mmdetection算法之DETR(1)
文章目录
- DETR里的Transformer
-
-
-
- Transformer的前向操作
- BaseTransformerLayer的前向操作
-
-
- 编码
- 解码
DETR里的Transformer
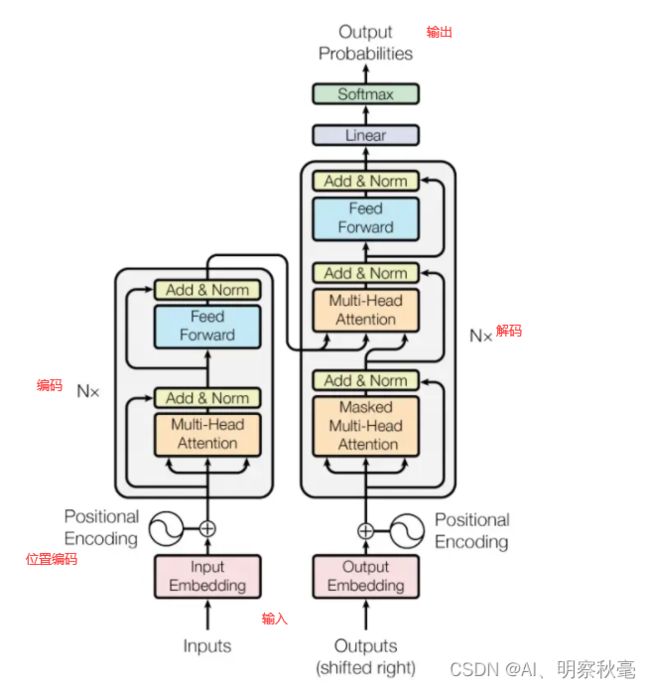
Transformer的前向操作
def forward(self, x, mask, query_embed, pos_embed):
"""Forward function for `Transformer`.
Args:
x (Tensor): Input query with shape [bs, c, h, w] where
c = embed_dims.
mask (Tensor): The key_padding_mask used for encoder and decoder,
with shape [bs, h, w].
query_embed (Tensor): The query embedding for decoder, with shape
[num_query, c].
pos_embed (Tensor): The positional encoding for encoder and
decoder, with the same shape as `x`.
Returns:
tuple[Tensor]: results of decoder containing the following tensor.
- out_dec: Output from decoder. If return_intermediate_dec \
is True output has shape [num_dec_layers, bs,
num_query, embed_dims], else has shape [1, bs, \
num_query, embed_dims].
- memory: Output results from encoder, with shape \
[bs, embed_dims, h, w].
"""
bs, c, h, w = x.shape
# use `view` instead of `flatten` for dynamically exporting to ONNX
x = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c]
pos_embed = pos_embed.view(bs, c, -1).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(
1, bs, 1) # [num_query, dim] -> [num_query, bs, dim]
mask = mask.view(bs, -1) # [bs, h, w] -> [bs, h*w]
memory = self.encoder( # 编码
query=x,
key=None,
value=None,
query_pos=pos_embed,
query_key_padding_mask=mask)
target = torch.zeros_like(query_embed)
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder( # 解码
query=target,
key=memory,
value=memory,
key_pos=pos_embed,
query_pos=query_embed,
key_padding_mask=mask)
out_dec = out_dec.transpose(1, 2)
memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)
return out_dec, memory
BaseTransformerLayer的前向操作
def forward(self,
query,
key=None,
value=None,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `TransformerDecoderLayer`.
**kwargs contains some specific arguments of attentions.
Args:
query (Tensor): The input query with shape
[num_queries, bs, embed_dims] if
self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
value (Tensor): The value tensor with same shape as `key`.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`.
Default: None.
attn_masks (List[Tensor] | None): 2D Tensor used in
calculation of corresponding attention. The length of
it should equal to the number of `attention` in
`operation_order`. Default: None.
query_key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_queries]. Only used in `self_attn` layer.
Defaults to None.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_keys]. Default: None.
Returns:
Tensor: forwarded results with shape [num_queries, bs, embed_dims].
"""
norm_index = 0
attn_index = 0
ffn_index = 0
identity = query # [100,bs,256]
if attn_masks is None:
attn_masks = [None for _ in range(self.num_attn)]
elif isinstance(attn_masks, torch.Tensor):
attn_masks = [
copy.deepcopy(attn_masks) for _ in range(self.num_attn)
]
warnings.warn(f'Use same attn_mask in all attentions in '
f'{self.__class__.__name__} ')
else:
assert len(attn_masks) == self.num_attn, f'The length of ' \
f'attn_masks {len(attn_masks)} must be equal ' \
f'to the number of attention in ' \
f'operation_order {self.num_attn}'
for layer in self.operation_order:
if layer == 'self_attn': # 编码的时候用这个
temp_key = temp_value = query # x[100,bs,256],这里
query = self.attentions[attn_index](
query,
temp_key,
temp_value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=query_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
**kwargs) # [bs,100,256]
attn_index += 1 #
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query, # x
key, # None
value, # None
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
attn_mask=attn_masks[attn_index], # None
key_padding_mask=key_padding_mask, # 注意
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn':
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
编码
memory = self.encoder( # 编码
query=x,
key=None,
value=None,
query_pos=pos_embed,
query_key_padding_mask=mask)
- 编码里,输入的q,k,v,其中q是x(shape[H*W,bs,256]),k=v=q。这里开始要注意输入输出的shape
- attn_mask = None
- key_padding_mask=key_padding_mask(上面传入的=query_key_padding_mask=mask)
编码部分就是使用self_atten
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_pos=None,
attn_mask=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `MultiheadAttention`.
**kwargs allow passing a more general data flow when combining
with other operations in `transformerlayer`.
Args:
query (Tensor): The input query with shape [num_queries, bs,
embed_dims] if self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
If None, the ``query`` will be used. Defaults to None.
value (Tensor): The value tensor with same shape as `key`.
Same in `nn.MultiheadAttention.forward`. Defaults to None.
If None, the `key` will be used.
identity (Tensor): This tensor, with the same shape as x,
will be used for the identity link.
If None, `x` will be used. Defaults to None.
query_pos (Tensor): The positional encoding for query, with
the same shape as `x`. If not None, it will
be added to `x` before forward function. Defaults to None.
key_pos (Tensor): The positional encoding for `key`, with the
same shape as `key`. Defaults to None. If not None, it will
be added to `key` before forward function. If None, and
`query_pos` has the same shape as `key`, then `query_pos`
will be used for `key_pos`. Defaults to None.
attn_mask (Tensor): ByteTensor mask with shape [num_queries,
num_keys]. Same in `nn.MultiheadAttention.forward`.
Defaults to None.
key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
Defaults to None.
Returns:
Tensor: forwarded results with shape
[num_queries, bs, embed_dims]
if self.batch_first is False, else
[bs, num_queries embed_dims].
"""
if key is None:
key = query
if value is None:
value = key
if identity is None:
identity = query
if key_pos is None:
if query_pos is not None:
# use query_pos if key_pos is not available
if query_pos.shape == key.shape:
key_pos = query_pos
else:
warnings.warn(f'position encoding of key is'
f'missing in {self.__class__.__name__}.')
if query_pos is not None:
query = query + query_pos # 加位置编码
if key_pos is not None:
key = key + key_pos # 加位置编码
# Because the dataflow('key', 'query', 'value') of
# ``torch.nn.MultiheadAttention`` is (num_query, batch,
# embed_dims), We should adjust the shape of dataflow from
# batch_first (batch, num_query, embed_dims) to num_query_first
# (num_query ,batch, embed_dims), and recover ``attn_output``
# from num_query_first to batch_first.
if self.batch_first:
query = query.transpose(0, 1)
key = key.transpose(0, 1)
value = value.transpose(0, 1)
out = self.attn( # 进入多头注意力机制,分了8个,256/8=32,后面会cat回去
query=query, # 这个就是transformer的常规操作,就不进入去看了
key=key, # 就是计算自注意力,注意输出就行
value=value,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask)[0] # 返回[bs,h*w,c]
if self.batch_first:
out = out.transpose(0, 1) # 转换维度,[h*w,bs,c]
return identity + self.dropout_layer(self.proj_drop(out)) # 残差,要dropout,可能数据量太大了吧,也可以防止过拟合
解码
target = torch.zeros_like(query_embed)
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder( # 解码
query=target, # [num_query, dim]
key=memory, # [h*w,bs,c]
value=memory, # [h*w,bs,c]
key_pos=pos_embed, # [num_query, bs, dim]
query_pos=query_embed, # [num_query, bs, dim]
key_padding_mask=mask) # [bs, h*w]
- 解码看图第一个部分是self_attn, 输入q=target,k=v=q,返回q[num_query, bs, dim]
- 第二部分是cross_attn,输入是q[num_query, bs, dim], key=value=memory, # [h*w,bs,c]我们主要看看cross_attn部分。shape不同,是怎么进行自注意力的
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query, # [num_query, dim]
key, # [h*w,bs,c]
value, # [h*w,bs,c]
identity if self.pre_norm else None,
query_pos=query_pos, # [num_query, bs, dim]
key_pos=key_pos, # [num_query, bs, dim]
attn_mask=attn_masks[attn_index], #none
key_padding_mask=key_padding_mask, # [bs, h*w]
**kwargs)
进入一个函数,挺复杂的,但原理应该和通道注意力差不多。想仔细看的话在:/home/用户/.conda/envs/open-mmlab2/lib/python3.7/site-packages/torch/nn/functional.py文件夹的multi_head_attention_forward函数里
- q:[100,1,256]-[100,8,256/8]-[8,100,32]
- k:[hw,1,256]-[hw,1,256/8]-[8,h*w,32]
- k:[hw,1,256]-[hw,1,256/8]-[8,h*w,32]
- 进行公式的自注意力操作
# 这只是为了方便理解,我截取的公式那部分代码,不是完整的,原理就是这样
attn_output_weights = torch.bmm(q, k.transpose(1, 2)) #[8,100,32]@[8,32,h*w] = [8,100,h*w]
attn_output_weights = softmax( # softmax
attn_output_weights, dim=-1)
attn_output_weights = dropout(attn_output_weights, p=dropout_p, training=training) # dropout
attn_output = torch.bmm(attn_output_weights, v) #[8,100,h*w]@[8,h*w,32] = [8,100,32]
# 最后转换维度展平成[100,1,256]
# 后面还要经过个线性层,计算y = xA^T + b
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)