yolo3目标检测整体思路+学习心得
连着看了几天的yolo源码,觉得不整理一下的话还真的有点理不清。先推荐几篇博文。也是本文参考的一些文章:
YOLOv3 算法的一点理解
睿智的目标检测11——Keras搭建yolo3目标检测平台
【论文理解】理解yolov3的anchor、置信度和类别概率
深入理解YOLO v3实现细节 - 第1篇 数据预处理
看代码心得:
初学者直接看代码是非常痛苦的,首先各种作者实现yolo3的方法不一样,其次虽然yolo3听起来没多少东西,但是零零碎碎的还是蛮多的。这里建议看代码时主要学思想,同时可以一起看多篇代码,因为只有一篇代码,会很容易走进死胡同,但如果同样的方法用另一种代码实现,可能就很容易明白。一个完整的yolo3代码中包含各种方法,我们首先要确定整体思路,注意看代码的次序,同时要注意代码的前后结合,联系上下文也很重要。另外如果有一方面实在不懂,看博文也都含糊不清,那就建议看有【论文理解】字样的文章,从底层思想入手更容易理解。

yolo3目标检测实现过程:
-
数据集导入:
例如VOC数据集或者COCO数据集,需要提取标签信息,标签中含有图片中的真实框信息——坐标宽高和类别。需要准备数据的锚盒路径,类文件路径。如果要用预训练的权重训练,则需要准备yolo3的权重文件。 -
图片类型转换:
一张图片进入训练的形状是怎么发生变化的呢?如果需要的图片训练大小为416,而输入的图像是(832,664),如果要变成(416,416)的形状,需要对图像进行灰度条填充。也就是在转换完后原图大小变成了(416,332),需要在高的两侧加上(416-332)/2的灰度,实现不失真的resize。

当然相对应图片的真实框信息也要进行转换,就是说将真实框信息首先调整为当前的尺寸,再将y坐标上移一个灰度条距离。 -
锚盒生成:
yolo3原有9个锚盒,分别是3中尺寸和3中宽高比的结合,可以直接用。如果要自己生成锚盒,需要引入锚盒生成算法。主要思想就是用iou进行K-means聚类,将所有的真实框按照iou分成5堆,按照iou聚类的意思,就是在一堆的真实框的彼此iou比较高。怎么判断两个框之间的iou是否比较高的,就是将所有框和随机选出来的聚类中心作比较,如果两个框和聚类中心相比,iou都比较大,那么这两个真实框的iou也是比较大,也就是一类的。
作者发现 k = 5 时就能较好地实现高召回率与模型复杂度之间的平衡。由于在 YOLOv3 算法里一共有3种尺度预测,因此只能是3的倍数,所以最终选择了 9 个先验框。这里还有个问题需要解决,k-means 度量距离的选取很关键。距离度量如果使用标准的欧氏距离,大框框就会比小框产生更多的错误。在目标检测领域,我们度量两个边界框之间的相似度往往以 IOU 大小作为标准。因此,这里的度量距离也和 IOU 有关。需要特别注意的是,这里的IOU计算只用到了 boudnding box 的长和宽。
- 网络结构:
很多文章都很详细的讲解过这一部分,在这里就不细说了。主干网络Darknet-53进行特征提取,yolo部分进行特征处理,最后输出3个特征图。其结果为(N,13,13,3,85),(N,26,26,3,85),(N,52,52,3,85)。最后一个维度中的85包含了4+1+80,分别代表x_offset、y_offset、h和w、置信度、分类结果。
尺寸为 416X416 的输入图片进入 Darknet-53 网络后得到了 3 个分支,这些分支在经过一系列的卷积、上采样以及合并等操作后最终得到了三个尺寸不一的 feature map,形状分别为 [13, 13, 255]、[26, 26, 255] 和 [52, 52, 255]。
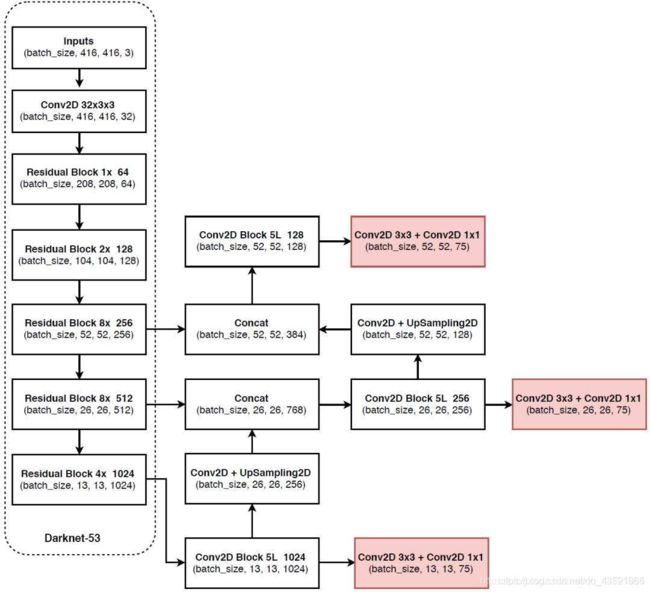
-
解码:
在获得特征图后,要进行解码。注意这时还没有找每个特征点对应的先验框,只是处理网络输出结果。将特征图的返回值对应到图片上,根据输出的x,y宽和高偏移,**对特征图上所有先验框的位置进行调整。**不同特征层的形状不一样,对应的解码而不一样。输入的input有3个,类似为( batch_size, 255, 13, 13)。主要步骤就是将输出偏移对特征图上的锚盒进行调整,之后返回到input_size上,也就是416的图形上。 -
非极大值抑制(NMS):
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,说白了就是去除掉那些重叠率较高并且 score 评分较低的边界框。根据置信度阈值(conf_thres)和nms阈值进行调整(nms_thres)。参考下面例子:
# 流程1: 判断边界框的数目是否大于0
while len(cls_bboxes) > 0:
# 流程2: 按照 socre 排序选出评分最大的边界框 A
max_ind = np.argmax(cls_bboxes[:, 4])
# 将边界框 A 取出并剔除
best_bbox = cls_bboxes[max_ind]
best_bboxes.append(best_bbox)
cls_bboxes = np.concatenate([cls_bboxes[: max_ind], cls_bboxes[max_ind + 1:]])
# 流程3: 计算这个边界框 A 与剩下所有边界框的 iou 并剔除那些 iou 值高于阈值的边界框
iou = bboxes_iou(best_bbox[np.newaxis, :4], cls_bboxes[:, :4])
weight = np.ones((len(iou),), dtype=np.float32)
iou_mask = iou > iou_threshold
weight[iou_mask] = 0.0
cls_bboxes[:, 4] = cls_bboxes[:, 4] * weight
score_mask = cls_bboxes[:, 4] > 0.
cls_bboxes = cls_bboxes[score_mask]
不妨举个简单的例子:假如5个边界框及评分为: A: 0.9,B: 0.08,C: 0.8, D: 0.6,E: 0.5,设定的评分阈值为 0.3,计算步骤如下。
步骤1: 边界框的个数为5,满足迭代条件;
步骤2: 按照 socre 排序选出评分最大的边界框 A 并取出;
步骤3: 计算边界框 A 与其他 4 个边界框的 iou,假设得到的 iou 值为:B: 0.1,C: 0.7, D: 0.02, E: 0.09, 剔除边界框 C;
步骤4: 现在只剩下边界框 B、D、E,满足迭代条件;
步骤5: 按照 socre 排序选出评分最大的边界框 D 并取出;
步骤6: 计算边界框 D 与其他 2 个边界框的 iou,假设得到的 iou 值为:B: 0.06,E: 0.8,剔除边界框 E;
步骤7: 现在只剩下边界框 B,满足迭代条件;
步骤8: 按照 socre 排序选出评分最大的边界框 B 并取出;
步骤9: 此时边界框的个数为零,结束迭代。
- 选择预测特征点的先验框:
如何在训练中确定哪个bounding box负责某个ground truth呢?方法是求出每个grid cell中每个anchor box与ground truth box的IOU(交并比),IOU最大的anchor box对应的bounding box就负责预测该ground truth,也就是对应的对象。真实框的中心落在哪个cell里,就由该cell里的iou最大的那个锚盒进行回归预测。
下面我将筛选出来,负责目标检测回归的先验框成为回归先验框
-
训练过程:
训练网络当然是使用优化器和损失函数。根据损失函数对模型进行优化。损失函数的形成是根据在选择回归先验框后,可以得到一系列的损失。包括对于每个选择回归先验框的置信度,回归先验框和真实框之间的位置偏移数据等,这些数据提供我们计算损失函数。细节部分可以参考这篇文章yolo3损失函数生成过程详解(get_target,get_ignore) -
损失函数计算:
观察损失函数的源代码。包含四种损失,坐标损失,宽高损失,置信度损失和类损失。
object_mask : 置信度
ignore_mask : 表示iou低于一定阈值的但确实存在的物体
box_loss_scale :2-目标面积
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)+ \
(1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:], from_logits=True)
坐标xy采用的二分类交叉熵损失,因为坐标xy的预测实际进行了归一化,是一个相对值。
而宽高wh则采用的差方和,等于1/2*(真值-预测的值)^2。这里使用1/2只是为了方便求导时约掉系数。
这里值得一提的是box_loss_scale
这个值,它等于2-目标面积,这个值是用于平衡大小目标之间的损失不均的问题,因为小目标在wh和xy的损失和大目标在wh和xy的损失不相同,大的目标的检测框的预测相对偏移值由于和大的anchor相比,所以相对值较小,但是小目标和小的anchor相比,所以小目标对于坐标和高宽的精确程度更加严格,所以采用box_loss_scale
来加重其损失权重。
重点:
①要注意box_loss_scale 这个变量,原文论述很详细了。因为小物体的框偏差即使很小,但看起来很明显,大物体的框偏差不明显,甚至有时是可以忽略的。因此我们希对小物体的框回归训练程度更强,所以需要给小物体检测更大的损失值。(2-目标面积)的值可以做到。
②对于置信度损失原文并没有给出详细说明,这里解释一下。置信度是每个bounding box输出的其中一个重要参数,作者对他的作用定义有两重:
一重是:代表当前box是否有对象的概率P r ( O b j e c t ) P_{r}(Object)。注意,是对象,不是某个类别的对象,也就是说它用来说明当前box内只是个背景(backgroud)还是有某个物体(对象);
另一重:表示当前的box有对象时,它自己预测的box与物体真实的box可能的iou的值,注意,这里所说的物体真实的box实际是不存在的,这只是模型表达自己框出了物体的自信程度。
以上所述,也就不难理解作者为什么将其称之为置信度了,因为不管哪重含义,都表示一种自信程度:框出的box内确实有物体的自信程度和框出的box将整个物体的所有特征都包括进来的自信程度
- 训练自己的数据集:
主干网络Darknet-53提取特征通用,冻结训练可以加快训练速度,也可以在训练初期防止权值被破坏。可以先冻结前一部分提取特征的网络参数再进行训练,然后再解冻进行整体训练。
参考视频:https://www.bilibili.com/video/BV1XJ411D7wF?p=8
一些帮助学习的参考文章
锚盒生成
先验框的生成算法可以参考这篇文章yolo2的先验框的生成代码(解析)
选取特征层:
先读取batch_size张图片进来,遍历每张图片的原始标签,size为(batch_size,n,5),n是某图片含有真实物体的数量,最后一维5包括了x、y、w、h、cls这5个信息。将每张图的所有标签框分别与9个anchor box(不止图片上的这三个)进行IOU(交并比)计算,找出IOU结果最大的那个anchor box所属于的特征层,该标签框也属于该特征层,它所有的编码操作都在这个层里进行。
————————————————
版权声明:本文为CSDN博主「奶糖哥哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/L1778586311/article/details/112677574
anchor、置信度和类别概率:
有以上理解困难的同学可以参考【论文理解】理解yolov3的anchor、置信度和类别概率