【Python】六一儿童节-万字速通python基础语法,小朋友也能看懂

文章目录
-
- 语句和变量
-
-
- 语句折行
- 缩进规范
- 变量赋值方式
-
- 多重赋值(链式赋值)
- 多元赋值
- 增量赋值
- 变量的作用域和生命周期
-
- 内建函数:globals和locals函数
-
- 其它小知识:
-
-
- python关键字
- 特殊标识符
- 文档字符串
-
- 内建函数:help
- 模块文档
- Unix起始行
-
- 对象和类型
-
- 一切皆是对象
-
- 理解对象和引用
-
- 思考: 为什么Python的变量是这样的? 和C/C++差异这么大捏?
- 理解对象和类型
-
- 关于不可变类型和可变类型:
- 关于动态静态强弱类型
- 标准类型
- 其它内建类型
- 类型的类型
- None ->空类型
- 内建类型的布尔值
- 关于对象的比较
-
- 对象值的比较
- 对象身份的比较
- 对象类型的比较
- 类型工厂函数
- python不支持的类型
- 数字和运算
-
- 整数的位运算
- 常用内置函数/模块
- 关于除法运算的坑:
- 条件和循环
-
- 缩进和悬挂的else
- 条件表达式
- 和循环搭配的else
- 函数和可调用对象
-
- 函数定义和调用
- 函数的参数
- 关键字参数
-
- 关于内建函数:sorted
- 参数组
- 函数重载?->不支持
-
- 为什么不支持
- 函数的返回值
- 函数的内置属性
-
-
- 内建函数dir
-
- 函数也可以作为函数的参数
- 函数也可以作为函数的返回值
- 可调用对象
本文档主要讲解内容:
对以下Python基础语法的一些细节有一定的巩固和认知.
语句和变量
对象和类型
数字和运算
条件和循环
函数和可调用对象
语句和变量
语句折行
如果一行代码太长, 可以折成多行来写, 看起来会更清楚.一定要记得, 代码写出来是给人看的, 不能看不懂. 怎么简单, 怎么清晰, 就怎么写.
-
Python中, 如果一个语句被小括号, 中括号, 大括号包起来, 是可以跨行书写的.
#这样格式化一个字典,字典的元素看起来会清晰很多 serve = { 'ip':"192.168.1.1" , 'port':80 } -
如果没有用括号包起来, 可以使用 \ 来换行.
if x ==1 and \ y ==1: do_something -
双引号(“)和单引号(‘)字符串, 都不能折行, 但是三引号(’‘’/”“”)可以折行.
print('''hello how are you''') -
使用 ; 可以把多个语句写到同一行. 但是强烈不建议这么做.
缩进规范
-
Python中使用缩进表示语句块.
-
同一个语句块中的代码必须保证严格的左对齐(左边有同样数目的空格和制表符).
-
虽然Python语法允许使用制表符作为缩进, 但是Python编码规范强烈不推荐使用制表符. 因为不同的编辑
器的制表符长度不同(4个空格或者8个空格). -
我们推荐使用四个空格来表示一个缩进.
变量赋值方式
多重赋值(链式赋值)
- 可以同时给多个变量赋相同的值
x = y = 1
多元赋值
- 可以同时给多个变量赋不同的值
x,y = 1,2
C语言里, 如何交换两个变量嘛? 我们讲了三种方法
//临时变量交换
int a = 10;
int b = 20;
int tmp = a;
a = b;
b = tmp;
//a+b有溢出的风险
int a = 10;
int b = 20;
a = a + b;
b = a - b;
a = a - b;
//异或法
int a = 10;
int b = 20;
a = a ^ b;
b = a ^ b;
a = a ^ b;
python交换两个变量的写法:
x, y = 10, 20
x, y = y, x
请看这样一段毁你三观的代码(仅限 Python2)
True, False = False, True
if True:
print('haha')
else:
print('hehe')
#程序打印hehe
猜猜输出结果:
- True和False也是变量, 只不过是系统自带的"内置变量", 一样可以修改值的
- 不过我们实际写代码的时候, 千万千万别这么写, 和作死无异~~~(当然, 除非是你故意想埋坑).
增量赋值
- 我们前面提到过, 可以使用 += 直接让变量自增.
- 其实还支持很多其他的自增操作(参见下图).
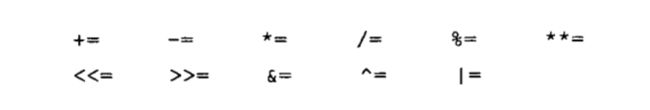
变量的作用域和生命周期
- Python中, def, class(我们后面会讲), lamda(我们后面会讲) 会改变变量的作用域
- if, else, elif, while, for, try/except(我们后面会讲) 不会改变变量的作用域
for i in range(0,10):
print(i)
print(i) #即使出了for循环,变量i仍然能访问i变量 打印9 for不会影响变量的作用域
例子2:
def func():
x = 1
print(x)
print(x) #出了函数的作用域就不能访问x变量
内建函数:globals和locals函数
-
内建函数
globals()返回了全局作用域下都有哪些变量, 内建函数locals()返回了局部作用域下都有哪些变量 -
关于Python的变量的生命周期, 这个不需要程序猿操心, Python提供了垃圾回收机制自动识别一个变量的生命周期是否走到尽头, 并自动释放空间(详情我们稍后再讲).
其它小知识:
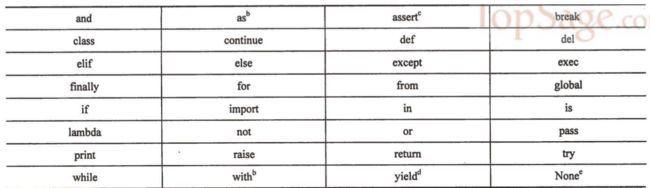
python关键字
特殊标识符
-
Python使用下划线(_)作为变量的前缀和后缀, 来表示特殊的标识符.
-
_xxx表示一个 “私有变量”, 使用
from module import *无法导入.add.py的内容
def _Add(x,y): return x+ytest.py的内容
from add import * print(_Add(1,2)) #报错:NameError: name '_Add' is not defined -
_xxx_ (前后一个下划线), _xxx_ (前后两个下划线) 一般是系统定义的名字. 我们自己在给变量命名时要避开这种风格. 防止和系统变量冲突.
文档字符串
- 写注释对于提升程序的可读性有很大的帮助.
- 前面我们介绍了 # 来表示单行注释.
- 对于多行注释, 我们可以使用 三引号(‘’'/“”") 在函数或者类开始位置表示. 这个东西也被称为 文档字符串
def Add(x,y):
'''
定义两数相加的函数
'''
return x+y
- 使用对象的 doc 属性就能看到这个帮助文档了(别忘了, 函数也是对象).
def Add(x,y):
'''
定义两数相加的函数
'''
return x+y
print(Add.__doc__) #打印: 定义两数相加的函数
内建函数:help
- 或者使用内建函数 help 也可以做到同样的效果.
def Add(x,y):
'''
定义两数相加的函数
'''
return x+y
print(help(Add))
打印结果:

- 注意:文档字符串一定要放在函数/类的开始位置. 否则就无法使用 _doc_ 或者 内建函数help 来访问了.
模块文档
不光一个函数/类可以有一个文档字符串. 一个模块也同样可以.
add.py的内容
注意文档字符串要放在最开始的位置
'''
定义两数相加的函数
'''
def _Add(x,y):
return x+y
test.py的内容
import add
print(add.__doc__) #定义两数相加的函数
print(help(add))
#执行结果
Help on module add:
NAME
add - 定义两数相加的函数
Unix起始行
对于Linux或者Mac这类的Unix类系统, 可以给Python代码文件增加一个起始行, 用来指定程序的执行方式.
保存上面的代码为test.py. 给这个文件增加可执行权限: chmod +x test.py
然后就可以通过 ./test.py 的方式执行了.
对象和类型
一切皆是对象
一个Python的对象, 包含三部分信息:
- 身份: 每一个对象都有一个唯一的身份标识自己. 用内建函数id可以看到这个标识的具体的值.
- 类型: 对象的类型决定了对象保存什么样的值, 可以进行什么样的操作, 以及遵守什么样的规则. 实用内建函
数type可以查看对象的类型. 本质上就是把对象分分类 - 值: 表示对象中具体保存的内容. 有些对象的值可以修改, 有些对象的值不能修改, 这个称为对象的 “可变性”
Python中任何类型的值其实都是一个对象(判定一个东西是不是对象, 就尝试用id取一下看能否取到,如果能取到,说明就是对象).
class:对象 module:模块
100 这样的字面值常量, 也是对象; 一个字符串, 也是对象;
一个函数, 也是对象;
一个类型(type函数的返回值), 其实也是对象; 一个模块, 还是对象;
理解对象和引用
以下面这段简单的代码为例, 仔细看一下对象创建的过程.
a = 2
b = 3
b = 2
按照我们C语言中的理解
a = 2 , 相当于先创建一个变量名a, a就是一个篮子(给a分配了内存空间), 然后把数字2装到a这个篮子中. 但Python中完全不是这样的.
python的理解:
-
我们在解释器中敲入 a = 2 , 首先有一个 integer class 被唤醒(找到了整数对象的图纸).

-
根据 integer class 这个图纸, 在内存中开辟一段空间(得到了对象id), 并填充入对象的类型和值. 房子已经建好, 装修完毕, 家具齐全.
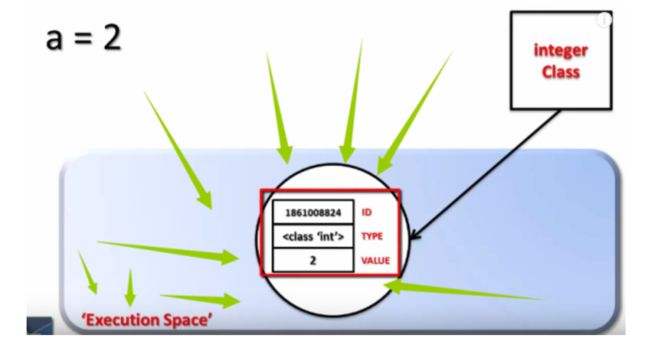
-
万事俱备, 只欠东风. 如果你想住进去, 还得有房子的钥匙. 这个时候, 变量名a其实就是我们的钥匙. 可以搬进去住啦~~美好的生活从此开始
-
卧槽, 老王怎么在隔壁也买了个房子??

-
老王房子建好了, 也拿着钥匙住进去了.

-
再次执行 b = 2 时, 隔壁老王的魔爪伸过来了T_T. 老王拿到了我家的钥匙…
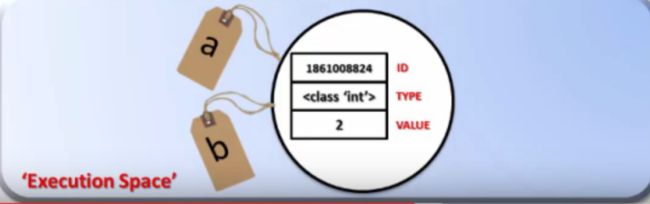
Python中的变量名, 只是一个访问对象的 “钥匙” . 多个不同的变量, 完全可以访问相同的对象, 因此我们讲
这种变量名也叫对象的 “引用”.
验证1:
a = 2
b = 3
print(id(a),id(b)) #140734889681584 140734889681616
b = 2
print(id(b)) #140734889681584
验证2:
b = 3
print(id(b)) #140734889681616
b +=1
print(id(b)) #140734889681648
相加其实是创建一个新的对象,然后把这个标签b移到这个新的对象上
思考: 为什么Python的变量是这样的? 和C/C++差异这么大捏?
- 空间考虑: 比如一个数字2, 在Python中只有这么一个数字2; 而一个C/C++程序中可能会有N个2.
- 时间考虑: 比如 a=b 这样的赋值, 只是修改了一下贴标签的位置, 不需要对对象进行深拷贝. 为什么Python可以这么做, 而C/C++不能这样设计呢?
- C++中的赋值相当于深拷贝, a = 100 b = a ->内存中存放了两份100
- java和python相当于浅拷贝 a = 100 b = a ->a和b都是100的引用,内存中只存放了一份100
Python的GC机制, 是这样的设定的基础.
理解对象和类型
关于不可变类型和可变类型:
- python中的
int,str,float,tuple其实是不可变类型的变量 (即:没办法修改一个已经存在的int类型的对象的值),只能创建新的,不能修改已经有的
s = "hehe"
s[0] = 'a'; #error 报错 TypeError: 'str' object does not support item assignment
s = 'a'+s[1:] #只能重新创建
print(s) #aehe
#原来的hehe对象已经销毁,s贴在了aehe这个对象的身上
- 列表和字典都是可变对象
- 有些对象是 “相似” 的, 于是我们把对象归归类. 比如把所有的整数归为一类, 把所有的浮点数对象归为一类,把所有的字符串归为一类.
- 相同的类型的对象, 须有相同的操作. 比如, 所有的整数对象, 都可以进行加减乘除操作. 所有的字符串都可以使用切片操作.
关于动态静态强弱类型
- Python是一种 动态强类型 编程语言.
- 动态是指运行时进行变量类型检查; 强类型 指类型检查严格, 并且"偏向于"不允许隐式转换.

动态类型:一个变量在运行过程中类型发生变化
静态类型:一个变量在运行过程中类型不能发生变化
强类型:越不支持隐式类型转化,类型越强
弱类型:越支持隐式类型转化,类型越弱
类似的, C语言是一种静态弱类型语言. Java的类型检查更为严格, 一般认为是静态强类型, 而Javascript则是动态弱类型
如:
int a = 10; long b = 20; a = b ->C++可以 java不可
int a = 10; bool b = false; a = b ->C++可以,把false当成0 java不可
动态类型:小规模下更好,使用灵活
大规模常用静态类型,否则多人协作容易有歧义
但是类型:越强越好
标准类型
-
整型
-
浮点型
- 注意:如果想要比较两个浮点数是否相同,不能直接比较,因为会有精度损失,要做差比较
-
复数型
-
布尔型
-
字符串
-
列表
-
元组
-
字典
其它内建类型
- 类型
- NULL对象(None)
- 文件
- 函数
- 模块
- 类
类型的类型
前面我们说, 类型也是对象
print(type(type(100))) #
print(id(type(100))) #140734889206240
None ->空类型
Python有一个特殊的类型, 称为NoneType. 这个类型只有一个对象, 叫做None
print(type(None)) #- NoneType类似于C语言中的void
- None类似于C语言的空指针NULL(NULL的含义:特指0号地址的内存)
- None这个对象没啥有用的属性, 它的布尔值为False
def func():
print("haha")
ret = func() #打印haha 函数没有返回值却接收了,就是None
print(ret) #打印None,
内建类型的布尔值
所有的标准对象, 均可以用于布尔测试(放到if条件中).
下列对象的布尔值是False
- None
- False
- 所有值为0的数字(0, 0.0, 0.0 + 0.0j (复数))
- “” (空字符串)
- [] (空列表)
- () (空元组)
- {} (空字典)
if "":
print("True")
else:
print("False")
#打印:False
其他情况下, 这些内建对象的布尔值就是True.
关于对象的比较
对象:包含 值 身份 类型
对象值的比较
- 所有内建类型对象都可以进行比较操作来进行值比较.(比较的双方必须是相同类型).
- 比较运算的结果是True或者False.
- 比较运算符包括 ==, !=, <, >, <=, >=
对象身份的比较
回忆我们之前讲过的, 变量名只是对象的一个引用. 那么两个变量名是否指向同一个对象呢?
可以使用 id 这个内建函数来比较. 如果id的值相同, 说明是指向同一个对象.
a = 100
b = a
print(id(a) == id(b)) #True
- Python还提供了 is 关键字, 直接进行判定是否指向相同的对象 本质也是比较id
a = 100
b = a
print(a is b) #True
- 还提供了 is not 可以直接判定两个变量名是否指向不同的对象.
a = 100
b = a
print(a is not b) #False
对象类型的比较
定义的时候可以写明类型,但是没用
a :int = 10
a :int = "he" #不报错,因为int不起效果
- 两个对象比较类型是否相同, 可以使用内建函数type
a = 10
print(type(a) == type(100)) #True
- Python还提供了一个内建函数 isinstance
a = 100
print(isinstance(a,type(10))) #True
a = []
print(isinstance(a,list)) #True
类型工厂函数
我们前面介绍了 int() 这个内建函数, 可以将一个字符串转换成一个整数. 其实是调用 int() 之后生成了一个
整数类型的对象. 我们称这种函数为 “工厂函数” , 就像工厂生产货物一样.
类似的工厂函数还有很多:
- int(), float(), complex() str(), unicode() list(), tuple() dict() bool()
python不支持的类型
- char, byte: 可以使用长度为1的字符串, 或者整数代替;
- 指针: Python替你管理内存, 虽然id()返回的值接近于指针的地址, 但是并不能主动去修改;
- int/short/long: 以前版本的Python中也是区分int和long的, 但是后来统一在一起了; 记住Python中的整数表示的范围, 只取决于你机器内存的大小.
- float/double: Python的float其实就是C语言的double. Python设计者认为没必要支持两种浮点数.
数字和运算
整数的位运算

常用内置函数/模块
- abs: 求一个数的绝对值.
a = -10
print(abs(a)) #10
- divmod: 返回一个元组, 同时计算商和余数
a,b = divmod(10,3) #返回的第一个数:10/3 返回的第二个数:10%3
print(a,b) # 3 1
- str: 将数字转换成字符串.
a = 100
print(str(a)) #100
print(type(a)) #并不会实际改变a的类型 - round: 对浮点数进行四舍五入. round有两个参数, 第一个是要进行运算的值, 第二个是保留小数点后多少位.
- 需要导入math模块
import math
for i in range(0,5):
print(round(math.pi,i)) #pi相当于Π 3.1415926
#执行结果
3.0
3.1
3.14
3.142
3.1416
- 整数进制转换: oct(), hex(), 参数是一个整数, 返回值是对应字面值的字符串.
print(oct(10)) #8进制 0o12
print(hex(10)) #16进制 0xa
-
math/cmath模块: 提供一些方便的数学运算的函数. math是常规数学运算; cmath是复数运算;
-
随机数random模块: 使用方法比较简单
- 需要导入random模块
默认返回的是0-1范围的数
关于除法运算的坑:
相除的得到的是浮点数,
x = 3
count = x/3
print(count) #1.0
print(type(count)) #如果想要得到整数,需要类型转化!
count = (int)(x/3)
#或者:
count = x/3
count = (int)(count)
条件和循环
缩进和悬挂的else
首先看一段C语言的代码(Java等其他语言也存在类似的问题).
if (x > 0)
if (y > 0)
printf("x and y > 0\n");
else
printf("x <= 0\n");
我们期望 else 对应的代码, 执行 x <= 0 的逻辑.
在C语言中, 如果不使用{ }来标明代码块, else会和最近的if匹配. 就意味着上面的else, 执行的逻辑其实是 y <= 0 .
在Python中, 就需要使用不同级别的缩进, 来标明, 这个else和哪个if是配对的.
# 和 if x > 0 配对
if x > 0:
if y > 0:
print('x and y > 0')
else:
print('x <= 0')
# else和if y > 0 配对
if x > 0:
if y > 0:
print('x and y > 0')
else:
print('x > 0 and y <= 0')
条件表达式
- Python中并没有 ? : 这样的三目运算符, 理由是Python设计者觉得这个玩意太丑 T_T
- 取而代之的是, 一种叫做条件表达式的东西. PS: 私以为, 这玩意更丑~ 但是预防同学们笔试面试被问到, 还是稍微提一下.
x, y, smaller = 3, 4, 0
if x < y:
smaller = x
else:
smaller = y
上面这一段代码, 用条件表达式写作
smaller = x if x < y else y #如果x
和循环搭配的else
- else不光可以和if搭配, 还能和while, for搭配
例子:
# 实现一个函数, 从列表中查找指定元素, 返回下标.
def Find(input_list, x):
#在input_list中查找x,遍历input_list
for i in range(0, len(input_list)):
if input_list[i] == x:
return i
else: #else和for配合
return None
实现一个函数, 打印出一个数的最大因子
bug代码:
# 实现一个函数, 打印出一个数的最大因子
def ShowMaxFactor(x):
count = x / 2
#试除法
while count > 1:
if x % count == 0:
print('largest factor of %d is %d' % (x, count))
break
count -= 1
else:
print(f"{x} is prime") #素数
for i in range(10, 20):
#打印10-19每个数对应的最大因子
ShowMaxFactor(i)

错误原因: 因为没有声明类型, 所以count = x / 2得到的是浮点数!!!
for i in range(0,5):
print(i/5)
#执行结果:
0.0
0.2
0.4
0.6
0.8
解决办法:把count的类型强转: || 计算结果强转为int
#方法1:
count = (int)(x / 2) #强转类型
#方法2:
count = x / 2
count = (int)(count) #强转类型
# 实现一个函数, 打印出一个数的最大因子
def ShowMaxFactor(x):
count = (int)(x / 2) #强转类型
#试除法
while count > 1:
if x % count == 0:
print('largest factor of %d is %d' % (x, count))
break
count -= 1
else:
print(f"{x} is prime") #素数
for i in range(10, 20):
#打印10-19每个数对应的最大因子
ShowMaxFactor(i)
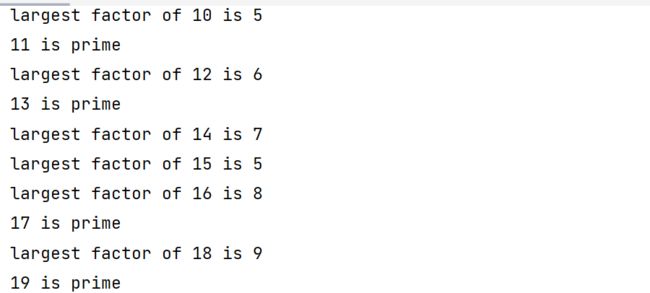
- 注意, 和循环搭配的else子句, 只会在循环条件不满足的时候才会执行(对于for来说就是整个序列遍历完成). 如果循环中途break了, 仍然会跳过else
函数和可调用对象
函数定义和调用
- 使用def关键字定义一个函数.
def Hello():
print("Hello")
- 函数的定义只是创建了一个函数, 并没有执行函数体中的代码. 要在真正进行函数调用时, 才执行函数体中的代码.
#使用()调用函数
Hello();#打印 Hello
- 函数的定义也可以放在其他函数内部~. 但是这样函数的作用域也就只是在函数内部才有效了.
def func1():
def func2(): #函数的作用域也就只是在函数内部才有效了.
print("hello")
func2() #报错 NameError: name 'func2' is not defined
函数的参数
- 函数定义时, 可以在 () 中填入这个函数都需要接受哪些参数. 注意, 此处不需要指定参数类型.
- Python是动态类型语言, 所以在你写下代码的时候, 解释器并不知道参数的类型是什么. 而是在运行时**(调用函数的时候)函数才知道了类型.**
例如
def Hello(x = 0):
print(x)
Hello(10) #10
Hello() #0
Hello("Mango") #Mango
Hello([1,2,3]) #[1, 2, 3]
- 只要传入的参数, 能够支持函数体中的各种操作就可以了. 否则就会运行时报错.
例如
def Add(x,y):
return x+y
print(Add(1,2)) #3
print(Add('he','llo')) #hello
print(Add([1,2],[3,4])) #[1,2,3,4]
#字符串不能和整数相加
print(Add(1,'hello')) #报错 TypeError: unsupported operand type(s) for +: 'int' and 'str
- 定义函数时, 支持给函数指定默认参数. 这样如果调用函数时不显式的指定参数, 就会使用默认参数作为参数值.
- 默认参数是非常有用的, 尤其是一些库的接口, 可能需要传入很多参数, 那么默认参数就可以帮我们减轻使用负担.
- 对于多个默认参数的函数, 可以按照顺序给函数的某几个参数进行传参.
def PrintPoint(x = 0,y = 0,z = 0):
print(x,y,z)
PrintPoint()
PrintPoint(100)
PrintPoint(100,200)
PrintPoint(100,200,300)
#执行结果
0 0 0
100 0 0
100 200 0
100 200 300
如果我们想指定x=100,z=200,而y使用默认值怎么做? ->这里就引出了关键字参数的概念
关键字参数
当我们有多个默认参数, 同时又只想传其中的某几个的时候, 还可以使用关键字参数的方式进行传参.
关于内建函数:sorted
例如内建函数 sorted (用来给序列进行排序), 函数原型为:
sort(list,cmp=None, key=None, reverse=False)
list是给定的列表;
cmp是比较的函数,以方式排序
key是排序过程调用的函数,也就是排序依据
reverse是降序还是升序,默认为False升序,True降序,
函数有四个参数.
第一个参数表示传入一个可迭代的对象(比如列表, 字符串, 字典等);
剩余三个参数都具备默认参数,可以不传.
a = [1, 3, 4, 2]
print (sorted(a)) #并不会改变a
print(a)
# 执行结果
[1, 2, 3, 4]
[1, 3, 4, 2]
注意:sorted生成的是列表
a =(9,5,2,7)
print(sorted(a)) #生成列表
print(a)
#执行结果:
[2, 5, 7, 9]
(9, 5, 2, 7)
对于这几个默认参数, 可以通过现实的指定关键字, 来说明接下来这个参数是传给哪个参数.
sorted可以支持自定制排序规则
例子1: 逆序排序
a = [1, 3, 4, 2]
print sorted(a, reverse=True) #逆序
# 执行结果
[4, 3, 2, 1]
例子2: 按元素的绝对值排序 key = abs
a = [1, -3, 4, 2]
print(sorted(a, key = abs))
# 执行结果
[1, 2, -3, 4]
例子3: 按字符串的长度排序 key = len
a = ['aaaa', 'bbb', 'cc', 'd']
print(sorted(a, key = len))
# 执行结果
['d', 'cc', 'bbb', 'aaaa']
总结一下
和其他编程语言不同, Python的函数形参, 变量名字可不是随便写的. 尤其是这是一个默认参数的时候, 形参名可能会随时被拎出来, 作为关键字参数协助函数调用时传入实参.
为什么C++不支持这样的语法呢? 其实理论上来讲也是完全可以实现的, 我们可以大胆猜测一下实现的思路
回忆C++函数调用过程(函数栈帧, C语言重点内容), 将参数按一定顺序压栈(倒腾ebp, esp), 然后跳转到函数体所在的指令地址, 开始执行; 然后函数体内按照栈和偏移量来取参数.
那么, 只要编译器能够维护形参名字和对应的位置关系, 这样的映射, 保证函数调用时, 能够按照正确的顺序把参数压栈, 就完成了这个过程.
参数组
- 我们还可以将一个元组或者字典, 作为参数组, 来传给函数. 这样就可以帮助我们实现 “可变长参数”
- 通过将参数名前加一个
*号, *** 之后的内容表示是一个元组.**
def log(*msg): #msg是一个元组
for m in msg:
print(m,end = ' ') #以空格分隔打印的内容
log(10,20,30)
#执行结果
10 20 30
思考: 为啥要用 \t 分割呢?
- 使用 \t 分割的行文本, 可以很方便的和linux上的一些文本处理工具搭配使用. 比如cut, sort, awk等.
- 通过在参数名前加两个星号
**, 星号后面的部分表示传入的参数是一个字典. 这时候调用函数就可以按照关键字参数的方式传参了
def log(**msg): #msg变成一个字典
for m in msg:
print(m,msg[m])
log(x= 10,y = 20, z= 30)
#执行结果
x 10
y 20
z 30
函数重载?->不支持
- 如果Python中有两个相同名字的函数, 会出现什么样的效果呢?
后一个函数覆盖前一个函数
def Func():
print('1')
def Func():
print('2')
Func()
# 执行结果
2
- 要记得, 函数也是对象. 代码中定义两个相同名字的函数, 这样的操作类似于
a = 1
a = 2
print(a)
相当于是对Func这个变量重新进行了绑定.
为什么不支持
我们知道, C++和Java中都有函数重载, 然而Python中并没有这个语法. 思考为什么?
- 重载归根结底是为了同一个函数, 能够适应几种不同类型的输入数据.
- 重载的关键词有两个: 不同参数类型; 不同参数数目.
- Python的变量类型是在运行时检查的, 同一个函数, 就已经可以处理不同类型的参数了.
- 通过参数组和默认参数, 解决处理不同数目的参数的能力.
- 通过关键字参数, 也极大的加强了传参的灵活性, 而不比像C++那样只能按顺序传参.
综上, Python完全没有任何必要再去支持 “重载” 这样的语法了. 包括后续出现的一系列动态类型语言, 都不再支持重载
重载:
1.参数类型不同,python是动态类型,天然一个函数就可以传入不同类型
2.参数个数不同,python有默认参数和参数组的语法
所以python不需要支持重载 ,python参数规则功能强于重载
函数的返回值
- 通过return关键字返回一个对象.
- 如果没有return语句, 则返回的是None对象.
- 可以同时返回N个对象, 通过
,分割(本质上是在返回一个元组).
def Hello():
print('hello')
print(Hello()) #如果没有return语句, 则返回的是None对象
# 执行结果
hello
None
函数的内置属性
内建函数dir
函数也是一个对象, 通过内建函数 dir 可以看到一个函数中都有哪些属性.
def Hello():
print("Hello()")
print(dir(Hello))
#执行结果
['__annotations__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
函数也可以作为函数的参数
- 函数也是一个对象, 因此可以作为其他函数的参数
以sorted函数为例, 给一个序列进行排序. 这个函数可以支持自定制比较规则.
函数也可以作为函数的返回值
- 一个函数可以在另外一个函数内部定义. 也可以作为一个返回值返回出去.
- 这里还有一个概念叫做 “闭包”
可调用对象
类似于函数这样的对象, 可以进行调用执行一段代码. 这种对象我们称为可调用对象
关于可调用对象, 只需要实现 _call_ 对应的函数即可
类似于重载operator()