Python正则表达式
提示
为了避免正则表达式中出现太多的反斜杠,建议使用r字符串,r"\n"表示两个字符\和n,前面不加r则表示一个换行符\n。(正则的\要写成\\,而在Python中,也是一样,这就导致在Python写正则时需要写\\\\四个反斜杠)
语法
特殊字符
-
.: 在默认模式下匹配除换行的任意字符,如果指定re.DOTALL模式,则匹配包括换行的任意字符 -
^: 匹配字符串的开头,re.MULTILINE模式匹配每行的开头

-
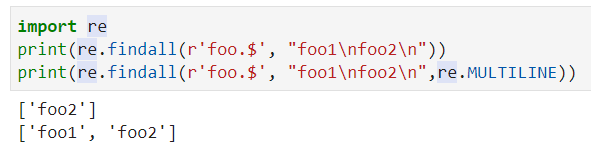
$: 匹配字符串的结尾,re.MULTILINE模式匹配每行的结尾
-
*: 前面的正则式匹配0到任意次,默认贪婪匹配(匹配尽可能多的字符)

-
+: 前面的正则式匹配1到任意次,默认贪婪匹配 -
?: 前面的正则式匹配0到1次, 默认也是贪婪匹配,能匹配到1次绝不匹配0次 -
*?,+?,??: 前面那些的非贪婪匹配,能匹配到0次绝不匹配多次

-
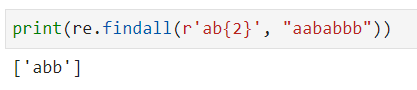
{m}: 前面的正则式匹配 m 个
-
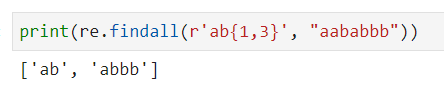
{m,n}: 前面的正则式匹配 m到n个,默认贪婪模式,后面加?变成非贪婪
-
\: 转移字符,允许你匹配正则中的特殊字符*,.等 -
[]: 表示一个字符集合。字符可以单独表示如[ab],也可以是范围如[a-z],[0-9],[A-Z],或者是\表示的字符类如[\w]。特殊字符在[]中无特殊含义,如[(+*)]仅表示匹配这四个字符中的其中一个。另外^表示字符集取反,如[^a]表示匹配除a的任意字符,不过如果^不是放到第一就只是字符^。因为[]内必须包含字符,所以[][]是一个整体的表达式,表示匹配[或]

-
|: A|B表示匹配A或B,如果A已经匹配成功,则不会再对B进行匹配

-
(): 组合,匹配括号内的任意正则表达式,并标识出组合的开始和结尾。之后可以用\1,\2等表示组合的字符

-
(?aiLmsux): ‘a’, ‘i’, ‘L’, ‘m’, ‘s’, ‘u’, 'x’分别表示一种模式,比如a(re.A)只匹配ASCII字符,i(re.I)忽略大小写,L(re.L)不建议使用, m(re.M)也就是之前的re.MULTILINE多行模式, s(re.S),也就是re.DOTALL,u(re.U)Unicode匹配,x(re.X)注释模式,允许用#注释

-
(?:): 非捕获组合,也就是无法使用\1引用了 -
(?aiLmsux-imsx:…): 这我没看懂 -
(?P: 命名组合,未命名的组合是通过从1递增的数字来引用,命名后可以通过名字引用如) (?P=name),当然数字引用依旧可用。如果是传递给re.sub函数中的repl参数则应该写成\g

-
(?P=name): 引用一个命名组合,见上一个 -
(?#…): 注释,里面的内容会被忽略 -
(?=…): 匹配…的内容但是并不会消费它

-
(?!…): 匹配 … 不符合的情况

-
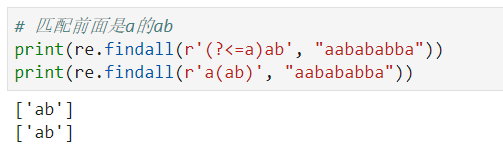
(?<=B)A: 匹配正则A,如果它前面的字符满足B
-
(?: 上面的那个取反的结果 -
(?(id/name)yes-pattern|no-pattern): 如果给定的id或name捕获组存在且匹配到内容,则匹配yes-pattern指定的正则,不然就匹配no-pattern指定的正则

-
\A: 只匹配字符串开始

-
\b: 匹配空字符串,但只在单词开始或结尾的位置

-
\B: \b的取反结果

-
\d: 一般指匹配[0-9] -
\D: \d取反集[^\d] -
\s: 匹配所有空白字符,对于ASCII指的是[ \t\n\r\f\v]6个字符 -
\S: \s取反 -
\w: 匹配构成语句(世界各种语言的都算)的字符,对于ASCII指[a-zA-Z0-9_] -
\W: \w取反 -
\Z: 只匹配字符串尾,和\A类似
python中的转义字符在正则中基本都能解析正常,只有\b在正则中有特殊含义
\a \b \f \n
\N \r \t \u
\U \v \x \\
Python re库
re.compile(pattern, flags=0)
将正则表达式pattern编译成正则表达式对象。说实话,没用过这个函数,都是直接调re的方法
re.search(pattern, string, flags=0)
扫描整个 字符串 找到匹配样式的第一个位置,并返回一个相应的match对象.如果没有匹配,就返回一个 None
re.match(pattern, string, flags=0)
匹配字符串的开头,即使在re.MULTILINE 模式下也只是匹配开头,不会匹配多行
re.fullmatch(pattern, string, flags=0)
如果string整个能匹配pattern正则,则返回match对象
re.split(pattern, string, maxsplit=0, flags=0)
用正则pattern切割字符串string,如果pattern包含捕获组(),则捕获组的内容也会在切割结果里

re.findall(pattern, string, flags=0)
对 string 返回一个不重复的 pattern 的匹配列表, string 从左到右进行扫描,匹配按找到的顺序返回.
如果存在捕获组,则返回捕获组的结果,如果存在多个,则返回多个结果组成的元组
re.finditer(pattern, string, flags=0)
pattern 在 string 里所有的非重复匹配,返回为一个迭代器 iterator 保存了match对象
re.sub(pattern, repl, string, count=0, flags=0)
用repl替换从string中用pattern匹配出的内容,repl可以是字符串也可以是函数。
如果是函数,那参数为pattern匹配到的结果(match对象),返回值为替换后的内容。
如果是字符串,可以使用捕获组的命名和id,写法:\g和\g,虽然也支持\number的形式,但为了避免歧义(比如\20不知道是\2加字符0还是\20),所以建议使用\g<1>而不是\1
re.subn(pattern, repl, string, count=0, flags=0)
同re.sub,但返回一个元组 (字符串, 替换次数)
re.escape(pattern)
转移pattern中的特殊字符,比如’.‘转为’.’
re.purge()
清除正则表达式的缓存
match对象
Match.expand(template)
对 template 进行反斜杠转义替换并且返回。比如替换\1, \g<1>, \g为相应的内容
Match.group([group1, …])
给捕获组的命名或id,返回一个或多个捕获组的内容,返回结果是一个字符串或多个字符串组成的元组。不给参数默认为0
Match.getitem(g)
允许使用[0] [1]的格式获取结果
Match.groups(default=None)
返回一个包含所有子捕获组的元组
Match.groupdict(default=None)
返回一个包含所有命名的捕获组的字典
Match.start([group])和Match.end([group])
返回 group 匹配到的字串的开始和结束标号。m.group(1)就相当于m.string[m.start(1):m.end(1)]
Match.span([group])
返回一个二元组 (m.start(group), m.end(group))。如果没有,返回(-1,-1)
Match.pos和Match.endpos
正则引擎开始和停止在字符串搜索一个匹配的索引位置
Match.lastindex和Match.lastgroup
捕获组的最后一个匹配的整数索引值和最后一个匹配的命名组名字
Match.re
返回产生这个实例的 正则对象
Match.string
传递到 match() 或 search() 的字符串
例子
“abcbdog” 匹配出最接近dog的b,即bdog