深度学习实现场景字符识别模型|代码干货


作者|李秋键
出品|AI科技大本营(ID:rgznai100)
# 前言 #
文字是人从日常交流中语音中演化出来,用来记录信息的重要工具。文字对于人类意义非凡,以中国为例,中国地大物博,各个地方的口音都不统一,但是人们使用同一套书写体系,使得即使远隔千里,我们依然能够通过文字进行无障碍的沟通。文字也能够跨越时空,给予了我们了解古人的通道。随着计算机的诞生,文字也进行了数字化的进程,但是不同于人类,让计算机能够正确地进行字符识别是一个复杂又艰巨但意义重大的工作。从计算机诞生开始,无数的研究者在这方面做了很多工作与尝试,但面临的困难艰巨。
其中场景文字识别中主要面临的困难是:
(1)场景复杂变化很大;
(2)字体形态颜色多变;
(3)光照条件变化大;
(4)文字排列方式不确定;
(5)文本行与文本行之间的距离,大小格式,字体变化大。
而深度学习的引入,使得在我们在复杂场景下进行字符识别更为便利。
本项目通过使用pytorch搭建resnet迁移学习模型实现对复杂场景下字符的识别。其模型训练过程如下图可见:

# 1.基本介绍#
文字是人从日常交流中语音中演化出来,用来记录信息的重要工具。文字对于人类意义非凡,以中国为例,中国地大物博,各个地方的口音都不统一,但是人们使用同一套书写体系,使得即使远隔千里,我们依然能够通过文字进行无障碍的沟通。文字也能够跨越时空,给予了我们了解古人的通道。随着计算机的诞生,文字也进行了数字化的进程,但是不同于人类,让计算机能够正确地进行字符识别是一个复杂又艰巨但意义重大的工作。从计算机诞生开始,无数的研究者在这方面做了很多工作与尝试,但面临的困难艰巨。
1.1
环境要求
本次环境使用的是python3.6.5+windows平台。
主要用的库有:Opencv-python模块、Pillow模块、PyTorch模块。
Opencv-python模块:
opencv-python是一个Python绑定库,旨在解决计算机视觉问题。其使用Numpy,这是一个高度优化的数据库操作库,具有MATLAB风格的语法。所有Opencv数组结构都转换为Numpy数组。这也使得与使用Numpy的其他库(如Scipy和Matplotlib)集成更容易。
Pillow模块:
Pillow是Python里的图像处理库,它提供了了广泛的文件格式支持和强大的图像处理能力,主要包括图像储存、图像显示、格式转换以及基本的图像处理操作等。
PyTorch模块
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多其他的主流框架都不支持的。PyTorch还提供了两个高级功能:1.具有强大的GPU加速的张量计算2.包含自动求导系统的深度神经网络 除了Facebook之外,Twitter、GMU和Salesforce等机构都采用了PyTorch。
1.2
迁移模型
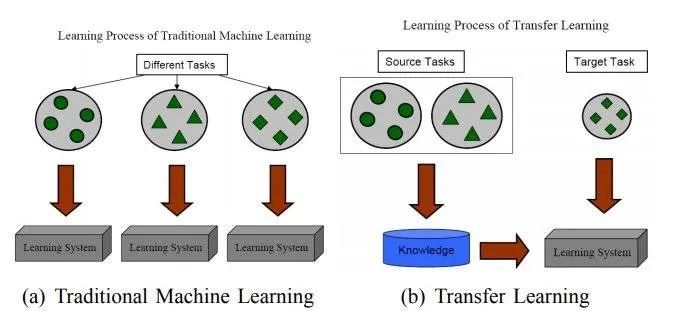
迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。
由下图可以看出迁移学习和传统机器学习的区别,在传统机器学习的学习过程中,我们试图单独学习每一个学习任务,即生成多个学习系统;而在迁移学习中,我们试图将在前几个任务上学到的知识转移到目前的学习任务上,从而将其结合起来。
# 2.算法模型#
在这里我们使用的是resnet模型对图像进行特征提取。其中图像特征提取通常使用卷积神经网络进行特征学习,由于字符识别相较于物体分类的不同,通常不会完全照搬分类网络来直接进行图形特征提取,会在分类网络的基础上为了适应目标任务的改进。
由于卷积神经网络会受到感受野的限制,因此提出了需要使用序列特征提取模型对特征进行建模,学习卷积神经网络提取到的图像特征之间的上下文关系。
2.1
数据集准备
在这里我们将训练的数据集分成了训练集、测试集和验证集三部分。其中准备的数据集如下:

2.2
数据处理
为了保证每次运行模型效果基本相同,这里设置随机种子,同时torch.backends.cudnn.deterministic将这个flag置为True。然后进行图像变换transforms,shffule=True在表示不同批次的数据遍历时,打乱顺序。num_workers=0表示使用0个子进程来加载数据。代码如下:
SVHNDataset(train_path, train_label,
transforms.Compose([
# 图像尺寸变换(resize) ——transforms.Resize
transforms.Resize((64, 128)),
# 随机裁剪:transforms.RandomCrop。size(sequence 或int)
transforms.RandomCrop((60, 120)),
# 修改亮度、对比度和饱和度:transforms.ColorJitter。亮度。对比度。饱和度。。。
transforms.ColorJitter(0.3, 0.3, 0.2),
# 随机旋转:transforms.RandomRotation。degrees(sequence 或float或int) -要选择的度数范围
transforms.RandomRotation(5),
# 将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1]
transforms.ToTensor(),
# 标准化:transforms.Normalize。用平均值和标准偏差归一化张量图像。mean每个通道的均值序列。std每个通道的标准偏差序列。
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=40,
shuffle=True,
num_workers=0
)
2.3
resnet模型搭建
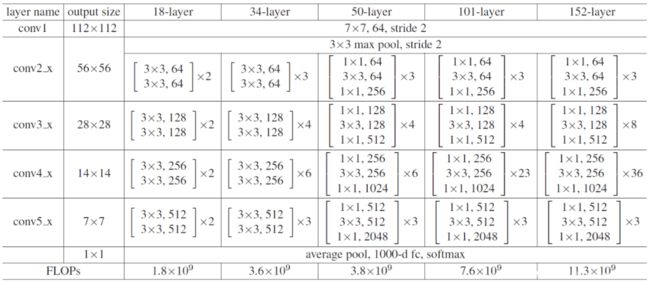
这里采用的resnet18模型是由17个卷积层(conv)+1个全连接层(fc)构成。其中使用resnet模型的主要优势在于,当逐渐增加神经网络的深度时,网络难以学习恒等函数的参数,导致最后的训练效果往往达不到预期,也会影响网络性能。残差网络学习恒等函数比较容易,可将添加的网络层看成一个个残差块。例如,一个20层的普通网络,每两层之间通过跳跃连接构成一个残差块,那么这个普通网络就成为一个由10个残差块构成的残差网络。网络性能不仅没有下降,而且甚至有所提高。普通网络转化为残差网络也比较容易,只需要加入残差块即可。残差网络大大提高了网络层数,通过残差映射的方式进行拟合,简单易操作,同时提高了准确率。
设置resnet18网络模型,进行迁移学习,保留resnet18网络的卷积网络部分,并保留预训练参数。然后设计自适应平均池化函数,即不管之前的特征图尺寸为多少,只要设置为(1,1),那么最终特征图大小都为(1,1),然后把resnet18模型除了最后一个全连接层之外的各个网络层提取出来,并设置5个全连接层,分别对应5个可能的街道字符的识别。
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
# c6 = self.fc6(feat)
return c1, c2, c3, c4, c5 # , c6
完整代码链接:
https://pan.baidu.com/s/1UpIq9XSlWxSotE0fama3Vw 提取码:gcwu
作者简介:李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。


更多精彩推荐
大手笔 !Julia Computing 获 2400 万美元融资,前 Snowflake CEO 加入董事会
二维已经 OUT 了?3DPose 实现三维人体姿态识别真香 | 代码干货
KNN 分类算法原理代码解析