【C++】C++基础
目录
- 1. C++关键字
- 2. 命名空间
-
- 2.1 命名空间的定义
- 3. 缺省参数
-
- 3.1缺省参数概念
- 3.2 缺省参数的分类
- 4. 函数重载*
-
- 4.1 函数重载概念
- 4.2 为什么需要函数重载
- 4.3 名字修饰
- 5. 引用*
-
- 5.1 引用的概念
- 5.2 引用特征
- 5.3 常引用
- 5.4 使用场景
-
- 5.4.1 **做参数**
- 5.4.2 **做返回值**
- 5.5 引用和指针的区别
- 6. 内联函数
-
- 6.1 概念
1. C++关键字
2. 命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
2.1 命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
//1. 普通的命名空间
namespace N1 // N1为命名空间的名称
{
// 命名空间中的内容,既可以定义变量,也可以定义函数
int a;
int Add(int left, int right)
{
return left + right;
}
}
//2. 命名空间可以嵌套
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
namespace N1
{
int Mul(int left, int right)
{
return left * right;
}
}
3. 缺省参数
3.1缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
void TestFunc(int a = 0)
{
cout<<a<<endl;
}
int main()
{
TestFunc(); // 没有传参时,使用参数的默认值
TestFunc(10); // 传参时,使用指定的实参
}
3.2 缺省参数的分类
- 全缺省参数
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- 半缺省参数
void TestFunc(int a, int b = 10, int c = 20)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
注意:
- 半缺省参数必须从右往左依次来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现
- 缺省值必须是常量或者全局变量
4. 函数重载*
4.1 函数重载概念
函数重载是指在同一作用域内,可以有一组具有相同函数名,不同参数列表的函数,这组函数被称为重载函数。重载函数通常用来命名一组功能相似的函数,这样做减少了函数名的数量,避免了名字空间的污染,对于程序的可读性有很大的好处。
When two or more different declarations are specified for a single name in the same scope, that name is said to overloaded. By extension, two declarations in the same scope that declare the same name but with different types are called overloaded declarations. Only function declarations can be overloaded; object and type declarations cannot be overloaded. ——摘自《ANSI C++ Standard. P290》
- 函数重载的规则:这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同
函数重载例子:
int Add(int left, int right)
{
return left+right;
}
double Add(double left, double right)
{
return left+right;
}
long Add(long left, long right)
{
return left+right;
}
int main()
{
Add(10, 20);
Add(10.0, 20.0);
Add(10L, 20L);
return 0;
}
4.2 为什么需要函数重载
- 试想如果没有函数重载机制,如在C中,你必须要这样去做:为这个print函数取不同的名字,如print_int、print_string。这里还只是两个的情况,如果是很多个的话,就需要为实现同一个功能的函数取很多个名字,如加入打印long型、char*、各种类型的数组等等。这样做十分麻烦且冗余。
- 我们都知道类的构造函数与类名是相同的,换句话说:构造函数都是同名的。如果没有函数重载机制,想要实例化不同的对象,会相当的麻烦。
- 操作符重载的本质就是函数重载,其大大丰富了已有操作符的含义,且使用方便,其中我觉得最经典的就是 重载 + 实现字符串的连接。
4.3 名字修饰
大家是否思考过,C语言为什么不支持函数重载?C++又是如何支持重载的?
在C/C++中,一个程序要运行起来,要经过几个阶段:预处理,编译,汇编,链接。
具体的过程可以看之前的相关博客程序的编译。

- 我们的项目通常是由多个头文件和源文件构成,以main.c 和 sum.c为例子,当我们在main.c中调用了sum.c中定义的sum函数的时候,在链接之前,main.o的目标文件中是没有sum函数的地址的。
- 当我们进行链接的时候,连接器检测到main.o调用了sum,但是缺少sum的地址,就会到sum.o的符号表中找sum的地址,然后链接在一起.
以上都是复习内容:
现在我们思考,链接的时候,面对sum函数,链接器是使用哪个名字去找的呢?在不同的编译器下有不同的函数名修饰规则.
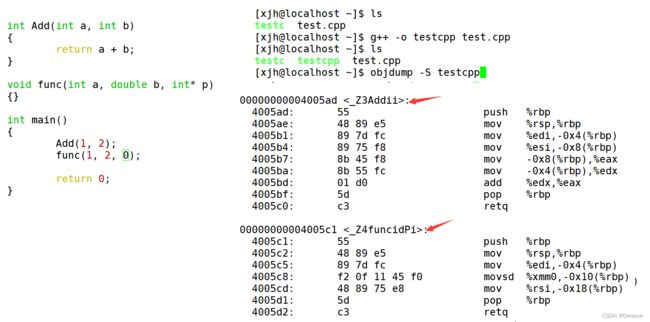
下面我们使用Linux下的gcc演示一下(Windows下的修饰规则比较复杂)。
通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】
采用C语言编译器后的结果:
在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。

采用C++编译器编译后结果:
在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中
- 补充:windows下的名字修饰规则:
虽然看上去比较诡异,但是道理一定是一致的
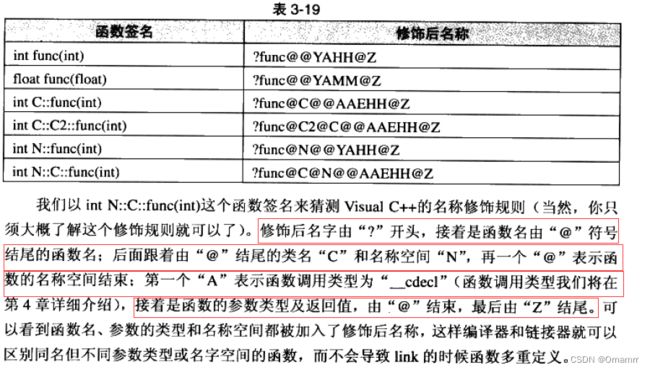
通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区
分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
想了解更多细节的同学可以看这篇文章:C++的函数重载
当然,这篇文章在说明为什么返回值不能够做为函数重载的参考的时候,是存在误区的,他将_Z3,_Z4…理解为不同的返回值类型,其实是错误的,其实数字只代表函数名的长度而已(有时候真相就是这么简单哈哈),所以C++在函数修饰的时候根本就没有考虑 返回值 ,只考虑了参数列表。
那么如果说我们把返回值加入到函数名修饰中,在编译器层面当然是可以区分的,但是在语法调用的时候,无法区分,带有很严重的歧义。这也是C++不把返回值纳入修饰的原因。
举个例子:
int func();
double func();
int main()
{
func(); //此时到底该调用谁?
}
5. 引用*
5.1 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
5.2 引用特征
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
5.3 常引用
void TestConstRef()
{
const int a = 10;
//int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a;
// int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;
}
下面我们看一个场景,请问为什么下面的代码为什么会发生报错?
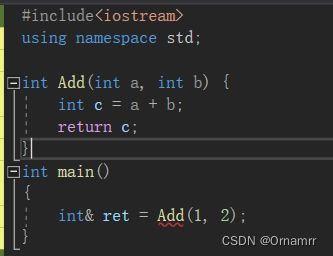
这是因为Add在返回的时候会拷贝c产生一个中间变量,而这个中间变量是具有常性的,也就是说我们要是用const int& 类型去接收。
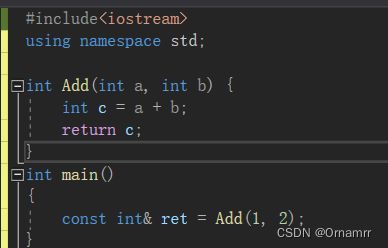
5.4 使用场景
5.4.1 做参数
具体来说:
a. 输出型参数,如 void swap(int& a ,int& b);
b. 当参数变量较大的时候,相比于传值,引用做参数可以减少拷贝
c. 如果函数中不改变形参的话,建议使用const type& ,因为 这样可以保护形参,避免误改,除此之 外,既可以传普通对象,还可以传const 对象。
void Swap(int& left, int& right) //做输出型参数
{
int temp = left;
left = right;
right = temp;
}
5.4.2 做返回值
- 引用返回的意义:
- 引用返回的价值是减少了拷贝
- 方便实现类似operator[]
- 使用示范:
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
- 错误的使用
下面我们看一段代码,这段代码是否存在问题?

我们先根据函数栈帧来分析一下代码。

当我们将c返回的时候,返回的是c的引用,也就是3.但是实际上,c是Add的函数栈帧中的一个临时变量,所以在函数返回之后,理论上栈帧会销毁,c不再存在,c的引用自然也不再存在,所以ret拿到的值实际上是一个随机值。
同时,我们可以看出,虽然栈帧销毁了,但是在VS中,数据并没有被清空(不同的平台不一样),换句话说,栈帧销毁只是把指定空间的使用权剥夺,销毁之后的访问属于非法访问,但是表面上看起来不会有任何问题。
如何让这只狐狸露出尾巴呢?我们将代码稍加修改。
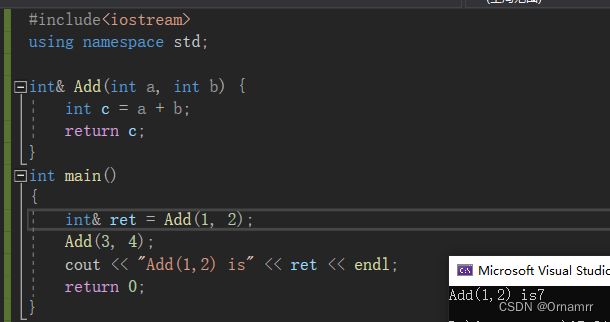
此时我们发现 1+2 算出的值为7,明显是错误的,依据我们之前的分析,这个结果并不在意料之外:
此时我们使用引用接受返回值,所以ret 指向的空间就是临时变量c的空间,当我们再次调用Add时,由于形参的变化,c空间上的值被覆盖为7,相应的ret也变为7。此时非法访问就十分明显了,这就是不正确使用引用返回造成的危害。
内存空间就像是租房子一样,操作系统是房东,我们申请内存就是让房东把房屋使用权给我们,法律保护别人不会到你的房子里来。而释放内存空间就是我们退租,房子不会消失但是我们的使用权没有了,房东在之后可能会把房子继续租给别人。如果我们没有在搬出去之后没有把自己的东西清空,那么在新租客来的时候我们的东西可能就会被丢弃。
所以,我们在使用 引用作为返回值的时候需要注意:
- 出了func函数的作用域,ret变量会销毁,就不应该使用引用返回
- 出了func函数的作用域,ret变量不会销毁,就可以使用引用返回
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
我们来看下引用和指针的汇编代码对比:

5.5 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
6. 内联函数
6.1 概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,内联函数提升程序运行的效率。
在C原因中是通过宏的方式来实现这一目的,但是缺点比较多。
- inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长或者有循环/递归的函数不适宜使用作为内联函数。
- inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。