语音识别 --- 音频信号提取
音频信号特征提取的一般流程为:

假设我们的语音信号采样频率为 8000Hz,语音数据在这里获取。
import numpy
import scipy.io.wavfile
from scipy.fftpack import dct
sample_rate, signal = scipy.io.wavfile.read('OSR_us_000_0010_8k.wav')
# sample_rate = 8000
signal = signal[0:int(3.5 * sample_rate)] # 我们只取前3.5s
得到频率图如下:

Q: 为什么信号值有正有负?
A: 信号值是相对于周围气压的压力差,正值表示气压高于周围气压,负值表示低于周围气压。
预加重
在音频录制过程中,高频信号更容易衰减,而像元音等一些因素的发音包含了较多的高频信号的成分,高频信号的丢失,可能会导致音素的共振峰并不明,使得声学模型对这些音素的建模能力不强。预加重是个一阶高通滤波器,可以提高信号高频部分的能量,给定时域输入信号 , 预加重之后信号为
其中滤波器系数的值通常为 0.95 或 0.97,这里取 pre_emphasis = 0.97:
emphasized_signal = numpy.append(signal[0], signal[1:] - 0.97 * signal[:-1])
题外话:预加重在现代系统中的影响不大,主要是因为除避免在现代 FFT 实现中不应成为问题的 FFT 数值问题,大多数预加重滤波器的动机都可以通过均值归一化来实现。
分帧加窗
分帧
语音信号是一个非稳态的、时变的信号。但在短时间范围内可以认为语音信号是稳态的、时不变的。这个短时间一般取 10-30ms,因此在进行语音信号处理时,为减少语音信号整体的非稳态、时变的影响,从而对语音信号进行分段处理,其中每一段称为一帧,帧长一般取 25ms。为了使帧与帧之间平滑过渡,保持其连续性,分帧一般采用交叠分段的方法,保证相邻两帧相互重叠一部分。相邻两帧的起始位置的时间差称为帧移,我们一般在使用中帧移取值为 10ms。
对于一个 16000Hz 采样的音频来说,帧长有 16000 * 0.025 = 400 个点,帧移有 16000 * 0.01 = 160 个点。使用 num_samples、frame_len、frame_shift 分别代表音频的数据点数、帧长和帧移,那么 i 帧的数据需要的点数为
加窗
因为后面会对信号做 FFT,而 FFT 变换的要求为:信号要么从 -∞ 到 +∞ ,要么为周期信号。现实世界中,不可能采集时间从 -∞ 到 +∞ 的信号,只能是有限时间长度的信号。由于分帧后的信号是非周期的,进行 FFT 变换之后会有频谱泄露的问题发生,为了将这个泄漏误差减少到最小程度,我们需要使用加权函数,也叫窗函数。加窗主要是为了使时域信号似乎更好地满足 FFT 处理的周期性要求,减少泄漏。
关于频率泄露,可参考 https://blog.csdn.net/zhaomengszu/article/details/72627750 。总结来说,对信号的非周期性截断做 FFT。
在语音识别中,一般选择汉明窗作为窗函数,它能使信号在窗边界的值近似为 0,从而使得信号趋近于是一个周期信号,该窗函数如下:
傅里叶变换
傅里叶变换的几个概念:
- FT(Fourier Transformation):傅里叶变换。就是我们理论上的概念,但是对于连续的信号无法在计算机上使用。其时域信号和频域信号都是连续的。
- DTFT(Discrete-time Fourier Transform):离散时间傅里叶变换。这里的“离散时间”指的是时域上式离散的,也就是计算机进行了采样。不过傅里叶变换后的结果依然是连续的。
- DFT(Discrete Fourier Transform):离散傅里叶变换。在 DTFT 之后,将傅里叶变换的结果也进行离散化,就是 DFT。
- FFT(Fast Fourier Transformation):快速傅里叶变换。就是 DFT 的快速算法,一般工程应用时用的都是这种算法。
- FS(Fourier Series):傅里叶级数。是针对时域连续周期信号提出的,结果是离散的频域结果。
- DFS(Discrete Fourier Series):离散傅里叶级数。是针对时域离散周期信号提出的,DFS 与 DFT 的本质是一样的。
也就是说:FT 时域连续、频域连续;DTFT 时域离散、频域连续;DFT 时域离散、频域离散。
Python 可通过 np.fft.fft(x) 来完成傅里叶变换。
一篇关于傅里叶变换的极好的博客:https://www.cnblogs.com/LXP-Never/p/11558302.html
小知识
傅里叶变换的意义:任何周期函数,都可以看作是不同振幅,不同相位正弦波的叠加.
频谱
频谱是指一个时域的信号在频域下的表示方式,可以针对信号进行傅里叶变换而得,所得的结果会是分别以幅度及相位为纵轴,频率为横轴的两张图.
频谱分析是包括幅频谱分析和相频谱分析,不过最常用的是幅频谱分析。
https://zhuanlan.zhihu.com/p/147386972
梅尔倒谱系数
梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)。
依据人的听觉实验结果来分析语音的频谱,MFCC 分析依据的听觉机理有两个
- 第一梅尔刻度(Mel scale):人耳感知的声音频率和声音的实际频率并不是线性的,有下面公式
- 从频率转换为梅尔刻度的公式为:
- 从梅尔回到频率:
式中是以梅尔(Mel)为单位的感知频域(简称梅尔频域), 是以 Hz 为单位的实际语音频率。
掩蔽效应
研究表明,人耳对不同频率的声波有不同的听觉敏感度。从 200Hz 到 5000Hz 的语音信号对语音的清晰度影响较大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。
求 MFCC 的步骤:
- 将信号帧化为短帧
- 对于每一帧,计算功率谱的周期图估计
- 将 mel 滤波器组应用于功率谱,求滤波器组的能量,将每个滤波器中的能量相加
- 取所有滤波器组能量的对数
- 取对数滤波器组能量的离散余弦变换(DCT)。
- 保持 DCT 系数 2-13,其余部分丢弃
MFCC 代码实现
1、预处理
预处理包括预加重、分帧、加窗函数。
参考
- 信号频域分析方法的理解
- 傅里叶分析之掐死教程
相关算法
Viterbi 算法
【wikipedia】: 维特比算法(Viterbi algorithm)是一种动态规划算法。它用于寻找最有可能产生观测事件序列的维特比路径——隐含状态序列,特别是在马尔可夫信息源上下文和隐马尔可夫模型中。
维特比算法由安德鲁·维特比(Andrew Viterbi)于1967年提出,用于在数字通信链路中解卷积以消除噪音。此算法如今被常用于语音识别、关键字识别、计算语言学和生物信息学中。例如在语音识别中,声音信号做为观察到的事件序列,而文本字符串,被看作是隐含的产生声音信号的原因,因此可对声音信号应用维特比算法寻找最有可能的文本字符串。
P.S. wikipedia 上给出的关于医生看病的例子解示的非常好:https://zh.wikipedia.org/wiki/%E7%BB%B4%E7%89%B9%E6%AF%94%E7%AE%97%E6%B3%95 。
- 在亚特兰斯特帝国偏远的一个村庄里,村民的身体状态有非常理想化的特征:要么 healthy 要么 fever,医生萨其玛定期访问村庄,对村民的身体状态进行例行检查。
- 村民的状态是 healthy 还是 fever 无法直接观察到,即这些状态对医生而言是隐含的。每天村民会告诉医生自己有以下几种感觉的一种:normal, cold, dizzy,这些是可观察结果。村民身体状态的变化由
transition_probability决定(参见下面状态迁移图),比如 healthy 村民第2天仍然 healthy 的概率为 0.7,而 fever 村民第2天转为 healthy 的概率仅为 0.4 。 - 放射概率
emission_probability表示每天病人感觉的可能性。假如他的状态是 healthy,50% 可能性会感觉 normal。如果他的状态为 fever, 那么有 60% 的可能感觉到头晕。
状态迁移图
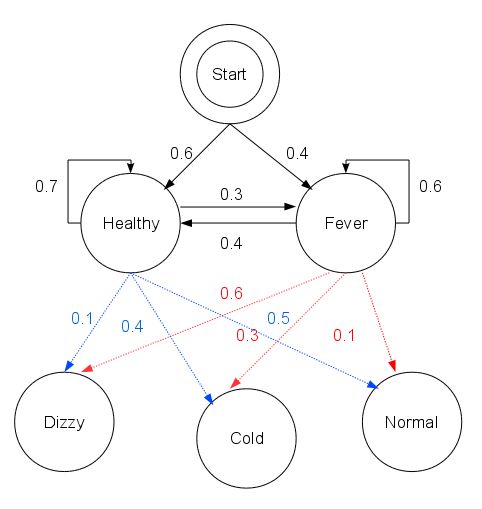
考虑几个问题:
- 医生连续3天检查村民王大春,得知大春3天的感受依次为 normal, cold, and dizzy,那么怎样的健康状态序列最能够解释这些观察结果?
Python 代码示例
states = ('Healthy', 'Fever')
observations = ('normal', 'cold', 'dizzy')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy': {
'Healthy': 0.7,
'Fever': 0.3
},
'Fever': {
'Healthy': 0.4,
'Fever': 0.6
},
}
emission_probability = {
'Healthy': {
'normal': 0.5,
'cold': 0.4,
'dizzy': 0.1
},
'Fever': {
'normal': 0.1,
'cold': 0.3,
'dizzy': 0.6
},
}
brute force method
三天的健康状态共有 8 种可能性,比如 (‘Healthy’, ‘Fever’, ‘Healthy’) 即为其中一种可能序列,BF 方法穷举所有可能序列并计算其概率,找出概率最大的序列。Python 代码如下:
def brute_force():
'''most possible state sequence to generate observation ('normal', 'cold', 'dizzy')'''
from itertools import product
all_states = list(product(states, states, states))
prob, res = 0, None
ep = emission_probability
tp = transition_probability
sp = start_probability
for a, b, c in all_states:
print('{:<10}{:<10}{:<10}'.format(a, b, c))
cur_prob = sp[a] * ep[a]['normal'] * tp[a][b] * ep[b]['cold'] * tp[b][
c] * ep[c]['dizzy']
if cur_prob > prob:
prob = cur_prob
res = (a, b, c)
print(prob, res)
return (prob, res)
其中概率最大的 (‘Healthy’, ‘Healthy’, ‘Fever’),对应的概率值为 0.1512(如下图)。这个方法的缺点是时间复杂度较高,对于长度为 n 的观察序列,求出其对应的概率最大的健康状态序列,时间复杂度为 。而如果有 个隐含状态,则时间复杂度为 。
一个更快捷的方法是 Viterbi 算法。在计算过程中,算法只关注两条健康状态序列,一条是以 ‘H’(Healthy) 结束,另一条以 ‘F’(Fever) 结束,且序列在所有同类别(即最后一个状态相同)且等长序列中概率值最大。
以状态对 (‘HHF’, ‘FHH’) 为例,假设下一步可观察状态为 ‘normal’, 在迭代过程中,算法计算出 (‘HHFH’, ‘HHFF’, ‘FHHH’, ‘FHHF’) 的各个概率,再将此概率乘以放射概率,然后选出分别以 ‘H’, ‘F’ 为后缀且概率最大的序列,作为下一步迭代的输入(参考下图)。即迭代计算的每一步中只保留两个可行输入方案,算法时间复杂度 ,其中 为观察序列的长度。如果有 个隐含状态,其时间复杂度为 。
Viterbi Python 代码
def _viterbi(obs: list, states: list, ep: dict, tp: dict, sp: dict) -> list:
''' Viterbi algorithm
:param obs: list, observation list, e.g., ['normal', 'dizzy', 'dizzy', 'cold']
:param states: list, hidden state list, ['healthy', 'fever']
:param ep: dict, emission probability
:param tp: dict, transition probability
:param sp: dict, state initial probability
:return: list, the most possible state sequence to generate observation list
'''
cache = {}
for i, o in enumerate(obs):
if i == 0:
for s in states:
cache[s] = (sp[s] * ep[s][o], s)
else:
copy_cache = cache.copy()
for s in states:
max_prob, _seq = 0, ''
# find (previous sequence, o) pair to maximize probability
for _prev_state, v in copy_cache.items():
_new_prob = v[0] * tp[_prev_state][s] * ep[s][o]
if _new_prob > max_prob:
max_prob = _new_prob
_seq = v[1]
cache[s] = (max_prob, _seq + '->' + s)
print(cache)
return sorted(cache.values()).pop()[1]
r = _viterbi(
observations,
states,
emission_probability,
transition_probability,
start_probability,
)
输出结果
reference
- Hidden Markov Model: Standford.edu
- Speech and Language Processing (3rd ed. draft)Dan Jurafsky and James H. Martin