linux应用编程和网络编程
注:本文是对朱老师linux应用编程和网络编程课程的备忘引导性笔记,主要是为了能够在学完后快速回忆起相关内容。本文主要记录了一些关键易忘性知识点并包含少量理解性内容,遵循尽量精简的原则,以尽量少的篇幅概括整个课程的知识点,便于后期能够快速定位知识点。故本文不包含具体的命令及函数使用方法等,同时不要太纠结于字面表达,这些只是为了能够快速回忆起相关知识点,具体的准确描述以及用法等需参考具体的文章。
(已完结)
文件IO
man 1 xx查linux shell命令,man 2 xxx查API, man 3 xxx查库函数
linux常用文件IO接口:open、close、write、read、lseek 、dup、dup2、fcntl
常见的标准IO库函数(glibc)有:fopen、fclose、fwrite、fread、ffulsh、fseek
文件描述符:其实质是一个数字,该数字的作用域就是当前进程,open一个文件时,OS在内存中构建了一些数据结构来表示这个动态文件,并返回给应用程序一个数字,这个数字与内存中这个动态文件的数据结构绑定,以后应用程序通过它操作这个动态文件。默认的stdin=0,stdout=1,stderr=2。
errno和perror
errno就是error number。linux系统中对各种常见错误做了个编号,当函数执行错误时,函数会返回一个特定的errno编号来告诉我们这个函数到底哪里错了。errno是由OS来维护的一个全局变量,任何OS内部函数都可以通过设置errno来告诉上层调用者究竟刚才发生了一个什么错误。
函数perror(意思print error),perror函数内部会读取errno并且将这个不好认的数字直接给转成对应的错误信息字符串,然后print打印出来。例:perror("xxx");
静态文件信息表inode(i节点)和动态文件信息表vnode(v节点)
用open函数打开一个不存在的文件时要加上O_CREAT这个flag,并需要加上一个mode值用来指定所创建的文件的权限,该权限由5位数组成,一般前两位固定位0,后3位的值减去umask(见文件属性章节)的值表示所创建文件的权限。
将命令的输出重定位:可以使用“>”将命令的输出重定位到指定文件。比如ls > a.txt。其原理其实就是利用open+close+dup,open打开一个文件a.txt,然后close关闭stdout,然后dup将1和a.txt文件关联起来即可。
文件属性
linux中各种文件类型:普通文件(-),目录文件(d),字符设备文件(c),块设备文件(b),管道文件(p),套接字文件(s),符号链接文件(l)
在linux系统层面是不区分文本文件和二进制文件的,譬如之前学过的open、read、write等方法操作这两个时一点区别都没有
文件属性获取API:stat、fstat、lstat
文件属性获取命令:stat
文件所有者、文件所有者所在的组、其他用户
access函数可以测得当前执行程序的那个用户在当前环境下对目标文件是否具有某种操作权限
chmod命令与API:修改文件权限
chown命令与API:修改文件所有者
umask命令与API:umask的作用是用来设定我们系统中新创建的文件的默认权限的
读取目录文件:opendir与readdir函数。readdir调用一次只能读出一个目录项,要想读出目录中所有的目录项必须多次调用readdir函数
可重入函数和不可重入函数
获取系统信息
jiffies是linux内核中的一个全局变量,这个变量用来记录以内核的节拍时间为单位时间长度的一个数值。内核配置的时候定义了一个节拍时间,实际上linux内核的调度系统工作时就是以这个节拍时间为时间片的。jiffies变量开机时有一个基准值,然后内核每过一个节拍时间jiffies就会加1,然后到了系统的任意一个时间我们当前时间就被jiffies这个变量所标注。
内核在开机启动的时候会读取RTC硬件获取一个时间作为初始基准时间 ,这个基准时间对应一个jiffies值(这个基准时间换算成jiffies值的方法是:用这个时间减去1970-01-01 00:00:00 +0000,然后把这个时间段换算成jiffies数值),这个jiffies值作为我们开机时的基准jiffies值存在。然后系统运行时每个时钟节拍的末尾都会给jiffies这个全局变量加1,因此操作系统就使用jiffies这个全局变量记录了下来当前的时间。当我们需要当前时间点时,就用jiffies这个时间点去计算(计算方法就是先把这个jiffies值对应的时间段算出来,然后加上1970-01-01 00:00:00 +0000即可得到这个时间点)。
操作系统只在开机时读一次RTC,整个系统运行过程中RTC是无作用的。RTC的真正作用其实是在OS的2次开机之间进行时间的保存。
一个时间节拍的时间取决于操作系统的配置,现代linux系统一般是10ms或者1ms。这个时间其实就是调度时间。
常用的时间相关的API和C库函数有:time/ctime/localtime/gmtime/mktime/asctime/strftime/gettimeofday/settimeofday.。
其中gettimeofday可以得到更加精确的事件,微秒级。
rand函数可以返回一个0-RAND_MAX(定义在stdlib.h中)之间的伪随机数
srand函数用来设置rand获取伪随机数的种子
单纯使用rand来得到伪随机数序列有缺陷,每次执行程序得到的伪随机序列是同一个序列,没法得到其他序列。因为rand内部的算法其实是通过一个种子(seed,其实就是一个原始参数,int类型),rand内部默认是使用1作为seed的,种子一定的算法也是一定的,那么每次得到的伪随机序列肯定是同一个。
一般常规做法是用time函数的返回值来做srand的参数
proc文件系统:专门用于调试内核。在内核中构建一个虚拟文件系统/proc,内核运行时将内核中一些关键的数据结构以文件的方式呈现在/proc目录中的一些特定文件中,这样相当于将不可见的内核中的数据结构以可视化的方式呈现给内核的开发者。proc目录下的文件大小都是0,因为这些文件本身并不存在于硬盘中,他也不是一个真实文件,他只是一个接口,当我们去读取这个文件时,其实内核并不是去硬盘上找这个文件,而是映射为内核内部一个数据结构被读取并且格式化成字符串返回给我们。
常用proc中的文件
(1)/proc/cmdline
(2)/proc/cpuinfo
(3)/proc/devices 系统中所有的设备
(4)/proc/interrupts 系统中用到的所有中断
sys文件系统:sys文件系统本质上和proc文件系统是一样的,都是虚拟文件系统,都在根目录下有个目录(一个是/proc目录,另一个是/sys目录),因此都不是硬盘中的文件,都是内核中的数据结构的可视化接口。不同的是/proc中的文件只能读,但是/sys中的文件可以读写。读/sys中的文件就是获取内核中数据结构的值,而写入/sys中的文件就是设置内核中的数据结构的元素的值。
proc文件系统比较乱,sys文件系统比较整洁
进程
可以使用ps
(1)ps -ajx 偏向显示各种有关的ID号
(2)ps -aux 偏向显示进程各种占用资源(3)后面可加入 | less,如ps -aux | less
或top
命令查看系统中的进程
向进程发送信号指令kill
(1)kill -信号编号 进程ID,向一个进程发送一个信号
(2)kill -9 xxx,将向xxx这个进程发送9号信号,也就是要结束进程
程序的开始:
(1)操作系统下的应用程序需要在main函数执行前先执行一段引导代码,这段代码由链接器将编译器中事先准备好的代码给链接进去并和我们的应用程序一起构成最终的可执行程序。
(2)加载器是操作系统中的程序,当我们去执行一个程序时(譬如./a.out,譬如代码中用exec族函数来运行)加载器负责将这个程序加载到内存中去执行这个程序。
(3)argc和argv的传参是先传给加载器再由加载器传给应用程序。
程序的结束:
(1)正常终止:return、exit、_exit
(2)非正常终止:自己或他人发信号终止进程
atexit注册进程终止处理函数
(2)atexit注册多个进程终止处理函数,先注册的后执行(先进后出,和栈一样)
(2)return、exit和_exit的区别:return和exit效果一样,都是会执行进程终止处理函数,但是用_exit终止进程时并不执行atexit注册的进程终止处理函数。
进程环境:
(1)环境变量
export命令用来查看和修改环境变量
每一个进程中都有一份所有环境变量构成的一个表格,也就是说我们当前进程中可以直接使用这些环境变量。进程环境表其实是一个字符串数组,用environ变量指向它。(使用时只需要 extern char **environ; 声明即可)
获取指定环境变量函数getenv
(2)虚拟地址空间
操作系统中每个进程在独立地址空间中运行
每个进程的逻辑地址空间均为4GB(32位系统)
0-1G为OS,1-4G为应用
虚拟地址到物理地址空间的映射
意义。进程隔离,提供多进程同时运行
进程控制块PCB(process control block)是内核中专门用来管理一个进程的数据结构。
进程ID
(1)getpid、getppid、getuid、geteuid、getgid、getegid
(2)实际用户ID和有效用户ID区别
fork创建子进程
进程的分裂生长模式。如果操作系统需要一个新进程来运行一个程序,那么操作系统会用一个现有的进程来复制生成一个新进程。老进程叫父进程,复制生成的新进程叫子进程。
fork函数调用一次会返回2次,返回值等于0的就是子进程,而返回值大于0(子进程的进程ID)的就是父进程。vfork和fork的区别
父进程在没有fork之前做的事情对子进程有很大影响。本质原因是因为fork内部实际上已经复制父进程的PCB生成了一个新的子进程,并且fork返回时子进程已经完全和父进程脱离并且独立被OS调度执行。例如子进程继承父进程中打开的文件
进程的诞生
(1)Linux下有3个特殊的进程,idle进程(PID = 0), init进程(PID = 1)和kthreadd(PID = 2)
(2)idle进程由系统自动创建, 运行在内核态
(3)init进程由idle创建,在内核空间完成初始化后,在用户空间中启动init进程,是系统中所有其它用户进程的祖先进程,在系统启动完成完成后,init将变为守护进程监视系统其他进程
(4)kthreadd进程由idle通过kernel_thread创建,并始终运行在内核空间, 负责所有内核线程的调度和管理。它的任务就是管理和调度其他内核线程, 它会循环执行一个kthread的函数,该函数的作用就是运行kthread_create_list全局链表中维护的kthread, 当我们调用kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程
进程的消亡
(1)正常终止(return、exit、_exit)和异常终止(被信号终止)
(2)进程在运行时需要消耗系统资源(内存、IO),进程终止时理应完全释放这些资源(如果进程消亡后仍然没有释放相应资源则这些资源就丢失了)
(3)linux系统设计时规定:每一个进程退出时,操作系统会自动回收这个进程涉及到的所有的资源(譬如malloc申请的内容没有free时,当前进程结束时这个内存会被释放,譬如open打开的文件没有close的在程序终止时也会被关闭)。但是操作系统只是回收了这个进程工作时消耗的内存和IO,而并没有回收这个进程本身占用的内存(8KB,主要是task_struct和栈内存)
(4)因为进程本身的8KB内存操作系统不能回收需要别人来辅助回收,因此我们每个进程都需要一个帮助它收尸的人,这个人就是这个进程的父进程。
僵尸进程
(1)子进程先于父进程结束。子进程结束后父进程此时并不一定立即就能帮子进程“收尸”,在这一段(子进程已经结束且父进程尚未帮其收尸)子进程就被成为僵尸进程。
(2)子进程除task_struct和栈外其余内存空间皆已清理
(3)父进程可以使用wait或waitpid以显式回收子进程的剩余待回收内存资源并且获取子进程退出状态。
(4)父进程也可以不使用wait或者waitpid回收子进程,此时父进程结束时一样会回收子进程的剩余待回收内存资源。(这样设计是为了防止父进程忘记显式调用wait/waitpid来回收子进程从而造成内存泄漏)
孤儿进程
(1)父进程先于子进程结束,子进程成为一个孤儿进程。
(2)linux系统规定:所有的孤儿进程都自动成为一个特殊进程(进程1,也就是init进程)的子进程。
父进程wait回收子进程
(1)子进程结束时,系统向其父进程发送SIGCHILD信号
(2)父进程调用wait函数后阻塞
(3)父进程被SIGCHILD信号唤醒然后去回收僵尸子进程
(4)父子进程之间是异步的,SIGCHILD信号机制就是为了解决父子进程之间的异步通信问题,让父进程可以及时的去回收僵尸子进程。
(5)若父进程没有任何子进程则wait返回错误(6)wait的返回值可以用来判断是哪一个子进程被收回了
(7)输出型参数wstatus搭配WIFEXITED、WIFSIGNALED、WEXITSTATUS这几个宏用来获取子进程的退出状态。
WIFEXITED宏用来判断子进程是否正常终止
WIFSIGNALED宏用来判断子进程是否非正常终止
WEXITSTATUS宏用来得到正常终止情况下的进程返回值的。
waitpid可以回收指定PID的子进程,可以阻塞式或非阻塞式两种工作模式
exec族函数把一个编译好的可执行程序直接加载运行
(1)execl、execv
(2)execlp和execvp
会多帮我们到PATH所指定的路径下去找一下
(3)execle和execvpe
main函数的原型其实不止是int main(int argc, char **argv),而可以是int main(int argc, char **argv, char **env) 第三个参数是一个字符串数组,内容是环境变量。如果用户在执行这个程序时没有传递第三个参数,则程序会自动从父进程继承一份环境变量(默认的,最早来源于OS中的环境变量);如果我们exec的时候使用execlp或者execvpe去给传一个envp数组,则程序中的实际环境变量是我们传递的这一份(取代了默认的从父进程继承来的那一份)
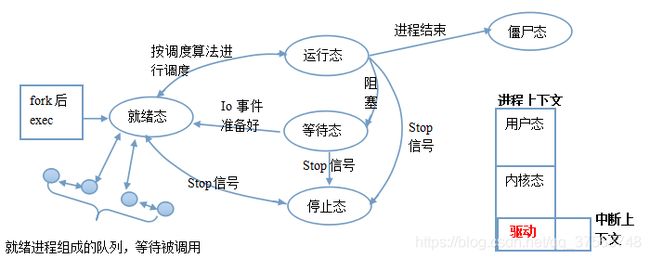
进程的5种状态
(1)就绪态。这个进程当前所有运行条件就绪,只要得到了CPU时间就能直接运行。
(2)运行态。就绪态时得到了CPU就进入运行态开始运行。
(3)僵尸态。进程已经结束但是父进程还没来得及回收
(4)等待态(浅度睡眠&深度睡眠),进程在等待某种条件,条件成熟后可进入就绪态。等待态下就算你给他CPU调度进程也无法执行。浅度睡眠等待时进程可以被(信号)唤醒,而深度睡眠等待时不能被唤醒只能等待的条件到了才能结束睡眠状态。
(5)暂停态。暂停并不是进程的终止,只是被人(信号)暂停了,还可以恢复的。
system函数 = fork+exec。是一个原子操作。
例,system("pwd");
进程组:多个进程的集合,其中肯定有一个组长,其进程PID等于进程组的PGID
会话:一个或多个进程组的集合
守护进程
系统日志函数 openlog、syslog、closelog
linux进程间通信机制
(1)无名管道和有名管道
(2)SystemV IPC:信号量、消息队列、共享内存
(3)Socket域套接字
(4)信号
信号
信号是内容受限的一种异步通信机制
(1)信号的目的:用来通信
(2)信号是异步的(对比硬件中断)
(3)信号本质上是int型数字编号(事先定义好的)
信号由谁发出
(1)用户在终端按下按键
(2)硬件异常后由操作系统内核发出信号
(3)用户使用kill命令向其他进程发出信号
(4)某种软件条件满足后也会发出信号,如alarm闹钟时间到会产生SIGALARM信号,向一个读端已经关闭的管道write时会产生SIGPIPE信号
信号由谁处理、如何处理
(1)忽略信号
(2)捕获信号(信号绑定了一个函数)
(3)默认处理(当前进程没有明显的管这个信号,默认:忽略或终止进程)
常见信号介绍
(1)SIGINT 2 Ctrl+C时OS送给前台进程组中每个进程
(2)SIGABRT 6 调用abort函数,进程异常终止
(3)SIGPOLL SIGIO 8 指示一个异步IO事件,在高级IO中提及
(4)SIGKILL 9 杀死进程的终极办法
(5)SIGSEGV 11 无效存储访问时OS发出该信号
(6)SIGPIPE 13 涉及管道和socket
(7)SIGALARM 14 涉及alarm函数的实现
(8)SIGTERM 15 kill命令发送的OS默认终止信号
(9)SIGCHLD 17 子进程终止或停止时OS向其父进程发此信号
(10)
SIGUSR1 10 用户自定义信号,作用和意义由应用自己定义
SIGUSR2 12
signal函数
返回值:返回先前的信号处理函数指针,如果有错误则返回SIG_ERR(-1)
参数: 第一个参数signum:指明了所要处理的信号类型,它可以取除了SIGKILL和SIGSTOP外的任何一种信号。
第二个参数handler:描述了与信号关联的动作,它可以取以下三种值:SIG_IGN、SIG_DFL 、函数指针。
sigaction函数,sigaction比signal好的一点:sigaction可以一次得到设置新捕获函数和获取旧的捕获函数(其实还可以单独设置新的捕获或者单独只获取旧的捕获函数),而signal函数不能单独获取旧的捕获函数而必须在设置新的捕获函数的同时才获取旧的捕获函数
alarm函数,内核以API形式提供的闹钟
pause函数,让当前进程暂停运行,交出CPU给其他进程去执行。当当前进程进入pause状态后当前进程会表现为“卡住、阻塞住”,要退出pause状态当前进程需要被信号唤醒
高级IO
阻塞与非阻塞IO
常见的阻塞函数有wait、pause、sleep等;在read或write某些文件时也会发生阻塞。
实现非阻塞IO访问:O_NONBLOCK和fcntl
并发式IO的解决方案
(1)非阻塞式IO
(2)多路复用IO
(3)异步通知(异步IO)
同步和异步的概念描述的是用户线程与内核的交互方式:同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作完成后才能继续执行;而异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
多路复用IO
select() 和 poll() 系统调用的本质一样,管理多个描述符也是进行轮询,即外部阻塞式,内部非阻塞式自动轮询多路阻塞式IO。根据描述符的状态进行处理,但是 poll() 没有最大文件描述符数量的限制(但是数量过大后性能也是会下降)。
查看例程
异步IO
异步IO可以看成操作系统用软件实现的一套中断响应系统,工作方法是:我们当前进程注册一个异步IO事件(使用signal注册一个信号SIGIO的处理函数),然后当前进程可以正常处理自己的事情,当异步事件发生后当前进程会收到一个SIGIO信号从而执行绑定的处理函数去处理这个异步事件。
查看例程
存储映射IO
mmap函数
LCD显示和IPC之共享内存
存储映射IO的特点
(1)共享而不是复制,减少内存操作
(2)处理大文件时效率高,小文件不划算
线程
进程技术的劣势
(1)进程间切换开销大
(2)进程间通信麻烦而且效率低
linux中的线程简介
(1)一种轻量级进程
(2)线程是参与内核调度的最小单元
(3)一个进程中可以有多个线程
线程技术的优势
(1)像进程一样可被OS调度实现多任务的特性
(2)同一进程的多个线程之间很容易高效率通信
(3)在多核心CPU(对称多处理器架构SMP)架构下效率最大化
线程创建与回收
(1)pthread_create 主线程用来创造子线程的
(2)pthread_join 主线程用来等待(阻塞)回收子线程
(3)pthread_detach 主线程用来分离子线程,分离后主线程不必再去回收子线程
线程取消
(1)pthread_cancel 一般都是主线程调用该函数去取消(让它赶紧死)子线程
(2)pthread_setcancelstate 子线程设置自己是否允许被取消
(3)pthread_setcanceltype
线程函数退出相关
(1)pthread_exit与return退出
(2)pthread_cleanup_push
(3)pthread_cleanup_pop
获取线程id
(1)pthread_self
pthread库不是Linux系统默认的库,连接时需要使用库libpthread.a,所以在使用pthread_create创建线程时,在编译中要加-lpthread参数:gcc createThread.c -lpthread -o createThread
线程同步之信号量
sem_init 初始化一个信号量
sem_destroy 销毁一个信号量
sem_wait 等待一个信号量
sem_post 释放一个信号量
线程同步之互斥锁
互斥锁又叫互斥量(mutex),可以认为互斥锁是一种特殊的信号量,互斥锁主要用来实现关键段保护 。
pthread_mutex_init 初始化一个互斥锁
pthread_mutex_destroy 销毁一个互斥锁
pthread_mutex_lock 上锁
pthread_mutex_unlock 解锁
注意:man 3 pthread_mutex_init时提示找不到函数,说明你没有安装pthread相关的man手册。安装方法:1、虚拟机上网;2、sudo apt-get install manpages-posix-dev
线程同步之条件变量
包括两个动作:一个线程等待”条件变量的条件成立”而挂起;另一个线程使”条件成立”(给出条件成立信号)。使用条件变量可以以原子方式阻塞线程,直到某个特定条件为真为止。条件变量始终与互斥锁一起使用,对条件的测试是在互斥锁(互斥)的保护下进行的。
pthread_cond_init 初始化条件变量
pthread_cond_destroy 销毁条件变量
pthread_cond_wait 等待条件变量
pthread_cond_signal 唤醒一个等待该条件的线程,存在多个等待线程时按入队顺序唤醒其中一个
pthread_cond_broadcast 唤醒所有等待线程
信号量、互斥锁、条件变量------例程
网络基础
网络通信其实就是位于网络中不同主机上面的2个进程之间的通信
网络通信的层次
(1)硬件部分:网卡
(2)操作系统底层:网卡驱动
(3)操作系统API:socket接口
(4)应用层:低级(直接基于socket接口编程)
(5)应用层:高级(基于网络通信应用框架库)
(6)应用层:更高级(http、网络控件等)
三大网络
电信网、电视网络、互联网
网络通信的传输媒介
(1)无线传输:WIFI、蓝牙、zigbee、4G/5G/GPRS等
(2)有线通信:双绞线、同轴电缆、光纤等
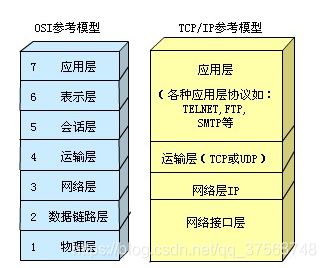
OSI 7层网络模型
网卡
(1)计算机上网必备硬件设备,CPU靠网卡来连接外部网络
(2)串转并设备
(3)数据帧封包和拆包
(4)网络数据缓存和速率适配
集线器(HUB)
(1)信号中继放大,相当于中继器
(2)组成局域网络,用广播方式工作。
(3)注意集线器是不能用来连接外网的
交换机
(1)包含集线器功能,但更高级
(2)交换机中有地址表,数据包查表后直达目的通信口而不是广播
(3)找不到目的口时广播并学习
路由器
(1)路由器是局域网和外部网络通信的出入口
(2)路由器将整个internet划分成一个个的局域网,却又互相联通。
(3)路由器对内管理子网(局域网),可以在路由器中设置子网的网段,设置有线端口的IP地址,设置dhcp功能等,因此局域网的IP地址是路由器决定的。
(4)路由器对外实现联网,联网方式取决于外部网络(如ADSL拨号上网、宽带帐号、局域网等)。这时候路由器又相当于是更高层级网络的其中一个节点而已。
(5)所以路由器相当于有2个网卡,一个对内做网关、一个对外做节点。
(6)路由器的主要功能是为经过路由器的每个数据包寻找一条最佳路径(路由)并转发出去。其实就是局域网内电脑要发到外网的数据包,和外网回复给局域网内电脑的数据包。
(7)路由器技术是网络中最重要技术,决定了网络的稳定性和速度。
DNS(Domain Name Service 域名服务)
(1)网络世界的门牌号:IP地址
(2)IP地址的缺点:难记、不直观
(3)IP地址的替代品:域名,譬如www.zhulaoshi.org
(4)DNS服务器就是专门提供域名和IP地址之间的转换的服务的,因此域名要购买的
(5)我们访问一个网站的流程是:先使用IP地址(譬如谷歌的DNS服务器IP地址为8.8.8.8)访问DNS服务器(DNS服务器不能是域名,只能是直接的IP地址),查询我们要访问的域名的IP地址,然后再使用该IP地址访问我们真正要访问的网站。这个过程被浏览器封装屏蔽,其中使用的就是DNS协议。
(6)浏览器需要DNS服务,而QQ这样的客户端却不需要(因为QQ软件编程时已经知道了腾讯的服务器的IP地址,因此可以直接IP方式访问服务器)
DHCP(dynamic host configuration protocl,动态主机配置协议)
(1)每台计算机都需要一个IP地址,且局域网内各电脑IP地址不能重复,否则会地址冲突。
(2)计算机的IP地址可以静态设定,也可以动态分配
(3)动态分配是局域网内的DHCP服务器来协调的,很多设备都能提供DHCP功能,譬如路由器。
(4)动态分配的优势:方便接入和断开、有限的IP地址得到充分利用
NAT(network address translation,网络地址转换协议)
(1)IP地址分为公网IP(internet范围内唯一的IP地址)和私网IP(内网IP),局域网内的电脑使用的都是私网IP(常用的就是192.168.1.xx)
(2)网络通信的数据包中包含有目的地址的IP地址
(3)当局域网中的主机要发送数据包给外网时,路由器要负责将数据包头中的局域网主机的内网IP替换为当前局域网的对外外网IP。这个过程就叫NAT。
(4)NAT的作用是缓解IPv4的IP地址不够用问题,但只是类似于打补丁的形式,最终的解决方案还是要靠IPv6。
(5)NAT穿透简介
IP地址分类(IPv4)
(1)IP地址实际是一个32位二进制构成,在网络通信数据包中就是32位二进制,而在人机交互中使用点分十进制方式显示。
(2)IP地址中32位实际包含2部分,分别为:网络地址和主机地址。子网掩码,用来说明网络地址和主机地址各自占多少位。
(3)由网络地址和主机地址分别占多少位的不同,将IP地址分为5类,最常用的有3类
三类IP地址
(1)A类。
(2)B类
(3)C类
(4)127.0.0.0用来做回环测试loopback
linux网络编程实践
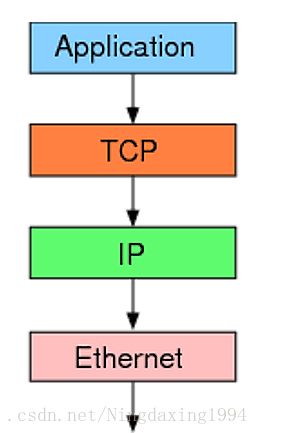
TCP/IP协议引入
(1)TCP/IP协议是用的最多的网络协议实现
(2)TCP/IP分为4层,对应OSI的7层
(3)我们编程时最关注应用层,了解传输层,网际互联层和网络接入层不用管
BS和CS
(1)CS架构介绍(client server,客户端服务器架构)
(2)BS架构介绍(broswer server,浏览器服务器架构)
关于TCP理解的重点
(1)TCP协议工作在传输层,对上服务socket接口,对下调用IP层
(2)TCP协议面向连接,通信前必须先3次握手建立连接关系后才能开始通信。
(3)TCP协议提供可靠传输,不怕丢包、乱序等。
TCP如何保证可靠传输
(1)TCP在传输有效信息前要求通信双方必须先握手,建立连接才能通信
(2)TCP的接收方收到数据包后会ack给发送方,若发送方未收到ack会丢包重传
(3)TCP的有效数据内容会附带校验,以防止内容在传递过程中损坏
(4)TCP会根据网络带宽来自动调节适配速率(滑动窗口技术)
(5)发送方会给各分割报文编号,接收方会校验编号,一旦顺序错误即会重传。
TCP的三次握手
(1)建立连接需要三次握手
(2)建立连接的条件:服务器listen时客户端主动发起connect
TCP的四次握手
(1)关闭连接需要四次握手
(2)服务器或者客户端都可以主动发起关闭
注:这些握手协议已经封装在TCP协议内部,socket编程接口平时不用管
基于TCP通信的服务模式
(1)具有公网IP地址的服务器(或者使用动态IP地址映射技术)
(2)服务器端socket、bind、listen后处于监听状态,accept等待客户端接入
(3)客户端socket后,直接connect去发起连接。
(4)服务器收到并同意客户端接入后会建立TCP连接,然后双方开始收发数据,收发时是双向的,而且双方均可发起
(5)双方均可发起关闭连接
socket编程接口介绍
(1)建立连接
- socket。socket函数类似于open,用来打开一个网络连接,如果成功则返回一个网络文件描述符(int类型),之后我们操作这个网络连接都通过这个网络文件描述符。
- bind。用于将网络文件描述符与特定的IP地址进行绑定。
- listen。监听网络。
- connect。建立网络连接。
(2)发送和接收
- send和write
- recv和read
(3)IP地址转换
- 老的接口,不支持IPV6:inet_aton、inet_addr、inet_ntoa
- 新的接口,支持IPV6:inet_ntop、inet_pton
IP地址相关数据结构
(1)定义在netinet/in.h中,在/usr/include/netinet/in.h里进行查看
(2)typedef uint32_t in_addr_t; 网络内部用来表示IP地址的类型
(3)struct in_addr
{
in_addr_t s_addr;
};(4)struct in6_addr
{
union
{
uint8_t __u6_addr8[16];
uint16_t __u6_addr16[8];
uint32_t __u6_addr32[4];
};(5)struct sockaddr_in
{
__SOCKADDR_COMMON (sin_);
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. *//* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr) -
__SOCKADDR_COMMON_SIZE -
sizeof (in_port_t) -
sizeof (struct in_addr)];
};(6)struct sockaddr_in6
{
__SOCKADDR_COMMON (sin6_);
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};(7)struct sockaddr。这个结构体是linux的网络编程接口中用来表示IP地址的标准结构体,bind、connect等函数中都需要这个结构体,这个结构体是兼容IPV4和IPV6的。在实际编程中这个结构体会被一个struct sockaddr_in或者一个struct sockaddr_in6所填充。
端口号,实质就是一个数字编号,用来在我们一台主机中(主机的操作系统中)唯一的标识一个能上网的进程。端口号和IP地址一起会被打包到当前进程发出或者接收到的每一个数据包中。每一个数据包将来在网络上传递的时候,内部都包含了发送方和接收方的信息(就是IP地址和端口号),所以IP地址和端口号这两个往往是打包在一起不分家的。
服务器端进行通信时使用accept返回的描述符进行收发,客户端使用socket返回的描述符进行数据收发。
例程
常用应用层协议:http、ftp······