【Kay】机器学习之XGBoost——鸢尾花数据集
一、基于XGBoost原生接口进行分类
1、导入相关包:
#导相关包
import time
import numpy as np
import xgboost as xgb
from xgboost import plot_importance,plot_tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_boston
import matplotlib
import matplotlib.pyplot as plt
import os
%matplotlib inline2、加载样本数据集并查看数据:
# 加载样本数据集并查看数据
iris = load_iris()
X,y = iris.data,iris.target
X,y①自变量数据:

②因变量数据:
3、训练算法并设置参数
# 训练算法参数设置
params = {
# 通用参数
'booster': 'gbtree', # 使用弱学习器,有两种选择,gbtree(默认)和gblinear,gbtree是基于树模型的提升计算,gblinear是基于线性模型的提升计算
'nthread': 4, # XGBoost运行时的线程数,缺省时是当前系统获得的最大线程数
'silent':0, # 0:表示打印运行时信息,1:表示以缄默方式运行,默认为0
'num_feature':4, '''boosting过程中使用的特征维数'''
'seed': 1000, # 随机数种子
# 任务参数
'objective': 'multi:softmax', # 多分类的softmax,objective用来定义学习任务及相应的损失函数
'num_class': 3, '''类别总数'''
# 提升参数
'gamma': 0.1, # 叶子节点进行划分时需要损失函数减少的最小值
'max_depth': 6, '''树的最大深度,缺省值为6,可设置其他值'''
'lambda': 2, # 正则化权重
'subsample': 0.7, '''训练样本占总样本的比例,用于防止过拟合'''
'colsample_bytree': 0.7, # 建立树时对特征进行采样的比例
'min_child_weight': 3, # 叶子节点继续划分的最小的样本权重和
'eta': 0.1, # 加法模型中使用的收缩步长
}
params_lst = list(params.items())4、转换数据集格式为Dmatrix
# 数据集格式转换
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test)5、训练模型(利用xgb.train())
# num_rounds参数是迭代次数,对于分类问题,每个类别的迭代次数,所以总的基学习器的个数 = 迭代次数*类别个数
num_rounds = 50
model = xgb.train(params_lst, dtrain, num_rounds) # xgboost模型训练6、利用model.predict()进行预测,并查看准确率
# 对测试集进行预测
y_pred = model.predict(dtest)
y_pred![]()
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))![]()
7、显示重要特征,可视化树的生成情况
# 显示重要特征
plot_importance(model)
plt.show()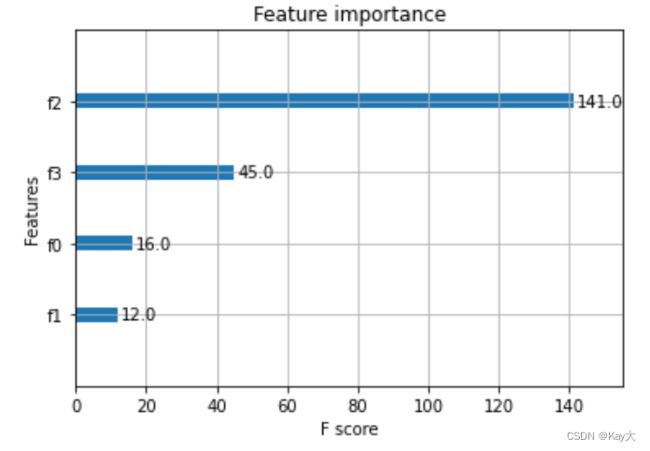
# 可视化树的生成情况,num_trees是树的索引
plot_tree(model, num_trees=5) 
8、将基学习器输出到txt文件
# 将基学习器输出到txt文件中
model.dump_model("model1.txt")二、基于SKlearn接口进行分类
1、加载数据集,划分训练集,测试集
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
# 获取特征名称
feature_name = iris.feature_names
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=3)2、利用xbg.XGBClassifier()训练模型
# 模型训练
model = xgb.XGBClassifier(max_depth=5, n_estimators=50, silent=True, objective='multi:softmax',feature_names=feature_name)
model.fit(X_train, y_train)
3、做出预测
# 预测
y_pred = model.predict(X_test)
y_pred![]()
4、计算准确率
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))![]()
5、显示特征重要性并可视化树
# 显示重要特征
plot_importance(model) 
# 可视化树的生成情况,num_trees是树的索引
plot_tree(model, num_trees=5)