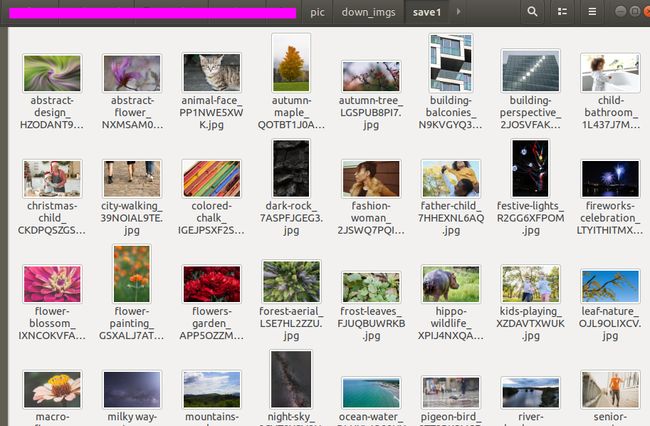
数据采集---高清壁纸
这个链接里面有很多热心网友贡献的链接,有哪些无版权、免费、高清图片素材网站? - 知乎 需要素材就随便点开一个网站去找很方便,今天想用爬虫方式来抓取一下这些图片
确定目标网站:Fireworks Celebration Free Stock CC0 Photo - StockSnap.io
打开界面可以发现,在界面上有个下载按钮,直接点击下载就可以了,但是在很多网站上是没有下载按钮的,这个时候就需要我们另想办法了:
方案一:野生的request

右键检查会发现里边有个url,但是里边并不是高清大图的url地址,
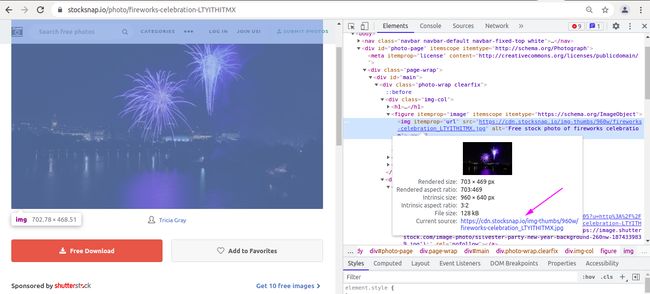
通过抓包工具点击download按钮,会发现有个download的文件,在network工具中查看本次请求的url为Free Stock Photos and Images - StockSnap.io
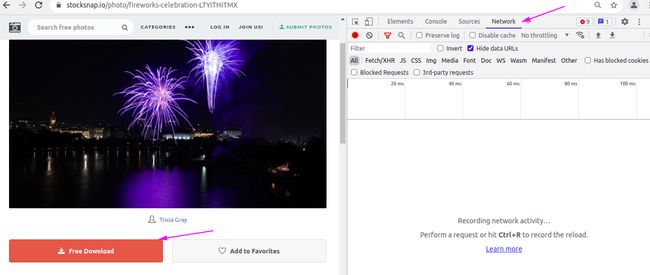
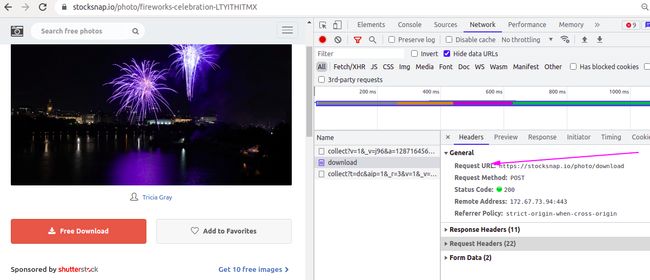
首先直接用url去请求,试图获取网页源代码
import requests
def download_pic(url):
resp = requests.post(url)
print("状态码:", resp)
if __name__ == '__main__':
url = r'https://stocksnap.io/photo/download'
download_pic(url)输出:
状态码: 403状态码代表的含义:
状态码 403 Forbidden 代表客户端错误,指的是服务器端有能力处理该请求,但是拒绝授权访问。. 这个状态类似于 401 ,但进入该状态后不能再继续进行验证。. 该访问是长期禁止的,并且与应用逻辑密切相关(例如不正确的密码)。
显然不正确
于是尝试加上请求头

还是会返回403
再加上请求信息试试
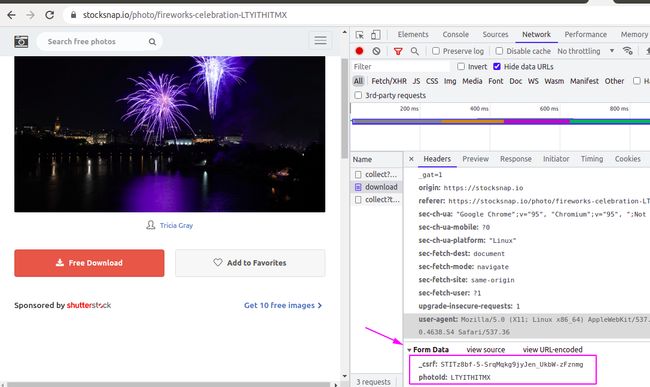
依然会返回403
再加上cookie试试
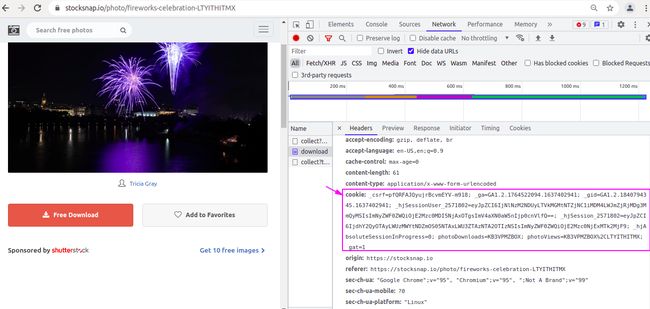
import requests
def download_pic(url):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
"Cookie": "_csrf=pfQRFAJQyujrBcvmEYV-m918; _ga=GA1.2.1764522094.1637402941; _gid=GA1.2.1840794345.1637402941; _hjSessionUser_2571802=eyJpZCI6IjNlNzM2NDUyLTVkMGMtNTZjNC1iMDM4LWJmZjRjMDg3MmQyMSIsImNyZWF0ZWQiOjE2Mzc0MDI5NjAxOTgsImV4aXN0aW5nIjp0cnVlfQ==; photoViews=KB3VPMZBOX,LTYITHITMX; photoDownloads=KB3VPMZBOX,LTYITHITMX"
}
data = {
"_csrf": "STITz8bf-5-SrqMqkg9jyJen_UkbW-zFznmg",
"photoId": "LTYITHITMX"
}
resp = requests.post(url,headers=headers, data=data)
print("状态码:", resp)
if __name__ == '__main__':
url = r'https://stocksnap.io/photo/download'
download_pic(url)输出:这下OK了
状态码: 接下来就是对图片内容的保存了
import requests
def download_pic(url):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
"Cookie": "_csrf=pfQRFAJQyujrBcvmEYV-m918; _ga=GA1.2.1764522094.1637402941; _gid=GA1.2.1840794345.1637402941; _hjSessionUser_2571802=eyJpZCI6IjNlNzM2NDUyLTVkMGMtNTZjNC1iMDM4LWJmZjRjMDg3MmQyMSIsImNyZWF0ZWQiOjE2Mzc0MDI5NjAxOTgsImV4aXN0aW5nIjp0cnVlfQ==; photoViews=KB3VPMZBOX,LTYITHITMX; photoDownloads=KB3VPMZBOX,LTYITHITMX"
}
data = {
"_csrf": "STITz8bf-5-SrqMqkg9jyJen_UkbW-zFznmg",
"photoId": "LTYITHITMX"
}
resp = requests.post(url,headers=headers, data=data)
print("状态码:", resp)
with open('1.jpg', mode='wb') as f:
f.write(resp.content)
if __name__ == '__main__':
url = r'https://stocksnap.io/photo/download'
download_pic(url)运行完成打开图片看看,确实是高清大图

在每次请求一个图片的时候都要进行cookie配置,会很麻烦,下面将用管理session的方式处理
方案二:进阶的request
在主页面刷新network工具查看请求的方式为get,于是通过get方式发送请求
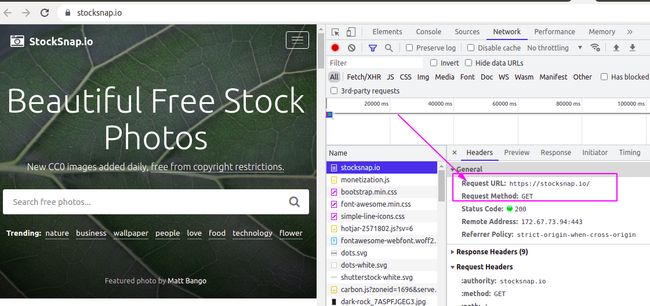
import requests
def download_pic(url):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
}
# data = {
# "_csrf": "STITz8bf-5-SrqMqkg9jyJen_UkbW-zFznmg",
# "photoId": "LTYITHITMX"
# }
session = requests.session()
resp = session.get(url, headers=headers)
print(resp)
resp.encoding = "utf-8"
print(resp.text)
if __name__ == '__main__':
url = r'https://stocksnap.io/'
download_pic(url)输出内容太长
拿到网页源代码之后进行解析获取图片的url

获取到子页面后在子页面中寻找两个请求的参数
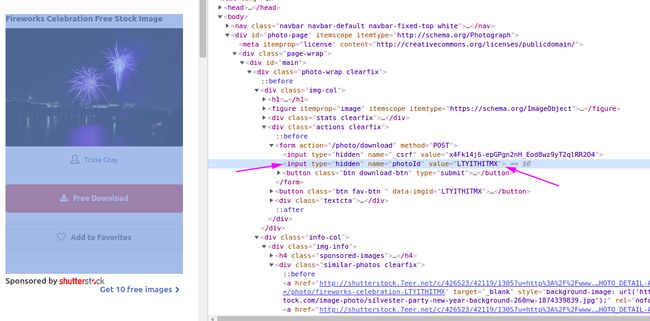
拿到两个请求参数就可以发起请求了
import requests
from lxml import etree
from urllib.parse import urljoin
def download_pic(url):
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
}
session = requests.session()
resp = session.get(url, headers=headers) # 获取主页面
resp.encoding = "utf-8"
source_page = resp.text
tree = etree.HTML(source_page)
hrefs = tree.xpath('//div[@id="main"]/div/a/@href')[1:]
for href in hrefs[0:len(hrefs)-1]:
# print(href)
child_url = urljoin(url, href)
child_resp = session.get(child_url) # 获取到子页面的url
child_resp.encoding = 'utf-8'
child_page = child_resp.text # 拿到子页面
child_tree = etree.HTML(child_page)
# 获取两个请求参数
_csrf = child_tree.xpath('//form[@action="/photo/download"]/input[1]/@value')[0]
photoId = child_tree.xpath('//form[@action="/photo/download"]/input[2]/@value')[0]
# 图片名在保存图片的时候使用
img_name = child_tree.xpath('//img[@itemprop="url"]/@src')[0].split('/')[-1]
print(img_name)
data = {
"_csrf":_csrf,
"photoId":photoId
}
download_url = r'https://stocksnap.io/photo/download'
dwon_resp = session.post(download_url, data=data) # 请求图片的地址
with open(img_name, mode='wb') as f:
f.write(dwon_resp.content)
if __name__ == '__main__':
url = r'https://stocksnap.io/'
download_pic(url)运行之后会获得一批高清图片

这样就下载下来了,但是下载速度有点慢, 改进一下,使用异步协程进行下载
import aiohttp
import asyncio
import aiofiles
import requests
from lxml import etree
from urllib.parse import urljoin
import os
# 本地写入
async def save_one(name,data, href,session):
# async with aiohttp.ClientSession() as session:
async with session.post(href,data=data) as resp:
img = await resp.read()
async with aiofiles.open(os.path.join('save',name),mode='wb') as f:
await f.write(img)
# 请求单个子页面,从子页面中 ,获取图片的请求数据
async def get_one_data(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
}
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers) as child_resp:
child_page = await child_resp.text(encoding='utf-8', errors='ignore')
child_tree = etree.HTML(child_page)
# 获取两个请求参数
_csrf = child_tree.xpath('//form[@action="/photo/download"]/input[1]/@value')[0]
photoId = child_tree.xpath('//form[@action="/photo/download"]/input[2]/@value')[0]
# 图片名在保存图片的时候使用
img_name = child_tree.xpath('//img[@itemprop="url"]/@src')[0].split('/')[-1]
print(img_name)
data = {
"_csrf": _csrf,
"photoId": photoId
}
href = r"https://stocksnap.io/photo/download"
await asyncio.create_task(save_one(img_name, data,href ,session))
# 从主页面中获取所有的子页面url
def get_urls(main_url):
headers = {
"user-agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
}
session = requests.session()
resp = session.get(main_url, headers=headers) # 获取主页面
resp.encoding = "utf-8"
source_page = resp.text
tree = etree.HTML(source_page)
hrefs = tree.xpath('//div[@id="main"]/div/a/@href')[1:]
child_urls = []
for href in hrefs[0:len(hrefs) - 1]:
print(href)
child_url = urljoin(main_url, href)
child_urls.append(child_url)
return child_urls
async def get_all_content_url(all_urls):
tasks = []
for url in all_urls:
task = asyncio.create_task(get_one_data(url))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
main_url = r'https://stocksnap.io/'
all_urls = get_urls(main_url)
asyncio.run(get_all_content_url(all_urls))方案三:scrapy
在终端运行
scrapy startproject pic
cd pic
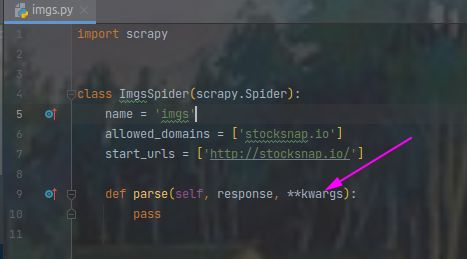
scrapy genspider imgs stocksnap.io将img.py中pase中的参数加入**kwargs可以使pycharm不报黄色警告
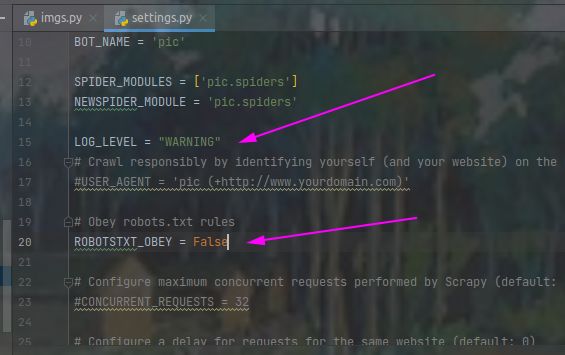
将settings.py中设置警告类型为LOG_LEVEL = "WARNING",并将robots协议设置为False
修改imgs.py并在终端运行scrapy crawl imgs运行以查看能够成功请求到数据
返回
<200 https://stocksnap.io/>说明可以获取到网页源代码,接下来就是对网页源代码进行解析了
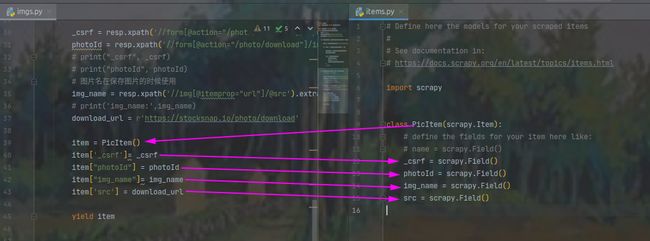
解析部分正在imgs.py中,其中pase函数是对主页面进行解析,返回一个request对象给子页面,子页面得到后通过parse_child函数进行解析,获取图片的高清大图地址,图片名,请求参数等信息
img.py
import scrapy
from scrapy.http import HtmlResponse
from pic.items import PicItem
class ImgsSpider(scrapy.Spider):
name = 'imgs'
allowed_domains = ['stocksnap.io']
start_urls = ['http://stocksnap.io']
def parse(self, response:HtmlResponse, **kwargs):
hrefs = response.xpath('//div[@id="main"]/div/a/@href').extract()
for href in hrefs[0:len(hrefs) - 1]:
child_url = response.urljoin(href)
print(child_url)
yield scrapy.Request(
url=child_url,
method = 'get',
callback=self.parse_child,
)
# break
def parse_child(self, resp, **kwargs):
# print('子页面:', resp)
_csrf = resp.xpath('//form[@action="/photo/download"]/input[1]/@value').extract_first()
photoId = resp.xpath('//form[@action="/photo/download"]/input[2]/@value').extract_first()
# print("_csrf", _csrf)
# print("photoId", photoId)
# 图片名在保存图片的时候使用
img_name = resp.xpath('//img[@itemprop="url"]/@src').extract_first().split('/')[-1]
# print('img_name:',img_name)
download_url = r'https://stocksnap.io/photo/download'
item = PicItem()
item['_csrf']= _csrf
item["photoId"] = photoId
item["img_name"]= img_name
item['src'] = download_url
yield item因为在返回中指定了标准格式的字典,因此在items.py中需要设置与之对应的Field
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class PicItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
_csrf = scrapy.Field()
photoId = scrapy.Field()
img_name = scrapy.Field()
src = scrapy.Field()两个文件是相互对应的
配置好img.py后,进到pipelines.py中进行配置,配置如下,其中get_media_requests函数指定一个请求对象,file_path函数指定图片的保存路径
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from pic import settings
import scrapy
import json
import os
class PicPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
src = item['src']
data = {
"_csrf":item["_csrf"],
"photoId":item["photoId"]
}
yield scrapy.FormRequest(url=src, formdata=data,meta={"item": item})
def file_path(self, request, response=None, info=None, *, item=None):
item = request.meta['item']
img_name = item['img_name']
return os.path.join('save1',img_name)接下来是队settings.py的设置,其中ITEM_PIPELINES会指定管道的执行顺序
# Scrapy settings for pic project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'pic'
SPIDER_MODULES = ['pic.spiders']
NEWSPIDER_MODULE = 'pic.spiders'
LOG_LEVEL = "WARNING"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'pic (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'pic.middlewares.PicSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'pic.middlewares.PicDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'pic.pipelines.PicPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
IMAGES_STORE = './down_imgs'所有文件都配置完成之后就可以下载了,终端运行
scrapy crawl imgs图片很快就下载完成了