内存 解决k8s集群环境内存不足导致容器被kill问题
最近线上环境上出现了一个问题, k8s集群环境Pod中的tomcat容器运行一段时间后直接被killd,但有时一切看起来正常,不能准确判断在什么时机出现被Killd问题。
本文就此问题介绍了Linux内存不足原因以及为什么特定进程会被杀死。并提供了Kubernetes集群环境故障排除指南教程。
tomcat进程被杀死原因分析
当这个应用程序被kill问题进行故障排除时,很大程度上确定是操作系统杀死的, 因为整个过程确认没有进行kill操作。当我查看tomcat日志时发现,tomcat只是简单的提示了killd, 至于原因, 日志中没有给出详尽的提示。紧接着我查看了syslog日志grep -i kill /var/log/messages*, syslog给出比较详细的提示, 大概意思是该应用占用内存超过cgroup限制, 直接被Kill。如下所示:
Oct 1 20:37:21 k8swork kernel: Memory cgroup out of memory: Kill process 13547 (java) score 1273 or sacrifice child如果当服务已经挂掉, 使用free查看内存占用, 对我们排除问题不会有太大帮助, 因为这个时候服务占用内存已经随着服务的挂掉而释放。如下所示:
[root@k8swork log]# free -lm
total used free shared buffers cached
Mem: 498 93 405 0 15 32
Low: 498 93 405
High: 0 0 0
-/+ buffers/cache: 44 453
Swap: 1023 0 1023但是Linux vmstat可以使用以下命令将的输出重定向到文件。我们甚至可以调整持续时间和次数以监控更长的时间。当命令运行时,我们可以随时查看输出文件以查看结果。我们每120秒查看内存1000次。该&行末尾的允许我们将其作为一个进程运行并重新获得终端。
vmstat -SM 120 1000 > memoryuse.out &通过如上信息可以判定罪魁祸首是这个Java进程占用内存超过资源限制, 直接被系统杀死。为什么会出现这个问题呢?
首先第一点,已经在编排文件中限制资源最大使用量为4G,理论上Pod中容器是不可能占用这么多资源, 默认情况下Java占用物理资源的1/4左右, 但是既然出现了这个问题,说明Java进程占用资源超过了这个限制。
于是在网上找到了如下信息,大概意思是说,jdk从131版本之后开始通过选项支持对容器对内存和CPU 的限制,如下图所示:

https://blogs.oracle.com/java-platform-group/java-se-support-for-docker-cpu-and-memory-limits
当我打开131版本更新信息之后,没有看到任何关于容器相关的更新, 于是开始查找之后的版本, 最后找到191版本, 可以看到Java对容器做出了支持。
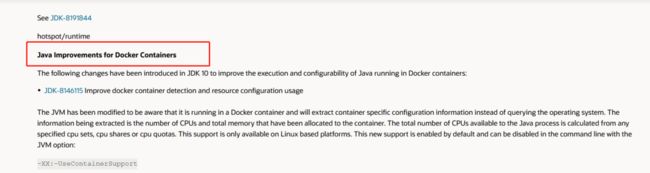
https://www.oracle.com/java/technologies/javase/8u191-relnotes.html
核对了目前出现问题的Java版本, 明显是低于这个版本的, 确定了问题所在。
“Java虚拟机感知不到Pod中资源限制,所以直接占用了宿主机1/4左右内存(宿主机是32G内存), cgroup检测到Pod占用内存超过限制(Pod限制为4G),进行了Kill操作。”
解决方式也很简单,直接在tomcat服务中配置最大最小内存占用, 在Java层面限制其内存占用。但是具体Java进程为什么占用这么高的内存就需要业务开发人员排查解决了。

总结
通过本文可以看出基于Java虚拟机构建项目, 在容器化过程中要尽量适配高版本或者对docker容器有亲和性的Jdk版本, 如果没有, 一定要在虚拟机层面限制Java服务占用内存大小。另外一定要在服务上添加存活探针,如果没有添加存活探针,类似于tomcat这种容器类服务,即使内部服务挂了了, Kubernetes不会自动帮你拉起的,原因很简单,它无法感知到你的服务是否存活。所以服务一定要添加Http存活探针(基于TCP层面的探针只是检测端口是否存活,大多数情况下,服务会出现假死问题,但端口依然可以正常访问)。