【MySQL】数据库函数通关教程上篇(聚合、数学、字符串、日期、控制流函数)
个人主页:Nezuko627的博客主页
❤️ 支持我: 点赞 收藏 关注
格言:一步一个脚印才能承接所谓的幸运本文来自专栏:MySQL8.0学习笔记
本文参考视频:MySQL数据库全套教程
欢迎点击支持订阅专栏 ❤️

写在前面
本文将 mysql 数据库中函数的相关知识进行了总结,并提供案例供大家吸收学习。需要注意的是对于聚合函数、数学函数、字符串函数、日期函数只需要会使用并熟悉即可,想不起来的时候可以在本文中查询相应的函数。对于控制流函数,在实际查询的时候使用频率还是比较高的,需要重点掌握。特别地,自 mysql 8.0开始新增了窗口函数,新技术还是需要学习的,在下篇中你可以学习到窗口函数包括序号函数、开窗聚合函数、分布函数等,记得关注数据库函数通关教程(下)哦。
文章目录
- 写在前面
- 1 聚合函数
-
- 1.1 GROUP_CONCAT()
- 1.2 其他聚合函数
- 2 数学函数
- 3 字符串函数
- 4 日期函数
-
- 4.1 常见日期函数与使用
- 4.2 日期格式
- 5 控制流函数
-
- 5.1 if逻辑判断语句
- 5.2 case when语句
- 写在最后
1 聚合函数
1.1 GROUP_CONCAT()
简介:
group_concat() 函数首先根据 group by 指定的列进行分组,并且根据分隔符分隔,默认为 ‘,’,将同一个分组的值连接起来,返回一个字符串结果。
语法格式:
GROUP_CONCAT([DISTINCT] 字段名
[ORDER BY 排序字段 ASC/DESC]
[SEPARATOR '分隔符']);
⭕️ 操作示例:
首先我们需要通过下面的代码创建一个表,而后录入一些数据(随意就行),示例代码及数据表示例如下:
CREATE TABLE emp (
eid VARCHAR (20) NOT NULL PRIMARY KEY,
ename VARCHAR (20) NULL,
age INT NULL,
dept_id VARCHAR (20) NULL
);
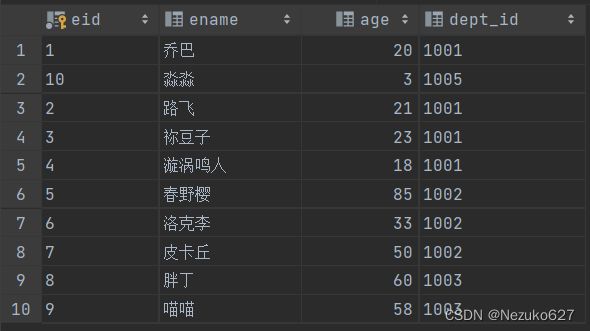
基于此表,简单举例,一段代码对应一个运行结果,供大家理解此函数的作用。
示例 1️⃣ 将所有名字合并成一行,并以爱心分隔
SELECT GROUP_CONCAT(ename SEPARATOR '♥')
FROM emp;

示例 2️⃣ 将所有名字合并成一行,要求根据部门号进行分组,并以年龄总和降序展示
SELECT SUM(age) age_sum, GROUP_CONCAT(ename)
FROM emp
GROUP BY dept_id
ORDER BY age_sum DESC;

1.2 其他聚合函数
| 聚合函数 | 作用 |
|---|---|
| count() | 统计指定列不为Null的记录行数 |
| sum() | 计算指定列的数值和,如果指定列类型不是数值类型,则计算结果为0 |
| max() | 计算指定列的最大值,如果指定列是字符串类型,则使用字符串排序运算 |
| min() | 计算指定列的最小值,如果指定列是字符串类型,则使用字符串排序运算 |
| avg() | 计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0 |
由于博主之前的文章涉及到这些函数的实例,这里就不一一赘述啦,链接附上,详细请见文章中的聚合查询与聚合函数:
【MySQL】DQL数据查询详细学习教程(完整版)

2 数学函数
常用数学函数一览表:
| 函数名 | 说明 |
|---|---|
| ABS( x ) | 返回 x 的绝对值 |
| CEIL( x ) | 返回大于等于 x 的最小整数 |
| FLOOR( x ) | 返回小于等于 x 的最大整数 |
| GREATEST(num1,num2,num3…) | 返回列表中最大的数 |
| LEAST(num1,num2,num3…) | 返回列表中最小的数 |
| MAX(expression) | 返回字段 expression 中的最大值 |
| MIN(expression) | 返回字段 expression 中的最小值 |
| MOD(x,y) | 返回 x 除以 y 后的余数 |
| PI() | 返回圆周率 3.141593 |
| POW(x,y) | 返回 x 的 y 次方 |
| RAND() | 返回 0 - 1 的随机数 |
| ROUND( x ) | 返回距离 x 最近的整数,遵循四舍五入 |
| ROUND(x,y) | 返回距离 x 最近的包含 y 位小数的小数,同样遵循四舍五入 |
| TRUNCATE(x,y) | 返回距离 x 最近的包含 y 位小数的小数,但是不会四舍五入 |
示例代码:
Tips: 答案在代码注释里哦~~~
SELECT ABS(-10); -- 10
SELECT CEIL(8.8); -- 9
SELECT CEIL(-8.8); -- -8
SELECT FLOOR(8.8); -- 8
SELECT FLOOR(-8.8); -- -9
SELECT GREATEST(-1,1,2,3,4,5,6); -- 6
SELECT LEAST(-1,1,2,3,4,5,6); -- -1
SELECT MOD(2.5, 2); -- 0.5
SELECT MOD(2.5, -2); -- 0.5
SELECT MOD(-2.5, 2); -- -0.5
SELECT MOD(-2.5, -2); -- -0.5
SELECT ROUND(5.532); -- 6
SELECT ROUND(5.532, 1); -- 5.5
SELECT TRUNCATE(6.67, 1); -- 6.6
3 字符串函数
常用字符串函数一览表:
| 函数 | 说明 |
|---|---|
| LENGTH( s ) | 按照字节计算 s 的长度,具体由编码格式决定 |
| CHAR_LENGTH( s ) | 返回字符串 s 的字符数 |
| CHARCTER_LENGTH( s ) | 返回字符串 s 的字符数 |
| CONCAT(s1,s2 … sn) | 将字符串 s1 s2 等多个字符串合并成一个字符串 |
| CONCAT_WS(D,s1,s2 … sn) | 合并多个字符串,并以 D 为分隔符 |
| FIELD(s,s1,s2…) | 返回第一个字符串在字符串列表(s1,s2…)中的位置 |
| LTRIM( s ) | 去除字符串左边的空格 |
| RTRIM( s ) | 去除字符串右边的空格 |
| TRIM( s ) | 去除字符串两边的空格 |
| MID(s,n,len) | 从字符串的 s 的 n 位置截取长度为 len 的字符串 |
| POSITION( s1 IN s) | 返回 s1 在 字符串 s 中第一次出现的位置 |
| REPLACE(s,s1,s2) | 将字符串 s2 替代 s 中的所有字符串 s1 |
| REVERSE( s ) | 反转字符串 s |
| RIGHT(s,n) | 返回字符串后 n 个字符 |
| STARCMP(s1,s2) | 比较字符串 s1 s2,如果相等返回0,s1>s2返回1,s1 |
示例代码:
Tips: 答案在代码注释里哦~~~
-- 1.按照字节求长度,注意 utf-8 英文 1 字节 汉字 3 字节
SELECT LENGTH('hello'); -- 5
SELECT LENGTH('祢豆子'); -- 9
-- 2.求字符串长度
SELECT CHAR_LENGTH('祢豆子'); -- 3
-- 3.合并字符串
SELECT CONCAT('我','是','祢豆子'); -- 我是祢豆子
SELECT CONCAT_WS('!','我','是','祢豆子'); -- 我!是!祢豆子
-- 4.返回字符串在列表的第一个位置,没有则返回0
SELECT FIELD('Nezuko','大头','小牛马','Nezuko','几何心凉','Nezuko'); -- 3
SELECT FIELD('小鹏','大头','小牛马'); -- 0
-- 5.去除空格
SELECT LTRIM(' Nezuko'); -- Nezuko
SELECT RTRIM('Nezuko '); -- Nezuko
SELECT TRIM(' Nezuko '); -- Nezuko
-- 6.字符串截取
SELECT MID('我是祢豆子',3,3); -- 祢豆子
-- 7.获取位置
SELECT POSITION('627' IN 'Nezuko627'); -- 7
-- 8.替换字符
SELECT REPLACE('是你的大头大头','大头','小牛马'); -- 是你的小牛马小牛马
-- 9.反转字符串
SELECT REVERSE('我喜欢你'); -- 你欢喜我
-- 10.返回字符串后几个字符
SELECT RIGHT('Nezuko627',3); -- 627
-- 11.字符串比较
SELECT STRCMP('abc','abc'); -- 0
SELECT STRCMP('azc','abc'); -- 1
SELECT STRCMP('abcd','abcdzzzzzz'); -- -1
小提示: 在字符串比较中,比较的是字典顺序,比如 b > a。
4 日期函数
日期函数相关内容大家了解下即可,需要使用的时候回过头来再查找。
4.1 常见日期函数与使用
常用日期函数一览表:
| 函数名称 | 说明 |
|---|---|
| UNIX_TIMESTAMP() | 返回从1970-01-01 00:00:00 到当前的毫秒值 |
| UNIX_TIMESTAMP(DATE_STRING) | 将指定日期转化成为时间戳 |
| FROM_UNIXTIME(BIGINT UNIXTIME,STRINGFORMAT) | 将毫秒值时间戳转为指定格式日期 |
| CURDATE() | 返回当前日期 |
| CURRENT_DATE() | 返回当前日期 |
| DATEDIFF(X, Y) | 获取日期差值,返回 Y 距离 X 有多少天 |
| TIMEDIFF(X,Y) | 获取时间差值,返回 Y 距离 X 有多少秒 |
| DATE_FORMAT(DATE,STRINGFORMAT) | 日期格式化 |
| DATE_SUB(DATE,INTERVAL X DAY/MOUTH…) | 日期减法 |
| DATE_ADD(DATE,INTERVAL X DAY/MONTH…) | 日期加法 |
| EXTRACT(MONTH/DAY/YEAR/HOUR FROM DATE) | 从日期中获取月、日等 |
示例代码:
Tips: 答案在代码注释里哦~~~
-- 1.获取时间戳
SELECT UNIX_TIMESTAMP(); -- 1653890515
-- 2.将一个日期转化为毫秒值
SELECT UNIX_TIMESTAMP('2022-05-30 14:02:57'); -- 1653890577
-- 3.将时间戳转化为指定格式的日期
SELECT FROM_UNIXTIME(1653890577,'%Y-%m-%d %H-%i-%s'); -- 2022-05-30 14-02-57
-- 4.获取当前年月日
SELECT CURDATE(); -- 2022-05-30
-- 5.获取当前时分秒
SELECT CURRENT_TIME(); -- 14:05:30
-- 6.获取当前时间包括年月日时分秒
SELECT CURRENT_TIMESTAMP(); -- 2022-05-30 14:07:12
-- 7.获取日期之间的差值(天)
SELECT DATEDIFF('2022-05-30','2008-07-23'); -- 5059
-- 8.获取时间差值
SELECT TIMEDIFF('17:00:00','16:00:00'); -- 01:00:00
-- 9.日期格式化
SELECT DATE_FORMAT('2022-6-1 14:16:5','%Y-%m-%d %H-%i-%s'); -- 2022-06-01 14-16-05
-- 10.日期加减
SELECT DATE_ADD('2022-06-01',INTERVAL 1 DAY); -- 2022-06-02
SELECT DATE_SUB('2022-06-01',INTERVAL 1 DAY); -- 2022-05-31
-- 11.从日期中获取年、日、月
SELECT EXTRACT(YEAR FROM '2022-06-01'); -- 2022
SELECT EXTRACT(DAY FROM '2022-06-01'); -- 1
SELECT EXTRACT(MONTH FROM '2022-06-01'); -- 6
4.2 日期格式
日期格式附表:
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时(00-23) |
| %h | 小时(01-12) |
| %I | 小时(01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天(001-366) |
| %k | 小时(0-23) |
| %l | 小时(1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时(hh:mm:ss) |
| %U | 周(00-53)星期日是一周的第一天 |
| %u | 周(00-53)星期一是一周的第一天 |
| %V | 周(01-53)星期日是一周的第一天,与 %X 使用 |
| %v | 周(01-53)星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天(0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
5 控制流函数
5.1 if逻辑判断语句
| 格式 | 说明 |
|---|---|
| IF(expr,v1,v2) | 如果表达式 expr 成立,返回 v1,否则返回 v2 |
| IFNULL(v1,v2) | v1如果为 NULL 则返回 v1,否则返回 v2 |
| ISNULL(expr) | 判断表达式是否为 NULL,是就返回 1,反之为0 |
| NULLIF(s1,s2) | 比较字符串,如果 s1 与 s2 相等,就返回 NULL,否则返回 s1 |
案例1️⃣: 查询判断成绩是否优秀
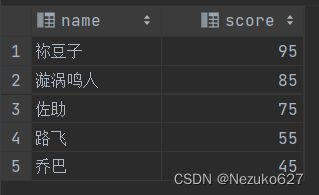
首先先准备下面的数据表,具体数据如图,数据表结构代码如下:
CREATE TABLE IF NOT EXISTS student(
name VARCHAR(20),
score INT
);
INSERT INTO student VALUES ('祢豆子', 95);
INSERT INTO student VALUES ('漩涡鸣人', 85);
INSERT INTO student VALUES ('佐助', 75);
INSERT INTO student VALUES ('路飞', 55);
INSERT INTO student VALUES ('乔巴', 45);
下面使用逻辑判断语句进行确定是否优秀,并查询,参考代码及结果如下:
SELECT *, IF(score >= 85, '优秀', '不优秀') 'grade'
FROM student;
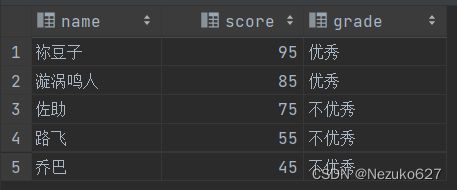
❓ 这里我们仅仅将成绩分成了两类:优秀与不优秀。可是实际情况是成绩分为良好、及格与不及格,但是 if 逻辑判断语句却不能很好的解决,那我们究竟该如何操作才能将成绩分成3类呢? 我们引入 case when 语句。
5.2 case when语句
语法格式:
CASE expression
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionN THEN resultN
ELSE result
END
说明:
CASE 表示函数的开始,END 表示函数的结束,如果 condition1 成立,则返回 result1,以此类推… … 如果都不成立,则返回 ELSE 后的 result。
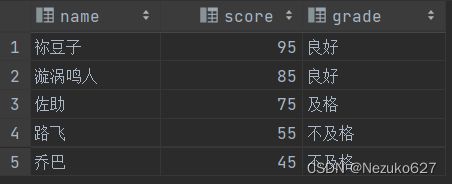
案例2️⃣: 将成绩分为良好、及格与不及格三类
我们还是使用案例1的数据表,并通过 case when函数来实现:
SELECT *,
CASE score
WHEN score >= 85 THEN '良好'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS 'grade'
FROM student;
写在最后
以上便是本文的全部内容啦,后续内容将会持续免费更新,如果文章对你有所帮助,麻烦动动小手点个赞 + 关注,非常感谢 ❤️ ❤️ ❤️ !
如果有问题,欢迎私信或者评论区!

共勉:“你间歇性的努力和蒙混过日子,都是对之前努力的清零。”
