吴恩达机器学习课程-第五周
1.神经网络的学习
1.1 代价函数
假设神经网络的训练样本有 m m m个,每个包含一组输入 x x x和一组输出信号 y y y, L L L表示神经网络的总层数, s l s_l sl表示在第 l l l层的神经元个数(不包括bias unit) :
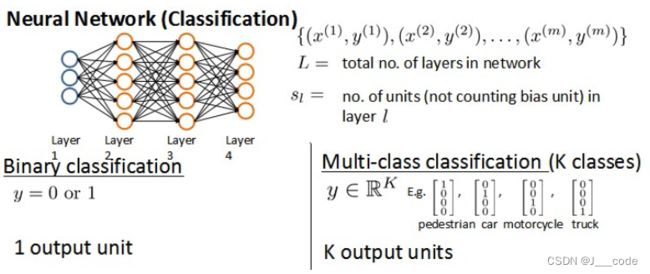
在逻辑回归中使用到的代价函数如下,它只有一个输出变量:
J ( θ ) = − 1 m [ ∑ i = 1 m y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=-\frac{1}{m}[\sum_{i=1}^my^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta^2_j J(θ)=−m1[∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλ∑j=1nθj2
而在神经网络中可以有多个输出变量,所以预测输出是一个维度为 k k k的向量 h θ ( x ) h_\theta(x) hθ(x),且 ( h θ ( x ) ) i (h_\theta(x))_i (hθ(x))i表示第 i i i个输出, y i y_i yi表示真实值的第 i i i个输出,和逻辑回归一样没有被偏置项进行正则化:
J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 k y k ( i ) log ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) log ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 J(\Theta)=-\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{k=1}^{k} y_{k}^{(i)} \log \left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}+\left(1-y_{k}^{(i)}\right) \log \left(1-\left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}\right)\right]+\frac{\lambda}{2 m} \sum_{l=1}^{L-1} \sum_{i=1}^{s_{l}} \sum_{j=1}^{s_{l}+1}\left(\Theta_{j i}^{(l)}\right)^{2} J(Θ)=−m1[∑i=1m∑k=1kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλ∑l=1L−1∑i=1sl∑j=1sl+1(Θji(l))2
1.2 反向传播
前面的学习中介绍了神经网络的前向传播,下图是一个训练样本的前向传播过程:

现在为了计算偏导数 d d θ i j ( l ) J ( θ ) \frac{d}{d\theta^{(l)}_{ij}}J(\theta) dθij(l)dJ(θ),需要使用到反向传播。其中 δ j ( l ) \delta_j^{(l)} δj(l)表示第 l l l层中第 j j j个神经元的误差值。从最后一层的误差开始计算,并且利用该层的误差继续计算上一层的误差值,依此类推:
δ ( 4 ) = a ( 4 ) − y \delta^{(4)}=a^{(4)}-y δ(4)=a(4)−y
δ ( 3 ) = ( θ ( 3 ) ) T δ ( 4 ) ⋅ g ′ ( z ( 3 ) ) , g ′ ( z ( 3 ) ) = a ( 3 ) ⋅ ( 1 − a ( 3 ) ) \delta^{(3)}=(\theta^{(3)})^T\delta^{(4)}·g^{'}(z^{(3)}),g^{'}(z^{(3)})=a^{(3)}·(1-a^{(3)}) δ(3)=(θ(3))Tδ(4)⋅g′(z(3)),g′(z(3))=a(3)⋅(1−a(3))
δ ( 2 ) = ( θ ( 2 ) ) T δ ( 3 ) ⋅ g ′ ( z ( 2 ) ) \delta^{(2)}=(\theta^{(2)})^T\delta^{(3)}·g^{'}(z^{(2)}) δ(2)=(θ(2))Tδ(3)⋅g′(z(2))
没有输入层的误差是因为输入是训练集,即实际观察到的数值,不需要改变
如果不做正则化处理时, d d θ i j ( l ) J ( θ ) = a j ( l ) δ i ( l + 1 ) \frac{d}{d\theta^{(l)}_{ij}}J(\theta)=a_j^{(l)}\delta_i^{(l+1)} dθij(l)dJ(θ)=aj(l)δi(l+1),其中 l l l表示当前计算第几层, j j j表示当前层中激活单元的下标, i i i表示下一层中误差单元的下标
如果考虑正则化,且训练集有多个样本,则输入的是矩阵,误差值也应当是一个矩阵,采用 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l)表示,即第 l l l层的第 i i i个激活单元受到第 j j j个参数影响而导致的误差,整体算法流程如下:

求出 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l)后,可以计算代价函数的偏导数 d d θ i j ( l ) J ( θ ) = D i j ( l ) \frac{d}{d\theta^{(l)}_{ij}}J(\theta)=D_{ij}^{(l)} dθij(l)dJ(θ)=Dij(l),其中 j = 0 j=0 j=0即为偏执项单元的下标(意味着没有进行正则化):
D i j ( l ) : = 1 m Δ i j ( l ) + λ Θ i j ( l ) D_{i j}^{(l)}:=\frac{1}{m} \Delta_{i j}^{(l)}+\lambda \Theta_{i j}^{(l)} Dij(l):=m1Δij(l)+λΘij(l) if j ≠ 0 j \neq 0 j=0
D i j ( l ) : = 1 m Δ i j ( l ) D_{i j}^{(l)}:=\frac{1}{m} \Delta_{i j}^{(l)} Dij(l):=m1Δij(l) if j = 0 j=0 j=0
1.3 理解反向传播
下图中前向传播计算 z 1 ( 3 ) = θ 10 ( 2 ) ∗ 1 + θ 11 ( 2 ) ∗ a 1 ( 2 ) + θ 12 ( 2 ) ∗ a 2 ( 2 ) z_1^{(3)}=\theta_{10}^{(2)}*1+\theta_{11}^{(2)}*a^{(2)}_1+\theta_{12}^{(2)}*a^{(2)}_2 z1(3)=θ10(2)∗1+θ11(2)∗a1(2)+θ12(2)∗a2(2),直观上的理解就是与 z 1 ( 3 ) z_1^{(3)} z1(3)相连的三个神经元值的加权和:
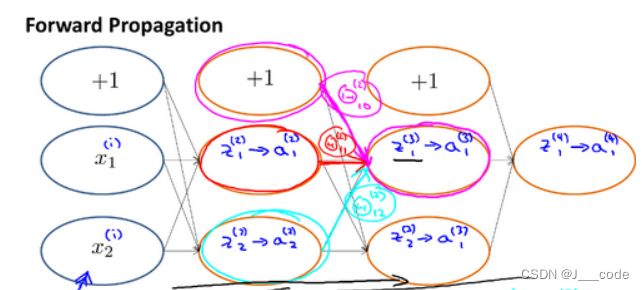
此时要计算下图中的 δ 2 ( 2 ) \delta_2^{(2)} δ2(2),和前向传播中的权重和理念类似, δ 2 ( 2 ) = θ 12 ( 2 ) δ 1 ( 3 ) + θ 22 ( 2 ) δ 2 ( 3 ) \delta_2^{(2)}=\theta_{12}^{(2)}\delta_1^{(3)}+\theta_{22}^{(2)}\delta_2^{(3)} δ2(2)=θ12(2)δ1(3)+θ22(2)δ2(3),直观理解就是和 δ 2 ( 2 ) \delta_2^{(2)} δ2(2)相连的两个神经元的误差加权和。至于前面计算误差中的 g ′ ( z ) g^{'}(z) g′(z)是什么,可以参考反向传播之我见,其中对具体推导有着更加详细的讲解
综上所述,前向传递输入信号直至输出产生误差,反向传播误差信息更新权重矩阵(摘自反向传播之我见)
1.4 梯度检验
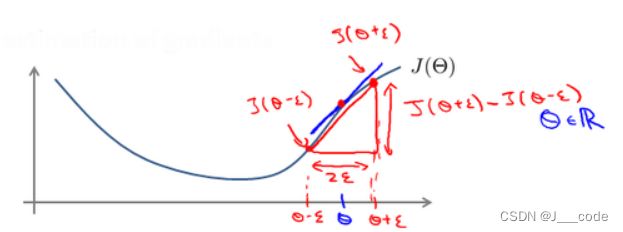
对一个较为复杂的模型使用梯度下降算法时,可能会存在一些不容易察觉的错误,虽然代价看上去在不断减小,但最终的结果可能并不是最优解。为了避免该问题,采取梯度数值检验方法:
- 在 J ( θ ) J(\theta) J(θ)沿着切线的方向选择离两个非常近的点 J ( θ + t ) J(\theta+t) J(θ+t)和 J ( θ − t ) J(\theta-t) J(θ−t)
- 计算这两个点构成的直线的斜率,即图中红色线的斜率 J ( θ + t ) − J ( θ − t ) 2 ξ \frac{J(\theta+t)-J(\theta-t)}{2\xi} 2ξJ(θ+t)−J(θ−t)
- 将红色线的斜率和蓝色线的斜率进行比较
当 θ \theta θ为向量时,代价函数中偏导数的检验在针对其中一个参数 θ 1 \theta_1 θ1校验时: d d θ 1 = J ( θ 1 + ξ , θ 2 , . . . + θ n ) − J ( θ 1 − ξ , θ 2 , . . . + θ n ) 2 ξ \frac{d}{d\theta_1}=\frac{J(\theta_1+\xi,\theta_2,...+\theta_n)-J(\theta_1-\xi,\theta_2,...+\theta_n)}{2\xi} dθ1d=2ξJ(θ1+ξ,θ2,...+θn)−J(θ1−ξ,θ2,...+θn)
1.5 随机初始化
假设下图中额神经网络所有参数初始化为相同的值,则计算后:
a 1 ( 2 ) = θ 10 ( 1 ) ∗ 1 + θ 11 ( 1 ) ∗ x 1 + θ 12 ( 1 ) ∗ x 2 a_1^{(2)}=\theta_{10}^{(1)}*1+\theta_{11}^{(1)}*x_1+\theta_{12}^{(1)}*x_2 a1(2)=θ10(1)∗1+θ11(1)∗x1+θ12(1)∗x2
a 2 ( 2 ) = θ 20 ( 1 ) ∗ 1 + θ 21 ( 1 ) ∗ x 1 + θ 22 ( 1 ) ∗ x 2 a_2^{(2)}=\theta_{20}^{(1)}*1+\theta_{21}^{(1)}*x_1+\theta_{22}^{(1)}*x_2 a2(2)=θ20(1)∗1+θ21(1)∗x1+θ22(1)∗x2
即 a 1 ( 2 ) = a 2 ( 2 ) a_1^{(2)}=a_2^{(2)} a1(2)=a2(2),这意味着后续计算梯度的值都是一样的,即使进行了梯度下降更新了权重,更新完的权重还是相同的。当所有神经元的值都一样时可以视为只计算一个特征,这是没有意义的
为了打破这种对称性,需要将权重进行随机初始化,该方式有很多种就不一一列举
1.6 训练神经网络流程
-
参数的随机初始化
-
利用正向传播方法计算所有样本的 h θ ( x ) h_\theta(x) hθ(x)
-
编写计算代价函数 J ( θ ) J(\theta) J(θ)的代码
-
利用反向传播方法计算偏导数
-
利用数值检验方法检验偏导数
-
使用优化算法来最小化代价函数
2.参考
https://www.bilibili.com/video/BV164411b7dx?p=50-56
http://www.ai-start.com/ml2014/html/week5.html
https://zhuanlan.zhihu.com/p/28821475