深度剖析「圈组」关系系统设计 | 「圈组」技术系列文章
导读:网易云信新晋的 IM 顶流产品「圈组」出道后获取到了极大的关注,很多云信的客户在接入的同时对于「圈组」的底层技术细节和原理也非常关注,为此,我们决定推出云信「圈组」相关的系列技术文章,分享网易云信在「圈组」技术设计上的一些思考。
业务特点
在互联网行业盛行一句话,技术是为业务服务的。具体到实践中,一个重要方面就是要面向业务特点设计技术方案。因此,想要了解「圈组」的关系系统设计,就要首先了解「圈组」的关系业务特点。
「圈组」的关系业务特点是什么?其一是关系复杂,即关系主体多、管理机制杂、联动耦合重;其二是规模巨大,即成员数量可达百万量级、变更批量可达百万量级。
所谓关系复杂,具体来讲:首先是关系主体多。在「圈组」业务中,关系主体包括服务器、频道、身份组、频道分组等,服务器承载社群关系,负责社群成员关系维护;频道从属于服务器,承载内容关系,负责内容互动关系维护;身份组可从属于服务器或频道,承载身份权限关系,负责身份设定和权限配置;频道分组从属于服务器,又关联一组频道,承载频道模版关系,负责分类频道和共享配置。其次是管理机制杂。在「圈组」业务中,仅就成员管理机制而言,服务器成员采用邀请/申请机制,频道成员采用公开/私密模式+黑/白名单机制,身份组成员采用加入/移出机制,频道分组成员与频道成员采用同步机制。最后是联动耦合。在「圈组」业务中,以频道成员维护为例,频道成员不仅受到公开/私密模式+黑/白名单配置变更的影响,而且会伴随服务器成员变更、身份组变更、身份组成员变更等做联动变更。
所谓规模巨大,具体来讲:一方面是成员数量可达百万量级。在「圈组」业务中,服务器成员数量可以达到数百万人,进一步,百万成员服务器下的频道和身份组,其成员数量也可以达到百万量级。另一方面是变更批量可达百万量级。在「圈组」业务中,不仅成员数量规模巨大,而且变更操作一个批次数量也可以达到百万量级。包括:删除百万成员的服务器/频道/身份组,增删频道/频道分组黑白名单中的百万成员身份组等。
从「圈组」关系业务的两大特点出发,可以发现「圈组」关系是不同于群组关系的全新业务场景,将会面临全新的技术难点。
技术难点
「圈组」关系系统的技术难点主要有两个方面。其一是多关系主体、多管理机制在层级结构下关联耦合导致的业务逻辑的复杂性;其二是成员数量、变更批量规模巨大导致的业务处理在时间、空间、资源等开销上的复杂性。
业务逻辑复杂性
首先「圈组」有多级结构。包括服务器/频道二级结构、服务器/频道分组/频道三级结构等。单个关系主体变更,不仅涉及自身的变更,而且涉及上下级关系主体的变更,可以说牵一发动全身。相比而言,群组是没有层级的,群组变更只要独善其身就好。
其次「圈组」有身份组。一个身份组是一组有共同权限的服务器成员的集合,不同身份组的成员可以相互交叉,身份组会作为整体参与到成员管理中。也就是说,成员变更不再只是个别成员(1-100人)的进入退出,将会出现整组成员(1-1000000人)的大进大出。相比而言,群组是没有身份组的,群组特殊成员包括群主、管理员等也都数量不多、互不重复。
最后「圈组」有多种成员管理机制。服务器成员和身份组成员的管理机制与群组类似,频道成员和频道分组成员的管理机制却是全新模式。频道分为公开和私密两种,公开模式默认允许所有服务器成员可见,但要排除黑名单身份组和黑名单成员;私密模式默认不许所有服务器成员可见,但要放开白名单身份组和白名单成员。除了受到公开/私密模式+黑/白名单配置变更的影响,频道成员也受到所依赖的关系主体(服务器成员、身份组、身份组成员)变更的影响。进一步,频道成员还受到所同步的频道分组变更的影响。相比而言,群组成员的邀请/申请机制,可以说是小巫见大巫。
业务处理复杂性
首先是成员数量规模巨大。由于成员数量可达百万,整个成员列表的存储空间开销、网络传输开销,变得十分巨大,不论全量成员列表数据的服务器缓存,还是全量成员列表数据从服务器到客户端的同步,都将变得难以实现。
其次是变更批量规模巨大。单次接口调用的关系变更,可能伴随百万规模的联动关系变更,这会导致巨大的处理时间开销、计算资源开销,不论所有变更同步完成处理,还是所有变更单机完成处理,都将变得难以实现。
最后是通知消息规模巨大。关系系统不仅需要做关系变更的数据处理,而且需要通知变更结果到客户端。由于在「圈组」中各个关系主体的成员数量规模巨大,使得单个变更需要扩散为百万通知同时下发,所需计算资源开销、网络传输开销十分巨大。
相比而言,群组方案因为成员数量、变更批量规模有限,并不涉及这些技术难点。
从「圈组」关系系统的两个方面技术难点出发,可以发现「圈组」关系系统面临不同于群组的全新技术难点,想要解决这些技术难点,需要创新的技术方案。
技术剖析
「圈组」关系系统是整个「圈组」方案的重要组成部分,在具体介绍「圈组」关系系统技术方案之前,有必要首先了解「圈组」方案的整体架构。
「圈组」整体架构
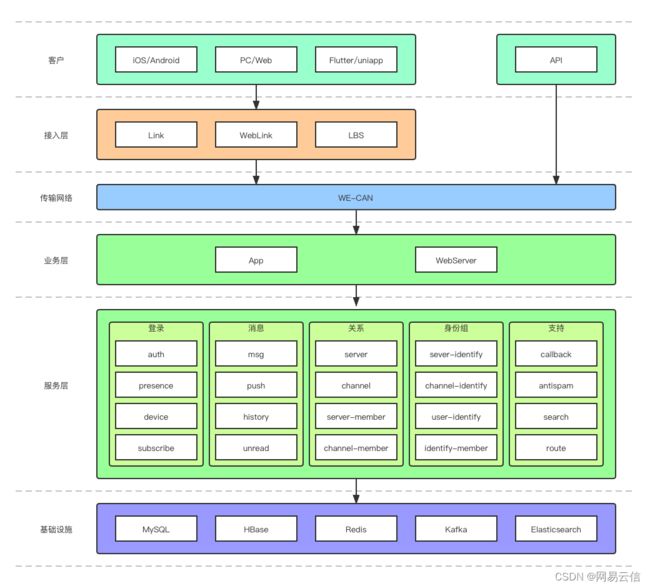
上面展示了「圈组」方案的整体架构,可以看到「圈组」整体是一个分层架构。从上到下看:
-
客户层:包括可供客户端集成的移动端、桌面端、跨平台 SDK,和可供服务器调用的 OpenAPI。
-
接入层:包括 LBS 服务、长连接服务和 API 网关,分别对应客户端 SDK 和用户服务器。
-
网络层:包括自研的全球实时传输网络 WE-CAN。
-
业务层:包括用于 SDK 业务处理的 App 服务和用于 OpenAPI 业务处理的 WebServer 服务。
-
服务层:划分有登录、消息、关系、身份组、支持等服务模块,每个服务模块包括有多个微服务或消费者。
-
基础设施层:包括系统所用的数据库和中间件。
关系系统架构

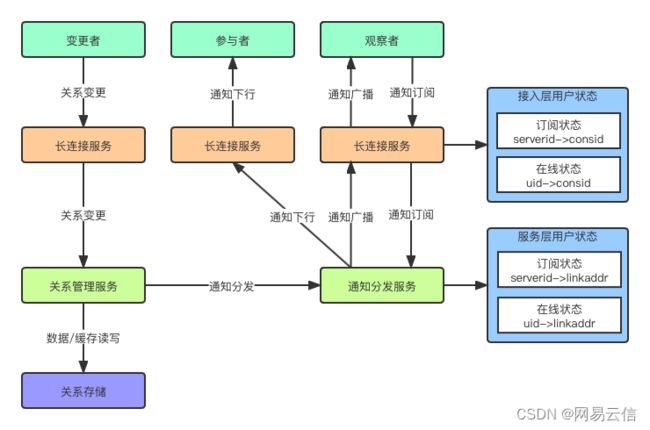
上图展示了「圈组」关系系统的技术架构,可以看到「圈组」关系系统遍及「圈组」架构的接入层、网络层、业务层和服务层。从功能出发整体上分为三个部分,包括:关系操作同步处理模块、关系事件异步处理模块和变更通知在线广播模块。
关系系统技术细节
在「圈组」关系系统中,下面具体讨论三个方案要点的技术细节,包括频道成员关系管理、变更通知在线广播和关系数据云端检索。
-
频道成员关系管理
频道成员关系管理,是「圈组」中极具挑战性的问题。频道成员涉及多关系主体、多管理机制、联动变更耦合严重,成员数量和变更批量规模巨大,可以说是「圈组」关系业务的典型代表。频道成员关系管理在业务逻辑和业务处理两方面的复杂性可想而知。针对频道成员关系管理问题,「圈组」设计了两大机制加以解决。包括:终态维护与过渡计算相结合机制、事件按序异步并行处理机制。
终态维护与过渡计算相结合机制,具体来讲,频道成员关系数据最终被维护在持久化数据库中,并在频道成员没有变更的终态阶段,直接支持频道成员数据的查询需求。当频道成员发生变更时,由于变更逻辑和变更处理两方面的复杂性,完成关系变更需要一段时间,称之为过渡阶段。在过渡阶段,数据库持久化的频道成员表数据是不完全准确的,无法直接支持频道成员数据的查询需求。此时转为由频道成员配置元数据直接计算频道成员以支持查询需求。因为频道成员配置元数据的变更是同步处理的,所以在过渡阶段由频道成员配置元数据直接计算频道成员可以保证查询准确性。通过将频道成员关系管理分为终态和过渡两个阶段,并在不同阶段采用不同频道成员查询方案,不仅解决了单纯由计算获取频道成员资源开销大的问题,而且解决了频道成员变更延迟导致由数据库获取频道成员结果不准确的问题。
除了频道成员的获取查询问题,频道成员的变更处理也很重要。事件按序异步并行处理机制,就是用于解决频道成员的变更处理问题。其一通过将影响频道成员关系的变更操作分层级、系统化定义为变更事件,显著降低频道成员关系管理的业务逻辑复杂性。其二通过 ID 哈希、分布式锁、事件版本号控制等保证变更事件的按序处理,有效避免事件处理乱序导致的持久化数据错误。其三通过消息队列中转事件并在消费者上异步处理,有效解决联动变更批量过大导致接口调用阻塞的问题。其四通过在单个事件处理中的多线程并行加速和本地缓存重用加速,显著缩短频道成员关系变更的时间延迟。
-
变更通知在线广播
关系系统不仅需要做关系变更的数据处理,而且需要通知变更结果到客户端。在百万量级的「圈组」关系中,每条关系变更通知,都会面临海量扩散的接收者。除了通知分发量激增,不同接收者对于通知接收的缓急差异也值得关注。针对变更通知在线广播问题,「圈组」设计了两大机制加以解决。包括:变更分类通知机制、数据通知拉取机制。
在变更分类通知机制中,一方面,根据相关人员在变更中的角色,划分为参与者和观察者分类做通知,即参与者一定通知,观察者按照订阅需求通知。其中参与者一般是变更中的少数关键人员,观察者则是除了参与者之外可以看到变更结果的其它人员。通过分类通知,不同接收者对于通知接收的缓急差异得到合理关注,变更通知的扩散规模也得到精准缩小。另一方面,观察者按照订阅需求通知,可以充分发挥「圈组」的在线广播订阅模式的优势。所谓在线广播订阅模式,是指在用户登陆之后,需要订阅感兴趣的服务器/频道的通知,「圈组」系统会记录下这些订阅信息,当有新的通知时,「圈组」系统通过订阅关系而非成员列表 + 在线状态获取需要在线广播的用户列表,从而不再需要遍历服务器/频道的所有成员及其在线状态。通过采用在线广播订阅模式,不仅显著降低变更通知在线广播的计算开销和带宽开销,而且可以实现变更通知在线广播在长连接服务集群的并行加速和水平扩展。
变更通知的最终目的是将变更后的数据给到客户端。不同于群组,「圈组」并不将变更后的数据直接由通知带给客户端,而是采用通知客户端有变更再触发客户端拉取结果数据的机制。究其原因,不同于群组将关系数据全量同步到客户端,「圈组」客户端不再存储关系数据的全量镜像,因此不再需要通过全量历史 + 增量变更的方式维护客户端上的关系数据全量镜像。与此同时,订阅变更通知的观察者也并不是每时每刻都要关心变更的结果数据,关心某次变更结果数据的观察者相比订阅变更通知的观察者在数量上会少很多,因此,数据通知拉取机制会显著降低变更通知的资源开销。另外,相比带变更数据通知,只通知有变更,便于直接合并相同类型的通知,而不用关心合并变更数据存在的时序、并发等问题,如此,数据通知拉取机制可以通过短时间内通知合并显著降低服务器在线广播开销和客户端通知接收开销。
-
关系数据云端检索
在「圈组」中,伴随关系规模的大幅增长,群组基于应用服务器全量查询关系数据或客户端全量同步关系数据实现精准查询和灵活排序的方案不再适用。对此,「圈组」采用了关系数据云端检索的方案。
「圈组」关系数据云端检索方案可以支持服务器、频道、成员等的检索能力。从检索场景上分,包括广场检索和内部检索。
广场检索:用于检索感兴趣的服务器。可以根据名称、类别等多种维度检索。检索结果可以根据预定义字段(成员数量等)或自定义值(数据热度等)等进行排序。
内部检索:用于检索用户可见的服务器、频道、成员等。可以根据名称、昵称等多种维度检索。检索结果可以根据预定义字段(创建时间等)或自定义值(数据热度等)等进行排序。
总结
说了这么多,云信「圈组」作为一款全新设计的产品,没有任何历史包袱的限制(但是却可以充分吸收历史优点),你可以使用它构建一个类 Discord 产品,或者任何你想得到的社交/娱乐/游戏产品,欢迎大家选择。