数栈技术大牛分享:云原生大数据系统架构的实践和思考
ArchSummit2021年全球架构师峰会于4月25日-26日在上海举办,袋鼠云运维开发技术专家沙章利(花名:浣熊)应邀出席此次峰会,并在4月26日下午的《弹性架构实践》专题会场上为大家带来《弹性云原生大数据系统架构实践》的演讲。本次演讲主要介绍袋鼠云基于数栈、结合数年大数据基础设施建设经验,打造云环境下的大数据基础设施的实践和案例,部分架构细节首次对外公布,以下内容整理自本次架构峰会。
大家好,我是来自袋鼠云的浣熊,感谢这次会议的讲师们给我们带来了云原生技术应用的分享,感觉又打开了几个新脉门,解锁了新的武魂。在接下来的分享中,希望大家跟着我们的实践案例做一些探索性的思考。
首先我们快速回顾下大数据技术的发展,然后重点给大家分享我们最近几年做的一些系统云化架构,最后再做个回归总结,希望能给大家带去有价值的思考。
大数据技术的发展
大数据技术的发展史也是大数据架构的发展史。

云原生大数据技术是否是新一代大数据处理技术?
1964年,IBM发布了System360,这是计算机发展史上的里程碑事件,System360上配备的磁盘驱动器(DASD)加速了数据库管理系统(DBMS)和关系型数据库的发展,DBMS和关系型数据库的出现使数据处理的效率大大提升,一些规模较大的银行、航空公司开始引入数据库软件处理业务数据,这可以追溯为第一代(大)数据处理技术。
随着全球经济的快速发展,需要处理的数据量也越来越大,单处理架构已经无法满足数据处理需求,有问题就有解决方案,针对这个问题美国Teradata公司推出了并行计算的架构,就是我们今天常说的MPP架构,在MPP架构的技术基础上,Teradata的数据仓库建设技术不断发展,在与当时的巨头IBM的激烈竞争之下,Teradata依托沃尔玛建设了当时世界上最大规模的数仓。这一代技术的关键词我们总结为MPP+数据仓库。
Hadoop生态的出现多少有点意外(眼前一亮),Hadoop、HDFS及其开源生态圈可以使用更低廉的X86机器,通过快速横向扩容的方式就能满足PB级别数据处理的需求。十多年的时间,从Hadoop(MapReduce)到Spark、Flink等,开源生态的计算框架不断演进,基于内存的Spark、Flink计算架构已经与具体的存储解耦,奠定了开源生态大数据系统计算与存储分离架构的基础,我们把开源生态这一系列看作是新一代大数据技术。
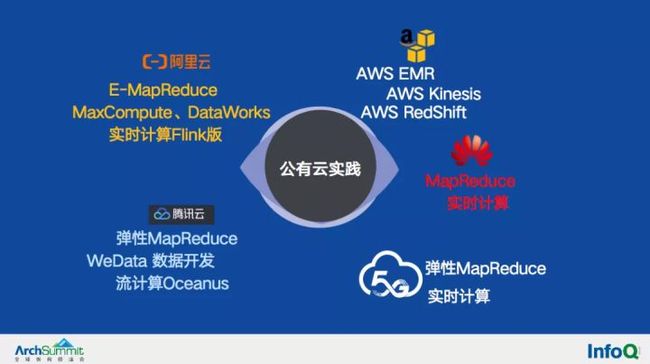
在云计算红利的推动下,大数据系统上云是必然的趋势,Teradata在2016年把自己的数据仓库搬到了公有云上,AWS也在2014年上架了数据仓库型产品Redshift,阿里云上的MaxCompute(早期叫ODPS)是国内云上高性能并行大数据处理技术的里程碑。
去年9月份Snowflake的上市,把云原生数据仓库的话题推上了风口,公有云厂商开始从自家云产品的角度做出对云原生数据库、数据仓库、大数据平台等的解答。相比较前几代大数据处理技术,云原生大数据处理技术是否能称为新一代大数据处理技术呢?带着这个问题,我们来看下在大数据系统云化方面我们的一些架构实践。
大数据系统云化实践
公有云上的大数据产品已经发展成熟,由于社区发展成熟、技术自主可控等特点,开源生态大数据体系已经在国内外头部公有云平台上先后上架,各家公有云厂商配套上架了成熟的数据开发套件。
经过了数年大大小小生产级实践检验,直接选型公有云大数据产品,即可享受按需创建、秒级弹扩、运维托管和海量的大数据处理能力。然而由于种种限制,一些传统大型企业、金融行业等的核心业务并没有到公有云上。各行业在追求云计算红利的进程中,又希望把更多的业务系统上云。在这种冲突下,私有云和混合云得到不断发展,这类云上的产品形态也日渐丰富,已经由早期的ECS自由逐渐发展成中间件自由。
大数据时代,大数据处理和分析是企业的共性需求,以批处理和流处理为代表的数据处理平台逐渐下沉为企业的大数据基础设施,若能实现大数据基础设施自由,即实现大数系统的按需创建、按需扩缩、运维托管,即可为企业内和行业客户提供快速可复制的大数据处理能力。
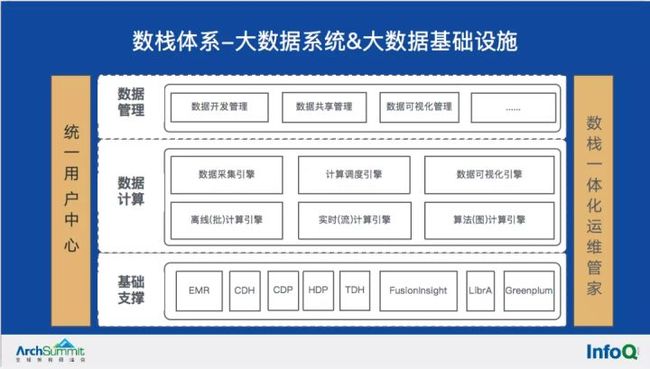
开源大数据处理系统以复杂著称,以数栈为例,底层的存算层兼容主流的Hadoop发行版,中间的的计算层可开放集成主流的批流、算法、图计算框架,既支持传统的MapReduce计算框架,也支持存算解耦的内存计算框架,上层应用层建立在数据共享、数据资产管理、数据可视化管理等核心数据应用之上。
在VM/PM环境下,部署和运维这样一套大数据基础设施系统,也不是一件容易的事情,早期需要我们1-2名中高级实施工程师,连续1-2周时间,才能完成这样一套系统的部署和调试。如何实现整套系统的云上自动化交付,成为我们系统云化架构的第一个目标,即实现大数系统的云上体验、按需创建。
1、第一套云化架构
第一目标达成关键是云化部署架构和自动化部署技术。
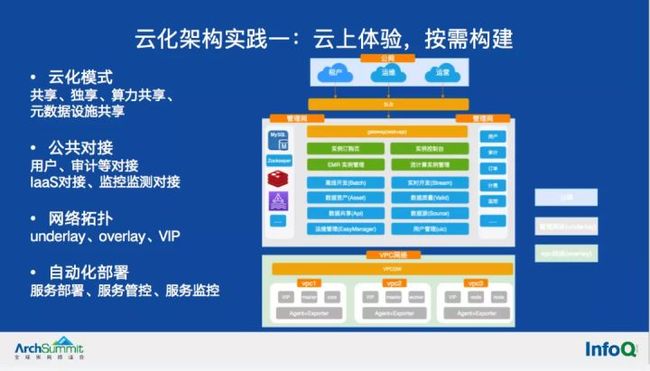
1)首先要考量的是云化模式,模式的不同如共享模式、独享模式等,将直接影响云化部署架构。
共享模式下一般以多租户的方式支持,一个机构共享一套基础设施,套内共享存储、计算和数据应用,资源之间以多租户的方式进行逻辑隔离,共享模式的优点是部署简单,缺点是租户间资源会相互抢占。
独享模式的隔离性会更好,但是按需创建的自动化部署技术是个难点。
2)第二个要考量的是公共系统对接,例如对接IaaS获取动态IaaS资源,对接用户、升级、监控、计费等公共模块,这部分不多说。
3)第三要考虑云环境下的网络环境,比如管理网(underlay)和VPC(overlay)网络划分情况,网络访问策略在制定部署架构前需要清晰。
4)最后也是最重要的,在环境准备好之后,如何高效的完成系统的自动化部署、服务发现、健康检查、监控数据接入等就比较关键了。
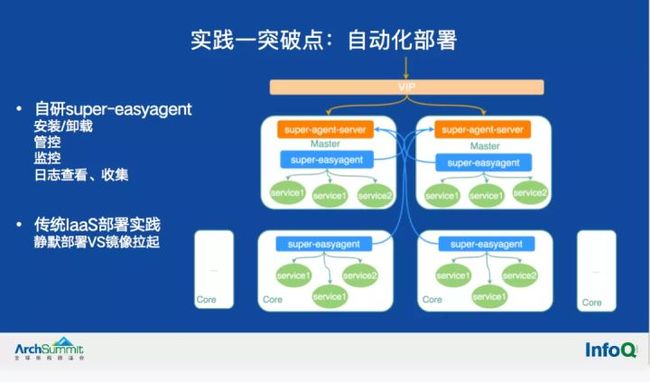
为完成系统的自动化部署和监控运维,从2018年开始,我们自研了部署运维管家EasyManager(以下简称EM),EM的核心能力之一是实现对资源的管理和服务的编排、管控。
把EM的Agent和服务编排模版打进系统镜像是自动化部署的最佳实践,VM启动的过程就是服务启动的过程,服务启动后自动注册至EM-Agent-Server,上层管理网络通过Agent-Server以服务的粒度实现对系统服务的管控,同时基于自动的服务发现机制,配套实施监控数据自动采集汇总、供查。

系统自动部署起来后,在独享模式下,为实现动态集群(实例系统)的访问,我们引入Traefik来解决动态代理问题,Traefik是一个不错的免开候选,Traefik支持从Zookeeper、Redis等配置中心动态加载路由配置,自动化部署模块拿到集群(实例系统)地址信息后写入配置中心,Traefik热加载配置并根据路由规则进行请求转发。结合Traefik动态路由的能力,访问请求可以通过统一的IP或域名进入,经由Traefik根据全局唯一的集群(实例系统)ID进行请求转发。

解决了以上几个关键问题之后,第一目标基本可以达成,配套上订购(创建)页、实例控制台,就完成了大数系统云化架构的第一个实践探索。这个实践的结果是可以实现5-10分钟快速创建一套独享的(云化)大数据系统,且支持在线扩容,基本实现了上云体验、按需创建的系统云化目标。
这套云化架构没有动业务系统本身的架构,容易落地是优点。当然缺点也很明显,首先不是标准化的云化方案,各个依赖系统如IaaS的对接需要根据具体云化环境定制,改造成本高;其次系统上云后的弹性能力并没有得到提升,勉强可以在线扩容,无法实现闲时缩容。基于这两个缺点的考虑,我们尝试了第二个云化架构。
2、第二套云化架构
为实现IaaS层对接标准化,我们做了系统的容器化改造和Kubernetes部署对接,并自研了无状态应用和有状态应用部署Operator。在系统组件全面容器化的基础上,结合一套自定义的Schema,构建面向Kubernetes的制品包,这个制品包可以通过EM一键部署到Kubernetes集群。
为实现系统弹性能力的提升,依托开源社区计算框架对Kubernetes的适配,我们做了产品层的封装,实现了把Spark和Flink的计算任务提交到Kubernetes执行。利用Kubernetes强大的资源管理能力,实现计算资源的弹性扩缩。
这套架构的另一个特点是兼容On Yarn模式,这个点很受企业的欢迎,原因是即能拥抱Kubernetes大法,又能继续使用已有的Hadoop基础设施进行生产,兼容并蓄,领导开心。

这套云化架构可以解决上一套遗留的问题,通过集成Kubernetes,实现对底层IaaS资源对接的标准化,同时提升了计算资源的扩缩能力,理论上是秒级的。当然也产生了新的问题:
- 计算任务提交至Kubernetes后,计算资源的弹性得到保障,但同时计算真正意义上的远离了数据,这对计算性能是否有不良影响?
- 计算的弹性解决了,那存储的弹性怎么办?
第二套云化架构上,架构调整的角度已经从部署架构转移到系统架构层面,我们开始调整系统的计算架构,即用Kubernetes代替Yarn作为计算资源管理者,这是在面向云环境做系统架构适配。
在我们进一步考虑存储架构调整的时候,我们重新审视系统云化实践的过程,我们发现我们的实践思路发生了改变,总结下来就是从构建云(云化)到基于云构建的思路转变。大数据系统的弹性能力也是数据的处理能力,从弹性的诉求出发 ,利用云化或者云原生技术统一管理资源池,实现大数系统产品、计算、存储资源池化,实现全局化、集约化的调度资源, 从而实现降本增效。
我们再回到大数系统云化架构上,产品和计算资源已经可以通过Kubernetes实现资源池化管理,考虑云化环境下实现存储能力的弹性诉求,依托计算框架对底层存储的解耦合,参考对象存储在公有云上的实践经验,我们把底层存储切换成分布式对象存储,这个架构选型上主要考量以下三点:
- 在私有云环境下,基于OpenStack、Swift、Ceph这些可以提供对象存储服务的开源软件架构已经在生产实践了多年;
- 开源生态的计算框架兼容对象存储服务;
- 兼顾数据湖存储选型,然后我们尝试了第三种云化架构。

云原生技术驱动下的大数系统云化架构演进
3、第三套云化架构
为满足存储的弹性和海量存储的需求,我们引入对象存储,为兼容公有云、私有云和现有其他成熟的对象存储服务,同时尽可能提高读写性能,在计算和底层存储之间我们加上一层缓存(选型参考JuiceFS、Alluxio)。其中存储层,在公有云环境上直接选型公有云的对象存储,在私有云环境下选型OpenStack Swift、Ceph、MinIO等成熟的开源方案。
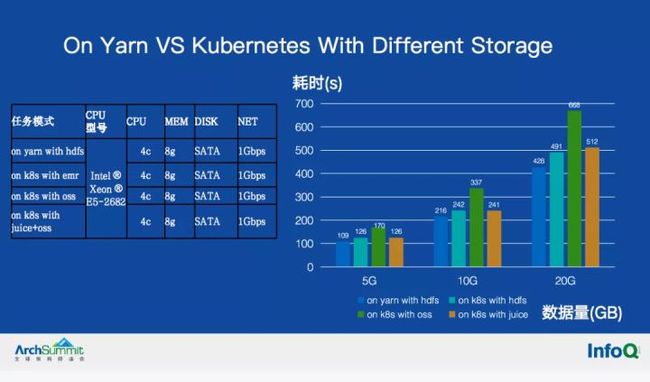
这套架构重点是从存储的角度,尝试改造系统的存储架构,同时兼容现有的HDFS存储,相比之下更适合在动态的云环境中落地,实现应用、计算、存储三层弹性可扩缩。目前这套架构还在内部性能测试中,如下是们其中一组性能测试数据(大文件词频统计),加上性能和缓存优化后的存储性能符合预期。
总结和展望
参考云原生基金会(CNCF)对云原生的定义,“云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用”,从定义上看跟我们大数系统云化的需求不谋而合。
利用容器化、服务网格、微服务、声明式API等云原生技术,实现在公有云、私有云和混合云等云化环境下构建和运行弹性可扩展的大数据系统,这是我们对大数据云原生的理解,也是我们拥抱大数据系统云原生的方式。
今天通过三个具体的大数系统云化架构,给大家呈现一个完整的架构过程,希望能给大家带去思考和帮助。然后我们再回到开头那个问题,云原生大数据技术是否是新一代大数据处理技术,相信大家已经有了自己的答案。
每一代大数据技术基本都是为了解决上一代技术存在的问题,云原生的方法论和技术路线契合了大数据系统云化过程中求弹性、求扩展的诉求,对大数据系统云化具有指导和实践意义。当然云原生不是银弹,只有结合自身业务系统的发展诉求,才能更好的享受其带来的红利。

最后做一点展望,由于种种限制和云化技术积累不均衡(公有云的技术积累大于私有云、混合云)等原因,公有云和私有云混合架构场景有待进一步探索和实践。数据湖和大数据云原生的架构呈现一种架构融合的趋势,我们会在云原生的湖仓一体的新型融合架构上做更多的尝试,谢谢大家。

数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx