搭建基于GMM-HMM的嵌入式命令词识别系统
一、准备
首先明确这是一个基于GMM-HMM的嵌入式命令词识别系统,它和基于GMM-HMM的孤立词识别系统有很大不同,孤立词识别系统的很好的一个参考文章是这篇,下面将简要介绍两个模型的区别,图和说明都是为了表述而简化的概念性版本,和我们实际操作的细节会有一些区别。
简要地说,孤立词的GMM-HMM模型是每个需要识别的词对应一个GMM-HMM,如图所示:
假设我们需要识别的词包括“前进”、“后退”、“左转”、“右转”,那么我们就会建立四个模型,每个模型对应其中的一个词,模型训练的时候,每个词的音频就用来训练其对应的GMM-HMM,最大化似然概率,训练完成之后,当我们遇到新的输入 x x x的时,我们把 x x x分别输入到这四个模型中,然后计算出四个似然概率,哪个大我们就认为 x x x是哪个词。
在这个模型中,每个词的训练数据只用来训练它自己的GMM-HMM,而与其他词无关,因而称为一个孤立词识别系统,这样的模型搭建简单,容易训练,针对性强,但是你会发现它有个问题,明明左转和右转里都有一个“转”字,那“左转”和“右转”的音频里应该有相似的部分可以让模型从二者的共性中学的更好啊,而且,如果我要新加一个命令词“跳跃”,我就要重新收集数据然后训练这个GMM-HMM,在命令词较多或需要动态扩充命令词的时候就十分麻烦。
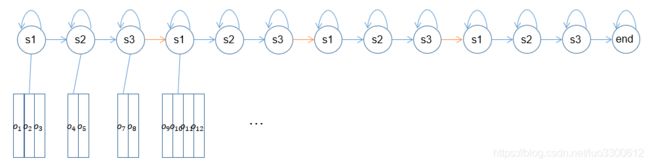
因而,我们可以考虑建立一个嵌入式的GMM-HMM命令词识别系统,这个系统如图所示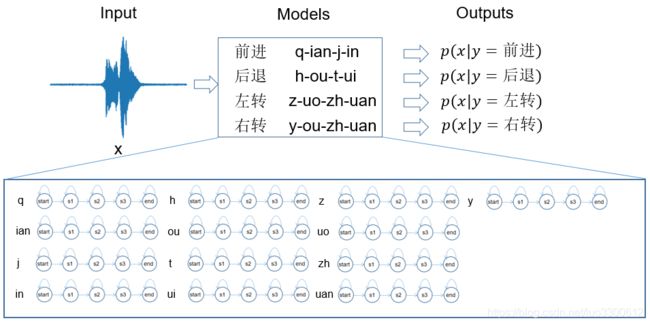
我们不再把每个词对应一个GMM-HMM,而是把每个声韵母对应一个GMM-HMM,训练的时候,我们只需要将声韵母序列对应的GMM-HMM连接起来(具体怎么连实验步骤中有),然后训练,比如“前进”的声韵母序列是“q”,“ian”,“j”,“in”,因此我们只需要把“q”,“ian”,“j”,“in”分别对应的GMM-HMM连起来,然后来训练这个样本即可。当我们遇到新的输入 x x x的时,我们把 x x x分别输入到这四个连起来的GMM-HMM中,然后计算出四个似然概率,哪个大我们就认为 x x x是哪个词。
由于我们的模型是音素级别的,当我们遇到需要识别的词时,我们只需要把对应的音素序列的GMM-HMM连接起来,这个过程就是一个嵌入的过程,因此称它为嵌入式的模型,注意到这个时候,我们甚至不需要准备“前进”、“后退”这样的训练数据,我们可以准备任意语音-句子对,只要保证我们的数据集中包括“q”,“ian”,“j”,“in”等音素即可,而且,当我们需要新增一个命令词“跳跃”时,我们只需要将“t”,“iao”,“y”,“ue”四个因素的GMM-HMM连接起来计算似然概率即可,无须重新训练模型,这样的模型可以用来识别几乎任意命令词(只要训练集中包含相应的音素),灵活性大大提高,只不过训练需要较多的数据、模型搭建较复杂。
二、开始
下面开始构建一个嵌入式命令词识别系统,其目的就是识别“前进”、“后退”、“左转”、“右转”
数据准备
首先来了解一下训练数据到底是什么样的,录音总共350句话,一句话对应一个音频,内容举例:
毛巾上有一个洞。
很抱歉,他们都在忙。很抱歉,他们都在忙。
你能帮我将这个东西抬起来吗?
请问,这个座位有人坐了吗?
可以看到,这些数据并没有刻意为“前进”等命令词准备,而是随机的日常对话。
为了建立嵌入式的音素级命令词识别系统,我们需要首先将这些句子都转化成音素序列,这里我用的是DaCiDian,里面有每个字对应的音素,其实就是一个简单的字到音素的映射过程,转化结果如下:
其中sil代表silence,因为每段录音的前后总会有一段静音的时间,需要在HMM里加入sil音素来对应这段时间的音频,这里的音素我使用的是带声调的版本。实际转化中存在多音字的错误问题,然而无伤大雅,只要一致即可,因此没有人为去处理这些问题(主要是因为懒),最后一共有181种音素。
我们日常说话中,说出来的各个音素的次数都是不同的,在这个数据集中,不同音素的出现次数如图所示:

其中,出现次数前五的音素分别是:’sil’ 700次,’i_0’413次,’y’390次,’d’387次,’sh’264次,出现次数仅为1次的音素有10种,这种不平衡问题会导致出现次数较少的音素所对应的模型无法得到充分训练,由于我们使用的是GMM-HMM模型,GMM模型在数据少的时候协方差矩阵难以估计,因此,将所有出现次数小于5次的音素使用特殊音素’UNK’替代,采用这种方法,数据集中总共有27类共67出现频次的音素被“UNK”替代,最后得到的音素类别为155个。
音频特征我们使用各个维度独立的13维MFCC特征,这也是我们GMM模型的重要假设。
三、模型建立及初始化
因为GMM-HMM是使用EM算法进行训练,所以需要参数初始化。
1. HMM初始化
根据数据预处理结果,我们需要建立155个GMM-HMM模型,这里我们每个音素的GMM-HMM采用通常的参数设置方法,其HMM共有4个状态(省略了开始状态),除了结束状态,中间三个状态都为发射状态(一般我们认为它们分别对应音素的开始,中间和结束),每个发射状态对应一个由3个高斯分布组成的GMM,然后先初始化HMM的初始分布和状态转移矩阵,以uang_1为例: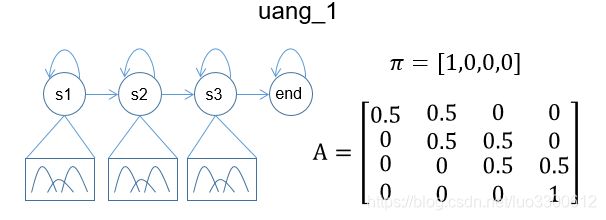
2. GMM初始化
那么如何来初始化每个状态对应的GMM呢?为了初始化GMM,我们需要把音素的GMM-HMM连起来,之前说了很多遍连起来,具体怎么连还是看下图,这是一个我对“彩虹”连接的示例:
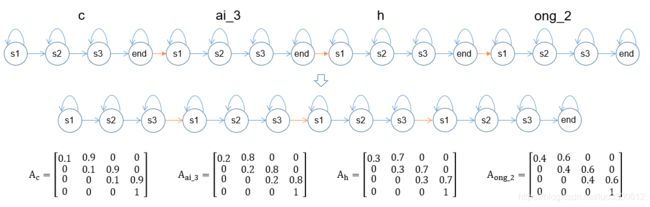
其实就是将GMM-HMM首尾相连嘛,连接之后,去掉中间的end状态,仅保留最后的end状态(包括之前去掉start状态,这些是我为了我编程时的方便的做法,具体操作因人而异),连接好之后,还需要将参数整合到一起,如果音素的小HMM转移矩阵如上图所示,那么连接后的大HMM的转移矩阵就是:

显然,初始的状态分布应该是:
![]()
而对于GMM参数,因为每个状态与其自己的GMM状态参数一一对应,所以在连接的时候也不需要什么特别的操作。
当然回到主题,这里连接GMM-HMM是为了初始化GMM参数,见下图:
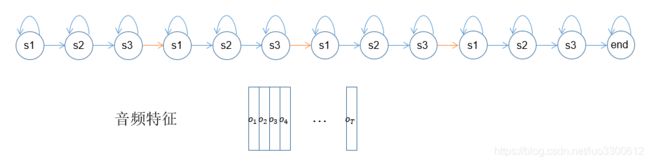
与HMM不同,我们需要根据音频特征来初始化GMM的参数(因为GMM-HMM的训练对GMM初始参数很敏感,因此不能像HMM那样随便初始化),我们首先来数一数上图中的发射状态数,共有12个,假设T=24,那么每个状态就会分到两个特征,具体地,就是第一个s1分到o1 o2,第一个s2分到o3 o4,以此类推,就是通过均分特征序列将两个序列有序地对齐起来。
注意到我们每个音素不仅仅是在一个句子中出现(甚至也会在一句话中出现多次),因此在我们对整个数据集进行此操作之后,每个音素的三个状态都会被分配到很多特征,从而我们可以对每个音素每个状态对应的GMM进行初始化(使用k-means算法),这样我们就初始化好了GMM的参数。
四、训练
初始化完成后,我们终于可以开始训练模型啦,这里使用的是Viterbi训练方法,整个过程是一个EM算法,分为E步和M步,概括地说,在E步,我们用当前参数重新根据Viterbi算法计算出一个特征和状态的对齐结果(刚刚初始化的时候我们用的是平均分割的对齐方法),然后在M步我们根据新的对齐结果重新估计参数。其实前面两个步骤理解完成之后,这个步骤就相对简单了。
1. E step
E步的时候就是重算对齐结果,这里直接使用Viterbi算法就可以了,如果不了解可以直接看网上的关于Viterbi算法的教程,简单说,我们使用了Viterbi算法,就可以计算出一个新的特征序列和状态序列的对齐结果,也就是知道哪些特征对应哪些状态,从而可以继续进行M step,下面就是一个Viterbi对齐结果:
这里呢,在E step额外要做的就是使用前向算法计算每个训练数据的似然概率,然后计算整个数据集的平均似然概率,作为模型训练程度的一个参考数值,通过前后两轮的似然概率之差,我们可以决定在何时终止模型的训练。
在整个数据集上完成上述操作即可开始M step。
2. M step
在M step,我们需要重新估计模型的参数,这些参数包括HMM的状态转移矩阵,以及GMM的参数,首先,对于HMM的状态转移矩阵参数估计,其本质上就是个数数的过程,以上图的结果为例,s1对应o1 o2 o3,s2对应o4 o5,s3对应o7 o8,第二个s1对应o9 o10 o11 o12,那么第一个s1就有两次转移到自身(o1->o2, o2->o3),一次转移到s2(o3->o4),因此 ![]() 之后的各个转移概率就这样一个个更新,需要注意的是,这里举的例子是一个语音——状态对的统计结果,实际训练时,我们是按照整个训练集上的统计结果进行状态转移矩阵更新的。
之后的各个转移概率就这样一个个更新,需要注意的是,这里举的例子是一个语音——状态对的统计结果,实际训练时,我们是按照整个训练集上的统计结果进行状态转移矩阵更新的。
对于GMM的参数,那就更简单了,每个状态直接根据被分配到的特征来更新(k-means初始化或者训练GMM)就可以了。
3. 训练过程
模型在整个数据集上的对数似然和训练轮次如图所示:

在验证集(专门录制的“前进”、“后退”、“左转”、“右转”每个5句共20句的数据集)上的准确率如图所示:
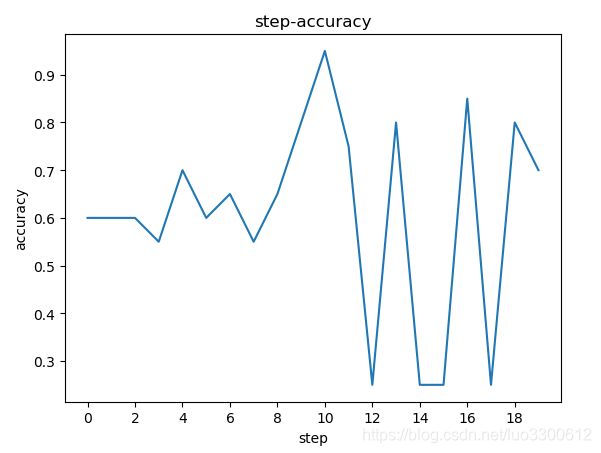
可以看到模型的验证集最好的结果是95%准确率,模型训练初始阶段平均对数似然不断上升,随后发生震荡。
4. 训练结果
Viterbi算法最有趣的部分就是它可以对其两个序列,而无需我们进行这种精度的标注,最后95%准确率模型的Viterbi对齐结果示例如图所示:
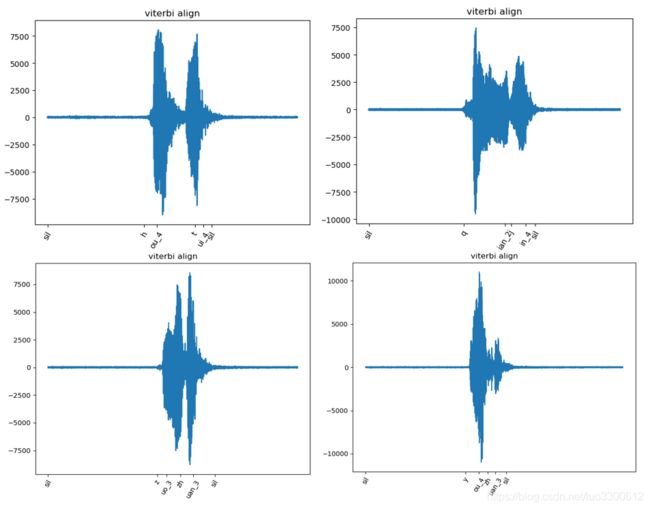
可以看到对齐的结果还是很准,这种模型的解释性也就挺好。
五、细节问题
为了行文的顺畅,很多细节问题都没有加以讨论,在此简单讨论其中几个关键问题:
1. 过拟合问题
其实最开始写完模型,是有严重的过拟合问题的,模型几乎瞬间在验证集上达到顶峰,随后一直在25%不变,为了解决这个问题,我选择了13维的MFCC特征而不是通常差分过的39维MFCC特征,这样减少了GMM的参数,一定程度上降低了过拟合问题,另一个想到的解决方法是使用不带声调的声韵母系统,不过我还没尝试。
2. 数值问题
用numpy和scipy从零开始搭这个系统,就需要自己解决其中存在的很多数值问题,比如有的音素的状态的GMM中某个高斯的协方差矩阵数值太小等问题,当然,导致这些问题的原因其实也是数据量不均匀,有的音素数据多,有的音素数据少,就使得你不可能单纯通过降低模型参数来解决这个问题(会导致数据多的音素欠拟合),为了解决这个问题,代码中我但凡碰到这种协方差矩阵,就将该高斯直接从GMM成分中舍弃,这样做其实是建立了一个动态K的GMM模型。
3. 标点符号
日常用语中带停顿的标点符号我也按照通常的做法使用’sp’音素代替了。
4. GMM
我在hmm_learn里面看到他们会使用协方差的对角矩阵来简化协方差矩阵,也算是减少参数的方法,因此我所有的GMM中使用的也是对角矩阵
5. 参数重估
HMM的状态转移参数重估的时候我加入了平滑,也就是分母和分子都+1,来保护一些较小的转移
6. 概率
GMM的参数重估方法我仅仅用K-means对其进行重新初始化了,这里我实在不清楚到底是要将GMM训练到收敛还是仅仅重新初始化它,因此我选了一个比较快的方法
7. LogSumExp
永远不要自己尝试去写什么logsumexp softmax之类的东西,就算你知道算的时候要减去一个最大值来保证exp的数值稳定,可你写的还是会爆炸…
本项目的数据在这个地址:链接: https://pan.baidu.com/s/1Ewz8ZyzEM8F6VYVZGynn8w 提取码: aonm