴部找到相应的聚类中心点。同时可以看到,在口腔部分,它倾向于形成两个不同的簇中心,这是由脸颊上的关键点造成的。聚类算法使用欧几里得距离作为数据点之间距离的度量,将对称的关键点划分为两个相对对称的聚类区域。对于图6所示的非对称关键点,算法会根据数据密度将其划分为相应的区域。
为了说明AP聚类算法的准确性和获得关键点聚类分布的共同性,我们还使用K-Means、Mean-shift聚类算法对采样数据进行聚类分析,结果如图8、9所示。显然,即使算法的聚类结果不同,这些聚类算法在眼、鼻、嘴的聚类趋势是相同的。这样的聚类结果启发我们根据眼睛、嘴巴和鼻子的位置来划分面部区域。因此,我们考虑如图10所示的划分方法来构建加权掩模用于实验。实验结果见表2。表中,DM1(垂直方向)的精度最低,其次是DM2(水平方向)。DM3(不规则)和DM4(网格)的精度非常接近。
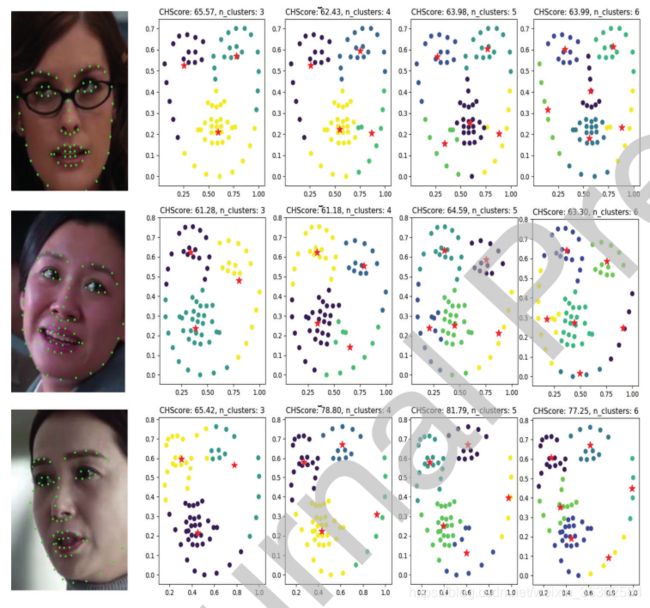 图8:k均值聚类结果。红色实心五角形为聚类中心,Calinski-Harabaz得分(CHScore)越大,聚类效果越好
图8:k均值聚类结果。红色实心五角形为聚类中心,Calinski-Harabaz得分(CHScore)越大,聚类效果越好
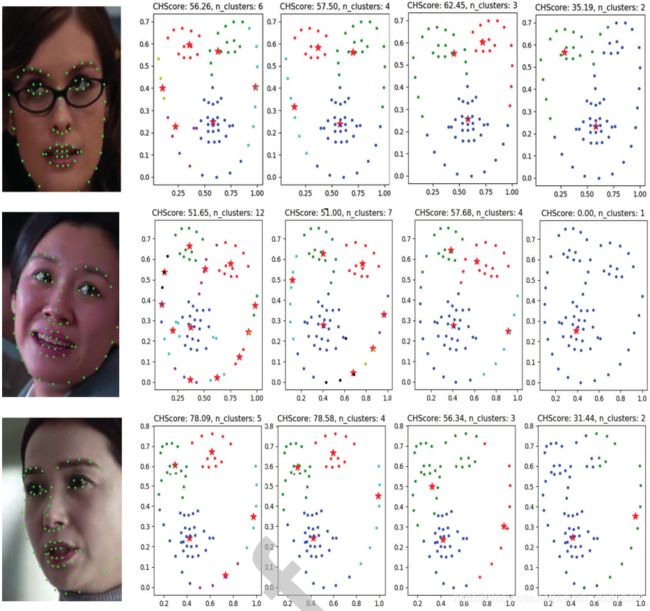 图9:Mean-shift聚类结果,红色实心五边形代表聚类中心,Calinski-Harabaz得分(CHScore)越大,聚类结果越好
图9:Mean-shift聚类结果,红色实心五边形代表聚类中心,Calinski-Harabaz得分(CHScore)越大,聚类结果越好
图10:不同人脸区域划分方法
DM3和DM4的划分较为详细,符合面部关键点的聚类趋势。脸是对称的,但在一些面部姿势,照片上的脸可能不完整。例如,在侧脸的情况下,我们只能获得部分的人脸图像。然而,无论在什么情况下,脸部各部分的相对位置都是恒定的。也就是说,在不同的情况下,那些应该聚集在一起的面部数据点仍然在很大程度上保留了数据点之间的相似性和可用性。
表2:比较不同的人脸分割方法,粗体值是对应数据集上最好的结果。相应的划分方法如图10所示。表中值为Top1精度,方差为±0.03。DM:划分方法
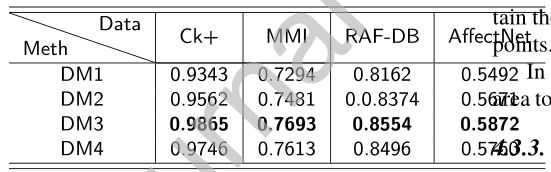
综上所述,我们选择DM3对人脸面积进行划分,构建相应的加权掩模。
4.3.3 加权掩膜评估
在本节中,我们在CK+和自发面部表情数据集AffectNet上进行了几个实验,以评估关键点和相关系数的效果。
我们根据消融研究II的DM3划分方法构建加权掩膜。要构建加权掩膜,首先需要构建一个相应的权重矩阵。如3.2节所述,整个图片的权值矩阵由两部分组成,第一部分是每个关键点及其邻点的权值矩阵。第二部分是关键点以外区域的权值矩阵。我们将这两个权重矩阵分别定义为wmatrix-land和wmatrixcorr。
对于每一张表情图像,我们首先对原始人脸的每个关键点进行标记,然后计算相应的wmatrix-land和wmatrix-corr。wmatrix-land和wmatrix-corr如图11所示。图11(a)为wamtrix-land,图11(b)为结合非关键区域相关系数wmatrix-corr的整体图像权值矩阵。由于图像较大,为了显示方便,我们只截取了整体权值矩阵的一部分区域。图11(b)中较亮的部分表示图11(a)路标处的权值矩阵。周围的数字表示从该区域的直方图中获得的相关系数。也就是说,wmatrix-corr。
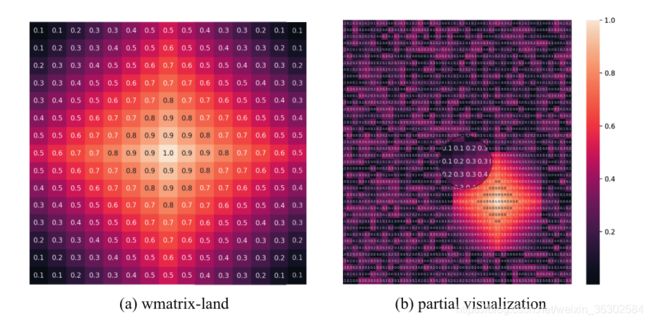 图11:整个图像的wmatrix-land和部分加权矩阵的可视化。
图11:整个图像的wmatrix-land和部分加权矩阵的可视化。
可以看出,关键点仍然是权重矩阵中最突出的权重,其他区域的像素根据不同的相关系数被赋予不同的权重。
为了得到加权掩模,我们需要将计算得到的权重矩阵应用到我们的原始表情图像上。图12、13显示了一些加权掩模的结果。为了验证加权掩模的有效性,我们进行了8组对照实验。实验结果见表3。

图12 CK+表情图像的不同加权掩模E*表示表3所示的不同加权矩阵组合
图13:AffectNet表情图像的不同加权掩膜。E*表示表3所示加权矩阵的不同组合。
表3:比较不同加权掩膜,粗体值是对应数据集上的最佳结果。wmat-corr为非焦点区域的相关系数矩阵,wmat-land为关键点区域的加权矩阵。与wmatrix-corr和wmatrix-land相同。表中值为Top-1精度,方差为±0.03。
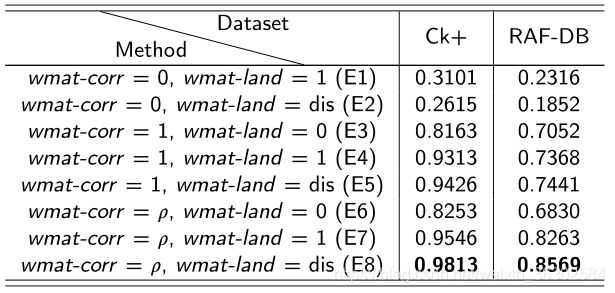
其中p为相关系数,dis为根据3.2节方法计算的距离。在E1和E2的比较中,E1比E2更准确。而E1和E2准确率均较低的主要原因是当wmatrix-corr = 0时,输入的数据太少,网络上可用的数据太少。图12(b)显示了这一例子的输入。E4和E5相比,可以发现E5的精度更高。这是因为当wmatrix-corr = 1时,网络在学习过程中会偏向非关键区域,这会对结果产生负面影响。通过对E3和E6的比较,进一步得出了人脸中存在不可忽视的非关键性区域的结论。对比E4和E7可以看出,非关键性区域虽然对表情识别有积极的影响,但该区域难以被注意也因此会影响网络的学习能力。这也从侧面说明了由相关系数构成的wmatrix的重要性。对比E6、E7、E8可以看出,梯度软注意相对于关键区域的硬注意更有利于网络学习。
4.3.4 注意力+加权掩膜
在本节中,我们分析了有和没有加权掩膜的注意分支的添加如何影响我们的FER模型的性能。我们将实验分为3组,与表1相似。Method-1:不带注意力机制的模型,Merthod-2:不带加权掩模的注意力模型,Method-3:带加权掩模的注意力模型。实验在AffectNet基准上进行。
实验结果的混淆矩阵如图14所示,其中xticks代表预测标签,yticks代表真实类别标签0∶惊讶,1∶恐惧,2∶厌恶,3∶快乐,4∶悲伤,5∶愤怒,6∶中性。从混淆矩阵可以看出,方法2对7个类别的平均准确率为50.83%,比没有注意分支的网络提高了2.31个百分点。方法3的平均正确率为52.31%,比方法1和方法2分别高3.79和1.48。同时,从混淆矩阵可以看出,在上述三组消融测试中,对恐惧、厌恶、愤怒的网络识别准确率较低,而对惊喜、快乐、悲伤、中性的识别准确率较高,这主要原因是数据中的标签模糊和类别样本的不平衡。
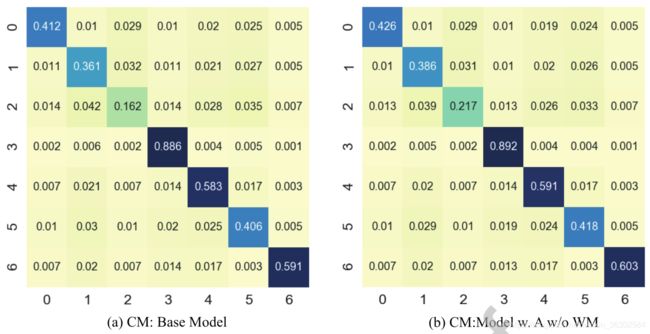
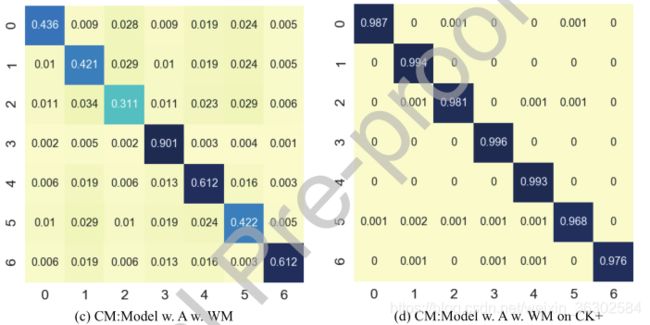
图14:我们模型的混淆矩阵(CM)。abc为AffectNet上的结果(a):基本模型的混淆矩阵。(b):无加权掩膜的注意力模型(WM)。( c ):加权掩膜的注意力模型。(d): CK+上有加权掩膜的注意力模型。(上图中的数字,0:惊讶,1:恐惧,2:厌恶,3:快乐,4:悲伤,5:愤怒,6:中立)
图16和图15显示了我们的模型在有无加权掩模情况下的对比。在每个图中,我们展示了维护分支的输出、注意分支的输出、融合结果和注意分支的输入。这两个图中的子图(a)、(b)、©、(d)是对应的。对比图15和图16中的子图 (b)、©可以明显看出,融合的feature map更集中在人脸的热点区域,特征更紧凑。对比这两张图对应的(a),图15中(a)的白色部分代表注意区域,图16中突出部分代表注意区域。直观地说,带有加权掩膜的注意力分支的特征图更加详细。从©的比较中可以看出,两图中突出的部分代表融合后的注意区域。由此可见,加权掩模融合的特征图在保留局部高亮信息有更强的能力。
图15:无加权掩模的效果(a)注意分支输出,(b)维护分支输出,© (a)与(b)融合,(d)无加权掩模模型的输入。(WM:加权掩膜。)
图16:有加权掩模的效果(a)注意分支输出,(b)维护分支输出,( c ) (a)和(b)融合,(d)加权掩模。(WM:加权掩膜)
从中间输出的可视化和两者的比较可以看出,我们所提出的加权掩模在网络中有比较明显的效果。方法-3对图像中特定区域的关注程度较高,可以更好地引导网络增强对表情图片中特定区域的学习;而相比之下,方法2对面部表情不那么敏感。
5. 结论
本文将注意力机制引入到表情识别任务中,通过定向注意集成方法,解决了局部信息利用不足的问题。我们设计了一个具有维护和注意分支的伪孪生网络。我们计算了人脸图像的方向梯度构造加权掩模,作为注意分支的输入。进而,利用注意分支得到表情的注意掩膜。语义掩膜和注意掩膜通过方法的深度组合来保证我们的网络的注意力。我们已经在几个热门的数据集上取得了较好性能,包括CK+、RAF-DB和AffectNet。我们也通过消融研究仔细分析我们的网络设计的有效性。在消融研究中,我们证明了理论导向注意合集的有效性。在未来关于面部表情问题的研究中,可以考虑以下几个问题:
-
在实验中,我们注意到面部区域的划分对最终的结果有很大的影响。为了获得更精确的除法,我们计划添加一个自适应预测子网来自适应地生成加权矩阵。我们的OAENet的输出和注意力分支的特征映射将作为反馈到这个子模块。同时,为了提高分割精度,我们将引入像素级分割的思想。通过对每个像素中的平均人脸和目标表情进行相减,得到一个更密集的加权矩阵,提高了人脸区域划分的精度。
-
针对表情识别任务中的遮挡问题,我们计划提出一种新的关系模型,用于评估遮挡位置和目标之间的相关性。为了获得准确的关系模型,需要建立三元组数据集。在每个三联体细胞中,阳性、阴性和样本本身都将包括在内,然后关系模型将成为我们新的FER模型的内置部分,一旦找到遮挡人脸表情图,就可以预测遮挡者与人脸之间的关系,然后生成一个修正矩阵来修改网络的学习方向。这样,网络的学习焦点被转移到未封闭区域,然后在那里进行表情识别。
-
我们的工作是在离散表情识别领域,但表情的产生不是一个完全离散的过程。当我们对每个表情图像进行离散标记时,我们可以使用某个表情生成的中间阶段图像作为最终标记的图像。例如,在产生愤怒和惊讶的过程中,有许多类似的中间表达。一旦这些中间表情被贴上不同的表情标签,就会影响模型的决策。因此,如何在大量的表情图像中找到一个相似度高的样本进行特定的处理就显得尤为重要。我们计划构建一个紧凑的向量嵌入模型,进行表情检索,在数据集中找到高度相似的数据进行精确标记和细分,以提高表情识别的准确性。
[1] Berman, M., Rannen Triki, A., Blaschko, M.B., 2018. The
lovász-softmax loss: a tractable surrogate for the optimiza-
tion of the intersection-over-union measure in neural net-
works, in: Proceedings of the IEEE Conference on Com-
puter Vison and Pattern Recognition.
[2] Bozorgtabar, B., Mahapatra, D., Thiran, J.P., 2020. Ex-
prada: Adversarial domain adaptation for facial expression
analysis. Pattern Recognition 100, 107111.
[3] Cai, J., Meng, Z., Khan, A.S., Li, Z., OâĂŹReilly, J., Tong,
Y., 2018. Island loss for learning discriminative features in
facial expression recognition, in: 2018 13th IEEE Interna-
tional Conference on Automatic Face & Gesture Recogni-
tion (FG 2018), pp. 302–309.
[4] Ding, H., Zhou, S.K., Chellappa, R., 2017.
Facenet2expnet: Regularizing a deep face recogni-
tion net for expression recognition, in: 2017 12th IEEE
International Conference on Automatic Face and Gesture
Recognition (FG 2017), pp. 118–126.
[5] Fan, Y., Lam, J.C., Li, V.O., 2018. Multi-region ensemble
convolutional neural network for facial expression recogni-
tion, in: International Conference on Artificial Neural Net-
works, Springer. pp. 84–94.
[6] Fu, J., Zheng, H., Mei, T., 2017. Look closer to see better:
Recurrent attention convolutional neural network for fine-
grained image recognition, in: Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition.
[7] Gan, Y., Chen, J., Xu, L., 2019. Facial expression recogni-
tion boosted by soft label with a diverse ensemble. Pattern
Recognition Letters 125, 105–112.
[8] Hadsell, R., Chopra, S., LeCun, Y., 2006. Dimensionality
reduction by learning an invariant mapping, in: Proceed-
ings of the IEEE Conference on Computer Vison and Pat-
tern Recognition.
[9] Hasani, B., Mahoor, M.H., 2017. Facial expression recog-
nition using enhanced deep 3d convolutional neural net-
works, in: Proceedings of the IEEE Conference on Com-
puter Vison and Pattern Recognition (CVPR) Workshops.
[10] Herlihy, M., 1993. A methodology for implementing
highly concurrent data objects. ACM Trans. Program.
Lang. Syst. 15, 745–770.
[11] Jung, H., Lee, S., Yim, J., Park, S., Kim, J., 2015. Joint
fine-tuning in deep neural networks for facial expression
recognition, in: Proceedings of the IEEE Conference on
Computer Vison and Pattern Recognition.
[12] Kim, D.H., Baddar, W.J., Jang, J., Ro, Y.M., 2017.
Multi-objective based spatio-temporal feature representa-
tion learning robust to expression intensity variations for
facial expression recognition. IEEE Transactions on Af-
fective Computing 10, 223–236.
[13] Levi, G., Hassner, T., 2015. Emotion recognition in the
wild via convolutional neural networks and mapped binary
patterns, in: Proceedings of the 2015 ACM on Interna-
tional Conference on Multimodal Interaction, ACM.
[14] Li, S., Deng, W., Du, J., 2017. Reliable crowdsourcing and
deep locality-preserving learning for expression recogni-
tion in the wild, in: Proceedings of the IEEE Conference
on Computer Vison and Pattern Recognition.
[15] Li, Y., Zeng, J., Shan, S., Chen, X., 2018. Occlusion
aware facial expression recognition using cnn with atten-
tion mechanism. IEEE Transactions on Image Processing
28, 2439–2450.
[16] Liu, P., Han, S., Meng, Z., Tong, Y., 2014. Facial expres-
sion recognition via a boosted deep belief network, in: Pro-
ceedings of the IEEE Conference on Computer Vison and
Pattern Recognition.
[17] Liu, X., Geng, J., Ling, H., ming Cheung, Y., 2019a. At-
tention guided deep audio-face fusion for efficient speaker
naming. Pattern Recognition 88, 557 – 568.
[18] Liu, X., Vijaya Kumar, B., Jia, P., You, J., 2019b. Hard neg-
ative generation for identity-disentangled facial expression
recognition. Pattern Recognition 88, 1–12.
[19] Liu, Y., Yuan, X., Gong, X., Xie, Z., Fang, F., Luo, Z.,
2018. Conditional convolution neural network enhanced
random forest for facial expression recognition. Pattern
Recognition 84, 251 – 261.
[20] Lucey, P., Cohn, J.F., Kanade, T., Saragih, J., Ambadar,
Z., Matthews, I., 2010. The extended cohn-kanade dataset
(ck+): A complete dataset for action unit and emotion-
specified expression, in: Proceedings of the IEEE Confer-
ence on Computer Vison and Pattern Recognition (CVPR)
Workshops.
[21] Mollahosseini, A., Hasani, B., Mahoor, M.H., 2017. Af-
fectnet: A database for facial expression, valence, and
arousal computing in the wild. Proceedings of the IEEE
Conference on Computer Vison and Pattern Recognition .
[22] Ng, H.W., Nguyen, V.D., Vonikakis, V., Winkler, S., 2015.
Deep learning for emotion recognition on small datasets
using transfer learning, in: Proceedings of the 2015 ACM
on International Conference on Multimodal Interaction,
ACM.
[23] Ouellet, S., 2014. Real-time emotion recognition for gam-
ing using deep convolutional network features. arXiv
preprint arXiv:1408.3750 .
[24] RodrÃŋguez, P., Cucurull, G., Gonfaus, J.M., Roca, F.X.,
GonzÃălez, J., 2017. Age and gender recognition in the
wild with deep attention. Pattern Recognition 72, 563 –
571.
[25] Ronneberger, O., Fischer, P., Brox, T., 2015. U-net: Con-
volutional networks for biomedical image segmentation,
in: International Conference on Medical Image Computing
and Computer-Assisted Intervention, Springer. pp. 234–
241.
[26] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen,
L.C., 2018. Mobilenetv2: Inverted residuals and linear bot-
tlenecks, in: Proceedings of the IEEE Conference on Com-
puter Vison and Pattern Recognition.
[27] Shah, J.H., Sharif, M., Yasmin, M., Fernandes, S.L., 2017.
Facial expressions classification and false label reduction
using lda and threefold svm. Pattern Recognition Letters .
[28] Shi, C., Zhang, J., Yao, Y., Sun, Y., Rao, H., Shu, X., 2020.
Can-gan: Conditioned-attention normalized gan for face
age synthesis. Pattern Recognition Letters 138, 520 – 526.
[29] Sun, T., Chen, Z., Yang, W., Wang, Y., 2018a. Stacked u-
nets with multi-output for road extraction, in: Proceedings
of the IEEE Conference on Computer Vison and Pattern
Recognition (CVPR) Workshops.
[30] Sun, W., Zhao, H., Jin, Z., 2018b. A visual attention
based roi detection method for facial expression recogni-
tion. Neurocomputing 296, 12–22.
[31] Valstar, M., Pantic, M., 2010. Induced disgust, happi-
ness and surprise: an addition to the mmi facial expression
database, in: Proc. 3rd Intern. Workshop on EMOTION
(satellite of LREC): Corpora for Research on Emotion and
Affect, LREC. p. 65.
[32] Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H.,
Wang, X., Tang, X., 2017. Residual attention network for
image classification, in: Proceedings of the IEEE Confer-
ence on Computer Vison and Pattern Recognition.
[33] Wen, Y., Zhang, K., Li, Z., Qiao, Y., 2016. A discrimina-
tive feature learning approach for deep face recognition,
in: European Conference on Computer Vison, Springer.
pp. 499–515.
[34] Xie, S., Hu, H., Wu, Y., 2019. Deep multi-path convolu-
tional neural network joint with salient region attention for
facial expression recognition. Pattern Recognition 92, 177
– 191.
[35] Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudi-
nov, R., Zemel, R., Bengio, Y., 2015. Show, attend and tell:
Neural image caption generation with visual attention, in:
International Conference on Machine Learning, pp. 2048–
2057.
[36] Yu, M., Zheng, H., Peng, Z., Dong, J., Du, H., 2020. Facial
expression recognition based on a multi-task global-local
network. Pattern Recognition Letters 131, 166 – 171.
[37] Zeng, J., Shan, S., Chen, X., 2018. Facial expression recog-
nition with inconsistently annotated datasets, in: Proceed-
ings of the European conference on Computer Vison.
[38] Zheng, H., Fu, J., Mei, T., Luo, J., 2017. Learning multi-
attention convolutional neural network for fine-grainedim-
age recognition, in: Proceedings of the IEEE International
Conference on Computer Vison.
[39] Zhong, L., Liu, Q., Yang, P., Liu, B., Huang, J., Metaxas,
D.N., 2012. Learning active facial patches for expression
analysis, in: Proceedings of the IEEE Conference on Com-
puter Vison and Pattern Recognition.
[40] Zhu, C., Zhao, Y., Huang, S., Tu, K., Ma, Y., 2017. Struc-
tured attentions for visual question answering, in: Proceed-
ings of the IEEE International Conference on Computer
Vison.