pytorch——mnist手写数据识别
目录
1、pytorch自带的数据集
1.1 torchvision.datasets
1.2 MNIST数据集的介绍
2、使用Pytorch实现手写数字识别
2.1思路和流程分析
2.2 MNIST数据处理常用API
2.2.1 torchvision.transforms.ToTensor
2.2.2 torchvision.transforms.Normalize(mean,std)
2.2.3 torchvision.transforms.Compose(transforms)
2.3 准备MNIST数据集的Dataset和DataLoader
2.4构建模型
2.4.1 激活函数的使用
2.4.2 模型中数据的形状
2.5 损失函数
2.6 模型的训练
2.7模型的保存和加载
2.8 模型的评估
3、完整代码
1、pytorch自带的数据集
pytorch中自带数据集由两个上层的API提供,分别是torchvision和torchtext。其中,torchvision提供了对照片数据处理相关的API和数据,数据所在位置:torchvision.datasets,比如torchvision.datasets.MNIST(手写数字照片数据);torchtext提供了对文本数据处理相关的API和数据,数据所在位置:torchtext.datasets,比如torchtext.datasets.IMDB(电影评论文本数据)。
以MNIST为例,实现pytorch加载数据集。首先应该准备好Dataset实例,然后将dataset交给dataloader打乱顺序,组成batch。
1.1 torchvision.datasets
torchvision.datasets中的数据集类(比如torchvision.datasets.MNIST),都是继承自Dataset,也就是说直接对torchvision.datasets.MNIST进行实例化,就可得到Dataset的实例。
torchvision.datasets.MNIST(root = '/files/',train = True,download = True,transform = ...)
root表示数据存放的位置;train是bool类型,表示是使用训练集的数据还是测试集的数据;download是bool类型,表示是否需要下载数据到root目录;transform用来实现对照片的处理函数。
1.2 MNIST数据集的介绍
MNIST是由Yann LeCun等人提供的免费的图像识别的数据集,其中包含60000个训练样本和10000个测试样本,其中图的尺寸已经进行标准化的处理,都是黑白图像,大小为28*28。我们通过:
from torchvision.datasets import MNIST
导入MNIST,进入其源文件可以看到其相关参数的定义:
def __init__(
self,
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False,
) -> None:执行代码,下载数据,观察数据类型:
from torchvision.datasets import MNIST
mnist = MNIST(root = "./data",train = True,download = True)
print(mnist)运行结果如下:

对应的数据也下载到了相应的文件夹。然后,将参数download改变为False即可。
可以通过下标进行索引:
print(mnist[0])
>>>(
, 5)
可以知道,第一个元素是image对象,第二个是对应的数值。通过show()进行显示:
mnist[0][0].show()结果为:

2、使用Pytorch实现手写数字识别
2.1思路和流程分析
- 准备数据,这些需要准备DataLoader
- 构建模型,这里可以使用torch构造一个深层的神经网络
- 模型的构建
- 模型的保存,保存模型,后续持续使用
- 模型的评估,使用测试集,观察模型的好坏
2.2 MNIST数据处理常用API
调用MNIST返回的结果中图形数据是一个image对象,需要对其进行处理。
2.2.1 torchvision.transforms.ToTensor
这个函数能把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转传成形状为[C,H,W],取值范围是[0,1.0]的torch.FloatTensor。其中(H,W,C)意思是(高,宽,通道数),黑白图片的通道数只有1,其中每个像素点的取值为[0,255],彩色图片的通道数为(R,G,B),每个通道的像素点的取值为[0,255],三个通道的颜色相互叠加,形成了各种颜色。
以下是使用的一个示例:
from torchvision import transforms
import numpy as np
data = np.random.randint(0,255,size = 12)
img = data.reshape(2,2,3)
print(img.shape)
img_tensor = transforms.ToTensor()(img)#转换为tensor
print(img_tensor)
print(img_tensor.shape)输出如下:

注意:transforms.ToTensor对象中有__call__方法,所以可以对其示例能传入数据获取结果。
如果对mnist进行操作:
from torchvision import transforms
from torchvision.datasets import MNIST
mnist = MNIST(root='./data',train = True,download = False)
print(mnist[0])
ret = transforms.ToTensor()(mnist[0][0])
print(ret)会将其变成大小[1,28,28]的tensor。
2.2.2 torchvision.transforms.Normalize(mean,std)
给定均值(mean)和方差(std),需要和图片的通道数相同,均值和方差都是对应通道的相应值,则将会对Tensor进行规范化处理。
就是Normalized_image = (image - mean) / std。比如:
from torchvision import transforms
import numpy as np
import torchvision
data = np.random.randint(0,255,size = 12)
img = data.reshape(2,2,3)
img = transforms.ToTensor()(img)#转换为tensor
img = img.float()
print(img)
print("*"*100)
norm_img = transforms.Normalize((20,10,30),(2,1,3))(img)
print(norm_img)输出为:

2.2.3 torchvision.transforms.Compose(transforms)
可以向其中传入一个列表,列表中放入各种transforms的对象:
transforms.Compose([
torchvision.transforms.ToTensor(),#先转换为Tensor
torchvision.transforms.Normalize(mean,std) #再进行正则化
])
将这个传给照片的transform参数,便可以对照片进行处理。
2.3 准备MNIST数据集的Dataset和DataLoader
准备训练集和测试集,因为方法相同,所以将数据集的准备放进函数里,通过调用函数,对函数的参数进行选择,来判断是准备训练集还是测试集。
其中的0.1307,0.3081位MNIST数据的均值和标准差,这样的操作能够对其进行标准化,因为MNIST只有一个通道(黑白图片),所以元组中只有一个值。
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
from torch.utils.data import DataLoader
BATCH_SIZE = 128
#准备数据集
def get_dataloader(train):
transform_fn = Compose([
ToTensor(),
Normalize(mean = (0.1307,),std = (0.3081,))
])#mean和std的形状与通道数相同
dataset = MNIST(root = './data',train = train,transform = transform_fn)
data_loader = DataLoader(dataset,batch_size = BATCH_SIZE,shuffle = True)
return data_loader2.4构建模型
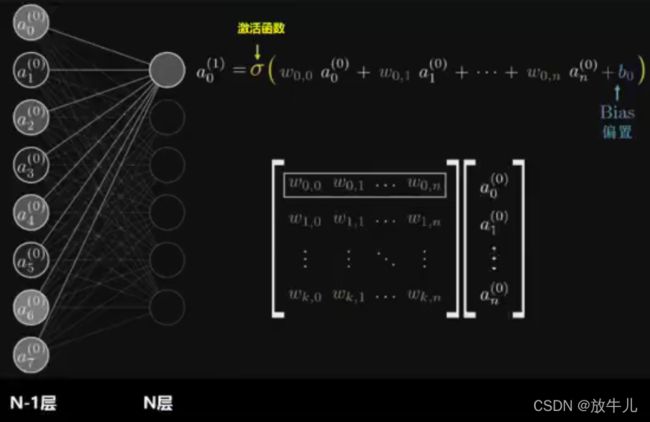
全连接层:当前一层的神经元和前一层的神经元相互链接,其核心操作就是y=wx,即矩阵的乘法,实现对前一层数据的变换。
模型构建使用了一个三层的神经网络,一个输入层,一个输出层(也是全连接层),一个全连接层。
2.4.1 激活函数的使用
常用激活函数为Relu激活函数,该激活函数由import torch.nn.functional as F进行调用,对数据进行处理的例子如下:
import torch
import torch.nn.functional as F
b = torch.tensor([-2,-1,0,1,2])
print(F.relu(b))结果输出如下:

2.4.2 模型中数据的形状
- 原始输入数据的形状[batch_size,1,28,28]
- 进行形状的修改:[batch_size,1*28*28](因为全连接层是在进行矩阵的乘法,所以变成二阶的形状)
- 全连接层的输出形状:[batch_size,28],这里的输出28是个人设定,也可以设置成别的。此时就是28*28的输入,产生28的输出,所以中间有28*28*28个参数。此时,矩阵是28*28行,28列。
- 激活函数不会修改数据的形状。
- 输出层的输出形状,因为手写数字有10个类型,所以[batch_size,10]
其中的batch_size需要根据前一个的结果来设定。
代码实现如下:
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel,self).__init__()#继承
self.fc1 = nn.Linear(1*28*28,28)#参数是input和output的feature
self.fc2 = nn.Linear(28,10)
def forward(self,input):
#1.进行形状的修改
x = input.view([-1,1*28*28])#-1表示根据形状自动调整,也可以改为input.size(0)
#2.进行全连接的操作
x = self.fc1(x)
#3.激活函数的处理
x = F.relu(x)#形状没有变化
#4.输出层
out = self.fc2(x)
return out2.5 损失函数
在逻辑回归中,我们使用sigmoid进行计算对数似然损失,来定义我们二分类的损失,在二分类中,我们有正类和负类,正类的概率为![]() ,则负类的概率是1-P(x)。将这个结果进行计算对数似然损失
,则负类的概率是1-P(x)。将这个结果进行计算对数似然损失![]() 就可以得到最终的损失。
就可以得到最终的损失。
多分类中我们不能再用sigmoid函数来计算当前样本属于某个类别的概率,而应该使用softmax函数,该函数和sigmoid的区别在于我们需要去计算样本属于每个类别的概率,需要计算多次,而sigmoid只需要计算一次。公式如下:
例如下图:


假如softmax函数之前的输出结果是2.3,4.1,5.6,则经过softmax之后结果分别是
对于softmax的输出结果是在0和1之间的,我们可以把它当做概率。
和前面的二分类的损失一样,多分类的损失只需要在把这个结果进行对数似然损失的计算即可,即
![]() ,其中
,其中![]() ,Y表示真实值
,Y表示真实值
最后,会计算每个样本的损失,求损失的平均值。我们把softmax概率传入对数似然损失得到的损失函数称为交叉熵损失。
在pytorch中有两种方法实现交叉熵损失:
- criterion = nn.CrossEntropyLoss()#实例化对象
loss = criterion(input,target)#将预测值和真实值传入
- #1.对输出值计算softmax然后取对数
output = F.log_softmax(x,dim = -1)
#2.使用torch中的带全损失nll
loss = F.nll_loss(output,target)
带全损失定义为:![]() ,其实就是将log(P)作为
,其实就是将log(P)作为 ,真实值作为权重。
,真实值作为权重。
因此,我们可以直接将forward函数返回log_softmax(out),即:
def forward(self,input):
x = input.view([-1,1*28*28])
x = self.fc1(x)
x = F.relu(x)#形状没有变化
out = self.fc2(x)
return F.log_softmax(out,dim=-1)2.6 模型的训练
训练的流程:
- 实例化模型,设置模式是训练模式。
- 实例化优化器类,实例化损失函数。
- 获取dataset,遍历dataloader
- 梯度设置为0
- 进行向前计算
- 计算损失
- 反向传播
- 更新参数
from torch.optim import Adam
model = MnistModel()
optimizer = Adam(model.parameters(),lr = 0.001)
def train(epoch):#epoch表示几轮
data_loader = get_dataloader(True)#获取数据加载器
for idx,(input,target) in enumerate(data_loader):#idx表示data_loader中的第几个数据,元组是data_loader的数据
optimizer.zero_grad()#将梯度置0
output = model(input)#调用模型,得到预测值
loss = F.nll_loss(output,target)#调用损失函数,得到损失,是一个tensor
loss.backward()#反向传播
optimizer.step()#梯度的更新
if idx % 10 == 0:
print(epoch,idx,loss.item())
#for是每一轮中的数据进行遍历对其进行验证:
for i in range(3):#训练三轮
train(i)2.7模型的保存和加载
模型的保存
torch.save(mnist_net.state_dict,"model/mnist_net.pth")#保存模型参数,state_dict用来获取数据,save用来保存数据
torch.save(optimizer.state_dict(),"results/mnist_optimizer.pth")#保存优化器模型的加载
mnist_net.load_state_dict(torch.load("model/mnist_net.pth"))
optimizer.load_state_dict(torch.load("results/mnist_optimizer.pth"))前一次训练进行数据的保存:
if idx % 100 == 0:
torch.save(model.state_dict,"./model/mnist_net.pth")
torch.save(optimizer.state_dict(),"./model/mnist_optimizer.pth")在前面加入数据的加载,在以后每一次训练都可以调用先前的数据:
import os
import torch
model = MnistModel()
optimizer = Adam(model.parameters(),lr = 0.001)
if os.path.exists("./model/mnist_net.pth"):
model.load_state_dict(torch.load("./model/mnist_net.pth"))
optimizer.load_state_dict(torch.load("./model/mnist_optimizer.pth"))下图是第一次训练的大小:
2.8 模型的评估
评估的过程和训练的过程相似,但是:
- 不需要计算梯度
- 需要收集损失和准确率,用来计算平均损失和平均准确率
- 损失的计算和训练时候损失计算方式相同
- 准确率的计算:模型输出是[batch_10,size]的形状,其中最大值的位置就是预测的目标值,最大值的位置获取方法可以使用torch.max返回最大值和最小值的位置,返回最大值位置后,和真实值进行比较,相同则表示预测成功。
tensor.max(dim = -1)可以获取每一行最大值,并获取对应的位置,dim = 0则获取每一列的位置,返回是一个元组,其中有两个数据,一个最大值,一个最大值所在的位置。
import numpy as np
TEST_BATCH_SIZE = 1000
def get_dataloader(train,batch_size=BATCH_SIZE):
transform_fn = Compose([
ToTensor(),
Normalize(mean = (0.1307,),std = (0.3081,))
])#mean和std的形状与通道数相同
dataset = MNIST(root = './data',train = train,transform = transform_fn)
data_loader = DataLoader(dataset,batch_size = batch_size,shuffle = True)
return data_loader
def test():
loss_list = []
acc_list = []
test_dataloader = get_dataloader(train = False,batch_size=TEST_BATCH_SIZE)#获取测试集
for idx,(input,target) in enumerate(test_dataloader):
with torch.no_grad():
output = model(input)
cur_loss = F.nll_loss(output,target)
loss_list.append(cur_loss)
#计算准确率,output大小[batch_size,10] target[batch_size] batch_size是多少组数据,10列是每个数字概率
pred = output.max(dim = -1)[-1]
cur_acc = pred.eq(target).float().mean()
acc_list.append(cur_acc)
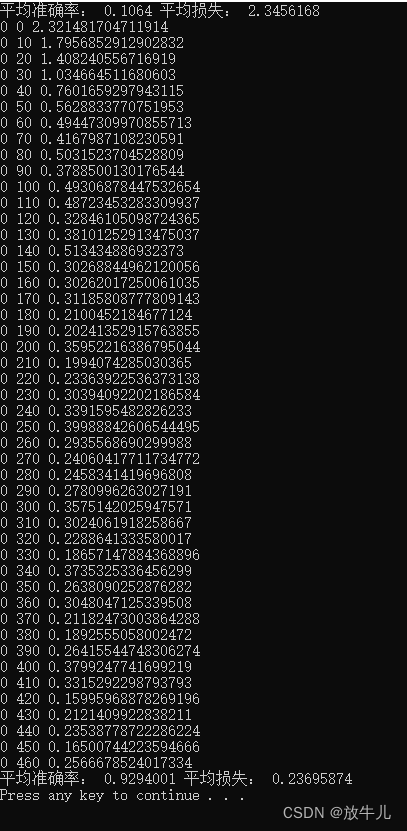
print("平均准确率:",np.mean(acc_list),"平均损失:",np.mean(loss_list))
for i in range(1):
train(i)
test()3、完整代码
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
import os
import torch
import numpy as np
BATCH_SIZE = 128
TEST_BATCH_SIZE = 1000
#准备数据集
def get_dataloader(train,batch_size=BATCH_SIZE):
transform_fn = Compose([
ToTensor(),
Normalize(mean = (0.1307,),std = (0.3081,))
])#mean和std的形状与通道数相同
dataset = MNIST(root = './data',train = train,transform = transform_fn)
data_loader = DataLoader(dataset,batch_size = batch_size,shuffle = True)
return data_loader
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel,self).__init__()#继承
self.fc1 = nn.Linear(1*28*28,28)#参数是input和output的feature
self.fc2 = nn.Linear(28,10)
def forward(self,input):
#1.进行形状的修改
x = input.view([-1,1*28*28])#-1表示根据形状自动调整,也可以改为input.size(0)
#2.进行全连接的操作
x = self.fc1(x)
#3.激活函数的处理
x = F.relu(x)#形状没有变化
#4.输出层
out = self.fc2(x)
return F.log_softmax(out,dim = -1)
model = MnistModel()
optimizer = Adam(model.parameters(),lr = 0.001)
def train(epoch):#epoch表示几轮
data_loader = get_dataloader(True)#获取数据加载器
for idx,(input,target) in enumerate(data_loader):#idx表示data_loader中的第几个数据,元组是data_loader的数据
optimizer.zero_grad()#将梯度置0
output = model(input)#调用模型,得到预测值
loss = F.nll_loss(output,target)#调用损失函数,得到损失,是一个tensor
loss.backward()#反向传播
optimizer.step()#梯度的更新
if idx % 10 == 0:
print(epoch,idx,loss.item())
#for是每一轮中的数据进行遍历
def test():
loss_list = []
acc_list = []
test_dataloader = get_dataloader(train = False,batch_size=TEST_BATCH_SIZE)#获取测试集
for idx,(input,target) in enumerate(test_dataloader):
with torch.no_grad():#不计算梯度
output = model(input)
cur_loss = F.nll_loss(output,target)
loss_list.append(cur_loss)
#计算准确率,output大小[batch_size,10] target[batch_size] batch_size是多少组数据,10列是每个数字概率
pred = output.max(dim = -1)[-1]#获取最大值位置
cur_acc = pred.eq(target).float().mean()
acc_list.append(cur_acc)
print("平均准确率:",np.mean(acc_list),"平均损失:",np.mean(loss_list))
test()
for i in range(1):#训练三轮
train(i)
test()运行结果: