OpenCV_12机器学习
前言:《计算机视觉学习路》
人脸识别
哈尔级联法
Haar是专门为解决人脸识别而推出的一种机器学习方法
1.创建Haar级联器
2.导入图片并灰度化
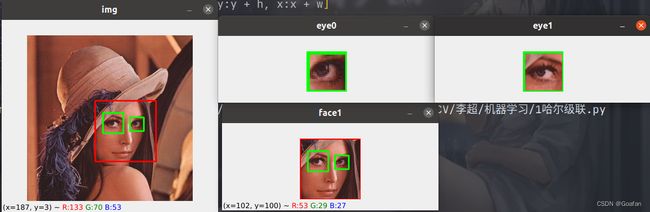
3.调用detectMultiScale方法进行人脸识别
detectMultiScale(img , double scaleFactor = 1.1, int minNeighbors = 3...)
scaleFactor :放缩图片
minNeighbors : 最小的像素值
import cv2
import numpy as np
# 第一步,创建Haar级联器
facer = cv2.CascadeClassifier('../img/haarcascades/haarcascade_frontalface_default.xml')
eye = cv2.CascadeClassifier('../img/haarcascades/haarcascade_eye.xml')
mouth = cv2.CascadeClassifier('../img/haarcascades/haarcascade_mcs_mouth.xml')
nose = cv2.CascadeClassifier('../img/haarcascades/haarcascade_mcs_nose.xml')
# 第二步,导入人脸识别的图片并将其灰度化
img = cv2.imread('../img/lena.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 第三步,进行人脸识别
# 返回数组[[x,y,w,h]]
# 检测出的人脸上再检测眼睛
faces = facer.detectMultiScale(gray, 1.1, 3)
i = 0
j = 0
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
roi_img = img[y:y + h, x:x + w]
eyes = eye.detectMultiScale(roi_img, 1.1, 3)
for (x, y, w, h) in eyes:
cv2.rectangle(roi_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
roi_eye = roi_img[y:y + h, x:x + w]
eyename = 'eye' + str(j)
j = j + 1
cv2.imshow(eyename, roi_eye)
i = i + 1
winname = 'face' + str(i)
cv2.imshow(winname, roi_img)
# mouths = mouth.detectMultiScale(gray, 1.1, 3)
# for (x,y,w,h) in mouths:
# cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
#
# noses = nose.detectMultiScale(gray, 1.1, 3)
# for (x,y,w,h) in noses:
# cv2.rectangle(img, (x, y), (x+w, y+h), (255, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
Haar + Tesseract车牌识别
Haar查找车牌的位置,Teesseract识别车牌内容
1.通过Haar定位车牌的大体位置
2.对车牌进行预处理:二值化- 形态学 - 去噪 - 缩放
3.调用tesseract完成车牌识别
安装Tesseract:
sudo apt install tesseract tesseract-lang
pip install pytesseract
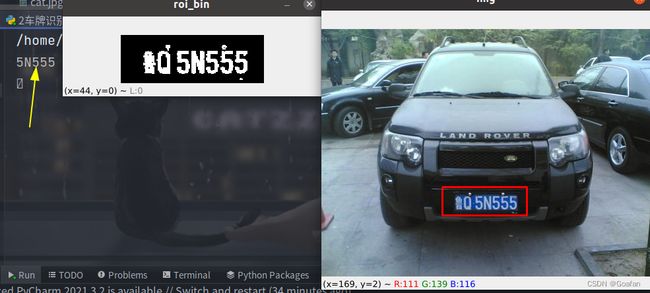 鲁Q没显示出来因为图片太模糊
鲁Q没显示出来因为图片太模糊
import cv2
import numpy as np
import pytesseract
# 第一步,创建Haar级联器
plate = cv2.CascadeClassifier('../img/haarcascades/haarcascade_russian_plate_number.xml')
# 第二步,导入图片
img = cv2.imread('../img/chinacar.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 第三步,车牌定位
# 返回数组[[x,y,w,h]]
# 检测车牌位置
plate = plate.detectMultiScale(gray, 1.1, 3)
for (x, y, w, h) in plate:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
# 对车牌进行预处理
# 提取ROI
roi = gray[y:y + h, x:x + w]
# 二值化
ret, roi_bin = cv2.threshold(roi, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 进行文字提取,lang是语言,中文加英文,中间用+号
# OCR引擎模式oem可选: 0:OriginalTesseract 1:神经网络LSTM 2:Tesseract+LSTM 3:默认什么可选选什么
text = pytesseract.image_to_string(roi , lang='chi_sim+eng',config='--psm 8 --oem 3')
print(text) # 5N555
cv2.imshow('img', img)
cv2.imshow('roi_bin',roi_bin)
cv2.waitKey(0)
深度学习
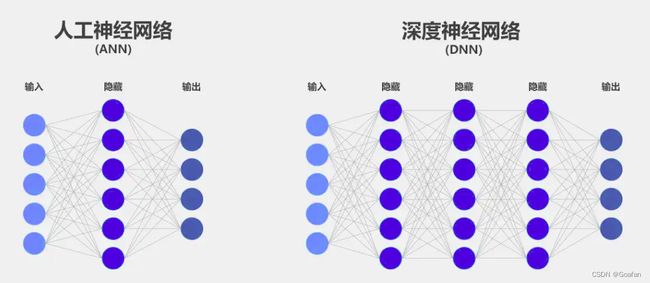
深度学习的网络模型:
DNN 深度神经网络
RNN 循环神经网络
用途:语音识别、机器翻译、生成图像描述
CNN 卷积神经网络
用途:图像分类、目标检测、图像分割、人脸识别
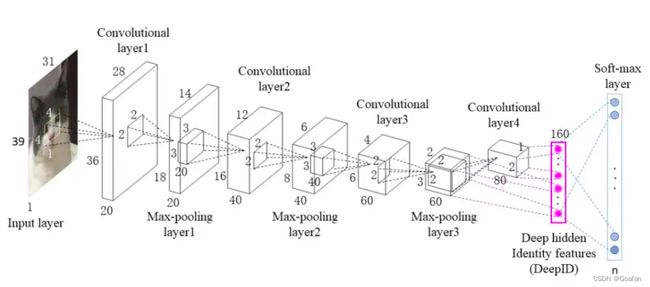
几种CNN的实现:
- LeNet 1998,第一代CNN,28x28手写字体识别
- AlexNet, 2012 , ImageNet比赛的冠军
- VGG , GoogleNet , ResNet
用于目标识别的CNN:
- RCNN 、Fast RCNN 、Faster RCNN
- SSD
- YOLO系列(检测速度最快)
深度学习库
- tensorflow , google
- caffe -> caffe2 ->torch(pytorch) 贾扬清
- MXNet , Apache
常见的数据集
- MNIST、Fashion-MINIST 手写字母
- VOC
- COCO 用于目标检测的大型数据集
- ImageNet
训练出的模型格式
- TF--> .pb文件
- pytorch --> .pth文件 linux下是.pt文件
- Caffe --> .caffe文件
- ONNX开放性神经网络交换格式 --> .onnx 上面的格式都可以转换为onnx文件格式
OpenCV对DNN的支持
只能使用DNN模型,不能训练。
支持的模型有:TF,Pytorch , Caffe , DarkNet , ONNX
如何使用DNN的API?
1.读取模型,得到深度神经网络模型
readNetFromTensorflow(model , config)
readNetFromCaffe(config , model)
readNetDarknet(config model)
readNet(model , [config , [framework]]) # 通用
2.读取图片/视频
3.将图片转换成张量,送入DNN
blobFromImage(img , scalefactor = 1.0 , size=Size(),mean = Scalar() ,swapRB=false,crop = false...)
mean:消除光照影响 swapRB根据深度学习模型,是否交换RB通道 crop :是否对图片裁剪
net.setInupt(blob)
net.forward()
4.进行分析,得到结果
import numpy as np
import argparse
import time
import cv2
from cv2 import dnn
# 1.导入模型,创建神经网络
config = '../img/model/bvlc_googlenet.prototxt'
model = '../img/model/bvlc_googlenet.caffemodel'
net = dnn.readNetFromCaffe(config, model)
# 2.读取图片,转为张量
img = cv2.imread('../img/smallcat.jpeg')
blob = dnn.blobFromImage(img,
1.0, # 缩放因子
(224, 224), # 模型要求的图片尺寸
(104, 117, 123)) # 模型定义的
# 3.将张量输入网络中,进行预测
net.setInput(blob)
r = net.forward() # r是分类后的结果
# 读入类目
path = '../img/model/synset_words.txt'
classes = []
with open(path, 'rt') as f:
classes = [x[x.find(" ") + 1:] for x in f]
# 每行的第一项进行倒序
ord = sorted(r[0], reverse=True)
# 对匹配最高的三项打印出来
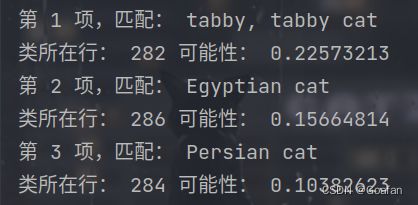
z = list(range(3))
for i in range(0, 3):
z[i] = np.where(r[0] == ord[i])[0][0]
print('第', i + 1, '项,匹配:', classes[z[i]], end='')
print('类所在行:', z[i] + 1, '可能性:', ord[i])