2022泰迪杯数据挖掘挑战赛C题思路及赛后总结
第十届“泰迪杯”数据挖掘挑战赛C题,@队友:Pluto_Ct、Be极客菌
今年C题的赛题是“疫情背景下的周边游需求图谱分析”,分析新冠疫情前后旅游业和游客需求发生的变化,题目的目标主要包括:
- 构建针对公众号文章文本分类模型,依据文章内容与文旅的相关性分为“相关”和“不相关”两类;
- 从在线旅游(OTA)和用户生成内容(UGC)数据中提取旅游产品,并按年度进行热度分析和排名;
- 依据OTA和UGC数据,对提取出的旅游产品进行关联分析,找出以景区、酒店、餐饮等为核心的强关联模式,并在此基础上构建本地旅游图谱,进行可视化分析;
- 使用本地旅游图谱作为分析工具,分析新冠疫情前后茂名市旅游产品的变化,并提出建议。
其中,“本地旅游图谱”为赛题给出的概念,在通用知识图谱的基础上加入了更多针对旅游行业的需求。题目数据包括2018年至2021年广东省茂名市的公众号文章、游记攻略和酒店、景区、餐饮评论。
竞赛官网赛题链接:
第十届“泰迪杯”数据挖掘挑战赛 赛题 https://www.tipdm.org:10010/#/competition/1481159137780998144/question
https://www.tipdm.org:10010/#/competition/1481159137780998144/question
目录
1. 问题一:微信公众号文章分类
1.1 问题分析与思路
1.2 数据预处理
1.3 主题词库构建
1.4 伪标注数据准备
1.5 BERT模型训练与预测
1.6 比赛过程中的失败尝试
2. 问题二:周边游产品热度分析
2.1 问题分析与思路
2.2 数据清洗
2.2.1 筛去非茂名旅游产品
2.2.2 过滤游记攻略重复内容
2.2.3 去停用词
2.2.4 繁体文字处理
2.3 词库准备
2.4 基于BiLSTM-CRF和LAC的命名实体识别
2.4.1 基于BiLSTM-CRF的命名实体识别
2.4.2 基于LAC分词工具的命名实体提取
2.4.3 命名实体合并筛选
2.5 基于标志词匹配和TextCNN的命名实体分类
2.6 基于Single-Pass文本聚类和地理编码的实体对齐
2.7 实体编码与回溯
2.8 指标体系建立与热度评价
3. 问题三&问题四:产品关联挖掘和本地旅游图谱构建
3.1 问题分析与思路
3.2 关联模式定义和指标量化
3.3 旅游产品关联图谱构建与分析
3.4 旅游宏观概念图谱构建与分析
3.5 旅游产品分布情况及建议
3.6 旅游产品疫情前后趋势分析及建议
4. 总结与展望
4.1 方案总结
4.2 不足之处与未来展望
4.3 比赛总结与启示
5. 写在最后
1. 问题一:微信公众号文章分类
1.1 问题分析与思路
构建文本分类模型,对附件1提供的微信公众号的推送文章根据其内容与文旅的相关性分为“相关”和“不相关”两类,并将分类结果以表1的形式保存为文件“result1.csv”。与文旅相关性较强的主题有旅游、活动、节庆、特产、交通、酒店、景区、景点、文创、文化、乡村旅游、民宿、假日、假期、游客、采摘、赏花、春游、踏青、康养、公园、滨海游、度假、农家乐、剧本杀、旅行、徒步、工业旅游、线路、自驾游、团队游、攻略、游记、包车、玻璃栈道、游艇、高尔夫、温泉等等。
赛题数据没有标注,全部数据有6000余篇,且题目给出了大量文旅相关的主题词,应当是分类的重要依据,人工打标训练的可行性不高,考虑将关键词扩充后形成词库,然后对文本数据进行特征提取和匹配。
首先,基于题目所给的文旅相关主题词,进行近义词扩充形成主题词库;然后,采用TextRank、TF-IDF分别提取语料关键词,与主题词库进行匹配;同时,采用规则对标题和正文进行直接匹配和判断,共得到3个标签,3个标签一致的伪标注数据用于训练模型。基于中文BERT预训练语言模型训练分类器,用于以上三种方法得到结果不一致时的判别依据。
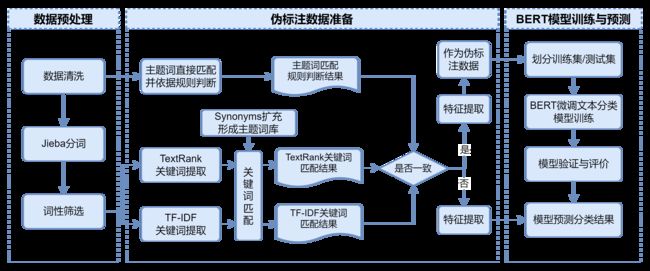 问题一流程图
问题一流程图
1.2 数据预处理
经探索,数据中不存在完全重复的数据,筛去空格和特殊字符后使用jieba进行分词,并筛选保留词性为名词、动词的词语。
1.3 主题词库构建
基于题目所给的文旅相关主题词进行筛选,对于筛选后的每个主题词,使用Synonyms库生成5个同义词,扩充形成文旅相关主题词库,共包括143个主题词。
1.4 伪标注数据准备
采用以下三种方法对文章的文旅相关性进行判断:
- 使用筛选后的原始主题词匹配标题和正文,若标题包含主题词或正文主题词超过20个,则认为其与文旅相关,反之则不相关;
- 使用TextRank算法提取每篇文章前15个关键词,并与主题词库匹配,若匹配到,认为其与文旅相关,反之则不相关;
- 使用TF-IDF算法提取每篇文章前15个关键词,并与主题词库匹配,若匹配到,认为其与文旅相关,反之则不相关。
每篇文章采用以上三种方法共得到3个“是否与文旅相关”的标签,三者一致的认为分类较为准确,作为伪标注数据用于训练模型;不一致的认为分类结果存疑,需要使用训练的模型进行进一步判别。
基于生成的伪标注语料,重新使用TextRank、TF-IDF各提取50个关键词,并将标题分词筛选词性后加入到关键词中与标题结合去重后作为模型输入。
1.5 BERT模型训练与预测
基于中文BERT预训练语言模型训练分类器,模型在训练集上的准确率达到98.23%,在测试集上准确率为96.57%,用训练的模型对结果存疑的文章进行分类。合并结果,保存到result1.csv。
1.6 比赛过程中的失败尝试
前期在示例数据上尝试了LDA和单纯规则匹配等方法,由于数据量太小,LDA在示例数据上并不能分出文旅相关的主题,单纯规则则取得了较好的效果,但全部数据公布后,由于数据源和数据格式比示例数据更加多样,原先建立的规则不再能够完全适应数据。
后期发现了一个仅基于标签就可以对文本进行分类的无监督分类算法LOTClass,但网上参考资料大多面向英文数据,由于时间所限,尝试对于本题中文数据进行的实现没能成功。
2. 问题二:周边游产品热度分析
2.1 问题分析与思路
从附件提供的OTA、UGC数据中提取包括景区、酒店、网红景点、民宿、特色餐饮、乡村旅游、文创等旅游产品的实例和其他有用信息,将提取出的旅游产品和所依托的语料以表2的形式保存为文件“result2-1.csv”。建立旅游产品的多维度热度评价模型,对提取出的旅游产品按年度进行热度分析,并排名。将结果以表3的形式保存为文件“result2-2.csv”。
为充分挖掘旅游发展现状,需要通过游记攻略和景区、酒店、餐饮评论4张数据表中提取旅游产品,并构建热度指标体系,计算每个旅游产品的热度值并按年度进行排名和分析。
 问题分析
问题分析
首先,基于CLUENER细粒度命名实体识别语料库筛选相关实体,采用BiLSTM-CRF训练模型,针对游记攻略、景区评论、酒店评论和餐饮评论4张表进行命名实体识别(NER),并结合LAC分词工具自带的NER功能设计了一套针对旅游产品的命名实体识别筛选和优化方法;其次,基于TextCNN分类模型、Single-Pass聚类算法和地理编码进行实体对齐(同义地名合并),共整合提取到631个有效实体,累计1014种表述方式;然后,建立包括参与热度、反响热度和宣传热度三大方面指标的热度评价体系,并进行指标计算;最后,采用AHP-TOPSIS方法进行指标权重计算和排序,得到最终热度评价结果。
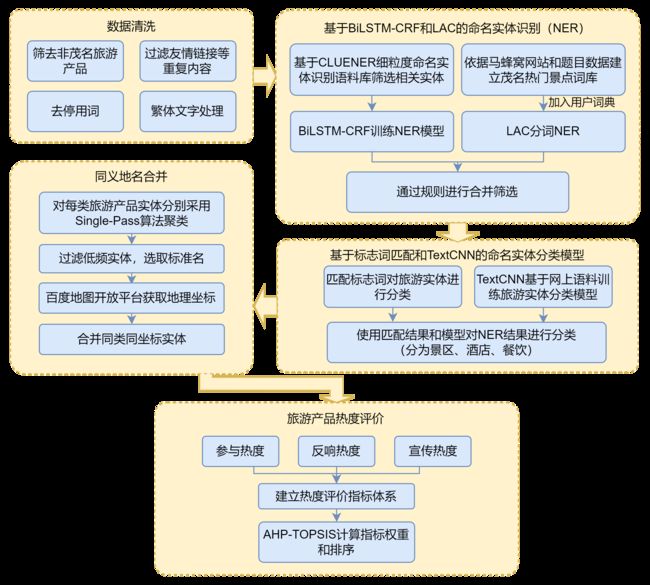 问题二流程图
问题二流程图
2.2 数据清洗
探索数据发现存在一些异常情况,主要从以下方面开展数据清洗。
2.2.1 筛去非茂名旅游产品
景区评论数据中,存在部分不属于茂名的景区评论(“中国南极长城站”位于南极,“广东海洋大学”位于湛江,同时存在较多景区名称为“湛江xxx”的非茂名景区)
清洗方法:景区名称包含“湛江”“广东海洋大学”“南极长城站”的评论,整行删除。
游记攻略中也存在一些不是茂名的景区,但数量较少。
清洗方法: 后期根据数量筛选(少于3篇出现的筛去)。
2.2.2 过滤游记攻略重复内容
游记攻略中存在友情链接等大量重复内容,严重影响产品提取和热度评价效果。
清洗方法:由于结构较为统一,采用正则表达式过滤,删去网址和网址前的标题。
re.sub(r'^.*?\n\d+\-\d+\-\d+.*?\nhttp.*?\n|\n.*?\d+\-\d+\-\d+.*?\nhttp.*?\n|\d+\-\d+\-\d+.*?\nhttp.*?\n| ', '', x)
2.2.3 去停用词
基于四川大学机器智能实验室停用词库,结合本题应用场景进行补充。
2.2.4 繁体文字处理
由于数据存在部分繁体内容,可能影响后期判断,使用OpenCC库将繁体内容转换为简体。
2.3 词库准备
从马蜂窝网站爬取茂名主要热门旅游景点(去重处理后共200条);结合题目景区评论表中的景区名称(如果与马蜂窝网站景点存在重合,取其中较长的作为标准名);最终形成“茂名旅游景点词库”,并加入LAC分词工具的用户词典,用于提升针对茂名的分词和旅游产品识别效果。
基于部分餐饮、景区、酒店名称的结构特征,形成“分类特征词库”,用于提升命名实体分类的准确性。
2.4 基于BiLSTM-CRF和LAC的命名实体识别
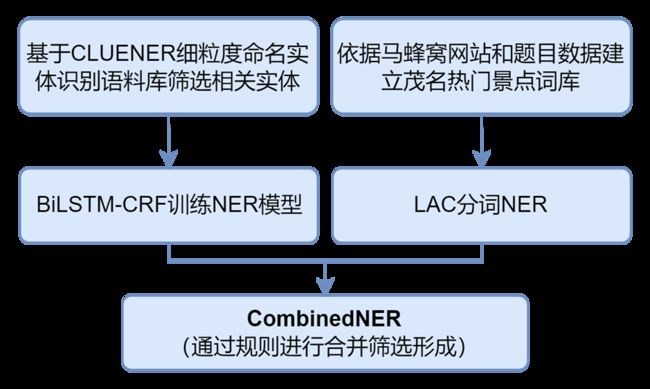 基于BiLSTM-CRF和LAC的命名实体识别
基于BiLSTM-CRF和LAC的命名实体识别
2.4.1 基于BiLSTM-CRF的命名实体识别
基于CLUENER细粒度命名实体识别语料库,筛选其中“旅游”“地址”类别标注实体,训练针对旅游领域的NER模型,并使用训练的模型对题目数据进行命名实体识别。
2.4.2 基于LAC分词工具的命名实体提取
开源的百度LAC分词工具具备一定的命名实体识别功能,筛选其中分词词性为LOC、ORG的词语,作为命名实体提取结果。
2.4.3 命名实体合并筛选
上述两种命名实体识别方式各有优劣,主要体现在:
(1)训练得到的NER模型针对旅游领域,能够发现更多旅游领域的实体;但结果存在较多无效内容和词语不完整的情况,需要进行清洗筛选;
(2)百度LAC本身就是分词工具,对上下文和全篇的考虑更为充分,提取到的实体更干净、结构更完整;但LAC对文旅行业的针对性不强,存在一些提取不到的情况;
由于两者都有另一种方法没有识别到的旅游产品,因此通过一定规则进行结合形成“CombinedNER”。
具体流程如下:
1. 增加停用词:政府、协会、广东省、茂名市;
2. 两者指代重合,选用lac的NER结果;
3. 模型NER结果过滤方法:
(1)长度筛选:长度大于2;
(2)对模型训练得到的结果进行lac词性标注,如果仅包含一个词且为普通词,或a/v/u等词性结尾,认为是普通词或结构不完整,去除;
(3)对照lac分词判断模型训练得到的结果是否存在词语截断,存在则去除,如:'困粤西山村', '村农村';
(4)仅包含字母数字去除;
(5)包含特殊符号过滤(re.sub);
(6)包含“省”&“市”认为是在讲解地理位置,去除;
(7)包含“的”,认为不是旅游产品实体名,去除;
(8)3-5字且以“省”“市”“区”“县”“委”结尾或为倒数第二字,认为不是我们需要的旅游产品实体,去除;
(9)3-4字且以“路”“站”“镇”结尾,认为不是我们需要的旅游产品实体,去除;
(10)“人大”“集团”“公司”“高速”等词语结尾,认为不是我们需要的旅游产品实体,去除。
2.5 基于标志词匹配和TextCNN的命名实体分类
为避免将不同类别实体聚为一类,同时为第三问准备,将命名实体分为餐饮、景区、酒店三类。
命名实体分类:标志词匹配+TextCNN
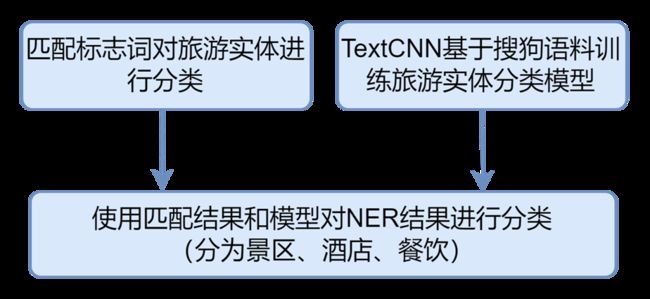 基于标志词匹配和TextCNN的命名实体分类
基于标志词匹配和TextCNN的命名实体分类
(1)首先基于“分类特征词库”对能够直接确定为餐饮/景区/酒店的特征词(如:餐厅、面馆、菜馆属于餐饮,博物馆、游乐园属于景区,旅馆、民宿、公寓属于酒店)进行匹配,匹配到则认为属于该类;
(2)匹配茂名景区词库(全字匹配),提高准确度;
(3)基于网上语料,结合题目数据中的评论对象构建训练语料库,共包含23571条景区、餐饮、酒店名称数据。构建TextCNN模型基于语料库进行训练,模型在训练集上的准确率达到93.74%;使用训练得到的模型对其余实体分类。
2.6 基于Single-Pass文本聚类和地理编码的实体对齐
 基于Single-Pass文本聚类和地理编码的实体对齐
基于Single-Pass文本聚类和地理编码的实体对齐
由于同实体存在不同表述方式、错别字、识别不够完整等情况,在命名实体分类的基础上,按分类对全部实体进行基于文本相似度的聚类。命名实体通常较短,Single-Pass是一种短文本聚类的算法。
命名实体聚类的准备工作和聚类主要流程步骤如下:
(1)Word2Vec训练200维的字向量;
(2)Embedding:将实体的每个字转换为字向量,各字的向量求平均得到整个命名实体词的向量,两个向量的余弦相似度可以衡量这两个命名实体的相似程度;
(3)Single-Pass聚类:对每一个新的命名实体,计算它与已经成组的命名实体词中每个词的余弦相似度,其最大值高于阈值则分入该组;计算完没有满足条件的组则独立成组;
(4)低频实体筛选过滤:对于聚类后整组词频之和少于3条且不包含实体特征词的,认为不位于茂名或识别效果不佳,予以剔除;
(5)标准名选取:首先匹配“茂名景点词库”中包含的实体名作为标准名,其次采用组内数量最多的实体名作为标准名,最后采用长度最大的实体名作为标准名。
由于部分相同实体的不同表述方式并不能完全从文本相似层面体现,采用百度地图API获取经纬度坐标进行进一步的实体对齐,合并同类同坐标实体。
使用百度地图API地点检索功能,在茂名市范围内检索每个实体并获取经纬度坐标。
地点检索 | 百度地图API SDKhttps://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi
对于经纬度坐标相同的实体,认为是同一个实体,进行合并;若补充地理结构多次检索后均不存在,则认为该实体不位于茂名或指代过于宽泛,对其予以剔除。
2.7 实体编码与回溯
最终提取到631个有效实体、1014种表述方式,对实体进行编码,同一实体的不同表述方式共用同一编码;对这些实体回溯来源,累计建立实体和游记评论关联10515篇次(不同实体计为多次、同一篇多次提及同一实体不重复计算),表述和游记评论关联20434篇次(不同表述计为多次、同一篇多次提及同一表述不重复计算)。
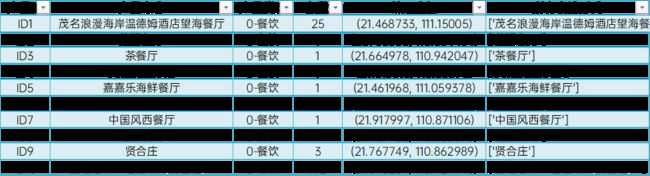 提取到的旅游产品(部分)
提取到的旅游产品(部分)
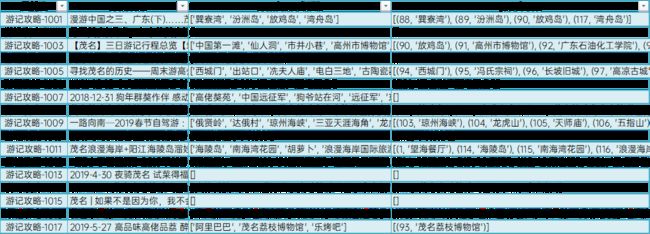 最终NER和产品提取结果(部分)
最终NER和产品提取结果(部分)
最后整理成题目所需格式,保存到result2-1.csv。
将旅游产品根据经纬度坐标绘制到茂名市地图上,如下所示。
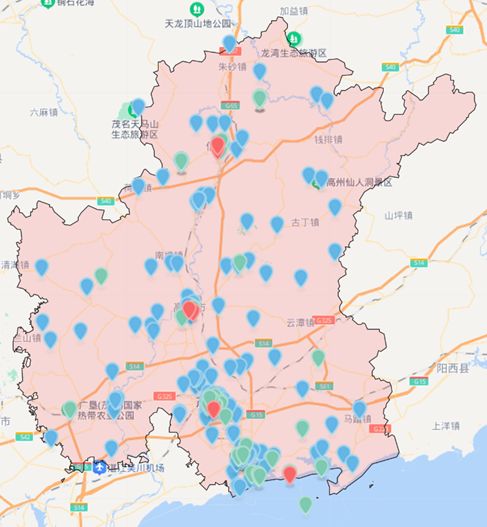 旅游产品分布地图展示
旅游产品分布地图展示
2.8 指标体系建立与热度评价
建立包括参与热度、反响热度和宣传热度三大方面指标的热度评价体系,并进行指标计算;最后,采用AHP-TOPSIS方法进行指标权重计算和排序,得到最终热度评价结果,保存到result2-2.csv。
| 一级指标 |
二级指标 |
量化方法 |
具体计算方法 |
| 参与热度 |
评价次数 |
频数 |
游记、评论4个表格提到的次数加和(游记按出发时间) |
| 活跃天数 |
频数 |
游记、评论4个表格提到的天数加和 |
|
| 周围文旅产品密度 |
百度地图获取经纬度坐标,计算距离 |
与其他旅游产品的距离倒数加和,距离<1km的记为1km |
|
| 反响热度 |
游客印象 |
情感分析 |
对每个评论/游记中描述该旅游产品的部分进行情感分析 |
| 回购热度 |
频数 |
旅游产品提到“下次再来”“住了多次”“第二次来”等回购标识的评论数 |
|
| 宣传热度 |
公众号文章 |
频数 |
公众号文章提到的次数 |
| 游记攻略 |
频数 |
游记攻略中提到的次数(按发布时间) |
3. 问题三&问题四:产品关联挖掘和本地旅游图谱构建
3.1 问题分析与思路
本地旅游图谱构建与分析
依据提供的OTA、UGC数据,对问题2中提取出的旅游产品进行关联分析,找出以景区、酒店、餐饮等为核心的强关联模式,结果以表4的形式保存为文件“result3.csv”。在此基础上构建本地旅游图谱并选择合适方法进行可视化分析。鼓励参赛队挖掘旅游产品间隐含的关联模式并进行解释。
疫情前后旅游产品需求的变化分析
基于历史数据,使用本地旅游图谱作为分析工具,分析新冠疫情前后茂名市旅游产品的变化,并撰写一封不超过2页的信件向该地区旅游主管部门提出旅游行业发展的政策建议。
三四问需要对问题二中提取出的旅游产品进行关联分析,在充分考虑到旅游产品间强关联模式的基础上,从地理位置、评论特征等多维度挖掘产品间隐含关系,并将关联度进行量化。在此基础上进行本地旅游图谱的构建,并在宏观和微观层面进行多视角的可视化呈现与分析。
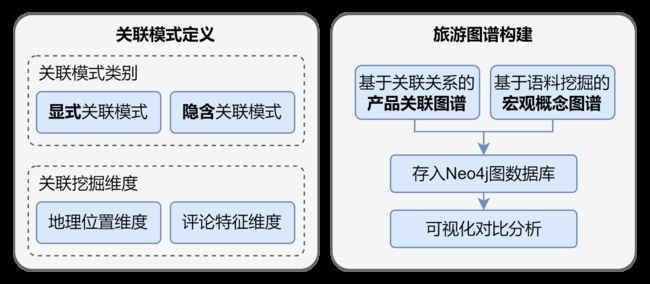 问题三&问题四分析与流程
问题三&问题四分析与流程
首先,在前一阶段的数据准备和实体抽取后进行关联模式定义,对每种关联模式进行量化计算和标准化处理后导出结果并存入Neo4j图数据库中,最后分别从宏观和微观的角度进行可视化分析。
3.2 关联模式定义和指标量化
在前一阶段的数据准备和实体抽取后进行关联模式的定义,根据本地经济发展程度、地理位置等因素定义了八种关联模式,其中包含三种隐含关联模式。
| 关联模式 |
量化方法(标准化前) |
备注 |
| 共现关系 |
A、B出现次数大于等于3时,P(AB)/P(A)+P(AB)/P(B) |
|
| 近邻关系 |
1/地理距离 |
地理距离<500m的记为500m(下同) |
| 辐射关系 |
景区热度/(周围同类产品密度·地理距离^2)^(1/3) |
限景区与酒店/餐饮之间 |
| 竞争关系 |
1/(经济距离·地理距离^2) ^(1/3) |
经济距离=|A餐饮酒店热度-B餐饮酒店热度|,限酒店/餐饮同类之间 |
| 导流关系 |
(A景区热度+B景区热度)/AB景区地理距离 |
限景区之间 |
| 餐饮风格相似* |
名称、标题、评论内容关键词相似度 |
限餐饮之间 |
| 酒店风格相似* |
名称、房型设置、评论内容关键词相似度 |
限酒店之间 |
| 历史文化关联* |
历史文化、高层概念语料中共现次数 |
基于茂名百度百科历史文化、风景名胜构建语料 |
对指标进行量化计算和标准化处理,保存到result3.csv。
3.3 旅游产品关联图谱构建与分析
将旅游产品和关联度存入Neo4j图数据库中,生成疫情前后茂名市旅游产品关联图谱和本地旅游宏观概念图谱。
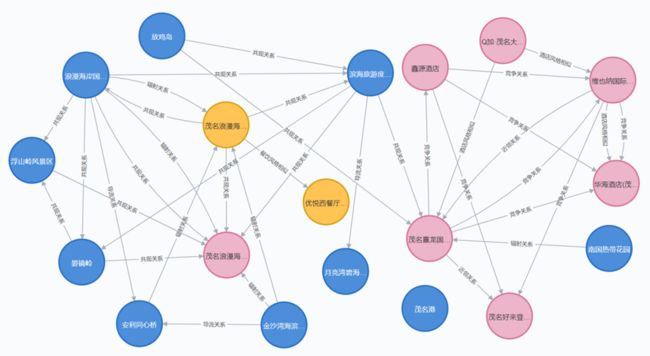 旅游产品间关联(示例)
旅游产品间关联(示例)
蓝色为景区,黄色为餐饮,粉色为酒店。餐饮/酒店风格相似显示关联度前50名的关联,其余每种关联中显示关联度前200名的关联。
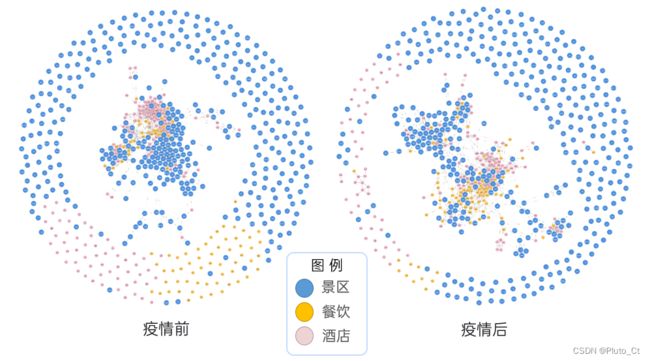 疫情前后旅游产品关联图谱对比
疫情前后旅游产品关联图谱对比
可以看到疫情前景区间的关联相对更为紧密,疫情后景区和餐饮酒店间的关联相对有所增长,旅游倾向从游遍多个景点转向深游少数景点,并更进一步探索周边的餐饮等旅游产品。
3.4 旅游宏观概念图谱构建与分析
由于题目所给的“本地旅游图谱”示例包含许多宏观概念,如“攻略”“住宿”等,并不完全是产品间的关联,同时第四题的分析也需要一些疫情前后宏观旅游市场变化的分析工具,通过定义上层概念并寻找相关热门旅游产品和评论中的高频词语,构建旅游宏观概念图谱。
每类旅游产品展示热度最高的5个产品、词频最大的8个关键词;游记攻略,展示词频最大的10个关键词,同时将历史文化、高层概念等关联绘制在图谱上。
 疫情前后旅游宏观概念图谱对比
疫情前后旅游宏观概念图谱对比
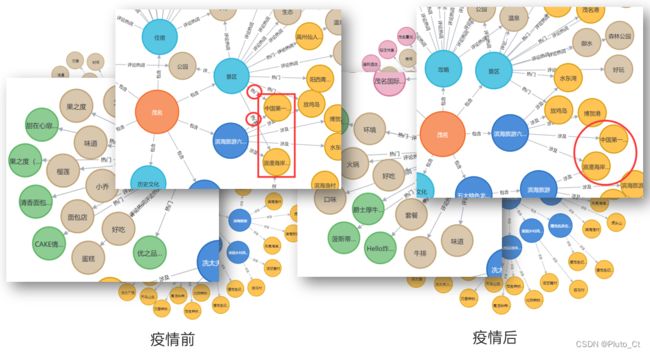 疫情前后旅游宏观概念图谱细节对比
疫情前后旅游宏观概念图谱细节对比
分析旅游宏观概念图谱可知浪漫海岸等滨海旅游景区受疫情冲击较大,热门程度有所下降;餐饮口味需求和热点产品发生变化;对于服务的相关评价也有一定变化。
3.5 旅游产品分布情况及建议
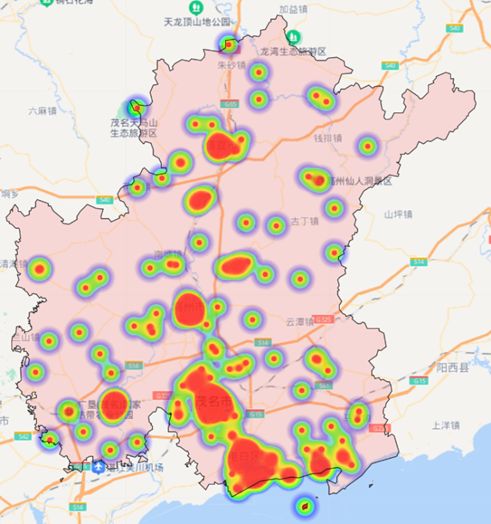 茂名旅游产品热度分布展示
茂名旅游产品热度分布展示
茂名热门景区较多集中在海岸,但同时滨海景点既是茂名的热门标志性景区,也是受疫情冲击影响最大的景区类型之一;
在疫情常态化背景下,茂名旅游业可考虑在支持滨海景区运营的基础上,加大力度发展其他结合历史文化和乡村特色的新兴旅游景点,建立旅游行业新的“增长极“。
3.6 旅游产品疫情前后趋势分析及建议
基于产品关联模式、目的地热度和评论热词变化进行对比分析,提出以下建议:
- 旅游倾向从“久游饱览式”过渡到“深挖全面式”,茂名旅游业可着力打造短线旅游市场,推出新玩法、新体验的短线产品,吸引更多周边游客;
- 疫情冲击使得本地游客占旅游市场的比重大幅上升,可以增加本地广告宣传投入,丰富旅游产品形式,为市民提供更多高品质的“家门口好去处” ;
- 可结合茂名市地理特色、文化底蕴进行线上引流,设计全场景全流程的配套软件服务拉动消费。
4. 总结与展望
4.1 方案总结
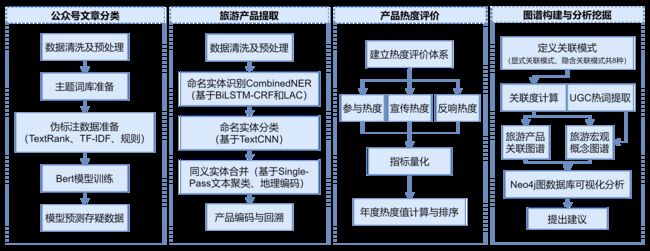 挖掘总流程图
挖掘总流程图
一、微信公众号文章分类:首先基于赛题所给的文旅相关主题词筛选并进行近义词扩充,形成主题词库;然后,采用TextRank、TF-IDF分别提取语料关键词,与主题词库进行匹配,同时建立一定规则对标题和正文进行直接匹配,共得到3个标签,3个标签一致的作为伪标注数据用于训练模型;最后,基于中文Bert预训练语言模型训练分类器,作为以上三种方法得到结果不一致时的判别依据;达到了较好的公众号文章分类效果。
二、旅游产品提取和热度分析:首先,基于CLUENER 细粒度命名实体识别语料库筛选相关实体,采用BiLSTM-CRF训练模型,针对游记攻略、景区评论、酒店评论和餐饮评论4张表进行命名实体识别(NER),并结合LAC库设计了一套针对旅游产品的命名实体识别筛选和优化方法;其次,基于TextCNN 分类模型、Single-Pass聚类算法和地理编码进行同义地名合并,共整合提取到631个有效实体,累计1014种表述方式;然后,建立包括参与热度、反响热度和宣传热度三大方面指标的热度评价体系,并进行指标计算;最后,采用AHP-TOPSIS方法进行指标权重计算和排序,得到最终热度评价结果。
三、产品关联挖掘和本地旅游图谱构建:首先,在前一阶段的数据准备和实体抽取后进行关联模式的定义,根据本地经济发展程度、地理位置等因素定义了八种关联模式,其中包含三种隐含关系的模式;然后,对每种关联模式进行量化计算和标准化处理,将旅游产品和关联存入Neo4j图数据库中,生成疫情前后茂名市旅游产品关联图谱和本地旅游宏观概念图谱;基于产品关联模式、目的地热度和评论热词变化进行对比分析,发现游客的旅游倾向从“久游饱览式”过渡到“深挖全面式”、餐饮业迎来较好发展趋势和营销风口、旅游产品的共现关系愈加明显;最后,基于以上发现撰写信件向茂名市旅游主管部门提出茂名旅游业发展政策建议。
4.2 不足之处与未来展望
(1)模型训练仍有改进空间
TextCNN和BERT等模型效果依赖于参数设定,还可进一步调优。
(2)规则设计可进一步细化
在文旅行业有较多的特色,可建立更为细致的词库和程序规则,进一步优化分类、命名实体识别等任务的效果。
(3)可结合实地考察进一步探索茂名当地旅游业的现状
现阶段结论主要基于游记和评论数据进行挖掘和分析,实地考察能够更清楚地了解当地旅游业发展的现状和问题,使得研究更贴合实际,提出针对性和可行性更高的建议。
4.3 比赛总结与启示
这次比赛在方案完善上花了较多的精力,在方案实施的过程中发现很多新的问题,不断修改扩充,比赛过程中也反复感叹“越做越多”。埋头写代码,对整体的时间把控不够好,后期论文有些仓促。在进度控制方面,写论文的成员知道目前有什么、还缺什么,由其把控进度可能更好。
技能的提升需要长期积累,多学习多实践。在这次比赛中学到了很多新的知识技能和方法,也发现了很多自己还要继续学习的地方。
5. 写在最后
这篇总结从比赛结束就开始写了,当时也没有想到能够有幸进入答辩;辗转两地准备多日,有机会更清晰地展现我们的方案和结论,并与评委老师进行了一些富于意义的交流。
这次比赛的体验很好,各有擅长的队友、认真负责的指导老师、精益求精的方案,赛后一起复盘讨论……
未来继续努力!