2020/12/11 基于Istio实现微服务治理
1.1 istio介绍及安装
基于spring-cloud去实现微服务的时候,实现服务治理,spring是基于java的,如果要所有语言都支持服务治理,就需要istio


服务网格是一种概念,只是一种思想,istio只是其中一种实现

spring cloud无法去跨平台。先把这两个理解为两个pod,如果两个服务pod要进行通信治理,基本实现就是放在业务代码里

service mesh是这么做的,在pod里加上容器,通常称为sidecar边车,流量都会经过sidecar,就可以进行一些流量的处理,就可以理解为每个业务的pod添加了类似nginx的容器,也就是服务治理的能力被放到了sidecar里,业务代码还是怎么写就怎么写,只不过代码里不写服务治理相关内容,服务治理的能力放到了平台上


sidecar里可以做很多事情,服务注册,健康检查,流量熔断

蓝色的是边车,边车之间做通信,流量和流量之间的传递是放在平台里

在你的服务旁边加上了代理层
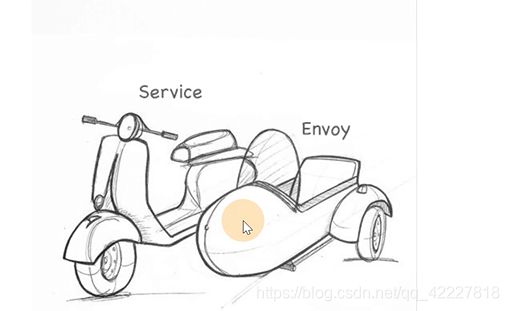
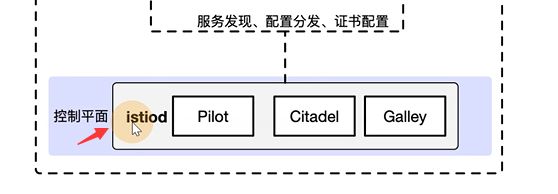
service mesh服务网格是一种思想,它的实现,第一代是linker的和envoy,更多偏向于代理层的实现

对于这个控制层面做的不好,可以写配置,配置如何下发给你

第二代的istio事实上是service mesh的一个标准,实际上是在envoy基础上进行改良,补足了控制平面的功能

流量来走的都是微服务的proxy(可以叫envoy,sidecar,就是一个容器),流量进入到代理,出去的流量也会经过代理,
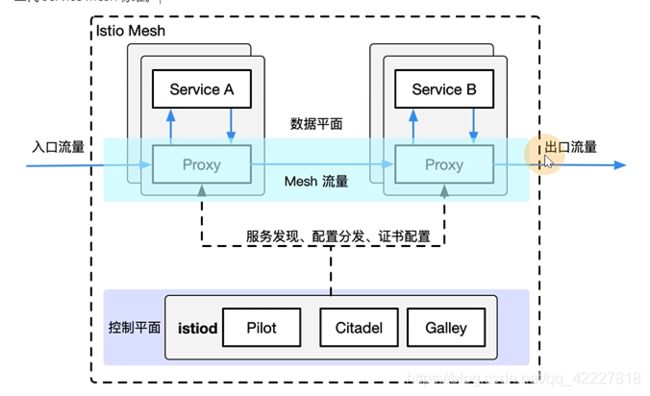
转发控制的规则,是控制层面下发代理的、


下载好istio版本
 ‘客户端控制工具
‘客户端控制工具
复制命令到path路径下

1.7.3版本

有个命令补全,需要去执行shell

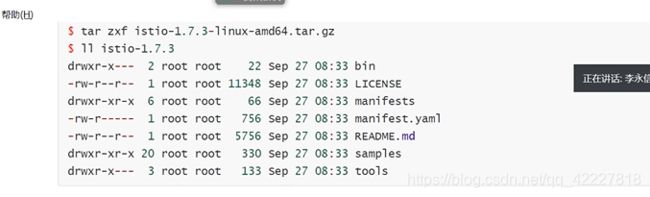

查看一下profile是什么意思
![]()

可以理解为不同的配置,跟买车类似,istio的配置有这么几个

选择default,就有这么几个组件是安装的,X号代表安装


istiod就是控制平面的

查看安装的哪些组件是安装的可以查看这个链接
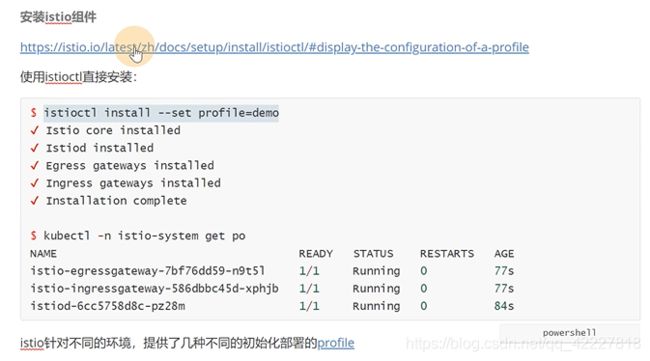

istioctl里有 manifest generate生成,按照指定的profile生成yaml文件


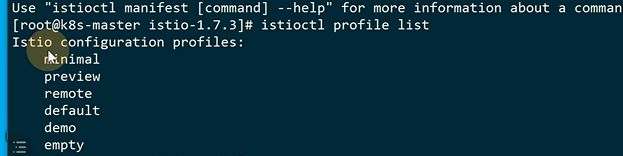
想看demo项有哪些
![]()
都是一些K8S的资源
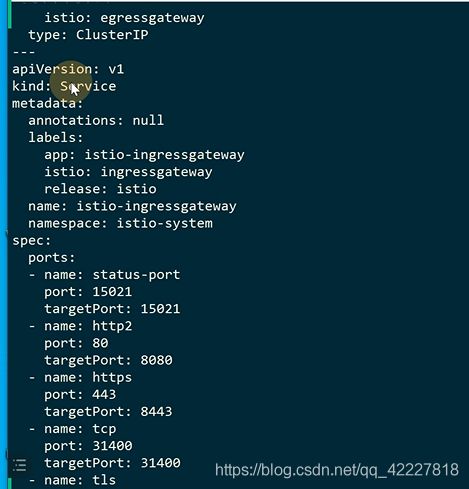
会多一个命名空间
 **、其实就是起了三个deployment,建立三个service、
**、其实就是起了三个deployment,建立三个service、
**

crd是istio自己实现的功能需要创建的
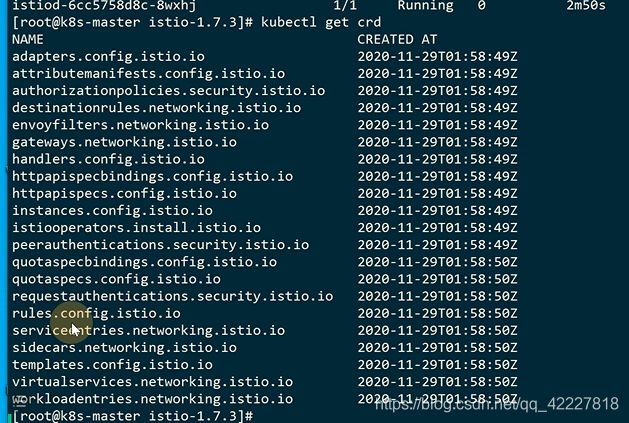
这样istio就安装好了,卸载就是把K8S里这么些资源删除

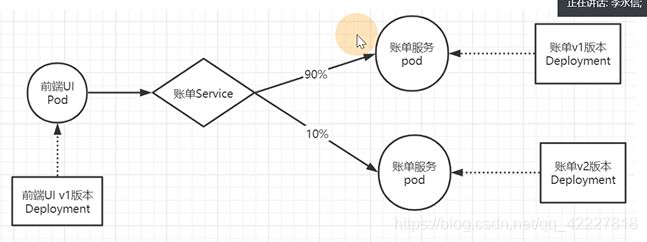
1.2 istio流量模型示例一
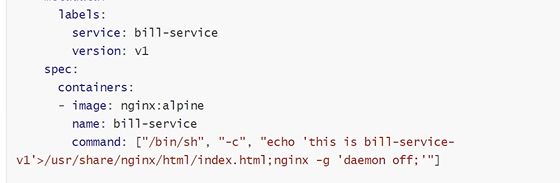
有一个前端服务,是一个前端v1 deployment版本的服务,后面是账单服务,由一个账单V1 deployment版本,前端暴露一个service账单服务去访问


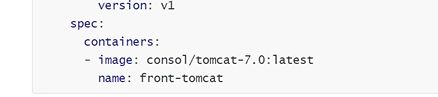
先创建前端的


pod容器里用这个命令来启动


还缺一个service
![]()
匹配的是bill-service

也就是这个


先创建istio-demo命名空间



现在有一个service

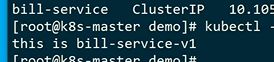
进入tomcat容器,curll一下service name来访问服务

返回bill 1
、
第二个模型,后台要更新,现在是v2版本



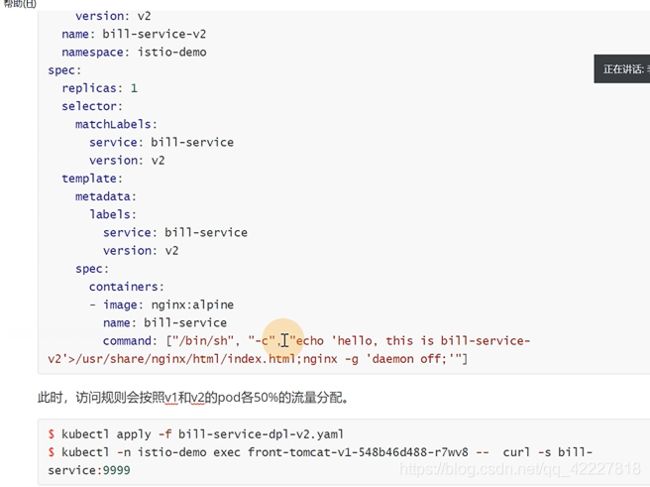


创建这个资源


现在是两个pod

但是现在访问基本上流量是均衡的

k8S服务是百分百的公式


访问的时候,第一步是域名解析,解析成ip地址
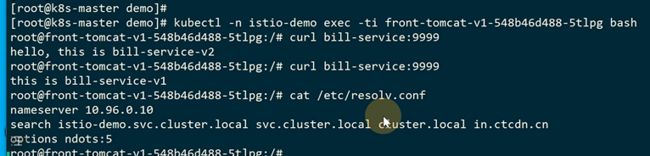
另外i一个pod其实也可以访问

解析出来是这样

这个地址就是bill-service的clusterip地址

也就是这两个是等价的

进pod容器看路由,这个是flannel的ip段

明显没有10.105.42的ip段

所以只能转发到gateway,10.244.2.1的网关上去
、
是在主机上的
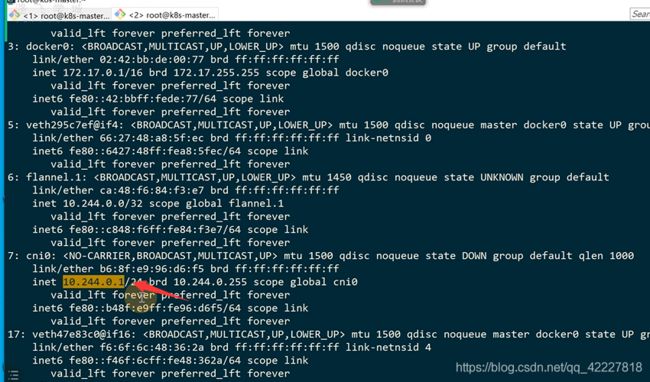
也就是访问的流量,转发到宿主机上去 了

但是宿主机没有这个10段的路由
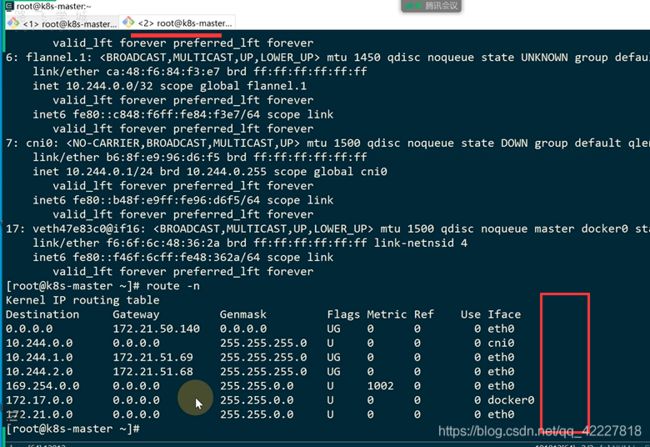
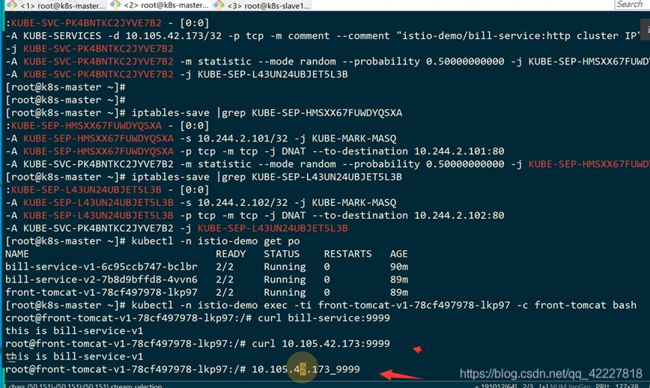
iptale里有这个实现,地址是10.105.42.173地址的流量,都转发到KUBE-SVC-PK4BNTKC2

多了一个random转发 ,0.5百分之50概率转发到KUBE-SEP-HMSXX67,剩下的转发到另外一个

两个pod,多了DNAT,转发到pod上
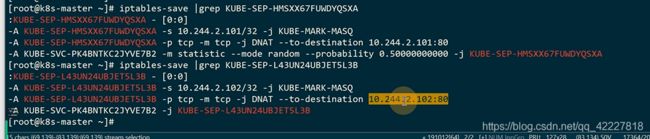
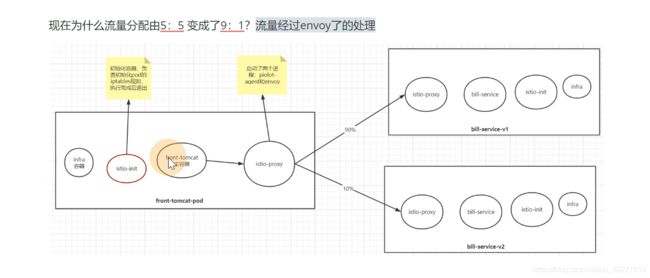
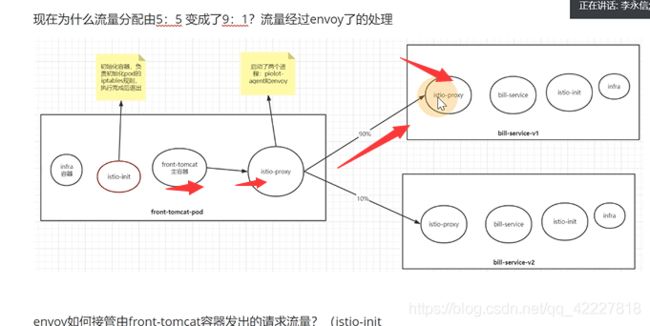
coredns维护的规则,你改不了,是希望流量都均分的,但是如果要90,10%就需要istio了

现在每个pod都只有一个容器

现在需要在服务里加上sidecar,inject注入


生成了一堆的yaml文件

![]()
注入后的yaml,前面都没变
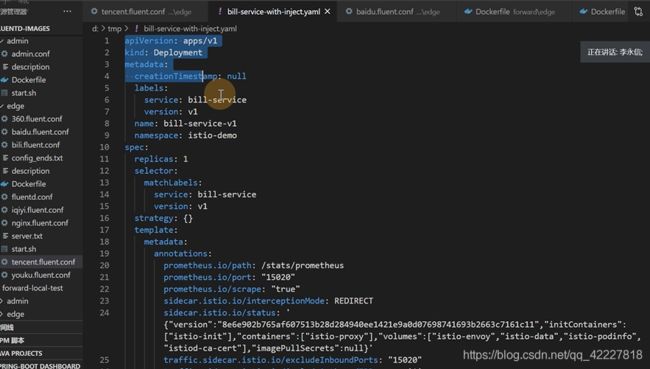
影响功能的在spec里

这是一部分
从这里开头

到这里

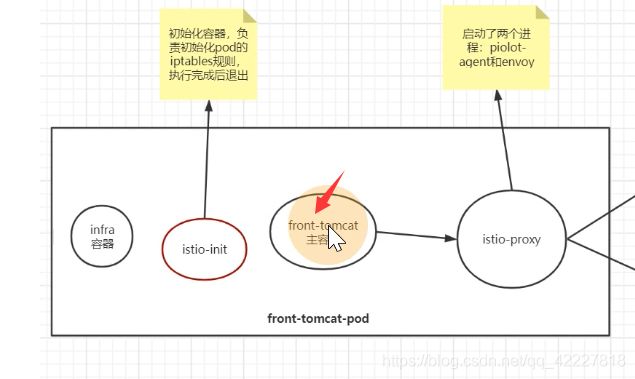
额外加了istio-proxy名字的容器,也就是所谓的边车容器

还加了一个初始化的容器,执行了一些命令,这个容器执行后就退出了,就是做了一些iptable规则
直接部署

在原来的基础上加上了istio的边车容器

前端,和v2版本都注入一下
等于一个小的网格,现在有三个节点


规则怎么写是一个点,流量如何区分两个版本不同
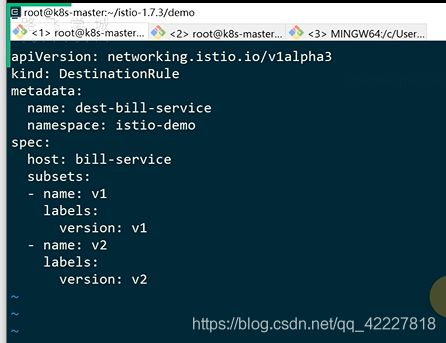
一般定义一个destnation-rule,destnation-rule是区分两组服务的,起个名字,然后命名空间

subset相当于一组,下面定义了一个数组,第一组v1,匹配的是version =v1的,第二组v2

不能匹配所有的v1,v2,是匹配前面的bill-service下的v1,v2

这样就在istio内部,给这两个pod起了名字

下面就要定义转发规则了,定义virtualservice,是用来加规则的
![]()
hosts是bill-service-route,http流量,下面是route路由
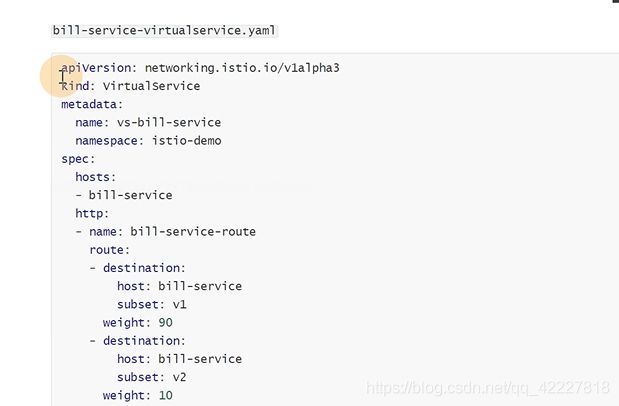
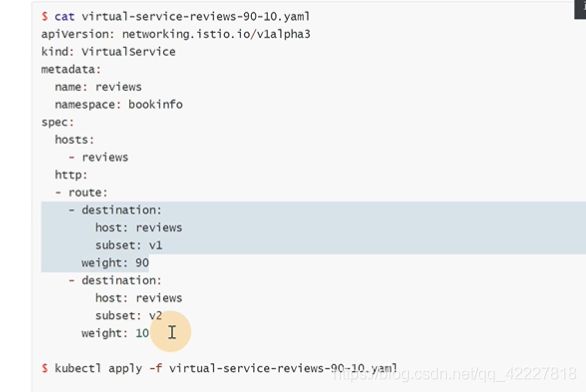
权重90的目的地是bill-service下的v1,权重10放bill-service下的v2

创建好这个规则后,就等于告诉网格内的服务,找bill-service这样的名称的,都会按照这个路由规则走。90%的流量走v1,10%流量走v2
实现一下
![]()

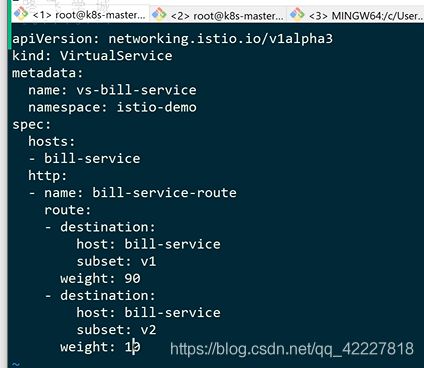
先创建destnation-rule

vs就是virtualservice缩写
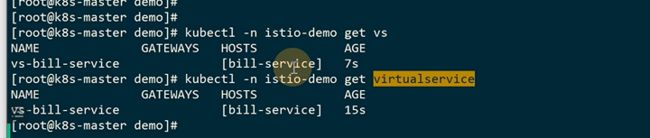


从前端的pod里访问bill-service的服务
一定要选择-c进入到哪个容器里

网格内部去访问bill-service,大概是9比1 的关系
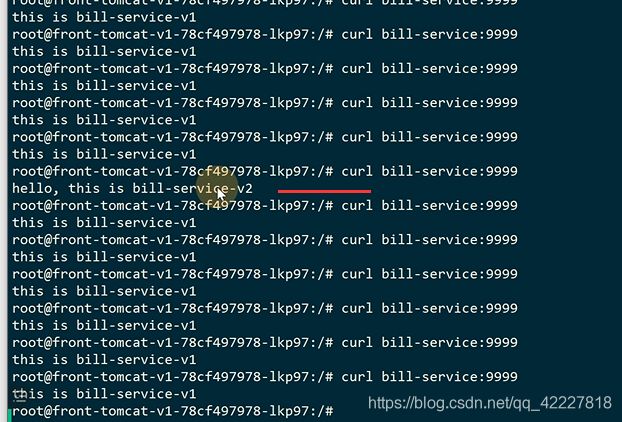

理解envoy
9比1的规则是virtualservice定义的

最终影响到这个pod的是十分复杂的

如果是nginx,就是这么配置的


加了两个容器,istio-init,istio-proxy

进入到istio-proxy看一下
![]()
envoy其实是一个代理,轻量级的代理


通过K8S的api创建一个service,存储到ETCD里

istiod会去watch我们创建的virtualservice规则

每个pod都增加一个envoy,istio容器,istiod感知到用户创建的规则后,由istiod的server端把配置同步到envoy

envoy的配置文件肯定和创建的virtualservice规则是不一样的,格式是不一样的,istiod是做转换用的
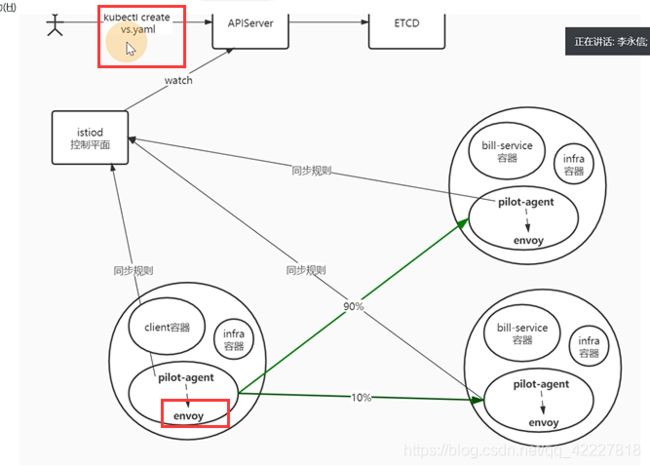
istiod监听到创建的virtualservice规则

大致了解一些envoy



nginx也是代理,envoy也是代理

现在看nginx如何迁移到envoy

上面是nginx配置,下面是envoy配置,nginx的server在envoy里叫监听器

location就是路由

在envoy里叫过滤器

最核心的这个,可以过滤http请求,把一些包转换成http的格式

、流量到了filter后,经过route_config,后面有一些匹配条件

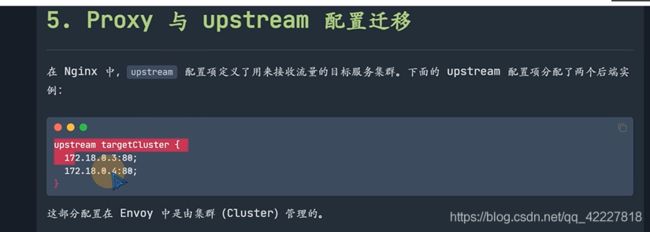
proxy和upstream对应envoy的集群
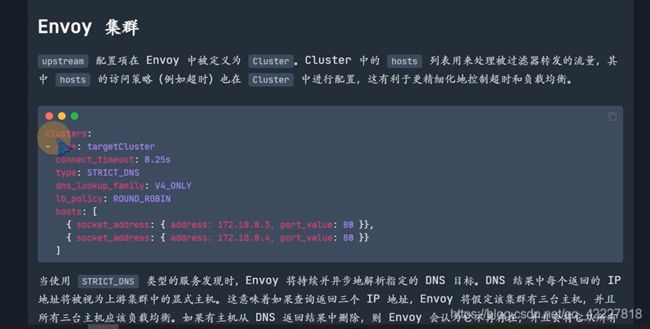
![]()
也就是nginx的配置都可以转换成envoy的配置,envoy里有一些概念

转发后的envoy配置文件如下

envoy会启动一个端口,作为管理端口


后面都是envoy的配置
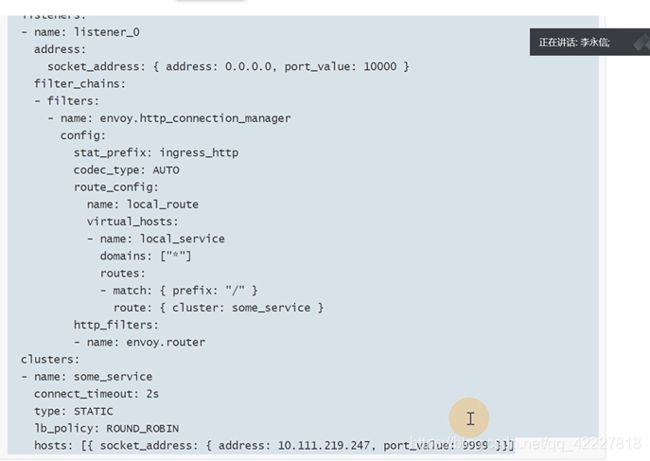
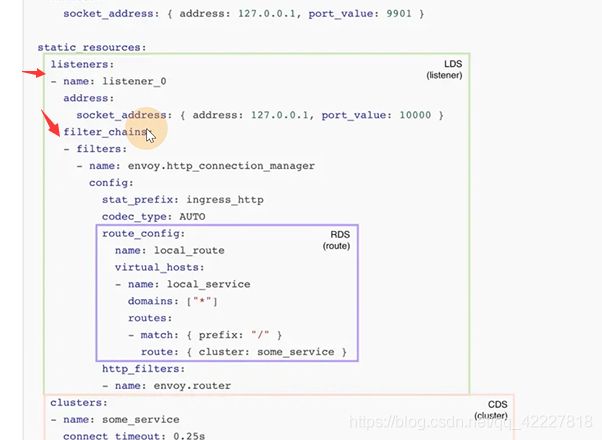
起了一个监听器listener_0,监听本地10000端口

获取的流量交给filter_chains来处理
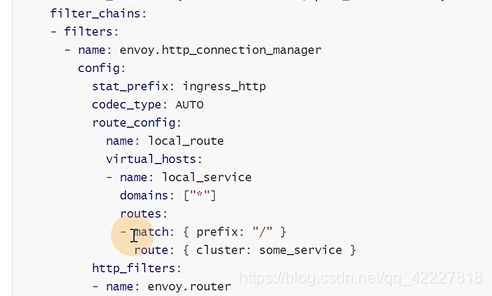
匹配斜杠做一个路由,转发到some_service这样一个cluster集群上去,类似nginx的upstream

service是什么,是下面clusters定义的


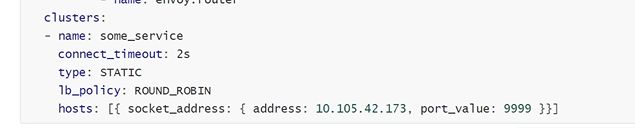
启动envoy1.15.2的版本,这个yaml文件放到容器里/etc/envoy/envoy.yaml

期望转到service的cluster-ip是10.105.42.173




envoy就是个代理

核心的概念,就是监听器

filter_chains里有http_connection_manager,处理http流量,匹配路由规则,转发到cluster上去

 、
、
配置云上ELB,SLB,也是要配置监听器,加上路由转发规则
envoy核心的概念XDS

、静态配置就是yaml文件,动态配置就是可以通过接口从别的地方动态获取到了
![]()
监听器其实是可以动态的,L(listener)D(discover)S(service),

还有一个配置是RDS,route的配置也可以动态的,不用写死
CDS也是可以动态的

EDS也可以动态

LDS,RDS,CDS,EDS统称为XDS,X代表变量,这些就是envoy适合云环境下的特性,所有环境都是不固定的,信息是存到etcd里去的


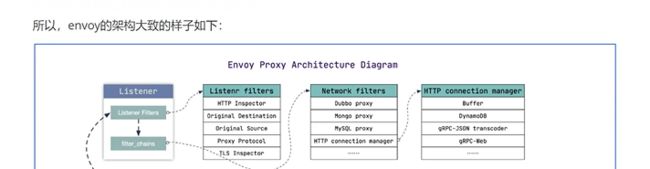
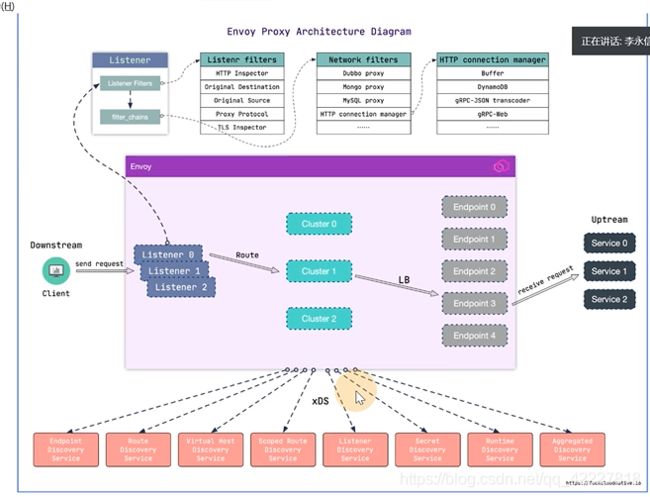
**最核心的就是listener,cluster,route,endpoint,也就是lds,cds,rds。eds
**
全都是通过xds接口去获取的,envoy可以动态获取配置来提供服务

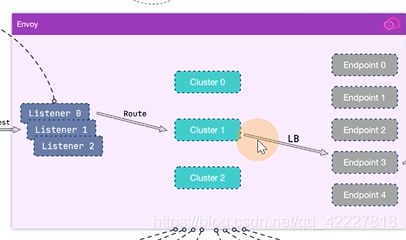
从client发起流量,发到listener之上,经过lds,cds,eds,就会知道让请求访问哪个endpoint地址,然后最终到真正提供服务的机器上去
下面是listener替换的部分,listener filter是改一些元数据的(可以不去看),监听器里有filter_chains

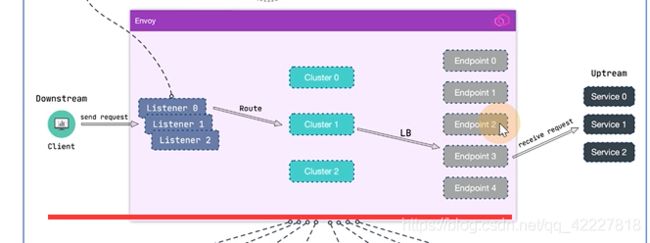
使用envoy的,就是有请求,通过监听器,通过route转发给cluster,最终把请求转发给提供服务的机器上去,配置不仅仅可以是静态还可以是动态的,xds可以满足
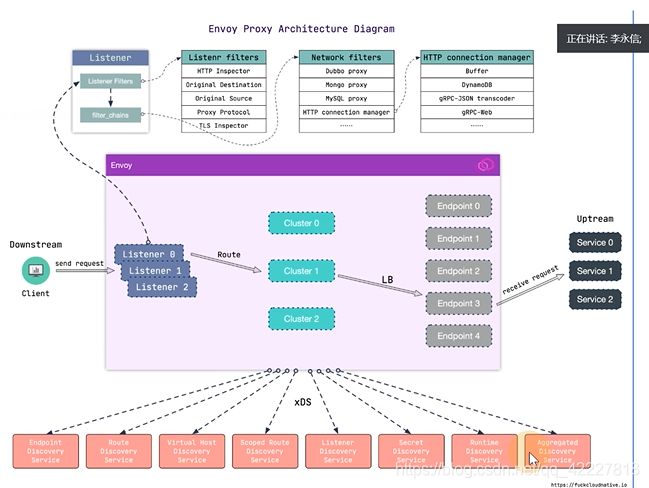

envoy其实就是一个代理
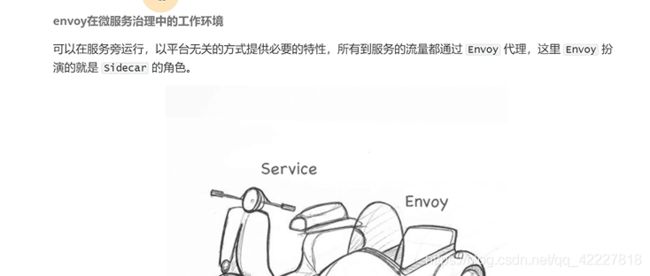
对于K8S来讲,envoy就是istio-proxy容器里的进程,可以监控流量,可以进行熔断,追溯

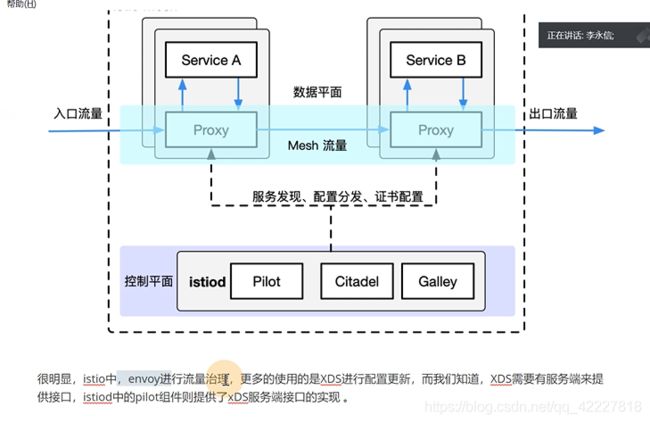
envoy只是一种能力,你需要服务端才能去提供接口告诉envoy,可以通过着接口获取什么数据,istio里的pilot转眼间就提供了xds服务端接口的实现。


里面有一个pilot-discover服务,这个进程其实就提供了envoy服务所需要的xds服务接口,也就是xds的服务端

工作原理

看看问题1,envoy的动态配置长什么样子

这个就是envoy、的管理端口
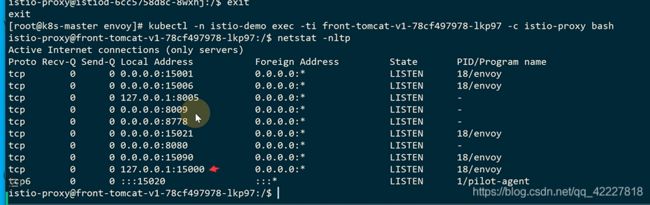
envoy需要一个配置文件

有一段管理配置,监听端口和地址

访问端口其实可以获取一些内容

envoy的信息可以从这里获取

下载envoy的配置
![]()
![]()
这个配置文件非常长

700多KB的配置
几个大点最主要的配置

这一个内容就比较复杂
![]()
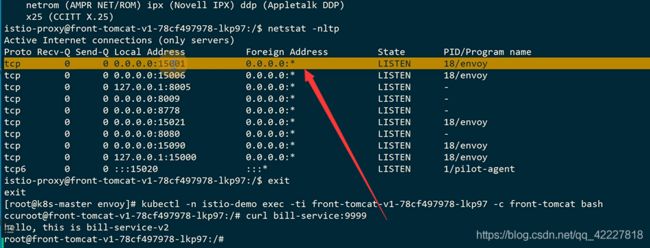
现在在网格内部,没注入istio,是先解析bill-serviceip地址,路由到主机上,访问9999端口

注入之后就是这么走的了

如果是在前端tomcat访问的,流量会转到istio-proxy这个容器里,它去把流量转发到不同版本的服务

istio-init就是去修改iptables规则

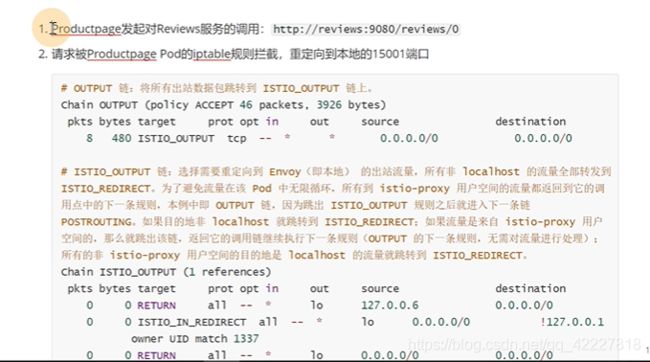
iptables,4表5链

流量进去prerouting链,是input链还是forward链看是否是本机地址,
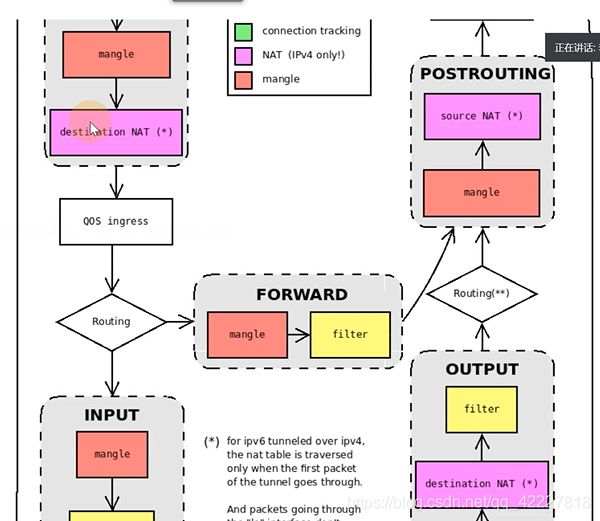
本机的流量会到本机的堆栈,然后转发到output链,转到postrouting链
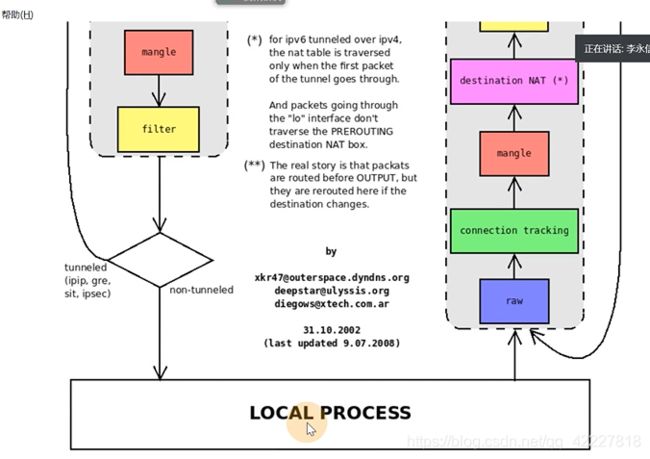
istio-proxy如果要进行流量的管理,一定要拦截tomcat的流量,也就是istio-proxy在自己的postrouting加个规则就可以拦截请求了,如何去拦截请求就是istio-init要做的,初始化iptables规则
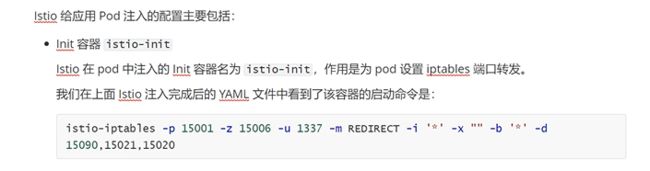

istio做了一次iptables的封装
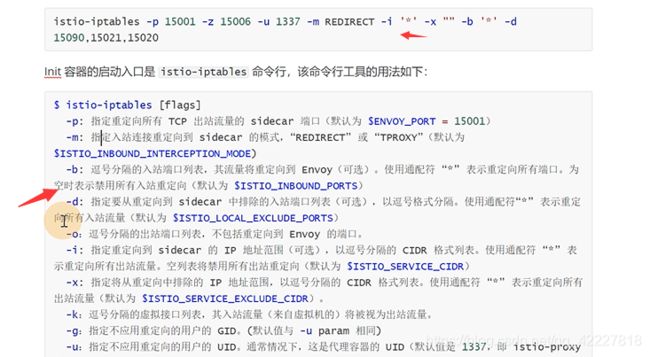

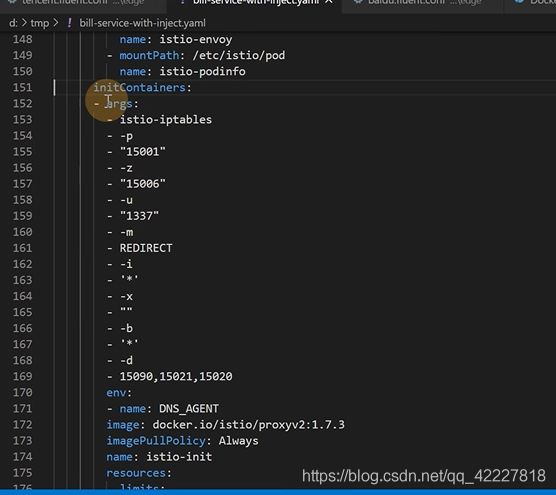
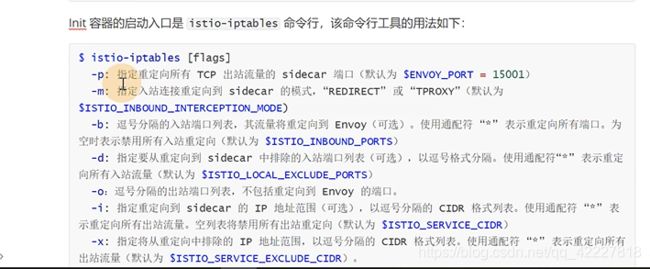
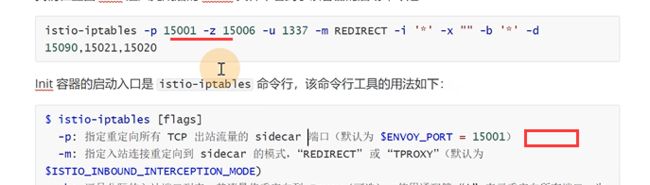
-p是重定向所有tcp出站流量,也就是所有的出站流量转发到15001上,-z所有进入pod/vm的tcp流量应该被重定向到的端口(默认$INBOUND_CAPTURE_PORT)
 拦截了所有的出站和入站
拦截了所有的出站和入站
最后就放了一个,有一个uid,这个用户,优化自己的请求,放到15090,15021,15020的端口i上,除此之外所有请求拦截

现在id是0,发起请求

一定会被拦截到,因为不符合条件,不符合uid是1337发起的,也不是访问的15090,15021,15020,所以istio会进行拦截

上面的这条规则其实就是下面的描述,15090是做prometheus的telemetry,15020是做ingress,15021是做监控检查的


如果拦截了,就等于自己拦截自己的,进入死循环了

**istio-init就是初始化iptable规则,让istio-proxy这个容器拦截出站入站流量
**



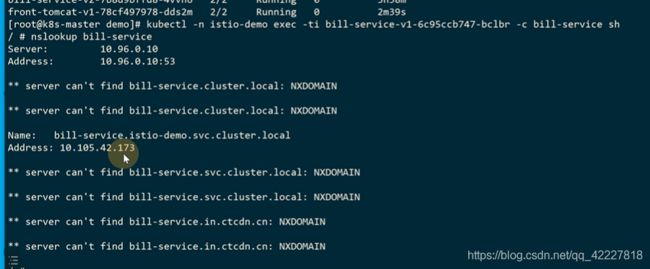
可以看istio-proxy里的规则,在slava1上

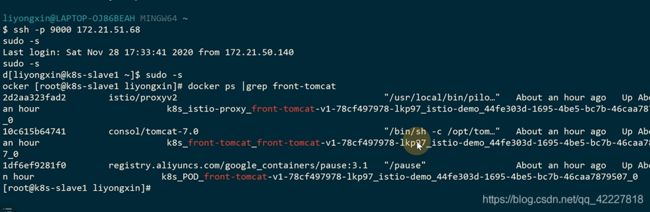
找到这个进程对应的pid

iptables规则是在pod设置的,是有独立的网络空间的

可以进入到网络空间,查看规则

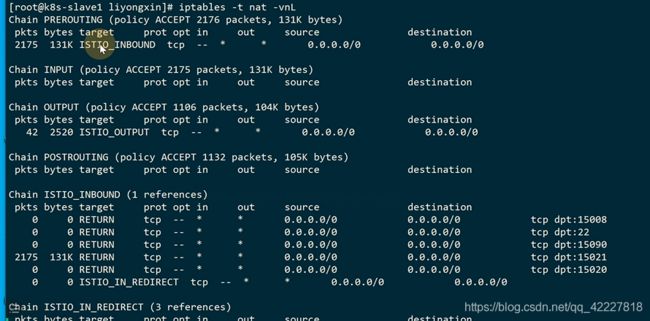
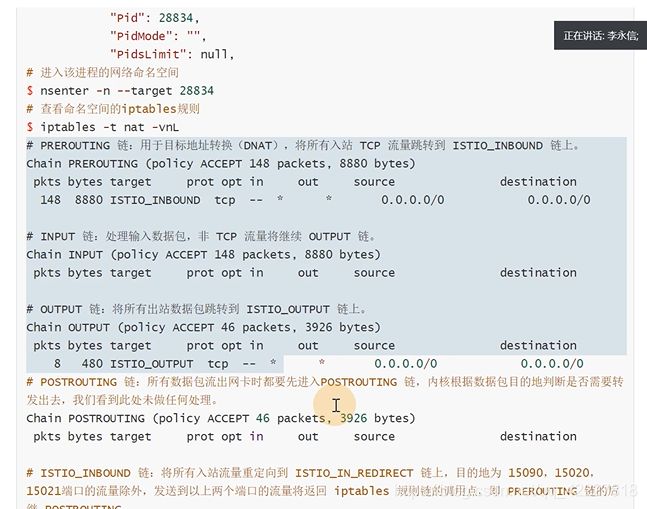
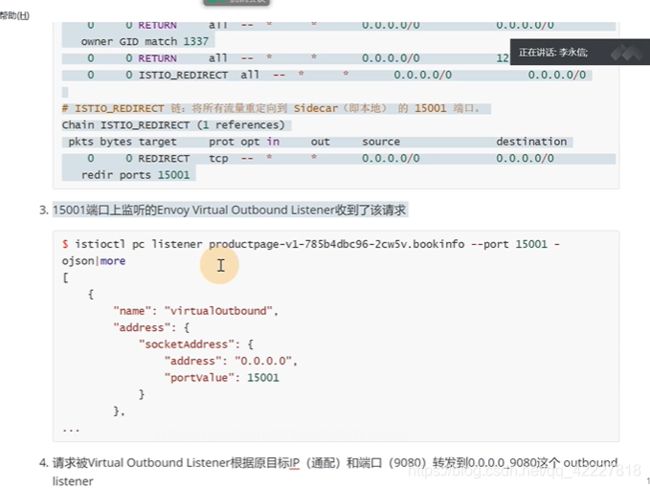
prerouting是来入栈的。转到了15006
![]()
tcp规则,转到了istio_inbound规则,所有入站tcp流量跳转到istio_inbound上

除了这几个端口之外的,剩下的都转到了istio_in_redirect里
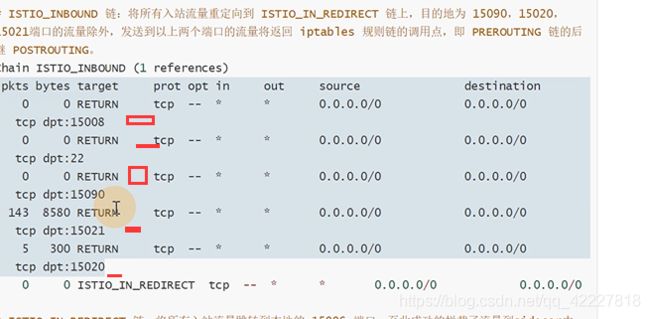 这里是-d生成的
这里是-d生成的

排除了不是业务的流量,都转到15006端口,envoy只需要监听15006端口,拿到这个入站流量

-p是出站流量
所有出站流量转发到了istio_output

这样就拦截了每个pod的流量
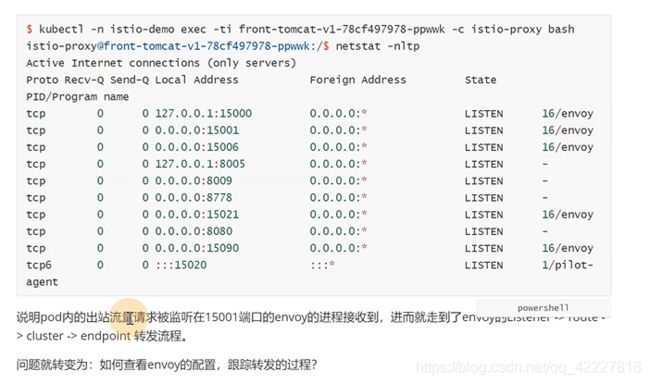
15001是拦截所有出站的。15006是拦截所有入站的
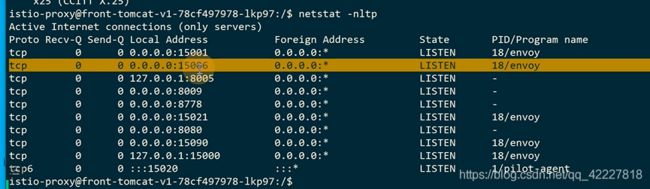
业务的流量直接被转到了istio-proxy,经过处理,发送到业务端,业务端istio-proxy监听的是15006(接收所有入站)

是被15001拦截到了,如何转发,envoy有监听器,filter_chains

这个命令可以只拿到关心的片段

出站是15001拦截的,(两个端口15006,15001)

在front-tomcat发请求,在istio-proxy被拦截,就要到istio-proxy查看这个pod的监听器


全部的太长了,很难找

例子,可以查看端口

有一个15001的,这里是一个缩写

出现了一个15001的监听器,但是没有做处理

使用原始的IP地址和端口
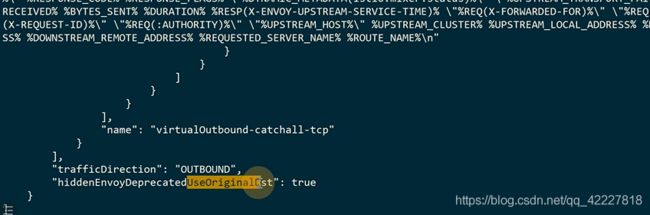
对流量只是做了通过,并没有做其他处理


这个请求其实是被15001拦截到了

流量只是做了passthroughcluster处理

15001不处理,转给了服务本身的9999端口

正常里面会有下面的一个监听器

查看监听器的样子

rds是动态的路由,监听器转到了9999route上去了
名字就叫9999

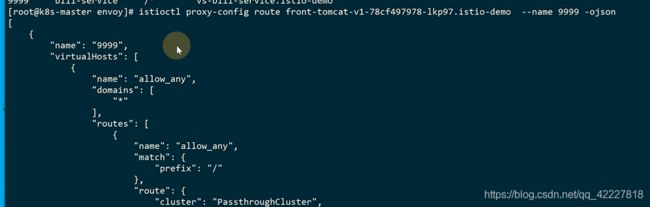
这一项看起就是,匹配所有转发到passthroughcluster,但是我们的请求现在不会到这,还有一个比这个更匹配的
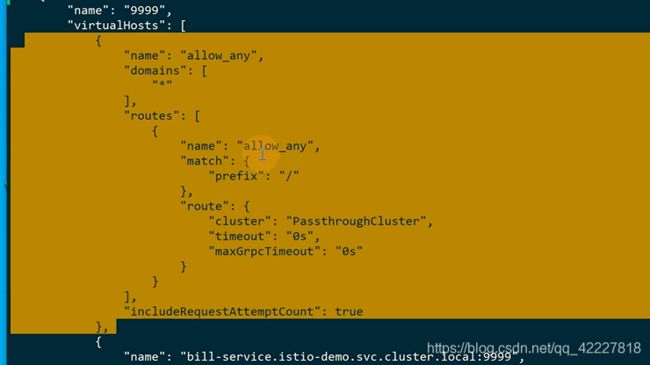
上面匹配的是,只有找不到下面的时候才会去找上面*
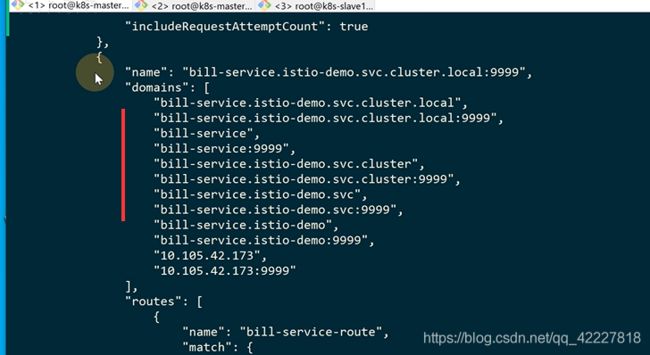
如果没有*号,就无法访问外网了,所以一定要加个放行的

prefix,匹配前缀

这里的规则都转换成了istio的规则

weightedcluster基于权重的cluster
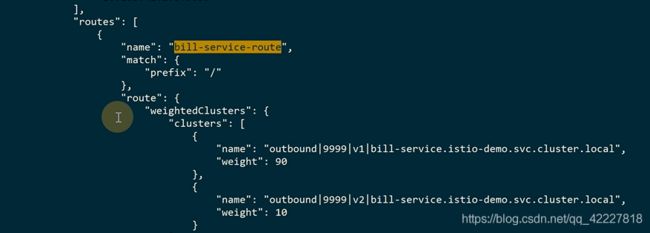
要查这两个名称的cluster

cluster提供了一个fqdn帮你去查

现在查endpoint,不知道怎么查可以-h,查看帮助


v1是90%流量的

port 80端口

104是v2

lds(listener),rds(route),cds(clsuter)eds(endpoint)
先查linstener转route,通过route找cluster
流量被istio-proxt的15001监听到,15001并不做处理,直接转发给原始的ip+端口,监听到9999端口的流量才转发给9999端口的服务,就转发到了cluster
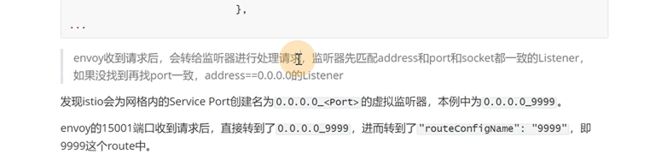


找到endpoint的地址以后,等于从istio-proxy内部,envoy curl这个地址



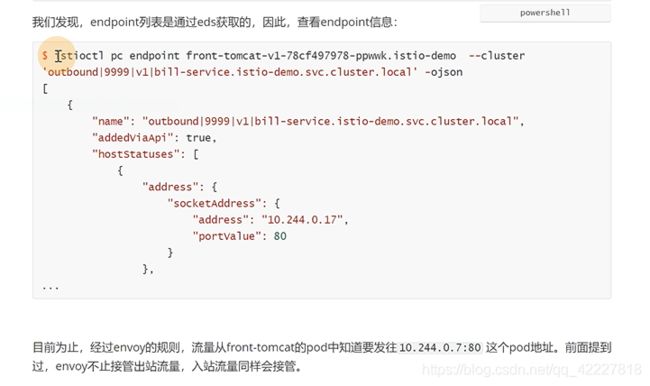
但是发起请求后,怎么到pod,还需要走网络,是一个pod的ip地址,在flannel网络可以看到路由
这里的istio-proxy是在prerouting链上做了拦截,最终由direct转到15006

15006要先查监听器,-h帮助,查是–port

转换成json
![]()
inbound入站请求

入站直接交给15006处理


15006这里有入站监听器,这个监听器是按端口匹配的
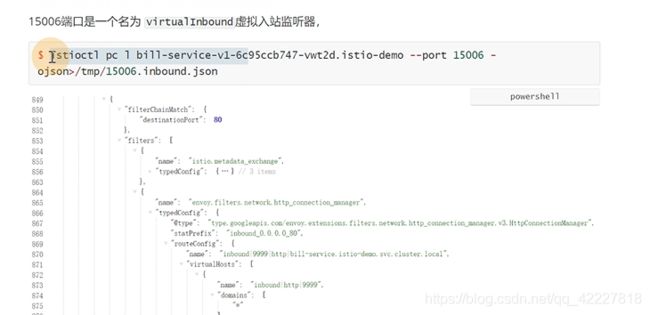
也有一个route,处理都交给匹配的cluster后面对应的endpoint




匹配80,转到route上去了

转到本机的来提供服务

创建了一些virtualservice规则,被istiod 识别到,最终转变成了envoy能够识别的配置片段,然后通过istiod的server端。同步到了service端,才能使流量的方向发生变化。envoy的配置片段可以通过 istio config-dump查看,可以查看route,cluster,endpoint
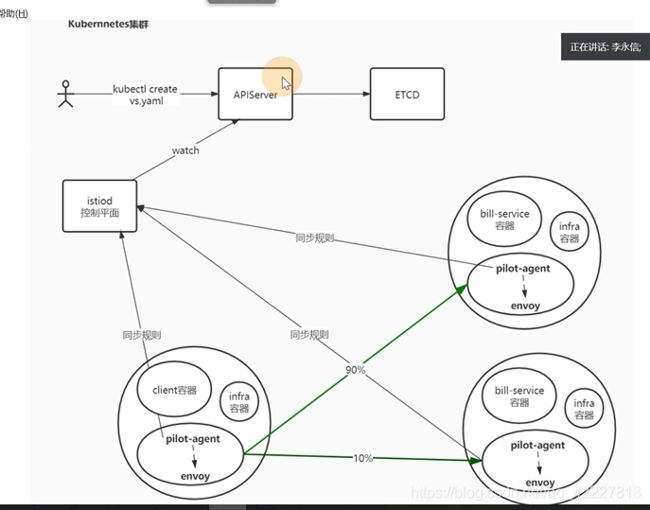
envoy小知识
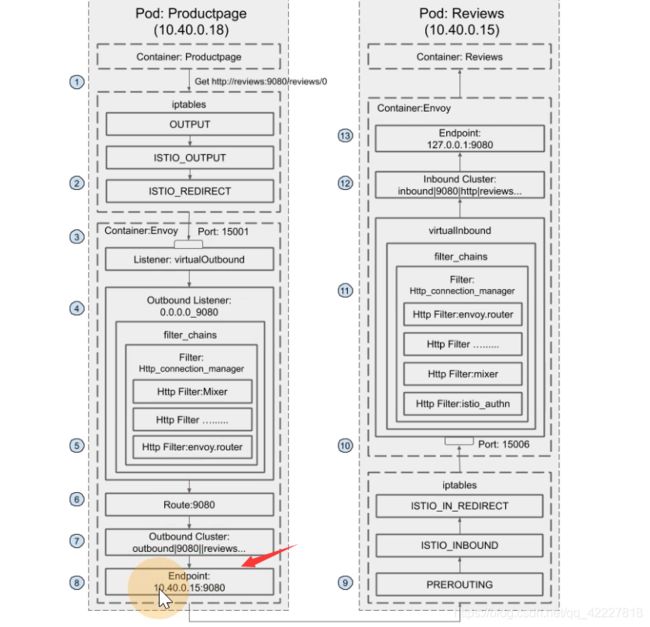
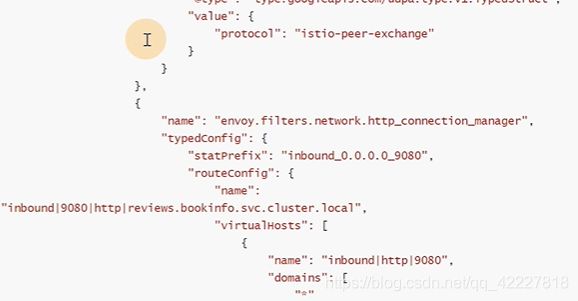
意思是这两个pod进行访问,pod里有两个容器,提供服务的容器,以及envoy容器,从productpage这个容器去curl review:9080,然后流量先到达iptable,(注入的时候,通过初始化容器,有iptable配置),有个配置output链上转发到了istio_output,转到了istio_redirect。通过15001(这个端口是被envoy监听的,virtualoutbound ,这是一个listener,)转发到一个orginal的监听器上,匹配到0.0.0.0_9080,经过filter_chains,开始做处理,转到一个route上,找到一个endpoint ip+端口。
转到后端的pod,(后端的envoy监听在prerouting链上,转到istio_in_redirect链上),15006端口进行处理,找到inbound cluster来进行处理

具体的流程还是要istioctl pc来查


到tomcat容器去curl
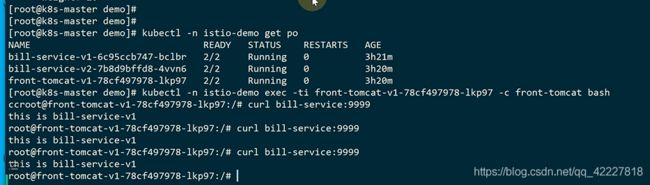
在istio-proxy容器里没有按照91的比例走
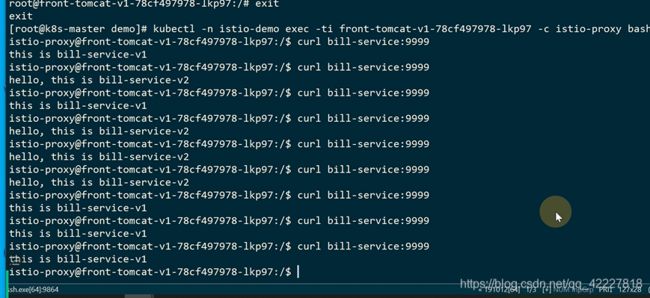
因为这个uid是1337,这个1337的请求并不会被iptable拦截,不拦截就不会到自己的里面去做处理,不走envoy就等于在网格外部一样

**它走的还是宿主机上的kube-proxy维护的iptable的网络过程,走到宿主机上,宿主机依靠flannel做的iptable转发走了
**



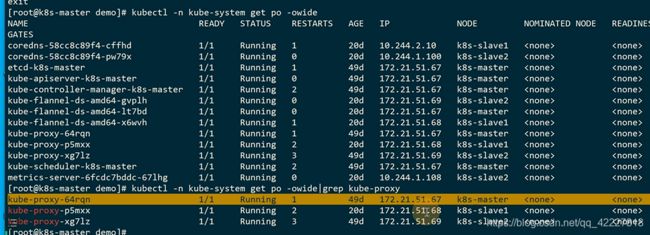
把着几个kube-proxy干掉,是否会受影响,但是用scale是不行的

可以这么看,看yaml

这里有一个标签

![]()

这样一个没有,就自动退出了
 清理一下nat
清理一下nat

没有这个规则了
这样按照刚才的理论,在istio网格内部就访问不到宿主机了,是直接iistio envoy去拦截了这个流量


真正去访问的时候其实是pod的IP
清空slave1上的iptable规则


还是可以访问的

master再去清理一下

现在在容器的istio-proxy里

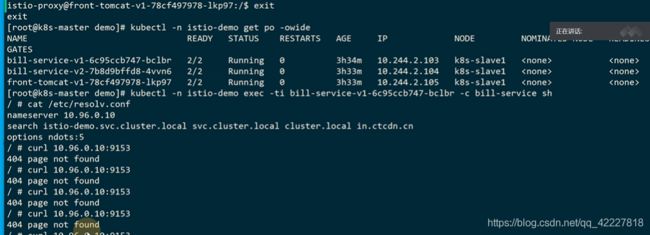
现在把kube-proxy已经停止了,宿主机上的iptable规则已经删除了cluster规则
删除一个pod试试

到外网链接一下

刚才没删除之前应该有解析的缓存

容器内部是可以访问到,解析不了,才到宿主机上,但是宿主机IPtable规则没有,还可以访问到,可能有一点问题
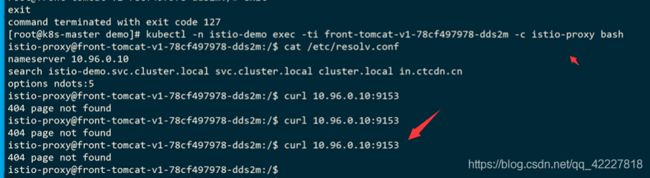


所有的service都创建了虚拟监听器

在pod里去访问服务

正常是可以访问到的,这个访问是走的istio的监听

istio内部,在集群里的每一个service都建立了一个监听器
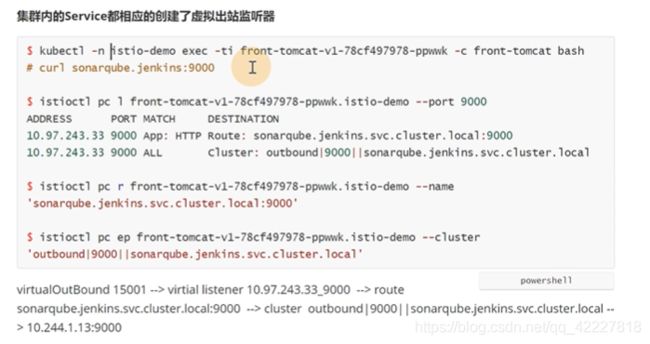
服务网格istio出现之前就有9000端口的service了

下面是service的ip+端口

istio是把整个service,加上istio的manager

最终转到下面的route、
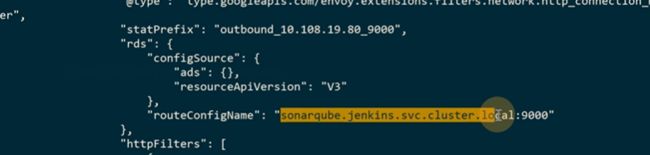
查route可以用r

可以转换成json看一下

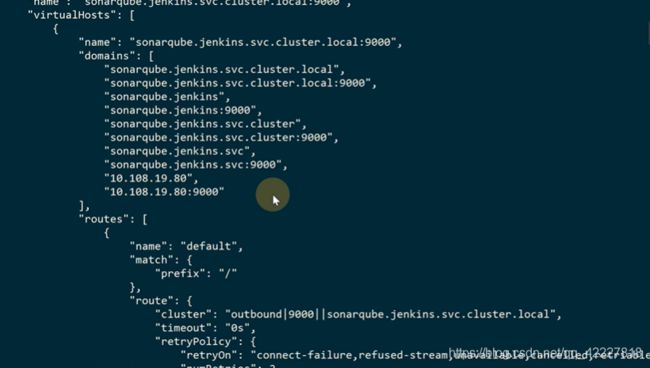
domain。匹配/,转到cluster上去,找到endpoint


这里都是之前的service创建的监听规则,服务越多listner越长,绝大多数都是outbound的一些监听

istio不希望再去用kube-proxy,直接可以在网格内部去管理iptable规则,控制流量

只要是在网格里面都有
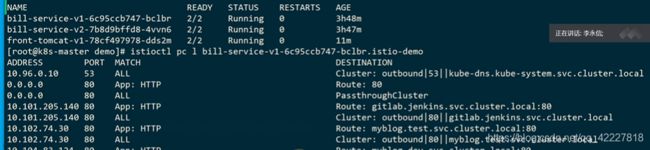
因为istio本身并不知道你这个pod需要去访问哪个服务
这些都是动态维护的,envoy的配置有静态动态,动态的都是根据istiod这个服务
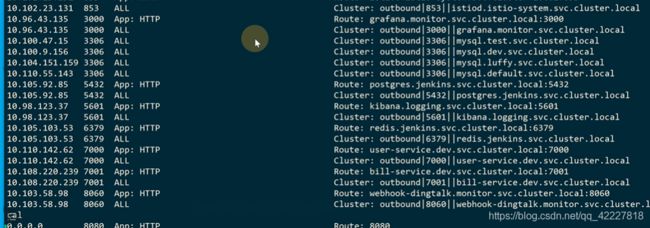
这是一个istio的动态的服务端,是gRPC的服务端

转换成envoy的配置段转发给envoy

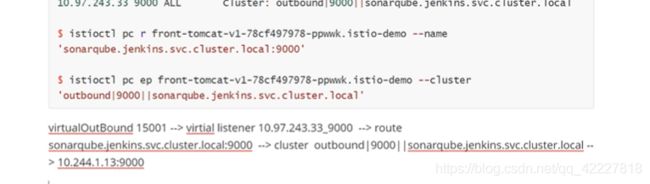
使用ingress-gateway访问网格服务
现在是这样的场景,用户端90%流量去访问v1版本, 10%流量去访问v2版本,实现这样的,就是去创建一个v2版本的pod,同时建立virtualservice虚拟服务去实现
selector是app:front-tomcat

下面是deployment文件

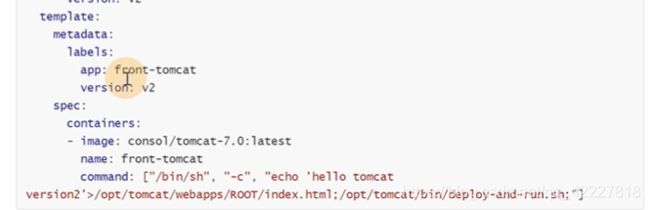
app是front-tomcat会被之前的调用到,版本v2
需要做的就是创建虚拟服务,通过front-tomcat在istio网格内部去访问到hosts。front-tomcat流量都经过它去匹配,根据route的配置进行转发,90到v1,10到v2
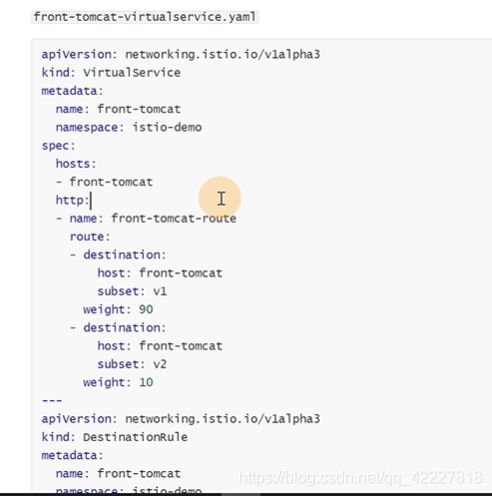
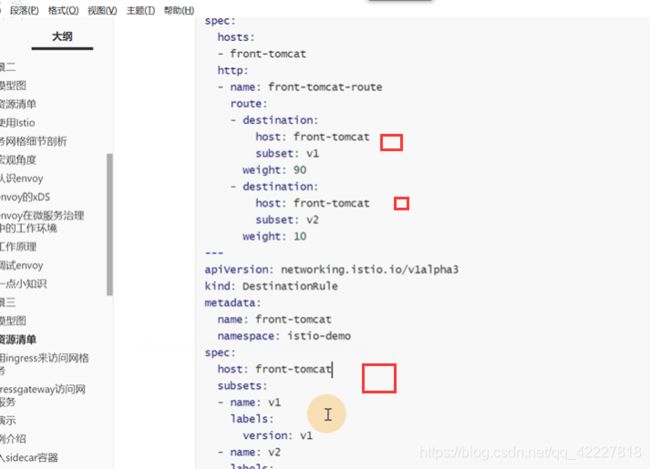
如何区分不同的机器组就是去创建destinationRule,destinationRule其实就是一组cluster


重点是host
 先启动v2的deployment和service,和上下文的规则
先启动v2的deployment和service,和上下文的规则

这是创建的virtualservice

![]()

需要注入istio

这里是1没有注入

不注入的话从前端访问,待会从前端去访问,通过ingress去访问,就没办法在网格内部


现在访问8080应该是9比1 的流量

现在可以从界面上去访问服务



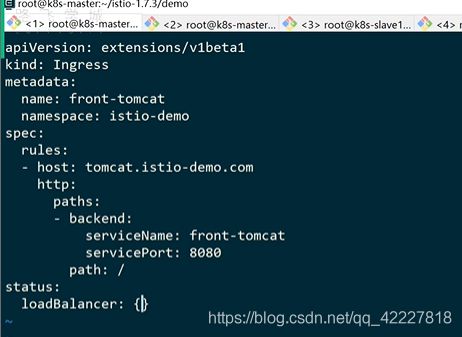
![]()
现在访问的ingress是走的它的上面

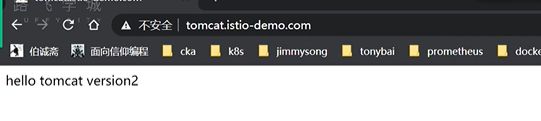
现在是1比1,没有按照istiod的规则来走
通过ingress去访问的话,不会按照istiod的规则去访问
因为istio里面去访问

现在是在宿主机上去访问不是在网格内部,注入的istio-proxy容器里是网格内部,现在宿主机走的是网格外部,走的是kube-proxy的iptable
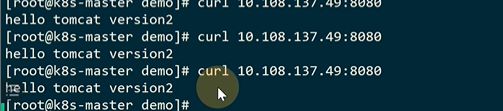
前端页面也是走的ingress,没有走istio,就没有意义,现在要在前端也走istio而不是kube-proxy

ingress只能简单的引流外部的http流量,这里的目的就是凸显了ingress的局限性

就需要用到ingressgateway
![]()
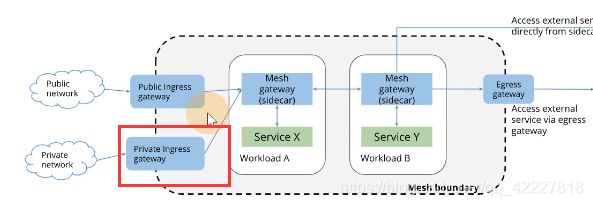
mesh boundary是网格内部,外部流量如果想要进入网格内部的一些规则。需要通过ingress gateway组件,引入到mesh gateway也就是sidecar。同样的流量出去,istio内部要去访问网格外部需要通过egress gateway,但是不是必须的,类似curl 百度,直接就可以curl,管理不了抽象的流量

又说了ingress坏话,只支持http的流量。任何高级功能对于ingress来讲实现起来都很麻烦(因为需要重新功能,还不能在同一个ingress里)

现在外部访问还是轮询1比1访问内部

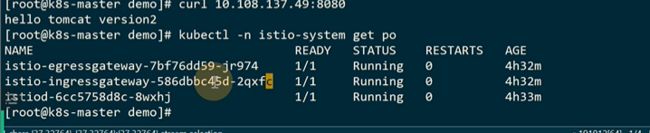
一个集群内部,ingressgateway可以有多个

要去找ingressgateway的

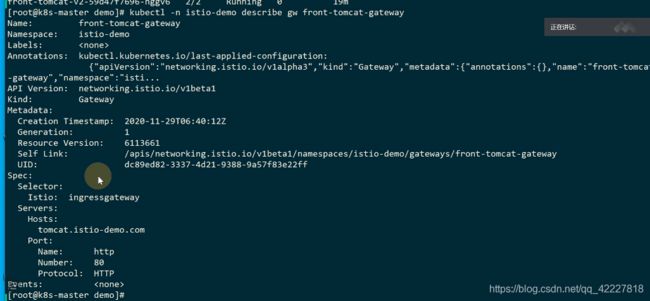
有这样istio=ingressgateway这样的一个label
这个规则就是,定义了这样一个gateway,是由带istio=ingressgateway的这样一个label的pod来处理,ingressgateway有多个,这样就可以在集群里指定找哪个ingressgateway来处理请求

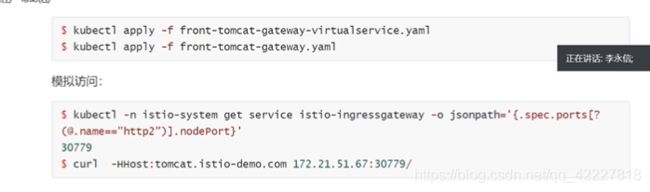
**创建上面这样的资源在K8S里的时候,就等于在istio的ingress网关上加了一条规则,这条规则就是允许tomcat.istio-demo.com的http流量进入到网格内部,通过带有istio=ingressgateway的网关来去处理,也就是tomcat.istio-demo.com的流量转到下面的pod是可以被接收的,也就是按照istio的规则去处理
**
添加一个Gateway(kind),允许hosts的http流量,从网格外部流入




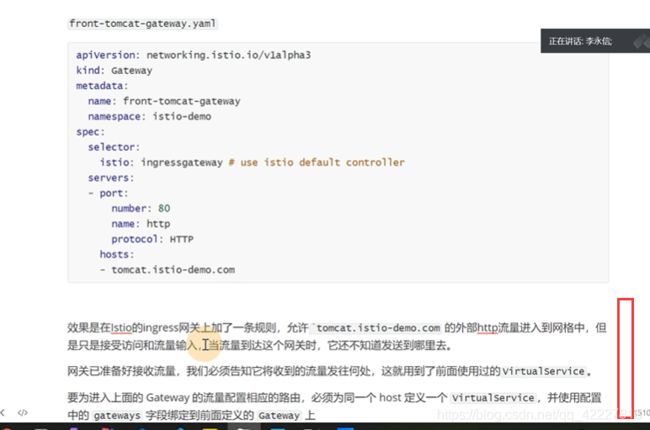
只是允许流量进来后,发送到哪里,需要前面定义的virtualservice,virtualserivice可以和网关一起使用

和前面建立的virtualservice唯一的区别就是,指定好了网关,先创建了一个允许tomcat.istio-demo.com流量进来的网关,下面创建的virtualservice绑定了这个网关,进来的流量就按照路由去匹配,90%匹配到front-tomcat,10%front-tomcat,和之前的virtualservice唯一的区别就是加了gateway绑定,也就是只有gateway来的流量才适用于这个规则,之前没有绑定gateway,意思就是在整个网格内部都会受影响,按照这个规则去走
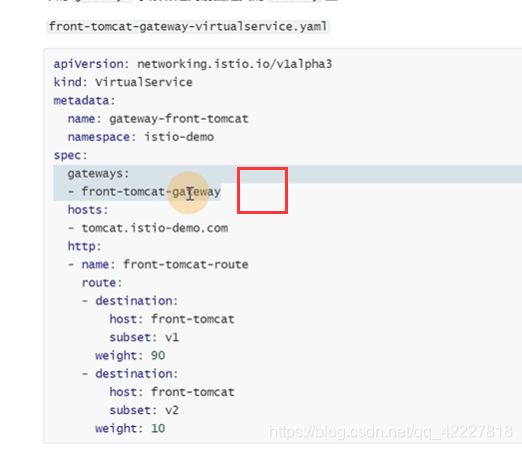
gateway没有就是一个通用的规则,也就是在istio网格内部去访问【front-tomcat】,就会按照这个virtualservice去走

![]()
现在让外部流量进来,就做了gateway的规则
tomcat.istio-demo.com的http流量可以进入ingress gateway来处理

下面的virtualservice绑定gateway


只有从这个我网关过来的流量才能进入这个规则,其他外部请求会被拒绝

现在网关已经创建出来了

创建规则
![]()

这个virtualservice只给front-tomcat-gateway用

只有gateway过来的流量才会应用这条规则

如果是从其他pod发出的请求不从front-tomcat-gateway网关过来,就不会受上面规则的影响

只要这个域名的流量转到ingressgateway上去了
转到这个pod上去了

现在请求这个域名要想让ingressgateway来处理


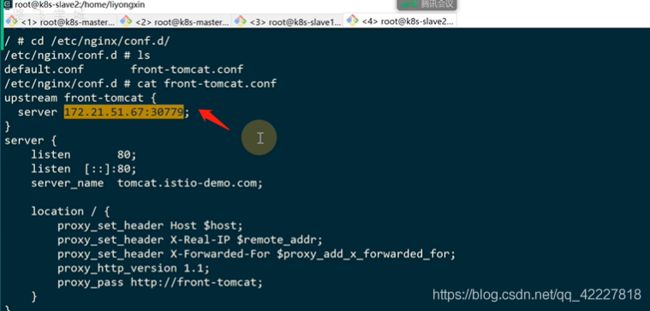
loadbalancer创建了很多port。,3079指向了80

-oyaml

这里有一个http的port
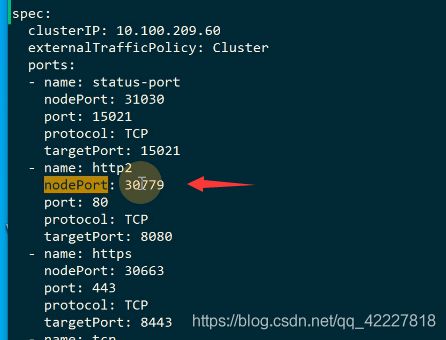
获取端口用这个命令


![]()
现在是9比1的关系
-H 域名 地址+端口

ingress gateway服务就是这个地址

加上解析

加上端口就可以访问,90%的流量在v1,10%的流量在v2

但是访问80端口。还是1比1
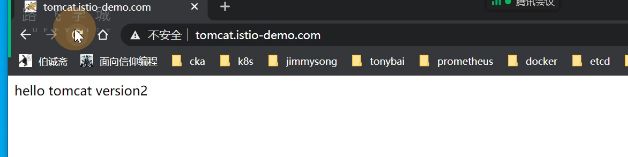
现在访问30779其实就是访问istio内部的提供的ingressgateway处理请求

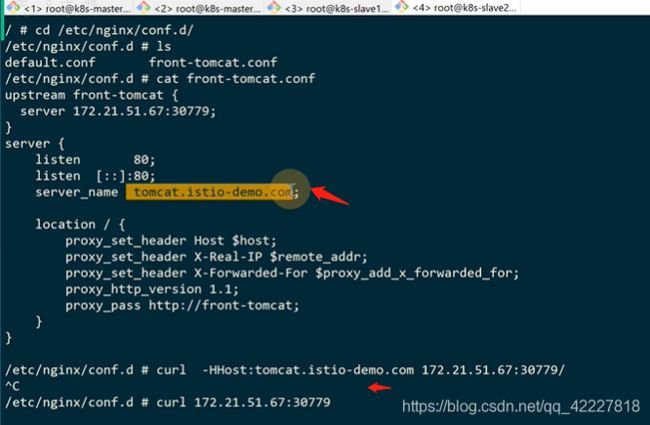
但是这个端口就不好看,可以找个nginx代理,或者找个云服务的lb,clb,elb都行




创建一个镜像

换个地址解析


gateway只选择这个域名

这样访问就进不去

通过域名就可以

监听域名,代理1.1版本
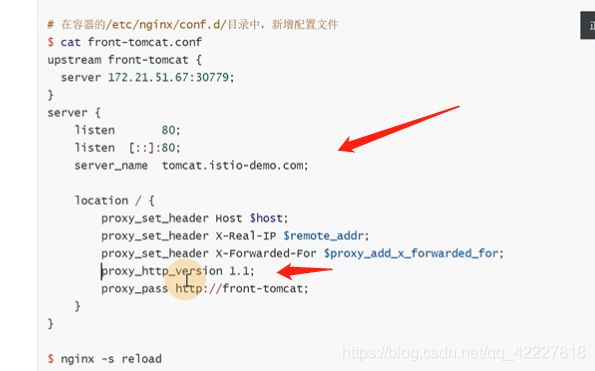



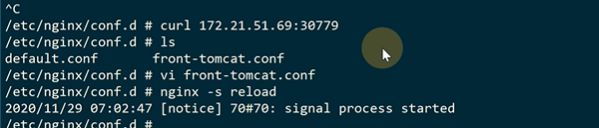
现在外部可以访问,但是nginx容器里访问不通
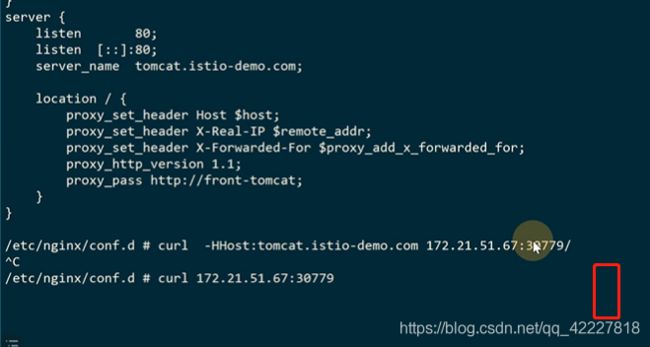
改成69,也就是本机宿主机


现在就可以了,9比1
前面加上nginx,发生问题也可以方便追踪,但是现实也是最起码买个云的LB去代理
流量路由
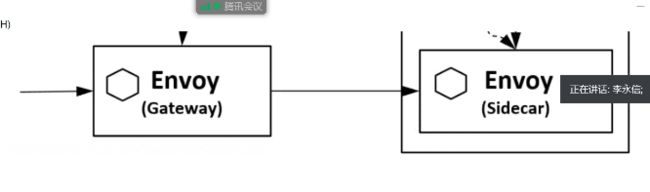
外部流量进来,简单来说,其实在istio网格内部,不用ingress了改成了ingressgateway,原来给ingress-controller流量都传给了ingressgateway
先转到nginx来进行反代,因为之前加的ingressgateway允许这个域名的http服务,来使用这个ingress
服务到这个ingress之后
创建了virtualservice,绑定到了gateway上去,进一步去匹配virtualservice规则

现在看一个新的实例,这是一个书店

创建一个名称空间



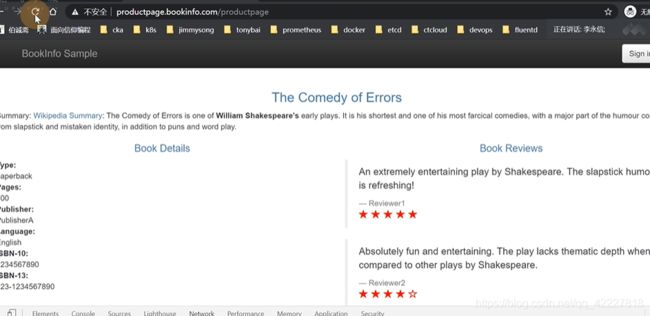
productpage相当于前端一个应用,这个应用会访问后面的reviews服务(v1版本不会去调用rating服务,v2,v3会调用ratings服务)和details服务

给product page创建一个ingress



都是9080端口
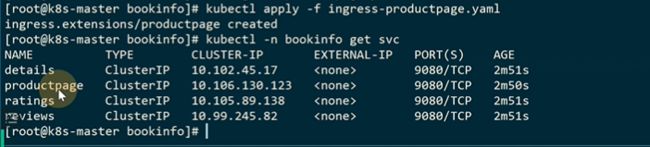
现在可以现在外部直接用K8S原来的ingress访问


访问product page页面的时候,detail和review是的服务

review本身还会去调用rating服务
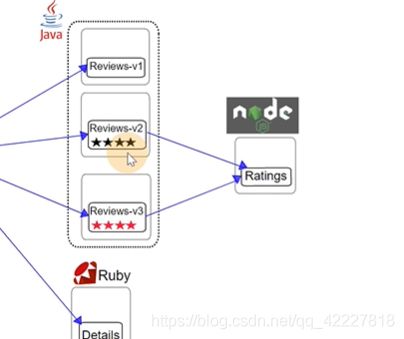
连续访问productpage,review会在三个版本之间随机的


**想要实现流量管控就需要放到istio里去,需要注入sidecar
**
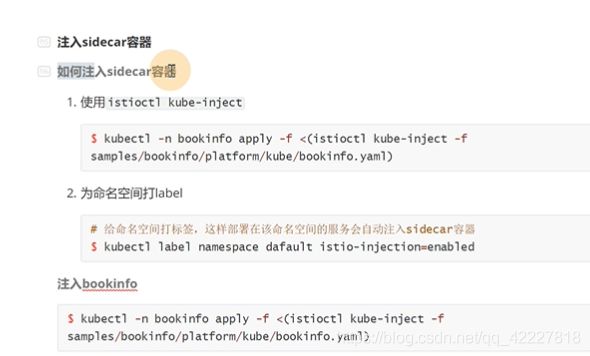
先用istioctl kube-inject 注入指定的yaml,然后kubectl再去apply。这种方式是在名称空间里,给指定的pod去注入。(也就是可以有已经在istio的服务,也可以有不在istio的服务)
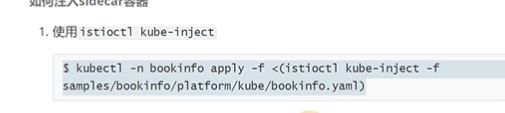
还有一种方式是这样的,给命名空间打label。比如在default名称空间打了一个istio-injection=enabled,那以后只要在default里部署服务,都会帮你注入

现在还是按pod注入


现在变成1/2就代表注入了,原来是1/1
 这个就代表envoy,每个pod都注入一个envoy
这个就代表envoy,每个pod都注入一个envoy

外部用ingressenvoy去访问

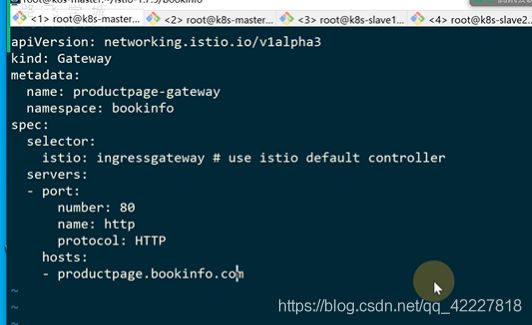
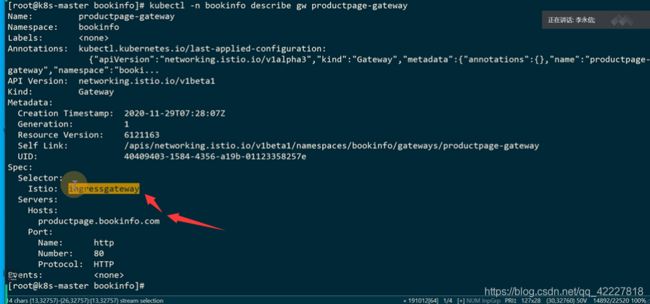
建立一个gateway,这个gateway还是用指定的ingressgateway
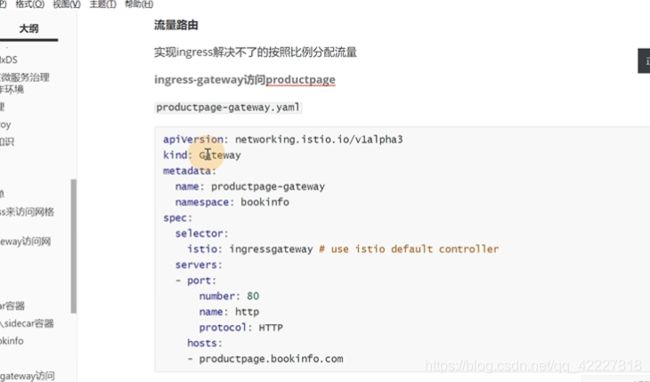

productpage-gateway,让productpage.bookinfo域名的流量进入网格内部
![]()
![]()



现在是建立了一个gw

这个域名进入网格内部
建立virtualservice,绑定这个gateway




现在是有一条规则,允许这个gateway来的流量访问hosts


如果不想review是随机的,想要只看到review3,那就需要在后面加配置

现在是product service去访问了review服务

首先需要建立virtualservice,所有访问reviews的流量都走下面路由
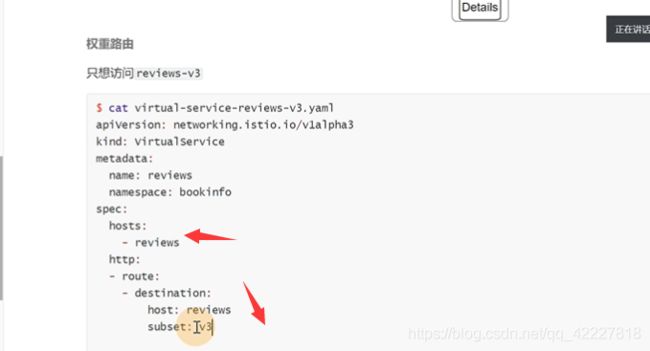
创建一个destination-rule

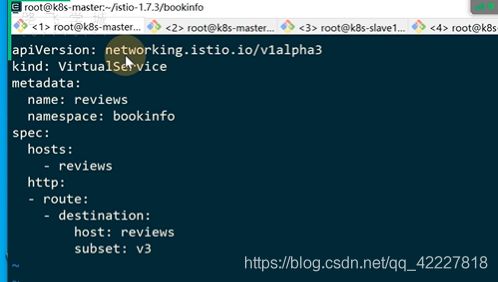
建立vs,访问review服务就转到v3版本
![]()

![]()


reviews是没有gateway的

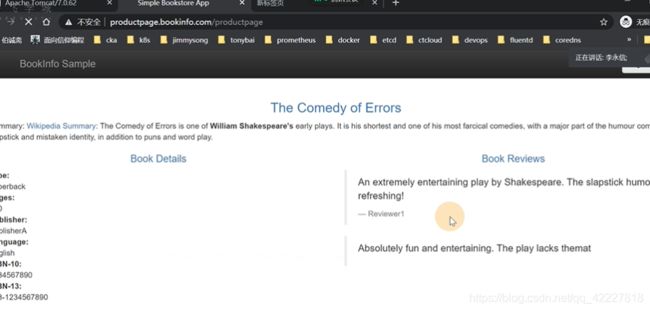
现在刷新就全部是红星的v3版本了




不考虑时效性可以这么做
现在就访问不到v3了

假如v2版本是多个实例会如何调用




envoy的lbs,rds,cds,eds,虽然有三个副本,但是eds的时候只选择其中一个、
流量在这里就route里已经分配好了,就跟后面有多少副本就没关系了

回归到一个副本

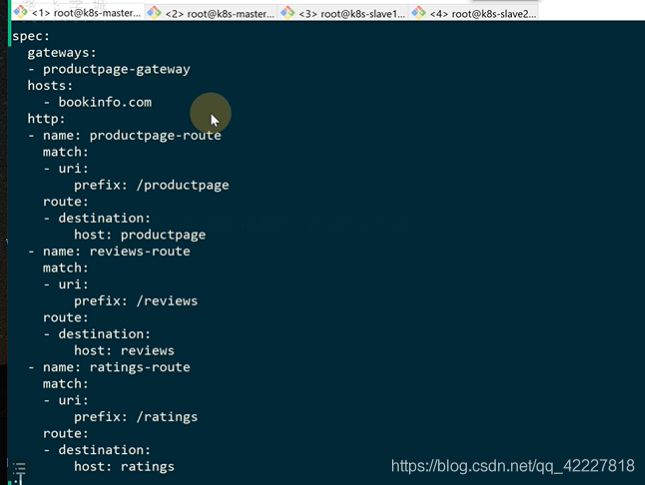
现在要实现下面的常见,bookinfo.com大服务访问review就访问review服务

首先要允许这个新域名进入服务网格,就需要gateway


这里其实是一个数组

两个域名现在都允许进入网格内部

根据path路径进行转发,还需要定义规则,一般绝大多数规则都是在virtualservice里定义的

从gateway来的流量,是访问bookinfo.com这个域名的流量按照下面的规则转发

匹配uri,如果是/productpage开头的就路由到productpage上去,如果要细分还可以转发给哪个版本什么的流量
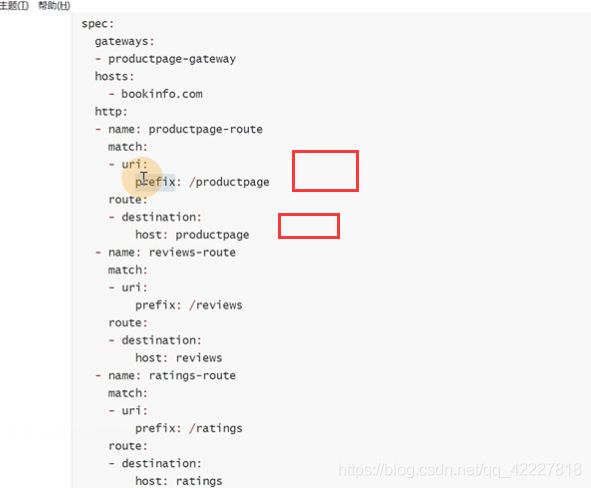
![]()

从productpage-gateway的转发的bookinfo.com流量转发给bookinfo



这里就可以访问
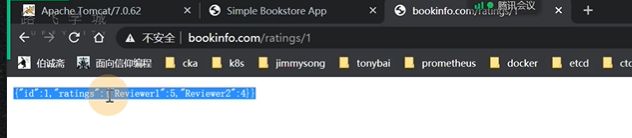
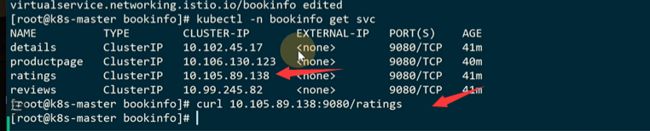
访问ratings的9080 是可以访问到的
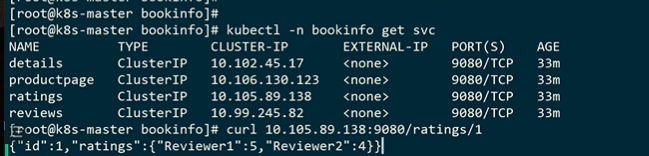


样式访问不到了

需要加个下划线


现在就可以了
访问productpage这个路由会自动帮你拼接到后端对应的service监听端口/路由
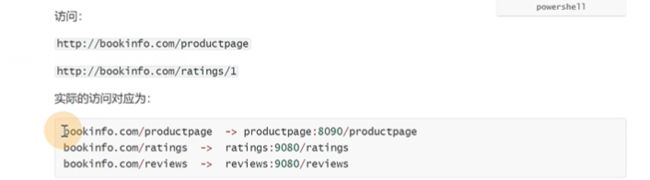
所以这就是为什么要加static
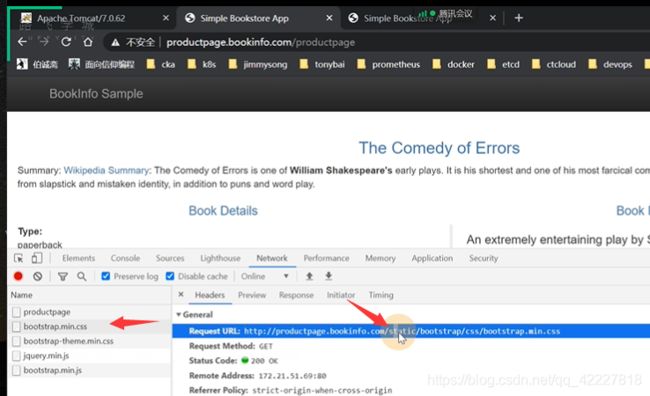

如果服务只有一个端口其实可以不用写


如果一个服务有多个端口,可以指向其中的一个

如果不想ratings区访问ratings,想rate去访问ratings,在原来基础上加个rewrite,匹配路径就换了




其实即使访问这个
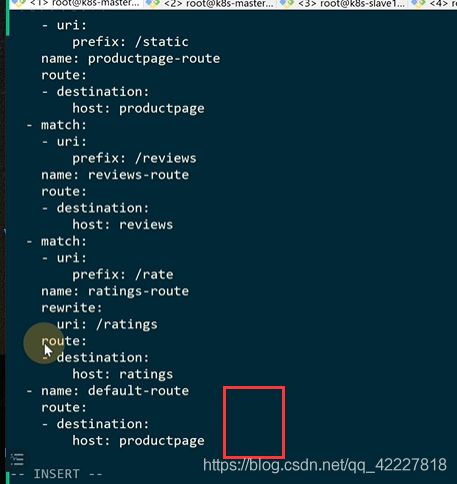
如果说想要一个用户专门访问一个版本,就可以做灰度发布,登陆里就会在headler里填写一堆数据,kv对


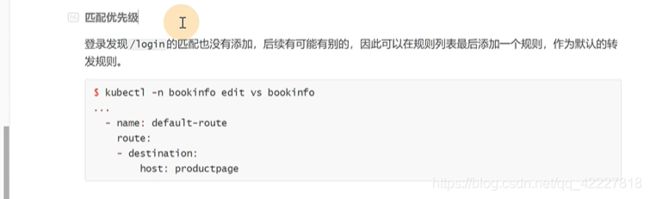
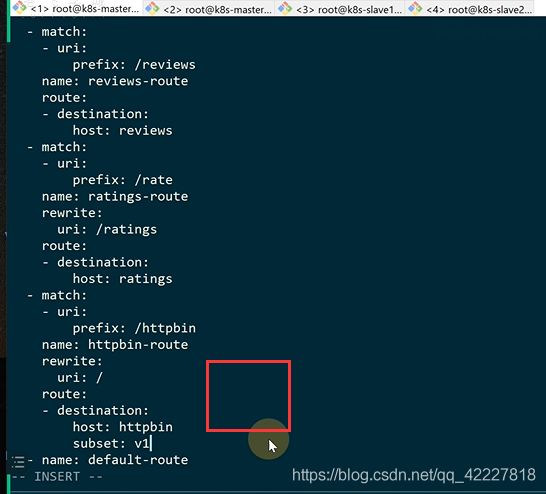
可以加一个default-route,match匹配不到就走默认路由
![]()



登陆之后会有一个header信息
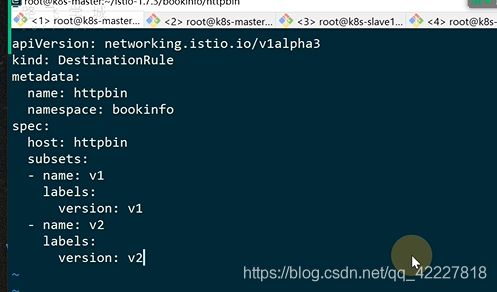
先暂时不管灰度发布,先看一下下destination-rule


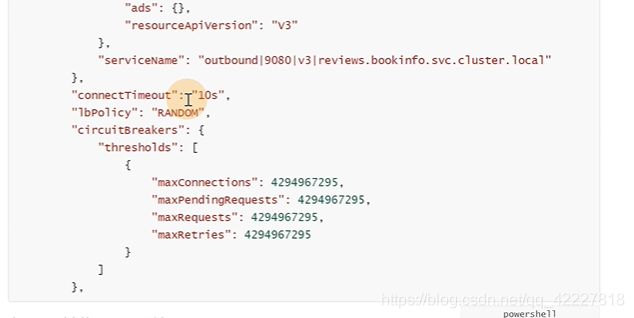
之前把v2版本的review换成了三个副本,那么10%的流量到后端后该如何去转发,那么这个策略就是在destination-rule里加的


默认规则是随机random

使用https,建议是放在ingress这一层(一般用公有云的lb,比如slb,clb),还可以放在istio侧使用证书

我们使用istio做灰度发布,也是用header来转发的

登陆之后,都会去带上这个信息
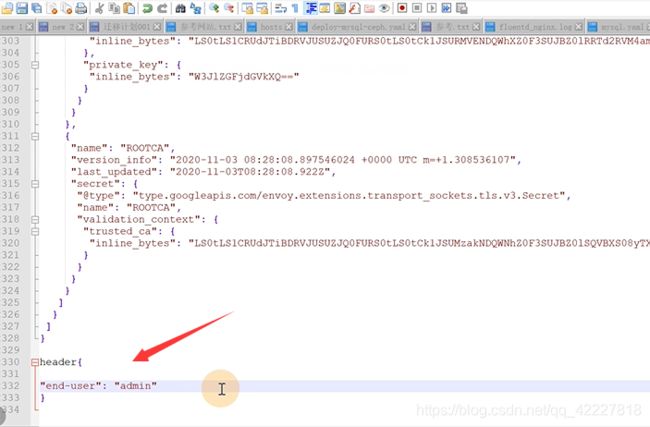
访问reviews服务的时候

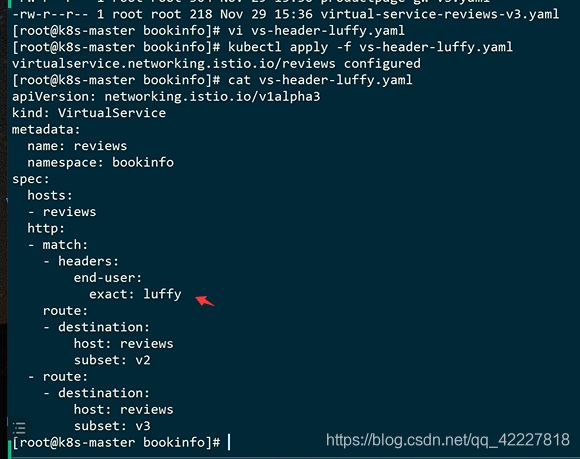
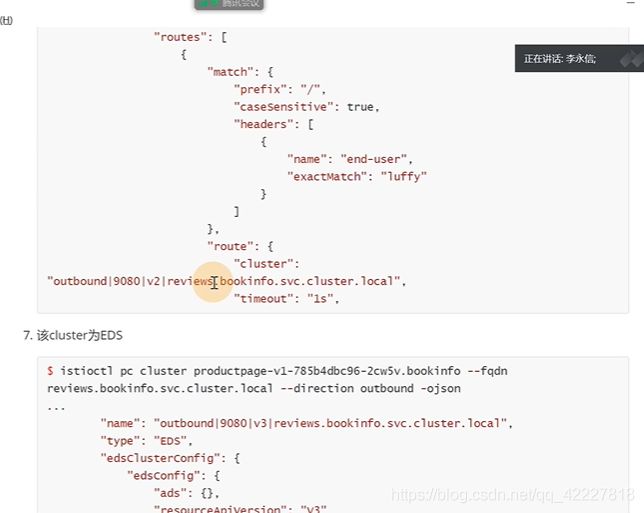
假如现在登陆的用户是路飞,想要让他只访问review2,其他的转发到review3上

那就是要写virtualservice规则。如果headers出现key是end-user里有)exact准确的就是完全等于)路飞的话就匹配到下面的路由上

否则剩下的就访问下面的
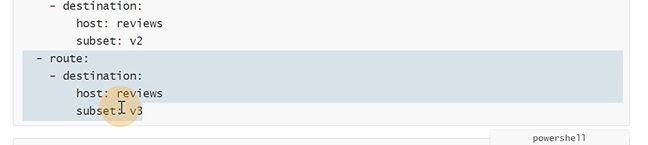



现在admin就只能分发到v3,是红星

登陆一下路飞

只能访问到v2版本

这里还支持以什么开头,甚至支持正则表达式
virtualservice的uri看到的,也是用的准确匹配,也可以前缀,或者正则表达式

还支持scheme,http或者https

get还是post方法

这个是httpv2的协议

headers就是之前用的,也支持正则表达式

还支持查询参数
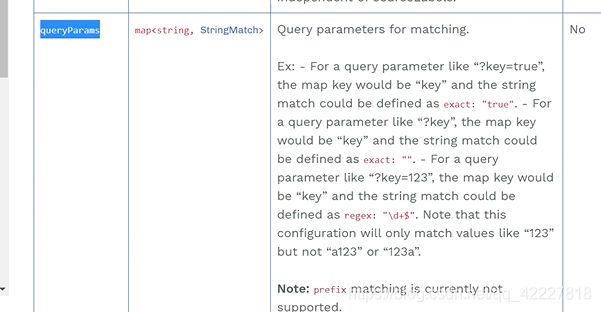
withoutheaders没有这些信息

不是路飞这个用户的就访问这里,是路飞这个用户的就访问下面


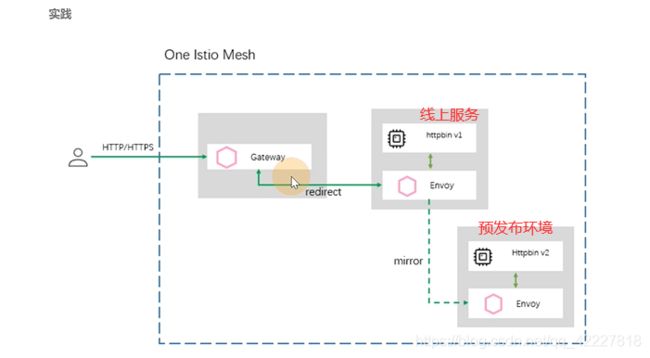
流量镜像和重试
流量镜像是非常厉害的功能,因为做压力测试的时候很难模拟一套线上的数据。流量镜像,就很大限度的解决了这个问题。是在不影响线上环境的前提下将线上流量持续的镜像到我们的预发布环境中去,让重构的服务结实的收到一波真实的冲击,同时预发布服务也表现出真实的处理能力

流量进入线上服务,同时发给预发布环境一份
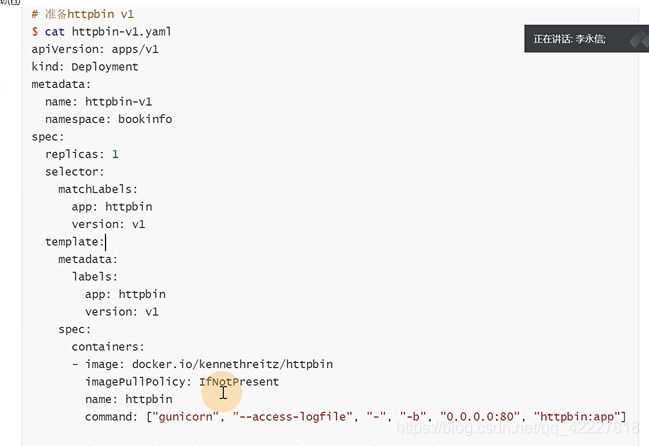

先建立一个httpv1的服务

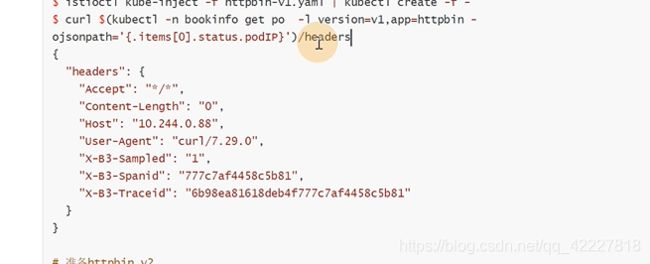
注入


合理有一个url,headers


准备v2版本

![]()
![]()

注入
![]()
建立一个service

![]()
istio建立规则少不了service,一定要创建service,因为virtualservice全是匹配servicename
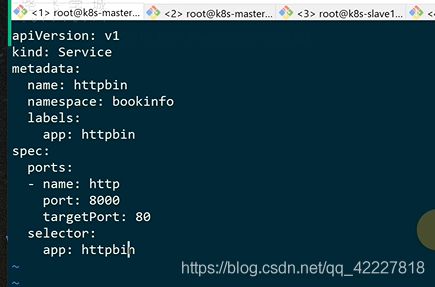
![]()

现在httpbin是访问不到的

需要添加规则


在default路由前加一下即可

现在只是创建了服务,还没有创建规则,destinationRule
![]()
![]()
现在就访问到了
headers就访问到这里了


查看一下日志

v2现在肯定还没有流量,因为都在v1上

现在就可以开始做流量镜像
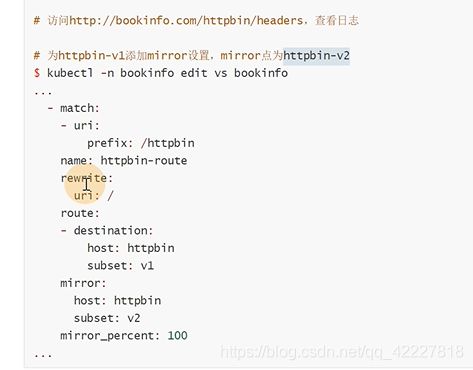
可以调整多少流量打过去

istio支持管理多集群,不同集群的服务可以通过这样的一种通用的来管理的


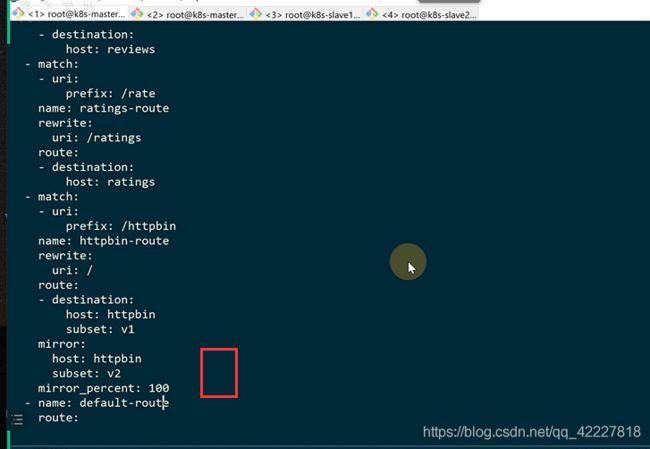
现在刷新一下页面

现在就有流量了

还可以重试,很多都是从代码层面来进行重试逻辑的,重试的本身这种需求,是和业务无关的,是一种通用的需求。istio可以帮你去实现重试的逻辑

当服务端返回502的时候,可以重试

现在访问,返回的是502

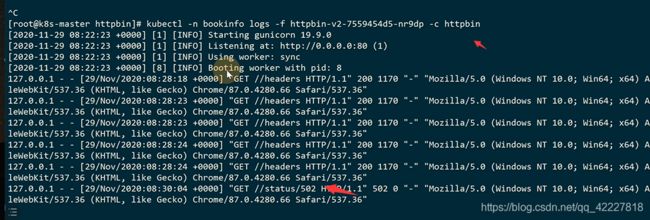
它自己从代理端就帮你重试了


访问server端返回是5XX的时候,重试三次
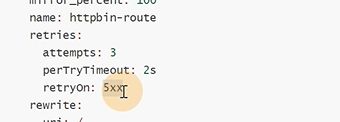
![]()
5xx的时候进行重试

![]()
访问一次400
就一条记录


重试三条


熔断
过载保护
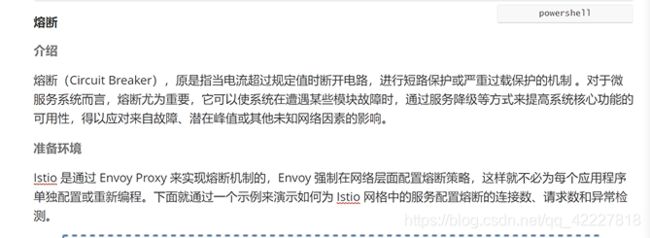
istio是通过envoy proxy来实现熔断机制的。envoy强制在网络层面配置熔断策略,这样就不必为了每个应用程序单独配置或重新编程。如果从代码层实现,可以实现一个callback,里面可以写逻辑。istio就没法写逻辑,因为没法进入你的代码。通常来讲istio网络中服务配置链接数和请求数用的是最多的
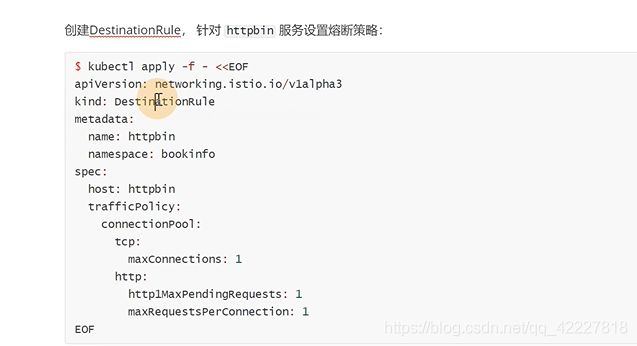
下面是httpbin去访问java app,可以在中间加一个熔断配置

、先创建服务

![]()

注入一下

![]()
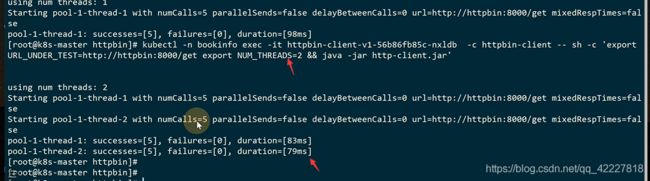
先用一个单线程的进行链接

现在用client去访问service,里面有get方法,其实就是设置了两个变量去发起请求
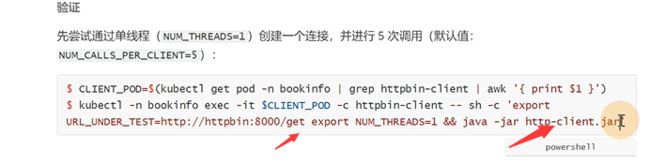
现在发送2个也是请求成功的

可以进行限制,是放在destinationrule里的
http2是一个链接去发送多个请求,不像http1,是建立一个链接发送一个请求

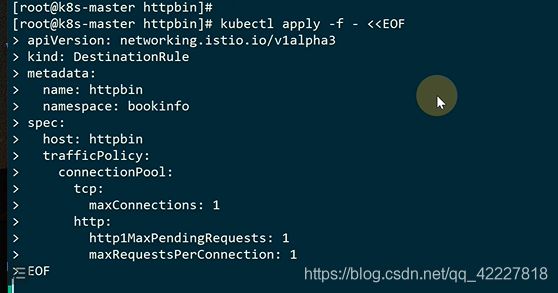
现在线程变成10就绝大多数是会失败的,istio里的熔断更像是限流
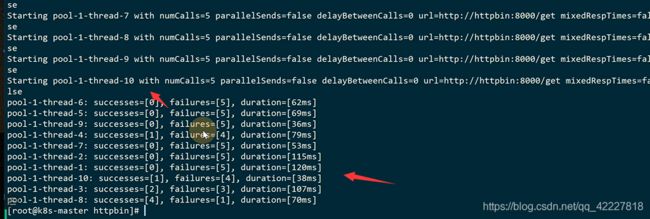
上面的应用的配置其实就是改了envoy的这里,envoy无法触发callback逻辑,因为它不进入代码

故障注入和超时

故障注入就是原来你的服务是正常,可以在envoy这层,显式的申明,访问details服务的时候,注入50%的故障,其实就是调试你的程序兼容性。如果100%故障就是服务挂了,它就是为了实现你的程序挂了,整个集群里是否还正常工作

是通过两类实现,abort是中止,delay是延迟

现在路飞用户访问到review v2上面
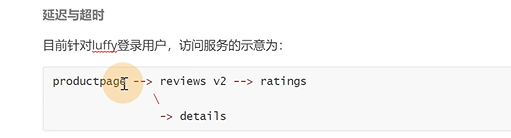
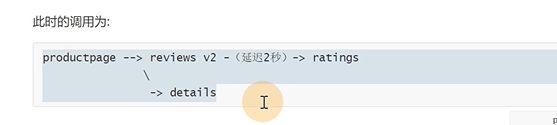
现在要这样,reviews去访问ratings这一层注入延迟2秒

建立一个virtualservice是跟ratings整个域名来进行访问的,有一个fault错误类型,也就是把访问rating服务100%流量,注入延迟2秒


所有访问rating服务的都注入一个延迟访问的故障,




现在就有延迟了

请求是两秒多
注入的延迟配置最终体现在envoy里

**可以加超时时间,针对reviews v2的进行1秒超时
**


超时针对v2生效,v3无效

登录路飞用户也是2秒,实际上是timout1秒,但是程序自己加了1秒超时

这里是1秒,它返回的时候rating还没有返回


这是一个延迟版的故障注入


还有状态码,把这个删除了就是故障了
![]()
代表50%纪律是500错误

![]()

![]()
这里就50%的几率出错了,也就是不用把服务停了模拟挂的情况
iptables规则失效排查
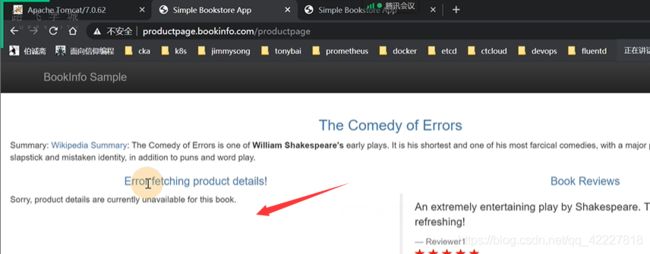
在istio网格内,流量请求完全绕过了kube-proxy组件

但是上次还能访问到

有几个服务都跑在slave1上,清理掉slave1的规则,也就是kube-proxy清理的规则,去访问通道

![]()
调度到不存在的机器,也就是把kube-proxy清理掉

在宿主机上清理掉iptables规则


现在访问不到
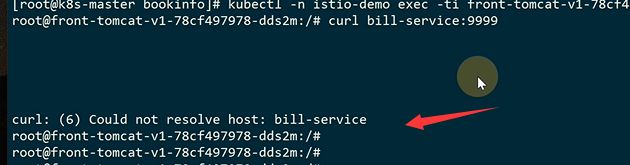 、
、
因为dns也是走的service流量,这个是走宿主机iptables规则去解析到的,现在规则没有了就解析不到了billservice了


直接访问ip可以通,是因为按照istio的走的
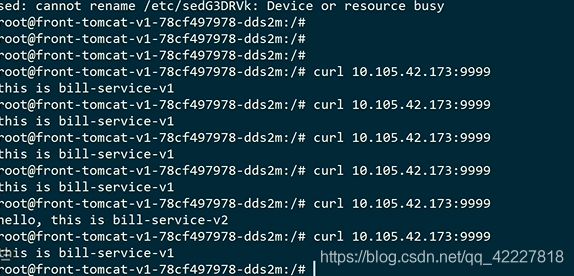
现在访问istio-proxy 是不通的,因为是走的宿主机的iptales

印证了在istio-proxy(虽然是网格里容器,但是访问外部是一摸一样的),在front-tomcat容器里,是走的envoy流量里去

把删除的kube-proxy改过来了


可观察性
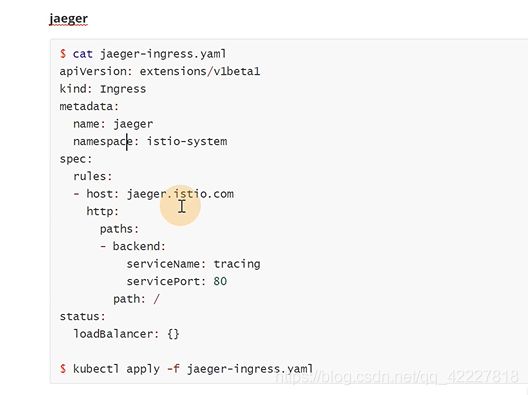
在整个istio里提供看的东西就grafana,jaeger(分布式追踪),kiali(专门针对istio做的可视化组件),prometheus

istio自带了这几个yaml文件,可以直接apply grafana
jaeger
![]()
需要改两个地址

![]()
这里用的是grafana自带的服务发现地址,默认是在istio名称空间里的

改成这个

![]()

这几个服务创建到了istio-system空间里


![]()
![]()



这些全是istio的


virtualservice加一个路由就是给服务发现服务路由,istio-proxy用的


istio在注入的时候已经帮你实现这个结构了
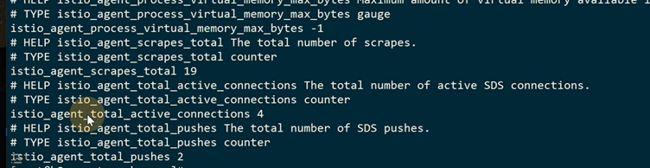
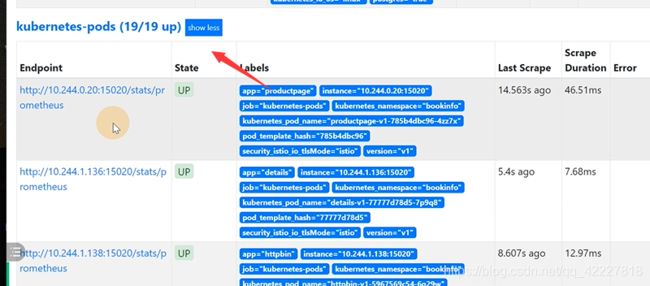
这是在pod层面做监控

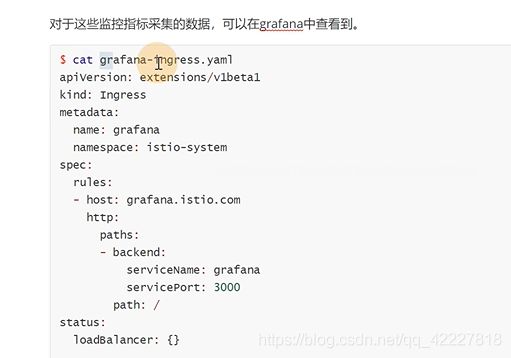
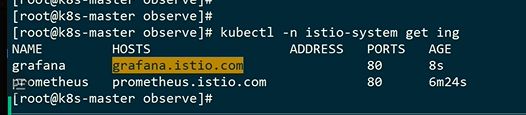
建立一个ingress
![]()
![]()
获得域名
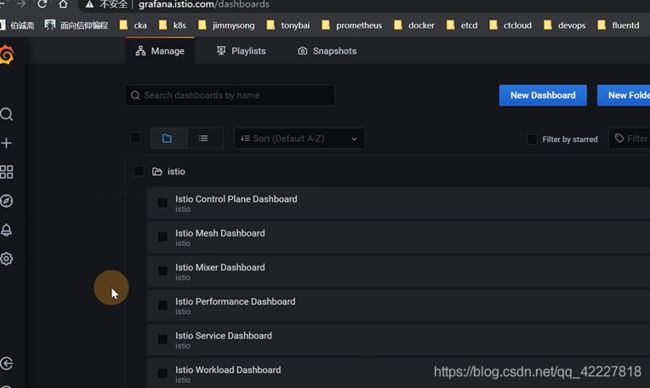
数据源都帮你配置好了


![]()
这是istio内部,grafana实现的配置




发送请求
![]()

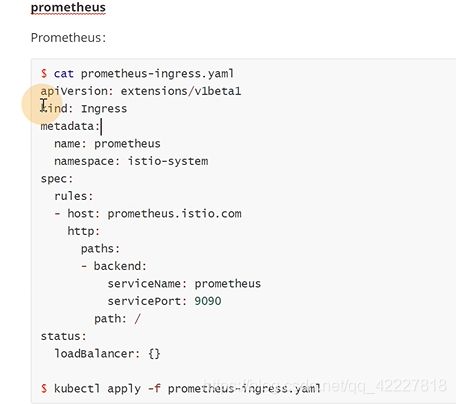
成功率百分百
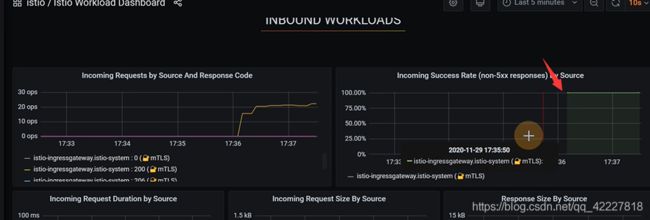
mesh dashboard,可以监控服务流量,所有服务都在这里




![]()

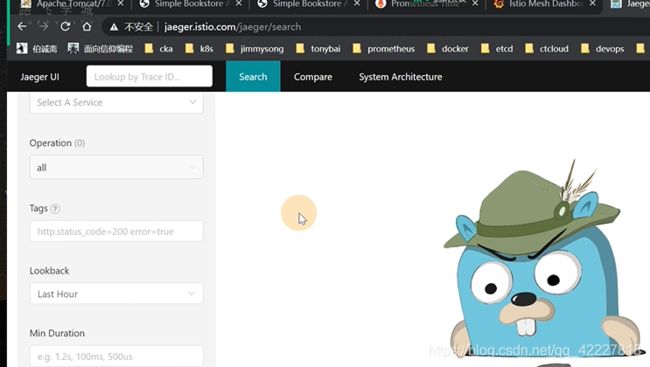
现在链路追踪是放在sidecar里的

envoy里已经帮你配置好了
启动的时候有1个配置文件
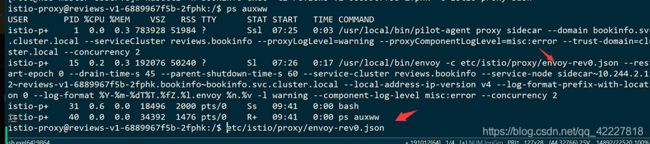

创建jaeger的时候已经看到这个zipkin创建好了

这两个都是追踪jaeger服务的,envoy虽然配置了zipkin,但是还是访问tracing

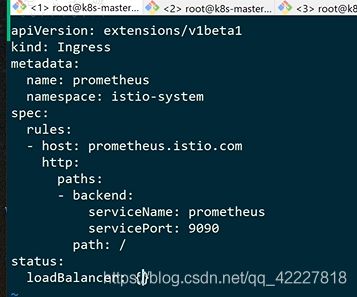
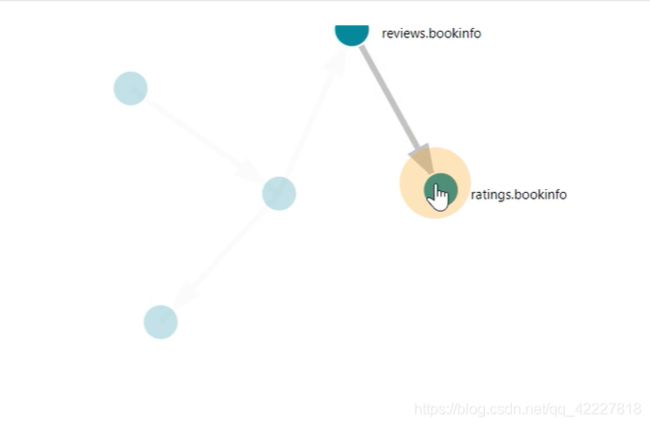
这里有图表展示对于关系

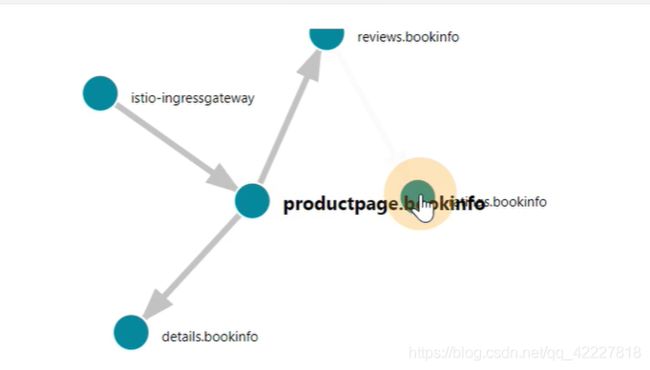
kiali
可观测性分析服务
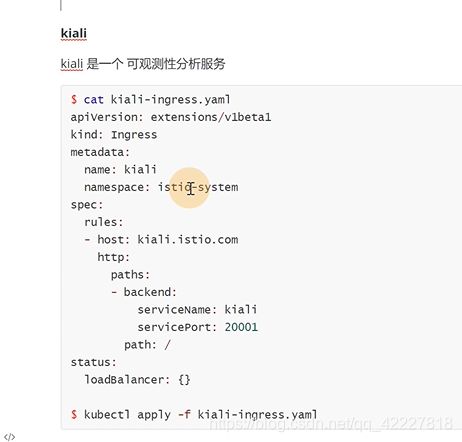




拿的是label里带app的

istio里做的
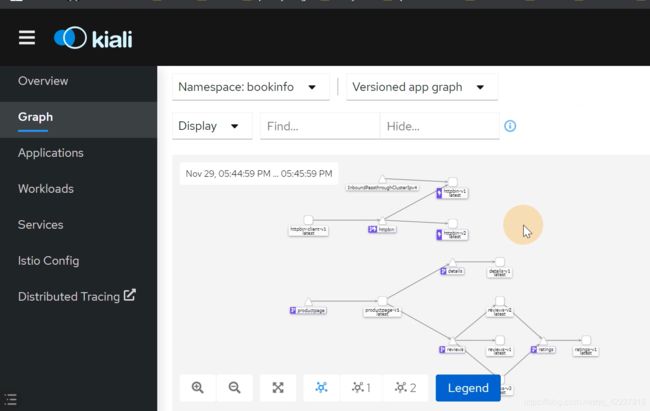
product配置,穿过v1,访问到detail

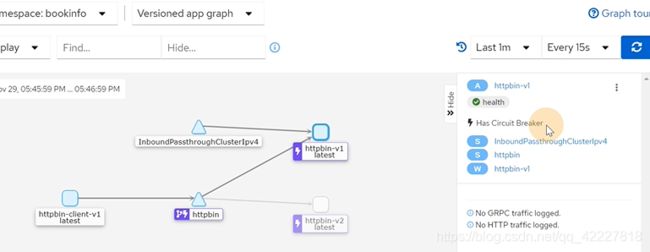
点击其他的service也可以看到这些图

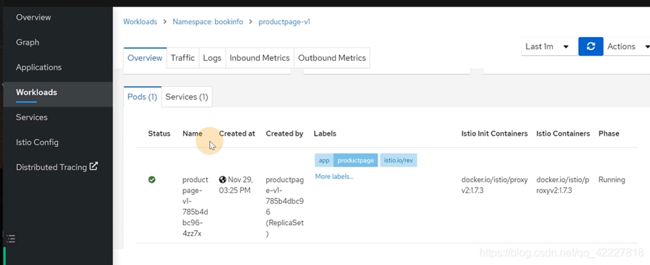
traffic,是inbound和outbound,入站和出站流量
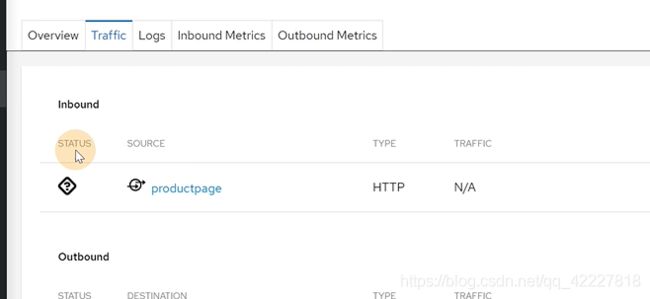
业务日志和istio-proxy日志
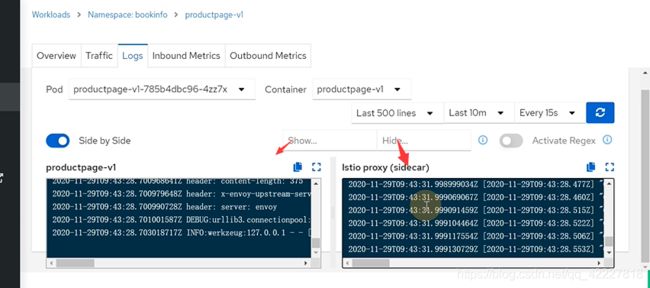
入站流量
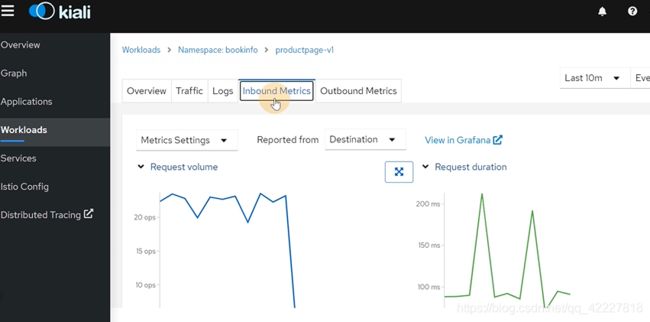

集成了很多东西,日志,inbound,outbound
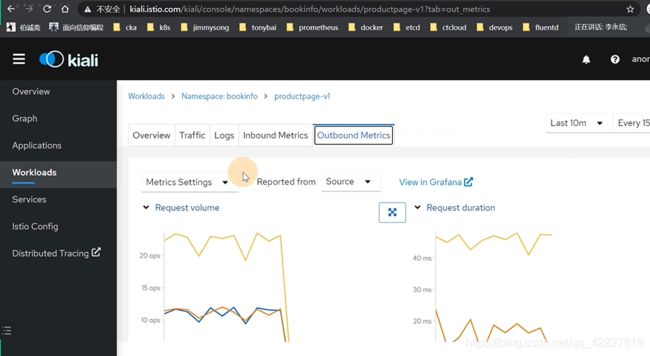
可以看一些service的基础信息


这个是拿的数据,确定有没有



小结
istio创建的规则,servicename必须依赖K8S实现的,istio的出现其实是微服务间的通讯的短板
**K8S已经称为容器调度编排的事实标准,容器正好可以作为微服务的最小工作单元,从而发挥微服务架Kubernets已经成为了容器调度编排的事实标准,而容器正好可以作为微服务的最小工作单元,从而发挥微服务架构的最大优势。所以我认为未来微服务架构会围绕Kubernetes展开。而lstio和Cnduit这类Service Mesh天生就是为了Kubernetes设计,它们的出现补足了Kubernetes在微服务间服务通讯。上的短板。虽然Dubbo. SpringCloud等都是成熟的微服务框架,但是它们或多或少都会和具体语言或应用场景绑定,并只解决了微服务Dev层面的问题。若想解决Ops问题,它们还需和诸如Cloud Foundry. Mesos、 Docker Swarm或Kubernetes这类资源调
度框架做结合:
**

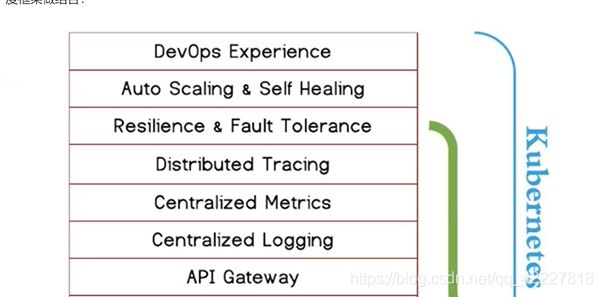


laas层面是系统层面的,从这个上面是K8S支持的,springcloud是这么支持,以后很长的时间都是K8S和istio
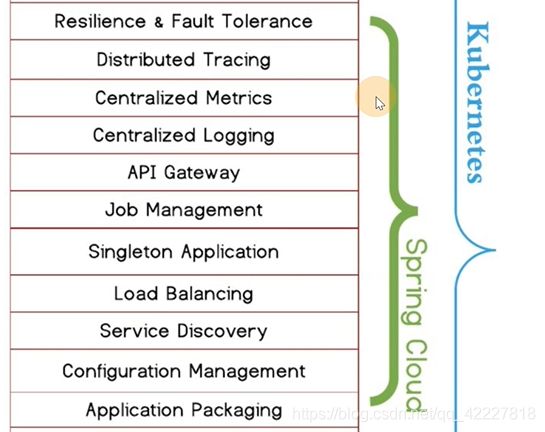



**总结一下:
第一代为spring cloud为代表的服务治理能力,是和业务代码紧耦合的,没法跨编程语言去使用
为了可以实现通用的服务治理能力,istio会为每个业务pod注入一个sidecar代理容器
**
提出了server mesh的理念,注入边车去监控业务流量

接管业务pod的流量,因此通过注入的时候引入初始化容器istio=init实现pod内防火墙规则的初始化,分别将出入站流量拦截到pod内的15001和15006端口

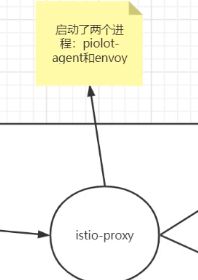
-还注入了istio-proxy容器,一个是pilot-agent进程,一个是envoy,envoy是pilot-agent拉起来的,pilot-agent是一个info进程,先起来生成配置文件-rev0,生成这个配置文件后把envoy拉起来,启动之后通过xds,再生成pilot,是istiod里的pilot-service这个服务,也就是grpc的server端
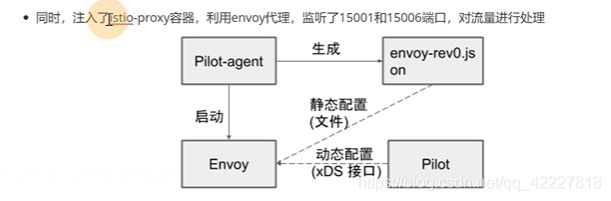
virtualservice,destination rule,gateway,转换和曾envoy可以识别的配置片段。通过xds同步到网格的envoy中



服务在productpage去curl这个地址,先给istio-init容器注入iptable规则,(output链转到istio_output链转到istio_redirect链)envoy监听15001端口,出站转到了0.0.0.0_端口这样一个监听上去,listener去读filter chains,经过路由规则,匹配到cluster,转到endpoint,最终转到pod的ip上
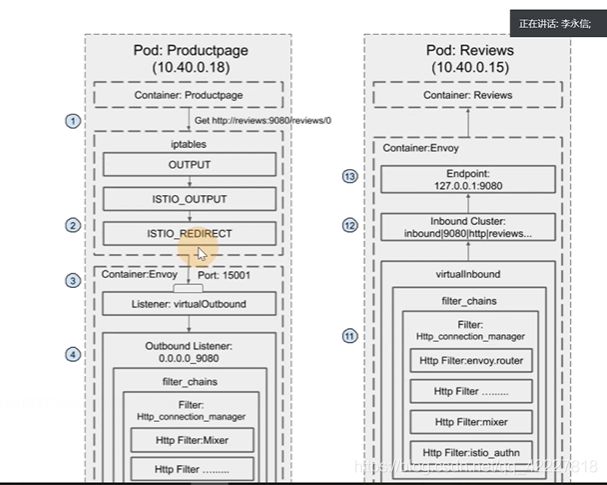
进入pod后被15006的envoy拦截,virrtual inbound做处理转到cluster上去,转到最终的endpoint


下面是整个过程,创建virtualservice,destination rule,endpoint









**envoy带来的肯定网络上更加复杂,还有额外的开销,是否需要用还要自己考量。灰度发布很简单,创建virtual service,destination rule规则就好了
**

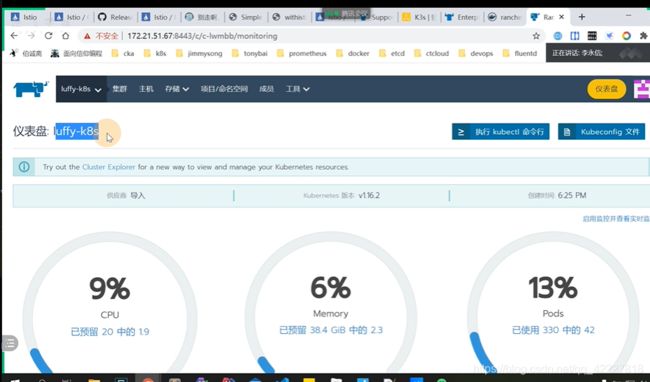
rancher安装使用
用rancher还是比较多的,因为用户不需要深入了解K8S


支持的版本


安装很简单就一句话


stable版本看一下,但是指定的为好

v2.5.2需要这样配置,privileged,使用该参数,container内的root拥有真正的root权限。否则,container内的root只是外部的一个普通用户权限。privileged启动的容器,可以看到很多host上的设备,并且可以执行mount。甚至允许你在docker容器中启动docker容器。


K3S是一个比K8S更轻量级的平台

可以用于物联网边缘计算设计

现在进行访问
设置密码
选择管理多集群的rancher

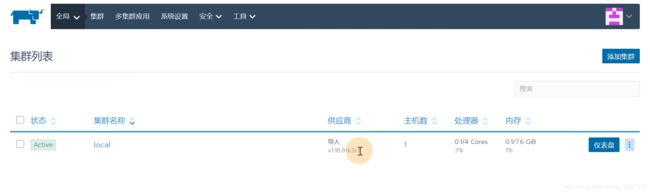
现在rancher就是一个K3S集群

可以理解为在里面启动了一个K3S集群

默认起了一个K3S集群

同样把这集群放到自己的管理页面去了




复制到集群里去执行


仪表盘还可以看一些资源的使用
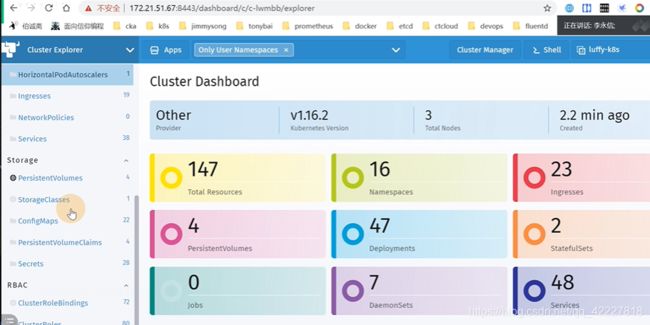
、可以执行命令行
这里也一样可以
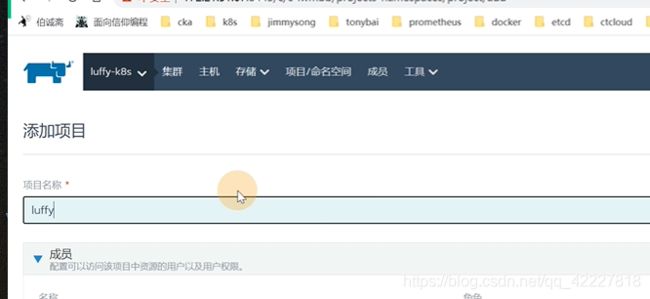
第一个概念就是项目,项目就是隶属于集群的有几个项目

这个项目是命名空间上面的一层虚拟概念,这个项目是包含名称空间的

default项目下包含一个default命名空间
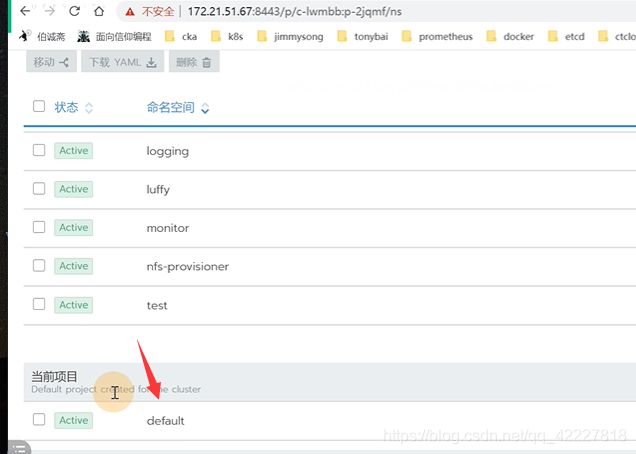
有这么多命名空间不属于任何项目

可以选择添加项目
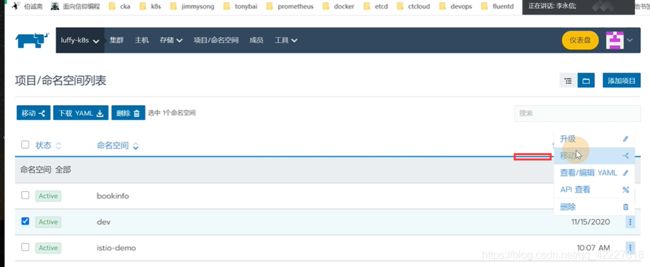
可以把命名空间移动到这个项目里
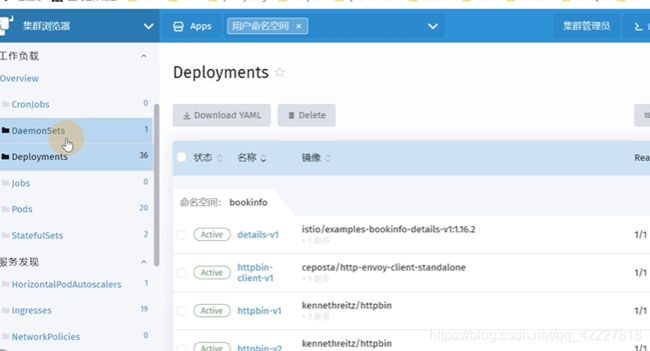
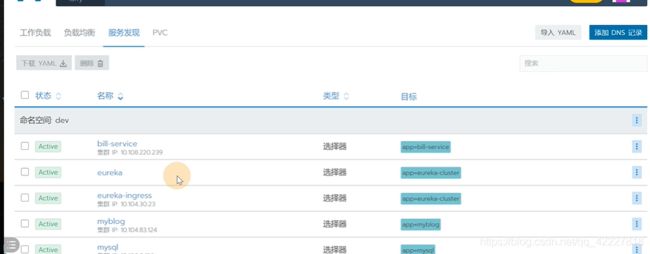
可以查看工作负载

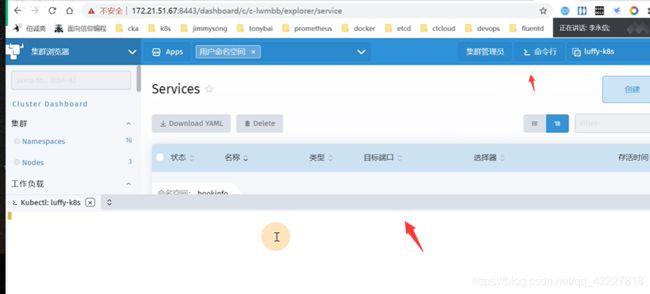
还有负载均衡
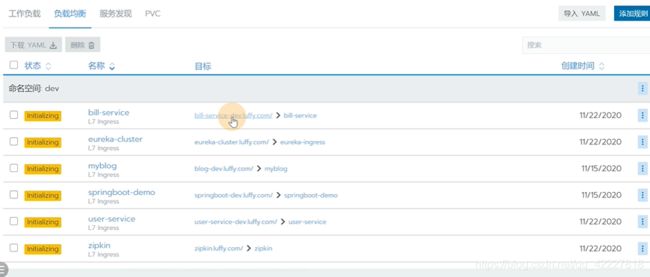
service,服务发现里有选择器
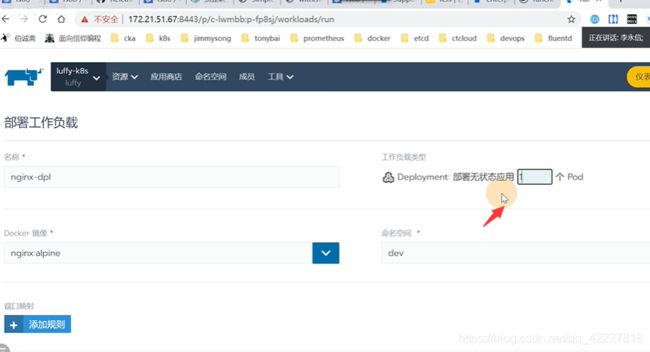
还可以部署服务


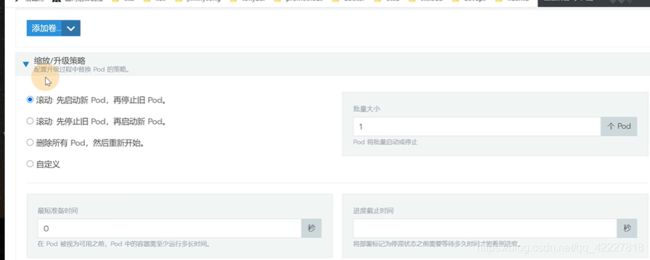
挂载卷

缩放升级策略,就是灰度更新
标签就是加label加标签

![]()

可以进容器进行curl

查看日志

事件就是deployment的内容
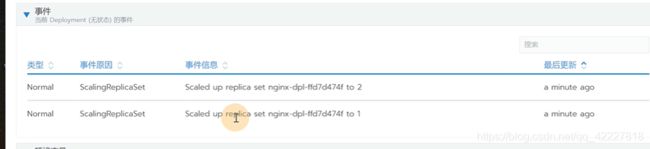

创建好service,会有一个工作负载

可以添加用户进行管理

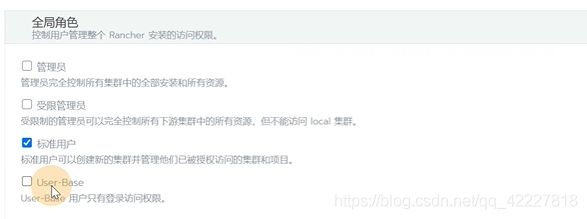

没有配置权限

假如想要访问dev环境下的项目,成员可以使用exec


现在就可以看到整个项目了

先创建用户然后在某个集群下添加用户

、应用商店其实就是克隆的一些项目,es集群还是其他的
还有devops操作,不过在2.5版本这里废弃了

使用了fleet,是一个devops工具
、


一直在报错,看起来镜像没有拉取成功。dns解析不了

宿主机上拉下来了

容器里是container-creating,pod起不来

是用containerd管理,并不是docker管理

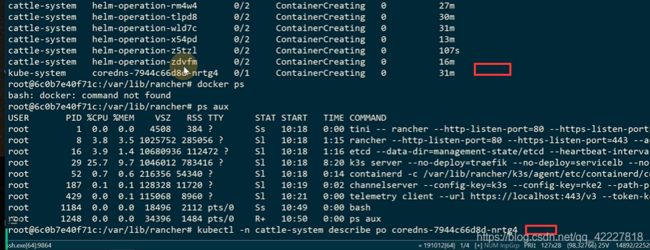
拉取镜像失败
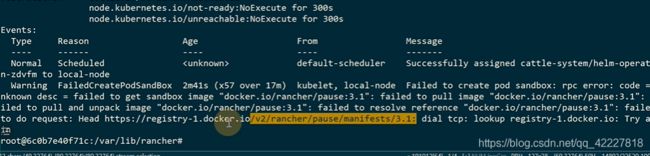
宿主机,有一个有一个rancher的pause镜像

获取到这个镜像
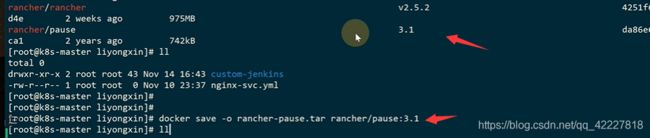
把这个镜像放到rancher里


这个目录里有bin
列出它的镜像

导入镜像,k3s里就是用ctr命令去管理containerd的

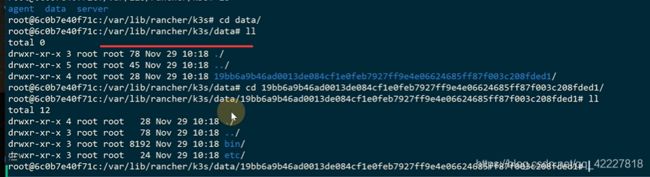
列出现在的镜像


集成了coredns


