一行Pandas代码制作数据分析透视表,太牛了
相信大家都用在Excel当中使用过数据透视表(一种可以对数据动态排布并且分类汇总的表格格式),也体验过它的强大功能,在Pandas模块当中被称作是pivot_table.
今天我就和大家来详细聊聊该函数的主要用途。喜欢记得收藏、点赞、关注。
注:文末提供完整资料和技术交流方式
导入模块和读取数据
那我们第一步仍然是导入模块并且来读取数据,数据集是北美咖啡的销售数据,包括了咖啡的品种、销售的地区、销售的利润和成本、销量以及日期等等
import pandas as pd
def load_data():
return pd.read_csv('coffee_sales.csv', parse_dates=['order_date'])
那小编这里将读取数据封装成了一个自定义的函数,读者也可以根据自己的习惯来进行数据的读取
df = load_data()df.head()
output
通过调用info()函数先来对数据集有一个大致的了解
df.info()
output
<class 'pandas.core.frame.DataFrame'>RangeIndex: 4248 entries, 0 to 4247Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 order_date 4248 non-null datetime64[ns] 1 market 4248 non-null object 2 region 4248 non-null object 3 product_category 4248 non-null object 4 product 4248 non-null object 5 cost 4248 non-null int64 6 inventory 4248 non-null int64 7 net_profit 4248 non-null int64 8 sales 4248 non-null int64 dtypes: datetime64[ns](1), int64(4), object(4)memory usage: 298.8+ KB
初体验
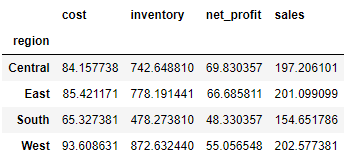
在pivot_table函数当中最重要的四个参数分别是index、values、columns以及aggfunc,其中每个数据透视表都必须要有一个index,例如我们想看每个地区咖啡的销售数据,就将“region”设置为index
df.pivot_table(index='region')
output
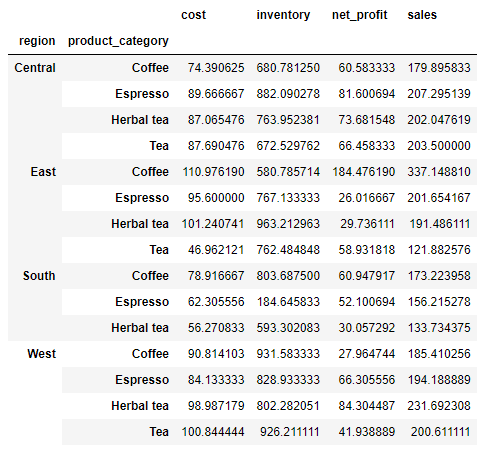
当然我们还可以更加细致一点,查看每个地区中不同咖啡种类的销售数据,因此在索引中我们引用“region”以及“product_category”两个,代码如下
df.pivot_table(index=['region', 'product_category'])
output
进阶的操作
上面的案例当中,我们以地区“region”为索引看到了各项销售指标,当中有成本、库存、净利润以及销量这个4个指标的数据,那要是我们想要单独拎出某一个指标来看的话,代码如下所示
df.pivot_table(index=['region'], values=['sales'])
output

这也就是我们上面提到的values,在上面的案例当中我们就单独拎出了“销量”这一指标,又或者我们想要看一下净利润,代码如下
df.pivot_table(index=['region'], values=['net_profit'])
output

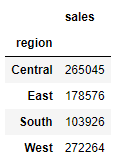
另外我们也提到了aggfunc,可以设置我们对数据聚合时进行的函数操作,通常情况下,默认的都是求平均数,这里我们也可以指定例如去计算总数,
df.pivot_table(index=['region'], values=['sales'], aggfunc='sum')
output
或者我们也可以这么来写
df.pivot_table(index=['region'], values=['sales'], aggfunc={ 'sales': 'sum' })
当然我们要是觉得只有一个聚合函数可能还不够,我们可以多来添加几个
df.pivot_table(index=['region'], values=['sales'], aggfunc=['sum', 'count'])
output

剩下最后的一个关键参数columns类似于之前提到的index用来设置列层次的字段,当然它并不是一个必要的参数,例如
df.pivot_table(index=['region'], values=['sales'], aggfunc='sum', columns=['product_category'])
output
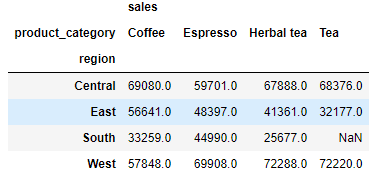
在“列”方向上表示每种咖啡在每个地区的销量总和,要是我们不调用columns参数,而是统一作为index索引的话,代码如下
df.pivot_table(index=['region', 'product_category'], values=['sales'], aggfunc='sum')
output

同时我们看到当中存在着一些缺失值,我们可以选择将这些缺失值替换掉
df.pivot_table(index=['region', 'product_category'], values=['sales'], aggfunc='sum')
output

熟能生巧
我们再来做几组练习,我们除了想要知道销量之外还想知道各个品种的咖啡在每个地区的成本如何,我们在values当中添加“cost”的字段,代码如下
df.pivot_table(index=['region'], values=['sales', 'cost'], aggfunc='sum', columns=['product_category'], fill_value=0)
output
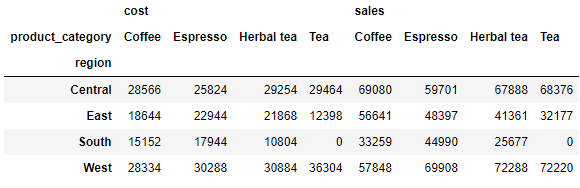
同时我们还能够计算出总量,通过调用margin这个参数
df.pivot_table(index=['region', 'product_category'], values=['sales', 'cost'], aggfunc='sum', fill_value=0, margins=True)
output
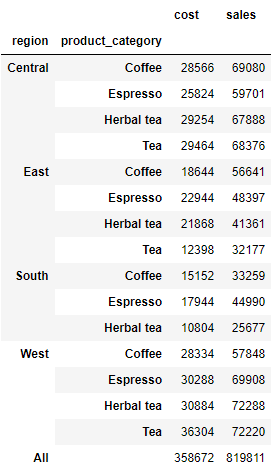
最后的最后,我们调用pivot_table函数来制作一个2010年度咖啡销售的销量年报,代码如下
month_gp = pd.Grouper(key='order_date',freq='M')
cond = df["order_date"].dt.year == 2010
df[cond].pivot_table(index=['region','product_category'],
columns=[month_gp],
values=['sales'],
aggfunc=['sum'])
output

完整代码、技术交流
完整代码已打包,可以按照如下方式找我
目前开通了技术交流群,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
