GoogLeNet网络结构详解及代码复现
1. GoogLeNet论文详解
Abstract:
提出了GoogLeNet网络结构——22层,此设计允许在保证计算预算不变的前提下,增加网络的深度和宽度,这个网络结构是基于Hebbian原则和多尺度处理,并且在ILSVRC 2014中的分类任务中获得第一名。
对于大型数据集,最近的趋势是增加层数和每一层的尺寸,同时使用dropout来解决过拟合问题
- 层尺寸的增大意味着需要更大数量的参数,这会使得网络更容易过拟合,尤其是对于数据集小的情况下
- 层深度的增加会大大增加计算资源的使用,尤其是卷积层的权重为0时,会浪费大量计算资源
1x1 卷积 & 全局平均池化
这两种方法都是为了提高卷积网络的表达能力,改善网络结构的。在Network-in-network中被提出的。

1x1卷积:
- 可以通过设置1x1卷积核的数量来实现降维或升维
- 实现特征图的通道间的聚合

全局平均池化:
传统CNN网络中,前面堆叠卷积层提取特征,最后通过全连接层分类提取出的特征,但是全连接层很容易导致模型过拟合,并且其参数比较多,为了解决这个问题,出现了dropout,但是在Network-in-network中,作者提出了全局平均池化来解决此问题
将卷积层提取出来的特征图(Feature map)进行相加求平均,然后将这些特征图对应的平均值作为某一类的置信度输入到softmax进行分类(要控制卷积层的最后一层的特征图数量与最终分类数量保持一致)
此方法的好处
- 减少了参数(相对于全连接层)
- 减轻过拟合
- 求和取平均操作综合了空间信息,提高模型的鲁棒性
缺点:
对特征图的简单相加求平均可能会丢失一些有用信息
网络结构细节:
- Inception

1x1卷积应用于3x3卷积和5x5卷积之前,主要作用:降维,降低参数数量
以inception(3a)中3x3卷积为例:
input: 28x28x192
- 不使用
1x1卷积
其参数数量为:192x3x3x128=221184 - 使用
1x1卷积
其参数数量为:192x1x1x96+96x3x3x128=184320
相当于先将channel的维数从192维降到96维
- GoogLeNet参数

- 所有的卷积层都包含
ReLu激活层 - #3x3 reduce:表示
Inception结构中3x3卷积层前的1x1卷积核的数量 - #5x5 reduce:表示
Inception结构中的5x5卷积前的1x1卷积核的数量 - pool proj:表示
Inception结构中的最大池化层后的1x1卷积核的数量
- GoogLeNet网络结构

- 红色:池化层
- 蓝色:卷积层+ReLu
- 绿色:拼接操作
- 黄色:softmax激活函数
由于网络的深度相对比较大,能够在所有层保证梯度能传播是一个问题。对此我们增加了2个辅助分类器,在训练期间辅助分类器的权重为0.3,在预测时,这些层会被丢弃。
辅助分类器结构:
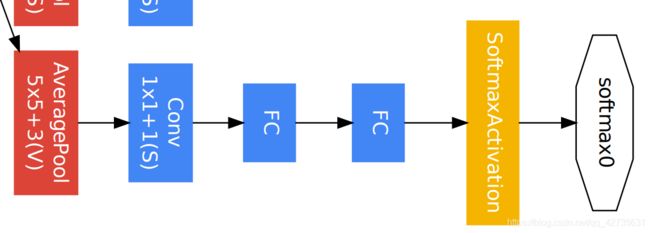
- AveragePool:滤波器大小(5,5)、步长:3。输出:4*4*512(from 4a)、4*4*528(from 4d)
- Conv:1x1卷积、卷积核数量:128、步长:1
- FC:(128*4*4,1024)
- FC:(1024,1000)
2. 基于Pytorch代码复现:
2.1 模型搭建
import torch
import torch.nn as nn
import torchvision.models as models
from torchsummary import summary
import torch.optim as optim
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._init_weight()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, start_dim=1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
if self.aux_logits and self.training:
return x, aux2, aux1
return x
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AdaptiveAvgPool2d((4, 4))
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.aux_classifier = nn.Sequential(
nn.Linear(128 * 4 * 4, 1024),
nn.Dropout(p=0.5),
nn.ReLU(inplace=True),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.averagePool(x)
x = self.conv(x)
x = torch.flatten(x, start_dim=1)
x = self.aux_classifier(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
2.2 训练结果如下
- 训练数据集与验证集大小以及训练参数
Using 3306 images for training, 364 images for validation
Using cuda GeForce RTX 2060 device for training
lr: 0.0001
batch_size: 16
- 使用自己定义的网络训练结果
[epoch 1/10] train_loss: 2.350 val_acc: 0.407
[epoch 2/10] train_loss: 1.912 val_acc: 0.505
[epoch 3/10] train_loss: 1.842 val_acc: 0.511
[epoch 4/10] train_loss: 1.769 val_acc: 0.560
[epoch 5/10] train_loss: 1.746 val_acc: 0.566
[epoch 6/10] train_loss: 1.670 val_acc: 0.621
[epoch 7/10] train_loss: 1.595 val_acc: 0.635
[epoch 8/10] train_loss: 1.538 val_acc: 0.621
[epoch 9/10] train_loss: 1.509 val_acc: 0.681
[epoch 10/10] train_loss: 1.456 val_acc: 0.657
Best acc: 0.681
Finished Training
Train 耗时为:277.0s
- 使用预训练模型参数训练结果
[epoch 1/10] train_loss: 0.668 val_acc: 0.871
[epoch 2/10] train_loss: 0.359 val_acc: 0.901
[epoch 3/10] train_loss: 0.298 val_acc: 0.923
[epoch 4/10] train_loss: 0.268 val_acc: 0.920
[epoch 5/10] train_loss: 0.252 val_acc: 0.904
[epoch 6/10] train_loss: 0.228 val_acc: 0.923
[epoch 7/10] train_loss: 0.196 val_acc: 0.915
[epoch 8/10] train_loss: 0.210 val_acc: 0.92
[epoch 9/10] train_loss: 0.169 val_acc: 0.918
[epoch 10/10] train_loss: 0.179 val_acc: 0.93
Best acc: 0.931
Finished Training
Train 耗时为:239.9s
上一篇:VggNet
下一篇:ResNet
完整代码