基于TLT训练Yolov3+darknet53
0. 背景
transfer learning toolkit(TLT)是基于python的AI toolkit,提供了常见分类,目标检测(Open image datasets)和语义分割算法的预训练模型, 即采用迁移学习的思路, 当创建大型训练数据集不可行时,通过在类似数据集上训练得到预训练模型再通过收集的数据对模型进行训练自定义。 通过TLT,可以将自己的数据应用于已经预先训练的模型上,而无需从头开始进行训练。
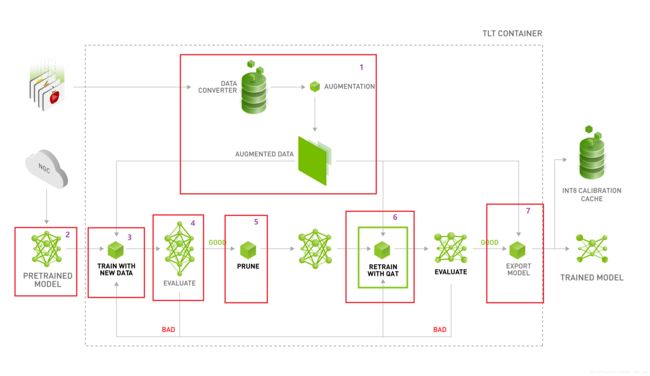
下图为transfer learning toolkit的overflow流程图。总共分为7部分:
- 数据增强和数据转换
- 模型选择
- 模型训练
- 模型评估
- 模型裁剪
- 模型重训练
- 模型导出(部署)
接下来,也会从上面这7部分进行分析tlt的工作流程和使用方法。主要是参加了NVIDIA SKY Hathathon比赛采用了tlt+tensorrt的技术路线,所以在此记录一下比赛过程中学习和问题。本文章重点讲解tlt的使用,对于tlt的docker环境安装,请参考给出的参考文章。
1. 数据增强和数据转换
1.1 数据增强
训练深度神经网络可能是一项艰巨的任务,而训练模型最重要的组成部分就是数据。 获取curated 和带注释的数据集可能是一个非常累人的手动过程,涉及数以千计的工时。 尽管计划和收集数据,但是很难估计网络可能遇到的所有极端情况,并且重复收集丢失的数据和进行注释的过程非常昂贵,并且周转时间很长。
训练数据加载器中的在线扩充是增加数据集中差异的好方法。 但是,扩充数据是根据数据加载器在采样数据时遵循的分布随机生成的,并且为了获得良好的准确性,可能需要对模型进行长时间的训练。 为了避免这种情况并生成具有所需增强功能的数据集并向用户提供控制,TLT提供了一种称为tlt-augment的离线增强工具。当收集和标记数据昂贵或不可能时,脱机扩充可以显着增加数据集的大小。tlt-augment工具提供了几种定制的GPU加速增强例程,这些例程分为:
Spatial augmentation 空间增强
Color space augmentation颜色空间增强
Image Blur图像模糊
空间扩充包括空间中的数据得以扩充。 TLT支持以下空间扩充操作。
Rotate旋转
Resize调整大小
Translate
Shear剪切
Flip翻转
色彩空间增强包括在色彩空间中得以增强。 支持以下颜色增强运算符。
色相旋转
亮度偏移
对比度偏移
上面提到的增强操作tlt-augment的使用,也使得可以使用高斯模糊运算符来使图像模糊。 有关操作的更多信息,请参见“模糊配置”。
当前tlt-augment提供的所有增强例程仅支持对象(目标)检测数据集。 空间增强例程将应用于图像以及标记的数据坐标,而颜色增强例程和逐通道蓝色运算符仅应用于图像,因为对象标签不受影响。
其中Configuring the Augmentor增强器配置的内容分析可以参考:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/augmenting_dataset.html#configuring-the-augmentor
Running the Augmentor Tool运行增强器工具内容分析可以参考:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/augmenting_dataset.html#running-the-augmentor-tool
数据增强在第三部分训练的配置文件中有所设置,因此这一步tlt-augment不需要使用,主要是了解tlt工具能提供哪些数据增强手段,以及怎么在训练配置文件中设置从而实现部分数据增强。
1.2 数据转换(参考:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/preparing_data_input.html)
TLT中的目标检测应用程序使用KITTI文件格式的数据进行training和evaluation。然后将数据转换为TFRecords进行训练,可以帮助更快的遍历数据。
1.2.1 目标检测KITTI文件格式
KITTI格式要求以下结构组织数据:
└── tlt-experiments
├── data
│ ├── ssd
│ ├── testing
│ │ └── image
│ └── training
│ ├── image
│ └── label
└── tfrecords
└── kitti_trainval
- images:训练包含的图像
- labels:对应图像的标签
图像和标签的扩展名之间需要具有相同文件ID。使用该ID维持标签图像之间的对应关系。
训练数据集中所有图像和标签应具有相同的分辨率。tlt-train工具不支持针对多种分辨率的图像进行训练,也不支持在训练过程中调整图像大小。
必须将所有图像调整为最终训练尺寸,并且相应的边界框也需要相应缩放。
1.2.2 KITTI转换为TFRecords
tlt-dataset-convert工具可以将KITTI格式的数据转换为TFRecords. 该工具需要一个配置文件作为输入。如下为配置文件的内容:
kitti_config {
# 数据根目录
root_directory_path: "/workspace/tlt-experiments/data/training"
image_dir_name: "image"
label_dir_name: "label"
image_extension: ".jpg"
partition_mode: "random"
num_partitions: 2
val_split: 14
num_shards: 10
}
image_directory_path: "/workspace/tlt-experiments/data/training"
这个配置文件中具有两个全局参数:
- kitti_config: 具有多个输入参数的嵌套prototxt配置
- image_directory_path: 数据集根的路径。此image_dir_name会附加到此路径以获取输入图像,并且必须与实验规范文件中提到的路径相同
1.2.3 转换器工具示例
tlt-dataset-convert [-h] -d DATASET_EXPORT_SPEC -o OUTPUT_FILENAME
[-f VALIDATION_FOLD]- -d, --dataset-export-spec: 包含用于导出.tfrecord文件的配置的检测数据集规范的路径
- -o, output_filename: 输出文件名
下面以Yolov3为例:

tlt-dataset-convert -d $SPECS_DIR/yolo_tfrecords_kitti_trainval.txt \
-o $DATA_DOWNLOAD_DIR/tfrecords/kitti_trainval/kitti_trainval
其中需要注意的是$DATA_DOWNLOAD_DIR/tfrecords/(kitti_trainval)/(kitti_trainval)这个路径中,第一个kitti_trainval指的是文件夹名,第二个kitti_trainval指的是生成tfrecords文件的前缀。
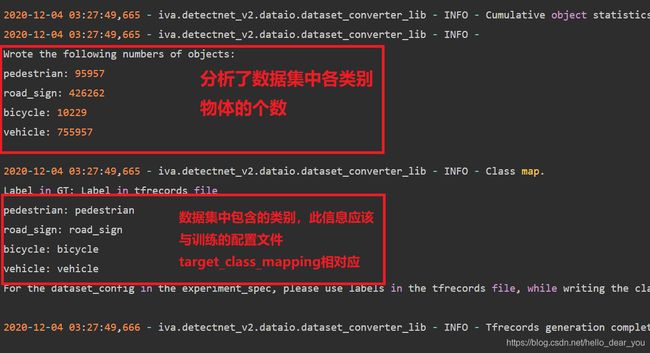
同时需要注意的是tfrecords文件生成时候产生的log信息,下面是一些需要注意的信息:
2. 模型训练
2.1 实验规范文件(配置文件用于模型训练,推理和评估)
参考:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/creating_experiment_spec.html#
下面主要针对Yolov3网络进行分析,以下是YOLOv3规范文件的示例。 它具有6个主要组件:yolo_config,training_config,eval_config,nms_config,augmentation_config和dataset_config。 规范文件的格式为protobuf文本(prototxt)消息,并且其每个字段都可以是基本数据类型或嵌套消息。
-
Training Config
training_config { batch_size_per_gpu: 16 num_epochs: 80 enable_qat: false learning_rate { soft_start_annealing_schedule { min_learning_rate: 5e-5 max_learning_rate: 2e-2 soft_start: 0.15 annealing: 0.8 } } regularizer { type: L1 weight: 3e-5 } }训练配置(training_config)定义了训练,评估和推理所需的参数。 下表中汇总了详细信息
参数
描述
enable_qat
是否使用quantization aware training
learning_rate
仅支持带有这些嵌套参数的soft_start_annealing_schedule。
min_learning_rate:在整个实验过程中看到的最少学习率
max_learning_rate:整个实验过程中可以看到的最大学习率
soft_start:预热之前要经过的时间(以0到1之间的进度百分比表示)
退火:开始退火学习率的时间
regularizer
此参数配置训练时要使用的正则化器,并包含以下嵌套参数。
type:要使用的类型或正则器。 NVIDIA支持NO_REG,L1或L2
权重:调节器权重的浮点值
其中学习率变化策略为下图:

-
Evaluation Config
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 16
matching_iou_threshold: 0.5
}评估配置(eval_config)定义了训练期间或独立评估所需的参数。 下表中汇总了详细信息。
| average_precision_mode |
平均精度(AP)计算模式可以是SAMPLE或INTEGRATE。 SAMPLE用作VOC 2009或更早版本的VOC指标。 INTEGRATE用于VOC 2010或之后的版本。 |
| matching_iou_threshold |
预测框和地面真实框的最低iou可以视为匹配项。 |
- NMS Config
nms_config {
confidence_threshold: 0.01 # 置信度阈值
clustering_iou_threshold: 0.6 # IOU阈值
top_k: 200 # 最后保存的预测框个数
}- augmentation_config
augmentation_config {
# 图像预处理
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
crop_right: 1248
crop_bottom: 384
min_bbox_width: 1.0
min_bbox_height: 1.0
}
# 数据增强具体参看1.1数据增强
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 0.7
zoom_max: 1.8
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
hue_rotation_max: 25.0
saturation_shift_max: 0.20000000298
contrast_scale_max: 0.10000000149
contrast_center: 0.5
}
}- dataset_config
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
# 图像文件后缀名一般是png,jpg
image_extension: "png"
# 这个应该和数据转换过程的输出相对应
# 请注意我这里是粘贴的官方给出的,你需要修改
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}- yolo_config
| matching_neutral_box_iou |
此字段应为介于0和1之间的浮点数。任何与ground truth 框不匹配但anchor与任何ground truth框的IOU高于浮点值,在训练过程中都不会向后传播其objectness loss。 这是为了减少false negatives。 |
|
| arch_conv_blocks |
支持的值为0、1和2。该值控制检测输出层之间存在多少卷积块。 如果要重现DarkNet 53随附的原始YOLOv3模型的元体系结构,请将此值设置为2。请注意,此配置设置仅控制YOLO元体系结构的大小,而功能提取器的大小与此无关 配置字段。 |
|
| arch |
用于特征提取的主干。 当前,支持“ resnet”,“ vgg”,“ darknet”,“ googlenet”,“ mobilenet_v1”,“ mobilenet_v2”和“ squeezenet”。 |
|
| nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
|
| freeze_bn |
Whether to freeze all batch normalization layers during training. |
|
| freeze_blocks |
训练期间要冻结在模型中的块ID列表。您可以选择冻结模型中的某些CNN块,以使训练更稳定和/或更易于收敛。块的定义是针对特定架构的启发式方法。例如,通过步幅或模型中的逻辑块等。但是,块ID号按顺序标识模型中的块,因此您在训练时不必知道块的确切位置。要记住的一般原则是:块ID越小,它与模型输入的距离越近;块ID越大,它与模型输出 越接近。
您可以将整个模型分为几个块,并可以选择冻结它的一个子集。请注意,对于FasterRCNN,您只能冻结ROI池层之前的块。 ROI合并层之后的任何层都不会冻结。对于不同的主干,块的数量和每个块的块ID是不同的。值得详细说明如何为每个主干指定块ID。 |
list(repeated integers) ● ResNet series. For the ResNet series, the block IDs valid for freezing is any subset of [0, 1, 2, 3] (inclusive) ● VGG series. For the VGG series, the block IDs valid for freezing is any subset of[1, 2, 3, 4, 5] (inclusive) ● GoogLeNet. For the GoogLeNet, the block IDs valid for freezing is any subset of[0, 1, 2, 3, 4, 5, 6, 7] (inclusive) ● MobileNet V1. For the MobileNet V1, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11](inclusive) ● MobileNet V2. For the MobileNet V2, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13](inclusive) ● DarkNet. For the DarkNet 19 and DarkNet 53, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4, 5](inclusive) |
2.2 模型训练
Yolov3为例,以下是模型训练的command。
tlt-train [-h] yolo -e
-r
-k
-m
--gpus - -r, --results_dir: 权重保存路径
- -k, --key: 特定编码key用于保存和加载tlt权重文件
- -e, --experiment_spec_file: 实验spec文件路径
- --gpus: 用于训练的GPU个数

3. 模型评估
分类网络模型计算evaluation loss,Top-k准确率,精度和召回率作为评判标准。对于DetectNet_v2,FasterRCNN,Retinanet,DSSD,YOLOv3和SSD根据定义在Pascal VOC Challenge中计算每一个类的AP和mAP作为评判标准。支持采样和积分模式以计算平均精度。SAMPLE模式使用11点方法来计算AP,而INTEGRATE模式使用更细粒度的积分方法并获得更准确的AP。MaskRCNN使用COCO的检测评估指标。COCO指标中AP50与Pascal VOC指标中的mAP相当。tlt提供tlt-evaluate工具用于评估训练后的网络模型,其中测试集为数据转换中生成的val部分数据。
tlt-evaluate {classification,detectnet_v2,faster_rcnn,ssd,dssd,retinanet,yolo, mask_rcnn} [-h]
[] 以下是Yolov3模型评估的命令行:
tlt-evaluate yolo [-h] -e -m -k - -m, --model: 用于评估的model file
- -e, --experiment_spec_file: 实验规范文件的路径
- -k,-key: 提供加密密钥以解密模型
4. 模型裁剪
使用tlt-prune命令从模型中删除参数,以减少模型大小,而不损害模型本身的完整性。
tlt-prune [-h] -m
-o -k
[-n ]
[-eq ]
[-pg ]
[-pth ]
[-nf ]
[-el [] 必须参数
- -m: 权重文件路径
- -o:输出权重路径
- -k: key用于解码模型
以下是Yolov3的一个实例:
tlt-prune -m
$USER_EXPERIMENT_DIR/experiment_dir_unpruned/weights/yolo_resnet18_epoch_$EPOCH.tlt \ # 输入权重路径
-o $USER_EXPERIMENT_DIR/experiment_dir_pruned/yolo_resnet18_pruned.tlt \ # 输出权重路径
-eq intersection \
-pth 0.5 \ # 裁剪比例
-k $KEY5. 模型重训练
一旦模型被修剪,准确性可能会略有下降。这是因为以前有用的权重可能被删除了。为了重新获得准确性,NVIDIA建议在相同的数据集上重新训练这个经过修剪的模型。为此,使用tlt-train命令,就像在训练模型时所记录的那样,使用一个更新的规范文件,该文件指向新修剪的模型作为预训练的模型文件。
建议用户在重新训练一个修剪后的模型时,关闭detectnet的training_config中的正则化器来恢复准确率。您可以通过将正则化器类型设置为NO_REG来实现这一点。所有其他参数都可以保留在上次培训的spec文件中。以Yolov3为例,首先我们需要更新一下规范文件,即将正则化去掉,然后和模型训练那一步类似进行训练。
# 模型重训练规范文件
regularizer {
type: NO_REG
weight: 3.0e-09
}tlt-train重训练实例,详细参数解析请参考模型训练
tlt-train yolo --gpus 1 \
-e $SPECS_DIR/yolo_retrain_resnet18_kitti.txt \
-r $USER_EXPERIMENT_DIR/experiment_dir_retrain \
-m $USER_EXPERIMENT_DIR/experiment_dir_pruned/yolo_resnet18_pruned.tlt \
-k $KEY6. 模型导出
Transfer学习工具包包括tlt -export命令,用于导出和准备用于部署到DeepStream的TLT模型.导出模型将训练过程从推理中解耦,并允许在TLT环境之外转换为TensorRT engine。 TensorRT engine特定于每一个硬件平台配置,因此需要为每一个推理环境生成对应的engine文件。
6.1 tlt-export得到etlt文件
基于tlt-export工具将tlt格式的权重文件转换为etlt格式的文件,在转换过程中会根据规范文件的一些参数处理Yolov3网络的后处理,需要注意的是etlt文件以及后面生成的engine文件对于Yolov3而言,其输出总共有四个值:
- topK:即最后保存多少个预测框数据(100或200)
- 预测的box信息:shape=(topK, 4)
- 预测的score信息:shape=(topK)
- 预测的class类别:shape=(topK)
其中可能用到规范文件中的一些信息如下:
1. anchor的宽高信息用于decode
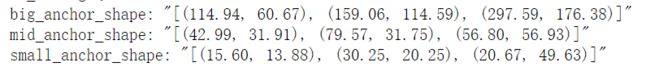
2. NMS信息用于作非极大值抑制

3. 图像预处理

4. 类别信息

以下为Yolov3的导出command,通过如下命令就可以得到etlt文件
# Export in FP32 mode. Change --data_type to fp16 for FP16 mode
tlt-export yolo -m $USER_EXPERIMENT_DIR/experiment_dir_retrain/weights/yolo_resnet18_epoch_$EPOCH.tlt \
-k $KEY \
-o $USER_EXPERIMENT_DIR/export/yolo_resnet18_epoch_$EPOCH.etlt \
-e $SPECS_DIR/yolo_retrain_resnet18_kitti.txt \
--batch_size 1 \
--data_type fp32
6.2 tlt-converter得到engine文件
对于需要将模型通过deepstream部署,tlt提供了两种方法,第一种就是直接输入etlt(deepstream直接兼容etlt文件的输入),第二种是将etlt文件转换成tensorrt的engine文件,然后通过deepstream调用engine实现部署。由于本次所参加的比赛不涉及deepstream,所以采用的是第二种方案,即通过tlt-converter转换etlt文件得到模型的engine,然后基于tensorrt的环境进行推理部署。
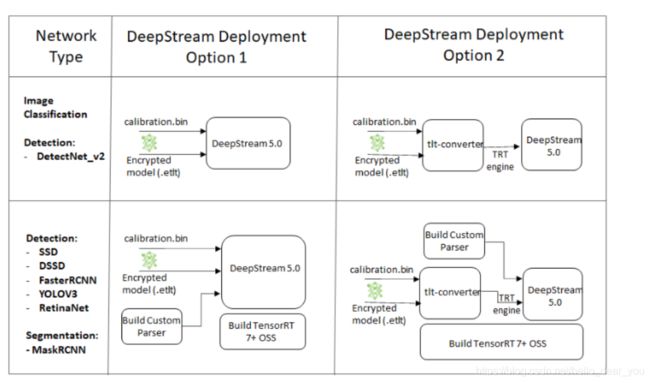
关于tlt-converter转换可以参考:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/deploying_to_deepstream.html#tensorrt-open-source-software-oss
针对x86和jetson环境,tlt-converter的运行环境配置要求是不相同的,(但是其实是可以在tlt的docker环境下直接使用tlt-converter工具),由于本次使用的Jetson Nano环境,所以主要介绍Jetson平台下如何配置tlt-converter环境。
对于Jetson平台的JetPack 4.4环境,需要编译安装TensorRT OSS文件,构建TensorRT开源软件(OSS)。这是必需的,因为这些模型所需要的几个TensorRT插件只在TensorRT开源repo中可用,而在一般的TensorRT版本中没有。
安装的具体参考连接为:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/deploying_to_deepstream.html#tensorrt-oss-on-jetson-arm64
- 第一步确保cmake的版本大于等于3.13,可以通过如下命令参看cmake的版本
cmake --version- 第二步安装TensorRT OSS
注意:请根据tensorrt的版本选择相应的分支进行下载,由于TensorRT OSS这个项目下包含很多子项目通过git下载通常会失败,这里提供一个tensorrt oss 7.1.3版本的供各位下载
链接:https://pan.baidu.com/s/1orPgdl1jFkWH6P3mx47dCg
提取码:lihg
git clone -b release/7.0 https://github.com/nvidia/TensorRT
cd TensorRT/
git submodule update --init --recursive
export TRT_SOURCE=`pwd`
cd $TRT_SOURCE
mkdir -p build && cd build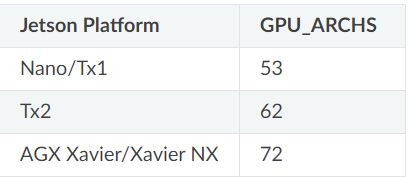
-DGPU_ARCHS=72其中的72需要根据上图的不同Jetson平台进行修改
/usr/local/bin/cmake .. -DGPU_ARCHS=72 -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=`pwd`/out
make nvinfer_plugin -j$(nproc)当我们编译成功后,会得到3个名称为libnvinfer_plugin.so*的文件,为了让tensorrt支持一些用到的插件,我们需要替换系统中tensorrt的libnvinfer_plugin的文件。
最后替换tensorrt中的libnvinfer_plugin文件,需要将生成的3个文件和系统中三个文件进行替换(请记得备份原来的共享库文件)
sudo mv /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.7.x.y ${HOME}/libnvinfer_plugin.so.7.x.y.bak // backup original libnvinfer_plugin.so.x.y
sudo cp `pwd`/out/libnvinfer_plugin.so.7.m.n /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.7.x.y
sudo ldconfig至此,TensorRT OSS的环境安装完毕,可以使用tlt-converter在Jetson平台下对etlt文件进行转换
在使用tlt-converter工具之前我们需要下载tlt-converter工具和配置以下环境:
参考链接:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/deploying_to_deepstream.html#instructions-for-jetson
1. 下载并解压tlt-converter工具,下载链接:https://developer.download.nvidia.com/assets/TLT/Secure/tlt_7.1.zip?RZ3-RocijZF7Jq0aHrWvN6rEzq6x69ejVJP5Sxqums6UNwg1Nvzv3Flj-_-EtAwieOLZR_f7FwKZ-GMB0wjJ2WqirR7xd5LhWBawgDKiPBUOcDHUDCfK6kpj0EA
2. 安装ssl库
sudo apt-get install libssl-dev3. 设置环境变量
export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”4. tlt-converter命令行模型转换
tlt-converter [-h] -k
-d
-o
[-c ]
[-e ]
[-b ]
[-m ]
[-t ]
[-w ]
[-i ]
input_file 其中:
- -d:为网络输入的维度
- -o:为输出的节点名称。
- For classification use: predictions/Softmax.
- For DetectNet_v2: output_bbox/BiasAdd,output_cov/Sigmoid
- For FasterRCNN: dense_class_td/Softmax,dense_regress_td/BiasAdd, proposal
- For SSD, DSSD, RetinaNet: NMS
- For YOLOv3: BatchedNMS
- For MaskRCNN: generate_detections, mask_head/mask_fcn_logits/BiasAdd
- -e: 输出engine文件的路径
- -m: 最大的batch size对于TRT engine而言
- -t: 数据类型
- -w: 所需要的显存空间
- -i :输入维度的排序,一般为nchw
- 输入的etlt文件路径
参考文章:
官网文档:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/index.html
NVIDIA之TLT迁移学习训练自己的数据集:https://zongxp.blog.csdn.net/article/details/107386744