deepsort+Cascade_RCnn行人追踪详细设计文档
前言
我们以DeepSORT追踪算法为基本方向,通过优化行人检测模型和特征提取模型来提升行人追踪的效果。DeepSORT追踪算法的基本思想:使用匈牙利算法解决预测的Kalman状态和新状态之间的关联度。以马氏距离作为第一个衡量尺度,并以最小余弦度量作为第二个衡量尺度,将计算得到的马氏距离度量和最小余弦距离进行线性加权融合作为最终的度量标准,使用综合度量标准判断出不同帧行人匹配度。首先,对MOT20数据集以及CrowdHuman数据集进行筛选以及预处理,得到训练数据集和测试数据集。然后,通过实验分析比较Cascade R-CNN、PP-YOLOv2等行人检测模型的效果,以及特征提取模型(深度度量学习metri_learing,提取bbox中的特征)的效果。最终以cascade_Rcnn_r50_vd_fpn_ssld_2x_coco作为行人检测模型,以深度度量学习metri_learing_ResNet50_vd作为特征提取模型,评测分数0.66619的效果。
源码已在paddle开源,开源地址:软件杯-多目标行人追踪 - 飞桨AI Studio - 人工智能学习实训社区 (baidu.com)
PDF文档下载链接

DeepSort
一、数据预处理
1、 MOT20数据简单介绍
一共8个视频序列,4个训练集,4个测试集。

标注det.txt和gt.txt文件
检测文件的标注格式:
< frame >, < id>,
每一列分别代表,
1:该目标出现的帧号
2:该目标被分配的唯一ID号,在det(检测)文件中为-1
3:目标bbox左上角的x坐标。
4:目标bbox左上角的y坐标。
5:目标bbox的宽
6:目标bbox的高
7:置信度。det中表示该目标是行人的概率,gt中若评估该目标则设为1,忽略则设置为0
8:gt中表示该目标的类别,Det为-1
9:可见率,gt中表示该目标可见的程度,可能被遮挡或者是图像边框裁剪导致目标不完整,值为0-1。det中为-1

2、MOT20标注格式转换以及数据筛选
2.1、将MOT20类型标注文件det,gt转换位标准的voc格式。同时对bbox进行筛选。
依据gt中的三个参数:是否需要忽略(0代表需要忽略),label,以及可见率对bbox进行筛选。分别对对应一行中的第7,8,9三个参数。
< frame >, < id>,
7:< conf>置信度。det中表示该目标是行人的概率,gt中若评估该目标则设为1,忽略则设置为0
8:< x>gt中表示该目标的类别,Det为-1
9:< y>可见率,gt中表示该目标可见的程度,可能被遮挡或者是图像边框裁剪导致目标不完整,值为0-1。det中为-1
#1、MOT20标注文件det,gt转xml标注文件。同时对bbox进行筛选。
import os
import cv2
import codecs
import time
ori_gt_lists = ['/home/aistudio/MOT20/train/MOT20-05/gt/gt.txt',
'/home/aistudio/MOT20/train/MOT20-03/gt/gt.txt',
'/home/aistudio/MOT20/train/MOT20-02/gt/gt.txt',
'/home/aistudio/MOT20/train/MOT20-01/gt/gt.txt'
]
img_dir = '/home/aistudio/mot20/JPEGImages/'
annotation_dir = '/home/aistudio/mot20/Annotations_gt/'#xml保存路径
for each_dir in ori_gt_lists:
start_time = time.time()
fp = open(each_dir, 'r')
userlines = fp.readlines()
fp.close()
fram_list = []
for line in userlines:
e_fram = int(line.split(',')[0])
fram_list.append(e_fram)
max_index = max(fram_list)
print(each_dir + 'max_index:', max_index)
for i in range(1, max_index+1):
# print("each:",each_dir[-12:-10])
# print(format(str(i), '0>6s'))
clear_name = each_dir[-12:-10] + format(str(i), '0>6s')
format_name =each_dir[-12:-10]+ format(str(i), '0>6s') + '.jpg'
detail_dir = img_dir + format(str(i), '0>6s') + '.jpg'
# print(format_name)
img = cv2.imread(img_dir+format_name)
shape_img = img.shape
height = shape_img[0]
width = shape_img[1]
depth = shape_img[2]
#如果采用index的方法去获取索引只会找到想匹配的第一个数据的索引,后面的索引信息无法获取,所以这里
#采用enumerate方式来获取所有匹配的索引
each_index = [num for num,x in enumerate(fram_list) if x == (i)]
with codecs.open(annotation_dir + clear_name + '.xml', 'w') as xml:
xml.write('\n')
xml.write('\n' )
xml.write('\t' + 'voc' + '\n')
xml.write('\t' + format_name + '\n')
# xml.write('\t' + format(str(i), '0>6s')+ '.jpg' + ' \n')
# xml.write('\t' + path + "/" + info1 + ' \n')
xml.write('\t\n' )
xml.write('\t\t The MOT20-Det \n')
xml.write('\t\n')
xml.write('\t\n' )
xml.write('\t\t' + str(width) + '\n')
xml.write('\t\t' + str(height) + '\n')
xml.write('\t\t' + str(depth) + '\n')
xml.write('\t\n')
xml.write('\t\t0 \n')
for j in range(len(each_index)):
num = each_index[j]
# print(userlines[num].split(',')[6])
# print(userlines[num].split(',')[6])
# if int(userlines[num].split(',')[6])==0 or float(userlines[num].split(',')[8])<=0.2:
if int(userlines[num].split(',')[6])==0 :#对于需要忽略的bbox进行跳过
continue
x1 = int(userlines[num].split(',')[2])
y1 = int(userlines[num].split(',')[3])
x2 = int(userlines[num].split(',')[4])
y2 = int(userlines[num].split(',')[5])
xml.write('\t)
xml.write('\t\tperson \n')
xml.write('\t\tUnspecified \n')
xml.write('\t\t0 \n')
xml.write('\t\t0 \n')
xml.write('\t\t\n' )
xml.write('\t\t\t' + str(x1) + '\n')
xml.write('\t\t\t' + str(y1) + '\n')
xml.write('\t\t\t' + str(x1 + x2) + '\n')
xml.write('\t\t\t' + str(y1 + y2) + '\n')
xml.write('\t\t\n')
xml.write('\t\n')
xml.write('')
end_time = time.time()
print('process {} cost time:{}s'.format(each_dir,(end_time-start_time)))
print('succeed in processing all gt files')
#引用:https://zhuanlan.zhihu.com/p/160930039
生成voc格式所需求的txt文档
1、train.txt文件的格式要求以及生成方法.
traint.txt中每一行内容是每一张图片以及对应的xml文件相对应与数据集根目录的路径。
数据集格式如下图:


with open('train.txt','w') as w:
img_list=os.listdir('')
for img_a in img_list:
w.write('JPEGImages/'+img_a+' Annotations/'+img_a.split('.')[0]+'.xml')
val.txt文件要求相同,按照测试集:训练集=3:10的比例生成val.txt
2、label_list.txt标签文档的生成。
该文档里包含所有类别的名称,每种类别各一行。对于MOT20训练集来说只有一个person类,只需在文档里写一个person就行。
2.2、在voc格式的基础上生成coco格式的json文件
基于Paddledetection中的x2coco.py方法将voc格式转换成coco格式的.json文件。需要提前准备好以下几个文件:xml标注文件、anno_trainlist.txt文件、label_list.txt文件。
xml文件以及labe_list.txt在准备voc格式时已准备完成。现在是生成anno_trainlist.txt文档。该文档里保存的是所有标注文件相对于数据集的相对路径,每一个标注文件写一行。(可以将train.txt中的标注文件路径复制生成anno_trainlist.txt
with open("train.txt",'r') as FR:#生成train.txt
with open('anno_trainlist.txt','w') as fw:#anno_trainlist.txt
line=FR.readline()
while line:
img_apth,anno_path=line.split()
fw.writelines(anno_path+'\n')
line=FR.readline()
x2coco.py方法将voc格式转换成coco格式
!python x2coco.py \
--dataset_type voc \
--voc_anno_dir mot20/Annotations \#xml路径
--voc_anno_list mot20/anno_trainlist.txt \#anno_trainlist.txt路径
--voc_label_list mot20/label_list.txt \#label_list.txt路径
--voc_out_name /home/aistudio/mot20/mot_train.json#json文件保存路径
以上即是MOT20转换为voc以及coco类型的完整方法,为后期模型的训练做好了准备。
2.3、标注可视化。将bbox绘制在相应的图片上,便于观察分析训练集bbox的特点。
#2、标注可视化。将bbx展示
import xml.etree.ElementTree as ET # 读取xml。
import os
import cv2
import numpy as np
from PIL import Image,ImageDraw,ImageFont
def parse_rec(filename):
tree = ET.parse(filename) # 解析读取xml函数
objects = []
img_dir =[]
for xml_name in tree.findall('filename'):
img_path = os.path.join(pic_path, xml_name.text)
img_dir.append(img_path)
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects,img_dir
def visualise_gt(objects,img_dir):
for id,img_path in enumerate(img_dir):
img = Image.open(img_path)
imgcopy = img
draw = ImageDraw.Draw(imgcopy)
# print(len(objects))
for a in objects:
xmin =int(a['bbox'][0])
ymin =int(a['bbox'][1])
xmax =int(a['bbox'][2])
ymax =int(a['bbox'][3])
label = a['name']
draw.rectangle((xmin,ymin,xmax,ymax), fill=None, outline=(0,255,0),width=2)
draw.text((xmin-10,ymin-15), label, fill = (0,255,0))
imgcopy.show()
save_path='/home/aistudio/showgt_part/'+img_path.split('/')[-1]#保存路径
# print(save_path)
imgcopy = np.float32(imgcopy)
cv2.imwrite(save_path,imgcopy)
root = '/home/aistudio'
ann_path = os.path.join(root, 'mot20/Annotations_gt/') # xml文件所在路径
pic_path = os.path.join(root, 'mot20/JPEGImages/') # 样本图片路径
files=(os.listdir(ann_path))[:100]
for filename in files:
xml_path = os.path.join(ann_path,filename)
# print(xml_path)
object,img_dir = parse_rec(xml_path)
visualise_gt(object,img_dir)
3、CrowdHuman训练集的简单介绍
CrowdHuman数据集是旷世发布的用于行人检测的数据集,其中训练集15000张,测试集5000张,验证集4370张。训练集和验证集中共有 470000 个实例,每张图片包含大概23个人。CrowdHuman 数据集 和 CityPersons 数据集可见比率(Visible Ratio)的比较。可见比率是可见边界框与完整边界框的比率。

4、CrowdHuman数据集格式转换
4.1、将CrowdHuman数据集 .odgt类型文件转换成标准的voc格式
from xml.dom import minidom
import cv2
import os
import json
from PIL import Image
roadimages = 'Images/'
xml_save_path = "CrowdHuman_VOC/Annotations/val/"#xml文件保存路径
img_save_path = ''
root_img_save = 'CrowdHuman_VOC/JPEGImages/val/'
fpath = "annotation_val.odgt" #odg文件路径
if not os.path.exists(xml_save_path):
os.makedirs(xml_save_path)
if not os.path.exists(root_img_save):
os.makedirs(root_img_save)
def load_func(fpath):
assert os.path.exists(fpath)
with open(fpath, 'r') as fid:
lines = fid.readlines()
records = [json.loads(line.strip('\n')) for line in lines]
return records
val_txt = open('CrowdHuman_VOC/val.txt', 'w')
bbox = load_func(fpath)
for i0, item0 in enumerate(bbox):
print(i0)
# 建立i0的xml tree
ID = item0['ID'] # 得到当前图片的名字
imagename = roadimages + ID + '.jpg' # 当前图片的完整路径
img_save_path = root_img_save + ID + '.jpg'
savexml = xml_save_path + ID + '.xml' # 生成的.xml注释的名字
val_txt.write('{} {}\n'.format(img_save_path, savexml))
print(img_save_path, savexml)
gtboxes = item0['gtboxes']
img_name = ID
floder = 'CrowdHuman'
im = cv2.imread(imagename)
cv2.imwrite(img_save_path, im)
w = im.shape[1]
h = im.shape[0]
d = im.shape[2]
doc = minidom.Document() # 创建DOM树对象
annotation = doc.createElement('annotation') # 创建子节点
doc.appendChild(annotation) # annotation作为doc树的子节点
folder = doc.createElement('folder')
folder.appendChild(doc.createTextNode(floder)) # 文本节点作为floder的子节点
annotation.appendChild(folder) # folder作为annotation的子节点
filename = doc.createElement('filename')
filename.appendChild(doc.createTextNode(img_name + '.jpg'))
annotation.appendChild(filename)
size = doc.createElement('size')
width = doc.createElement('width')
width.appendChild(doc.createTextNode("%d" % w))
size.appendChild(width)
height = doc.createElement('height')
height.appendChild(doc.createTextNode("%d" % h))
size.appendChild(height)
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode("%d" % d))
size.appendChild(depth)
annotation.appendChild(size)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode("0"))
annotation.appendChild(segmented)
for i1, item1 in enumerate(gtboxes):
# 提取全身框(full box)的标注
boxs = [int(a) for a in item1['fbox']]
# 左上点长宽--->左上右下
minx = str(boxs[0])
miny = str(boxs[1])
maxx = str(boxs[2] + boxs[0])
maxy = str(boxs[3] + boxs[1])
# print(box)
object = doc.createElement('object')
nm = doc.createElement('name')
nm.appendChild(doc.createTextNode('fbox')) # 类名: fbox
object.appendChild(nm)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode("Unspecified"))
object.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode("1"))
object.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode("0"))
object.appendChild(difficult)
bndbox = doc.createElement('bndbox')
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(minx))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(miny))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(maxx))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(maxy))
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
savefile = open(savexml, 'w')
savefile.write(doc.toprettyxml())
savefile.close()
#引用于:韩三岁-PPYOLO训练行人检测模型https://aistudio.baidu.com/aistudio/projectdetail/1785771
4.2、将voc类型换为coco类型
这里讲CrouwHuman数据集的voc类型转换成coco类型方法与MOT20中的转换方法相同,参见于文章第二部分MOT20标注格式转换以及数据筛选中的第二小部分。这里就不再重复说明了。
5、测试集处理
将测试集图片合成视频用于之后的模型预测
#将图片集合成视频
import cv2
import
import tqdm
# 图片路径
rootpath='/home/aistudio/mot_images'
path=rootpath+'/0/'
#读取第一张图片以获得图片的尺寸
img = cv2.imread(path+'/00001.jpg')
# 设置每秒读取多少张图片
fps = 25
imgInfo = img.shape
# 获取图片宽高度信息
size = (imgInfo[1], imgInfo[0])
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 定义写入图片的策略
videoWrite = cv2.VideoWriter(rootpath+'/0.mp4', fourcc, fps, size)
files = os.listdir(path)
files = sorted(files)
print(files[0:10])
out_num = len(files)
for i in tqdm.tqdm(range(0, out_num)):
# 读取所有的图片
# fileName = path + 'in' + str(i).zfill(6)+'.jpg'
fileName = path+files[i]
img = cv2.imread(fileName)
videoWrite.write(img)
videoWrite.release()
print('finish')
二、DeepSort 追踪算法的实现
在开源的deep_sort_paddle的基础上,我们进行了适当的优化。解决了paddle训练导出的行人检测模型与deep_sort_paddle匹配的问题。
通过实践发现,deepsort算法在加载paddle导出的行人检测模型时,提示的各类错误都是与模型的配置文件加载有关。在查看deepsort算法中的模型加载文件后,发现其版本比较久旧,对于现在比较流行的yolo以及ppyolo系列等都不适用。找到根本问题后,我们将模型加载方法进行重写,同时用PaddleDetection2.0版本中的模型加载方法将旧版本进行替换。
具体实现方法:
1、将PaddleDetection模型部署模块里的模型加载文件文件夹(/PaddleDetection/ deploy/python)拷贝到deep_sort_paddle中
2、修改deep_sort_paddle中行人检测模型的Detector实例化方法。调用从PaddleDetection中拷贝的模型加载方法实例化行人检测器。
from python.infer import Detector
self.detector = Detector(det_model_dir, det_model_dir,True)
结果替换之后,该DeepSort算法基本上能适应所有Paddle训练导出的行人检测模型, 为优化模型的追踪效果打好了基础。
提交文件的生成:
提交要求:用户将每一个测试数据集的输出结果,打印成如下格式存放在txt中。
< frame >,< id >,< bb_left >,< bb_top >,< bb_width >,< bb_height >,< conf >,< x >,< y >, < z>

每一个txt里面内容结构如图所示
其中:
-
id是指目标(行人或者车辆等)的ID
-
frame是指第几帧
-
bb_left 是指目标所在box的左边界的横向坐标
-
bb_top指box的上边界的纵向坐标
-
bb_width指box定宽 bb_height指box的高度 conf指该box的置信度 取值应该在0到1之间 在标注文件中 所有conf为1
-
x,y,z是3d中用到的 在2d中默认为-1即可
f = open(args.save_dir+'/SoftwareCup-0'+args.video_path.split('/')[-1][0]+'.txt','w+') fff = 0 while True: # < frame >,< id >,< bb_left >,< bb_top >,< bb_width >,< bb_height >,< conf >,< x >,< y >, < z> success, frame = cap.read() string = "" string = string+str(fff)+"," if not success: break outputs = deepsort.update(frame) if outputs is not None: for output in outputs: temp_s = string cv2.rectangle(frame, (int(output[0]), int(output[1])), (int(output[2]), int(output[3])), (0,0,255), 2) cv2.putText(frame, str(output[-1]), (int(output[0]), int(output[1])), font, 1.2, (255, 255, 255), 2) w = output[2]-output[0] h = output[3]-output[1] temp_s=temp_s+str(int(output[-1]))+","+str(output[0])+","+str(output[1])+","+str(w)+","+str(h)+",1,-1,-1,-1\n" f.writelines(temp_s) # print(temp_s) # print(outputs) if args.save_dir: writer.write(frame) if args.display: cv2.imshow('test', frame) k = cv2.waitKey(1) if k==27: cap.release() break fff+=1 f.close()
三、行人检测模型的训练
1、 Cascade R-CNN模型
1.1Cascade R-CNN模型介绍
Cascade R-CNN算法是CVPR2018的文章,通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同的是,cascade R-CNN的几个检测网络是基于不同IOU阈值确定的正负样本上训练得到的,这是该算法的一大亮点。

上图是关于几种网络结构的示意图。(a)是Faster RCNN,因为two stage类型的object detec-tion算法基本上都基于Faster RCNN,所以这里也以该算法为基础算法。(b)是迭代式的bbox回归,从图也非常容易看出思想,就是前一个检测模型回归得到的bbox坐标初始化下一个检测模型的bbox,然后继续回归,这样迭代三次后得到结果。(c)是Integral Loss,表示对输出bbox的标签界定采取不同的IOU阈值,因为当IOU较高时,虽然预测得到bbox很准确,但是也会丢失一些bbox。(d)就是本文提出的cascade-R-CNN。cascade-R-CNN看起来和(b)这种迭代式的bbox回归以及(c)这种Integral Loss很像,和(b)最大的不同点在于cascade-R-CNN中的检测模型是基于前面一个阶段的输出进行训练,而不是像(b)一样3个检测模型都是基于最初始的数据进行训练,而且(b)是在验证阶段采用的方式,而cascade-R-CNN是在训练和验证阶段采用的方式。和(c)的差别也比较明显,cascade R-CNN中每个stage的输入bbox是前一个stage的bbox输出,而(c)其实没有这种refine的思想,仅仅是检测模型基于不同的IOU阈值训练得到而已。

1.2cascade_Rcnn_r50_vd_fpn_ssld_2x_coco行人检测MOT20训练集
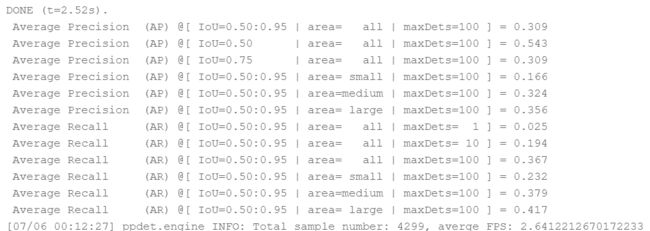
1)在MOT20上模型训练的结果(对label不是行人的bbox进行剔除):

此时行人检测的预测结果:
2)在MOT20上模型训练的结果(对label不是行人的bbox,以及可见率小于0.3的bbox进行剔除。模型输入为改为:1664*960):
可以看到,模型对于小目标的准确率有很大的提升,从之前的0.166到0.505。整体效果也从0.527提升到0.670。

此时行人检测结果:
1.3cascade_Rcnn_r50_vd_fpn_ssld_2x_coco行人检测CrowHuman训练集
模型训练结果:
行人检测结果:
2、PP-YOLOv2模型
2.1PP-YOLOv2模型介绍

PP-YOLO(https://arxiv.org/abs/2007.12099)是在 YOLOv3 的基础上,采用了一整套优化策略,在几乎不增加模型参数和计算量(FLOPs)的前提下,提升检测器的精度得到的极高性价比(mAP 45.9,72.9FPS)的单阶段目标检测器。而 PP-YOLOv2,是以 PP-YOLO 为基线模型进行了一系列的延展实验得到的。具体的优化策略有:
1、采用 Path Aggregation Network(路径聚合网络)设计 Detection Net
YOLO 系列的一大通病,是对不同尺幅的目标检测效果欠佳,因此,PP-YOLOv2 第一个优化的尝试是设计一个可以为各种尺度图像构建高层语义特征图的检测颈(detection neck)。不同于 PP-YOLO 采用 FPN 来从下至上的构建特征金字塔,PP-YOLOv2 采用了 FPN 的变形之一—PAN(Path Aggregation Network)来从上至下的聚合特征信息。
2、采用 Mish 激活函数
Mish 激活函数被很多实用的检测器采用,并拥有出色的表现,例如 YOLOv4 和 YOLOv5 都在骨架网络(backbone)的构建中应用 mish 激活函数。而对于 PP-YOLOv2,我们倾向于仍然采用原有的骨架网络,因为它的预训练参数使得网络在 ImageNet 上 top-1 准确率高达 82.4%。所以我们把 mish 激活函数应用在了 detection neck 而不是骨架网络上。

3、更大的输入尺寸
增加输入尺寸直接带来了目标面积的扩大。这样,网络可以更容易捕捉到小尺幅目标的信息,得到更高的性能。
4、IoU Aware Branch
在PP-YOLO中, IoU aware loss 的计算采用了soft weight format,这与最初的意图不一致。因此改进为应用soft label format。以下是IoU aware loss:
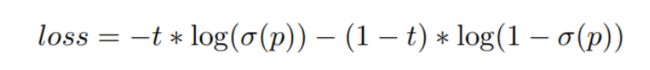
其中t为锚点与ground-truth-bounding box之间的IoU,p为IoU aware branch的原始输出, σ \sigma σ为sigmoid激活函数。注意,只计算阳性样本的IoU aware loss。通过替换损失函数IoU aware branch比以前更好。
最终网络优化效果:

SOTA对比:

2.2ppyolov2_r50vd_dcn_365e_coco行人检测MOT20训练集
模型预测结果:
3、FairMOT模型
3.1 FairMOT模型介绍
作者对影响跟踪器准确性的关键性因素做了以下的分析:
(1)基于Anchor锚点的方法不适合Re-ID
当前的单步法跟踪器都是基于anchor锚的,因为它们是从对象检测器修改而来的。但是,有两个原因造成了锚点不适合学习Re-ID功能。首先,对应于不同图像块的多个锚点可能负责估计同一个目标的 id,这导致严重的歧义(参见图 1)。此外,需要将特征图的大小缩小 1/8,以平衡准确率和速度。对于检测任务而言这是可以接受的,但对于 Re-ID 来说就有些粗糙了,因为目标中心可能无法与在粗糙锚点位置提取的特征一致。文章中提出解决该问题的方法,是通过将MOT问题看作为在高分辨率特征图上的像素级关键点(目标中心)估计和 id 分类问题
(2)多层特征聚合
这对于 MOT 问题尤其重要,因为Re-ID 特征需要利用低级和高级特征来适应小型和大型目标。究者通过实验发现,这对降低 one-shot 方法的 id 转换数量有所帮助,因为它提升了处理尺度变换的能力。
(3)ReID特征的维数
以前的ReID方法通常学习高维特征,并在其基准上取得了可喜的结果。但是,本文发现低维特征实际上对MOT更好,因为它的训练图像比ReID少(由于 Re-ID 数据集仅提供剪裁后的人像,因此 MOT 任务不使用此类数据集)。学习低维特征有助于减少过拟合小数据的风险,并提高跟踪的稳健性。

首先,采用 anchor-free 目标检测方法,估计高分辨率特征图上的目标中心。去掉锚点这一操作可以缓解歧义问题,使用高分辨率特征图可以帮助 Re-ID 特征与目标中心更好地对齐。
1、主干网络
采用ResNet-34 作为主干网络,以便在准确性和速度之间取得良好的平衡。为了适应不同规模的对象,如上图所示,将深层聚合(DLA)的一种变体应用于主干网络。与原始DLA 不同,它在低层聚合和低层聚合之间具有更多的跳跃连接,类似于特征金字塔网络(FPN)。此外,上采样模块中的所有卷积层都由可变形的卷积层代替,以便它们可以根据对象的尺寸和姿势动态调整感受野。 这些修改也有助于减轻对齐问题。
2、物体检测分支
本方法中将目标检测视为高分辨率特征图上基于中心的包围盒回归任务。特别是,将三个并行回归头(regression heads)附加到主干网络以分别估计热图,对象中心偏移和边界框大小。 通过对主干网络的输出特征图应用3×3卷积(具有256个通道)来实现每个回归头(head),然后通过1×1卷积层生成最终目标。
Heatmap Head:这个head负责估计对象中心的位置。这里采用基于热图的表示法,热图的尺寸为1×H×W。 随着热图中位置和对象中心之间的距离,响应呈指数衰减。
Center Offset Head:该head负责更精确地定位对象。ReID功能与对象中心的对齐精准度对于性能至关重要。
Box Size Head:该部分负责估计每个锚点位置的目标边界框的高度和宽度,与Re-ID功能没有直接关系,但是定位精度将影响对象检测性能的评估。
3、id嵌入分支 Identity Embedding Branch
id嵌入分支的目标是生成可以区分不同对象的特征。理想情况下,不同对象之间的距离应大于同一对象之间的距离。为了实现该目标,本方法在主干特征之上应用了具有128个内核的卷积层,以提取每个位置的身份嵌入特征。
4、Loss Functions损失函数
Heatmap Loss:(cxi, cyi)是标签框的中心点,stride=4:
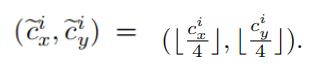
Mxy是heatmap上(x, y)的响应:
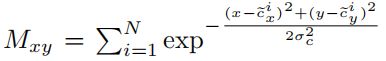
heatmap损失函数:
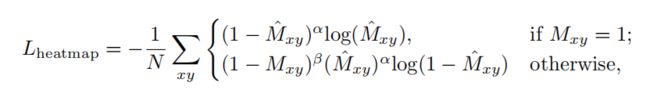
Offset and Size Loss:(x1i, y1i, x2i, y2i)是标签框的坐标, s为框的长和宽,c是中心点:
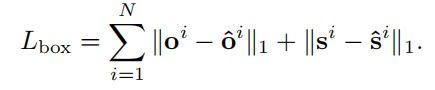
Identity Embedding Loss:

将对象识别嵌入作为分类任务。训练集中具有相同标识的所有对象实例都被视为一个类。
对于图片中的每一个标签框,在heatmap上获得目标中心(cxi, cyi),提取一个恒等特征向量Exi,yi定位并学习将其映射到一个类分布向量p(k),表示标签的one-hot编码为Li(k):
模型效果:

3.2Fairmot_dla34_30e_1088x608行人追踪模型MOT20数据集
cd PaddleDetection
# 使用4卡进行训练
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --log_dir=./fairmot_dla34_30e_1088x608/ --selected_gpus 0,1,2,3 tools/train.py -c /root/paddlejob/workspace/code/fairmot_dla34_30e_1088x608.yml --use_vdl=True -o use_gpu=True
模型训练结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c9q8CRAN-1648986718005)(https://gitee.com/enhengHello/enheng/raw/master/img/202204031801810.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gEAytgea-1648986718006)(https://gitee.com/enhengHello/enheng/raw/master/img/202204031800830.png)]
四、特征提取模型的训练
深度度量学习[metri_learing](models/PaddleCV/metric_learning at develop · PaddlePaddle/models (github.com))
度量学习是一种对样本对学习区分性特征的方法,目的是在特征空间中,让同一个类别的样本具有较小的特征距离,不同类的样本具有较大的特征距离。该项目是基于Paddle官方模型库中的Metric Learning模型开发。
#模型训练
%cd ~/work/metric_learning
!python train_pair.py \
--model ResNet50_vd \
--embedding_size 128 \
--train_batch_size 64 \
--test_batch_size 64 \
--image_shape 3,128,128 \
--class_dim 1421 \
--lr 0.0001 \
--lr_strategy piecewise_decay \
--lr_steps 3000,6000,9000 \
--total_iter_num 10000 \
--display_iter_step 10 \
--test_iter_step 500 \
--save_iter_step 500 \
--use_gpu True \
--loss_name eml \
--samples_each_class 4 \
--margin 0.1 \
--npairs_reg_lambda 0.01
使用的数据集是经典的行人重识别数据集Market-1501。Market-1501 数据集在清华大学校园中采集,夏天拍摄,在 2015 年构建并公开,它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的 1501 个行人、32668 个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。训练集有 751 人,包含 12,936 张图像,平均每个人有 17.2 张训练数据;测试集有 750 人,包含 19,732 张图像,平均每个人有 26.3 张测试数据,3368 张查询图像的行人检测矩形框是人工绘制的,而 gallery 中的行人检测矩形框则是使用DPM检测器检测得到的,该数据集提供的固定数量的训练集和测试集均可以在single-shot或multi-shot测试设置下使用。
五、追踪评测结果
最终团队排名以及评分:

| 网络模型 | 模型输入 | 阈值 | 评测得分 |
|---|---|---|---|
| cascade_Rcnn_r50_vd_fpn_ssld_2x_coco**+metric_learning+**DeepSort | 1333*800 | 0.5 | 0.66619 |
| cascade_Rcnn_r50_vd_fpn_ssld_2x_coco**+metric_learning+**DeepSort | 1333*800 | 0.6 | 0.66958 |
| ppyolov2_r50vd_dcn_365e_coco**+metric_learning+**DeepSort | 608*608 | 0.3 | 0.42889 |
| Fairmot_dla34_30e | 1664*1088 | 0.5 | 0.41753 |
在模型训练完成之后,通过调整检测的阈值可以对追踪效果进一步优化,例如对于cascade_Rcnn_r50_vd_fpn_ssld_2x_coco模型阈值为0.5时评测为0.666当阈值提上到0.6时为0.669,阈值再提高效果开始下降,从而可以推出最好的效果大致在0.669左右。对于其他的两个模型也是如此,通过调整阈值能够使追踪效果有一些小的提升。
引用
[1]前尘忆梦丿MOT2020数据集介绍
[2]HUST小菜鸡-将MOT17-Det数据集转成VOC格式
[3]未完城-多目标跟踪MOT踩坑记录
[4] CrowdHuman: A Benchmark for Detecting Human in a Crowd (arxiv.org)
[[5]韩三岁-ppyolo训练行人检测](PPYOLO训练行人检测模型 - 飞桨AI Studio - 人工智能学习实训社区 (baidu.com))
[6]deep_sort_paddle
[7]_AI之路-CSDN博客_cascade rcnn
[8] Cascade R-CNN: Delving into High Quality Object Detection (arxiv.org)
[9]PaddlePaddle/models /metric_learing
[10]寂寞你快进去:基于度量学习的行人重识别算法
[11] PP-YOLOv2: A Practical Object Detector (arxiv.org)
[12]机器之心:超越YOLOv5的PP-YOLOv2和1.3M超轻量PP-YOLO Tiny都来了!
[13]FairMOT:统一检测、重识别的多目标跟踪框架
](https://github.com/jm12138/deep_sort_paddle)
[7]_AI之路-CSDN博客_cascade rcnn
[8] Cascade R-CNN: Delving into High Quality Object Detection (arxiv.org)
[9]PaddlePaddle/models /metric_learing
[10]寂寞你快进去:基于度量学习的行人重识别算法
[11] PP-YOLOv2: A Practical Object Detector (arxiv.org)
[12]机器之心:超越YOLOv5的PP-YOLOv2和1.3M超轻量PP-YOLO Tiny都来了!
[13]FairMOT:统一检测、重识别的多目标跟踪框架
[14]PaddlePaddle/PaddleDetection: Object detection and instance segmentation toolkit based on PaddlePaddle. (github.com)