【Java牛客刷题第四期】——想让自己算法大幅度提升,这一期你一定不要错过
【Java牛客刷题第四期】——想让自己算法大幅度提升,这一期你一定不要错过
前言:
文章目录,
从易到难,层层递进,如果每一道题都吃透,你一定会在做题方面有质的飞跃,关注我,一起学习算法,一起分享好的题型。博主将持续更新算法,大厂笔试题,经典算法题,易错题,如果觉得不错,点点赞支持一下,如果有错误的地方,欢迎指正✨✨
作者介绍:
作者:偷偷敲代码的青花瓷✨
作者的Gitee:代码仓库
系列文章推荐:
✨1. Java刷题特辑第一期
✨2. Java刷题特辑第二期
✨3. Java刷题特辑第三期
✨✨我和大家一样都是热爱算法✨,很高兴能在此和大家分享知识,希望在分享知识的同时,能和大家一起共同进步,取得好成绩,今天和大家分享的章节是 ,如果有错误❌,欢迎指正哟,咋们废话不多说,跟紧步伐,开始学习吧~

文章目录
- ✨斐波那契系列
- ✨斐波那契凤尾
- ✨客似云来
- ✨养兔子
- ✨日期_年月_计算系列
- ✨淘宝网店
- ✨贪心算法系列
- ✨剪花布条
- ✨字符串系列
- ✨ 收件人列表
- ✨公共子串计算(DP)
- ✨最长公共子序列(DP)
- ✨错排问题系列
- ✨年会抽奖
- ✨发邮件
- ✨读懂题意即可完成系列
- ✨数据库连接池
- ✨mkdir
- ✨总结
✨斐波那契系列
✨斐波那契凤尾
题目描述:
NowCoder号称自己已经记住了1-100000之间所有的斐波那契数。为了考验他,我们随便出一个数n,让他说出第n个斐波那契数。当然,斐波那契数会很大。因此,如果第n个斐波那契数不到6位,则说出该数;否则只说出最后6位。
输入描述:
输入有多组数据。
每组数据一行,包含一个整数n (1≤n≤100000)。
输出描述:
对应每一组输入,输出第n个斐波那契数的最后6位。
示例1
输入
1
2
3
4
100000
输出
1
2
3
5
537501
链接:牛客链接
解题思路:
题目要求输出斐波那契数列的第n项,我们先循环的求出每一项,构造出斐波那契数列,而题目的要求的是后六位,那么我们只需要存储后六位就行了
特别注意:
- 题目思路很简单,但是这道题有一个坑,那就是你不知道斐波那契的第多少项输出的结果是大于6位的,所以这道题我们要去判断一下第几个下标(border)的时候,输出的结构大于等于了6位数,如果输入的 n大于了 border 那么直接输出 “%06d\n” ,如果小于 border 那么输出 “%d\n”
- 注意题上给出的输入输出,我们一般的认为斐波那契数列 是 1 1 2 3 5… 但是这道题给出的输入输出是从 1 2 3 5 … 这样给的所以我们在构建斐波那契数列的时候, 要注意 1 下标所对应的值 此时不是1,而是2
代码如下:
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
//构造斐波那契 数列
int border = 0;//临界下标
long[] a = new long[100000];
a[0] = 1;
a[1] = 2;//题目给的1 下标是 2
for (int i = 2; i < 100000 ; i++) {
a[i] = a[i-1] + a[i-2] ;
if(border == 0 && a[i] >= 1000000) {
border = i;
}
a[i] = a[i] % 1000000;
}
while (sc.hasNext()) {
int n = sc.nextInt();
long b = a[n-1];
if(n < border) {
System.out.printf("%d\n",b);
}else {
System.out.printf("%06d\n",b);
}
}
}
}
✨客似云来
题目描述:
NowCoder开了一家早餐店,这家店的客人都有个奇怪的癖好:他们只要来这家店吃过一次早餐,就会每天都过来;并且,所有人在这家店吃了两天早餐后,接下来每天都会带一位新朋友一起来品尝。
于是,这家店的客人从最初一个人发展成浩浩荡荡成百上千人:1、1、2、3、5……现在,NowCoder想请你帮忙统计一下,某一段时间范围那他总共卖出多少份早餐(假设每位客人只吃一份早餐)。
输入描述:
测试数据包括多组。
每组数据包含两个整数from和to(1≤from≤to≤80),分别代表开店的第from天和第to天。
输出描述:
对应每一组输入,输出从from到to这些天里(包含from和to两天),需要做多少份早餐。
链接:牛客链接
题目解析:
跟上一道题思路一致:
先准备好斐波那契的数组,然后遍历那一段数组,求出他们的和即可。而第80项斐波那契数列是一个17位数,所以需要用long long来解决问题。
代码如下:
import java.util.*;
public class Main{
public static void main(String[] agrs) {
long[] fib = new long[80];
fib[0] = 1;
fib[1] = 1;
for(int i = 2;i < 80; i++) {
fib[i] = fib[i-1] + fib[i-2];
}
Scanner sc = new Scanner(System.in);
while(sc.hasNext()) {
int from = sc.nextInt();
int to = sc.nextInt();
int count = 0;
for(int i = from -1;i <= to-1;i++) {
count += fib[i];
}
System.out.println(count);
}
}
}
✨养兔子
题目描述:
一只成熟的兔子每天能产下一胎兔子。每只小兔子的成熟期是一天。 某人领养了一只小兔子,请问第N天以后,他将会得到多少只兔子。
输入描述:
测试数据包括多组,每组一行,为整数n(1≤n≤90)。
输出描述:
对应输出第n天有几只兔子(假设没有兔子死亡现象)。
示例1
输入
1
2
输出
1
2
链接:牛客链接
解题思路:
本题的兔子第二天就开始下小兔了,所以这个是从第二项开始的斐波那契数列。前90组的数据恰好还在long的范围内,所以不需要高精度,直接long求解。
代码如下:
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
long[] fib = new long[91];
fib[1] = 1;
fib[2] = 2;
for (int i = 3; i < 91 ; i++) {
fib[i] = fib[i-1] + fib[i-2];
}
System.out.println(fib[n]);
}
}
}
✨日期_年月_计算系列
✨淘宝网店
题目描述:
NowCoder在淘宝上开了一家网店。他发现在月份为素数的时候,当月每天能赚1元;否则每天能赚2元。现在给你一段时间区间,请你帮他计算总收益有多少。
输入包含多组数据。
每组数据包含两个日期 from和to (2000-01-01 ≤ from ≤ to ≤ 2999-12-31)。
日期用三个正整数表示,用空格隔开:year month day。
输出描述:
对应每一组数据,输出在给定的日期范围(包含开始和结束日期)内能赚多少钱。
示例1
输入
2000 1 1 2000 1 31
2000 2 1 2000 2 29
输出
62
29
链接:牛客链接
解题思路:
举个例子:
比如 1993年4月3日 ------ 2004年5月4日,我们如何去算这段时间的利润?很简单拆成3部分
- 1993年剩余的时间的利润—>用1993年整体利润去减去当前利润
- [1994,2003]整年的利润
- 2004年5月4日的总利润
这道题,题意和思路很简单,但是代码写起来有点复杂,代码我写的很详细,带着这个思路,看下列代码就行
代码如下:
import java.util.Scanner;
/**
* 淘宝网店
*/
public class Demo4 {
//判断是不是闰年
public static boolean isLeapYear(int year) {
return year % 400 == 0 || (year % 4 == 0 && year % 100 != 0);
}
//判断整年的 利润
public static int profitOfYear(int year) {
return 2 * 31
+ 1 * 28 //这里先都看做是平年,平年二月为28天
+ 1 * 31
+ 2 * 30
+ 1 * 31
+ 2 * 30
+ 1 *31
+ 2 * 31
+ 2 * 30
+ 2 * 31
+ 1 * 30
+ 2 * 31
+ (isLeapYear(year)? 1:0);
}
//判断是不是 素数月
public static boolean isPrime(int month) {
return month == 2 || month == 3 || month == 5 || month == 7 || month == 11;
}
//计算当年的 利润
public static int profitOfThisYear(int year,int month,int day) {
int profit = 0;
if(!isPrime(month)) {
profit = 2 * day;
}else {
profit = day;
}
while (--month > 0) {
switch (month) {
case 1 : case 8 : case 10 : case 12:
profit += 62;
break;
case 3: case 5: case 7:
profit += 31;
break;
case 4: case 6: case 9:
profit +=60;
break;
case 11:
profit += 30;
break;
case 2:
profit += 28 + (isLeapYear(year)?1:0);
break;
}
}
return profit;
}
public static void main(String[] args) {
int year1,month1,day1,year2,month2,day2;
int profit = 0;
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
year1 = sc.nextInt();
month1 = sc.nextInt();
day1 = sc.nextInt();
year2 = sc.nextInt();
month2 = sc.nextInt();
day2 = sc.nextInt();
//1.起始年剩下的 利润 如 2013年1月5日- 2014年4月5日 --> 2013年1月5日之后的利润 + 2014年4月5日的总利润
profit = profitOfYear(year1) - //为什么要day-1因为1月5月的利润是包含在内的
profitOfThisYear(year1,month1,day1-1);
//2.结尾年的利润
profit += profitOfThisYear(year2,month2,day2);
//3.判断是不是同一年
if(year1 == year2) {
profit -= profitOfYear(year1);
}
//4.整年的利润
for (int i = year1+1; i ✨贪心算法系列
✨剪花布条
题目描述:
一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案。对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢?
输入描述:
输入包含多组数据。
每组数据包含两个字符串s,t,分别是成对出现的花布条和小饰条,其布条都是用可见ASCII字符表示的,可见的ASCII字符有多少个,布条的花纹也有多少种花样。花纹条和小饰条不会超过1000个字符长。
输出描述:
对应每组输入,输出能从花纹布中剪出的最多小饰条个数,如果一块都没有,那就输出0,每个结果占一行。
示例1
输入
abcde a3
aaaaaa aa
输出
0
3
链接:牛客链接
解题思路;
题目简单描述下,就是在S串中,T串整体出现了多少次。

代码如下:
import java.util.Scanner;
/**
*
*减花布条
**/
public class Demo5 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String s = sc.nextLine();
String t = sc.nextLine();
System.out.println(cut(s,t));
}
}
public static int cut(String s,String t) {
int i = s.indexOf(t);//返回t首次出现再s中的位置
if(i == -1) {
return 0;
}
return 1 + cut(s.substring(i + t.length()),t);
}
}
✨字符串系列
✨ 收件人列表
题目描述:
NowCoder每天要给许多客户写电子邮件。正如你所知,如果一封邮件中包含多个收件人,收件人姓名之间会用一个逗号和空格隔开;如果收件人姓名也包含空格或逗号,则姓名需要用双引号包含。.现在给你一组收件人姓名,请你帮他生成相应的收件人列表。
输入描述:
输入包含多组数据。
每组数据的第一行是一个整数n (1≤n≤128),表示后面有n个姓名。
紧接着n行,每一行包含一个收件人的姓名。姓名长度不超过16个字符。
输出描述:
对应每一组输入,输出一行收件人列表。
示例1
输入
3
Joe
Quan, William
Letendre,Bruce
2
Leon
Kewell
输出
Joe, "Quan, William", "Letendre,Bruce"
Leon, Kewell
链接:牛客链接
解题思路:
基础的字符串处理问题,题干非常清晰
- 先接受到一个数字,代表接下来是多少数据
- 逐个接收每个名字,如果名字中没有
','或者' '则直接初出,否者在改名字前后拼接"'\"再输出- 除最后一个名字外,每个名字之后都有一个
","- 注意用例处理完换行
代码如下:
import java.util.Scanner;
/**
* 牛客 收件人列表
*/
public class Demo6 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
sc.nextLine();//改行代码非常关键,将数字所在行之后的内容接收完
for (int i = 0; i < n; i++) {
String name = sc.nextLine();
if(name.contains(",") || name.contains(" ") ) {
System.out.print("\"" + name + "\"");
}else{
System.out.print(name);
}
//收件人姓名之间用 逗号 和 空格 分开 注意:最后一个位置是没有的
if(i != n-1) {
System.out.print(", ");
}
}
System.out.println();
}
}
}
✨公共子串计算(DP)
题目描述:
给定两个只包含小写字母的字符串,计算两个字符串的最大公共子串的长度。
注:子串的定义指一个字符串删掉其部分前缀和后缀(也可以不删)后形成的字符串。
数据范围:字符串长度:1\le s\le 150\1≤s≤150
进阶:时间复杂度:O(n^3)\O(n 3 ) ,空间复杂度:O(n)\O(n)
输入描述:
输入两个只包含小写字母的字符串
输出描述:
输出一个整数,代表最大公共子串的长度
示例1
输入:
asdfas
werasdfaswer
复制
输出:
6
链接:牛客链接
在之前的刷题笔记当中,这道题也出现过,想了解更多
DP题目请点击:【Java刷题特辑第二章】
如果对DP问题解题思路,不够清楚,不知道从何下手请点击:算法篇之动态规划
解题思路:

代码如下:
public class Demo5 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String str1 = sc.nextLine();
String str2 = sc.nextLine();
System.out.println(func(str1,str2));
}
}
public static int func(String str1,String str2){
int len1 = str1.length();
int len2 = str2.length();
char[] A = str1.toCharArray();//字符串转字符串数组
char[] B = str2.toCharArray();
int max = 0;
int[][] dp = new int[len1 + 1][len2 +1];
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if(A[i-1] == B[j-1]) {
dp[i][j] = dp[i-1][j-1] + 1;
}
if(max < dp[i][j]) {
max = dp[i][j];
}
}
}
return max;
}
}
✨最长公共子序列(DP)
题目描述:
我们有两个字符串m和n,如果它们的子串a和b内容相同,则称a和b是m和n的公共子序列。子串中的字符不一定在原字符串中连续。
例如字符串“abcfbc”和“abfcab”,其中“abc”同时出现在两个字符串中,因此“abc”是它们的公共子序列。此外,“ab”、“af”等都是它们的字串。现在给你两个任意字符串(不包含空格),请帮忙计算它们的最长公共子序列的长度。
输入描述:
输入包含多组数据。
每组数据包含两个字符串m和n,它们仅包含字母,并且长度不超过1024。
输出描述:
对应每组输入,输出最长公共子序列的长度。
示例1
输入
abcfbc abfcab
programming contest
abcd mnp
输出
4
2
0
链接:牛客链接
解题思路:
首先,
这道题题目要求的是求最长公共子序列(子串可以不连续),而上一道题求公共子串(子串连续),切勿混淆
注意:这道题和上一道题,区别在于本题 子串不连续,所以我们应该考虑两种情况(思路和上一道题类似)
- 如果连续:则
DP[i][j] == DP[i-1][j-1] + 1 - 如果不连续:我们需要在
DP[i-1][j] 和 DP[i][j-1]中取最大值即dp[i][j] = max(dp[i-1][j],dp[i][j-1]) - 最后返回
DP[len1][len2],len1和len2分别为两个字符串的长度
代码如下:
import java.util.Scanner;
// 牛客 最长公共子序列
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String str1 = sc.next();
String str2 = sc.next();
System.out.println(func(str1,str2));
}
}
public static int func(String str1,String str2) {
int len1 = str1.length();
int len2 = str2.length();
int[][] DP = new int[len1 + 1][len2 + 1];
for (int i = 1; i <= len1 ; i++) {
for (int j = 1; j <= len2 ; j++) {
// 如果 arr[i-1] == arr[j-1]
if(str1.charAt(i-1) == str2.charAt(j-1)) {
DP[i][j] = DP[i-1][j-1] + 1;
}else {
// 如果不相等,在 dp[i-1][j] 和 dp[i][j-1 中取最大值
DP[i][j] = Math.max(DP[i-1][j],DP[i][j-1]);
}
}
}
return DP[len1][len2];
}
}
这里我发现了个 牛客上的 bug 不知道咋回事
如果 最长公共子序列这道题 控制台输入是 sc.nextLine() 代码通不过 ???
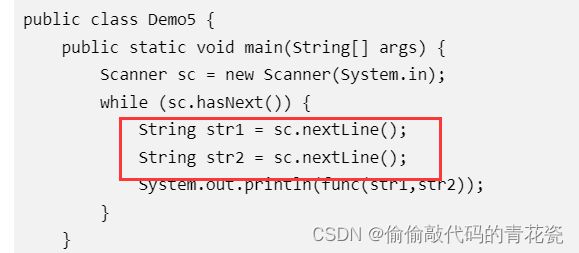
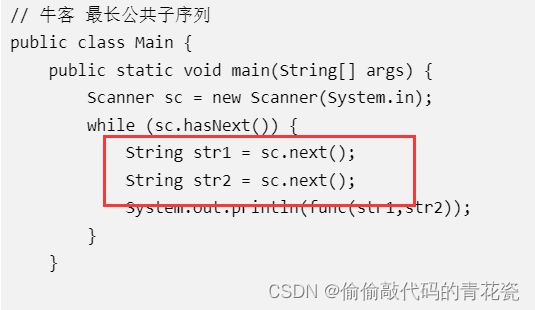
✨错排问题系列
✨年会抽奖
题目描述:
今年公司年会的奖品特别给力,但获奖的规矩却很奇葩:
- 首先,所有人员都将一张写有自己名字的字条放入抽奖箱中;
- 待所有字条加入完毕,每人从箱中取一个字条;
- 如果抽到的字条上写的就是自己的名字,那么“恭喜你,中奖了!”
现在告诉你参加晚会的人数,请你计算有多少概率会出现无人获奖?
输入描述:
输入包含多组数据,每组数据包含一个正整数n(2≤n≤20)
输出描述:
对应每一组数据,以“xx.xx%”的格式输出发生无人获奖的概率。
示例1
输入
2
输出
50.00%
链接:牛客链接
解题思路:
解这道题之前,我们需要明白 什么时候才算都不获奖?全部都不获奖的概率如何计算?对于 什么时候才算都 不获奖,当然是所有人都拿到了别人的名字,没有拿到自己的名字
全部都不获奖的概率 必定是由 n个人都拿错的情况种数 除 n个人都拿出的所有排列情况数
推导:
假设
a的名字没有被a拿到,其他n - 1个人都有可能拿到,即有n - 1种情况。假设b拿到了a的名字,那么对于b的名字有两种情况
- 第一种是
b的名字被a拿到了,也就是a、b互相拿到了对方的名字,那么对于其他n - 2个人互相拿错又是一个子问题f(n - 2). - 第二种是
b的名字没有被a拿到,则剩下的问题是子问题f(n - 1).
因此可得递推公式f(n) = (n - 1) * (f(n - 1) + f(n - 2)).
最终得出公式n人都不获奖的概率h(n) = (n - 1) * (f(n - 1) + f(n - 2)) / (n!).
错排问题举例:
用A、B、C……表示写着n位友人名字的信封,a、b、c……表示n份相应的写好的信纸。把错装的总数为记作D(n)。假设把a错装进B里了,包含着这个错误的一切错装法分两类:
- b装入A里,这时每种错装的其余部分都与A、B、a、b无关,应有D(n-2)种错装法。
- b装入A、B之外的一个信封,这时的装信工作实际是把(除a之外的)n-1份信纸b、c……装入(除B以外的)n-1个信封A、C……,显然这时装错的方法有D(n-1)种。
总之在a装入B的错误之下,共有错装法D(n-2)+D(n-1)种。
a装入C,装入D……的n-2种错误之下,同样都有D(n-1)+D(n-2)种错装法,因此D(n)=(n-1)[D(n-1)+D(n-2)] --------------->D(n) = (n-1) [D(n-2) + D(n-1)]
特殊地,D(1) = 0, D(2) = 1.
所以这道题的总体思路:
错排的递推公式是:
D(n) = (n - 1) [D(n - 2) + D(n - 1)],也就是第n项为n - 1倍的前两项和。通过这个递推公式可以得到在总数为n的时候,错排的可能性一共有多少种。那么要求错排的概率,我们还需要另一个数值,就是当总数为n的时候,所有的排列组合一共有多少种,那么根据排列组合,肯定是使用
的公式来求,也就是n的阶乘。所以结果很简单,就是用公式求出第n项的错排种类,和n的阶乘,然后两者一除,就是概率了。
代码如下:
import java.util.Scanner;
public class Demo3 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// p(无人获奖) = 都没获奖的情况/n个人抽取的情况
// 无一人获奖的 情况 D(n)
long[] a = new long[21]; //错排特殊情况 D[1] = 0 D[2] =1
a[0] = a[1] = 0;
a[2] = 1;
long[] b = new long[21]; // 阶乘
b[0] = b[1] = 1;
b[2] = 2;
// 算N错排数据和阶乘
for (int i = 3; i <= 20 ; i++) {
a[i] = (i-1)*(a[i-1] + a[i-2]);
b[i] = b[i-1] * i;
}
while (sc.hasNext()) {
int n = sc.nextInt();
System.out.printf("%.2f%%\n",100.0*a[n]/b[n]);
}
}
}
✨发邮件
题目描述:
NowCoder每天要给很多人发邮件。有一天他发现发错了邮件,把发给A的邮件发给了B,把发给B的邮件发给了A。于是他就思考,要给n个人发邮件,在每个人仅收到1封邮件的情况下,有多少种情况是所有人都收到了错误的邮件?即没有人收到属于自己的邮件。
输入描述:
输入包含多组数据,每组数据包含一个正整数n(2≤n≤20)。
输出描述:
对应每一组数据,输出一个正整数,表示无人收到自己邮件的种数。
示例1
输入
2
3
输出
1
2
链接:牛客链接
解题思路:
这道题和上一道思路一模一样,也是典型的错排问题,这道题,根据题目意思,要求我们去求,所有人收到错误的邮件的情况,如何推导,这里不在赘述
代码如下:
import java.util.Scanner;
// 牛客 发邮件 错排问题
public class Demo4 {
public static void main(String[] args) {
//错排情况
long[] D = new long[21];
D[0] = D[1] = 0;
D[2] = 1;
for (int i = 3; i <= 20 ; i++) {
D[i] = (i-1) * (D[i-1] + D[i-2]);
}
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
System.out.println(D[n]);
}
}
}
✨读懂题意即可完成系列
✨数据库连接池
题目描述:
Web系统通常会频繁地访问数据库,如果每次访问都创建新连接,性能会很差。为了提高性能,架构师决定复用已经创建的连接。当收到请求,并且连接池中没有剩余可用的连接时,系统会创建一个新连接,当请求处理完成时该连接会被放入连接池中,供后续请求使用。现在提供你处理请求的日志,请你分析一下连接池最多需要创建多少个连接。
输入描述:
输入包含多组数据,每组数据第一行包含一个正整数n(1≤n≤1000),表示请求的数量。
紧接着n行,每行包含一个请求编号id(A、B、C……、Z)和操作(connect或disconnect)。
输出描述:
对应每一组数据,输出连接池最多需要创建多少个连接。
示例1
输入
6
A connect
A disconnect
B connect
C connect
B disconnect
C disconnect
输出
2
链接:牛客链接
解题思路:
循环接收每组用例,对于每组用例进行如下操作
- 依次获取每个状态,如果该状态是connect,则将其id插入到set中,否则删除该id
- 获取从刚开始到目前set中的最大值
- 输出结果
代码如下:
import java.util.*;
// 牛客 数据库连接池
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
int max = 0;
// 每一行有 n条 记录
Set s = new HashSet<>();
while ( n != 0) {
String id,record;
id = sc.next();
record = sc.next();
// 如果是改记录是链接,将其id插入到set中,否则删除
if(record.equals("connect")) {
s.add(id);
}else {
s.remove(id);
}
max = Math.max(max,s.size());
n--;
}
System.out.println(max);
}
}
}
✨mkdir
题目描述:
工作中,每当要部署一台新机器的时候,就意味着有一堆目录需要创建。例如要创建目录“/usr/local/bin”,就需要此次创建“/usr”、“/usr/local”以及“/usr/local/bin”。好在,Linux下mkdir提供了强大的“-p”选项,只要一条命令“mkdir -p /usr/local/bin”就能自动创建需要的上级目录。现在给你一些需要创建的文件夹目录,请你帮忙生成相应的“mkdir -p”命令。
输入描述:
输入包含多组数据。
每组数据第一行为一个正整数n(1≤n≤1024)。
紧接着n行,每行包含一个待创建的目录名,目录名仅由数字和字母组成,长度不超过200个字符。
输出描述:
对应每一组数据,输出相应的、按照字典顺序排序的“mkdir -p”命令。
每组数据之后输出一个空行作为分隔。
示例1
输入
3
/a
/a/b
/a/b/c
3
/usr/local/bin
/usr/bin
/usr/local/share/bin
输出
mkdir -p /a/b/c
mkdir -p /usr/bin
mkdir -p /usr/local/bin
mkdir -p /usr/local/share/bin
链接:牛客链接
解题思路:
循环接收获取每组用例,对于每组用例进行如下操作:
对该组用例按照字典顺序排序将该数组用例中相等的或者前一个是后一个子串的路径剔除输入结果并换行
注意:
如果目录结构为如下:/ab 为 二级目录 /a/b为三级目录,我们需要判断 /ab的结尾是不是‘/’
/a
/ab
/a/b
代码如下:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int n = sc.nextInt();
// 接收 n 条路径
String[] path = new String[n];
for (int i = 0; i < n; i++) {
path[i] = sc.next();
}
// 对 path中的 n条路径进行排序
Arrays.sort(path);
// 将数组中:相等的元素一级前一个是后一个淄川的字符串剔除
// 注意:此处采用标记法删除
boolean[] flag = new boolean[n];
for (int i = 0; i < n - 1; i++) {
// 相同目录
if(path[i].equals(path[i+1])) {
flag[i] = true;//剔除
}else if(path[i].length() < path[i+1].length() &&
path[i+1].contains(path[i]) && path[i+1].charAt(path[i].length())=='/') {
flag[i] = true;//剔除
}
}
//输出
for (int i = 0; i < n; i++) {
if(!flag[i]) {
System.out.println("mkdir -p " +path[i]);
}
}
//给空行
System.out.println();
}
}
}
✨总结
“种一颗树最好的是十年前,其次就是现在”
所以,
“让我们一起努力吧,去奔赴更高更远的山海”
如果有错误❌,欢迎指正哟
如果觉得收获满满,可以动动小手,点点赞,支持一下哟
