有趣的Python —— 图片爬取(从分析到实现)
文章目录
- 1.分析网页
-
- 1.1 分析url
- 1.2 分析Html 结构,找出图片链接
- 2.获取网页数据
- 3.使用BeautifulSoup4 获取图片链接
- 4. 进行图片下载并保存
- 5. 最后组装起来
- 总结
首先来个思维导图。对这篇记录有个大概认识。篇幅主要是记录实现步骤,涉及的知识点在实现步骤中会体现,但不会展开细说。

1.分析网页
1.1 分析url
要爬取的地址,斗图为例:
第一页:https://www.doutula.com/photo/list?page=1
第二页:https://www.doutula.com/photo/list/?page=2
…
那么,第N页的url 地址就是 https://www.doutula.com/photo/list/?page= N
为什么 要分析url ,因为爬取数据时候,不单单就爬取一页的。设计出来的代码,应该可以随意爬取多少页的数据的。或者自动爬取所有数据的。而通过分析爬取url 的变化规律,就可以轻松迭代所有的页面了。
1.2 分析Html 结构,找出图片链接
这里就需要我们查找页面的源代码,进行分析了,找出需要的信息标签。
A . 首先最好使用 Chrome浏览器 打开斗图网站,对应的页面。
B . 然后我们按 F12,就会出现下面的界面:

C . 在源代码中,先找到 body 标签
body 标签里面就是网页展示的源代码

D. 在每个标签上,移动鼠标,你发现有趣的事情,你鼠标停留在某个标签上,左边的页面就会展示成蓝色。

E. 点击打开标签,一步步找到图片所在的标签

F. 最后我们看看每一张图片的标签代码是长什么样的
第一个图片标签
<a class="col-xs-6 col-sm-3" href="https://www.doutula.com/photo/5489966" style="padding:5px;">
<img
referrerpolicy="no-referrer"
src="//www.doutula.com/img/loader.gif"
style="width: 100%; height: 100%;"
data-original="http://ww3.sinaimg.cn/bmiddle/9150e4e5gy1g5aju5m3x8j206o06lwf1.jpg"
alt="小妹妹我的枪还不错吧"
class="img-responsive lazy image_dta"
data-backup="http://img.doutula.com/production/uploads/image/2019/07/24/20190724948680_ObVYKx.png">
<p style="display: none">小妹妹我的枪还不错吧p>
a>
第二个图片标签
<a class="col-xs-6 col-sm-3" href="https://www.doutula.com/photo/7620638" style="padding:5px;">
<img
referrerpolicy="no-referrer"
src="//www.doutula.com/img/loader.gif"
style="width: 100%; height: 100%;"
data-original="http://ww2.sinaimg.cn/bmiddle/9150e4e5gy1g5aju9zi9yj205g05i745.jpg"
alt="哼,气死人家啦"
class="img-responsive lazy image_dta"
data-backup="http://img.doutula.com/production/uploads/image/2019/07/24/20190724948679_ynvITc.jpg">
<p style="display: none">哼,气死人家啦p>
a>
这是两个 a 标签, 标签里面包含了
img 标签里面就是我们需要找的信息,有三个重要信息:
1、图片链接地址是:
data-original=“http://ww3.sinaimg.cn/bmiddle/9150e4e5gy1g5aju5m3x8j206o06lwf1.jpg”
2、图片的名字是:
alt=“小妹妹我的枪还不错吧”
3、图片标签 class=“img-responsive lazy image_dta” , 这个信息非常重要,这个可以帮助我们找出所有的图片标签,因为在斗图里面,我们需要爬取的图片标签都有这个标识。
PS:同样的步骤可以分析出其他网友的 Html 的结构,找到你需要的信息,进行爬取分析。
如果对Html 不了解或者想更深入了解的,可以自行查找Html 相关的知识,进行学习。
2.获取网页数据
上面都是分析部分,下面就要开始写代码了。
我们上面的分析都是通过网页的源代码进行的,这一步就是要获取页面的源代码数据了。
这一步比较简单,我们使用最原始的办法 urllib 库, 这个方法非常简单, 返回的是网页的 html 数据。
这里的header 头伪装,这个比较重要,因为你如果不设置header 头,服务器会拒绝你的访问,返回 403报错
import urllib
import urllib.request
def get_web_html(url):
"""
获取需要爬取的html文件,做一定的浏览器伪装
:param url:地址
:return: HTML结果
"""
headers = {
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Mobile Safari/537.36"
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
return response.read()
PS. 对于动态数据的网页, 这个方法是拿不到动态数据的, 可以使用 selenium 或者其他库 进行模拟用户行为,打开网页获取网页数据
3.使用BeautifulSoup4 获取图片链接
下载完网页数据之后,就开始拿具体图片数据了。
BeautifulSoup4 是非常好用的分析库,可以快速的找到网页里面,我们需要的信息。
因为是第三方库,这个需要手动安装一下:
pip install beautifulsoup4
下面的代码就是根据我们第一步的分析,来获取相关的图片信息了:
from bs4 import BeautifulSoup
def get_pic_dic(html):
"""
分析 Html 数据,获取到图片链接数据
:param html: html源码
:return: 字典形式返回图片链接数据 key : 图片名字 value: 下载链接
"""
soup = BeautifulSoup(html, features="lxml")
matching = soup.body.find_all("img","img-responsive lazy image_dta")
pic_dic = {}
for pic_dot in matching:
pic_dic.update({pic_dot["alt"]:pic_dot["data-original"]})
return pic_dic
具体步骤分析:
1、soup = BeautifulSoup(html, features=“lxml”)
是获取解析html的对象
2、matching = soup.body.find_all(“img”,“img-responsive lazy image_dta”)
这个就是我们第一步分析图片标签 class = “img-responsive lazy image_dta” 的作用,
这里会在 body 里面找到 class = “img-responsive lazy image_dta” 的所有的img标签,以 列表的形式返回所有符合的标签。
3、最后一个for 循环,就是把数据 塞到 一个字典里面了。
第一步的分析,这里就起作用了,字典 key 是 img 标签里面的 “alt” 属性, 字典的value 就是 img 标签的 “data-original”
这里其实就是把第一步分析 img 标签的事情, 代码化了, 把数据提取出来
4. 进行图片下载并保存
经过前面三步,分析,下载网页,解析网页,已经得到一堆 图片链接了,下面就是把它下载到本地了。
先看看下载文件的代码,也是一个函数,也非常简单,这个是单个文件下载和写入的函数:
# 步骤1
def download_file(url, file_name, extension, path_name = "download_file"):
"""
下载文件(浏览器伪装)
:param url:下载地址
:param file_name: 文件名称
:param extension: 后缀名称
:param path_name: 保存目录
:return: 保存目录地址
"""
# 步骤2
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Mobile Safari/537.36"
}
request = urllib.request.Request(url = url, headers= headers)
response = urllib.request.urlopen(request)
data = response.read()
# 步骤3
if path_name and not os.path.exists(path_name):
os.mkdir(path_name)
elif not path_name:
path_name = "download_file"
if not os.path.exists(path_name):
os.mkdir(path_name)
# 步骤4
data_path = (path_name+'\%s' + extension) % file_name
# 步骤5
with open(data_path, 'wb') as file:
file.write(data)
具体步骤分析:
1、 这个函数,传入几个参数:url (下载地址),file_name (下载后的文件名),extension (下载文件的后缀名), path_name (保存的目录地址)
2、和网页下载数据下载一样,通过 urllib 库,获取图片数据,这个可以和下载网页复用
3、判断需要保存的地址是否已经存在,如果不存在,就进行文件目录的创建
4、组装最后需要写入的文件地址,如 : /doutu/哈哈哈.png
5、进入文件写入
5. 最后组装起来
先回顾一下,前面几步:
第二步,是获取单个url 页面的数据;
第三步,是单个页面解析,得到图片链接字典;
第四步,是单个图片文件下载;
这几步都是单个,单个的, 我们最后应该是需要做些循环迭代,来获取所有的数据。
第一步其实是有代码的,就是循环迭代多个Url ,得到多个Url 的html 数据。然后继续循环迭代获取所有的图片数据。
还是先来最后组装成的代码:
#步骤1
def begin_spider(pages):
#步骤2
for i in range(pages):
print("page code:" , str(i+1), "start download")
#步骤3
html= get_web_html("https://www.doutula.com/photo/list?page=" + str(i+1))
#步骤4
pic_dic = get_pic_dic(html)
#步骤5
for key, pic in pic_dic.items():
#步骤6
pic_split_list = pic.split(".")
extension_str = pic_split_list[len(pic_split_list) - 1]
#步骤7
download_file(pic, StringUtils.final_dic_name(key), "." + extension_str, path_name = "doutu")
print("page code:", str(i+1),", Finish!")
具体步骤分析:
1、参数出入 pages ,需要爬取的页数;
2、一个for 循环,进行页面url迭代;
3、根据url 的规律,每个循环得到一个新的页面url ,并且调用get_web_html 获取单个 url 数据;
4、根据url 页面数据,调用 get_pic_dic 获取单页面的 图片 字典;
5、进行字典循环,获取每一条图片数据;
6、这是一个特殊操作,就是提取出 图片的后缀名(因为图片后缀有可能是 多种的,如 png, jpeg, git 等)
7、调用前面的 download_file ,进行文件下载。 (代码中 StringUtils.final_dic_name(key),这个是一个文件名的处理函数,正则实现,去掉非法的字符,不去掉的话,可能会出现写不了文件的报错)
就一句代码:
import re
def final_dic_name(org_name):
"""
:param org_name: 原始字符串
:return: 合法字符串
文件夹名称处理,去除不合法字符
"""
return re.sub(r'[\\/:*?<>|]',"",org_name)
最后调用 begin_spider ,输入需要获取的页数,就可以获取对应页数的图片数据了。
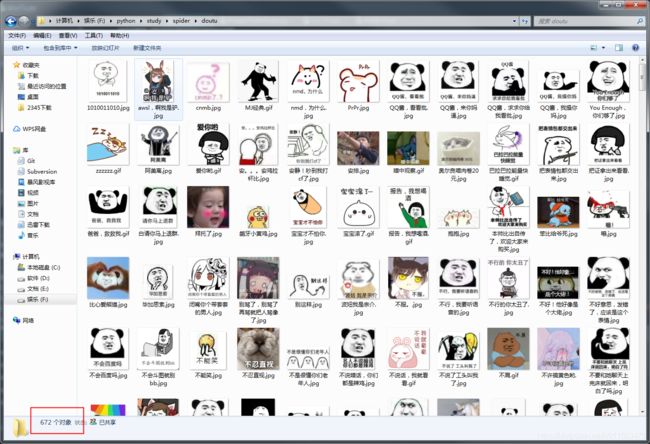
我爬了10页数据, 672张图片:
总结
按照步骤实现,基本可以实现斗图图片的爬取了,代码量其实非常少,这也是 Python 的优势。
如果需要爬取其他网站(静态网站),其实也是一样的道理的,有些步骤是通用的,不过分析 url 和 解析html 数据的细节会不一样。下载网页,下载图片这些代码基本都是一样的。可以拿个其他网站练习一下。
这里描述的基本都是爬图片的实现流程,但是其实里面很多细节点,都是没有展开的,如: Html 结构,BeautifulSoup4的更多用法,文件写入,有兴趣可以去认真学习一下。对做数据的爬取都非常有帮助的。
免责声明:
本内容仅供学习使用,如用于违法行为操作,与本人无关。