数理统计与机器学习
目录
摘要
1.引言
2.贝叶斯算法
2.2.贝叶斯算法推导过程
2.3.贝叶斯算法应用实例
2.4贝叶斯应用小结
3.EM算法
3.1.EM算法介绍
3.2.EM算法理论推导
3.3.EM算法实例应用
3.4.EM算法小结
4. 小结
参考文献
摘要
在现代社会生活当中, 信息技术的进步提升了数据的可利用价值。在此背景下, 数据挖掘的各种方法成为人们研究的对象, 而数理统计作为数据分析的理论基础, 更是受到了广泛的重视。本文从数理统计和计算机数据挖掘领域共有得贝叶斯算法和EM算法为例,进行贝叶斯算法和EM算法的介绍。从数理统计的角度进行算法的理论推导,从计算机的角度以具体实例来说明算法的应用。最后通过这两个算法的学习,加深了我对数理统计领域和数据挖掘领域的理解,也极大激发了我对数理统计在数据挖掘方面应用的兴趣。
关键词:贝叶斯算法;EM算法;数理统计;数据挖掘
1.引言
在偏理论的算法还没有被应用到生活中时,统计学和计算机中的数据挖掘是完全两个不同的领域,然而随着计算机的快速发展和统计学中理论的不断深入,人们越来越发现数理统计中的许多基础理论是数据挖掘领域的基础,数据挖掘中许多经典算法有很多都是从数理统计中迁移过来的,换句话说,数据挖掘在一定程度上是数理统计在实际生活中的实例应用。本文通过讲解数据统计中两个经典算法及其应用,展示数理统计在数据挖掘方面的应用。
2.贝叶斯算法
2.1.贝叶斯算法介绍
贝叶斯算法是统计学中的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。
通俗来讲,贝叶斯算法是一种把类的先验知识和数据中收集的新证据相结合的统计原理。具体表示就是先验概率 + 数据 = 后验概率。贝叶斯公式见公式(2.1).
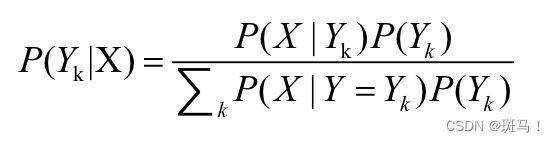 (2.1)
(2.1)
把上面的公式进行扩展到多维向量。以信息分类为例。信息分类是信息处理中最基本的模块,每一段信息无论长与短,都由若干特征组成,因此可以将所有特征视为一个向量集有向量集W = (W1, W2, W3, …,W n),其中Wi即表示其中第i个特征.而信息的分类也可以视为一个分类标记的集合C = {C1, C2, C3, …,Cn}.在进行特征学习之前,特征Wi与分类标记C j的关系不是确定值,因此需要提前P(C|W).即在特征Wi出现的情况下,信息属于分类标记C的概率对应的公式为公式(2.2):
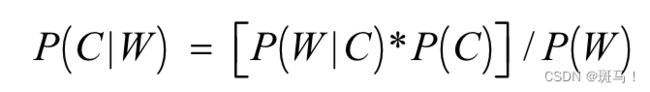 (2.2)
(2.2)
2.2.贝叶斯算法推导过程
有统计学的知识:如果X和Y相互独立,则有联合概率:
P(X,Y) = P(X)*P(Y) (2.3)
有条件概率公式:
P(Y|X) = P(X,Y) / P(X) (2.4)
P X|Y) = P(X,Y) / P(Y) (2.5)
即
P(Y|X) = P(X|Y)P(Y) / P(X) (2.6)
接着由全概率公式:
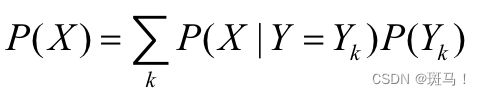 (2.7)
(2.7)
综合上面容易得贝叶斯公式(2.8):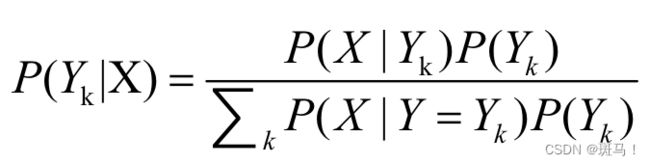 (2.8)
(2.8)
2.3.贝叶斯算法应用实例
已知有如下图的样本数据。某网站发布一条采购产品的信息:没有在词库中,没有经过手机号校验,没有详情,非会员发布的,请判断该条产品信息的真实性?
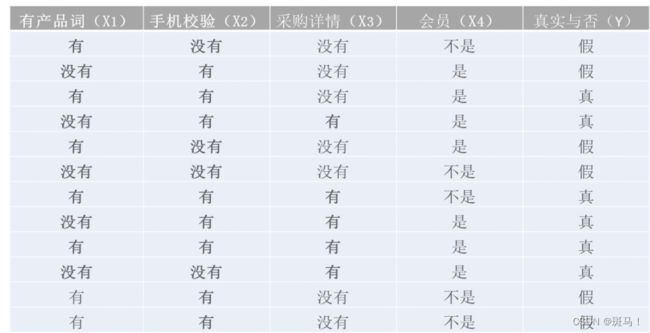
解:
(一)准备阶段
1.确定特征属性x={a1,a2, a3 ,a4}
a1 发布的采购信息产品词是否在我们词库中;
a2 发布信息时是否对手机号进行的短信验证码的校验;
a3 发布的采购信息是否有详情;
a4 发布者是不是网站的会员;
2.确定类别集合C={y1,y2 }
y1 线索为真实采购;
y2 线索为虚假采购
(二)训练阶段
1.对每个类别计算P(y)
P(y=真实)=6/12(总样本数)=1/2
P(y=假)=6/12(总样本数)=1/2
2.对每个特征属性计算所有划分的条件概率P(x | y )
2.1 在y取值真实的情况下
- 针对特征有无产品词计算条件概率:
P(x1=有产品词 | y)=1/2
- 针对特征是否经过手机号校验计算条件概率:
P(x2=经过校验 | y)=5/6
P(x2=不经过校验 | y)=1/6
- 针对特征采购详情校验计算条件概率:
P(x3=有详情 | y)=5/6
P(x3=无详情 | y)=1/6
- 针对特征采购详情校验计算条件概率:
P(x4=会员 | y)=5/6
P(x4=非会员 | y)=1/6
2.2 在y取值为假的情况下
- 针对特征有无产品词计算条件概率:
P(x1=有产品词 | y)=2/3
P(x1=没有产品词 | y)=1/3
- 针对特征是否经过手机号校验计算条件概率:
P(x2=经过校验 | y)=1/2
P(x2=不经过校验 | y)=1/2
- 针对特征采购详情校验计算条件概率:
P(x3=有详情 | y)=0
P(x3=无详情 | y)=1
- 针对特征采购详情校验计算条件概率:
P(x4=会员 | y)=1/3
P(x4=非会员 | y)=2/3
(三)应用阶段
判断题目中样本X(没在词库中,没有经过手机号检验,没有详情,非会员发布)是否为真? 即判断在上述四个特征属性的情况下,该信息为真的概率和该信息为假的概率。
1)计算该信息为真的概率:
P(Y = 真 | x1 = 无,x2 =不经过 , x3 =无 , x4 = 非会员)

由上面公式可以看见,无论是计算该条信息为真的概率还是为假的概率,公式的分母都是![]() ,因此我们只需要计算分子的值并进行比较即可。
,因此我们只需要计算分子的值并进行比较即可。
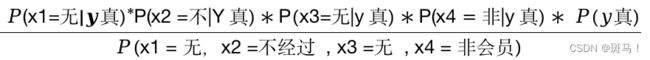
对应的分子为: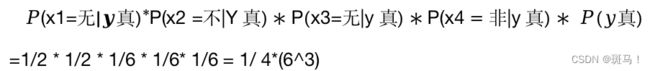
=1/2 * 1/2 * 1/6 * 1/6* 1/6 = 1/ 4*(6^3)
2)计算该信息为假的概率:
同理可求:对应的分子为:1/2 * 1/2 * 1 * 2/3 * 1/3 1/18
比较该信息为真的概率和该信息为假的概率1/18 > 1/ 4*(6^3)。因此可以判断该条信息为假的可能性较大
2.4贝叶斯应用小结
由样例可见贝叶斯算法解题步骤分为三步:
(一)准备阶段:判断有哪些特征属性,特征的取值;判断有哪些类别,进行分类;
(二)训练阶段:根据训练数据集去计算一些概率为后面应用阶段准备。例如各种类别出现的概率;在各种类别各属性取各种对应值的条件概率
(三)应用求解阶段:根据贝叶斯公式,进行具体的特征属性下属于各种类别的概率,比较概率的大小,进行归类。
3.EM算法
3.1.EM算法介绍
EM算法也称期望最大化算法。它是一种隐变量估计方法并且采用迭代优化策略,它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步)。
EM算法受到缺失思想影响,最初是为了解决数据缺失情况下的参数估计问题,其基本思想是:首先根据己经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值估计缺失数据的值,再根据估计出的缺失数据加上己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
3.2.EM算法理论推导
首先给出EM公式和E-step,M-steps,接着借助极大似然估计的思想采用数理统计的知识进行证明。
EM公式:
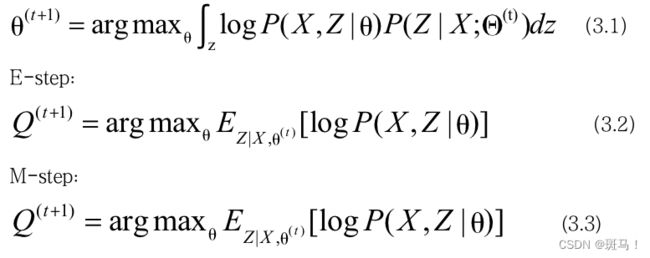
现在进行理论证明,即证明公式(3.1)
证明:
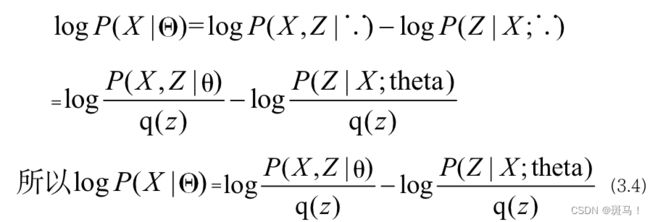
公式(3.4)两边对分布q(z)求期望:
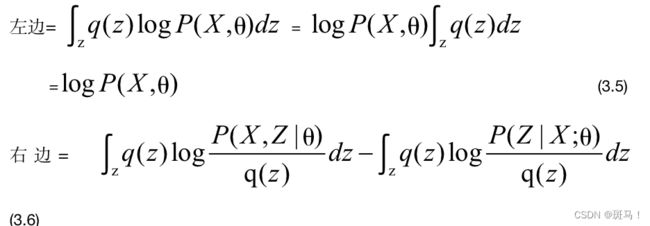


3.3.EM算法实例应用
有两个非标准的硬币,这里的非标准是指掷硬币时得到正反面概率不是相等的对这两个硬币共进行了5组实验每组实验开始前先选定一个硬币然后用这个选定的硬币进行十次投掷对结果进行记录如下图所示:
| 组 |
硬币 |
正反(T代表正面,H代表反面) |
|||||||||
| 1 |
B |
H |
T |
T |
T |
H |
H |
T |
H |
T |
H |
| 2 |
A |
H |
H |
H |
H |
T |
H |
H |
H |
H |
H |
| 3 |
A |
H |
T |
H |
H |
H |
H |
H |
T |
H |
H |
| 4 |
B |
H |
T |
H |
T |
T |
T |
H |
H |
T |
T |
| 5 |
A |
T |
H |
H |
H |
T |
H |
H |
H |
T |
H |
可以看到第一组四组使用了硬币B第二组,第三组,第五组使用硬币A使用最大似然估计这两个硬币扔出正面的概率A硬币共进行3组实验投掷30次其中24次正面所以投掷正面的概率为0.8B硬币共进行了两组实验共投掷20次其中9次正面所以投掷正面的概率为0.45。
接下来对这个小例子进行一点点小小的变化引入EM算法中重要的概念—–隐变量仍然是上面的五组实验数据现在假设不知道每组实验是由哪个硬币投掷的只观测到每次投掷的正反面如何利用最大似然法求每个硬币投掷时正面朝上的概率。
在新的状况下我们只观测到了一部分数据即只有每次投掷结果是正面还是反面被观察到另外一部分数据没有被观察到即每组实验是采用的哪个硬币这里可以发现现在的情况和EM算法提出的动机一样了所以也就意味着可以用EM算法来解决。
解:
先初始化P(a0)=0.6,P(b0)=0.5。
如果硬币是A,则计算第一次实验中5面朝上,5面朝下的概率:(0.6)^5 * (0.4)^5 = 0.0007962 ;如果硬币是B,计算第一次实验中硬币5面朝上5面朝下的概率:b = (0.5)^5 * (0.5)^5 = 0.00097656625.
比较a和b的值,值越大,说明越可能使用该硬币。由上面a,b的数值可以计算出:使用硬币A的概率为:a/(a+b) = 0.45;使用硬币B的概率为:b/( a+ b) = 0.55;由此可见,第一次实验中我们有0.45的概率选择硬币A,有0.45的概率选择硬币B。于是,第一次实验5个为正的结果:对应0.45* 5 = 2.25,所以5个为正的可以看作有2.25个是A产生的,同理,5个为反,0.45*5 = 2.25所以5个反面可以看作有2.5个是a产生的。
同理,我们用初始化的P(a0)=0.6,P(b0)=0.5去计算第二次实验。如果硬币是A,则计算第一次实验中9面朝上,1面朝下的概率:(0.6)^9 * (0.4)^1 = 0.004031078 ;如果硬币是B,计算第一次实验中硬币5面朝上5面朝下的概率:b = (0.5)^9 * (0.5)^1 = 0.00097656625。
由上面a和b的数值可以计算出:使用硬币A的概率为:a/( a + b ) = 0.8;使用硬币B的概率为:b/(a+ b) = 0.2;由此可见,第一次实验中我们有0.8的概率选择硬币A,有0.2的概率选择硬币B。于是,第一次实验9个为正的结果:对应0.8* 9 = 7.2,所以9个为正的可以看作有7.2个是A产生的,同理,1个为反,0.2*1 = 0.2所以5个反面可以看作有0.2个是a产生的。
因为样本中一共有5组数据,上面我们具体计算了第一组和第二组数据,按照上面的思路我们依次完成第三轮,第四轮,第五轮的计算。过程和结果如下面过程图。整个图反映了第一轮过程,我们得到新的P(a1),P(a2).根据新得到的概率加上已知五次测试数据,我们进行第二轮迭代,一直迭代至收敛,得到的结果就是我们想要的结果。
我们使用计算机进行编程模拟可以得到最后的结果为:pa=0.796744 pb=0.519659。
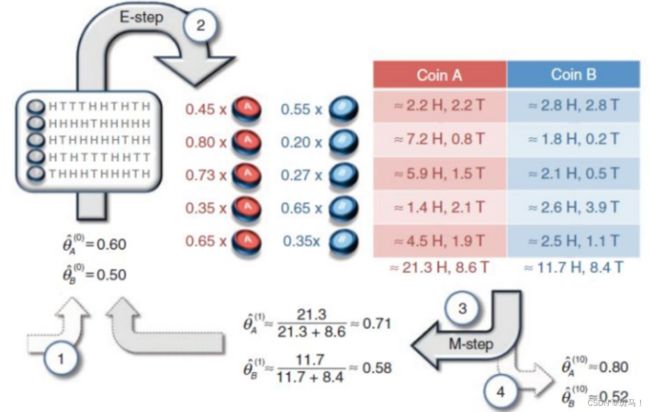
过程图(来源于知乎)
3.4.EM算法小结
EM算法解题思路(以上述硬币为例):
(一):随机初始化A硬币正面朝上的概率和B硬币正面朝上的概率
(二):利用初始化的概率对已知的五组样本数据进行一一训练,利用五组样本数据的均值更新初始化的概率。
(三):利用更新后的概率和已知的五组数据进行第二轮训练,直至收敛,结束迭代,得到结果。
4. 小结
在高等数理统计中贝叶斯算法和EM算法偏向理论定义和介绍,本篇论文通过理论和实例结合全面展现了这两种算法的思想。并且以两个具体例子把理论的算法应用到我们的实际生活中。在一方面能够给我们提供解决问题的思路,在另一方面利用计算机编程去模拟算法也能够提高我们解决问题的能力。
可以看到各行各业、各个领域只有重视数理统计的重要作用, 并且把数理统计和数据挖掘结合起来, 才能为生产和实践活动提供更加准确的参考, 从而形成更加科学的决策。
参考文献
[1] Wu, Xindong, et al. "Top 10 algorithms in data mining." Knowledge and information systems 14.1 (2008): 1-37.
[2] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the royal statistical society. Series B (methodological), 1977: 1-38.