ElasticSearch 介绍、安装及简单使用
文章目录
-
-
- 介绍
- 基本概念
-
- 全文搜索(Full-text Search)
- 倒排索引(Inverted Index)
- 节点&集群(Node & Cluster)
- 文档(Document)
- 索引(Index)
- 类型(Type)
- 文档元数据(Document Metadata)
- 字段(Field)
- ElasticSearch与关系型数据库对应关系
- ElasticSearch与Solr对比
- ElasticSearch安装
- ElasticSearch Head安装
- Kibana安装
- ElasticSearch增删改查
-
- 新增文档(Index API)
- 修改文档(Update API)
- 查询文档(Get API)
- 删除文档(Delete API)
- 批量操作(Bulk API)
- 根据多个文档ID获取文档(Multi Get API)
- ES中文分词器
-
- 内置的标准分词器standard
- IK分词器
- 问题
-
- 单机情况下增加索引集群健康状态是yellow
- 参考网址
-
介绍
Elasticsearch 是大数据时代下的分布式搜索引擎,底层基于 Lucene 实现。Elasticsearch 屏蔽了 Lucene 的底层细节,提供了分布式特性,同时对外提供了 Restful API,数据交互格式为JSON。Elasticsearch 以其易用性迅速赢得了许多用户,被用在网站搜索、日志分析等诸多方面。由于 ES 强大的横向扩展能力,甚至很多人也会直接把 ES 当做 NoSQL 来用。
基本概念
全文搜索(Full-text Search)
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
倒排索引(Inverted Index)
该索引表中的每一项都记录了属性值与具有该属性值的记录的地址。由于不是由记录找到属性值而是通过属性值找到记录,所以叫作倒排索引。譬如歌手张学友唱过《味道》这首歌曲,歌手辛晓琪和吴彦斌也唱过,我们能通过张学友找到他唱了《味道》这首歌曲,但是反过来我们通过《味道》这首歌曲能找到张学友和其他歌手,这样通过属性值找到记录的方法就称为反向索引,也就是倒排索引。
ES是为记录的每个字段都建立了倒排索引,所以才能实现快速高效的搜索功能。
具体倒排索引结构可以参考ElasticSearch倒排索引结构分析。
节点&集群(Node & Cluster)
ElasticSearch本质上就是分布式搜索引擎,允许多台服务器协同工作,每台服务器可以运行多个ElasticSearch实例,每个ElasticSearch实例就称为一个节点(Node),一组节点就称为一个集群(Cluster)。
单节点的ES也可以是一个集群。
文档(Document)
文档其实就是用户提交给ES的一条数据,上面也说过ES数据交互格式都是JSON,所以这里的文档就是一条JSON数据。这里的文档可以类比成关系型数据库中的记录。JSON数据中含有多个字段,JSON里的字段可以类比成关系型数据库中表的字段。
索引(Index)
索引(Index)可以理解成文档的集合,同在一个索引中的文档共同建立倒排索引。
索引(Index)可以类比成关系型数据库中的库(Database)。
类型(Type)
文档可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
不同的Type应该有相似的结构,性质完全不同的数据应该存成两个Index而不是一个Index里不同的Type。
ES官网提出的Type观念的演变情况如下
5.x版本中,一个Index下可以创建多个Type
6.x版本中,一个Index下只能存在一个Type
7.x版本中,去除了Type的概念
8.x版本中,正式弃用
为什么会被弃用?
因为同一个索引下,不同type下若字段名是一样的则ES会认为是一个字段而且类型必须一致,因为type只是一个虚拟的逻辑分组。不同type的数据存储其他type的字段大量空值,造成资源浪费,而且基于Lucene的倒排索引是基于Index而不是Type的,多个Type反而会减慢搜索速度。
文档元数据(Document Metadata)
文档元数据为_index、_type、_id,这三者可以唯一表示一个文档。_index表示文档存放于哪个索引,_type表示文档的对象类别,_id为文档的唯一标识。
字段(Field)
每个文档都是一条JSON数据,JSON数据中的每个key就是字段(Field)。
ElasticSearch与关系型数据库对应关系
ES早期是借鉴了关系型数据库的模式,对应关系如下图

对于最新的ES版本而言,由于弃用了Type概念,一张表就对应一个索引。
ElasticSearch与Solr对比
二者安装都很简单;
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
ElasticSearch安装
由于国内访问ElasticSearch官网很慢,所以建议从华为开源镜像站下载。
后续相关内容都以7.6.1版本来学习。并且相关服务都部署在Linux服务器上。

- 解压文件
将文件放到/usr/local/src/packages/es目录下

解压文件并建立软连接
cd /usr/local/src
tar zxPvf packages/es/elasticsearch-7.6.1-linux-x86_64.tar.gz
ln -s elasticsearch-7.6.1 elasticsearch

- 创建ElasticSearch启动用户并给相关文件夹赋予权限
useradd es
passwd es
chown -R es:es /usr/local/src/elasticsearch-7.6.1
chown -R es:es /usr/local/src/elasticsearch
- 修改配置文件
elasticsearch-7.6.1/config/elasticsearch.yml
当前主机名是: master
node.name: node-1
network.host: master
discovery.seed_hosts: ["master"]
- 修改配置文件
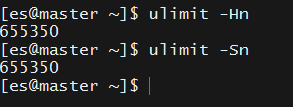
/etc/security/limits.conf
修改后通过ulimit -Hn 和 ulimit -Sn查看是否生效
* soft nofile 655350
* hard nofile 655350
- 修改配置文件
/etc/sysctl.conf
并执行sysctl -p重新加载该配置文件
vm.max_map_count=655360
- 启动ElasticSearch
cd /usr/local/src/elasticsearch/bin
./elasticsearch
# 或者 ./elasticsearch -d 以后台进程的方式启动

- 验证ElasticSearch是否正常
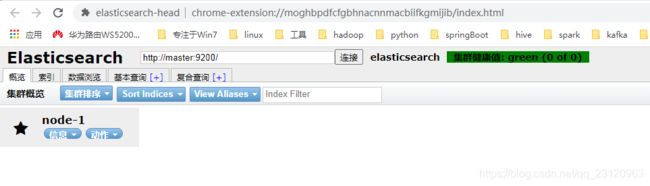
在浏览器上输入 http://master:9200/ 得到下图所示

curl方式访问curl -XGET "http://master:9200"

ElasticSearch Head安装
该工具是GitHub开源的项目elasticsearch-head,能连接上ElasticSearch集群并以可视化的界面呈现信息。
该项目不仅提供了前端项目连接ElasticSearch的方式,也提供了Chrome插件方式,我们此处用Chrome插件方式即可。
插件下载地址是https://raw.githubusercontent.com/mobz/elasticsearch-head/master/crx/es-head.crx
为了能够临时解析访问该地址,需要在C:\Windows\System32\drivers\etc\hosts文件添加如下内容,添加后就可以下载了。
199.232.28.133 raw.githubusercontent.com
然后解压文件es-head.crx

打开Chrome浏览器的扩展程序页面chrome://extensions/ 并选择刚刚解压的文件夹es-head

会出现如下图的插件

点击红框按钮即可

在输入框输入ElasticSearch的HTTP访问地址,点击连接看到如下图即为正常
Kibana安装
- 解压文件
将文件放到/usr/local/src/packages/es目录下
解压文件并建立软连接
cd /usr/local/src
tar zxPvf packages/es/kibana-7.6.1-linux-x86_64.tar.gz
ln -s kibana-7.6.1-linux-x86_64 kibana
- 赋予权限
chown -R es:es /usr/local/src/kibana-7.6.1-linux-x86_64
chown -R es:es /usr/local/src/kibana
- 修改配置文件
/usr/local/src/kibana-7.6.1-linux-x86_64/config/kibana.yml
server.host: "master"
elasticsearch.hosts: ["http://master:9200"]
i18n.locale: "zh-CN"
- 启动Kibana,默认端口是
5601
cd /usr/local/src/kibana-7.6.1-linux-x86_64/bin
./kibana
- 在浏览器上输入
http://master:5601/


同时也能在ElasticSearch Head插件看到Kibana自己的索引,如下图

ElasticSearch增删改查
新增文档(Index API)
新增文档有两种方式
PUT //_doc/<_id> POST //_doc/
<_id>是可选的,如果用PUT方法必须要传入<_id>,如果用POST方法则会自动生成ID
GET /student/_search
{
"query": {
"match_all": {}
}
}
PUT /student/_doc/1
{
"name": "jackie",
"age": 26,
"school": "ShenZhen University",
"desc": "技术宅, 动漫爱好者, 大数据"
}
POST /student/_doc
{
"name": "marry",
"age": 27,
"sex": "girl",
"desc": "可爱的女生"
}


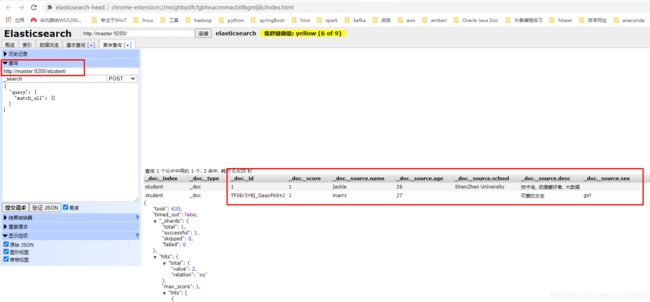
我们可以在ElasticSearch Head插件里查询到刚刚插入的数据
修改文档(Update API)
POST /
可用于更新该文档的指定字段内容,若想全部更新则可以使用上面提到的PUT方法
POST /student/_update/1
{
"doc": {
"sex": "boy",
"age": "28"
}
}

查询文档(Get API)
GET
GET /student/_doc/1

删除文档(Delete API)
DELETE /
DELETE /student/_doc/1

批量操作(Bulk API)
BULK API就是在单个API调用中执行多个Index或Create或Delete或Update操作,减少了开销,大大提高了索引速度。
但是单个API中到底执行多少个Action性能最好需要根据集群的配置来实验优化选择合适的Action数。
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
请求格式如下
POST /_bulk
POST //_bulk
数据格式如下
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
....
action_and_meta_data\n
optional_source\n
Index和Create操作期望下一行就是source内容。如果文档document已存在那么Create会报错,Index则会根据需要更新或添加一个document。Update操作期望下一行是partial doc, upsert, and script and its options。Delete操作下一行无内容即可。
如批量插入数据
由于我指定了往lol这个索引插入数据,所以action_and_meta_data没有显示指定索引
POST /lol/_bulk
{"index":{"_id": "1"}}
{"heroId":1,"name":"黑暗之女","alias":"Annie","title":"安妮","roles":["mage"],"attack":2,"magic":10,"difficulty":6,"goldPrice":4800,"couponPrice":2000,"keywords":["安妮","黑暗之女","火女","Annie","anni","heianzhinv","huonv","an","hazn","hn"]}
{"index":{"_id": "2"}}
{"heroId":2,"name":"狂战士","alias":"Olaf","title":"奥拉夫","roles":["fighter","tank"],"attack":9,"magic":3,"difficulty":3,"goldPrice":1350,"couponPrice":1500,"keywords":["狂战士","奥拉夫","kzs","alf","Olaf","kuangzhanshi","aolafu"]}
{"index":{"_id": "3"}}
{"heroId":3,"name":"正义巨像","alias":"Galio","title":"加里奥","roles":["tank","mage"],"attack":1,"magic":6,"difficulty":5,"goldPrice":3150,"couponPrice":2000,"keywords":["正义巨像","加里奥","Galio","jla","zyjx","zhengyijuxiang","jialiao"]}
{"index":{"_id": "4"}}
{"heroId":4,"name":"卡牌大师","alias":"TwistedFate","title":"崔斯特","roles":["mage"],"attack":6,"magic":6,"difficulty":9,"goldPrice":4800,"couponPrice":3000,"keywords":["卡牌大师","崔斯特","卡牌","TwistedFate","kp","cst","kpds","kapaidashi","cuisite","kapai"]}
{"index":{"_id": "5"}}
{"heroId":5,"name":"德邦总管","alias":"XinZhao","title":"赵信","roles":["fighter","assassin"],"attack":8,"magic":3,"difficulty":2,"goldPrice":3150,"couponPrice":2500,"keywords":["德邦总管","德邦","赵信","XinZhao","db","dbzg","zx","debangzongguan","debang","zhaoxin"]}
如批量删除数据
由于我的API里没有显示指定索引,所以在action_and_meta_data必须要显示指定哪个索引
POST /_bulk
{"delete":{"_index": "lol", "_id": "1"}}
{"delete":{"_index": "lol", "_id": "2"}}
{"delete":{"_index": "lol", "_id": "3"}}
{"delete":{"_index": "lol", "_id": "4"}}
{"delete":{"_index": "lol", "_id": "5"}}
如批量更新数据
POST /lol/_bulk
{"update":{"_id": "1"}}
{"doc": {"age": 11}}
{"update":{"_id": "2"}}
{"doc": {"age": 12}}
{"update":{"_id": "3"}}
{"doc": {"age": 13}}
当然批量操作的Action类型是可以混用的。
普通插入的Curl语句如下,需要指定请求头Content-Type: application/json
curl -XPOST "http://master:9200/test1/_doc" -H 'Content-Type: application/json' -d'{ "name": "marry", "age": 27, "sex": "girl", "desc": "可爱的女生"}'
但是批量操作如果用Curl的方式,则必须将请求数据存入文件,指定请求头Content-Type: application/x-ndjson,然后使用--data-binary "@filename"指定数据文件。如下所示
curl -s -XPOST "http://master:9200/_bulk?pretty" -H "Content-Type: application/x-ndjson" --data-binary "@delete_lol_requests"

根据多个文档ID获取文档(Multi Get API)
Multi Get API可以根据多个文档ID批量获取文档数据。既可以检索多个索引的多个文档,也可以检索单个索引的多个文档。
API请求格式如下。
GET /_mget
GET //_mget
请求体参数如下图

下面就是通过/_mgetAPI批量获取文档的例子
GET /lol/_mget
{
"ids": ["1","2","3"]
}
# 只想获取指定字段
GET /lol/_mget
{
"docs": [
{
"_id": "1",
"_source": {
"include": ["name", "age"]
}
},
{
"_id": "2",
"_source": {
"include": ["name", "age"]
}
},
{
"_id": "5",
"_source": {
"include": ["name", "age"]
}
}
]
}
GET /lol/_mget
{
"docs": [
{
"_id": "1",
"_source": ["name", "age"]
},
{
"_id": "2",
"_source": ["name", "age"]
},
{
"_id": "5",
"_source": ["name", "age"]
}
]
}
ES中文分词器
内置的标准分词器standard
我们以中华人民共和国国歌为例进行分词
# 默认分词器
# standard whitespace
POST /_analyze
{
"text": "中华人民共和国国歌",
"tokenizer": "standard"
}
如下图所示,将每个汉字当成了一个token


IK分词器
- 安装
该项目elasticsearch-analysis-ik已在GitHub开源。
由于我们的ElasticSearch版本是7.6.1,所以也需要下载对应版本的IK分词器。
安装步骤很简单,将下载好的elasticsearch-analysis-ik-7.6.1.zip放到/usr/local/src/packages/es目录下,将解压到es-home/plugins/ik文件夹后重启ES即可。
# 在ES的HOME/plugins下创建ik文件夹
su - es
mkdir -p /usr/local/src/elasticsearch-7.6.1/plugins/ik
# 将IK分词器压缩包解压到/usr/local/src/elasticsearch-7.6.1/plugins/ik
su - root
cd /usr/local/src/packages/es
unzip elasticsearch-analysis-ik-7.6.1.zip -d /usr/local/src/elasticsearch-7.6.1/plugins/ik
chown -R es:es /usr/local/src/elasticsearch-7.6.1/plugins/ik
启动会看到如下加载了插件loaded plugin [analysis-ik]的日志

- ik_max_word 分词
# ik_max_word即最细粒度分词器,穷尽可能
POST /_analyze
{
"text": "中华人民共和国国歌",
"tokenizer": "ik_max_word"
}


- ik_smart 分词
# ik_smart即最粗粒度分词器
POST /_analyze
{
"text": "中华人民共和国国歌",
"tokenizer": "ik_smart"
}

- ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
- 自定义词典
我们以圣枪游侠卢锡安为例进行分词,我想得到两个token即圣枪游侠和卢锡安,但是ik_max_word和ik_smart都无法得到我想要的结果,所以需要自定义词典。
- 修改配置文件
ES-HOME/plugins/ik/config/IKAnalyzer.cfg.xml
添加了两个词典文件custom/my.dic和custom/lol.dic(编码格式必须是UTF-8)
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">custom/my.dic;custom/lol.dicentry>
<entry key="ext_stopwords">entry>
properties>
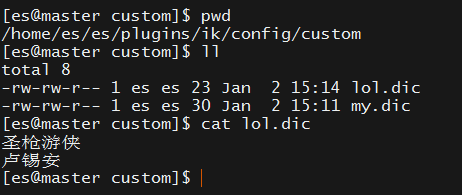
- 在自定义词典
custom/lol.dic中添加token
- 验证结果
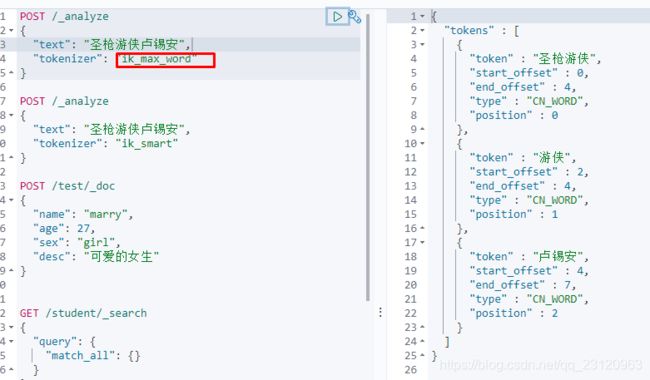
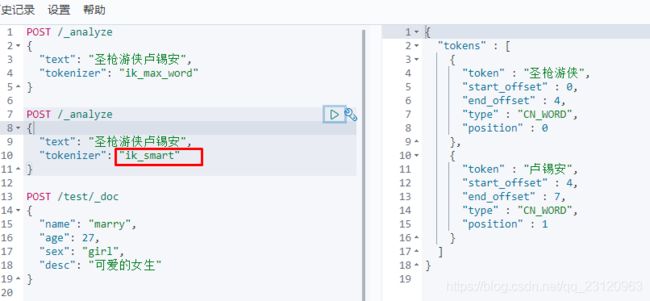
问题
单机情况下增加索引集群健康状态是yellow
在增加test索引后集群状态是yellow
POST /test/_doc
{
"name": "marry",
"age": 27,
"sex": "girl",
"desc": "可爱的女生"
}

这是因为默认自动创建的索引number_of_replicas=1即默认副本数为1
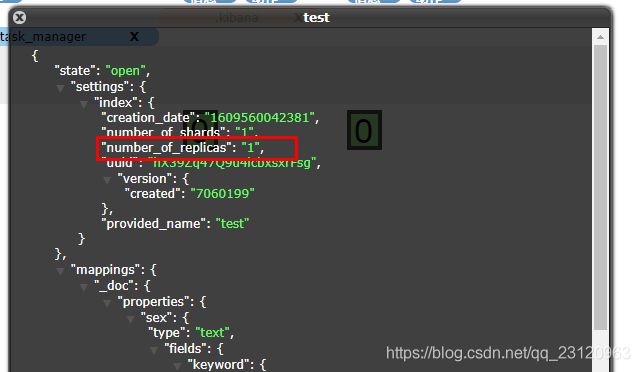
由于此处是单机不需要副本,可以通过AP将该索引副本数设置为0即可
# 设置索引的副本数为0
PUT /test/_settings
{
"number_of_replicas": "0"
}

参考网址
ElasticSearch7.6官网文档
ElasticSearch与Solr对比
ElasticSearch倒排索引结构分析
狂神说ES教程
ElasticSearch在Linux上安装遇到的问题
ElasticSearch中文分词器
ElasticSearch官网client API