【Python笔记】正则表达式基础和应用
文章目录
- 0 引言
-
- 0.1 正则の定义、功能
- 0.2 正则の基本知识
- 0.3 在常见的编辑器中使用正则の方法
- 0.4 进阶内容
- 1 基础篇
-
- 1.1 元字符:如何巧妙记忆正则表达式的基本元件?
-
- 1 特殊单字符
- 2 空白符
- 3 量词
- 4 范围
- 5 小结
- 1.2 量词与贪婪:小小的正则,也可能把CPU拖垮!
-
- 1 为什么会有贪婪与非贪婪模式?
-
- 加号:+
- 星号:*
- 2 贪婪、非贪婪与独占模式
-
- 贪婪匹配(Greedy)
- 非贪婪匹配(Lazy)
- 独占模式(Possessive)
- 正则回溯引发的血案
- 3 小结
- 1.3 分组与引用:如何用正则实现更复杂的查找和替换操作?
-
-
- 1 分组与编号
- 2 不保存子组
- 3 括号嵌套
- 4 命名分组
- 5 分组引用
- 6 分组引用在查找中使用
- 7 分组引用在替换中使用
- 8 在文本编辑器中使用
- 9 小结
-
- 1.4 匹配模式:一次性掌握正则中常见的4种匹配模式
-
- 1 不区分大小写模式(Case-Insensitive): re.I
- 2 点号通配模式(Dot All): re.S
- 3 多行匹配模式(Multiline): re.M
- 4 注释模式(Comment): re.X
- 5 小结
- 1.5 断言:如何用断言更好地实现替换重复出现的单词?
-
- 1 单词边界(Word Boundary)
- 2 行的开始或结束
- 3 环视( Look Around)
-
- 单词边界用环视表示
- 环视与子组
- 4 小结
- 1.6 转义:正则中转义需要注意哪些问题?
-
- 1 转义字符(Escape Character)
- 2 字符串转义和正则转义
- 3 正则中元字符的转义
-
- 量词的转义
- 括号的转义
- 使用函数消除元字符特殊含义
- 字符组中的转义
- 4 字符组中其它的元字符
- 5 小结
- 1.7 正则有哪些常见的流派及其特性?
-
- 1 正则表达式简史
- 2 正则表达式流派
-
- POSIX 流派
-
- POSIX 字符组
- PCRE 流派
-
- PCRE 流派的兼容问题
- 在 Linux 中使用正则
- 小结
- 2 应用篇
-
- 2.1 应用1:正则如何处理 Unicode 编码的文本?
-
- 1 Unicode 基础知识
- 2 Unicode 中的正则
-
- 编码问题的坑
- 点号匹配
- 字符组匹配
- Unicode 属性
- 表情符号
- 3 小结
- 2.2 应用2:如何在编辑器中使用正则完成工作?
-
- 1 编辑器功能
-
- 光标移动和文本选择
- 多焦点编辑
- 竖向编辑
- 2 在编辑器中使用正则
-
- 内容提取
- 内容替换
- 内容验证
- 内容切割
- 3 小结
- 2.3 应用3:如何在语言中用正则让文本处理能力上一个台阶?
-
- 1 校验文本内容
- 2 提取文本内容
- 3 替换文本内容
- 4 切割文本内容
- 5 小结
- 2.4 如何理解正则的匹配原理以及优化原则?
-
- 1 有穷状态自动机
- 2 正则的匹配过程
- 3 DFA& NFA 工作机制
- 4 POSIX NFA 与 传统 NFA 区别
- 5 回溯
- 6 优化建议
- 7 小结
- 2.5 问题集锦:详解正则常见问题及解决方案
-
- 1 问题处理思路
- 2 常见问题及解决方案
-
- 匹配数字
- 匹配正数、负数和小数
- 浮点数
- 十六进制数
- 手机号码
- 身份证号码
- 邮政编码
- 腾讯 QQ 号码
- 中文字符
- IPv4 地址
- 日期和时间
- 邮箱
- 网页标签
- 3 小结
- 3 书目推荐
0 引言
0.1 正则の定义、功能
正则,就是正则表达式,英文是 Regular Expression,简称 RE。正则其实就是一种描述文本内容组成规律的表示方式。
在编程语言中,正则常常用来简化文本处理的逻辑。在 Linux 命令中,它也可以帮助我们轻松地查找或编辑文件的内容,甚至实现整个文件夹中所有文件的内容替换,比如 grep、egrep、sed、awk、vim 等。
另外,在各种文本编辑器中,比如 Atom,Sublime Text 或 VS Code 等,在查找或替换的时候也会使用到它。
0.2 正则の基本知识
正则的很多基本知识其实并不难,只是难记。我们的目的是理解并且会用正则这个工具。
比如正则中的各种元字符,本篇blog会给出有关元字符的记忆技巧。再比如各种模式和分组,它们可以在查找和替换时发挥强大的威力。
下面我用 Python 语言示例,从文本中找出连续出现的重复单词。我们可以看到,正则可以很方便地搞定这个需求。
import re
test_str = "the little cat cat in the hat hat."
re.sub(r'(\w+) \1', r'\1', test_str)
'the little cat in the hat.'
0.3 在常见的编辑器中使用正则の方法
我们经常需要从大段文本中抽取需要的内容。
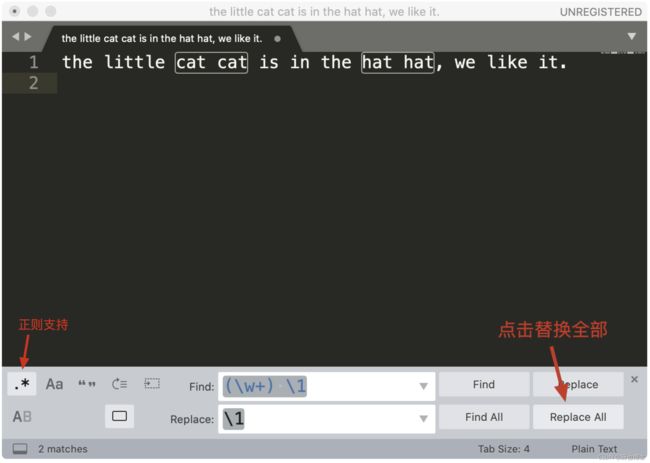
举个栗子 假如在 Sublime Text 3 中使用正则,查找重复出现的单词并把它替换成单个单词。
菜单中的 Find -> Replace,在查找栏中输入 (\w+) \1,在替换栏中输入子组的引用 \1 ,然后点击 Replace All 就可以完成替换工作了。
0.4 进阶内容
这部分主要有正则中的断言(包括单词边界、行开始和结束、环视),三种主要流派的区别以及对应的软件实现,正则的工作机制和常见的优化方式等。
掌握这些内容可以让我们更好地理解正则, 也可以避过很多坑。比如,为什么在编程语言中能工作的正则,在 Linux 命令 grep 中就不能工作了呢?正则匹配的原理又是什么?如何写出性能更好的正则呢?
综上所述,本篇一网打尽文の架构:
- 基础:正则中一些重要的概念和功能
- 利器:有关正则的记忆方法
- 实战:使用示例
1 基础篇
1.1 元字符:如何巧妙记忆正则表达式的基本元件?
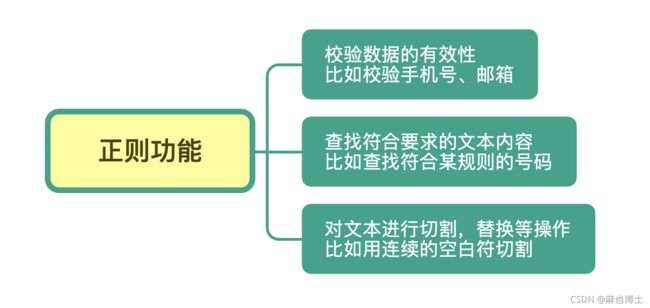
正则常见的三种功能,分别是:
- 校验数据的有效性
- 查找符合要求的文本
- 对文本进行切割和替换等操作
正则是如何完成这些工作的呢?先从简单的字符串查找和替换入手。
字符串查找和替换 功能在办公软件(比如 Word、Excel 中)经常被用到。使用 查找 功能快速定位关注的内容,然后使用 替换 批量更改这些内容。

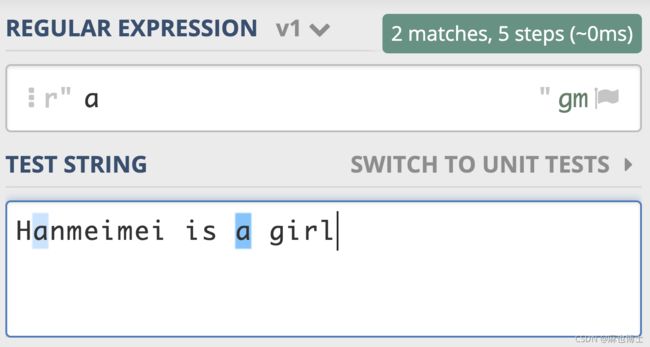
正则表达式,简单地说就是描述字符串的规则。在正则中,普通字符表示的还是原来的意思,比如字符 a,它可以匹配“Hanmeimei is a girl”中的 H 之后的 a,也可以匹配 is 之后的 a,这个和我们日常见到的普通的字符串查找是一样的。
它真正的强大之处就在于可以查找符合某个规则的文本。
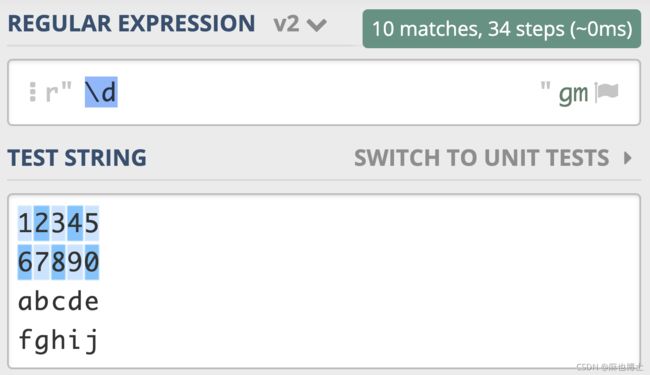
举个栗子 假如你想查找文本中的所有数字,我们直接使用 \d 就可以表示 0-9 这 10 个数字中的任意一个,如下图所示。
如果我们在后面再加上量词,就可以表示单个的数字出现了几次。比如 \d{11} 表示单个数字出现 11 次,即 11 位数字,如果文本中只有姓名和手机号,我们就可以利用这个查找出文本中的手机号了,如下图所示。

像上面案例中提到的 \d 和 {11},在正则中有一个专门的名称——元字符(Metacharacter)
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。正则就是由一系列的元字符组成的。
但是,因为元字符很基础,又比较多,所以很多人看见正则就头疼。那么今天,我就通过分类的方式,教你理解并且巧妙地记忆、使用元字符——分类记忆。
元字符虽然非常多,但如果我们按照分类法去理解记忆,效果会好很多。事实上,这个方法不光可以用在记忆元字符上,也可以用在记忆各种看似没有章法的内容上。
- 首先,把元字符大致分成这几类:表示单个特殊字符的,表示空白符的,表示某个范围的,表示次数的量词,另外还有表示断言的,我们可以把它理解成边界限定
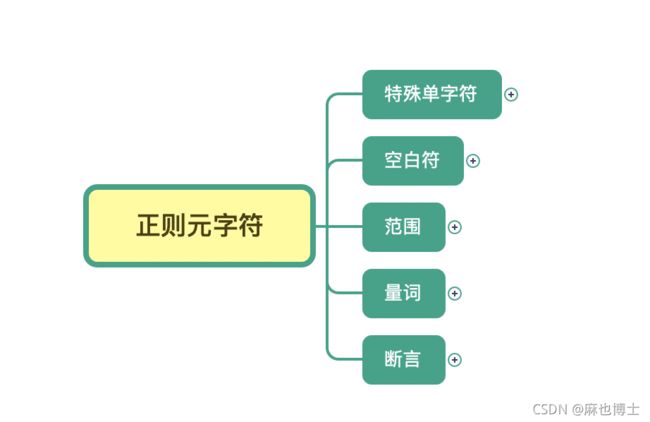
1 特殊单字符

d 是 digit 数字
w 是 word 单词
s 是 space 空白
我把常见数字,字母,部分标点符号作为文本,用 \d 去查找,可以看到只能匹配上 10 个数字
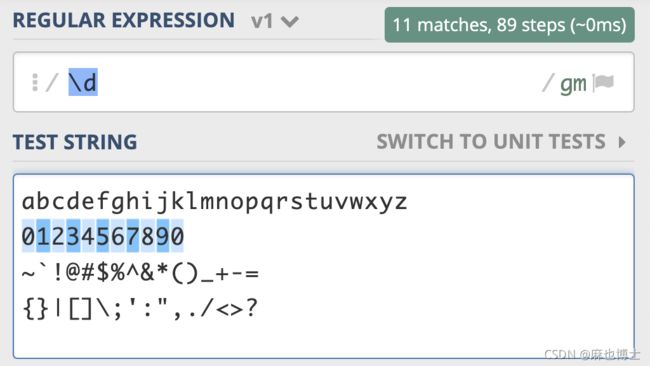
这是元字符 \d 测试用例的链接,你不妨测试一下:https://regex101.com/r/PnzZ4k/1
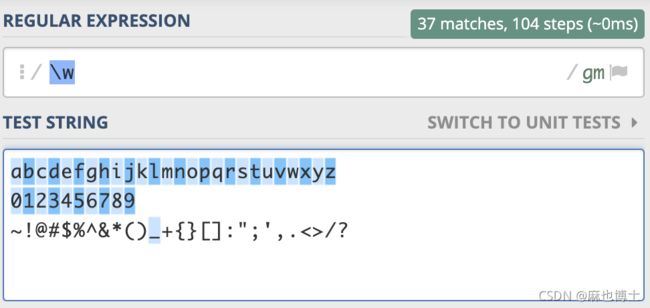
元字符 \w 能匹配所有的数字、字母和下划线,测试用在这里:https://regex101.com/r/PnzZ4k/2
2 空白符
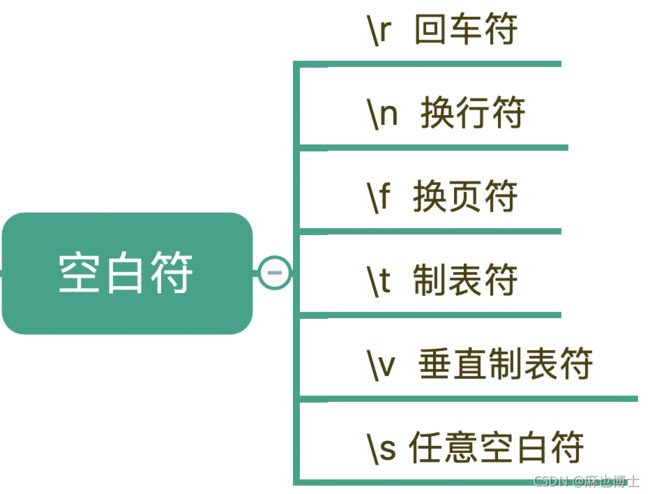
除了特殊单字符外,你在处理文本的时候肯定还会遇到空格、换行等空白符。其实在写代码的时候也会经常用到,换行符 \n,TAB 制表符 \t 等
我们可以看到, \s 能匹配上各种空白符号,也可以匹配上空格。换行有专门的表示方式,在正则中,空格就是用普通的字符英文的空格来表示。
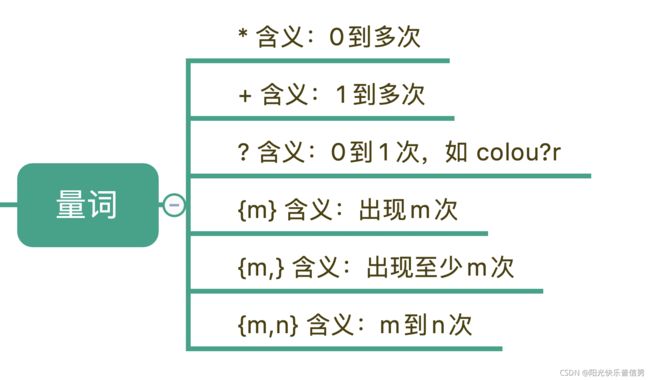
3 量词
刚刚我们说到的“基础”的元字符也好,“空白符”也好,它们都只能匹配单个字符,比如\d 只能匹配一个数字。但更多时候,我们需要匹配单个字符,或者某个部分“重复 N 次”“至少出现一次”“最多出现三次”等等这样的字符,这就需要用到表示量词的元字符
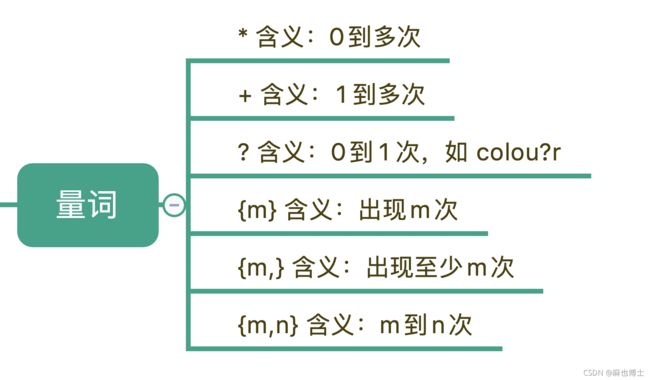
比如,在文本中“颜色”这个单词,可能是带有 u 的 colour,也可能是不带 u 的 color,我们使用 colou?r 就可以表示两种情况了。
在真实的业务场景中,比如某个日志需要添加了一个 user 字段,但在旧日志中,这个是没有的,那么这时候可以使用问号来表示出现 0 次或 1 次,这样就可以表示 user 字段存在和不存在两种情况。
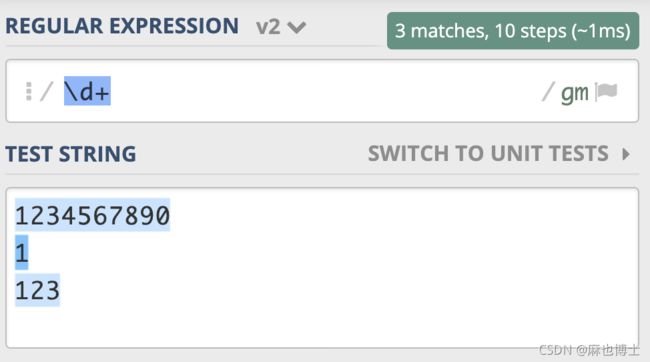
下面这段文本由三行数字组成,当我们使用 \d+ 时,能匹配上 3 个,但使用 \d* 时能匹配上 6 个,详细匹配结果可以参考下面的图片https://regex101.com/r/PnzZ4k/8:
4 范围
学习了量词,我们就可以用 \d{11} 去匹配所有手机号,但同时也要明白,这个范围比较大,有一些不是手机号的数字也会被匹配上,比如 11 个 0,那么我们就需要在一个特殊的范围里找符合要求的数字。
再比如,我们要找出所有元音字母 aeiou 的个数,这又要如何实现呢?在正则表达式中,表示范围的元字符可以轻松帮我们搞定这样的问题。在正则表达式中,表示范围的符号有四个分类。

比如某个资源可能以 http:// 开头,或者 https:// 开头,也可能以 ftp:// 开头,那么资源的协议部分,我们可以使用 (https?|ftp):// 来表示
- 第1次写的:
(http|https|ftp):\/\/ - 第2次写的:
(https?|ftp):\/\/
注意:
[]里面只能写一个元素,比如[abc]表示a|b|c, 但是不能用[(abc)(bd)(ce)]表示abc|bd|ce
我把示例链接也放在了下面,大家可以参考一下:https://regex101.com/r/PnzZ4k/5
5 小结
记住元字符是掌握正则的第一步
补充练习
我在这里给出一些手机号的组成规则:
- 第 1 位固定为数字 1;
- 第 2 位可能是 3,4,5,6,7,8,9;
- 第 3 位到第 11 位我们认为可能是 0-9 任意数字
参考:1[3-9]\d{9}
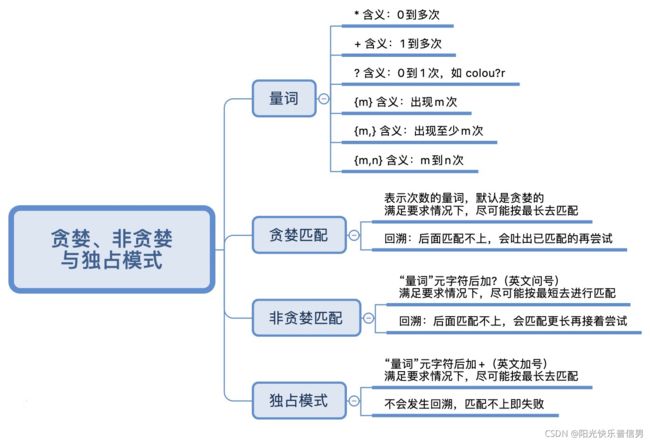
1.2 量词与贪婪:小小的正则,也可能把CPU拖垮!
本节分享正则中的三种模式:
- 贪婪匹配
- 非贪婪匹配
- 和独占模式
这些模式会改变正则中量词的匹配行为,比如匹配一到多次;在匹配的时候,匹配长度是尽可能长还是要尽可能短呢?如果不知道贪婪和非贪婪匹配模式,我们写的正则很可能是错误的,这样匹配就达不到期望的效果了。
1 为什么会有贪婪与非贪婪模式?
在这 6 种元字符中,我们可以用 {m,n} 来表示 (*)(+)(?) 这 3 种元字符:
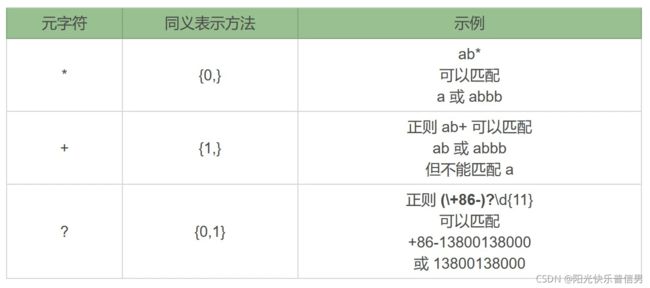
加号:+
使用 a+ 在 aaabb 中查找,可以看到只有一个输出结果:
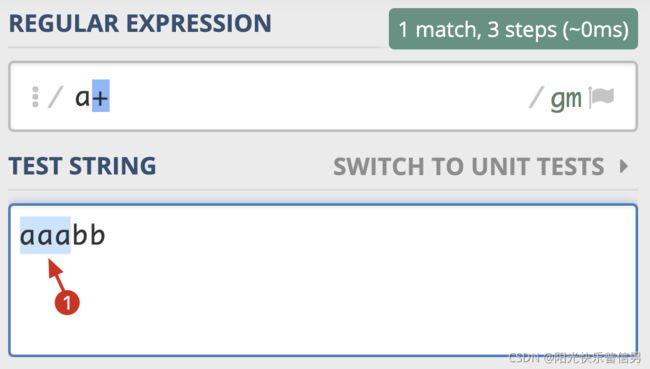
import re
re.findall(r'a+', 'aaabb')
['aaa']
星号:*
使用 a* 在 aaabb 这个字符串中进行查找,这次我们看到可以找到 4 个匹配结果。
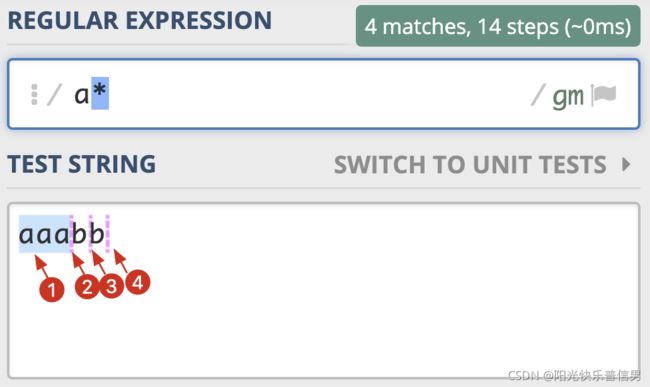
红线表示3-3,4-4,5-5的间隙(空字符串):为什么会匹配到空字符串呢?因为星号(*)代表 0 到多次,匹配 0 次就是空字符串。
import re
re.findall(r'a*', 'aaabb')
['aaa', '', '', '']
如果这样,aaa 部分应该也有空字符串,为什么没匹配上呢?
这就引入了贪婪与非贪婪模式。这两种模式都必须满足匹配次数的要求才能匹配上。
- 贪婪模式:尽可能进行最长匹配
- 非贪婪模式:尽可能进行最短匹配
2 贪婪、非贪婪与独占模式
贪婪匹配(Greedy)
在正则中,表示次数的量词 默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。首先,我们来看一下在字符串 aaabb 中使用正则 a* 的匹配过程。

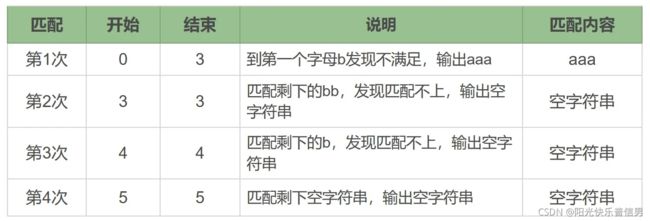
贪婪模式的特点就是尽可能进行最大长度匹配。所以要不要使用贪婪模式是根据需求场景来定的。
如果我们想尽可能最短匹配呢?那就要用到非贪婪匹配模式了。
非贪婪匹配(Lazy)
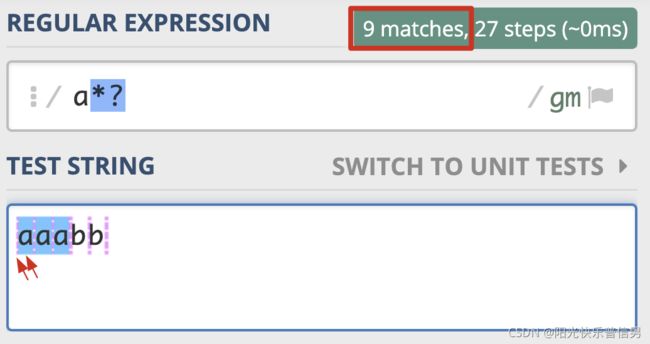
那么如何将贪婪模式变成非贪婪模式呢?我们可以在量词后面加上英文的问号 ?,正则就变成了 a*?。此时的匹配结果如下:
import re
# 贪婪模式
re.findall(r'a*', 'aaabb')
# ['aaa', '', '', '']
# 非贪婪模式
re.findall(r'a*?', 'aaabb')
# ['', 'a', '', 'a', '', 'a', '', '', '']
这次匹配到的结果都是单个的 a,就连每个 a 左边的空字符串也匹配上了

从下面这个示例中,我们可以很容易看出两者对比上的差异。左右的文本是一样的,其中有两对双引号。不同之处在于,左边的示例中,不加问号时正则是贪婪匹配,匹配上了从第一个引号到最后一个引号之间的所有内容;而右边的图是非贪婪匹配,找到了符合要求的结果。
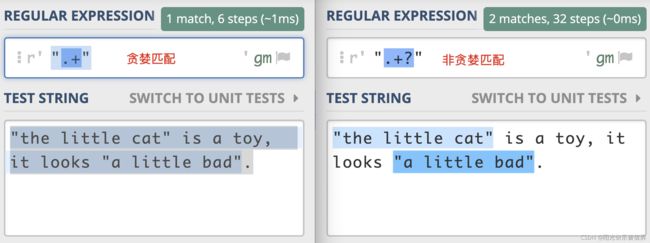
独占模式(Possessive)
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。
但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
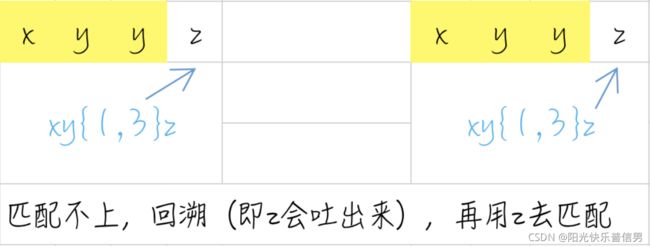
你可能会问,那什么是回溯呢?我们来看一些例子,例如下面的正则:
regex = "xy{1,3}z"
text = "xyyz"
在匹配时,y{1,3}会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即3个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配。
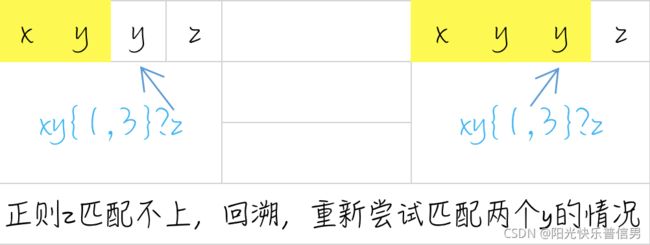
如果我们把这个正则改成非贪婪模式:
regex = "xy{1,3}?z"
text = "xyyz"
由于 y{1,3}? 代表匹配 1 到 3 个 y,尽可能少地匹配。匹配上一个 y 之后,也就是在匹配上 text 中的 xy 后,正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配,这时正则就会向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy,然后再用 z 去匹配 text 中的 z,匹配成功。
了解了回溯,我们再看下独占模式。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号+。
regex = "xy{1,3}+yz"
text = "xyyz"

需要注意的是 Python 和 Go 的标准库目前都不支持独占模式:
import re
re.findall(r'xy{1,3}+yz', 'xyyz')
error: multiple repeat at position 7
报错显示加号+被认为是重复次数的元字符了。如果要测试这个功能,我们可以安装 PyPI 上的 regex 模块:pip install regex
import regex
regex.findall(r'xy{1,3}z', 'xyyz') # 贪婪模式
# ['xyyz']
regex.findall(r'xy{1,3}+z', 'xyyz') # 独占模式
# ['xyyz']
regex.findall(r'xy{1,2}+yz', 'xyyz') # 独占模式
# []
正则回溯引发的血案
在网上可以看到不少因为回溯引起的线上问题。这里我们挑选一个比较出名的(阿里技术微信公众号上的发文)
Lazada 卖家中心店铺名检验规则比较复杂,名称中可以出现下面这些组合:
- 英文字母大小写
- 数字
- 越南文
- 一些特殊字符,如“&”,“-”,“_”等
负责开发的小伙伴在开发过程中使用了正则来实现店铺名称校验,如下所示:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
这个正则比较长,但很easy,中括号里面代表多选一,我们简化一下,就成下面这样:
^([符合要求的组成1]|[符合要求的组成2])+$
- 脱字符
^:代表以这个正则开头 - 美元符号
$:代表以正则结尾,这里可以先理解成整个店铺名称要能匹配上正则,即起到验证的作用 - 正则中有个加号
+,表示前面的内容出现一到多次,默认进行贪婪匹配会导致大量回溯,占用大量 CPU 资源,引发线上问题,我们只需要将贪婪模式改成独占模式就可以解决这个问题。
要根据具体情况来选择合适的模式,在这个例子中,匹配不上时证明店铺名不合法,不需要进行回溯,因此我们可以使用独占模式。
但要注意并不是说所有的场合都可以用独占模式解决,我们要首先保证正则能满足功能需求。仔细再看一下这个正则,你会发现 “组成 1” 和 “组成 2” 部分中,A-Za-z 英文字母在两个集合里面重复出现了,这会导致回溯后的重复判断。我们应该尽量减少回溯后的计算量,避免使用低效的正则,引发线上问题。
腾讯云技术社区也有类似的技术文章
3 小结
正则中量词默认是贪婪匹配,如果想要进行非贪婪匹配需要在量词后面加上问号。
贪婪和非贪婪匹配都可能会进行回溯,独占模式也是进行贪婪匹配,但不进行回溯,因此在一些场景下,可以提高匹配的效率,具体能不能用独占模式需要看使用的编程语言的类库的支持情况,以及独占模式能不能满足需求。
补充练习
有一篇英文文章,里面有很多单词,单词和单词之间是用空格隔开的,在引号里面的一到多个单词表示特殊含义,即引号里面的多个单词要看成一个单词。
现在你需要提取出文章中所有的单词。我们可以假设文章中除了引号没有其它的标点符号,有什么方法可以解决这个问题呢(不要求结果去重)?
text = "we found 'the little cat' is in the hat, we like 'the little cat'"
其中 the little cat 需要看成一个单词
参考:
- 第1次写:
\w{1,}|"[\w ]+"或\w{1,}|"[\w\s]+" - 第2次写:
\w{1,}|"[^"]{1,}"(引号里面是非引号出现一到多次)
import re
text = "we found 'the little cat' is in the hat, we like 'the little cat'"
a=re.findall(r"\w{1,}|'[\w\s]+'", "we found 'the little cat' is in the hat, we like 'the little cat'")
# a=re.findall(r"\w{1,}|'[^']{1,}'", "we found 'the little cat' is in the hat, we like 'the little cat'")
print(a)
# ['we', 'found', "'the little cat'", 'is', 'in', 'the', 'hat', 'we', 'like', "'the little cat'"]
1.3 分组与引用:如何用正则实现更复杂的查找和替换操作?
什么场合下会用到分组呢?
假设我们现在要去查找 15 位 或 18 位数字。根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,你应该很快就能写出\d{15}|\d{18}。但经过测试,你会发现,这个正则并不能很好地完成任务,因为 18 位数字也会匹配上前 15 位。
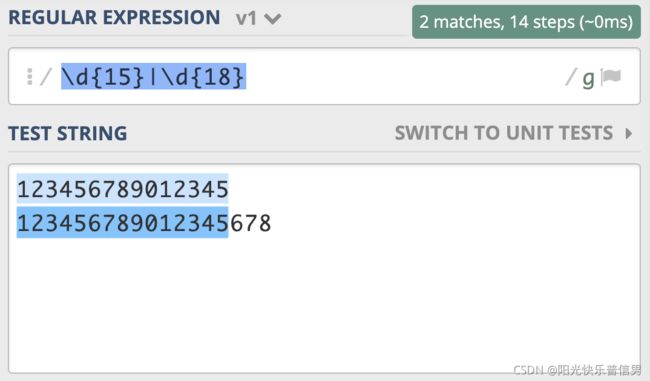
为了解决这个问题,你灵机一动,很快就想到了办法,就是把 15 和 18 调换顺序,即写成 \d{18}|\d{15},这回符合要求了。
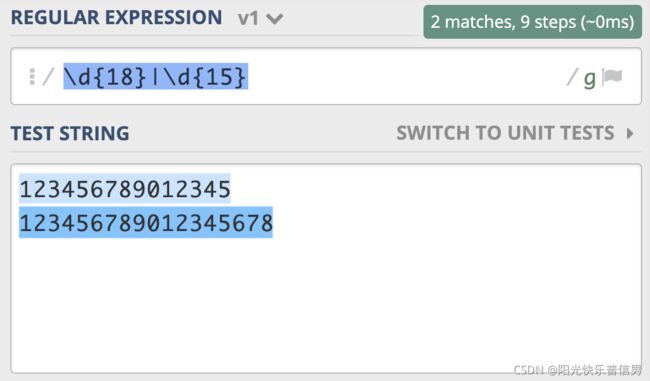
为什么会出现这种情况呢?因为在大多数正则实现中,多分支选择都是左边的优先。
类似地,你可以使用 “北京市|北京” 来查找 “北京” 和 “北京市”。你发现可以使用“北京市?” 来实现来查找 “北京” 和 “北京市”。
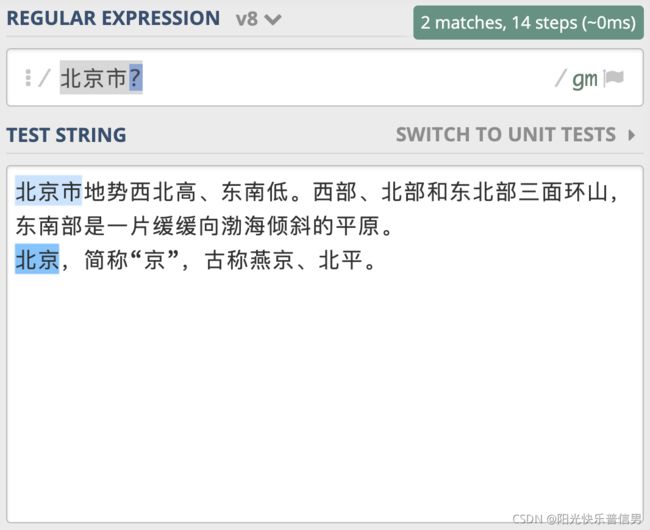
同样,针对 15 或 18 位数字这个问题,可以看成是 15 位数字,后面 3 位数据有或者没有,你应该很快写出了 \d{15}\d{3}? ,对不对呢?在上一节我们学习了量词后面加?表示非贪婪,而我们现在想要的是 \d{3} 出现 0 次或 1 次。
\d{15}\d{3}?由于\d{3}表示三次,加问号非贪婪还是 3 次\d{15}(\d{3})?在\d{3}整体后加问号,表示后面三位有或无
这时候,必须使用括号将来把表示“三个数字”的\d{3}这一部分括起来。括号在正则中的功能就是用于分组。
括号的功能:
- 表示一个整体:由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示
- 复用
1 分组与编号
括号在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组。
假设我们想要使用正则提取出里面的日期和时间。第几个括号就是第几个分组。我们可以写出如图所示的正则,将日期和时间都括号括起来。这个正则中一共有两个分组,日期是第 1 个,时间是第 2 个。

2 不保存子组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用 ?: 不保存子组。
如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能。除此之外呢,这么做还有一些好处,由于子组变少了,正则性能会更好,在子组计数时也更不容易出错。
那到底啥是不保存子组呢?可以理解成,括号只用于归组,把某个部分当成“单个元素”,不分配编号,后面不会再进行这部分的引用。


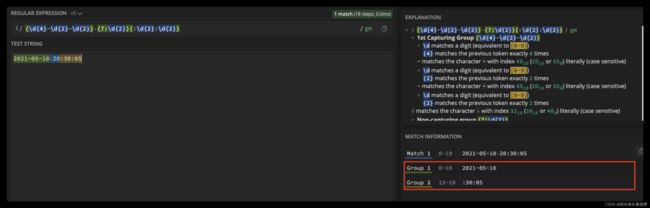
3 括号嵌套
前面讲完了子组和编号,但有些情况会比较复杂,比如在括号嵌套的情况里,我们要看某个括号里面的内容是第几个分组怎么办?我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。
在阿里云简单日志系统中,我们可以使用正则来匹配一行日志的行首。日期分组编号是 1,时间分组编号是 5,年月日对应的分组编号分别是 2,3,4,时分秒的分组编号分别是 6,7,8。

4 命名分组
前面我们讲了分组编号,但由于编号得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。
命名分组的格式为(?P<分组名>正则)。比如在 Django 的路由中,命名分组示例如下:
url(r'^profile/(?P\w+)/$' , view_func)
注意:你可以使用名称代替编号,实际上命名分组的编号已经分配好了。不过命名分组并不是所有语言都支持的,在使用时需要查阅所用语言正则说明文档,如果支持才可以使用。
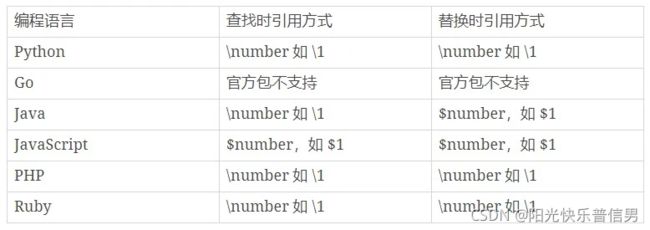
5 分组引用
在知道了分组引用的编号 (number)后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用,而 JavaScript 中是通过$编号来引用,如$1。
这里给到一些在常见的编程语言中,分组查找和替换的引用方式(需要用到的时候查一下)
6 分组引用在查找中使用
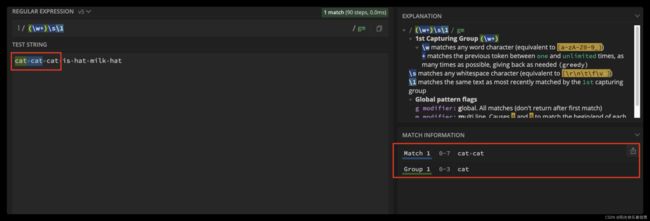
现在我们来看下在正则查找时如何使用分组引用。
比如我们要找重复出现的单词,我们使用正则可以很方便地使“前面出现的单词连续出现”。我们可以使用 \w+ 来表示一个单词,针对刚刚的问题,我们就可以很容易写出 (\w+) \1 。
括号对表达式分组后,可以通过 ”反斜杠 + 编号“ 来引用分组;
(Cat)\1
\1 表示引用第一个分组(Cat)

7 分组引用在替换中使用
和查找类似,我们可以使用反向引用,在得到的结果中,去拼出来我们想要的结果。
还是使用刚刚日期时间的例子,我们可以很方便地将它替换成, 2020 年 05 月 10 日这样的格式。
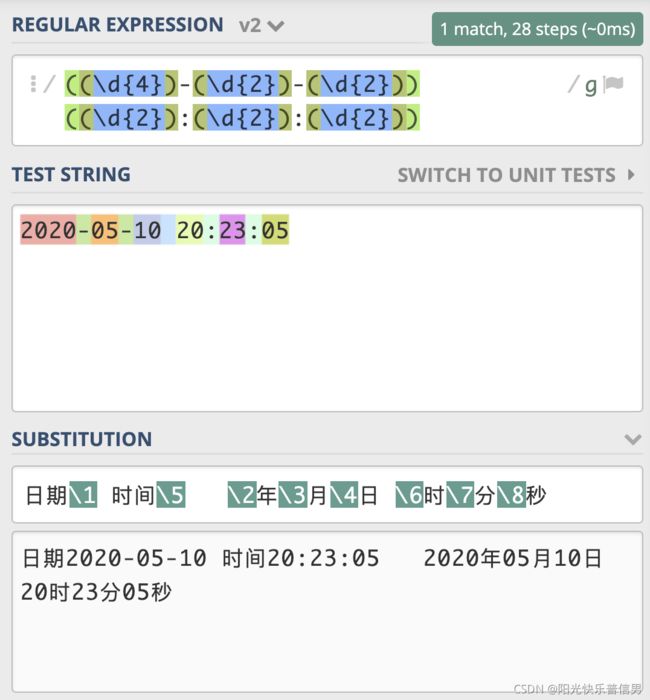
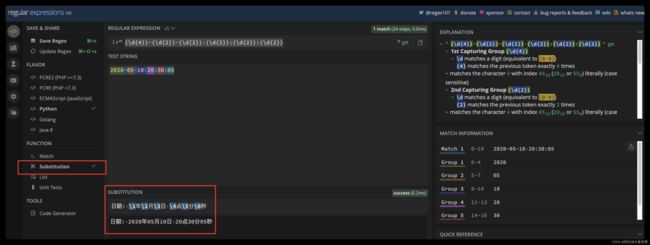
下面以 Python3 为例,给出一个示例。
import re
test_str = "2020-05-10 20:23:05"
regex = r"((\d{4})-(\d{2})-(\d{2})) ((\d{2}):(\d{2}):(\d{2}))"
subst = r"日期\1 时间\5 \2年\3月\4日 \6时\7分\8秒"
re.sub(regex, subst, test_str)
#'日期2020-05-10 时间20:23:05 2020年05月10日 20时23分05秒'
在 Python 中 sub 函数用于正则的替换,使用起来也非常简单,和在网页上操作测试的几乎一样。
更多Python正则函数的应用,详见 【Python笔记】字符串的处理方法(延伸到pandas)(含正则表达式)
8 在文本编辑器中使用
下面我以文本编辑器 Sublime Text 3 为例,来讲解正则查找和替换的使用方式。首先,我们要使用的“查找”或“替换”功能,在菜单 Find 中可以找到。
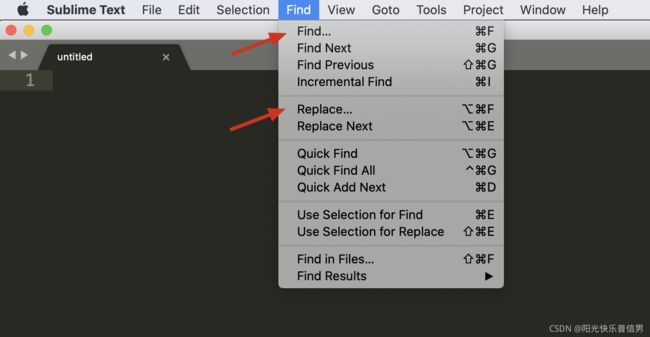

将下述源码复制进 Sublime Text 3:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="referrer" content="no-referrer-when-downgrade" />
<meta name="keywords" content="后端,架构,前端,移动,人工智能,大数据,产品,运营,运维,测试,极客时间,极客邦" id="metakeywords">
<meta name="description" content="" id="metadesc">
<link rel="apple-touch-icon" sizes="180x180" href="//static001.geekbang.org/static/time/icon/apple-touch-icon.jpg">
<link rel="icon" type="image/png" sizes="32x32" href="//static001.geekbang.org/static/time/icon/favicon-32x32.jpg">
<link rel="icon" type="image/png" sizes="16x16" href="//static001.geekbang.org/static/time/icon/favicon-16x16.jpg">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no, viewport-fit=cover" />
<meta name="format-detection" content="telephone=no" />
<meta property="og:url" content="https://time.geekbang.org/">
<meta property="og:type" content="article">
<meta property="og:title" content="极客时间-轻松学习,高效学习-极客邦">
<meta property="og:description" content="">
<meta property="og:image" content="">
<meta name="applicable-device" content="pc,mobile">
<meta http-equiv="Cache-Control" content="no-transform"/>
<meta http-equiv="Cache-Control" content="no-siteapp" />
<link rel="canonical" href="https://time.geekbang.org/" />
<title>极客时间-轻松学习,高效学习-极客邦</title>
<script type="text/javascript" src="https://res.wx.qq.com/open/js/jweixin-1.3.2.js"></script>
<script type="text/javascript" src="https://g.alicdn.com/dingding/dingtalk-jsapi/2.7.13/dingtalk.open.js"></script>
<script type="text/javascript" src="//static001.geekbang.org/static/time/js/[email protected]"></script>
<script type="text/javascript" src="//at.alicdn.com/t/font_372689_nw1guejwd2q.js"></script>
<script type="text/javascript" src="//static001.geekbang.org/static/time/js/katex.f3817a93026e8eaf1793e7b770cf588e.js"></script>
<script type="text/javascript" src="//static001.geekbang.org/static/time/js/hls.8361666e7e2690d988ff5fe775b62bbe.js"></script>
<script type="text/javascript" src="//g.alicdn.com/de/prismplayer/2.8.2/aliplayer-min.js"></script>
<script type="text/javascript">
if((!('flex' in document.documentElement.style) && !navigator.userAgent.match(/spider|googlebot|bingbot|geekbang|yahoo! Slurp/i)) || navigator.userAgent.match(/rv:11.+\) like gecko/i)){
window.location.href = 'https://static001.geekbang.org/static/common/browser_update/index.html'
}
</script>
<script type="text/javascript">
if (!('ontouchstart' in window)) {
window.ontouchstart = 1
}
</script>
</head>
<body>
<div id="app"></div>
<script type="text/javascript" src="/main.js?t=1630315958"></script>
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-103082599-6', 'auto');
ga('send', 'pageview');
</script>
<script>
var _hmt = _hmt || [];
var __gBaiduSiteIdConfig__ = {
optimize: '59c4ff31a9ee6263811b23eb921a5083',
time: '022f847c4e3acd44d4a2481d9187f1e6'
};
var _hmt = _hmt || [];
_hmt.push(['_setAccount', __gBaiduSiteIdConfig__.optimize]);
_hmt.push(['_setAutoPageview', true]);
_hmt.push(['_setAccount', __gBaiduSiteIdConfig__.time]);
_hmt.push(['_setAutoPageview', true]);
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?" + __gBaiduSiteIdConfig__.optimize;
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?" + __gBaiduSiteIdConfig__.time;
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https'){
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
} else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
<script>
(function(para) {
var p = para.sdk_url, n = para.name, w = window, d = document, s = 'script',x = null,y = null;
if(typeof(w['sensorsDataAnalytic201505']) !== 'undefined') {
return false;
}
w['sensorsDataAnalytic201505'] = n;
w[n] = w[n] || function(a) {return function() {(w[n]._q = w[n]._q || []).push([a, arguments]);}};
var ifs = ['track','quick','register','registerPage','registerOnce','trackSignup', 'trackAbtest', 'setProfile','setOnceProfile','appendProfile', 'incrementProfile', 'deleteProfile', 'unsetProfile', 'identify','login','logout','trackLink','clearAllRegister','getAppStatus'];
for (var i = 0; i < ifs.length; i++) {
w[n][ifs[i]] = w[n].call(null, ifs[i]);
}
if (!w[n]._t) {
x = d.createElement(s), y = d.getElementsByTagName(s)[0];
x.async = 1;
x.src = p;
x.setAttribute('charset','UTF-8');
w[n].para = para;
y.parentNode.insertBefore(x, y);
}
})({
sdk_url: 'https://static.sensorsdata.cn/sdk/1.15.12/sensorsdata.min.js',
heatmap_url: 'https://static.sensorsdata.cn/sdk/1.15.12/heatmap.min.js',
name: 'sensors',
server_url: "https://sscentry.geekbang.org/sa?project=production",
show_log: !true,
is_track_single_page: true,
is_track_device_id: true,
app_js_bridge: true,
heatmap: {
clickmap: 'default',
scroll_notice_map: 'not_collect'
},
preset_properties: {
latest_referrer_host: true,
latest_landing_page: true,
url: true
}
});
</script>
</body>
</html>

输入相应的正则,我们就可以看到查找的效果了。这里给一个小提示,如果你点击 Find All,然后进行剪切,具体操作可以在菜单中找到 Edit -> Cut,也可以使用快捷键操作。
剪切之后,找一个空白的地方,粘贴就可以看到提取出的所有内容了。
我们可以使用正则进行资源链接提取,比如从一个图片网站的源代码中查找到图片链接,然后再使用下载工具批量下载这些图片。
9 小结
补充练习
有一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次,比如:
the little cat cat is in the hat hat hat, we like it.
其中 cat 和 hat 连接出现多次,要求处理后结果是
the little cat is in the hat, we like it.
测试:https://regex101.com/r/2RVPTJ/3
解题思路:\w+ 用于选中出现一次到多次的字母,由于默认贪婪匹配最长,所以能选中每个单词,由于是要找出重复的单词,所以要用第一次匹配成功的结果即使用分组 (\w+) \1,到此可以拿到重复两次场景的结果,对于重复两次以上的结果,需要重复刚刚的行为,但是不能一直叠加 \1 ,自然想到了 +,得到了 (\w+) (\1)+,发现匹配不成功,在这里卡壳了一段时间没想明白,翻到别人的答案才猛然想起来单词之间应该有空隙,(\1)+不能表示空隙,用\s代替敲出来的空格最终得到 (\w+)(\s+\1)+
参考:(\w+)( \1)+
1.4 匹配模式:一次性掌握正则中常见的4种匹配模式
所谓匹配模式,指的是正则中一些改变元字符匹配行为的方式,比如匹配时不区分英文字母大小写。常见的匹配模式有 4 种:
- 不区分大小写模式
- 点号通配模式
- 多行模式
- 注释模式
注意:这里的“模式”对应的是英文中的
mode,而不是 pattern。有些地方会把正则表达式 pattern 也翻译成模式,在网上看到的技术文章中讲的正则模式,有可能指的是正则表达式本身
1 不区分大小写模式(Case-Insensitive): re.I
在进行文本匹配时,我们要关心单词本身的意义。比如要查找单词 cat,我们并不需要关心单词是 CAT、Cat,还是 cat。根据之前我们学到的知识,你可能会把正则写成这样:[Cc][Aa][Tt],这样写虽然可以达到目的,但不够直观,如果单词比较长,写起来容易出错,阅读起来也比较困难。
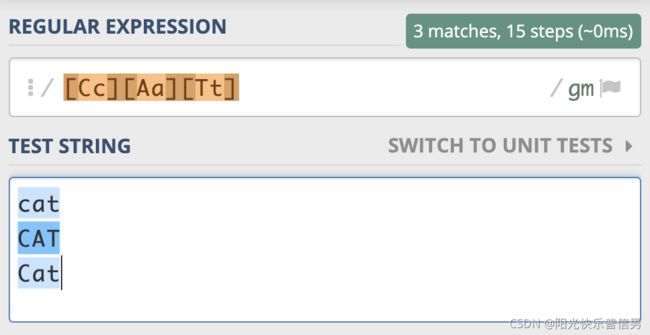
这时候不区分大小写模式就派上用场了。不区分大小写是匹配模式的一种。当我们把模式修饰符放在整个正则前面时,就表示整个正则表达式都是不区分大小写的。
模式修饰符是通过 (? 模式标识) 的方式来表示的。 我们只需要把模式修饰符放在对应的正则前,就可以使用指定的模式了。在不区分大小写模式中,由于不分大小写的英文是 Case-Insensitive,那么对应的模式标识就是 I 的小写字母 i,所以不区分大小写的 cat 就可以写成 (?i)cat。
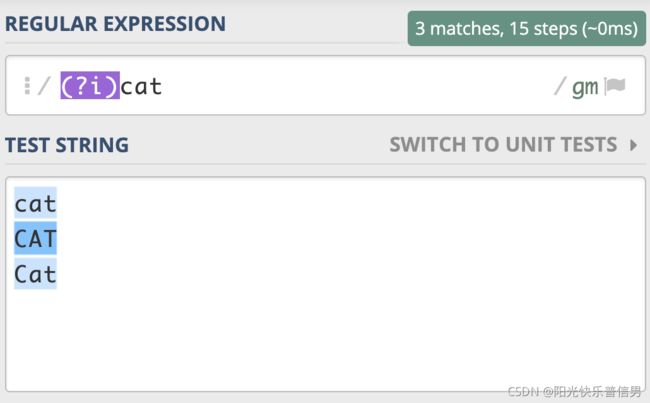
我们也可以用它来尝试匹配两个连续出现的 cat,如下图所示,你会发现,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上:https://regex101.com/r/x1lg4P/1

如果我们想要前面匹配上的结果,和第二次重复时的大小写一致,那该怎么做呢?我们只需要用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。
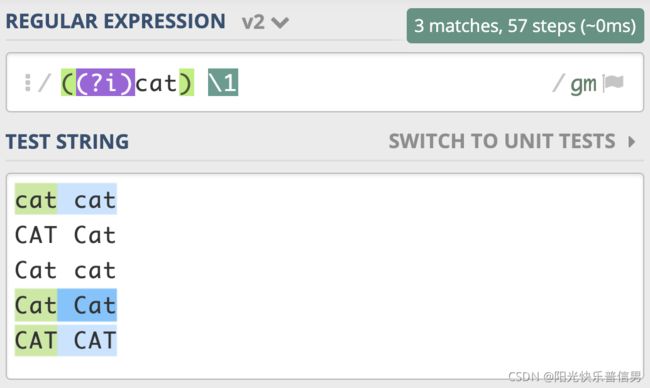
注意:这里正则写成了 ((?i)cat) \1,而不是 ((?i)(cat)) \1。也就是说,我们给修饰符和 cat 整体加了个括号,而原来 cat 部分的括号去掉了。如果 cat 保留原来的括号,即
((?i)(cat)) \1,这样正则中就会有两个子组,虽然结果也是对的,但这其实没必要。
上面讲到的通过修饰符指定匹配模式的方式,在大部分编程语言中都是可以直接使用的,比如 Python 中可以使用 re.IGNORECASE 或 re.I ,来传入正则函数中来表示不区分大小写。
import re
re.findall(r"cat", "CAT Cat cat", re.IGNORECASE)
# ['CAT', 'Cat', 'cat']
总结:
- 不区分大小写模式的指定方式,使用模式修饰符
(?i) - 修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则
- 使用编程语言时可以使用预定义好的常量来指定匹配模式
2 点号通配模式(Dot All): re.S
英文的点.可以匹配上任何符号,但不能匹配换行。当我们需要匹配真正的“任意”符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。

但是这么写不够简洁自然,所以正则中提供了一种模式,让英文的点.可以匹配上包括换行的任何字符。这个模式就是点号通配模式,有很多地方把它称作单行匹配模式,但这么说容易造成误解,毕竟它与多行匹配模式没有联系,因此我们统一用更容易理解的“点号通配模式”。
单行的英文表示是 Single Line,单行模式对应的修饰符是 (?s),我还是选择用 the cat 来给你举一个点号通配模式的例子:

注意:JavaScript 不支持此模式,那么我们就可以使用前面说的
[\s\S]等方式替代。在 Ruby 中则是用 Multiline,来表示点号通配模式(单行匹配模式),我猜测设计者的意图是把点(.)号理解成“能匹配多行”。
3 多行匹配模式(Multiline): re.M
通常情况下,^匹配整个字符串的开头,$ 匹配整个字符串的结尾。多行匹配模式改变的就是 ^ 和 $ 的匹配行为。

多行模式的作用在于,使 ^ 和 $ 能匹配上每行的开头或结尾,我们可以使用模式修饰符号 (?m) 来指定这个模式。
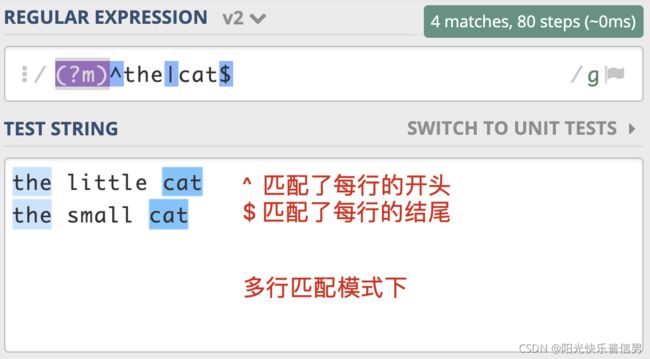
这个模式有什么用呢?在处理日志时,如果日志以时间开头,有一些日志打印了堆栈信息,占用了多行,就可以使用多行匹配模式,在日志中匹配到以时间开头的每一行日志。
值得一提的是,正则中还有
\A和\z(Python 中是\Z) 这两个元字符容易混淆
\A仅匹配整个字符串的开始\z仅匹配整个字符串的结束,在多行匹配模式下,它们的匹配行为不会改变,如果只想匹配整个字符串,而不是匹配每一行,用这个更严谨一些。
4 注释模式(Comment): re.X
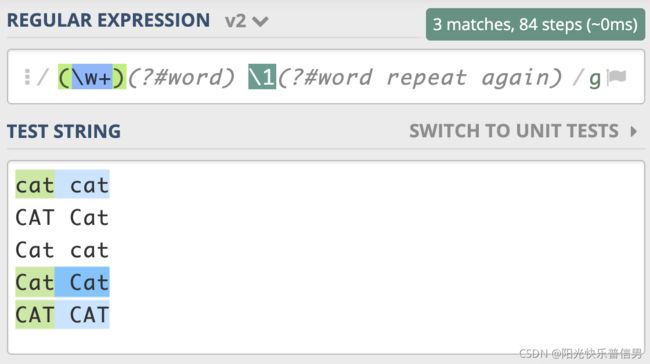
在实际工作中,正则可能会很复杂,这就导致编写、阅读和维护正则都会很困难。我们在写代码的时候,通常会在一些关键的地方加上注释,让代码更易于理解。很多语言也支持在正则中添加注释,让正则更容易阅读和维护,这就是正则的注释模式。正则中注释模式是使用 (?#comment) 来表示。
比如我们可以把单词重复出现一次的正则 (\w+) \1 写成下面这样,就算不是很懂正则的人也可以通过注释看懂正则的意思。
(\w+)(?#word) \1(?#word repeat again)
在很多编程语言中也提供了 x 模式来书写正则,也可以起到注释的作用。我用 Python3 给你举了一个例子。
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
(\d{2}) # 月
$ # 结尾
'''
re.findall(regex, '202006\n202007')
# 输出结果 [('2020', '06'), ('2020', '07')]
注意:在 x 模式下,所有的换行和空格都会被忽略。为了换行和空格的正确使用,我们可以通过把空格放入字符组中,或将空格转义来解决换行和空格的忽略问题。
regex = r'''(?mx)
^ # 开头
(\d{4}) # 年
[ ] # 空格
(\d{2}) # 月
$ # 结尾
'''
re.findall(regex, '2020 06\n2020 07')
# 输出结果 [('2020', '06'), ('2020', '07')]
regex1=r"""(?m)^(\d{4})(\d{2})$(?#注释)"""
re.findall(regex1, '202006\n202007')
# 输出结果 [('2020', '06'), ('2020', '07')]
re.findall(regex1, '2020 06\n2020 07')
# 输出结果 []
regex2=r"""(?m)^(\d{4}) (\d{2})$(?#注释)"""
re.findall(regex2, '2020 06\n2020 07')
# 输出结果 [('2020', '06'), ('2020', '07')]
5 小结
补充练习
HTML 标签是不区分大小写的,比如我们要提取网页中的 head 标签中的内容,用正则如何实现呢?
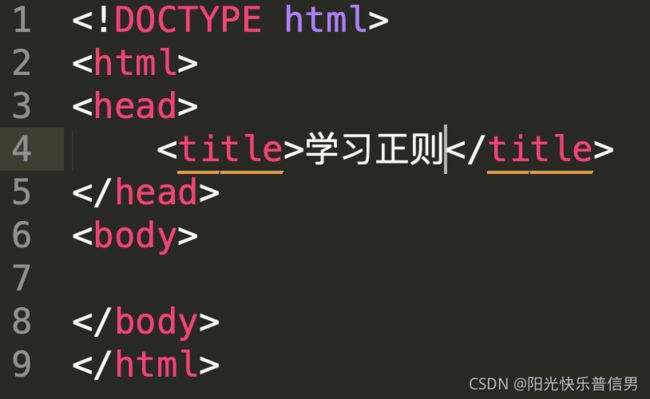
参考:(?si)(.*) 或 (?is).*
其他问题:怎么把
和这2个过滤掉,就是只取他们直接的内容。
回答:这个在断言里面
1.5 断言:如何用断言更好地实现替换重复出现的单词?
断言:对匹配到的文本位置有要求。
Eg:你应该知道
\d{11}能匹配上 11 位数字,但这 11 位数字可能是 18 位身份证号中的一部分。再比如,去查找一个单词 tom,但其它的单词,比如 tomorrow 中也包含了 tom。也就是说,在有些情况下,我们对要匹配的文本的位置也有一定的要求。
为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。
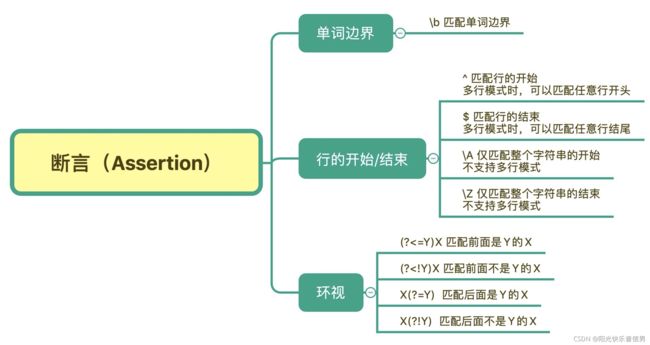
常见的断言有三种:单词边界、行的开始/结束 以及 环视。

1 单词边界(Word Boundary)
我们想要把下面文本中的 tom 替换成 jerry。注意一下,在文本中出现了 tomorrow 这个单词,tomorrow 也是以 tom 开头的
tom asked me if I would go fishing with him tomorrow.
利用前面学到的知识,我们如果直接替换,会出现下面这种结果。显然是错误的,因为明天这个英语单词里面的 tom 也被替换了。
替换前:tom asked me if I would go fishing with him tomorrow .
替换后:jerry asked me if I would go fishing with him jerryorrow.
那正则是如何解决这个问题的呢?单词的组成一般可以用元字符 \w+ 来表示,\w 包括了大小写字母、下划线和数字(即 [A-Za-z0-9_])。那如果我们能找出单词的边界,就是当出现了\w 表示的范围以外的字符,比如引号、空格、标点、换行等这些符号,我们就可以在正则中使用\b 来表示单词的边界。 \b 中的 b 可以理解为是边界(Boundary)这个单词的首字母。

在准确匹配单词时,我们使用 \b\w+\b 就可以实现了。
以 Python3 为例,实现上面提到的 “tom 替换成 jerry”:
import re
test_str = "tom asked me if I would go fishing with him tomorrow."
re.sub(r'\btom\b', 'jerry', test_str)
# 'jerry asked me if I would go fishing with him tomorrow.'
2 行的开始或结束
- 正则中还有文本每行的开始和结束:如果我们要求匹配的内容要出现在一行文本开头或结尾,就可以使用
^和$来进行位置界定 - 行的结尾如何判断:在计算机中,回车(
\r)和换行(\n)其实是两个概念,并且在不同的平台上,换行的表示也是不一样的。我在这里列出了 Windows、Linux、macOS 平台上换行的表示方式

匹配行的开始或结束有什么用呢?
- 日志起始行判断。最常见的例子就是日志收集,我们在收集日志的时候,通常可以指定日志行的开始规则,比如以时间开头,那些不是以时间开头的可能就是打印的堆栈信息。我来给你一个以日期开头,下面每一行都属于同一篇日志的例子。
在这种情况下,我们就通过 日期时间开头 来判断哪一行是日志的第一行,在日期时间后面的日志都属于同一条日志。除非我们看见下一个日期时间的出现,才是下一条日志的开始。
[2020-05-24 12:13:10] "/home/tu/demo.py"
Traceback (most recent call last):
File "demo.py", line 1, in <module>
1/0
ZeroDivisionError: integer division or modulo by zero
- 输入数据校验。在 Web 服务中,我们常常需要对输入的内容进行校验,比如要求输入 6 位数字,我们可以使用
\d{6}来校验。如果用户输入的是 6 位以上的数字呢?在这种情况下,如果不去要求用户录入的 6 位数字必须是行的开头或结尾,就算验证通过了,结果也可能不对。比如下面的示例,在不加行开始和结束符号时,用户输入了 7 位数字,也是能校验通过的:
import re
re.search('\d{6}', "1234567") is not None
# True <-- 能匹配上 (包含6位数字)
re.search('^\d{6}', "1234567") is not None
# True <-- 能匹配上 (以6位数字开头)
re.search('\d{6}$', "1234567") is not None
# True <-- 能匹配上 (以6位数字结尾)
re.search('^\d{6}$', "1234567") is not None
# False <-- 不能匹配上 (只能是6位数字)
re.search('^\d{6}$', "123456") is not None
# True <-- 能匹配上 (只能是6位数字)
在多行模式下,^ 和 $ 符号可以匹配每一行的开头或结尾。大部分实现默认不是多行匹配模式(但也有例外,比如 Ruby 中默认是多行模式)。
- 所以对于校验输入数据来说,一种更严谨的做法是,使用
\A和\z(Python 中使用 \Z) 来匹配整个文本的开头或结尾 - 解决这个问题还有一种做法,我们可以在使用正则校验前,先判断一下字符串的长度,如果不满足长度要求,那就不需要再用正则去判断了。相当于你用正则解决主要的问题,而不是所有问题,这也是前面说的使用正则要克制
3 环视( Look Around)
环视:要求匹配部分的 前面 或 后面 要 满足(或不满足)某种规则,有些地方也称环视为零宽断言
举个栗子 邮政编码的规则是由 6 位数字组成。写出一个正则提取文本中的邮政编码。根据规则,我们很容易就可以写出邮编的组成
\d{6}。我们可以使用下面的文本进行测试130400 满足要求 465441 满足要求 4654000 长度过长 138001380002 长度过长
我们发现,7 位数的前 6 位也能匹配上,12 位数匹配上了两次,这显然是不符合要求的。也就是说,除了文本本身组成符合这 6 位数的规则外,这 6 位数左边或右边都不能是数字。正则是通过环视来解决这个问题的。
解决这个问题的正则有 4 种,左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思:
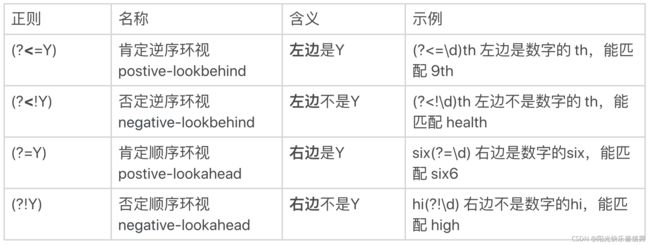
针对刚刚邮编的问题,就可以写成左边不是数字,右边也不是数字的 6 位数的正则:(?
单词边界用环视表示
你可以思考一下,表示单词边界的 \b 如果用环视的方式来写,应该是怎么写呢?
这个问题其实比较简单,单词可以用 \w+ 来表示,单词的边界其实就是那些不能组成单词的字符,即左边和右边都不能是组成单词的字符。比如下面这句话:the little cat is in the hat
the 左侧是行首,右侧是空格,hat 右侧是行尾,左侧是空格,其它单词左右都是空格。所有单词左右都不是 \w。
(? 表示左边不能是单词组成字符,(?!\w) 右边不能是单词组成字符,即 \b\w+\b 也可以写成 (?
环视与子组
1.3 “分组与引用”相关的内容中涉及了括号()。环视中虽然也有括号,但不会保存成子组。
保存成子组的一般是匹配到的文本内容,后续用于替换等操作,而环视是表示对文本左右环境的要求,即环视只匹配位置,不匹配文本内容。
4 小结
有左尖括号代表看左边,没有尖括号是看右边,而感叹号是非的意思
补充练习
前面我们用正则分组引用来实现替换重复出现的单词,其实之前写的正则是不严谨的,在一些场景下,其实是不能正常工作的:
the little cat cat2 is in the hat hat2, we like it.
需要注意一下,文本中 cat 和 cat2,还有 hat 和 hat2 其实是不同的单词。你应该能想到在 \w+ 左右加上单词边界 \b 来解决这个问题。可以试一下,真的能像期望的那样工作么?也就是说,在分组引用时,前面的断言还有效么?
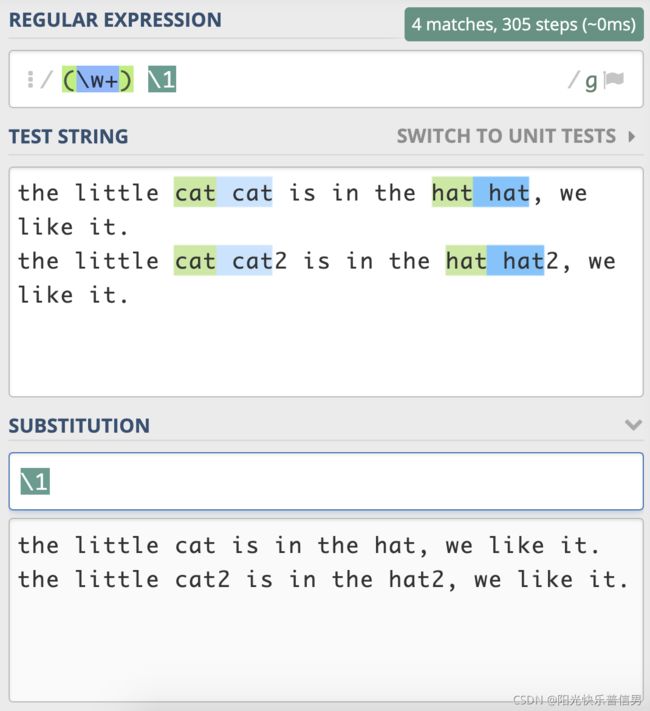
参考写法:
\b(\w+)\s\1\b, 测试链接https://regex101.com/
1.6 转义:正则中转义需要注意哪些问题?
转义对我们来说都不算陌生,编程的时候,使用到字符串时,双引号里面如果再出现双引号,我们就可以通过转义来解决。就像下面这样:
str = "How do you spell the word \"regex\"?"
但正则中什么时候需要转义,什么时候不用转义,在真正使用的时候可能会遇到这些麻烦。
1 转义字符(Escape Character)
转义序列通常有两种功能:
- 编码 无法用字母表直接表示的特殊数据
- 表示 无法直接键盘录入的字符(如回车符)
我们针对第二种情况,转义字符自身和后面的字符看成一个整体,用来表示某种含义。
最常见的例子是,C 语言中用反斜线字符“\”作为转义字符,来表示那些不可打印的 ASCII 控制符。另外,在 URI 协议中,请求串中的一些符号有特殊含义,也需要转义,转义字符用的是百分号“%”。之所以把这个字符称为转义字符,是因为它后面的字符,不是原来的意思了。
在日常工作中经常会遇到转义字符,比如我们在 shell 中删除文件,如果文件名中有 * 号,我们就需要转义,此时我们能看出,使用了转义字符后,* 号就能放进文件名里了。
rm access_log* # 删除当前目录下 access_log 开头的文件
rm access_log\* # 删除当前目录下名字叫 access_log* 的文件
再比如我们在双引号中又出现了双引号,这时候就需要转义了,转义之后才能正常表示双引号,否则会报语法错误。如下,引号中的 Hello World! 也是含有引号的。
print "tom said \"Hello World!\" to the crowd."
下面是一些常见的转义字符以及含义。
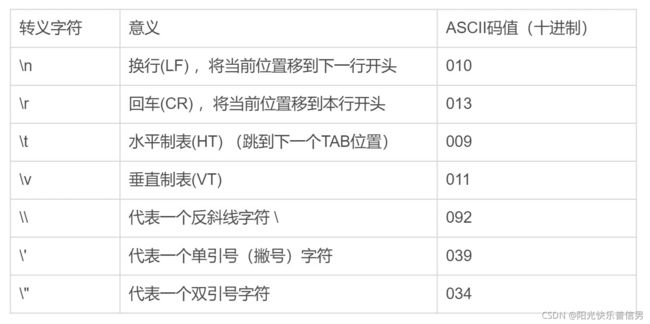
2 字符串转义和正则转义
说完了转义字符,我们再来看正则中的转义。正则中也是使用反斜杠进行转义的。
一般来说,正则中 \d 代表的是单个数字,但如果我们想表示成 反斜杠和字母 d,这时候就需要进行转义,写成 \\d,这个就表示反斜杠后面紧跟着一个字母 d。
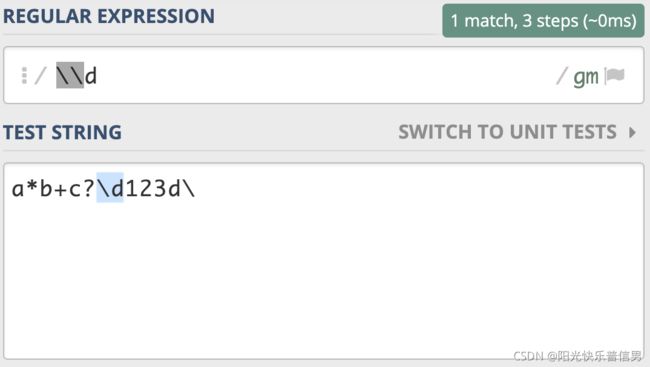
刚刚的反斜杠和 d 是连续出现的两个字符,如果你想表示成反斜杠或 d,可以用管道符号或中括号来实现,比如 \|d 或 [\d]。
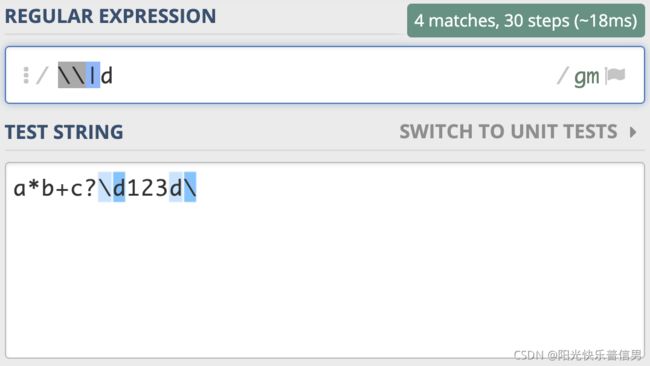
使用 Python3 测试:
import re
re.findall('\\|d', 'a*b+c?\d123d\') # 字符串没转义"反斜杠"
# ———————————————————————————————————————————————
File "", line 1
re.findall('\\|d', 'a*b+c?\d123d\')
^
SyntaxError: EOL while scanning string literal
# ———————————————————————————————————————————————
re.findall('\\|d', 'a*b+c?\\d123d\\')
# []
为什么转义了还不行呢?我们来把正则表达式部分精简一下,看看两个反斜杠在正则中是什么意思。
import re
re.findall('\\', 'a*b+c?\\d123d\\')
# ———————————————————————————————————————————————
Traceback (most recent call last):
省去部分信息
re.error: bad escape (end of pattern) at position 0
# ———————————————————————————————————————————————
可以发现,正则部分写的两个反斜杠 ,Python3 处理的时候会报错,认为是转义字符,即认为是单个反斜杠,如果你再进一步测试在正则中写单个反斜杠,你会发现直接报语法错误,你可以自行尝试。
那如何在正则中正确表示“反斜杠”呢?答案是写四个反斜杠。
import re
re.findall('\\\\', 'a*b+c?\\d123d\\')
# ['\\', '\\']
 我lay了你呢= =
我lay了你呢= =
转义过程解析:在程序使用过程中,从输入的字符串到正则表达式,其实有两步转换过程,分别是字符串转义和正则转义。
正则中正确表示“反斜杠”具体的过程:我们输入的字符串,四个反斜杠 \\,经过第一步字符串转义,它代表的含义是两个反斜杠 \;这两个反斜杠再经过第二步正则转义,它就可以代表单个反斜杠 \了。

那在真正使用的时候,有没有更简单的方法呢?
有的,尽量使用原生字符串,在 Python 中在正则前面加上小写字母 r 来表示,加r之后相当于r'xxxx‘引号里的内容完全当成字符串转义来看了!
import re
re.findall(r'\\', 'a*b+c?\\d123d\\')
# ['\\', '\\']
通俗解释:正则转义和字符串转义
3 正则中元字符的转义
量词的转义
在前面的内容中,我们讲了很多元字符,相信你一定都还记得。如果现在我们要查找比如星号(*)、加号(+)、问号(?)本身,而不是元字符的功能,这时候就需要对其进行转义,直接在前面加上反斜杠就可以了。
import re
re.findall('\+', '+')
# ['+']
括号的转义
在正则中方括号 [] 和 花括号 {} 只需转义开括号,但圆括号 () 两个都要转义。https://regex101.com/r/kJfvd6/1
import re
re.findall('\(\)\[]\{}', '()[]{}')
# ['()[]{}']
re.findall('\(\)\[\]\{\}', '()[]{}') # 方括号和花括号都转义也可以
# ['()[]{}']
使用函数消除元字符特殊含义
也可以使用编程语言自带的转义函数来实现转义,以 Python 转义为例:
import re
re.escape('\d') # 反斜杠 和 字母d 转义
# '\\\\d'
re.findall(re.escape('\d'),'\d')
# ['\\d']
re.escape('[+]') # 中括号 和 加号
# '\\[\\+\\]'
re.findall(re.escape('[+]'), '[+]')
# ['[+]']
转义函数re.escape可以将整个文本转义,一般用于转义用户输入的内容,即把这些内容看成普通字符串去匹配,但你还是得好好注意一下,如果使用普通字符串查找能满足要求,就不要使用正则,因为它简单不容易出问题。
下面是一些其他编程语言对应的转义函数:

字符组中的转义
书写正则的时候,在字符组中,如果有过多的转义会导致代码可读性差。
在字符组里只有 3 种情况需要转义:
- 脱字符
^在中括号中,且在第一个位置需要转义:
import re
re.findall(r'[^ab]', '^ab') # 转义前代表"非"
# ['^']
re.findall(r'[\^ab]', '^ab') # 转义后代表普通字符
# ['^', 'a', 'b']
- 中划线在中括号中,且不在首尾位置:
import re
re.findall(r'[a-c]', 'abc-') # 中划线在中间,代表"范围"
# ['a', 'b', 'c']
re.findall(r'[a\-c]', 'abc-') # 中划线在中间,转义后的
# ['a', 'c', '-']
re.findall(r'[-ac]', 'abc-') # 在开头,不需要转义
# ['a', 'c', '-']
re.findall(r'[ac-]', 'abc-') # 在结尾,不需要转义
# ['a', 'c', '-']
- 右括号在中括号中,且不在首位:
import re
re.findall(r'[]ab]', ']ab') # 右括号不转义,在首位
# [']', 'a', 'b']
re.findall(r'[a]b]', ']ab') # 右括号不转义,不在首位
# [] # 匹配不上,因为含义是 a后面跟上b]
re.findall(r'[a\]b]', ']ab') # 转义后代表普通字符
# [']', 'a', 'b']
4 字符组中其它的元字符
一般来说如果我们要想将元字符(.*+?() 之类)表示成它字面上本来的意思,是需要对其进行转义的,但如果它们出现在字符组中括号里,可以不转义。这种情况,一般都是单个长度的元字符,比如点号(.)、星号(*)、加号(+)、问号(?)、左右圆括号等。它们都不再具有特殊含义,而是代表字符本身。但如果在中括号中出现 \d 或 \w 等符号时,他们还是元字符本身的含义。
import re
re.findall(r'[.*+?()]', '[.*+?()]') # 单个长度的元字符
re.findall('[.*+?()]', '[.*+?()]') # 单个长度的元字符
# ['.', '*', '+', '?', '(', ')']
re.findall(r'[\d]', 'd12\\') # \w,\d等在中括号中还是元字符的功能
re.findall('[\d]', 'd12\\') # \w,\d等在中括号中还是元字符的功能
# ['1', '2'] # 匹配上了数字,而不是反斜杠\和字母d
5 小结
补充练习
解析正则过程——文本部分是反斜杠,n,换行,反斜杠四个部分组成。正则部分分别是 1 到 4 个反斜杠和字母 n,用Python3 写了 4 个例子:
import re
re.findall('\n', '\\n\n\\')
# ['\n'] # 找到了换行符
re.findall('\\n', '\\n\n\\')
# ['\n'] # 找到了换行符
re.findall('\\\n', '\\n\n\\')
# ['\n'] # 找到了换行符
re.findall('\\\\n', '\\n\n\\')
# ['\\n'] # 找到了反斜杠和字母n
原字符串中,共包含四个字符,第一个字符是 \,第二个是字母n,第三个是换行符\n,第四个是 \
四个正则表达式的构造字符串:
- 第一个字符转义后是换行符(正则转义后还是换行符)
- 第二个字符转义后是
\和n字母(正则转义后是换行符) - 第三个字符转义后是
\和换行符\n(正则转义后,单个换行符无意义,只剩下换行符) - 第四个字符转义后是
\\和字母n(正则转义后为一个斜杠和字母n)。
前三个都是找到了 换行符,第四个找到了 前两个字符的组合。
1.7 正则有哪些常见的流派及其特性?
了解正则的演变过程是很有必要的。因为一旦了解了正则的演变过程之后,就能够更加正确地去使用正则,尤其是在 Linux 系统中。
举个栗子 如果你在 Linux 系统的一些命令行中使用正则,比如使用 grep 过滤内容的时候,你可能会发现结果非常诡异,在 grep 命令中,使用正则\d+取不到数据,甚至在 egrep 中输出了英文字母 d 那一行。菜鸟教程:Linux egrep命令

这个执行结果的原因就和正则的演变有着密不可分的关系,请看分晓。
1 正则表达式简史
正则表达式的起源,可以追溯到,早期神经系统如何工作的研究。在 20 世纪 40 年代,有两位神经生理学家(Warren McCulloch 和 Walter Pitts),研究出了一种用数学方式来描述神经网络的方法。
1956 年,一位数学家(Stephen Kleene)发表了一篇标题为《神经网络事件表示法和有穷自动机》的论文。这篇论文描述了一种叫做“正则集合(Regular Sets)”的符号。
随后,大名鼎鼎的 Unix 之父 Ken Thompson 于 1968 年发表了文章《正则表达式搜索算法》,并且将正则引入了自己开发的编辑器 qed,以及之后的编辑器 ed 中,然后又移植到了大名鼎鼎的文本搜索工具 grep 中。自此,正则表达式被广泛应用到 Unix 系统或类 Unix 系统 (如 macOS、Linux) 的各种工具中。
随后,由于正则功能强大,非常实用,越来越多的语言和工具都开始支持正则。 不过遗憾的是,由于没有尽早确立标准,导致各种语言和工具中的正则虽然功能大致类似,但仍然有不少细微差别。
于是,诞生于 1986 年的 POSIX 开始进行标准化的尝试。POSIX作为一系列规范,定义了 Unix 操作系统应当支持的功能,其中也包括正则表达式的规范。因此,Unix 系统或类 Unix 系统上的大部分工具,如 grep、sed、awk 等,均遵循该标准。我们把这些遵循 POSIX 正则表达式规范的正则表达式,称为 POSIX 流派的正则表达式。
在 1987 年 12 月,Larry Wall 发布了 Perl 语言第一版,因其功能强大一票走红,所引入的正则表达式功能大放异彩。之后 Perl 语言中的正则表达式不断改进,影响越来越大。于是在此基础上,1997 年又诞生了PCRE——Perl 兼容正则表达式(Perl Compatible Regular Expressions)。
PCRE 是一个兼容 Perl 语言正则表达式的解析引擎,是由 Philip Hazel 开发的,为很多现代语言和工具所普遍使用。除了 Unix 上的工具遵循 POSIX 标准,PCRE 现已成为其他大部分语言和工具隐然遵循的标准。
之后,正则表达式在各种计算机语言或各种应用领域得到了更为广泛的应用和发展。
目前正则表达式主要有两大流派(Flavor):
- POSIX 流派
- PCRE 流派
2 正则表达式流派
POSIX 流派
POSIX 规范定义了正则表达式的两种标准:
- BRE 标准(Basic Regular Expression 基本正则表达式)
- ERE 标准(Extended Regular Expression 扩展正则表达式)
早期 BRE 与 ERE 标准的主要区别:
- BRE 标准不支持量词问号和加号,也不支持多选分支结构管道符
- BRE 标准在使用花括号,圆括号时要转义才能表示特殊含义
BRE 标准用起来这么不爽,于是有了 ERE 标准。
- ERE 标准在使用花括号,圆括号时不需要转义了,还支持了问号、加号 和 多选分支。
我们现在使用的 Linux 发行版,大多都集成了 GNU 套件。GNU 在实现 POSIX 标准时,做了一定的扩展,主要有以下三点扩展。
- GNU BRE 支持了
+、?,但转义了才表示特殊含义,即需要用\+、\?表示 - GNU BRE 支持管道符多选分支结构,同样需要转义,即用
\|表示 - GNU ERE 也支持使用反引用,和 BRE 一样,使用
\1、\2…\9表示。
BRE 标准和 ERE 标准的详细区别如下图,浅黄色背景是两者不同的地方,三处蓝色字体是 GNU 扩展。

一句话,GNU BRE 和 GNU ERE 它们的功能特性并没有太大区别,区别是在于部分语法层面上,主要是一些字符要不要转义
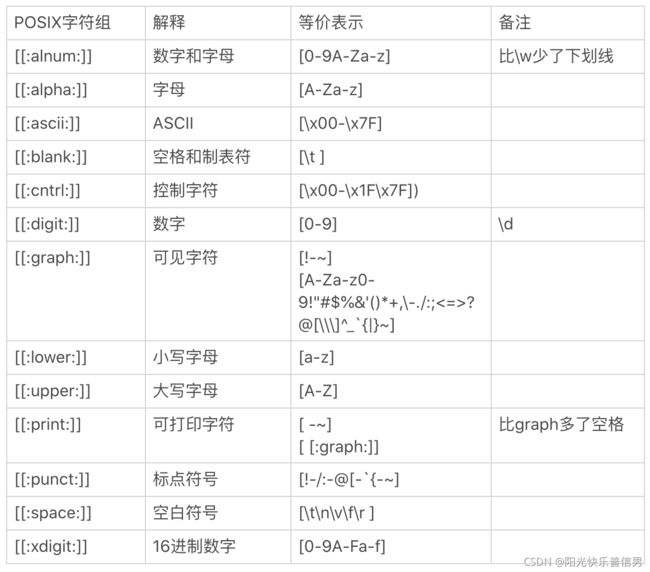
POSIX 字符组
POSIX 流派还有一个特殊的地方,就是有自己的字符组,叫 POSIX 字符组。
这个类似于我们之前学习的 \d 表示数字,\s 表示空白符等,POSIX 中也定义了一系列的字符组。具体的清单和解释如下所示:
PCRE 流派
除了 POSIX 标准外,还有一个 Perl 分支,也就是我们现在熟知的 PCRE。随着 Perl 语言的发展,Perl 语言中的正则表达式功能越来越强悍,为了把 Perl 语言中正则的功能移植到其他语言中,PCRE 就诞生了。
目前大部分常用编程语言都是源于 PCRE 标准,这个流派显著特征是有\d、\w、\s 这类字符组简记方式。
不过,虽然 PCRE 流派是从 Perl 语言中衍生出来的,但与 Perl 语言中的正则表达式在语法上还是有一些细微差异,比如 PHP 的 preg 正则表达式 (Perl Regular Expression) 与 Perl 正则表达存在一些差异。
考虑到目前绝大部分常用编程语言所采用的正则引擎,基本都属于 PCRE 流派的现实情况,下面主要研究 PCRE流派。前面,对于正则表达式语法元素的解释都是以 PCRE 流派为准。
PCRE 流派的兼容问题
虽然 PCRE 流派是与 Perl 正则表达式相兼容的流派,但这种兼容在各种语言和工具中还存在程度上的差别,这包括了直接兼容与间接兼容两种情况。
而且,即便是直接兼容,也并非完全兼容,还是存在部分不兼容的情况。原因也很简单,Perl 语言中的正则表达式在不断改进和升级之中,其他语言和工具不可能完全做到实时跟进与更新。
- 直接兼容,PCRE 流派中与 Perl 正则表达式直接兼容的语言或工具。比如 Perl、PHP preg、PCRE 库等,一般称之为 Perl 系
- 间接兼容,比如 Java 系(包括 Java、Groovy、Scala 等)、Python 系(包括 Python2 和 Python3)、JavaScript 系(包括原生 JavaScript 和扩展库 XRegExp)、.Net 系(包括 C#、VB.Net 等)等
在 Linux 中使用正则
在遵循 POSIX 规范的 UNIX/LINUX 系统上,按照 BRE 标准 实现的有 grep、sed 和 vi/vim 等,而按照 ERE 标准 实现的有 egrep、awk 等。
在 UNIX/LINUX 系统里 PCRE 流派与 POSIX 流派的对比,如下。
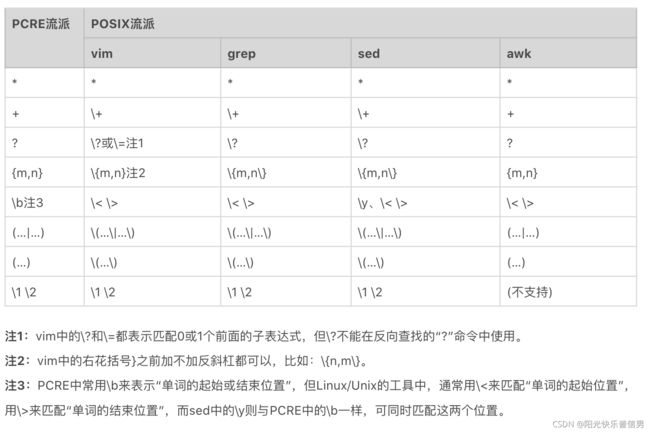
刚刚我们提到了工具对应的实现标准,其实有一些工具实现同时兼容多种正则标准,比如前面我们讲到的 grep 和 sed。如果在使用时加上 -E 选项,就是使用 ERE 标准;如果加上 -P 选项,就是使用 PCRE 标准。
# 使用 ERE 标准
grep -E '[[:digit:]]+' access.log
# 使用 PCRE 标准
grep -P '\d+' access.log
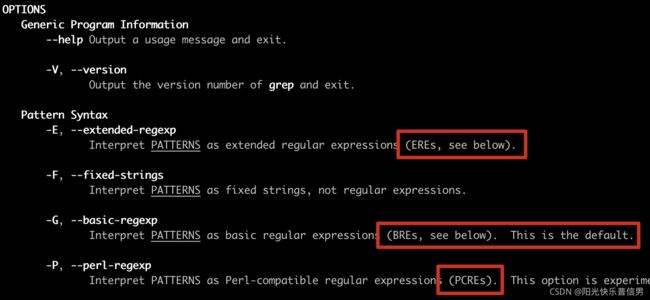
在使用具体命令时,如何知道属于哪个流派呢?
在 Linux 系统中有个 man 命令可以帮助我们。我在 macOS 上执行 man grep ,可以看到选项 -G 是指定使用 BRE 标准(默认),-E 是 ERE 标准,-P 是 PCRE 标准。
所以,在使用具体工具时, 通过这个方法查一下命令的说明就好了。
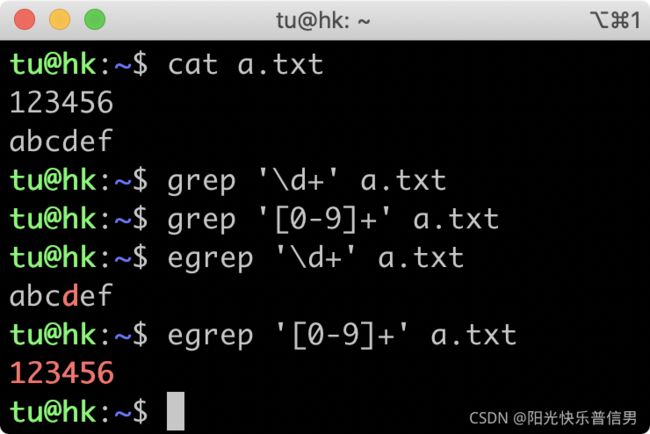
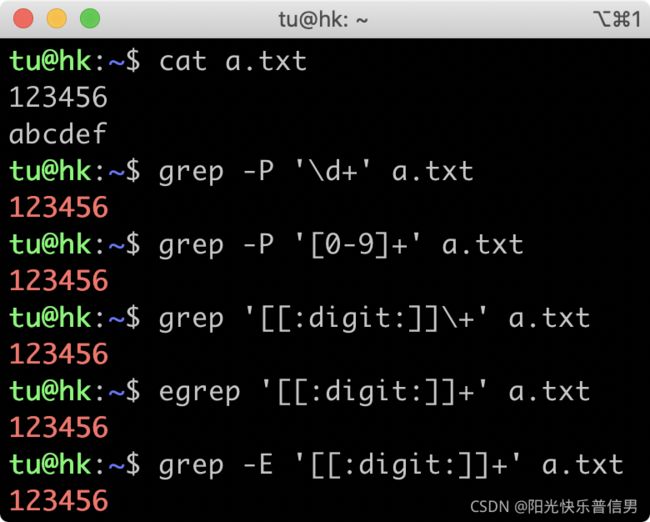
再看开头的问题。在 grep 中使用 \d+ 查找不到结果,是因为 grep 属于 BRE 流派,不支持 \d 来表示数字,加号也要转义才能表示量词的一到多次,所以无法找出数字那一行。
- 如果你一定要用 BRE 流派,可以通过使用 POSIX 字符组 和 转义加号 来实现
- egrep 属于 ERE 流派,也不支持
\d,\d相当于字母 d,所以找到了字母那一行
小结
GNU ERE 名称中有两个 E,不需要再转义。而 GNU BRE 只有一个 E,使用时“花圆问管加”时都要转义
补充练习
在 Linux 上使用 grep 命令,分别实现使用不同的标准(即 BRE、ERE、PCRE ),来查找含有 ftp、http 或 https 的行。
https://time.geekbang.org
ftp://ftp.ncbi.nlm.nih.gov
www.baidu.com
www.ncbi.nlm.nih.gov
参考写法:
## BRE
grep '\(f\|ht\)tps\?.*' a.txt
## ERE
grep -E '(f|ht)tps?.*' a.txt
## PCRE
grep -P '(f|ht)tps?.*' a.txt
2 应用篇
2.1 应用1:正则如何处理 Unicode 编码的文本?
如果你需要使用正则处理中文,可以好好了解一下这些内容。
1 Unicode 基础知识
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字进行了整理、编码。Unicode 使计算机呈现和处理文字变得简单。
Unicode 至今仍在不断增修,每个新版本都加入更多新的字符。目前 Unicode 最新的版本为 2020 年 3 月 10 日公布的 13.0.0,已经收录超过 14 万个字符。
现在的 Unicode 字符分为 17 组编排,每组为一个平面(Plane),而每个平面拥有 65536(即 2 的 16 次方)个码值(Code Point)。然而,目前 Unicode 只用了少数平面,我们用到的绝大多数字符都属于第 0 号平面,即 BMP 平面。除了 BMP 平面之外,其它的平面都被称为补充平面。
关于各个平面的介绍,如下。
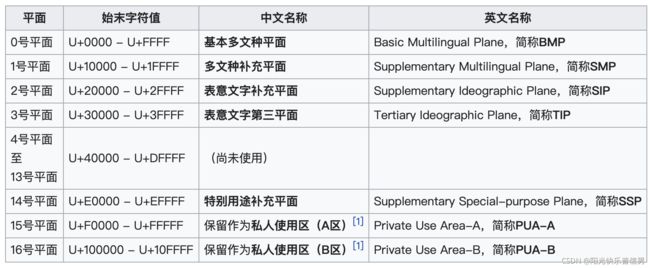
Unicode 标准也在不断发展和完善。目前,使用 4 个字节的编码表示一个字符,就可以表示出全世界所有的字符。
那么 Unicode 在计算机中如何存储和传输的呢?
- Unicode 相当于规定了字符对应的码值,这个码值得编码成字节的形式去传输和存储。最常见的编码方式是 UTF-8,另外还有 UTF-16,UTF-32 等。UTF-8 之所以能够流行起来,是因为其编码比较巧妙,采用的是变长的方法。也就是一个 Unicode 字符,在使用 UTF-8 编码表示时占用 1 到 4 个字节不等。最重要的是 Unicode 兼容 ASCII 编码,在表示纯英文时,并不会占用更多存储空间。而汉字呢,在 UTF-8 中,通常是用三个字节来表示。
>>> u'正'.encode('utf-8')
b'\xe6\xad\xa3'
>>> u'则'.encode('utf-8')
b'\xe5\x88\x99'
下面是 Unicode 和 UTF-8 的转换规则。

2 Unicode 中的正则
大概了解了 Unicode 的基础知识后,下面是在用 Unicode 中可能会遇到的坑,以及其中的点号匹配和字符组匹配的问题。
编码问题的坑
如果你在编程语言中使用正则,编码问题可能会让正则的匹配行为很奇怪。先说结论,在使用时一定尽可能地使用 Unicode 编码 。
如果你需要在 Python 语言中使用正则,我建议你使用 Python3。如果你不得不使用 Python2,一定要记得使用 Unicode 编码。在 Python2 中,一般是以 u 开头来表示 Unicode。如果不加 u,会导致匹配出现问题。
下面是我在 macOS 上做的测试,“时间”这两个汉字表示成了 UTF-8 编码,正则不知道要每三个字节看成一组,而是把它们当成了 6 个单字符。
# 测试环境 macOS/Linux,Python 2.7
>>> import re
>>> re.compile(r'[时间]', re.DEBUG)
in
literal 230
literal 151
literal 182
literal 233
literal 151
literal 180
<_sre.SRE_Pattern object at 0x1053e09f0>
>>> re.compile(ur'[时间]', re.DEBUG)
in
literal 26102
literal 38388
<_sre.SRE_Pattern object at 0x1053f8710>
我们再看一下 “极客” 和 “时间” 这两个词语对应的 UTF-8 编码。
这两个词语都含有 16 进制表示的 e6,而 GBK 编码时都含有 16 进制的 bc,所以才会出现前面的表现。下面是查看文本编码成 UTF-8 或 GBK 方式,以及编码的结果:
# UTF-8
>>> u'极客'.encode('utf-8')
'\xe6\x9e\x81\xe5\xae\xa2' # 含有 e6
>>> u'时间'.encode('utf-8')
'\xe6\x97\xb6\xe9\x97\xb4' # 含有 e6
# GBK
>>> u'极客'.encode('gbk')
'\xbc\xab\xbf\xcd' # 含有 bc
>>> u'时间'.encode('gbk')
'\xca\xb1\xbc\xe4' # 含有 bc
因此在使用时,一定要指定 Unicode 编码,这样就可以正常工作了。
# Python2 或 Python3 都可以
>>> import re
>>> re.search(ur'[时间]', u'极客') is not None
False
>>> re.findall(ur'[时间]', u'极客')
[]
点号匹配
点号 可以匹配除了换行符以外的任何字符,但之前我们接触的大多是单字节字符。在 Unicode 中,点号可以匹配上 Unicode 字符么?这个其实情况比较复杂,不同语言支持的也不太一样。 Python 测试的结果如下:
# Python 2.7
>>> import re
>>> re.findall(r'^.$', '学')
[]
>>> re.findall(r'^.$', u'学')
[u'\u5b66']
>>> re.findall(ur'^.$', u'学')
[u'\u5b66']
# Python 3.7
>>> import re
>>> re.findall(r'^.$', '学')
['学']
>>> re.findall(r'(?a)^.$', '学')
['学']
(?a)是一种匹配模式,可以查询下 Python 文档,看下re模块的说明。指的是ASCII模式,可以让\w等只匹配 ASCII https://docs.python.org/3.8/library/re.html#module-re

字符组匹配
Unicode 属性
在正则中使用 Unicode,还可能会用到 Unicode 的一些属性。这些属性把 Unicode 字符集划分成不同的字符小集合。
在正则中常用的有三种,分别是按功能划分 的Unicode Categories(有的也叫 Unicode Property),比如标点符号,数字符号;按连续区间划分的 Unicode Blocks,比如只是中日韩字符;按书写系统划分的 Unicode Scripts,比如汉语中文字符。

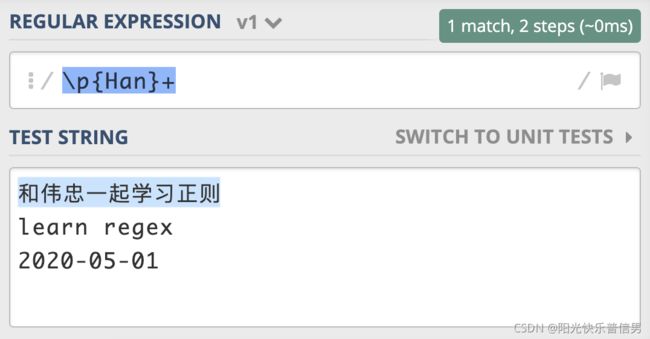
在正则中如何使用这些 Unicode 属性呢?在正则中,这三种属性在正则中的表示方式都是\p{属性}。比如,我们可以使用 Unicode Script 来实现查找连续出现的中文:https://regex101.com/r/Bgt4hl/1
其中,Unicode Blocks 在不同的语言中记法有差异,比如 Java 需要加上 In 前缀,类似于 \p{InBopomofo} 表示注音字符。
表情符号
表情符号其实是“图片字符”,最初与日本的手机使用有关,在日文中叫“绘文字”,在英文中叫 emoji,但现在从日本流行到了世界各地:完整的表情列表

这些表情符号有如下特点:
- 许多表情不在 BMP 内,码值超过了 FFFF。使用 UTF-8 编码时,普通的 ASCII 是 1 个字节,中文是 3 个字节,而有一些表情需要 4 个字节来编码
- 这些表情分散在 BMP 和各个补充平面中,要想用一个正则来表示所有的表情符号非常麻烦,即便使用编程语言处理也同样很麻烦
- 一些表情现在支持使用颜色修饰(Fitzpatrick modifiers),可以在 5 种色调之间进行选择。这样一个表情其实就是 8 个字节了
关于表情颜色修饰的 5 种色调:

下面是使用 IPython 测试颜色最深的点赞表情,在 macOS 上的测试结果:它是由 8 个字节组成,这样用正则处理起来就很不方便了。因此,在处理表情符号时,不建议你使用正则来处理。 你可以使用专门的库,这样做一方面代码可读性更好,另一方面是表情在不断增加,使用正则的话不好维护,会给其它同学留坑。而使用专门的库可以通过升级版本来解决这个问题。

3 小结
补充练习
在正则 xy{3} 中,你应该知道, y 是重复 3 次,那如果正则是“极客{3}”的时候,代表是“客”这个汉字重复 3 次,还是“客”这个汉字对应的编码最后一个字节重复 3 次呢?如果是重复的最后一个字节,应该如何解决?
参考回答:
- 客重复3次,如果重复的是最后一个字节,就这样‘极(客){3}’, 给客加个括号分组。
import re
a=re.findall(r'极客{3}','极客客客') # ['极客客客']
b=re.findall(r'极(客){3}','极客客客') # ['客']
2.2 应用2:如何在编辑器中使用正则完成工作?
以 Sublime Text 3 为例,分享一些在编辑器里的强大功能,这些功能在 Sublime Text、Atom、VS Code、JetBrains 系列(IntelliJ IDEA/PyCharm/Goland 等) 中都是支持的。
1 编辑器功能
光标移动和文本选择
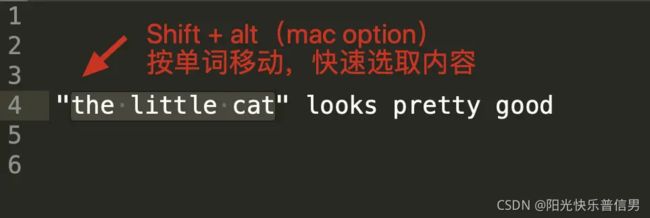
在常见的编辑器、IDE、甚至 Chrome 等浏览器中,我们编辑文本时,使用键盘的左右箭头移动光标,可以按住 Shift 键来选中文本。在左右移动时,如果你按住 Alt(macOS 的 option),你会发现光标可以“按块移动”,快速移动到下一个单词。两种方式组合起来,你可以快速选择引号里面的内容。
多焦点编辑
在 IDE 中,我们如果想对某个变量或函数重命名,通常可以使用重构(refactor)功能。但如果处理的不是代码,而是普通文本,比如 JSON 字符串的时候,就没法这么用了。不过现在很多编辑器都提供了多焦点编辑的功能。
比如选择单词 route 之后,点击菜单 Find -> Quick Find All 就可以选中所有的 route 了:
竖向编辑
在编辑多行时,如果我们需要编辑的内容都是纵向上同一个位置,就可以使用 Alt (macOS 上是 Option)加上鼠标拖拽的方式来选择(或者尝试按下鼠标中键拖拽)。
2 在编辑器中使用正则
正则是一种文本处理工具,常见的功能有文本验证、文本提取、文本替换、文本切割等。有一些地方说的正则匹配,其实是包括了校验和提取两个功能。
- 校验 常用于验证整个文本的组成是不是符合规则,比如密码规则校验
- 提取 则是从大段的文本中抽取出需要的内容,比如提取网页上所有的链接。
在使用正则进行内容提取时,要做到不能提取到错误的内容(准确性),不能漏掉正确的内容(完备性)。
内容提取
下图是编辑器 Sublime Text 查找界面的介绍
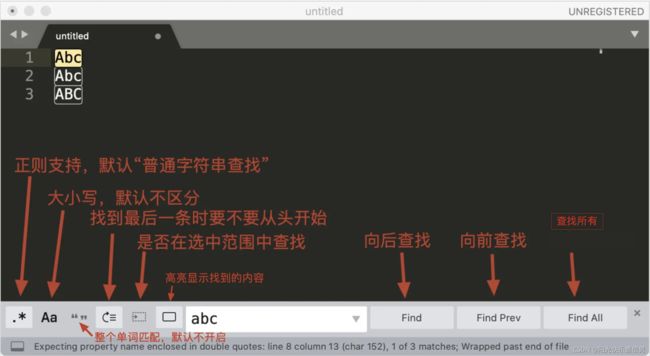
我们来尝试使用 sublime 提取文本中所有的邮箱地址,这里并不要求你写出一个完美的正则,因此演示时,使用\S+@\S+\.\S+ 这个正则。另外我们可以加上环视,去掉尾部的分号。你可以在这里随机生成一些邮箱用于测试
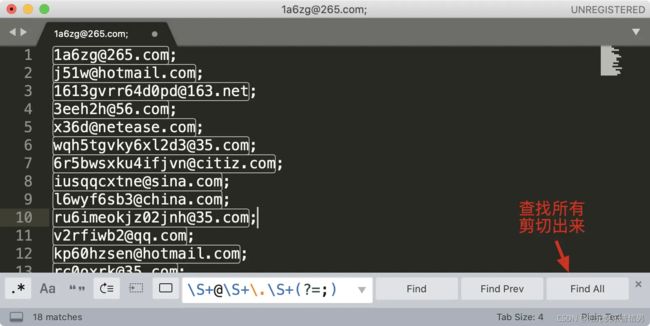
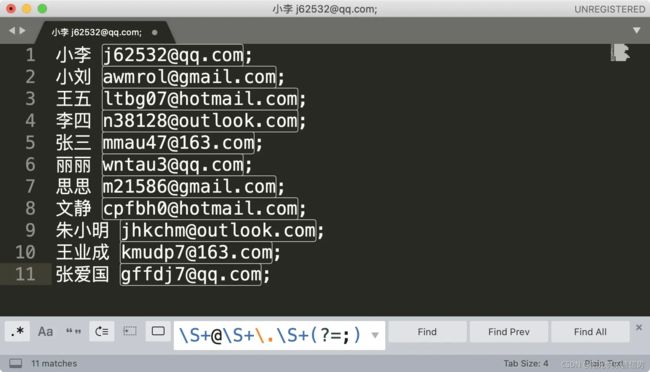
你可能会有疑问,我直接找到最后的分号,然后删除掉不就可以了么?这个例子是没问题的,但如果文本中除了邮箱之外,还有其它的内容这样就不行了,这也是正则比普通文本强大的地方
内容替换
下图是编辑器 Sublime Text 替换界面的介绍
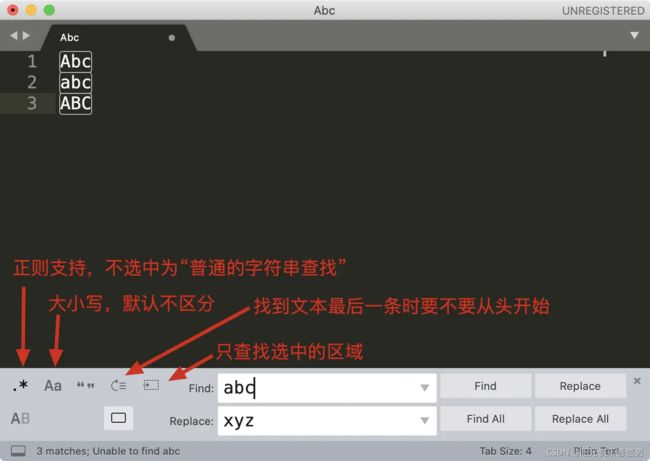
同样是上面邮箱的例子,我们可以使用子组和引用,直接替换得到移除了分号之后的邮箱,我们还可以在邮箱前把邮箱类型加上。操作前和操作后的示意图如下:


替换和提取的不同在于,替换可以对内容进行拼接和改造,而提取是从原来的内容中抽取出一个子集,不会改变原来的内容。当然在实际应用中,可以两个结合起来一起使用。
内容验证
在编辑器中进行内容验证,本质上和内容提取一样,只不过要求编辑器中全部内容都匹配上,并且匹配次数是一次

内容切割
在编辑器中进行内容切割,本质上也和内容提取一样,用什么切割,我们就提取什么,选中全部之后,把选中的内容删除掉或者编辑成其它的字符
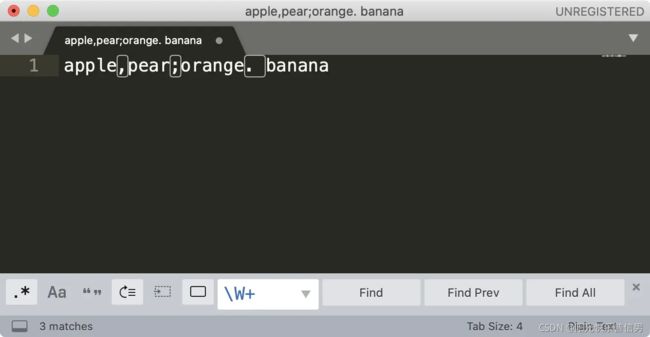
刚刚我们讲解了在 Sublime Text 中使用正则处理文本的方法,其它的编辑器或 IDE,如 Atom、VS Code、JetBrains 系列(IntelliJ IDEA/PyCharm/Goland 等)等,也都是类似的。这里给出一些主流跨平台编辑器 /IDE 对正则的支持情况。
3 小结
学习了编辑器中一些提高文本处理效率的操作方式:光标移动和选择、多焦点编辑以及竖向编辑。学会了这些,即使不使用正则,我们在编辑器中处理文本效率也会大大提高。接着通过一些示例,我们学习了在编辑器中使用正则来进行文本内容提取,内容替换等操作。正则的使用一般会和其它的方法结合起来,最终帮助我们高效地完成文本的处理工作。
补充练习:
统计一篇英文文章中每个单词出现的次数,使用 Sublime Text 等编辑器提取文章里所有的单词,处理成一行一个单词,保存到文件中,然后再使用 sort、uniq 等命令统计单词出现的次数
使用 uniq 前需要先用 sort 命令排序,uniq -c 可以统计次数
sort words.txt | uniq -c
如果想取前10名,可以继续对结果排序
sort words.txt | uniq -c | sort -nrk1 | head -n10
至于为什么要加 n、r 和 k1 你可以通过 man sort 看一下说明
uniq -c: 统计每行出现次数
sort :
-n 按数字排序
-r 逆序排序
-k1 根据-t的分割,分成几域,取第1个域排序
-t 指定分隔符,默认的分隔符为空白字符和非空白字符之间的空字符
head -n10: 取前10行数据
参考写法:
grep -Po '\w+' article.txt | sort | uniq -c | sort -nr | head -10
grep -P启用PCRE语法. (这是一个非标准扩展-甚至不是所有的GNU grep构建都支持它,因为它取决于可选的libpcre库,是否将其链接是一个编译时选项).grep -o在输出中仅发出匹配的文本,而不发出包含该文本的整行. (尽管它比-P更为广泛,但这也是非标准的.)
2.3 应用3:如何在语言中用正则让文本处理能力上一个台阶?
现代主流的编程语言几乎都内置了正则模块,很少能见到不支持正则的编程语言。学会在编程语言中使用正则,可以极大地提高文本的处理能力。
在进行文本处理时,正则解决的问题大概可以分成 4 类:
- 校验文本内容
- 提取文本内容
- 替换文本内容
- 切割文本内容
涉及的
re.函数请参考: 在python中使用正则表达式
1 校验文本内容
通常我们在网页上输入的手机号、邮箱、日期等,都需要校验。
校验的特点在于,整个文本的内容要符合正则,比如要求输入 6 位数字的时候,输入 123456abc 就是不符合要求的。以验证日期格式年月日为例,比如 2020-01-01,我们使用正则\d{4}-\d{2}-\d{2} 来验证。
在 Python 中,正则的包名是 re,验证文本可以使用 re.match 或 re.search 的方法,这两个方法的区别在于,re.match 是从开头匹配的,re.search 是从文本中找子串:
# 测试环境 Python3
>>> import re
>>> re.match(r'\d{4}-\d{2}-\d{2}', '2020-06-01')
<re.Match object; span=(0, 10), match='2020-06-01'>
# 这个输出是匹配到了,范围是从下标0到下标10,匹配结果是2020-06-01
# re.search 输出结果也是类似的
在 Python 中,校验文本是否匹配:
# 测试环境 Python3
>>> import re
>>> reg = re.compile(r'\A\d{4}-\d{2}-\d{2}\Z') # 建议先编译,提高效率
>>> reg.search('2020-06-01') is not None
True
>>> reg.match('2020-06-01') is not None # 使用match时\A可省略
True
如果不添加
\A和\Z的话,我们就可能得到错误的结果。而造成这个错误的主要原因就是,没有完全匹配,而是部分匹配。至于为什么不推荐用^和$,因为在多行模式下,它们的匹配行为会发现变化
2 提取文本内容
提取内容,就是从大段的文本中抽取出我们关心的内容。
比较常见的例子是网页爬虫,或者说从页面上提取邮箱、抓取需要的内容等。如果要抓取的是某一个网站,页面样式是一样的,要提取的内容都在同一个位置,可以使用 xpath 或 jquery 选择器 等方式,否则就只能使用正则来做了。
在 Python 中提取内容最简单的就是使用 re.findall 方法了,当有子组的时候,会返回子组的内容,没有子组时,返回整个正则匹配到的内容。下面以查找日志的年月为例,年月可以用正则 \d{4}-\d{2} 来表示:
# 没有子组时
>>> import re
>>> reg = re.compile(r'\d{4}-\d{2}')
>>> reg.findall('2020-05 2020-06')
['2020-05', '2020-06']
# 有子组时
>>> reg = re.compile(r'(\d{4})-(\d{2})')
>>> reg.findall('2020-05 2020-06')
[('2020', '05'), ('2020', '06')]
通过上面的示例你可以看到,直接使用 findall 方法时,它会把结果存储到一个 列表(数组) 中,一下返回所有匹配到的结果。如果想节约内存,可以采用迭代器的方式来处理:
>>> import re
>>> reg = re.compile(r'(\d{4})-(\d{2})')
>>> for match in reg.finditer('2020-05 2020-06'):
... print('date: ', match[0]) # 整个正则匹配到的内容
... print('year: ', match[1]) # 第一个子组
... print('month:', match[2]) # 第二个子组
...
date: 2020-05
year: 2020
month: 05
date: 2020-06
year: 2020
month: 06
3 替换文本内容
文本内容替换,通常用于对原来的文本内容进行一些调整。
在 Python 中替换相关的方法有 re.sub 和 re.subn,后者会返回替换的次数。以替换年月的格式为例,假设原始的日期格式是月日年,我们要将其处理成 xxxx 年 xx 月 xx 日的格式:
>>> import re
>>> reg = re.compile(r'(\d{2})-(\d{2})-(\d{4})')
>>> reg.sub(r'\3年\1月\2日', '02-20-2020 05-21-2020')
'2020年02月20日 2020年05月21日'
# 可以在替换中使用 \g<数字>,如果分组多于10个时避免歧义
>>> reg.sub(r'\g<3>年\g<1>月\g<2>日', '02-20-2020 05-21-2020')
'2020年02月20日 2020年05月21日'
# 返回替换次数
>>> reg.subn(r'\3年\1月\2日', '02-20-2020 05-21-2020')
('2020年02月20日 2020年05月21日', 2)
4 切割文本内容
在 Python 中切割相关的方法是 re.split。如果我们有按照任意空白符切割的需求,可以直接使用字符串的 split 方法,不传任何参数时就是按任意连续一到多个空白符切割。
>>> import re
>>> reg = re.compile(r'\W+')
>>> reg.split("apple, pear! orange; tea")
['apple', 'pear', 'orange', 'tea']
# 限制切割次数,比如切一刀,变成两部分
>>> reg.split("apple, pear! orange; tea", 1)
['apple', 'pear! orange; tea']
5 小结
补充练习
很多网页为了防止爬虫,喜欢把邮箱里面的 @ 符号替换成 # 符号,写一个正则兼容一下这种情况.
例如网页的底部可能是这样的:
联系邮箱:xxx#163.com (请把#换成@)
参考写法:
>>> import re
>>> reg = re.compile(r'(\w+)#(\w+)')
>>> reg.sub(r'\1@\2','xxx#163.com')
'[email protected]'
2.4 如何理解正则的匹配原理以及优化原则?
1 有穷状态自动机
正则之所以能够处理复杂文本,就是因为采用了有穷状态自动机(finite automaton)。
- 有穷状态:一个系统具有有穷个状态,不同的状态代表不同的意义
- 自动机:系统可以根据相应的条件,在不同的状态下进行转移。从一个初始状态,根据对应的操作(比如录入的字符集)执行状态转移,最终达到终止状态(可能有一到多个终止状态)。
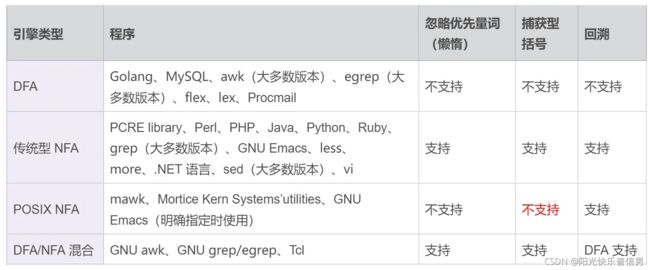
有穷自动机的具体实现称为正则引擎,主要有 DFA 和 NFA 两种,其中 NFA 又分为传统的 NFA 和 POSIX NFA。
DFA:确定性有穷自动机(Deterministic finite automaton)
NFA:非确定性有穷自动机(Non-deterministic finite automaton)
2 正则的匹配过程
在使用到编程语言时,我们经常会“编译”一下正则表达式,来提升效率,比如在 Python3 中它是下面这样的:
>>> import re
>>> reg = re.compile(r'a(?:bb)+a')
>>> reg.findall('abbbba')
['abbbba']
这个编译的过程,其实就是生成自动机的过程,正则引擎会拿着这个自动机去和字符串进行匹配。生成的自动机可能是这样的(下图是使用Regexper 工具生成,再次加工得到的)。
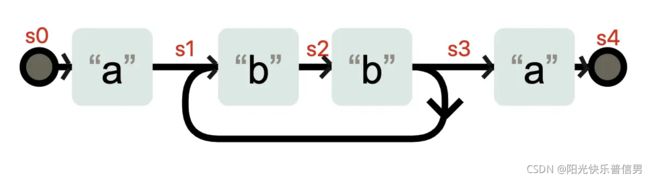
在状态 s3 时,不需要输入任何字符,状态也有可能转换成 s1。你可以理解成 a(bb)+a 在匹配了字符 abb 之后,到底在 s3 状态,还是在 s1 状态,这是不确定的。这种状态机就是非确定性有穷状态自动机(Non-deterministic finite automaton 简称 NFA)。
NFA 和 DFA 是可以相互转化的,当我们把上面的状态表示成下面这样,就是一台 DFA 状态机了,因为在 s0-s4 这几个状态,每个状态都需要特定的输入,才能发生状态变化。
3 DFA& NFA 工作机制
字符串:we study on jikeshijian app
正则:jike(zhushou|shijian|shixi)
NFA 引擎的工作方式:先看正则,再看文本,而且以正则为主导。正则中的第一个字符是 j,NFA 引擎在字符串中查找 j,接着匹配其后是否为 i ,如果是 i 则继续,这样一直找到 jike。
我们再根据正则看文本后面是不是 z,发现不是,此时 zhushou 分支淘汰。
我们接着看其它的分支,看文本部分是不是 s,直到 shijian 整个匹配上。shijian 在匹配过程中如果不失败,就不会看后面的 shixi 分支。当匹配上了 shijian 后,整个文本匹配完毕,也不会再看 shixi 分支。
假设这里文本改一下,把 jikeshijian 变成 jikeshixi,正则 shi j ian 的 j 匹配不上时 shixi 的 x,会接着使用正则 s hixi 来进行匹配,重新从 s 开始(NFA 引擎会记住这里)。
第二个分支匹配失败
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支(正则j匹配不上文本x)
text: we study on jikeshixi
^
再次尝试第三个分支
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshixi
^
DFA 引擎的工作方式:DFA 会先看文本,再看正则表达式,是以文本为主导的。在具体匹配过程中,DFA 会从 we 中的 w 开始依次查找 j,定位到 j ,这个字符后面是 i。所以我们接着看正则部分是否有 i ,如果正则后面是个 i ,那就以同样的方式,匹配到后面的 ke。
text: we study on jikeshijian
^
regex: jike(zhushou|shijian|shixi)
^
继续进行匹配,文本 e 后面是字符 s ,DFA 接着看正则表达式部分,此时 zhushou 分支被淘汰,开头是 s 的分支 shijian 和 shixi 符合要求。
然后 DFA 依次检查字符串,检测到 shijian 中的 j 时,只有 shijian 分支符合,淘汰 shixi,接着看分别文本后面的 ian,和正则比较,匹配成功。
text: we study on jikeshijian
^
regex: jike(zhushou|shijian|shixi)
^ ^
符合 淘汰
一般来说,DFA引擎 会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。也就是说 DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组。NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
4 POSIX NFA 与 传统 NFA 区别
因为传统的 NFA 引擎“急于”报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现。比如使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。
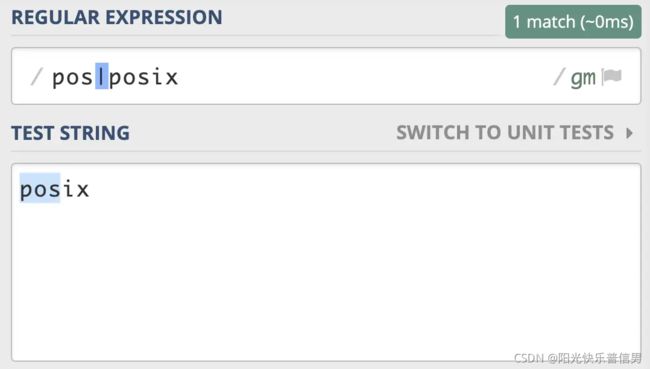
POSIX NFA 的应用很少,主要是 Unix/Linux 中的某些工具。POSIX NFA 引擎与传统的 NFA 引擎类似,但不同之处在于,POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,如果分支一样长,以最左边的为准(“The Longest-Leftmost”)。因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
我们日常面对的,一般都是 传统的 NFA,所以通常都是最左侧的分支优先,在书写正则的时候务必要注意这一点。
5 回溯
回溯是 NFA 引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能会发生回溯。
比如我们使用正则 a+ab 来匹配 文本 aab 的时候,过程是这样的,a+ 是贪婪匹配,会占用掉文本中的两个 a,但正则接着又是 a,文本部分只剩下 b,只能通过回溯,让 a+ 吐出一个 a,再次尝试。如果正则是使用 .*ab 去匹配一个比较长的字符串就更糟糕了,因为 .* 会吃掉整个字符串(不考虑换行,假设文本中没有换行),然后,你会发现正则中还有 ab 没匹配到内容,只能将 .* 匹配上的字符串吐出一个字符,再尝试,还不行,再吐出一个,不断尝试。

所以在工作中,我们要尽量不用 .* ,除非真的有必要,因为点能匹配的范围太广了,我们要尽可能精确。常见的解决方式有两种:
- 比如要提取引号中的内容时,使用 “
[^"]+” - 或者使用非贪婪的方式 “
.+?”,来减少“匹配上的内容不断吐出,再次尝试”的过程
6 优化建议
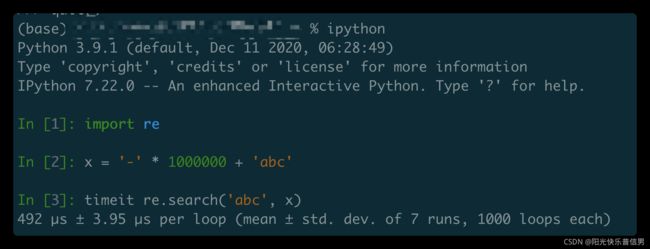
我们必须先保证正则的功能是正确的,然后再进行优化性能。
- 1.测试性能的方法
我们可以使用 ipython 来测试正则的性能,ipython 是一个 Python shell 增强交互工具,在macOS/Windows/Linux 上都可以安装使用。比如测试在字符串中查找 abc 时的时间消耗。
IPython介绍
快捷启动:终端输入ipython
In [1]: import re
In [2]: x = '-' * 1000000 + 'abc'
In [3]: timeit re.search('abc', x)
480 µs ± 8.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
- 2.提前编译好正则
编程语言中一般都有“编译”方法,我们可以使用这个方法提前将正则处理好,这样不用在每次使用的时候去反复构造自动机,从而可以提高正则匹配的性能。
>>> import re
>>> reg = re.compile(r'ab?c') # 先编译好,再使用
>>> reg.findall('abc')
['abc']
>>> re.findall(r'ab?c', 'abc') # 正式使用不建议,但测试功能时较方便
['abc']
- 3.尽量准确表示匹配范围
比如我们要匹配引号里面的内容,除了写成 “.+?” 之外,我们可以写成 “[^"]+”。使用 [^"] 要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上,再吐出的问题。
- 4.提取出公共部分
通过上面对 NFA 引擎的学习,相信你应该明白(abcd|abxy)这样的表达式,可以优化成ab(cd|xy),因为 NFA 以正则为主导,会导致字符串中的某些部分重复匹配多次,影响效率。
因此我们会知道th(?:is|at)要比this|that要快一些,但从可读性上看,后者要好一些,这个就需要用的时候去权衡,也可以添加代码注释让代码更容易理解。
类似地,如果是锚点,比如(^this|^that) is这样的,锚点部分也应该独立出来,可以写成比如^th(is|at) is的形式,因为锚点部分也是需要尝试去匹配的,匹配次数要尽可能少。
- 5.出现可能性大的放左边
由于正则是从左到右看的,把出现概率大的放左边,域名中 .com 的使用是比 .net 多的,所以我们可以写成.(?:com|net)\b,而不是.(?:net|com)\b。
- 6.只在必要时才使用子组
在正则中,括号可以用于归组,但如果某部分后续不会再用到,就不需要保存成子组。通常的做法是,在写好正则后,把不需要保存子组的括号中加上 ?: 来表示只用于归组。如果保存成子组,正则引擎必须做一些额外工作来保存匹配到的内容,因为后面可能会用到,这会降低正则的匹配性能。
- 7.警惕嵌套的子组重复
如果一个组里面包含重复,接着这个组整体也可以重复,比如 (.*)* 这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。
- 8.避免不同分支重复匹配
在多选分支选择中,要避免不同分支出现相同范围的情况,上面回溯的例子中,我们已经进行了比较详细的讲解。
7 小结
补充练习
说明下例的 NFA 引擎的匹配过程。
文本:a12
正则:^(?=[a-z])[a-z0-9]+$
首先由元字符“^”取得控制权,从位置0开始匹配,“^”匹配的就是开始位置“位置0”,匹配成功,控制权交给顺序环视“(?=[a-z])”;
“(?=[a-z])”要求它所在位置右侧必须是字母才能匹配成功,零宽度的子表达式之间是不互斥的,即同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“a”,符合要求,匹配成功,控制权交给“[a-z0-9]+”;
因为“(?=[a-z])”只进行匹配,并不将匹配到的内容保存到最后结果,并且“(?=[a-z])”匹配成功的位置是位置0,所以“[a-z0-9]+”也是从位置0开始尝试匹配的,“[a-z0-9]+”首先尝试匹配“a”,匹配成功,继续尝试匹配,可以成功匹配接下来的“1”和“2”,此时已经匹配到位置3,位置3的右侧已没有字符,这时会把控制权交给“$”;
元字符“$”从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a12”,开始位置为0,结束位置为3。其中“^”匹配位置0,“(?=[a-z])”匹配位置0,“[a-z0-9]+”匹配字符串“a12”,“$”匹配位置3。
2.5 问题集锦:详解正则常见问题及解决方案
1 问题处理思路
在讲解具体的问题前,我先来说一下使用正则处理问题的基本思路。有一些方法比较固定,比如将问题分解成多个小问题,每个小问题见招拆招:某个位置上可能有多个字符的话,就⽤字符组。某个位置上有多个字符串的话,就⽤多选结构。出现的次数不确定的话,就⽤量词。对出现的位置有要求的话,就⽤锚点锁定位置。
在正则中比较难的是某些字符不能出现,这个情况又可以进一步分为组成中不能出现,和要查找的内容前后不能出现。后一种用环视来解决就可以了。我们主要说一下第一种。
如果是要查找的内容中不能出现某些字符,这种情况比较简单,可以通过使用中括号来排除字符组,比如非元音字母可以使用 [^aeiou]来表示。
如果是内容中不能出现某个子串,比如要求密码是 6 位,且不能有连续两个数字出现。假设密码允许的范围是 \w,你应该可以想到使用 \w{6} 来表示 6 位密码,但如果里面不能有连续两个数字的话,该如何限制呢?这个可以环视来解决,就是每个字符的后面都不能是两个数字(要注意开头也不能是 \d\d)。
>>> import re
>>> re.match(r'^((?!\d\d)\w){6}$', '11abcd') # 不能匹配上
# 提示 (?!\d\d) 代表右边不能是两个数字,但它左边没有正则,即为空字符串
>>> re.match(r'^((?!\d\d)\w){6}$', '1a2b3c') # 能匹配上
<re.Match object; span=(0, 6), match='1a2b3c'>
>>> re.match(r'^(\w(?!\d\d)){6}$', '11abcd') # 错误正则示范
<re.Match object; span=(0, 6), match='11abcd'>
2 常见问题及解决方案
匹配数字
数字的匹配比较简单,通过字符组,量词等就可以轻松解决。
- 数字在正则中可以使用 \d 或 [0-9] 来表示
- 如果是连续的多个数字,可以使用 \d+ 或 [0-9]+
- 如果 n 位数据,可以使用 \d{n}
- 如果是至少 n 位数据,可以使用 \d{n,}
- 如果是 m-n 位数字,可以使用 \d{m,n}
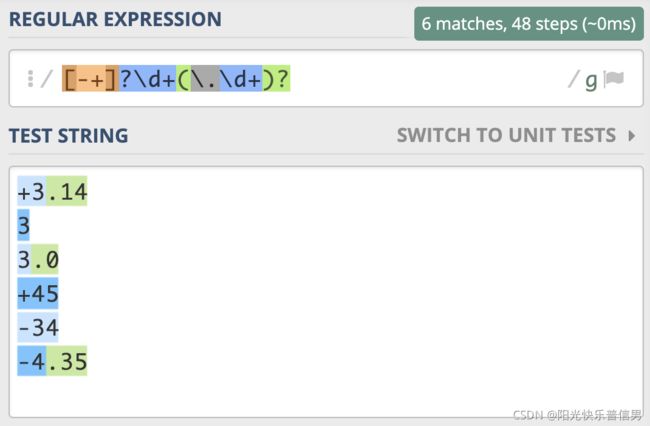
匹配正数、负数和小数
如果希望正则能匹配到比如 3,3.14,-3.3,+2.7 等数字,需要注意的是,开头的正负符号可能有,也可能没有,所以可以使用 [-+]? 来表示,小数点和后面的内容也不一定会有,所以可以使用 (?:\.\d+)? 来表示
- 匹配正数、负数和小数的正则可以写成
[-+]?\d+(?:\.\d+)?
- 非负整数,包含 0 和 正整数,可以表示成
[1-9]\d*|0 - 非正整数,包含 0 和 负整数,可以表示成
-[1-9]\d*|0
浮点数
浮点数分为符号位、整数部分、小数点和小数部分,这些部分都有可能不存在,如果我们每个部分都加个问号,这样整个表达式可以匹配上空。
根据上面的提示,负号的时候整数部分不能没有,而正数的时候,整数部分可以没有,所以正则你可以将正负两种情况拆开,使用多选结构写成 -\d+(?:\.\d+)?|\+?(?:\d+(?:\.\d+)?|\.\d+)
这个可以拆分成两个问题:
- 负数 浮点数表示:
-\d+(?:\.\d+)? - 正数 浮点数表示:
\+?(?:\d+(?:\.\d+)?|\.\d+)
十六进制数
十六进制的数字除了有 0-9 之外,还会有 a-f(或 A-F) 代表 10 到 15 这 6 个数字,所以正则可以写成 [0-9A-Fa-f]+。
手机号码
手机号应该是比较常见的,手机号段比较复杂,如果要兼容所有的号段并不容易。目前来看,前四位是有一些限制,甚至 1740 和 1741 限制了前 5 位号段。
我们可以简单地使用字符组和多选分支,来准确地匹配手机号段。如果只限制前 2 位,可以表示成 1[3-9]\d{9},如果想再精确些,限制到前三位,比如使用1(?:3\d|4[5-9]|5[0-35-9]|6[2567]|7[0-8]|8\d|9[1389])\d{8}来表示。如果想精确到 4 位,甚至 5 位,可以根据公开的号段信息自己来写一下,但要注意的是,越是精确,只要有新的号段,你就得改这个正则,维护起来会比较麻烦。另外,在实际运用的时候,你可能还要考虑一下有一些号码了 +86 或 0086 之类的前缀的情况。
手机号段的正则写起来其实写起来并不难,但麻烦的是后期的维护成本比较高,我之前就遇到过这种情况,买了一个 188 的移动号码,有不少系统在这个号段开放了挺长时间之后,还认为这个号段不合法。
目前公开的手机号段:

身份证号码
我国的身份证号码是分两代的,第一代是 15 位,第二代是 18 位。如果是 18 位,最后一位可以是 X(或 x),两代开头都不能是 0,根据规则,你应该能很容易写出相应的正则,第一代可以用 [1-9]\d{14} 来表示,第二代比第一代多 3 位数据,可以使用量词 0 到 1 次,即写成[1-9]\d{14}(\d\d[0-9Xx])?。
邮政编码
邮编一般为 6 位数字,比较简单,可以写成 \d{6},之前我们也提到过,6 位数字在其它情况下出现可能性也非常大,比如手机号的一部分,身份证号的一部分,所以如果是数据提取,一般需要添加断言,即写成(?
腾讯 QQ 号码
目前 QQ 号不能以 0 开头,最长的有 10 位,最短的从 10000(5 位)开始。从规则上我们可以得知,首位是 1-9,后面跟着是 4 到 9 位的数字,即可以使用 [1-9][0-9]{4,9} 来表示。
中文字符
中文属于多字节 Unicode 字符,之前我们讲过比如通过 Unicode 属性,但有一些语言是不支持这种属性的,可以通过另外一个办法,就是码值的范围,中文的范围是 4E00 - 9FFF 之间,这样可以覆盖日常使用大多数情况。
不同的语言是表示方式有一些差异,比如在 Python,Java,JavaScript 中,Unicode 可以写成 \u码值 来表示,即匹配中文的正则可以写成 [\u4E00-\u9FFF],如果在 PHP 中使用,Unicode 就需要写成 \u{码值} 的样式。
# 测试环境,Python3
>>> import re
>>> reg = re.compile(r'[\u4E00-\u9FFF]')
>>> reg.findall("和伟忠一起学正则regex")
['和', '伟', '忠', '一', '起', '学', '正', '则']
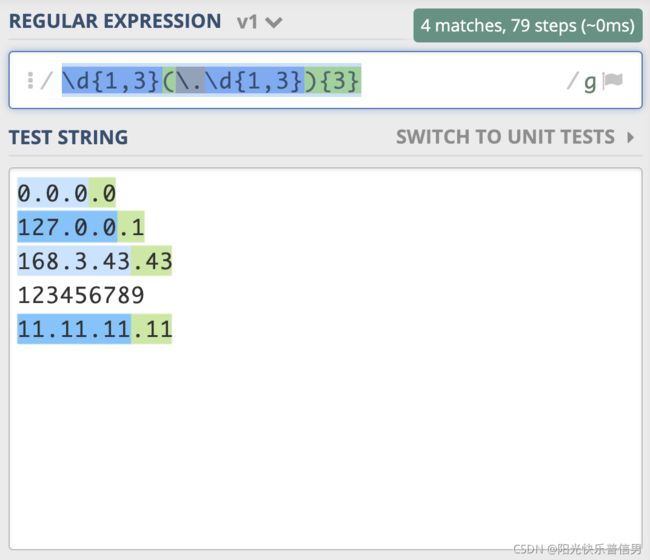
IPv4 地址
IPv4 地址通常表示成 27.86.1.226 的样式,4 个数字用点隔开,每一位范围是 0-255,比如从日志中提取出 IP,如果不要求那么精确,一般使用 \d{1,3}(\.\d{1,3}){3}就够了,需要注意点号需要转义。
如果我们想更精确地匹配,可以针对一到三位数分别考虑,一位数时可以表示成 0{0,2}\d,两位数时可以表示成 0?[1-9]\d,三位数时可以表示成 1\d\d|2[0-4]\d|25[0-5],使用多选分支结构把他们写到一起,就是 0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5]这样。
这是表示出了 IPv4 地址中的一位(正则假设是 X),我们可以把 IPv4 表示成 X.X.X.X,可以使用量词,写成 (?:X.){3}X 或 X(?:.X){3},由于 X 本身比较复杂,里面有多选分支结构,所以需要把它加上括号,所以 IPv4 的正则应该可以写成
(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5]){3}
如果测试一下就发现,匹配行为很奇怪。

原因主要有两点,都和多选分支结构有关系。我们想的是所有的一到三位数字前面都有一个点,重复三次,但点号和 0{0,2}\d 写到一起,意思是一位数字前面有点,两位和三位数前面没有点,所以需要使用括号把点挪出去,最终写成(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])){3}。发现还是有问题,最后一个数字只匹配上了一位。
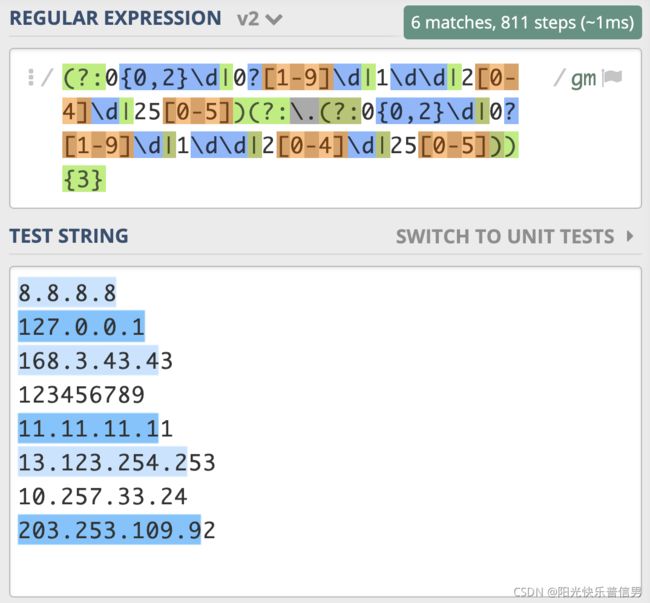
上一讲正则匹配原理中,我们讲解了 NFA 引擎在匹配多分支选择结构的时候,优先匹配最左边的,所以找到了一位数符合要求时,它就”急于“报告,并没有找出最长且符合要求的结果,这就要求我们在写多分支选择结构的时候,要把长的分支放左边,这样就可以解决问题了,即正则写成(?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)(?:\.(?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)){3}。
日期和时间
假设日期格式是 yyyy-mm-dd,如果不那么严格,我们可以直接使用 \d{4}-\d{2}-\d{2}。如果再精确一些,比如月份是 1-12,当为一位的时候,前面可能不带 0,可以写成 01 或 1,月份使用正则,可以表示成 1[0-2]|0?[1-9],日可能是 1-31,可以表示成 [12]\d|3[01]|0?[1-9],这里需要注意的是 0?[1-9] 应该放在多选分支的最后面,因为放最前面,匹配上一位数字的时候就停止了(示例),正确的正则(示例)应该是 \d{4}-(?:1[0-2]|0?[1-9])-(?:[12]\d|3[01]|0?[1-9])。
时间格式比如是 23:34,如果是 24 小时制,小时是 0-23,分钟是 0-59,所以可以写成 (?:2[0-3]|1\d|0?\d):(?:[1-5]\d|0?\d)。12 小时制的也是类似的,你可以自己想一想怎么写。
另外,日期中月份还有大小月的问题,比如 2 月闰年可以是 29 日,使用正则没法验证日期是不是正确的。我们也不应该使用正则来完成所有事情,而是只使用正则来限制具体的格式,比如四位数字,两位数字之类的,提取到之后,使用日期时间相关的函数进行转换,如果失败就证明不是合法的日期时间。
邮箱
> 邮箱示例:
> weizhong.tu2020@abc.com
> 12345@qq.com
邮箱的组成是比较复杂的,格式是 用户名 @主机名,用户名部分通常可以有英文字母,数字,下划线,点等组成,但其中点不能在开头,也不能重复出现。不过我们可以实现一些简体的版本,比如:[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+
网页标签
配对出现的标签,比如 title,一般网页标签不区分大小写,我们可以使用 (?i)来进行匹配。在提取引号里面的内容时,可以使用 [^"]+,方括号里面的内容时,可以使用 [^>]+ 等方式。
3 小结
这些正则如果用于校验,还需要添加断言,比如 \A 和 \z(或\Z),或 ^ 和 $。
如果用于数据提取,还应当在首尾添加相应的断言。
补充练习
根据 IPv4 的方法,写一下 IPv6 的正则表达式
IPv6示例
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789
这种表示法中,每个X的前导0是可以省略的,例如:
2001:0DB8:0000:0023:0008:0800:200C:417A
上面的IPv6地址,可以表示成下面这样
2001:DB8:0:23:8:800:200C:417A
备注:这里不考虑0位压缩表示
参考写法:测试
- 前导匹配正则表达式:
[0-9A-Fa-f]{4}(?:\:(?:[0-9A-Fa-f]{4})){7} - 省略前导0正则表达式:
(?:0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})(?:\:(?:0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})){7}
3 书目推荐
- 《精通正则表达式》(第 3 版):正则方面最为权威的一本书,对正则的原理等都有比较深入的讲述
- 《正则指引》(第 2 版):by余晟,有大量的编程语言示例,比较接地气,对正则表达式如何处理中文有比较详细的讲解