实体识别NER——BiLSTM+CRF知识总结与代码(Pytorch)分析——细粒度实体的识别(基于CLUENER)
0-写在前面
看完这篇文章你将:
1> 了解BiLSTM和CRF的基本原理
2> 基于本文提供的代码你能轻松跑起来一个NER模型
3> 如果你愿意,细粒度的NER也能从本文的内容指导下实现
4> Bert模型与BiLSTM+CRF的拼接
最近在做关于NER的相关问题,在使用了Hanlp、哈工大的LTP[Link]进行简单的NER之后,发现确实比较方便快捷,但是这类通用的工具只对通用领域的“人物、机构、地点”进行了识别,准确率不是特别的高。刚好课程需要,于是决定对常见的BiLSTM+CRF的算法模型进行学习,找到新的训练数据集,完成更宽领域的实体识别工作,比如书籍,职位等。当然本篇文章还包括对具体的代码实现与分析,如果你对原理并不感兴趣,请直接移步第三节。
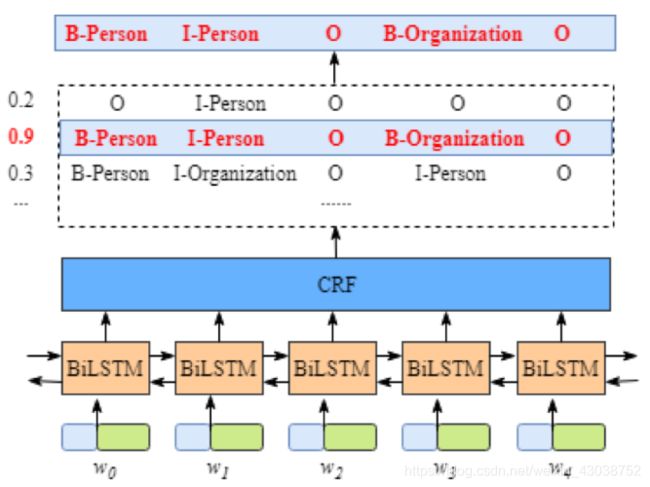
上图描述了BiLSTM-CRF的架构,底层的BiLSTM和上层的CRF共同完成了实体识别的工作。很好奇它是如何工作的吧?下面分开进行介绍:
1-BiLSTM的机制
在了解BiLSTM的基本原理之前,我们先说说BiLSTM层的输入和输出是什么样子的?

每一个神经元(带有长短时记忆结构)的输入是一个字(数值化表示),输出为每一种标签的得分情况(向量形式),理论上得分越高的可能性越大。
从循环网络说起
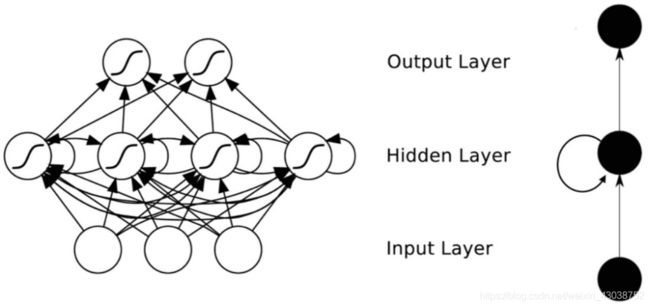
了解神经网络的都知道,RNN(循环神经网络)可谓是序列化数据处理的“专家”。如下图展示的这样,它克服了一般神经网络同一层神经元之间无链接的缺陷。仔细观察Hidden Layer层的结构,是不是和上面的BiLSTM的结构相似。
 将上图中的每一个单元在时间上展开,可以得到下图这种结构:
将上图中的每一个单元在时间上展开,可以得到下图这种结构:
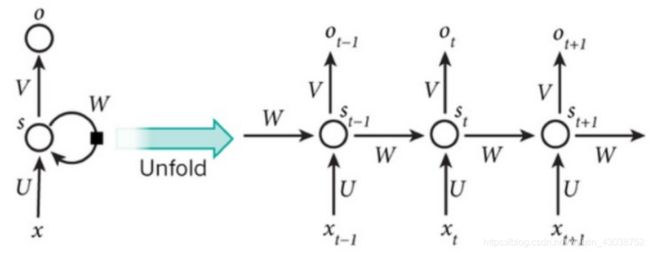
在循环神经网络中,有一条单向流动的信息流是从输入单元到达隐含单元的,与此同时,另一条单向流动的信息流从隐含单元到达输出单元,就想我们人思考一样,对当前的事务做出识别判断等操作,绝对依赖于以前的记忆经验等。
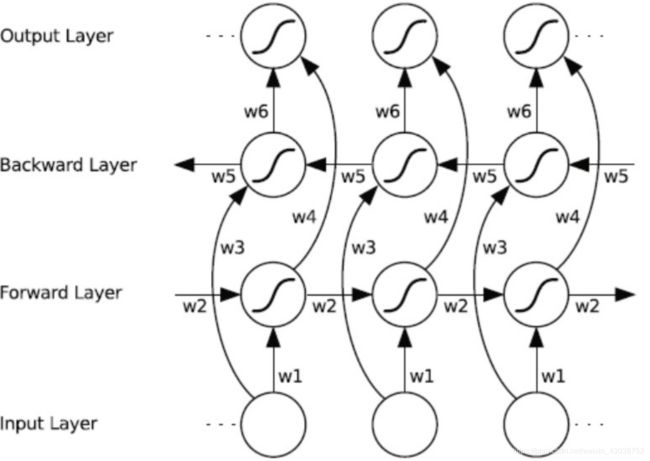
在NLP领域,上图就模拟了一种序列中前文影响后文的情况。但是事实是文本序列并不是像时间序列具有一维性,后文也同样可能影响前文。于是乎,双向RNN(BRNN)产生了:
你可能会说,我要看的是LSTM(或者BiLSTM),和RNN(或者BRNN)有何关系?
引入长短时记忆结构
其实很简单,在标准的RNN网络中,前后文的范围是有限的,可能在权重的影响下很快就失效,也就是隐含层的输入对于网络输出的影响随着网络环路的不断递归而衰退。
为了解决上述问题,长短时记忆(LSTM)结构诞生了。长短时记忆是一种结构,可以理解为一个加强版的组件放在了循环神经网络中,也就是把循环神经网络中隐含层的小圆圈换成长短时记忆的模块,如下图:

在数学模型上通过一系列的门结构控制,对于一般的使用者来说,不必深究。BiLSTM如下图所示,也就是在编码的过程中使用了两个方向的权重:

综上所述,BiLSTM就是考虑了序列上下文的RNN网络结构,其中RNN网络是基础,LSTM结构是加持。
PS:想要深入了解BiLSTM,推荐阅读[Link]
2-CRF的约束作用
看起来问题得到了解决,使用BiLSTM就完成了标签预测分类任务。但是事实上没有这么简单:
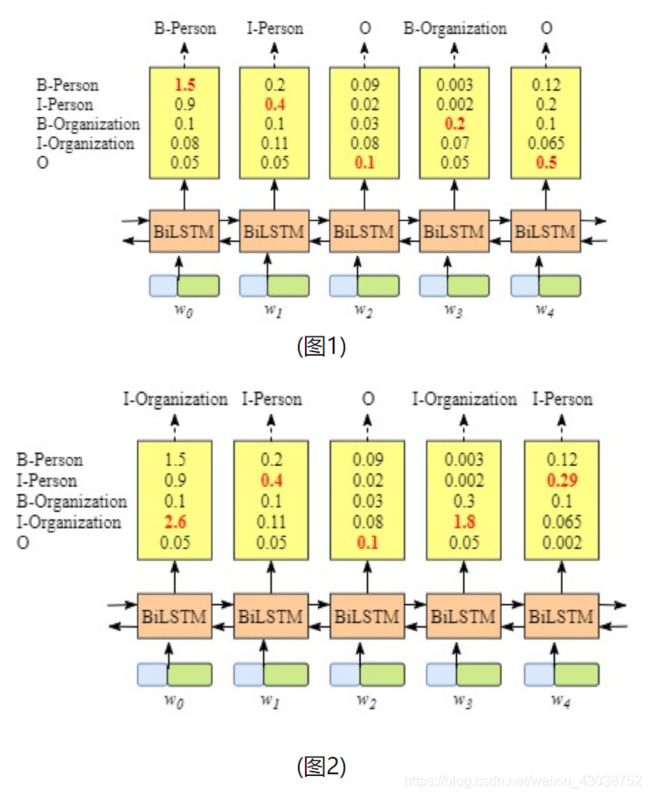
图1表现是我们想要的,但是图2却出现了一些很低级的错误,I-Org后面不可能紧接着出现I-Per(关于这里的标注符号含义请不明白含义的读者自行了解)。由于BiLSTM的输出为单元的每一个标签分值,我们可以挑选分值最高的一个作为该单元的标签。但我们不能保证标签每次都是预测正确的,即所谓的标记偏置的问题。所以这就是CRF(条件随机场)的功能,增加了一些约束规则,来大大降低预测错误的概率。
CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习。
比如我们直观可以想到的一些约束:
- 句子中第一个词总是以标签“B-“ 或“O”开始,而不是“I-” 标签“B-label1 I-label2 I-label3 I-…”;
- label1, label2, label3应该属于同一类实体。例如“B-Person I-Person” 是合法序列,但是“B-Person I-Organization” 是非法标签序列;
- 标签序列“O I-label”是非法的.实体标签的首个标签应该是“B-“ ,而非“I-”。
说白了,只要你认为你可以把规则想完整,不重复、不遗漏,你也可以自行编写规则库替代CRF的工作。
直观来说,就是根据状态关系找到当前最可能出现的状态,大多数时候采用的最大似然估计的方法。多说一句,在NLP领域,我们随处可见这种概率模型的应用,如HMM等,感兴趣的读者还是最好去了解一下原理。
PS:想要深入了解CRF,推荐阅读[Link]
3-源码分析与使用
好了,以上简单的介绍了BiLSTM和CRF的基本原理,接下来就是撸代码时间了,下载地址[Link]。
快速入手
首先是目录结构,注意其中的标红框位置是原项目中一开始是没有的,运行程序可以得到:
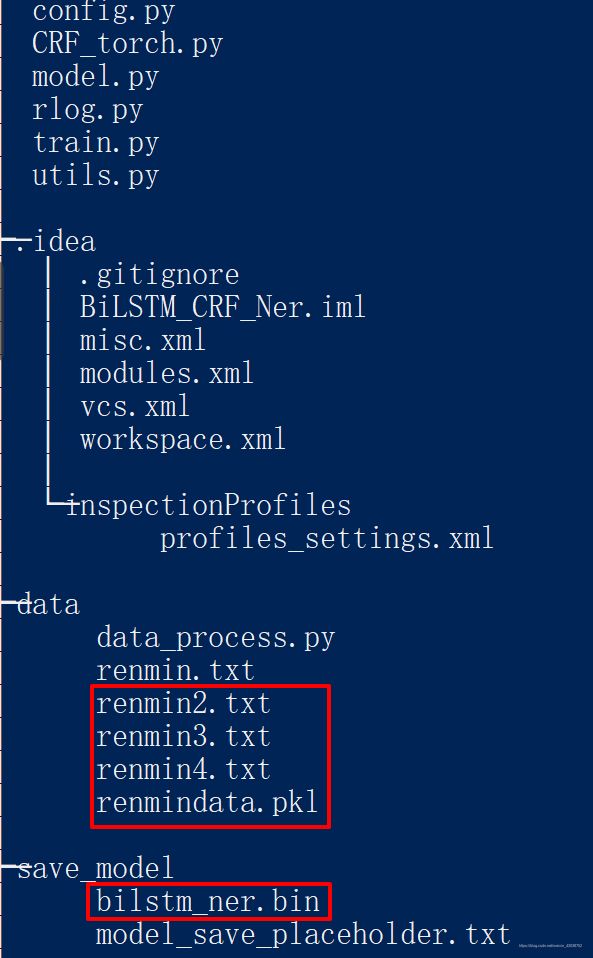
接下来介绍基础环境以及各个模块的作用。
该项目运行环境要求并不高,本身基于Pytorch,版本方面只要不是很低的版本都能运行。这里贴出我的版本(CPU版):

代码本身支持GPU加速,当然对应的配置比较繁琐,可以参考我的一篇博客配置NIVIDIA的显卡驱动,同时Pytorch的GPU版本安装在CSDN或者其他平台也可以找到教程,这里不再细说。
项目的架构比较清晰:
1)data目录下的data_process.py文件完成对数据格式的转换,最终转换为PKL格式。一开始的数据是基于人民日报的标注数据集,数据大概长这个样子:

这个数据集随处可见,词性标注比较全面,包含了命名实体(上图标注绿色为代表),但是模型需要的BIOE标注模式的数据,大概是下面这样:

B表示开头、M是实体的中间、E标示实体的结束,ns是地名,nt是机构名称,nr是人名。
总的来说,data_process完成的就是这样的工作。
这里需要把原程序做如下修改,也就是取消注释即可:
if __name__ == '__main__':
originHandle() # 将原始语料进行简单处理
originHandle2() # 转为标记语言
sentence2split() # 将所有段落分成一条一条的短句子
data2pkl() # 将数据集放在pkl文件中
最终的data目录就会变成前面展示的目录结构中那个样子。
2)config.py文件完成了项目的参数配置
device = torch.device('cuda: 1' if torch.cuda.is_available() else 'cpu')#选择计算设备
pickle_path = './data/renmindata.pkl' # 训练集存放路径,不需要修改
load_model_path = None # 加载预训练的模型的路径,为None代表不加载
batch_size = 128 # batch size
num_workers = 4 # how many workers for loading data
print_freq = 20 # 屏幕打印频率
max_epoch = 20 #最大训练次数(正常笔记本大概一轮要100s左右)
lr = 0.001 #学习率
lr_decay = 0.5 #学习率调整系数,当损失变大时,减小学习率!
weight_decay = 1e-5 # 损失函数阈值
embedding_dim = 100 #编码层维度
hidden_dim = 200 #隐藏层维度
dropout = 0.2 #dropout比例
以上参数很多不必调整,只需要关注max_epoch、batch_size的大小设置。
3)utils.py文件中定义了一些常见函数
不必做调整,这里实现了F1值得计算、获取训练数据中的标签类型、对数据输出格式进行规整等等。这里的训练数据标签类型的自动获取很好的提升了模型本身与数据的解耦性。
4)CRF_torch.py中实现了CRF算法,并以类的形式封装
5)model.py中实现了网络的构建以及其与CRF的级联
6)train.py是模型的训练和预测
这一块是项目的入口,在1)中生成完数据之后,其实就可以来到train.py文件中执行了。注意项目一开始是注释掉train函数的,需要把注释去掉:
model = NERLSTM_CRF(Config.embedding_dim, Config.hidden_dim, Config.dropout, word2id, tag2id)
train() # 训练
predict(tag='all',input_str="李明说联合国教科文组织是个好地方,美国应该重视纽约的地位!")
#ns 地名;nt是机构名称;nr是人名
对了,我这里的tag应该是ns/nr/nt之类的,all是我在上面的函数中修改了部分代码,这样就可以一次性打印出人物、机构、地点,不用手动切换ns、nr之类的。我调整的部分代码如下:
#这一块代码在predict函数的最后面
if tag=='all':
for i in ['nr','nt','ns']:
tags = get_tags(paths[0], i, tag2id)
entities += format_result(tags, input_str, i)
print(entities)
else:
tags = get_tags(paths[0], tag, tag2id)
entities += format_result(tags, input_str, tag)
print(entities)
运行train.py就可以看到彩虹颜色的log打印,其格式设置在rlog.py中,一般不必修改。
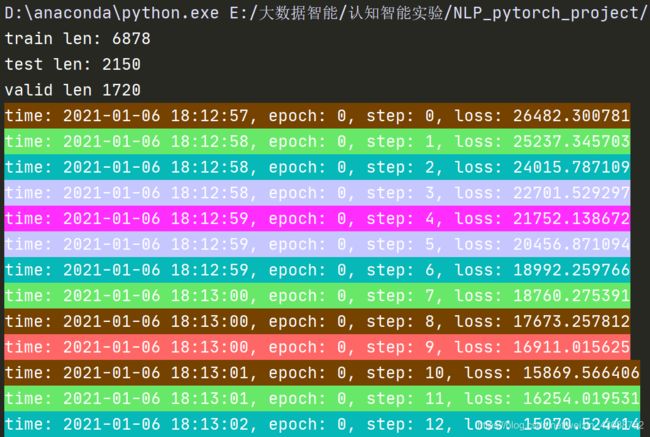
待训练完成就会看到目录中的bilstm_ner.bin文件了,说明模型被保存下来。这时你再注释掉train函数,直接调用模型开始你的预测之旅吧!
进一步训练
这就满足了?前面受限于训练数据的因素,只可以提取到人物、地点、机构。那我要是识别一本书呢?一个公司呢?模型无罪,数据集的问题。这里推荐一个比较好用的细粒度实体识别可用的数据集:CLUENER [Link]
————————————————————————————————————————
包括:【训练集:10748 验证集:1343】
标签类别:【数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)】
数据集相当的棒!
————————————————————————————————————————
美中不足的是,数据格式不对(如下图),json的原始数据需要转换为上面提到的模型需要的数据格式。

给出我们的代码:
import json
import pandas as pd
data=[]
with open(r'E:\cluener_public\train.json', 'r', encoding='utf8') as inp:
for line in inp.readlines():
data.append(json.loads(line.split('\n')[0]))
data_all=[]
for i in range(len(data)):
dict={}
for key in data[i]['label']:
dict[key]=[]
for key1 in data[i]['label'][key]:
dict[key].append(data[i]['label'][key][key1][0])
data_all.append(dict)#存储的是每一行对应的各个名称的位置信息
index_all=[] #存储每个text长度的序列数字
for i in range(len(data_all)):
d=data[i]['text']
index_1=[]
for j in range(len(d)):
index_1.append(j)
index_all.append(index_1)
def rm(dict,data):
for key in dict:
for i in dict[key]:
for j in range(i[0],i[1]+1):
data.remove(j)
return data
#把index_all中的对应个机构名称的数字删除掉,剩下的就对应other的部分,后面只需要加上|O即可
for i in range(len(data_all)):
if i!=1506:
rm(data_all[i],index_all[i])
def sp_b(d,index,key):
return d[index]+"/"+"B_"+key
def sp_m(d,index,key):
return d[index]+"/"+"M_"+key
def sp_e(d,index,key):
return d[index]+"/"+"E_"+key
def sp_O(d,index):
return str(d[index])+"/O"
def oth(dict,d):
data1=[]
for i in range(len(d)):
data1.append(i)
for key in dict:
for i in dict[key]:
for j in range(i[0],i[1]+1):
data1.remove(j)
return data1
#在名称对应的字后面加上对应的表示内容,存储在字典中 按照{数字位置:数字值}的数据结构存储
def ind(data_all,data,index):
dict=data_all[index]
d=data[index]['text']
dict_1={}
for key in dict:
for i in dict[key]:
for j in range(i[0],i[1]+1):
if(j==i[0]):
dict_1[j]=sp_b(d,j,key)
elif(j==i[1]):
dict_1[j]=sp_e(d,j,key)
else:
dict_1[j]=sp_m(d,j,key)
return dict_1
data_dic=[]
for i in range(len(data)):
data_dic.append(ind(data_all,data,i))
#为其他位置的字加上|O
for j in range(len(index_all)):
for i in index_all[j]:
d=data[j]['text']
data_dic[j][i]=sp_O(d,i)
#将字典按照键排序,为了在连接时能够保证顺序不变
for i in range(len(data)):
data_dic[i]=sorted(data_dic[i].items(),key=lambda d:d[0])
#把所有字符串连接在一起
data_f=[]
for i in range(len(data)):
str1=""
for j in range(len(data_dic[i])):
str1=str1+" "+data_dic[i][j][1]
data_f.append(str1)
with open(r'clueNER.txt', 'w', encoding='utf8') as f:
for line in data_f:
f.write(line+"\n")
代码是在jupyter lab中写的,复制过来可能存在缩进问题,程序比较简单,读者可以自己写一写,这里仅仅作为参考。
将该数据直接做成PKL格式,塞进模型中即可训练。
运行结果

可以看出识别的效果还是不错的,在epoch设置为40,其余不变的情况下,准确率可以达到0.87。
4-引入Bert
引入Bert的意义在于更好的进行字编码。先来看看前面介绍的模型是如何接受输入数据的:
(['我',在'北','京'],['O','O','B-LOC','I-LOC'])
但是在程序内部做了word2id的操作,也就是所有的训练数据集中的字全部会按顺序从1编码到N,N是字的总数。计算机不能处理汉字输入,必须转换为某种数值编码,进一步变成二进制的机器码。
从1顺序编码的方法听起来确实很简单。引入Bert之后就是将这种编码方式进行了变革,Bert和后面的架构耦合性并不高,但是2015年诞生的Bert模型本身的注意力机制使得其能够在充分的表达文本背后的信息的前提下将字向量化,在你怎么调整模型参数和延长学习时间都不能提升模型性能时,考虑把Bert这顶帽子戴上可能会有极大的提升。
这里不再进行具体代码的分析,也不再详细的展开,读者如果需要可以私信联系。
欢迎大家交流指正!
2021年1月6日 by hash怪