http://www.cnblogs.com/cyfonly/p/6059374.html
一. 与 Thrift 的初识
也许大多数人接触 Thrift 是从序列化开始的。每次搜索 “java序列化” + “方式”、“对比” 或 “性能” 等关键字时,搜索引擎总是会返回一大堆有关各种序列化方式的使用方法或者性能对比的结果给你,而其中必定少不了 Thrift,并且其性能还不错嘞,至少比那战斗力只有1的渣渣 java 原生序列化要强很多(好吧原谅我的小情绪……)。
然而,我最初接触 Thrift 却是从公司的一个项目开始。
也就在去年的这个时候,我所在事业部发现几个 UGC 社区的小广告特别严重,Boss 要求所有社区必须接入公司的富媒体监控系统(负责公司所有业务的内容审核、处罚工作,以下简称监控系统),以实现 UGC 内容(包括文本、图片、音视频以及用户头像、昵称等UserInfo)的准实时上报与垃圾信息的自动处理(如清理现场、账号封禁等)。出于对业务服务的最小侵入、功能复用和流程统一等原则的考虑,抽象出介于业务系统和监控系统之间的接入系统,统一负责对数据的接收、上报、重推、搜索、结果查询以及对监控系统处罚指令的转发。该业务可简单抽象成图 1.1:
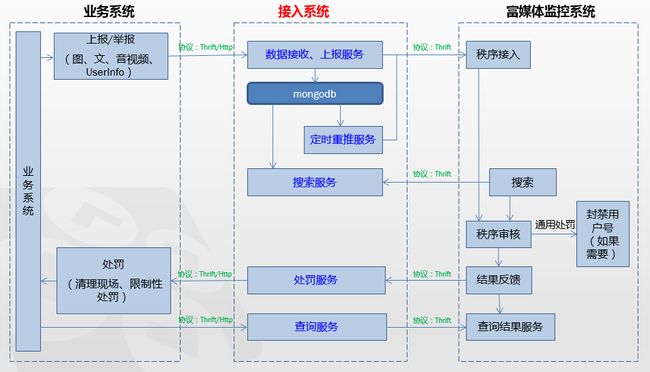
图 1.1
由于监控系统使用 Thrift 提供服务,因此接入系统与监控系统之间的交互都使用 Thrift 协议。考虑到接入的便捷性,业务系统可以使用 Thrift 和 Http 两种协议与接入系统交互。
当时是我一个人负责这个项目,由于对 Thrift 的认识还是0,且项目时间短,所以总体上项目是非常赶的,一开始以为自己难以在规定时间内完成,但想不到 Thrift 开发起来还真的是相当的便捷。系统按时上线了,至今也没出什么幺蛾子。后来又通过学习进一步了解了 Thrift,深以为是个必须入手的技能。
好吧,至此算是和 Thrift 正式结缘了。
二. 所谓的 RPC
在了解 Thrift 之前,先来简单科普一下什么是 RPC(远程过程调用)。
先看下面这个栗子:
|
1
2
3
4
5
6
7
8
9
|
public void invoke(){
String param1 = "my String 1" ;
String param2 = "my String 2" ;
String res = getStr(param1, param2);
System.out.println( "res=" + res)
}
private String getStr(String str1, String str2){
return str1 + str2;
}
|
这是一个最简单不过的本地函数调用代码,调用方和被调用方都在一个程序内部,属于进程内调用。
CPU 在执行调用时切换去执行被调用函数,执行完后再切换回来执行后续的代码。对调用方而言,执行被调用函数时会阻塞(非异步情况下)直到调用函数执行完毕。过程如图 2.1
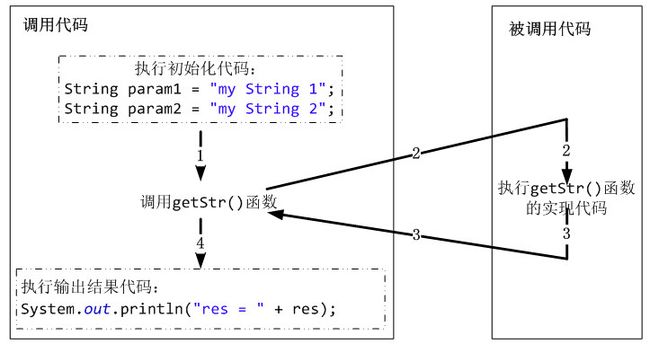
图 2.1
接下来看个 RPC 调用的栗子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public void test(){
TestQry.Client client = getClient( "192.168.4.222" , 7800 , 5000 );
String param1 = "my String 1" ;
String param2 = "my String 2" ;
String res = client.getStr(param1, param2);
System.out.println( "res=" + res);
}
private TestQry.Client getClient(String ip, int port, int timeOut) throws Exception{
TSocket tSocket = new TSocket();
TTransport transport = new TFramedTransport(tSocket);
tTransport.open();
TProtocol protocol = new TBinaryProtocol(tTransport);
return new TestQry.Client(protocol);
}
|
这是一个进程间调用,调用方和被调用方不在同一个进程(甚至不同的服务器或机房)。
进程间调用需要通过网络来传输数据,调用方在执行 RPC 调用时会阻塞(非异步情况下)直到调用结果返回才继续执行后续代码。过程如图 2.2
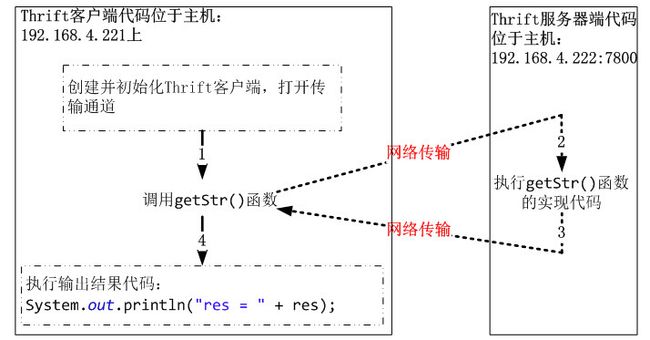
图 2.2
一言以蔽之,RPC 是一种通过网络从远程计算机程序上请求服务的方式,它使得开发包括网络分布式多程序在内的应用程序更加容易。
三. 不仅仅是个序列化工具
Thrift 最初是由 Facebook 开发用做系统内各语言之间的 RPC 通信的一个可扩展且跨语言的软件框架,它结合了功能强大的软件堆栈和代码生成引擎,允许定义一个简单的定义文件中的数据类型和服务接口,以作为输入文件,编译器生成代码用来方便地生成RPC客户端和服务器通信的无缝跨编程语言。
Thrift 是 IDL 描述性语言的一个具体实现,适用于程序对程序静态的数据交换,需要先确定好数据结构。
Thrift 是完全静态化的,当数据结构发生变化时,必须重新编辑IDL文件、代码生成再编译载入的流程,跟其他IDL工具相比较可以视为是 Thrift 的弱项。Thrift 适用于搭建大型数据交换及存储的通用工具,在大型系统中的内部数据传输上相对于 JSON 和 XML 无论在性能、传输大小上有明显的优势。
注意, Thrift 不仅仅是个高效的序列化工具,它是一个完整的 RPC 框架体系!
3.1 堆栈结构
如图 3.1所示,Thrift 包含一个完整的堆栈结构用于构建客户端和服务器端。

图 3.1
其中代码框架层是根据 Thrift 定义的服务接口描述文件生成的客户端和服务器端代码框架,数据读写操作层是根据 Thrift 文件生成代码实现数据的读写操作。
3.2 client/server调用流程
首先来看下 Thrift 服务端是如何启动并提供服务的,如下图 3.2所示(点击此处看大图):
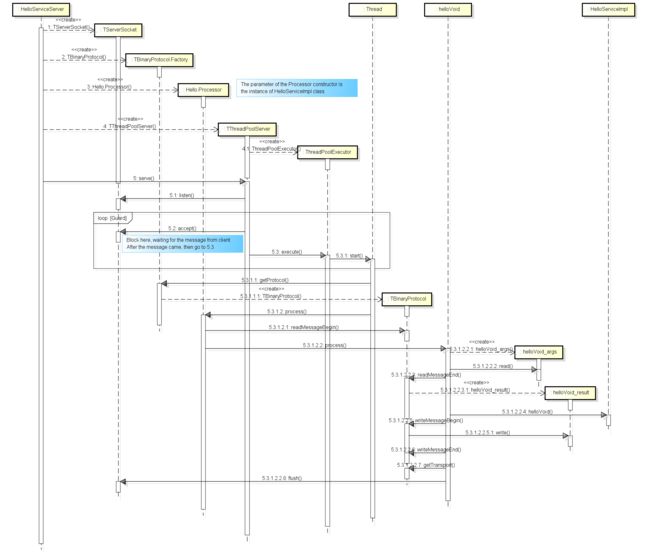
图 3.2
上图所示是 HelloServiceServer 启动的过程,以及服务被客户端调用时服务器的响应过程。我们可以看到,程序调用了 TThreadPoolServer 的 serve() 方法后,server 进入阻塞监听状态,其阻塞在 TServerSocket 的 accept()方法上。当接收到来自客户端的消息后,服务器发起一个新线程处理这个消息请求,原线程再次进入阻塞状态。在新线程中,服务器通过 TBinaryProtocol 协议读取消息内容,调用 HelloServiceImpl 的 helloVoid() 方法,并将结果写入 helloVoid_result 中传回客户端。
在服务启动后,客户端就开始调用其服务,如图 3.3所示(点击此处看大图):
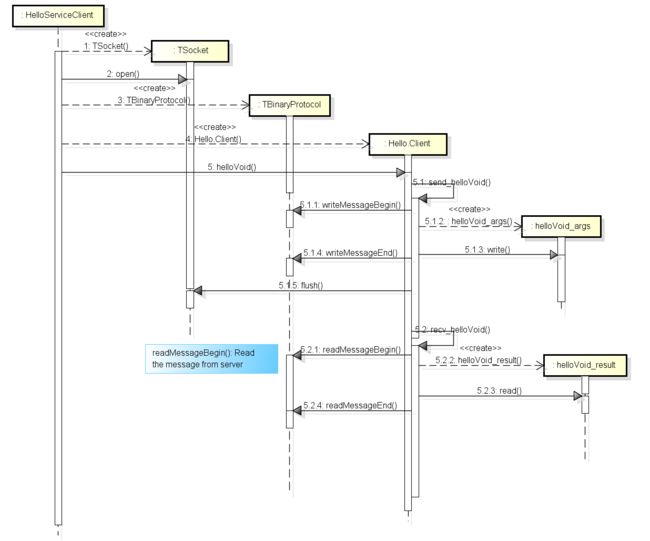
图 3.3
上图展示的是 HelloServiceClient 调用服务的过程,以及接收到服务器端的返回值后处理结果的过程。我们可以看到,程序调用了 Hello.Client 的 helloVoid() 方法,在 helloVoid() 方法中,通过 send_helloVoid() 方法发送对服务的调用请求,通过 recv_helloVoid() 方法接收服务处理请求后返回的结果。
3.3 数据类型
上一节我们已经大致了解了 Thrift 的 server 和 client 的工作流程,现在就来讲讲 Thrift 可定义的数据类型。Thrift 支持几大类数据结构:基本类型、结构体和异常类型、容器类型、服务类型。
基本类型:
|
1
2
3
4
5
6
7
|
bool:布尔值 ( true or false ), one byte
byte :有符号字节
i16: 16 位有符号整型
i32: 32 位有符号整型
i64: 64 位有符号整型
double : 64 位浮点型
string:未知编码或者二进制的字符串
|
结构体和异常类型:
Thrift 结构体 (struct) 在概念上类似于 C 语言结构体类型,在 java 中 Thrift 结构体将会被转换成面向对象语言的类。struct 的定义如下:
|
1
2
3
4
5
6
|
struct UserDemo {
1 : i32 id;
2 : string name;
3 : i32 age = 25 ;
4 : string phone;
}
|
struct 具有以下特性:
|
1
2
3
4
5
6
7
|
struct 不能继承,但是可以嵌套,不能嵌套自己
其成员都是有明确类型
成员是被正整数编号过的,其中的编号使不能重复的,这个是为了在传输过程中编码使用(详情往下看备注 1 )
成员分割符可以是逗号(,)或是分号(;),而且可以混用,但是为了清晰期间,建议在定义中只使用一种,比如java学习者可以就使用逗号(;)
字段会有optional和required之分(详情往下看备注 2 )
每个字段可以设置默认值
同一文件可以定义多个struct,也可以定义在不同的文件,进行include引入
|
备注1:数字标签作用非常大,随着项目开发的不断发展,也许字段会有变化,但是建议不要轻易修改这些数字标签,修改之后如果没有同步客户端和服务器端会让一方解析出问题。
备注2:关于 struct 字段类型,规范的 struct 定义中的每个域均会使用 required 或者 optional 关键字进行标识,但是如果不指定则为无类型,可以不填充该值,但是在序列化传输的时候也会序列化进去。其中 optional 是不填充则不序列化,required 是必须填充也必须序列化。如果 required 标识的域没有赋值,Thrift 将给予提示;如果 optional 标识的域没有赋值,该域将不会被序列化传输;如果某个 optional 标识域有缺省值而用户没有重新赋值,则该域的值一直为缺省值;如果某个 optional 标识域有缺省值或者用户已经重新赋值,而不设置它的 __isset 为 true,也不会被序列化传输。
异常在语法和功能上相当于结构体,差别是异常使用关键字 exception 而不是 struct 声明。它在语义上不同于结构体:当定义一个 RPC 服务时,开发者可能需要声明一个远程方法抛出一个异常。
容器类型
Thrift 容器与目前流行编程语言的容器类型相对应,有3种可用容器类型:
|
1
2
3
|
list
set
map
|
其中容器中元素类型可以是除了 service 外的任何合法 Thrift 类型(包括结构体和异常)。
服务类型
服务的定义方法在语义上等同于面向对象语言中的接口。Thrift 编译器会产生执行这些接口的 client 和 server 存根(详情下一节会具体描述)。下面我们就举个简单的例子解释 service 如何定义:
|
1
2
3
4
5
6
7
8
9
10
11
|
service QuerySrv{
/**
* 本方法实现根据名字和年龄来找到对应的用户信息
*/
UserDemo qryUser( 1 :string name, 2 :i32 age);
/**
* 本方法实现根据id找到对应用户的手机号码
*/
string queryPhone( 1 :i32 id);
}
|
在上面的例子中我们定义了一个 service 类型的结构,里面包含两个方法的定义。
在定义 services 的时候,我们还需要了解一下规则:
|
1
2
3
4
5
6
|
继承类必须实现这些方法
参数可以是基本类型或者结构体
所有的参数都是 const 类型,不能作为返回值
返回值可以是 void (oneway的返回值一定是 void )
服务支持继承,一个service可使用 extends 关键字继承另一个service
服务不支持重载
|
除上面所提到的四大数据类型外,Thrift 还支持枚举类型(enum)和常量类型(const)。
命名空间
Thrift 中的命名空间类似于 java 中的 package,它们提供了一种组织(隔离)代码的简便方式。名字空间也可以用于解决类型定义中的名字冲突。
3.4 传输体系
传输协议
Thrift 支持多种传输协议,用户可以根据实际需求选择合适的类型。Thrift 传输协议上总体可划分为文本 (text) 和二进制 (binary) 传输协议两大类,一般在生产环境中使用二进制类型的传输协议为多数(相对于文本和 JSON 具有更高的传输效率)。常用的协议包含:
|
1
2
3
4
|
TBinaryProtocol:是Thrift的默认协议,使用二进制编码格式进行数据传输,基本上直接发送原始数据
TCompactProtocol:压缩的、密集的数据传输协议,基于Variable-length quantity的zigzag 编码格式
TJSONProtocol:以JSON (JavaScript Object Notation)数据编码协议进行数据传输
TDebugProtocol:常常用以编码人员测试,以文本的形式展现方便阅读
|
关于以上几种类型的传输协议,如果想更深入更具体的了解其实现及工作原理,可以参考站外相关文章《thrift源码研究》。
传输方式
与传输协议一样,Thrift 也支持几种不同的传输方式。
1. TSocket:阻塞型 socket,用于客户端,采用系统函数 read 和 write 进行读写数据。
2. TServerSocket:非阻塞型 socket,用于服务器端,accecpt 到的 socket 类型都是 TSocket(即阻塞型 socket)。
3. TBufferedTransport 和 TFramedTransport 都是有缓存的,均继承TBufferBase,调用下一层 TTransport 类进行读写操作吗,结构极为相似。其中 TFramedTransport 以帧为传输单位,帧结构为:4个字节(int32_t)+传输字节串,头4个字节是存储后面字节串的长度,该字节串才是正确需要传输的数据,因此 TFramedTransport 每传一帧要比 TBufferedTransport 和 TSocket 多传4个字节。
4. TMemoryBuffer 继承 TBufferBase,用于程序内部通信用,不涉及任何网络I/O,可用于三种模式:(1)OBSERVE模式,不可写数据到缓存;(2)TAKE_OWNERSHIP模式,需负责释放缓存;(3)COPY模式,拷贝外面的内存块到TMemoryBuffer。
5. TFileTransport 直接继承 TTransport,用于写数据到文件。对事件的形式写数据,主线程负责将事件入列,写线程将事件入列,并将事件里的数据写入磁盘。这里面用到了两个队列,类型为 TFileTransportBuffer,一个用于主线程写事件,另一个用于写线程读事件,这就避免了线程竞争。在读完队列事件后,就会进行队列交换,由于由两个指针指向这两个队列,交换只要交换指针即可。它还支持以 chunk(块)的形式写数据到文件。
6. TFDTransport 是非常简单地写数据到文件和从文件读数据,它的 write 和 read 函数都是直接调用系统函数 write 和 read 进行写和读文件。
7. TSimpleFileTransport 直接继承 TFDTransport,没有添加任何成员函数和成员变量,不同的是构造函数的参数和在 TSimpleFileTransport 构造函数里对父类进行了初始化(打开指定文件并将fd传给父类和设置父类的close_policy为CLOSE_ON_DESTROY)。
8. TZlibTransport 跟 TBufferedTransport 和 TFramedTransport一样,调用下一层 TTransport 类进行读写操作。它采用
9. TSSLSocket 继承 TSocket,阻塞型 socket,用于客户端。采用 openssl 的接口进行读写数据。checkHandshake()函数调用 SSL_set_fd 将 fd 和 ssl 绑定在一起,之后就可以通过 ssl 的 SSL_read和SSL_write 接口进行读写网络数据。
10. TSSLServerSocket 继承 TServerSocket,非阻塞型 socket, 用于服务器端。accecpt 到的 socket 类型都是 TSSLSocket 类型。
11. THttpClient 和 THttpServer 是基于 Http1.1 协议的继承 Transport 类型,均继承 THttpTransport,其中 THttpClient 用于客户端,THttpServer 用于服务器端。两者都调用下一层 TTransport 类进行读写操作,均用到TMemoryBuffer 作为读写缓存,只有调用 flush() 函数才会将真正调用网络 I/O 接口发送数据。
TTransport 是所有 Transport 类的父类,为上层提供了统一的接口而且通过 TTransport 即可访问各个子类不同实现,类似多态。
四. 选择 java server 的艺术
Thrift 包含三个主要的组件:protocol,transport 和 server。
其中,protocol 定义了消息是怎样序列化的;transport 定义了消息是怎样在客户端和服务器端之间通信的;server 用于从 transport 接收序列化的消息,根据 protocol 反序列化之,调用用户定义的消息处理器,并序列化消息处理器的响应,然后再将它们写回 transport。
Thrift 模块化的结构使得它能提供各种 server 实现。下面列出了 Java 中可用的 server 实现:
|
1
2
3
4
5
|
TSimpleServer
TNonblockingServer
THsHaServer
TThreadedSelectorServer
TThreadPoolServer
|
有多个选择固然是很好的,但如果不清楚个中差别则是个灾难。所以接下来就谈谈这些 server 之间的区别,并通过一些简单的测试以说明它们的性能特点。
TSimpleServer
TSimplerServer 接受一个连接,处理连接请求,直到客户端关闭了连接,它才回去接受一个新的连接。正因为它只在一个单独的线程中以阻塞 I/O 的方式完成这些工作,所以它只能服务一个客户端连接,其他所有客户端在被服务器端接受之前都只能等待。
TSimpleServer 主要用于测试目的,不要在生产环境中使用它!
TNonblockingServer vs. THsHaServer
TNonblockingServer 使用非阻塞的 I/O 解决了 TSimpleServer 一个客户端阻塞其他所有客户端的问题。它使用了 java.nio.channels.Selector,通过调用 select(),它使得你阻塞在多个连接上,而不是阻塞在单一的连接上。当一或多个连接准备好被接受/读/写时,select() 调用便会返回。TNonblockingServer 处理这些连接的时候,要么接受它,要么从它那读数据,要么把数据写到它那里,然后再次调用 select() 来等待下一个可用的连接。通用这种方式,server 可同时服务多个客户端,而不会出现一个客户端把其他客户端全部“饿死”的情况。
然而,还有个棘手的问题:所有消息是被调用 select() 方法的同一个线程处理的。假设有10个客户端,处理每条消息所需时间为100毫秒,那么,latency 和吞吐量分别是多少?当一条消息被处理的时候,其他9个客户端就等着被 select,所以客户端需要等待1秒钟才能从服务器端得到回应,吞吐量就是10个请求/秒。如果可以同时处理多条消息的话,会很不错吧?
因此,THsHaServer(半同步/半异步的 server)就应运而生了。它使用一个单独的线程来处理网络I/O,一个独立的 worker 线程池来处理消息。这样,只要有空闲的 worker 线程,消息就会被立即处理,因此多条消息能被并行处理。用上面的例子来说,现在的 latency 就是100毫秒,而吞吐量就是100个请求/秒。
为了演示做了一个测试,有10客户端和一个修改过的消息处理器——它的功能仅仅是在返回之前简单地 sleep 100 毫秒。使用的是有10个 worker 线程的 THsHaServer。消息处理器的代码看上去就像下面这样:
|
1
2
3
4
5
6
7
|
public ResponseCode sleep() throws TException{
try {
Thread.sleep( 100 );
} catch (Exception ex) {
}
return ResponseCode.Success;
}
|
特别申明,本章节的测试结果摘自站外文章,详情请看文末链接
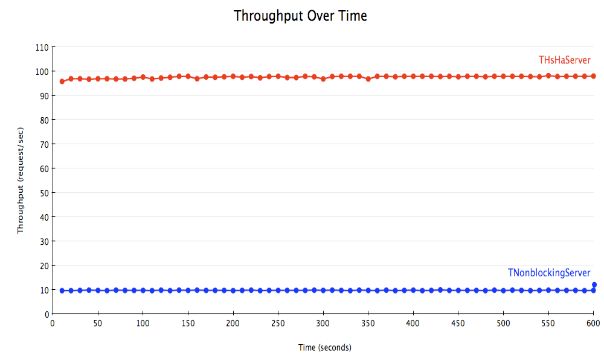
图 4.1
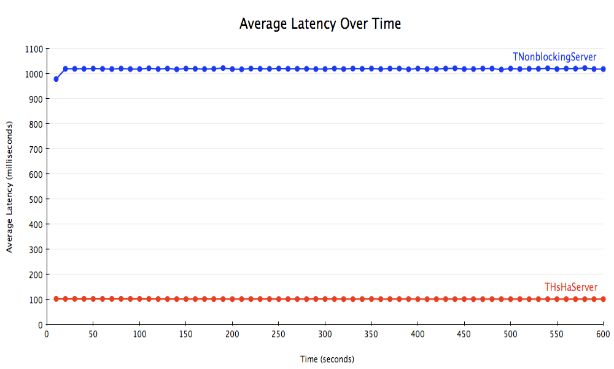
图 4.2
结果正如我们想像的那样,THsHaServer 能够并行处理所有请求,而 TNonblockingServer 只能一次处理一个请求。
THsHaServer vs. TThreadedSelectorServer
Thrift 0.8 引入了另一种 server 实现,即 TThreadedSelectorServer。它与 THsHaServer 的主要区别在于,TThreadedSelectorServer 允许你用多个线程来处理网络 I/O。它维护了两个线程池,一个用来处理网络 I/O,另一个用来进行请求的处理。当网络 I/O 是瓶颈的时候,TThreadedSelectorServer 比 THsHaServer 的表现要好。为了展现它们的区别进行一个测试,令其消息处理器在不做任何工作的情况下立即返回,以衡量在不同客户端数量的情况下的平均 latency 和吞吐量。对 THsHaServer,使用32个 worker 线程;对 TThreadedSelectorServer,使用16个 worker 线程和16个 selector 线程。
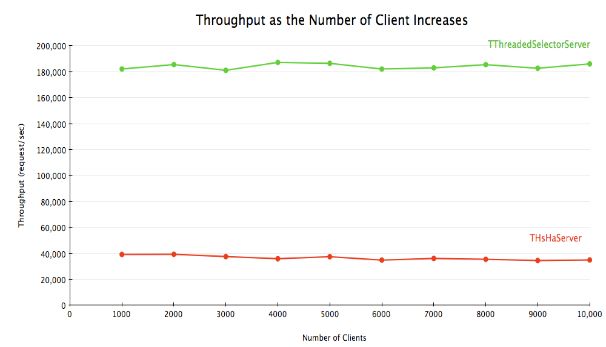
图 4.3
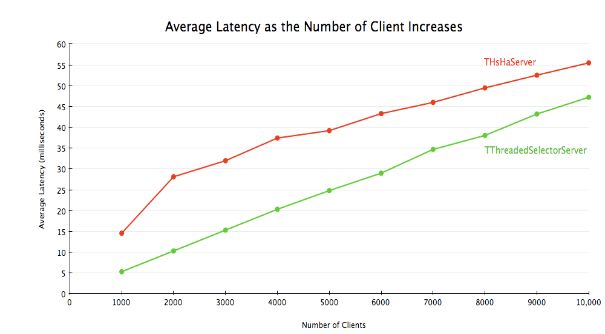
图 4.4
结果显示,TThreadedSelectorServer 比 THsHaServer 的吞吐量高得多,并且维持在一个更低的 latency 上。
TThreadedSelectorServer vs. TThreadPoolServer
最后,还剩下 TThreadPoolServer。TThreadPoolServer 与其他三种 server 不同的是:
|
1
2
3
4
|
有一个专用的线程用来接受连接
一旦接受了一个连接,它就会被放入 ThreadPoolExecutor 中的一个 worker 线程里处理。
worker 线程被绑定到特定的客户端连接上,直到它关闭。一旦连接关闭,该 worker 线程就又回到了线程池中。
你可以配置线程池的最小、最大线程数,默认值分别是 5 (最小)和 Integer.MAX_VALUE(最大)。
|
这意味着,如果有1万个并发的客户端连接,你就需要运行1万个线程。所以它对系统资源的消耗不像其他类型的 server 一样那么“友好”。此外,如果客户端数量超过了线程池中的最大线程数,在有一个 worker 线程可用之前,请求将被一直阻塞在那里。
我们已经说过,TThreadPoolServer 的表现非常优异。在我正在使用的计算机上,它可以支持1万个并发连接而没有任何问题。如果你提前知道了将要连接到你服务器上的客户端数量,并且你不介意运行大量线程的话,TThreadPoolServer 对你可能是个很好的选择。

图 4.5
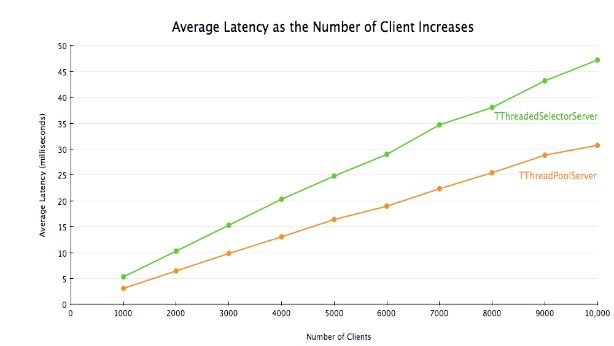
图 4.6
我想你可以从上面的描述可以帮你做出决定:哪一种 Thrift server 适合你。
TThreadedSelectorServer 对大多数案例来说都是个安全之选。如果你的系统资源允许运行大量并发线程的话,建议你使用 TThreadPoolServer。
五. Let's do it
上面已经介绍了很多理论知识了,很多同学还是不知道如何使用呢!好吧,是时候表演真正的技术了(LOL...)。
所谓大道至简,讲的就是最简单的代码就是最优美的代码,只要功能强悍,最简单的代码也掩盖不了它出众的气质。下面就来给大伙儿讲讲如何使用 Thrift 强大的代码生成引擎来生成 java 代码,并通过详细的步骤实现 Thrift Server 和 Client 调用。
备注:本文实现基于 Thrift-0.9.2 版本,实现过程忽略日志处理等非关键代码。
步骤一:首先从官网中下载对应的 Window 平台编译器(点击下载 thrift-0.9.2.exe)。使用 IDL 描述语言建立 .thrift 文件。本文提供一个实现简单功能的测试案例,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
/**
* 文件名为TestQry.thrift
* 实现功能:创建一个查询结果struct和一个服务接口service
* 基于:thrift-0.9.2
**/
namespace java com.thrift
struct QryResult {
/**
*返回码, 1成功,0失败
*/
1 :i32 code;
/**
*响应信息
*/
2 :string msg;
}
service TestQry{
/**
* 测试查询接口,当qryCode值为1时返回"成功"的响应信息,qryCode值为其他值时返回"失败"的响应信息
* @param qryCode测试参数
*/
QryResult qryTest( 1 :i32 qryCode)
}
|
步骤二:将上述 TestQry.thrift 文件与 thrift-0.9.2.exe 放在同一目录,如下:
图 5.1
在命令提示符 CMD 中进入文件目录所在目录,执行代码生成命令:
|
1
|
thrift- 0.9 . 2 .exe -r -gen java TestQry.thrift
|
执行之后,我们在文件夹中可以看到生成的 java 代码
图 5.2
步骤三:接下来我们新建 Maven Project(注意:JDK 版本1.5及以上),将上一步骤生成的代码拷贝到项目,并在 pom.xml 中加载 Thrift 的依赖,如下
|
1
2
3
4
5
6
7
8
9
10
11
12
|
0.9 . 2
1.7 . 13
|
步骤四:创建 QueryImp.java 实现 TestQry.Iface 接口,关键代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class QueryImp implements TestQry.Iface{
@Override
public QryResult qryTest( int qryCode) throws TException {
QryResult result = new QryResult();
if (qryCode== 1 ){
result.code = 1 ;
result.msg = "success" ;
} else {
result.code = 0 ;
result.msg = "fail" ;
}
return result;
}
}
|
步骤五:创建 ThriftServerDemo.java 实现服务端(本例采用非阻塞I/O,二进制传输协议),关键代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class ThriftServerDemo {
private final static int DEFAULT_PORT = 30001 ;
private static TServer server = null ;
public static void main(String[] args){
try {
TNonblockingServerSocket socket = new TNonblockingServerSocket(DEFAULT_PORT);
TestQry.Processor processor = new TestQry.Processor( new QueryImp());
TNonblockingServer.Args arg = new TNonblockingServer.Args(socket);
arg.protocolFactory( new TBinaryProtocol.Factory());
arg.transportFactory( new TFramedTransport.Factory());
arg.processorFactory( new TProcessorFactory(processor));
server = new TNonblockingServer (arg);
server.serve();
} catch (TTransportException e) {
e.printStackTrace();
}
}
}
|
步骤六:创建 ThriftClientDemo.java 实现客户端,关键代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class ThriftClientDemo {
private final static int DEFAULT_QRY_CODE = 1 ;
public static void main(String[] args){
try {
TTransport tTransport = getTTransport();
TProtocol protocol = new TBinaryProtocol(tTransport);
TestQry.Client client = new TestQry.Client(protocol);
QryResult result = client.qryTest(DEFAULT_QRY_CODE);
System.out.println( "code=" +result.code+ " msg=" +result.msg);
} catch (Exception e) {
e.printStackTrace();
}
}
private static TTransport getTTransport() throws Exception{
try {
TTransport tTransport = getTTransport( "127.0.0.1" , 30001 , 5000 );
if (!tTransport.isOpen()){
tTransport.open();
}
return tTransport;
} catch (Exception e){
e.printStackTrace();
}
return null ;
}
private static TTransport getTTransport(String host, int port, int timeout) {
final TSocket tSocket = new TSocket(host, port, timeout);
final TTransport transport = new TFramedTransport(tSocket);
return transport;
}
}
|
好的,所有准备工作都已经做好了,接下来我们就来进行 Client 和 Server 的通信。先运行 ThriftServerDemo 启动 Server,然后运行 ThriftClientDemo.java 创建 Client 进行调用,当 qryCode = 1 时,结果如下
|
1
|
code= 1 msg=success
|
当 qryCode = 0 时,结果如下
|
1
|
code= 0 msg=fail
|
附上项目的代码结构:
图 5.3
你看我没骗你吧,是不是 so easy ?
当然在项目中使用时绝对没有这么简单,但上面的栗子已经足够用来指导你进行 Thrift 服务端和客户端开发了。
六. 路漫漫其修远兮
到目前为止你所看到的都不是源码分析层面的知识,本文的目的也并非在此。掌握任何一门技术,都应该先从其宏观体系和架构开始了解,然后再去深入研究其中的细节和精髓。如果一开始就追求所谓的源码解析等“高大上”的东西,反而会因为拥有了一颗大树而失去了欣赏整个森林的美妙。
当然,笔者下一步的计划就是深入研究 Thrift 的实现,希望能和大家一起交流共同进步。
参考文章
[1] 《Apache Thrift - 可伸缩的跨语言服务开发框架》
[2] 《Thrift Java Servers Compared》