从底层结构开始学习FPGA----分布式RAM(DRAM,Distributed RAM)
文章目录
系列目录与传送门
一、什么是RAM?什么是ROM?
二、块RAM和分布式RAM
2.1、BRAM
2.2、DRAM
2.3、使用建议
三、详解分布式RAM
四、实现方式
4.1、推断
4.2、原语
4.3、IP
4.4、仿真
五、应用
系列目录与传送门
《从底层结构开始学习FPGA》目录与传送门
一、什么是RAM?什么是ROM?
RAM是Random Access Memory的首字母缩写。它是一种主存储器,用于存储当前正在使用的信息。信息可以是正在处理的数据或程序代码。它是一种读写存储器,这意味着它几乎可以同时存储(写入)和访问(读取)数据。但RAM是易失性或临时性存储器,即当电源被移除时其内容会被擦除。RAM是一种快速存取存储器,因为无论其物理位置如何,它都可以随时随机存储和访问数据。它存储启动设备所需的必要指令和处理器正在使用的数据。它通过在组件之间快速传输数据来提高系统的处理速度。
ROM,Read Only Memory,即只读存储器,也是一种主存储器,但它永久存储数据。它是一种非易失性存储器,即当电源被移除时,其数据内容不会被擦除。顾名思义,它是只读存储器,这意味着数据不能更改,但可以访问任意次数。只能访问数据而不能写入数据。
RAM和ROM都可以简单地视为一张表格,每个格子的内容就是其所存储的信息,而地址线则是寻找对应表格的“身份号码”。RAM可以对表格的内容进行读、写操作,而ROM只能对表格进行读操作,无法进行写操作。
二、块RAM和分布式RAM
FGPA内部的分布式RAM(DRAM,Distributed RAM)的概念是相对于块RAM(BRAM,Block RAM)来说的。物理上看,BRAM是fpga中固定存在的硬件资源,而DRAM则是使用逻辑单元LUT拼出来的,实际上算是LUT的延伸使用。
2.1、BRAM
BRAM由一定数量固定大小的存储块构成的,使用BRAM不占用额外的逻辑资源,且速度快。但是使用的时候消耗的BRAM资源是其块大小的整数倍。如Xilinx7系列FPGA结构中每个BRAM有36Kbit的容量,既可以作为一个36Kbit的存储器使用,也可以拆分为两个独立的18Kbit存储器使用。反过来相邻两个BRAM可以结合起来实现72Kbit存储器。每个Block RAM都有两套访问存储器所需的地址总线、数据总线及控制信号等信号,因此其既可以作为单端口存储器,也可以作为双端口存储器。需要注意的时访问BRAM需要和时钟同步,异步访问是不支持的。
2.2、DRAM
只有SLICEM里的查找表才可以用做DRAM,利用查找表为电路实现存储器,既可以实现芯片内部存储,又能提高资源利用率。DRAM的特点是可以实现BRAM不能实现的异步访问。不过使用分布式RAM实现大规模的存储器会占用大量的LUT,可用来实现逻辑的查找表就会减少。因此建议仅在需要小规模存储器时,使用这种分布式RAM。
2.3、使用建议
DRAM使用的是没有综合的LUT单元,而BRAM是块RAM,它的大小和位置是固定的。即使你只使用了一点点BRAM,综合后同样会消耗一整块RAM。BRAM是一列一列分布的,这样可能造成用户逻辑模块和BRAM直接的距离较长,延时较长,最终导致性能下降。如果使用到多个BRAM最好合理规划一下布局。
较大的存储应用,建议用BRAM;零星的小应用,可以用DRAM。但这只是个一般原则,具体的使用得看整个设计中资源的冗余度和性能要求。
三、详解分布式RAM
CLB(可配置逻辑单元,Configurable Logic Block)是FPGA底层的基本逻辑单元,由两个SLICE组成。SLICE的种类有两种:SLICEL与SLICEM:


SLICEL与SLICEM的组成大致相同,只有LUT6有区别。我们把两种LUT6放到一起来看看:

SLICEM中的LUT较SLICEL中的LUT,除了具备读总线A1~A6,还具有WE(写使能)、DI1~DI2(数据写入端口)和WA1~WA8(数据写地址端口),所以SLICEM还具备数据写入功能,这使得其可以作为分布式RAM和移位寄存器使用。
而SLICEL中的LUT只有地址线与输出,所以我们只能将其作为一个ROM使用,从而实现查找表功能。
由于每个SLICEM中均有4个LUT,所以其资源可以实现以下形式的DRAM:

其配置如下:
- 单口RAM
- 双口RAM
- 简单双端口
- 四端口
(一)单口RAM:同步写、异步读,读写操作共用一组地址总线

(二)双口RAM:一个端口用于同步写和异步读;一个端口用于异步读取

(三)简单双端口:一个用于同步写的端口(从写端口没有数据输出/读端口);一个端口用于异步读取

(四)四端口:一个用于同步写和异步读的端口;三个端口用于异步读取

(五)更大深度的实现
此外,可以通过多个LUT6+MUX的方式实现更大深度的DRAM。

128深度的DRAM,可以通过2个LUT6+1个MUX2实现,两个LUT6分别存储低64bit和高64bit的数据,通过MUX2来进行选取,从而拼接而成实现128深度的单口DRAM。

同样的,也可以使用相同的结构实现256深度的DRAM。

256深度的单口RAM则使用了4个LUT6+2个F7MUX+1个F8MUX,刚好是一个SLICEM里面的最大资源数量,所以单个SLICEM能实现的最大深度DRAM就是256*1的单口DRAM。
四、实现方式
DRAM可以使用多种方式来实现,各种方法都有利弊,所以在实际使用过程中应根据需求及开发环境来灵活使用。
4.1、推断
推断是指设计者使用符合规范的RTL代码,由综合工具(此文均指xilinx的vivado)自动推断出DRAM结构的方式。
由于推断结果一般较为理想,因此建议采用推断,除非给定用例不受支持,或者无法在性能、面积或功耗方面实现足够的结果。在此类情况下,请尝试其它方法。推断 RAM 时,赛灵思建议您使用 Vivado 工具中提供的 HDL 模板。如前文所述,使用异步复位会给 RAM 推断造成不利影响,应避免使用。
(优点)
- 便于移植
- 便于读取和理解
- 自我文档化
- 快速仿真
(不足)
- 不能访问所有可用的 RAM 配置
- 结果可能并非最佳
以下是64深度,6宽度的单端口DRAM的RTL代码实现方式:
module RTL_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
reg [5:0] dram64x6 [63:0] ; //64*6
always@(posedge wclk)
if(we) dram64x6[addr] <= d;
assign o = dram64x6[addr];
endmodule其写操作与时钟同步,而读操作则是异步。
在FPGA上综合的结果如下:

由6个1宽度的64深度RAM级联组成,资源消耗则为6个LUT6,与理论情况一致。

4.2、原语
原语是xilinx提供的底层设计元素,类似于嵌入式开发中提供的底层库函数。针对DRAM的实现,xilinx同样提供了数个原语,如:RAM64X1S,RAM16X4S,RAM128X1D等,具体可查阅《UG799,Xilinx 7 Series FPGA and Zynq-7000 All Programmable SoC Libraries Guide for Schematic Designs》。需要注意的是,DRAM原语通常都是固定了位宽、深度和实现方式的,对于某些不符合深度、位宽的DRAM实现,则需要找更小的原语来实现。例如,原语无法直接实现64深度6位宽的单端口DRAM,只能通过6个64深度1位宽的单端口DRAM--RAM64X1S来实现。
(优点)
- 对实现方案有最高控制权限
- 能访问块的各项功能
(不足)
- 代码可移植性差
- 功能和用途冗长繁琐,难以理解
以下是64深度,6宽度的单端口DRAM的原语实现方式:
module PRIMATE_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst0 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[0]), // 1-bit data input
.O (o[0]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst1 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[1]), // 1-bit data input
.O (o[1]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst2 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[2]), // 1-bit data input
.O (o[2]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst3 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[3]), // 1-bit data input
.O (o[3]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst4 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[4]), // 1-bit data input
.O (o[4]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst5 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[5]), // 1-bit data input
.O (o[5]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
endmodule综合结果与推断的结果基本一致。

资源使用情况也与推断的结果一致--由6个1宽度的64深度RAM级联组成,资源消耗则为6个LUT6,与理论情况一致。

可以看到采用原语的DRAM开发方式,需要对基础原语进行多次例化,虽然可以借用generate语法,但是仍然很麻烦。
4.3、IP
XILINX还提供了DRAM的IP供开发者使用,采用IP的开发方式,GUI程度高,开发简单,但是由于定制程度高,所以可移植性也一般。
(优点)
- 在使用多个组件时一般能提供更优化的结果
- 易于指定和配置
(不足)
- 代码可移植性差
- 需要管理核
DRAM的IP核全称为Distributed Memory Generator,其使用较为简单,接下来我们采用IP核配置一个64深度的6位宽单端口DRAM,配置过程如下:
(第一页)
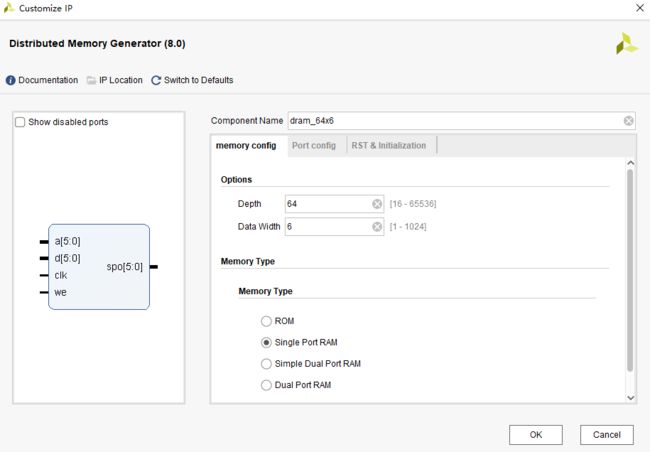
(第二页)

(第三页)

接下来综合,再根据veo文件提供的例化模板,编写RTL对IP核进行例化:
module IP_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
//例化DRAM IP核
dram_64x6 dram_64x6_inst (
.a (addr), // input wire [5 : 0] a
.d (d), // input wire [5 : 0] d
.clk (wclk), // input wire clk
.we (we), // input wire we
.spo (o) // output wire [5 : 0] spo
);
endmodule综合结果,资源消耗均与上述两种方法一致。


4.4、仿真
我们将三种实现DRAM的模块例化到同一个顶层文件,再编写testbench对其仿真,实现功能:先往地址0-63写入数据0-63,再从地址0-63读出数据,观察写、读数据是否一致。
顶层文件:
module test(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o_rtl,
output [5:0] o_primate,
output [5:0] o_ip
);
//例化RTL型
RTL_DRAM RTL_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_rtl ) //output
);
//例化原语型
PRIMATE_DRAM PRIMATE_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_primate) //output
);
//例化IP型
IP_DRAM IP_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_ip ) //output
);
endmoduletestbench:
`timescale 1ns / 1ns
module tb_test();
reg wclk; //input clk
reg [5:0] addr; //input address
reg [5:0] d; //input data
reg we; //input write enable
wire [5:0] o_rtl;
wire [5:0] o_primate;
wire [5:0] o_ip;
//例化test模块
test test_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o_rtl (o_rtl ), //output
.o_primate (o_primate ), //output
.o_ip (o_ip ) //output
);
initial begin
wclk =0;
we =1;
d = 0;
addr = 0;
wait(d == 6'd63);#10 we =0;
end
always #5 wclk = ~wclk;
always @(posedge wclk)begin
d <= d+1;
addr <= addr+1;
end
endmodule仿真结果如下:与设想情况一致。

五、应用
分布式RAM提供了对非常小的数组使用存储元素和对较大数组使用BRAM之间的权衡。建议尽可能地使用RTL方式推断内存,以提供最大的灵活性。分布式RAM也可以通过原语实例化或使用IP来生成。
一般来说,分布式RAM应该用于所有深度为64位或更少的情况,除非设备缺少SLICEM或逻辑资源。因为分布式RAM在资源、性能和功能方面更高效。
对于大于64位但小于或等于128位的深度,使用最佳资源的决定取决于以下因素:
- 额外块ram的可用性。如果不可用,就使用分布式RAM。
- 延迟的要求。如果需要异步读功能,则必须使用分布式ram。
- 数据宽度。宽度大于16位应该使用块RAM,如果可以的话。
- 必要的性能要求。寄存的分布式ram通常比Bram有更短的Tco时间和更少的布局限制。