课程向:深度学习与人类语言处理 ——李宏毅,2020 (P25)
Multilingual BERT
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
考虑到部分英文术语的不易理解性,因此笔记尽可能在标题后加中文辅助理解,虽然这样看起来会乱一些,但更好读者理解,以及文章内部较少使用英文术语或者即使用英文也会加中文注释,望见谅
深度学习与人类语言处理 P25 系列文章目录
- Multilingual BERT
- 前言
- I Multilingual BERT
-
- 1.1 Monolingual->Multilingual 单一语种到多语种BERT
- 1.2 Multilingual BERT Speciality 多语种BERT的神奇之处
- 1.3 Result 实验结果
- 1.4 XTREME 评测
- 1.5 Cross-lingual 跨语言学习的猜想
- 1.6 Mean Reciprocal Rank 同义但不同语种的词向量相似度
- II How Cross-lingual
-
- 2.1 hypothesis 两种猜想
- 2.2 Experiment 实验证明
- 2.3 Weird 疑惑
前言
在前一篇的上半篇中(P24-1)我们讲解了 Text Style Transfer 文字风格转换,我们将类比语音、图像风格转换,进而实现文字风格转换,其实三者方法大同小异。以及在使用无监督学习方法做文字风格转换时会遇到的问题,解决方法等。在下半篇本篇P24-2中,我们讲解了一些其他应用无监督的自然语言处理的模型与方法:无监督的 Summarization 摘要 、Translation 翻译 和 ASR 语音辨识。
本篇,我们将进入Multilingual BERT,多语种BERT的神奇之处,零样本学习的跨语言学习能力以及有关猜想和实验。
I Multilingual BERT
我们知道世界上有6000至7000多种语言,面对如此多的语言,我们需要对每一种语言都训练一个BERT么?
1.1 Monolingual->Multilingual 单一语种到多语种BERT
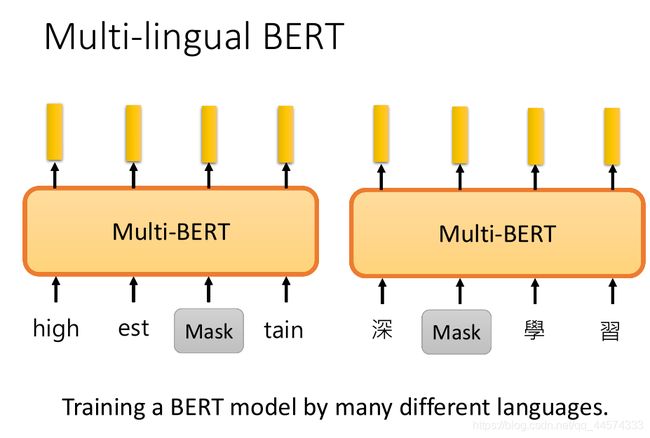
其实我们可以训练一个精通多种语言的BERT,这个就是Multilingual BERT,多语种BERT。简单来讲,多语种BERT就是通过多种语言的语料训练得来的预训练模型。训练任务和我们最开始讲的预测[MASK]方式相同(BERT讲解,请看P18的III BERT)
这里唯一要注意的就是,因为各语种的token不同,也就是例如中文的字和英文的词汇,所以在训练这个多语种BERT前,我们是需要构建一个超大的词汇表,里面要包含所有语言的所有的token。
其实训练方式相同,我们完全可以把多语种BERT看作数据量、参数量更多的大号BERT而已,那到底通过这种多语种训练出的BERT比单一语种训练得到的BERT有什么特殊之处,有什么优点呢?
1.2 Multilingual BERT Speciality 多语种BERT的神奇之处
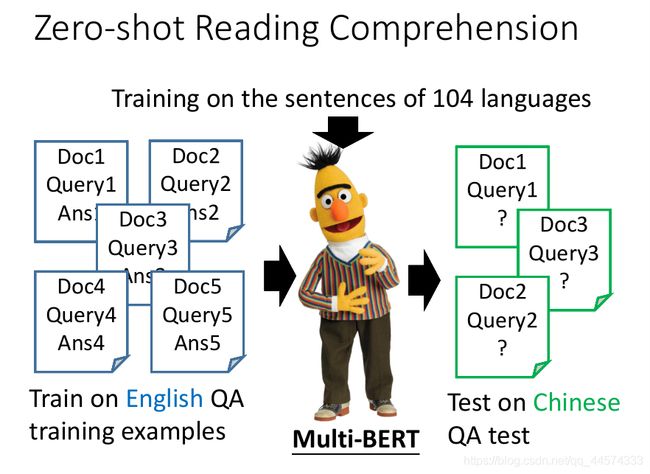
如果大家有了解GPT系列,也能猜到多语种BERT的特殊之处,Zero-shot Reading Comprehension, 可以通过零样本学习方式解决阅读理解问题。
举例而言,如上图,在我们有了这个Multilingual BERT以后,接下来要拿它去做down-stream具体任务来微调。假设我们的down-stream任务是英文的阅读理解,也就是抽取式QA,输入文章和问题,输出答案在文章的起始索引和终止索引。在Multilingual BERT已经经过英文语料的QA阅读理解有监督训练后,它可以直接解决中文的抽取式QA问题。
1.3 Result 实验结果
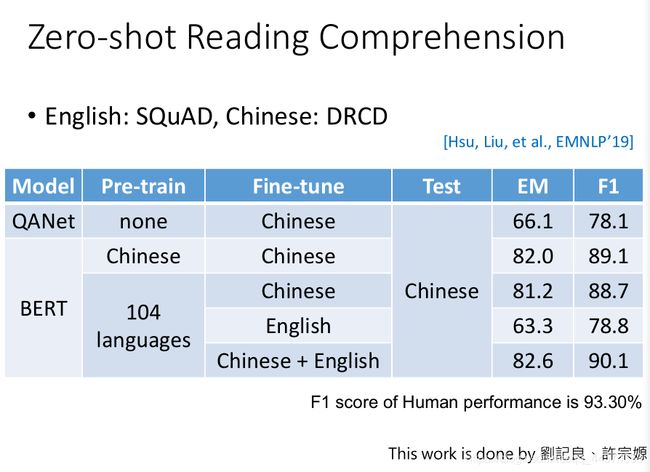
实验结果,如上图,我们可以看到,仅用中文训练、微调和测试的BERT F1的值为89.1%。而多语种训练、中英文微调和中文测试下的多语种BERT F1的值为90.1%,竟超过了专门就是用来解中文QA的BERT分数,当然两者都没超过人类的93.3%。
这种跨语言的学习能力,可以帮助我们解决这类问题,手上只有中文的任务资料,但我们想应用到英文同样的任务中。此时,你不需要将手上中文的任务资料都翻译成英文再使用,可以用多语种BERT在中文任务上微调,最后直接应用到英文任务中。老师也对这样的任务进行了实验,结果表明,直接跨语种学习的BERT甚至比翻译后应用BERT的效果更好!(当然,也有可能是翻译的问题QAQ,是直接拿Google翻译跑的)
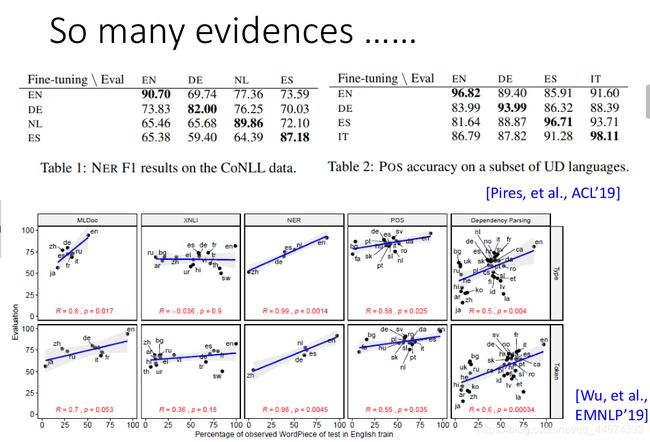
当然,跨语种学习的任务不只是QA,像NER命名实体识别、POS词性标注也有类似的优秀效果。
1.4 XTREME 评测

用 Multilingual BERT 做跨语言的学习,今天上算是常识了
所以谷歌特意做了一个评测任务XTREME,测试多语种BERT的跨语言学习的能力。在XTREME里面一共有9个任务,上图的从XNLI从上到下到TyDiQA,每一个任务都有40种不同的语言。参加这个评测就是要在英文上训练模型,测试在剩下39种不同的语言上。
1.5 Cross-lingual 跨语言学习的猜想
至此,你一定也会有这样的问题,为什么跨语言学习是可能的,甚至是出色的,为什么在英文上训练的模型能够测试在中文上?训练和测试的不同可是万万不可的啊。
可能的原因的是,也许在 Multilingual BERT 中,它学到了把不同语言的资讯去掉,只保留语义的资讯。对它来说不同的语言都是同一种语言!(在此,笔者又想到了那句1就是1,2就是2,如果你也想到这个了说明你真的有认真学过上一节课或者上一篇笔记。当然,这只是笔者推测的一个原因)
1.6 Mean Reciprocal Rank 同义但不同语种的词向量相似度
那 Multilingual BERT 真的能把同样语义的词汇视为同一种么,也就是对于它而言,例如“fish”就是“鱼”,“鱼”也就是“fish”。对此,老师也做了这样的实验:
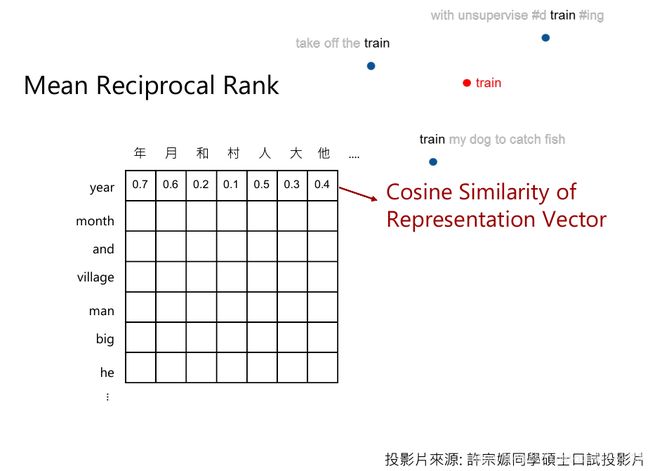
用英文训练出的Multilingual BERT后,得到每一个英文词汇的embedding,当然BERT会考虑上下文,不同上下文的同一个词汇的embedding不同,因此直接把这些同一词汇的不同embedding平均起来作为这个词汇的词向量。同样,也把中文每个字的embedding也平均出来。并计算英文词汇和中文的每一个字的词向量的两两相似度。
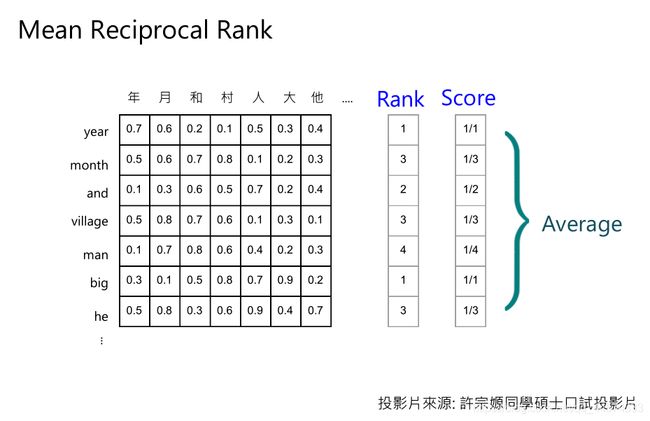
这个Rank排名方式叫 Mean Reciprocal Rank
具体计算相似度分数方法如上图,
在计算year时,发现相似度最大是正确答案年,正确答案排第一,因此给Rank 1,Score 1
在计算month时,发现相似度最大是错误答案村,而正确答案月排第三,因此给Rank 3 ,Score 1 3 \frac{1}{3} 31
依次计算,便得到整个词表的分数,把这些分数平均起来就代表中文和英文的语义一样的embedding越接近。
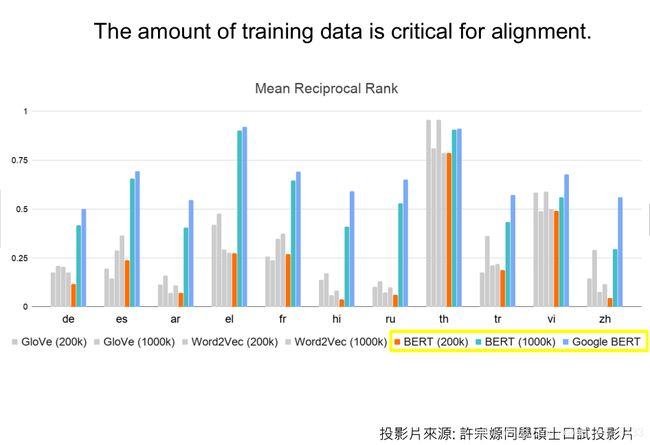
这个 Mean Reciprocal Rank 算出来的值,在某些语言上是惊人的高,在th 泰文这个值都要达到0.9,而且对于多数语言,则个MRR的值都超过了0.5,这代表了几乎每一个词汇的对应关系不是排在第一就是第二,这个是相当惊人的结果!
II How Cross-lingual
在听到上述惊人的结果后,你一定也想知道模型究竟是如何做到跨语言学习的。
2.1 hypothesis 两种猜想
而对于Multilingual BERT而言,到底是怎样实现这种神奇的结果,可以使同义但不同语种的词向量相似度如此之高,也就是1.6讲的MRR。
一个比较直觉的想法是,不同语言其实还是有同样的token,如属于同一语系的语言。但是这解释不了中文、英文的对应关系。在此,有两种猜想:
(1)一个可能的推想是Code Switching 中英交融,举例来说,在中文的句子里面是有掺杂英文的词汇的,如“DNA的结构很像螺旋梯”,凭借着这种中英交杂的句子多语种BERT可能就会学到一定的中英关系。就算是我们的训练资料里没有这种中英交杂的句子,对于中英文还是可能有共用的token,如阿拉伯数字,1就是1,2就是2:)。而此时多语种BERT就可以根据数字的词向量的映射关系类比到其他文字关系。
(2)还有一个另外的猜测是会不会还有一些中介的语言。虽然中英文没有共用的token,但是有一种神秘的语言,称其为X,X和中文有一些共用的token,X和英文有一些共用的token。
所以就有很多文献研究了这一问题,我们只讲其中一个实验,一篇来自ICLR’2020的文献破解了我们刚刚讨论的两个猜想。
2.2 Experiment 实验证明

作者做了这样的一个实验,将英文训练资料里的所有token都换成一种根本不存在的假语言,Fake-English,如上图中的将“the->甲”、”cat->乙“等等。假语言和英文:
一没有 任何Code Switching 交杂句,没有任何共用的token。
二没有 任何中介的语言 ,这两种限制刚好对应了我们刚刚讲的两种假设。
因为作者只拿两种语言:English英语和Fake-English假语言训练,不是Multilingual BERT多语种BERT,而被自称为B-BERT。在这种情况下,B-BERT在英文和假英文预训练完成后,在假英文任务中微调,测试在假英文上准确率78%。在假英文任务中微调,测试在英文上准确率77.5%。
综上实验,可知,这种跨语言的能力不需要两种语言有任何交杂、中介语言的存在,这个就是一个神奇的现象。那究竟是因为什么能让模型有这种跨语言学习能力还是一个尚待研究的问题。
如果按照老师示例所讲,在此笔者还是觉得这个实验是有一定问题,因为仅仅替换英文词汇就当作一种新语言是讲不通的,如”A B C“这个句子,我们用”1 2 3 “代替,且结构、含义是没变的。词序都没更改,只不过相当于做了个转码操作。
2.3 Weird 疑惑
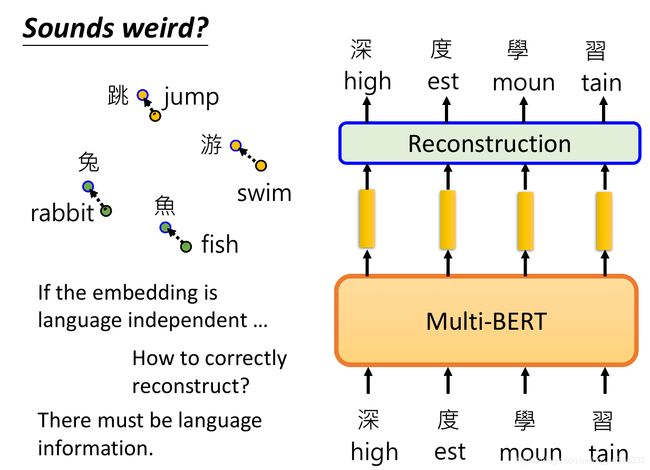
此时,你可能会有这样的疑惑,如果Multilingual BERT多语种BERT可以把不同语言同样意思的词汇的embedding都相似地表示,也就是说不同语言的token如果有同样的意思就会有同样的embedding。这样的想法好像不太合理。
因为Multilingual BERT多语种BERT在训练的时候,如果我们输入英文的句子,输出就是英文的句子;如果输入中文的句子,输出就是中文的句子。如果多语种BERT把语种间的差异抹除了,那它怎么做到输入英文就输出英文,输入中文就输出中文的呢?因此,多语种BERT显然是知道语种信息的。
有实验表明,不同语言的所有token的embedding的平均还是有差异的。而且同样语系的语言的embedding的平均就会比较接近。
老师的学生后来做了这样的一个实验,将所有英文的Embedding平均起来得到E,把所有中文的Embedding都平均起来得到C。然后进行实验验证,是不是同样意思的中英文词汇其实都只是差一个方向而已,即:
跳 − j u m p = = C − E 跳 - jump == C - E 跳−jump==C−E
实验结果表明
跳 − j u m p = = ( C − E ) × α 跳 - jump == ( C - E)× \alpha 跳−jump==(C−E)×α 且 α \alpha α越大,翻译的程度越大。
至此,神奇的Multilingual BERT多语种BERT的讲解到此结束。