【一起入门DeepLearning】中科院深度学习_期末复习题2018-2019第二题:求梯度
专栏介绍:本栏目为 “2022春季中国科学院大学王亮老师的深度学习” 课程记录,这门课程与自然语言处理以及机器学习有部分知识点重合,重合的部分不再单独开博客记录了,有需要的读者可以移步 自然语言处理专栏和机器学习专栏。 如果感兴趣的话,就和我一起入门DL吧
2018-2019 学年第二学期期末试题
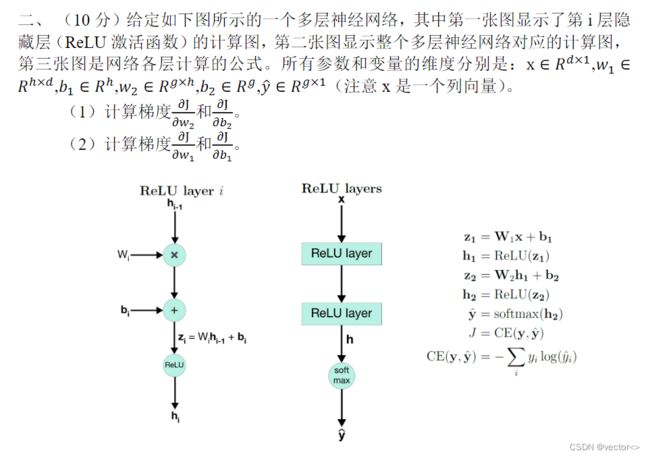
想了解梯度下降算法可以看这篇博客:【一起入门NLP】中科院自然语言处理第3课-前馈神经网络DNN(反向传播+梯度下降),这个题目完全是数学问题,一个很难算的数学问题下面是两位师兄的参考答案:
答案一:
∂ J ∂ w 2 = ∂ J ∂ y ^ ∂ y ^ ∂ h 2 ∂ h 2 ∂ z 2 ∂ z 2 ∂ w 2 = ( y ^ ∗ ∑ j y j − y i ) ∗ Relu ( z 2 ) ∗ h 1 \frac{\partial J}{\partial w_{2}}=\frac{\partial J}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial h_{2}} \frac{\partial h_{2}}{\partial z_{2}} \frac{\partial z_{2}}{\partial w_{2}}=\left(\hat{y} * \sum_{j} y_{j}-y_{i}\right) * \operatorname{Relu}\left(z_{2}\right) * h_{1} ∂w2∂J=∂y^∂J∂h2∂y^∂z2∂h2∂w2∂z2=(y^∗∑jyj−yi)∗Relu(z2)∗h1
∂ J ∂ b 2 = ∂ J ∂ y ^ ∂ y ^ ∂ h 2 ∂ h 2 ∂ z 2 ∂ z 2 ∂ b 2 = ( y ^ ∗ ∑ j y j − y i ) ∗ Relu ′ ( z 2 ) \frac{\partial J}{\partial b_{2}}=\frac{\partial J}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial h_{2}} \frac{\partial h_{2}}{\partial z_{2}} \frac{\partial z_{2}}{\partial b_{2}}=\left(\hat{y} * \sum_{j} y_{j}-y_{i}\right) * \operatorname{Relu}^{\prime}\left(z_{2}\right) ∂b2∂J=∂y^∂J∂h2∂y^∂z2∂h2∂b2∂z2=(y^∗∑jyj−yi)∗Relu′(z2)
∂ J ∂ w 1 = ∂ J ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 1 = ( y ^ ∗ ∑ j y j − y i ) ∗ Relu ( z 2 ) ∗ w 1 ∗ Relu ( z 1 ) ∗ x \frac{\partial J}{\partial w_{1}}=\frac{\partial J}{\partial h_{2}} \frac{\partial h_{2}}{\partial h_{1}} \frac{\partial h_{1}}{\partial z_{1}} \frac{\partial z_{1}}{\partial w_{1}}=\left(\hat{y} * \sum_{j} y_{j}-y_{i}\right) * \operatorname{Relu}\left(z_{2}\right) * w_{1} * \operatorname{Relu}\left(z_{1}\right) * x ∂w1∂J=∂h2∂J∂h1∂h2∂z1∂h1∂w1∂z1=(y^∗∑jyj−yi)∗Relu(z2)∗w1∗Relu(z1)∗x
∂ J ∂ b 1 = ∂ J ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ b 1 = ( y ^ ∗ ∑ j y j − y i ) ∗ Relu ( z 2 ) ∗ w 1 ∗ Rel u ′ ( z 1 ) \frac{\partial J}{\partial b_{1}}=\frac{\partial J}{\partial h_{2}} \frac{\partial h_{2}}{\partial h_{1}} \frac{\partial h_{1}}{\partial z_{1}} \frac{\partial z_{1}}{\partial b_{1}}=\left(\hat{y} * \sum_{j} y_{j}-y_{i}\right) * \operatorname{Relu}\left(z_{2}\right) * w_{1} * \operatorname{Rel} u^{\prime}\left(z_{1}\right) ∂b1∂J=∂h2∂J∂h1∂h2∂z1∂h1∂b1∂z1=(y^∗∑jyj−yi)∗Relu(z2)∗w1∗Relu′(z1)
答案二:
1. 将各层的计算公式按标量形式展开,下标中带括号的表示在矩阵或向量中对应的位置:
z 1 ( j ) = ∑ m = 1 d W 1 ( j m ) x ( m ) + b 1 ( j ) z_{1(j)}=\sum_{m=1}^{d} W_{1(j m)} x_{(m)}+b_{1(j)} z1(j)=∑m=1dW1(jm)x(m)+b1(j)
h 1 ( j ) = Re L U ( z 1 ( j ) ) h_{1(j)}=\operatorname{Re} L U\left(z_{1(j)}\right) h1(j)=ReLU(z1(j))
z 2 ( i ) = ∑ n = 1 h W 2 ( i n ) h 1 ( n ) + b 2 ( i ) z_{2(i)}=\sum_{n=1}^{h} W_{2(i n)} h_{1(n)}+b_{2(i)} z2(i)=∑n=1hW2(in)h1(n)+b2(i)
h 2 ( i ) = Re L U ( z 2 ( i ) ) h_{2(i)}=\operatorname{Re} L U\left(z_{2(i)}\right) h2(i)=ReLU(z2(i))
y ( i ) = soft max ( h 2 ( i ) ) = e h 2 ( i ) ∑ g e h 2 ( i ) ) y_{(i)}=\operatorname{soft} \max \left(h_{2(i)}\right)=\frac{e^{h_{2(i)}}}{\sum^{g}} e^{\left.h_{2(i)}\right)} y(i)=softmax(h2(i))=∑geh2(i)eh2(i))
J = C E ( y , y ^ ) = − ∑ i ′ = 1 g y ( i ′ ) log ( y ^ ( i ′ ) ) J=C E(y, \hat{y})=-\sum_{i^{\prime}=1}^{g} y_{\left(i^{\prime}\right)} \log \left(\hat{y}_{\left(i^{\prime}\right)}\right) J=CE(y,y^)=−∑i′=1gy(i′)log(y^(i′))
2. 计算交叉熵的导数:
∂ J ∂ ( y ^ ( i ′ ) ) = − y ( i ′ ) y ^ ( i ′ ) \frac{\partial J}{\partial\left(\hat{y}_{\left(i^{\prime}\right)}\right)}=-\frac{y_{\left(i^{\prime}\right)}}{\hat{y}_{\left(i^{\prime}\right)}} ∂(y^(i′))∂J=−y^(i′)y(i′)
3. Softmax求导:
当 k = i \mathrm{k}=\mathrm{i} k=i 时
∂ y ^ ( i ) ∂ h 2 ( k ) = ∂ y ^ ( i ) ∂ h 2 ( i ) = e h 2 ( i ) ∑ i ′ = 1 g e h 2 ( i ) − ( e h 2 ( i ) ) 2 ( ∑ i ′ = 1 g e h 2 ( i ) ) 2 = y ^ ( i ) ( 1 − y ^ ( i ) ) \frac{\partial \hat{y}_{(i)}}{\partial h_{2(k)}}=\frac{\partial \hat{y}_{(i)}}{\partial h_{2(i)}}=\frac{e^{h_{2(i)}} \sum_{i^{\prime}=1}^{g} e^{h_{2(i)}}-\left(e^{h_{2(i)}}\right)^{2}}{\left(\sum_{i^{\prime}=1}^{g} e^{h_{2(i)}}\right)^{2}}=\hat{y}_{(i)}\left(1-\hat{y}_{(i)}\right) ∂h2(k)∂y^(i)=∂h2(i)∂y^(i)=(∑i′=1geh2(i))2eh2(i)∑i′=1geh2(i)−(eh2(i))2=y^(i)(1−y^(i))
当 k ≠ i k \neq i k=i 时
∂ y ^ ( i ) ∂ h 2 ( k ) = − e h 2 ( i ) e h 2 ( k ) ( ∑ i ′ = 1 g e h 2 ( i ) ) 2 = − y ^ ( i ) y ^ ( k ) \frac{\partial \hat{y}_{(i)}}{\partial h_{2(k)}}=-\frac{e^{h_{2(i)}} e^{h_{2(k)}}}{\left(\sum_{i^{\prime}=1}^{g} e^{h_{2(i)}}\right)^{2}}=-\hat{y}_{(i)} \hat{y}_{(k)} ∂h2(k)∂y^(i)=−(∑i′=1geh2(i))2eh2(i)eh2(k)=−y^(i)y^(k)
4. ReLU求导
∂ ReLU ( x ) ∂ x = u ( x ) \frac{\partial \operatorname{ReLU}(x)}{\partial x}=u(x) ∂x∂ReLU(x)=u(x), 其中 u ( x ) u(x) u(x) 为阶跃函数
(1)
∂ J ∂ W 2 ( i n ) = ∑ i ′ = 1 g ∂ J ∂ y ^ ( i i ) ∂ y ^ ( i ′ ) ∂ h 2 ( i ) ∂ h 2 ( i ) ∂ z 2 ( i ) ∂ z 2 ( i ) ∂ W 2 ( i n ) = − [ y ( i ) y ^ ( i ) y ^ ( i ) ( 1 − y ^ ( i ) ) − ∑ k ≠ i y ( k ) y ^ ( k ) y ^ ( i ) y ^ ( k ) ] u ( z 2 ( i ) ) h 1 ( n ) = u ( z 2 ( i ) ) h 1 ( n ) [ − y ( i ) ( 1 − y ^ ( i ) ) + ∑ k ≠ i y ( k ) y ^ ( i ) ] = u ( z 2 ( i ) ) h 1 ( n ) [ − y ( i ) + ∑ k = 1 g y ( k ) y ^ ( i ) ] = u ( z 2 ( i ) ) h 1 ( n ) ( y ^ ( i ) − y ( i ) ) 同理可知 ∂ J ∂ b 2 ( i ) = u ( z 2 ( i ) ) ( y ^ ( i ) − y ( i ) ) \begin{aligned} &\frac{\partial J}{\partial W_{2(i n)}}=\sum_{i^{\prime}=1}^{g} \frac{\partial J}{\partial \hat{y}_{\left(i^{i}\right)}} \frac{\partial \hat{y}_{\left(i^{\prime}\right)}}{\partial h_{2(i)}} \frac{\partial h_{2(i)}}{\partial z_{2(i)}} \frac{\partial z_{2(i)}}{\partial W_{2(i n)}} \\ &=-\left[\frac{y_{(i)}}{\hat{y}_{(i)}} \hat{y}_{(i)}\left(1-\hat{y}_{(i)}\right)-\sum_{k \neq i} \frac{y_{(k)}}{\hat{y}_{(k)}} \hat{y}_{(i)} \hat{y}_{(k)}\right] u\left(z_{2(i)}\right) h_{1(n)} \\ &=u\left(z_{2(i)}\right) h_{1(n)}\left[-y_{(i)}\left(1-\hat{y}_{(i)}\right)+\sum_{k \neq i} y_{(k)} \hat{y}_{(i)}\right] \\ &=u\left(z_{2(i)}\right) h_{1(n)}\left[-y_{(i)}+\sum_{k=1}^{g} y_{(k)} \hat{y}_{(i)}\right] \\ &=u\left(z_{2(i)}\right) h_{1(n)}\left(\hat{y}_{(i)}-y_{(i)}\right) \\ &\text { 同理可知 } \\ &\frac{\partial J}{\partial b_{2(i)}}=u\left(z_{2(i)}\right)\left(\hat{y}_{(i)}-y_{(i)}\right) \end{aligned} ∂W2(in)∂J=i′=1∑g∂y^(ii)∂J∂h2(i)∂y^(i′)∂z2(i)∂h2(i)∂W2(in)∂z2(i)=−⎣⎡y^(i)y(i)y^(i)(1−y^(i))−k=i∑y^(k)y(k)y^(i)y^(k)⎦⎤u(z2(i))h1(n)=u(z2(i))h1(n)⎣⎡−y(i)(1−y^(i))+k=i∑y(k)y^(i)⎦⎤=u(z2(i))h1(n)[−y(i)+k=1∑gy(k)y^(i)]=u(z2(i))h1(n)(y^(i)−y(i)) 同理可知 ∂b2(i)∂J=u(z2(i))(y^(i)−y(i))
(2)
∂ J ∂ w 1 ( j m ) = ∑ i ′ = 1 g ∂ J ∂ y ^ ( i ′ ) ∂ y ^ ( i ′ ) ∂ h 2 ( i ) ∂ h 2 ( i ) ∂ z 2 ( i ) ∂ z 2 ( i ) ∂ w 1 ( j m ) = ∑ i ′ = 1 g u ( z 2 ( i ′ ) ) ( y ^ ( i ′ ) − y ( i ′ ) ) W 2 ( i ′ j ) u ( z 1 ( j ) ) ∑ m = 1 d x ( m ) = u ( z 1 ( j ) ) ∑ m = 1 d x ( m ) ∑ i ′ = 1 g u ( z 2 ( i ′ ) ) ( y ^ ( i ′ ) − y ( i ′ ) ) W 2 ( i ′ j ) \begin{aligned} &\frac{\partial J}{\partial w_{1(j m)}}=\sum_{i^{\prime}=1}^{g} \frac{\partial J}{\partial \hat{y}_{\left(i^{\prime}\right)}} \frac{\partial \hat{y}_{\left(i^{\prime}\right)}}{\partial h_{2(i)}} \frac{\partial h_{2(i)}}{\partial z_{2(i)}} \frac{\partial z_{2(i)}}{\partial w_{1(j m)}} \\ &=\sum_{i^{\prime}=1}^{g} u\left(z_{2\left(i^{\prime}\right)}\right)\left(\hat{y}_{\left(i^{\prime}\right)}-y_{\left(i^{\prime}\right)}\right) W_{2\left(i^{\prime} j\right)} u\left(z_{1(j)}\right) \sum_{m=1}^{d} x_{(m)} \\ &=u\left(z_{1(j)}\right) \sum_{m=1}^{d} x_{(m)} \sum_{i^{\prime}=1}^{g} u\left(z_{2\left(i^{\prime}\right)}\right)\left(\hat{y}_{\left(i^{\prime}\right)}-y_{\left(i^{\prime}\right)}\right) W_{2\left(i^{\prime} j\right)} \end{aligned} ∂w1(jm)∂J=i′=1∑g∂y^(i′)∂J∂h2(i)∂y^(i′)∂z2(i)∂h2(i)∂w1(jm)∂z2(i)=i′=1∑gu(z2(i′))(y^(i′)−y(i′))W2(i′j)u(z1(j))m=1∑dx(m)=u(z1(j))m=1∑dx(m)i′=1∑gu(z2(i′))(y^(i′)−y(i′))W2(i′j)
同理可得
∂ J ∂ b 1 ( j ) = u ( z 1 ( j ) ) ∑ i ′ = 1 g u ( z 2 ( i ′ ) ) ( y ^ ( i ′ ) − y ( i ′ ) ) W 2 ( i ′ j ) \frac{\partial J}{\partial b_{1(j)}}=u\left(z_{1(j)}\right) \sum_{i^{\prime}=1}^{g} u\left(z_{2\left(i^{\prime}\right)}\right)\left(\hat{y}_{\left(i^{\prime}\right)}-y_{\left(i^{\prime}\right)}\right) W_{2\left(i^{\prime} j\right)} ∂b1(j)∂J=u(z1(j))i′=1∑gu(z2(i′))(y^(i′)−y(i′))W2(i′j)