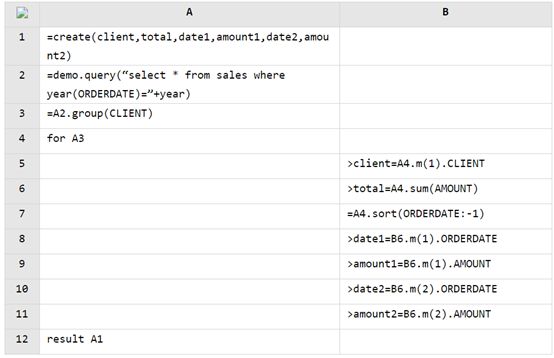
为什么用了大牌工具后报表开发依然头痛
因为用错了报表工具,或者没有用对姿势。
疼在哪里?
报表工具不就是为了解决手工开发报表效率低、困难多等这些让人头痛的难题的吗?怎么用了大牌工具还会头痛,是功能不行解决不了这些问题?
不,并不是
好的报表工具确实可以很好地解决制表方面的困难,但是报表开发的难题,并不全在制表上,
还有相当一部分在数据准备上,应用中的报表,有80%的数据来源和计算都比较简单,很多一个简单的SQL语句就搞定了,但还有20%的情况中,数据准备工作就没有那么好做了,一些过程式的多步骤复杂计算,常常要写很长的多层嵌套的SQL或者存储过程才能搞定,如果数据来源再复杂一些,要对各类数据源混算,一些非关系数据库或者文本数据源都不支持SQL了,那还得用JAVA等语言来写,SQL 10几行能写完的,JAVA恨不得写出几百行来,编码难度和效率就更糟糕了
然而恰恰是这仅占20%的需要硬编码来做复杂数据准备的报表,会占去80%的工作量,这就是为什么用了大牌报表工具后依然会头疼的最大原因:用了虽然大牌但缺乏数据准备功能的报表工具,其实就是用错了报表工具,而且也没有好的数据准备方案来补充。
没完没了的报表加剧头疼
报表随需而动的业务属性又决定了它不稳定的特性,随时都会有新的查询统计需求冒出来,或做新的,或修改旧的,没完没了。。
做新的
如果又遇上复杂计算的,那就又得硬写存储过程和JAVA了,没有好的办法那就得一直持续头痛
修改旧的
因为之前复杂的数据准备都是用存储过程或者JAVA写的,导致报表模块和数据库以及应用高度耦合,开发人员不能随意动终端方的数据库,权限和安全都是问题,改一次存储过程会很费劲,JAVA代码可以随便改,但是改了又得重新编译,应用就得三番五次的停机,修改维护起来也很头痛
这些没完没了的报表,搞得项目永远做不完,居高不下的成本还一直在追加。这是令很多软件开发公司都头痛不已的问题
怎么办
简单,补上数据准备环节的工具就可以了
集算器做数据准备写的快算的快
集算器,流行的开源免费数据计算工具
一:它能对接各类数据源

二:能轻松写出SQL和JAVA写起来困难的计算过程,而且还算的快,让数据准备工作变的轻松又高效
我们来看两个小例
1 报表中需要呈现连续上涨超过 5 天的股票及上涨天数
这样的报表,制表时候只需要设计几个格子,很简单,但数据准备却不简单,大部分的工作量都得花在这个数据的计算上
用SQL来算的话,得写3层子查询
select code,max(risenum)-1 maxRiseDays from
( select code,count(1) risenum from
(
select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from
(
select
code,
ddate,
case when price>=lag(price) over(partition by code order by ddate)
then 0 else 1 end changeSign
from stock_record
)
)
group by code,unRiseDays
)
group by code
having max(risenum) > 5
用开源的集算器去写则简单很多
| A | ||
|---|---|---|
| 1 | =connect@l(“orcl”).query@x(“select * from stock_record order by ddate”) | |
| 2 | =A1.group(code) | |
| 3 | =A2.new(code,~.group@i(price < price[-1]).max(~.len())-1:maxrisedays) | 计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
2 列出每一个用户最近一次登录间隔
SQL的大致写法
WITH TT AS
(SELECT RANK() OVER(PARTITION BY uid ORDER BY logtime DESC) rk, T.* FROM t_loginT)
SELECT uid,(SELECT TT.logtime FROM TT where TT.uid=TTT.uid and TT.rk=1)
-(SELET TT.logtim FROM TT WHERE TT.uid=TTT.uid and TT.rk=2) interval
FROM t_loginTTTT GROUP BY uid
开源集算器的写法
| A | ||
|---|---|---|
| 1 | =t_login.groups(uid;top(2,-logtime)) | 最后2个登录记录 |
| 2 | =A1.new(uid,#2(1).logtime-#2(2).logtime:interval) | 计算间隔 |
一两个难的可能省不了多少时间,常年累月做项目,那么多复杂的计算场景如果都用开源的集算器,能省下多少时间呢
完全工具化应对没完没了
洗衣机发明之前,每一次洗衣服,都是一次头痛的经历
洗衣机发明之后,洗多少次,都不发愁了
工具化,才是解决频繁,复杂劳动的好办法
没完没了的报表新需求和修改要求是消除不了的,也必须用工具化的方法才能解决
报表制作的工具化,就是报表工具本身,解决了频繁做表效率低下的问题
数据准备的工具化,就是集算器,则可以解决频繁的,困难的数据准备的问题
全面的工具化,才能彻底解决从数据准备到报表制作的所有头疼问题
另外使用集算器代替存储过程和JAVA后,由于集算器的脚本是写在报表文件里或者和报表文件一起存储的,这样就可以把报表应用从数据库以及整个应用中解耦出来,集算器的脚本又是解释执行的,天然拥有热切换能力,也可以省去频繁修改时每次编译的麻烦
对于集算器协助报表开发感兴趣的同学可以参考 http://c.raqsoft.com.cn/article/1639703872560
直接用润乾报表更便利
润乾报表已经集成了集算器,可以直接使用集算器的相关功能,不仅省去了集成的麻烦,而且还有额外的便利
报表直接使用集算器结果做数据集,无缝对接

报表中还能使用集算器函数,提升开发效率
还可以在报表的单元格里直接使用集算器中一些高级的函数,让计算过程更加的简便,提升报表本身的开发效率
比如下面这个单元格表达式:
表达式:=“班级名次上升最快的三位同学是:”+string(esproc(“?.m(?.ptop(-3))”,B3{},K3{})),这个单元格要求取出名次上升最快的三位同学,有多种做法,可以像排名那样,先对名次变化幅度做个排名,然后再根据幅度排名获取前三位,但是这种做法要增加辅助单元格,计算过程稍显繁琐,但是直接用集算器的高级函数就很简单了,将 K3 单元格(名次变化幅度)传入,ptop(-3) 取最大的 3 位的位置,然后用 m() 函数根据位置取对应的姓名,就可以了
大报表功能,提升报表性能
润乾结合集算器独创的双异步线程方案,可以很好的解决清单式大报表的性能问题,比传统的数据库分页技术解决方案效果更好,更快
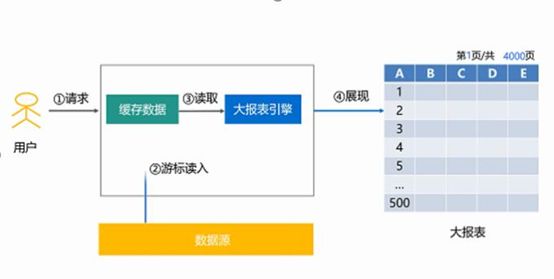
另外润乾报表一直以来都是报表行业的领导者,更是性价比高的代表,不仅质冠商用,而且价怼开源,1w一套,3w一年随便用,一套润乾报表,就可以解决所有烦恼了
结语
头痛是因为现有的报表工具不能解决全部难题,耗费大量时间成本的、需要硬编码的复杂数据准备场景,就是目前很多项目上的大难题。解决这类频繁的、复杂的难题,关键的办法就是工具化,要么集成开源集算器,要么直接采用支持数据准备的润乾报表,难开发的就都简单了,效率也自然提升了,就不会再那么头痛了
润乾报表资料
- 润乾报表官网
- 润乾报表下载
欢迎对润乾报表有兴趣的加小助手(VX号:RUNQIAN_RAQSOFT),进技术交流群