使用keras-retinanet训练自己的数据集
使用kears-retinanet训练自己的数据集
1.数据准备
(1.)数据标注
使用labelimg对自己准备好的数据集图片进行标注,我是mac版本的labelimg直接搜索下载mac版本的labelimg包,解压缩后运行
python Downloads/labelImg/labelImg.py
即可使用,w是标注框的快捷键,a键是上一张图片,d键是下一张图片,有一个经验是:数据文件夹和标注的label以及图片的名字尽量不要包含中文。
标注完成的样子如图:
(2).数据集切分
// An highlighted block
# -*- coding=utf-8 -*-
import os
import shutil
import random
#修改split_fraction的数值改变切分的比例,我自己训练和验证是9:1
def split_dataset(dataset, split_fraction=0.9):
train_data_dir = os.path.join(dataset, 'train')
test_data_dir = os.path.join(dataset, 'test')
if os.path.exists(train_data_dir) and os.path.exists(test_data_dir):
return train_data_dir, test_data_dir
os.makedirs(train_data_dir)
os.makedirs(test_data_dir)
#根据自己的图片后缀修改JPG为你对应图片的数据类型,共6处
img_samples = [tr for tr in os.listdir(dataset) if tr.endswith('.JPG')]
print(len(img_samples))
train_samples = random.sample(img_samples,int(len(img_samples)*split_fraction))
test_samples = [te for te in img_samples if te not in train_samples]
os.mkdir(os.path.join(dataset,'train','JPEGImages'))
os.mkdir(os.path.join(dataset,'train','Annotations'))
os.mkdir(os.path.join(dataset, 'test', 'JPEGImages'))
os.mkdir(os.path.join(dataset,'test','Annotations'))
for s in train_samples:
print(s)
shutil.move(os.path.join(dataset,s),os.path.join(dataset,'train','JPEGImages'))
shutil.move(os.path.join(dataset,s.replace('JPG','xml')),os.path.join(dataset,'train','Annotations'))
for t in test_samples:
shutil.move(os.path.join(dataset, t), os.path.join(dataset, 'test', 'JPEGImages'))
shutil.move(os.path.join(dataset, t.replace('JPG','xml')), os.path.join(dataset, 'test', 'Annotations'))
return train_data_dir, test_data_dir
def clean_dataset(dataset):
img_samples = [tr for tr in os.listdir(dataset) if tr.endswith('.JPG') ]
xml_samples = [tr for tr in os.listdir(dataset) if tr.endswith('.xml')]
if len(img_samples) > len(xml_samples):
for s in img_samples:
if s.replace('JPG','xml') not in xml_samples:
os.remove(os.path.join(dataset,s))
else:
for s in xml_samples:
if s.replace('JPG','xml') not in img_samples:
os.remove(os.path.join(dataset,s))
if __name__ == '__main__':
#修改自己的数据集位置,该文件中应包含所有的图片及对应的xml
clean_dataset('/path/data')
split_dataset('/path/data')
执行完该切分代码后文件夹中会变成这样:
data为你的原始文件夹下面会被切分成train/test,train里面包含Annotations(存放左右的xml)和JPEGImages (存放所有的图片)2个文件夹,test里面一样。

(3).生成训练所需的csv文件
将train中的Annotations和下面这段代码的py文件放在同一个目录下,运行py文件会在同目录下生成2个文件:
#-*- coding:utf-8 -*-
import csv
import os
import glob
import sys
class PascalVOC2CSV(object):
def __init__(self,xml=[], ann_path='./Annotations.csv',classes_path='./classes.csv'):
'''
:param xml: 所有Pascal VOC的xml文件路径组成的列表
:param ann_path: ann_path
:param classes_path: classes_path
'''
self.xml = xml
self.ann_path = ann_path
self.classes_path=classes_path
self.label=[]
self.annotations=[]
self.data_transfer()
self.write_file()
def data_transfer(self):
for num, xml_file in enumerate(self.xml):
# try:
# print(xml_file)
# 进度输出
sys.stdout.write('\r>> Converting image %d/%d' % (
num + 1, len(self.xml)))
sys.stdout.flush()
with open(xml_file, 'r',encoding='UTF-8') as fp:
for p in fp:
if '' in p:
self.filen_ame = p.split('>')[1].split('<')[0]
print(self.filen_ame)
if ' in p:
# 类别
d = [next(fp).split('>')[1].split('<')[0] for _ in range(10)]
self.supercategory = d[0]
if self.supercategory not in self.label:
self.label.append(self.supercategory)
# 边界框
print('xml_file',xml_file)
print('==d==',d)
if d[-1] == '\n':
x1 = int(d[-5]);
y1 = int(d[-4]);
x2 = int(d[-3]);
y2 = int(d[-2])
else:
x1 = int(d[-4]);
y1 = int(d[-3]);
x2 = int(d[-2]);
y2 = int(d[-1])
self.annotations.append([os.path.join('JPEGImages',self.filen_ame),x1,y1,x2,y2,self.supercategory])
fp.close()
# except:
# continue
#print(self.annotations)
sys.stdout.write('\n')
sys.stdout.flush()
def write_file(self,):
with open(self.ann_path, 'w') as fp:
csv_writer = csv.writer(fp, dialect='excel')
csv_writer.writerows(self.annotations)
class_name=sorted(self.label)
class_=[]
for num,name in enumerate(class_name):
class_.append([name,num])
with open(self.classes_path, 'w') as fp:
csv_writer = csv.writer(fp, dialect='excel')
csv_writer.writerows(class_)
xml_file = glob.glob('./Annotations/*.xml')
print(xml_file)
PascalVOC2CSV(xml_file)
执行上述代码以后会生成2个文件如图所示:
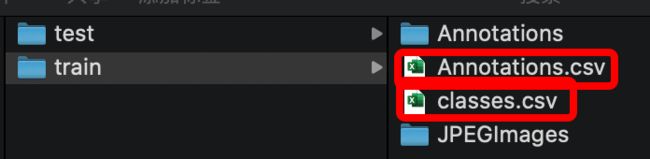
其中Annotations.csv文件是我们训练所需要的bbox信息及label信息,classes.csv是我们的检测框的所有类别。
Annotations.csv内容示例:
classes.csv内容示例:

目前我只有一个类别box,0是类别的index。
使用同样的操作方式将test中的Annotations文件夹也运行一下代码生成对应的Annotations.csv和classes.csv,将Annotations.csv放到test文件夹下,因为数据是随机切分的所以生成的classes.csv有可能类别不全,所以我们弃用。到此数据就全部准备好了,最终的数据结构应该为:

2.训练前期准备
(1)环境搭建
目前我使用的环境是:
1.keras 版本 2.2.4
2.tensorflow-gpu 版本 1.13.2(macbook本机训练tenserflow 版本 1.13.2)
3.克隆代码仓库: https://github.com/fizyr/keras-retinanet
4.切换到克隆下来的keras-retinanet的目录下面:
pip install numpy --user(如果已经装了numpy的略过此步骤)
pip install . --user
python setup.py build_ext --inplace
如果使用的是服务器,同样执行上面的4步操作。
(2)数据
1.将第一步准备好的data文件夹拷贝到keras-retinanet目录下即可,或者是其他自定义的目录。
3.模型训练
1.如果只是单纯的训练的话
python keras_retinanet/bin/train.py csv data/train/Annotations.csv data/train/classes.csv
2.设置某些训练参数进行训练
python keras_retinanet/bin/train.py --epochs 20 --steps 1000 --batch-size 2 --gpu 0 csv data/train/Annotations.csv data/train/classes.csv
3.如果要在训练过程中查看训练的模型的map
python keras_retinanet/bin/train.py --epochs 20 --steps 1000 --batch-size 2 --gpu 0 csv data/train/Annotations.csv data/train/classes.csv --val-annotations data/test/Annotations.csv
4.模型转换及前向预测
(1)模型转化
1.根据自己设置的参数模型训练完毕后,默认的保存路径keras-retinanet/snapshots文件夹下如图:![]()
这是我训练了10个epoch保存了10个h5的模型,这个模型还不能进行前向推理,我们根据map值从训练保存的模型中挑选一个map最高的进行模型转化,执行:
python keras_retinanet/bin/convert_model.py snapshots/resnet50_csv_02.h5 /path/to/save/inference/model.h5
即可得到转换后的模型model.h5(可以根据自己的需要取名字)
(2)模型预测
1.加载模型
from keras_retinanet.models import load_model
model = load_model('/path/to/model.h5', backbone_name='resnet50')
2.预测
boxes, scores, labels = model.predict_on_batch(inputs)
模型的预测结果是boxes 包含4个信息( x1,y1,x2,y2),
scores 是类别置信度,
label是类别的index。