k8s 详解 pod 生命周期 容器探测(live and ready) 钩子函数 pod的重启策略
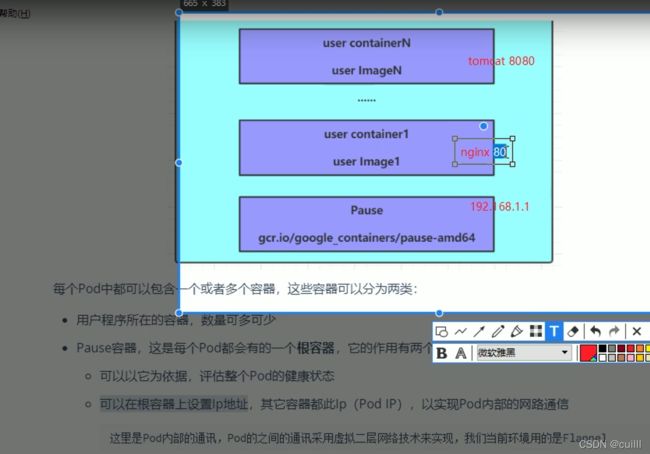
pause 容器,
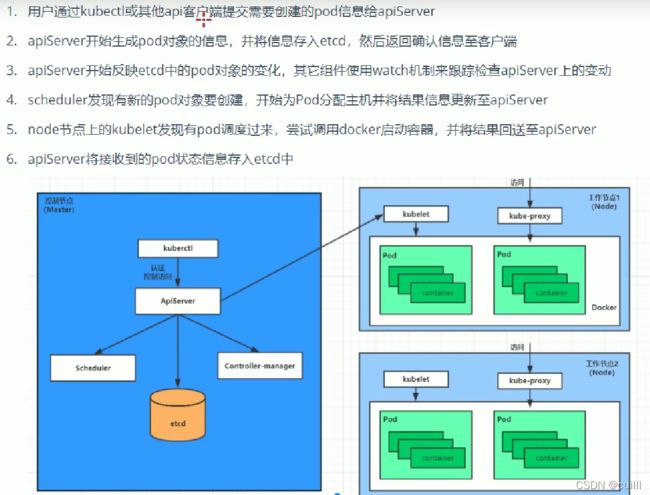
每个pod的都有的根容器,评估pod 的健康状态,设置ip地址,ip+端口可以访问到指定的容器
pod pod 之间采用 flannel 通信
pod 定义 yaml 资源清单
一级 二级 三级 属性
explain pod

一级属性

二级属性 点出来
三级属性,继续点
kubectl explain pod.metadata.managerFields
![]()

status 状态,k8s 自动生成,
spec 描述 ,当前资源的各种各样详细的描述,pod 中有哪些容器,属性怎么ya


nodeName: 当前pod 调度到哪个节点上
nodeSelector: 也是把pod 调度到node上
-o wide,显示ip是pod的ip

hostNetwork: 一般不用宿主机网络,造成同一个pod 内 容器端口冲突
volumes:当前pod 东西存储的地方 ,mount 一个地方
restartpolicy:pod运行出现问题 是重启 还是 重建 还是 怎么着
explain
pod设置


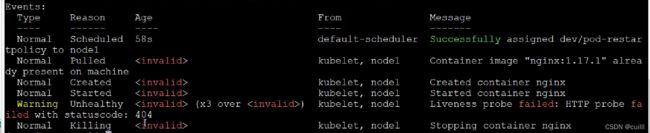
排查错误
describe pod(s) s可加不加 podName ,看events属性
一个pod里面,定义多个容器
镜像拉取策略,使用远程的镜像,还是使用本地

tag具体版本号,latest-总是辣最新的
command 定义容器启动之后,执行的命令
args 定义容器启动之后,执行的参数
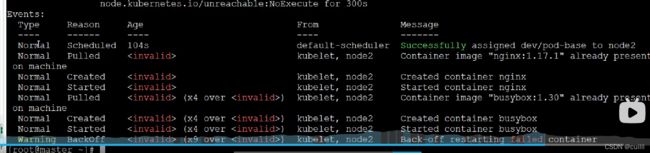
ready 1/2 意思是pod 中有两个容器,但是只有一个正常运行
busybox会自动关闭,所以呢,容器启动之后,执行命令 不让它自动关闭
启动命令
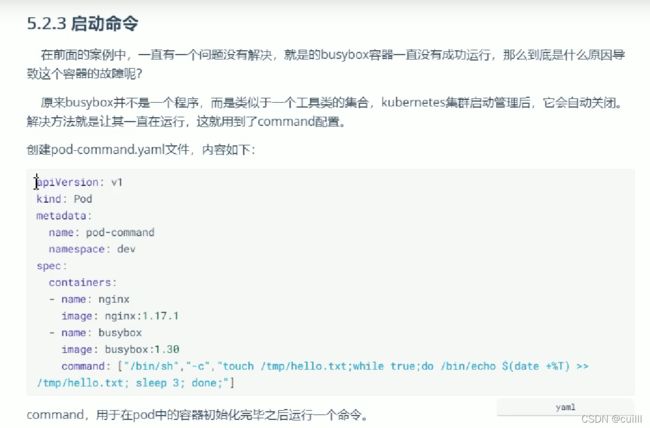
command 容器启动命令

进入到pod中的容器 exec podName -n NS -it 交互方式 -c 容器名称 /执行的命令

pod 环境变量 键值对
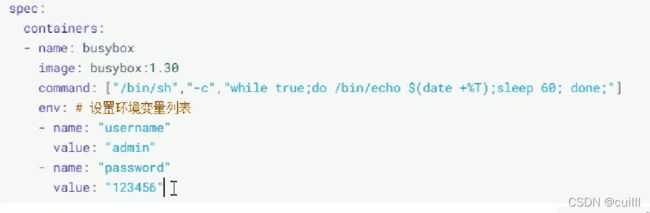
进入到容器 echo $username ,echo $password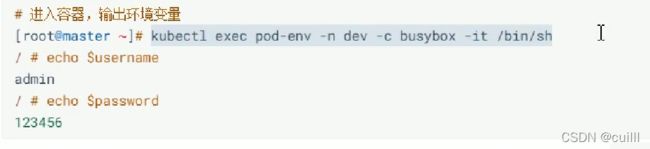
ports 端口
容器暴露的端口列表

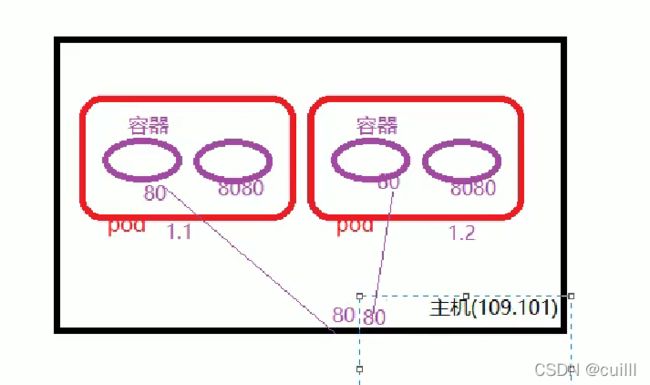
端口冲突 ,该怎么解决?

访问容器中的程序 podIp+容器端口,这样就可以访问容器中的程序了]
资源配额-resouces,资源限制和资源请求设置
pod 中有容器 a b c, 如果a 突然 发飙,吃掉大量的内存, bc 肯定会受到牵连
为了防止出现这样的情况,资源配额
规定 a只能用500M内存

limits 上限,限定容器运行的最大占用资源
requests: 下限 最小的资源
最少10m ,改成最少10g,重建容器,发现容器是pending 状态, 虚拟机肯定没有10g的内存

describe 看一下,insufficient memory

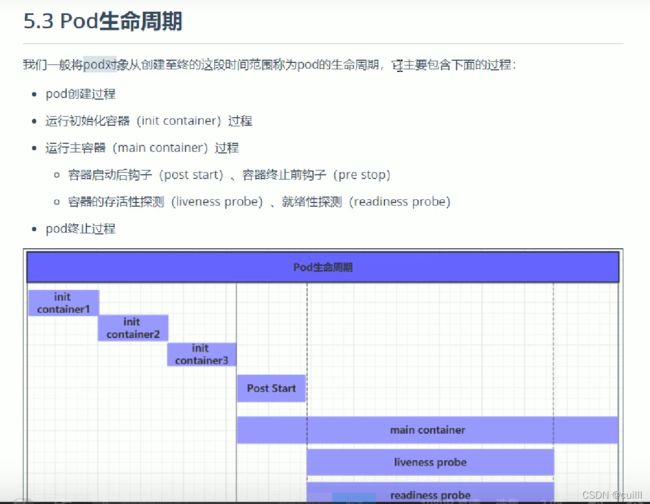
pod 生命周期
创建到销毁的全过程
创建 初始化容器 运行主容器 终止过程
钩子函数
liveness probe 存活性探测
readness probe 就绪性探测


五中状态
pending 挂起,running 运行中,succeded 成功终止不会重启,failed 失败,unkonwn 未知状态

删除pod ,会被打上 terminating 标记
初始化容器

初始化容器必须成功,且按照顺序依次执行 (串行启动)
工具程序,自定义代码,执行依赖检测
实验 Nginx运行之前,需要先能连接上mysql

containers和initContainers是平级的 数组
kubectl get pod podName -w 动态监听
钩子函数

预留的点 允许用户定义一些代码,当pod 运行到这些点的时候,会去代用钩子代码,自定义扩展功能
容器启动后钩子 preStart
容器终止后钩子 postStart


不知道命令该怎么写,都有哪些内容

容器探测
是否正常工作,业务保障 问题实例,剔除
找出出了问题的pod,移除掉
健康的pod ,才可以提供服务
存活性检测 liveness-是否正常运行,启动成功了吗
就绪性检测 readyness-启动成之后,是否可用接收请求,是否准备了接收请求?

要不要重启容器-liveness probe
要不要接收流量-readyness probe
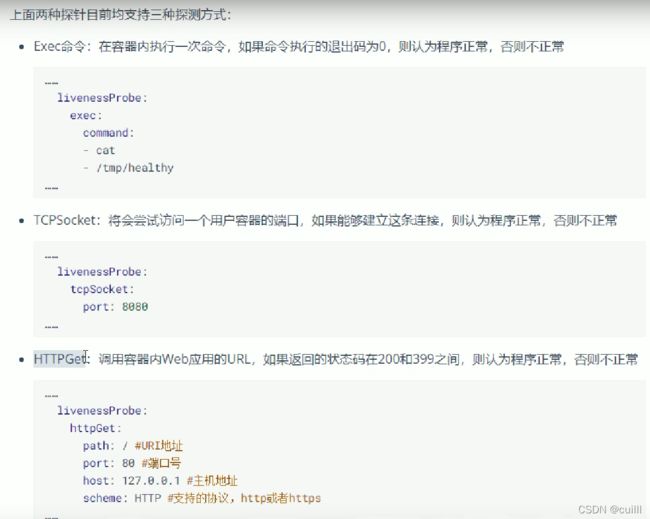
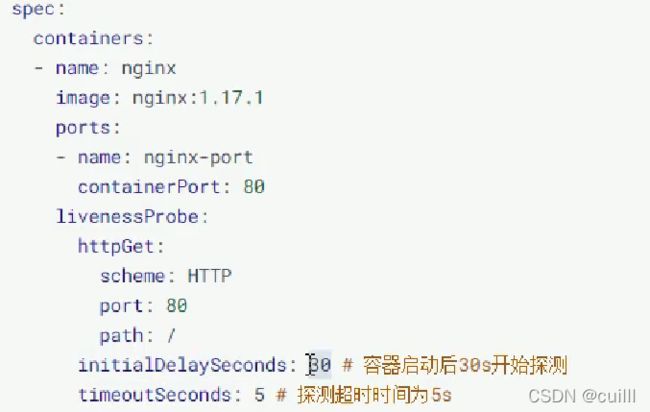
存活性探针


容器探针 补充

启动后什么时候开始探测
探测超时时间 频率 成功 失败 ?
pod重启策略
容器探测出现问题,对pod 进行重启

exitCode 不为0
重启延迟,10 20 40 ..300s
容器探测配合启动策略

-w 动态监听