目标检测正负样本区分和平衡策略(anchor-based)
最近看了一篇大佬写关于正负样本区分和平衡策略的博文,研究了一下并且查了一下资料进行了补充,加上个人的见解和解读,在此做个总结,欢迎大家补充指正,侵权必删。
大佬博文:目标检测正负样本区分策略和平衡策略总结(一) - 知乎
目标检测正负样本区分策略和平衡策略总结(anchor-based)
本文抛弃网络具体结构,仅仅从正负样本区分和正负样本平衡策略进行分析,大体可以分为 正负样本定义、正负样本采样和平衡loss设计三个方面 ,主要是网络预测输出和loss核心设计即仅涉及网络的head部分。 本文是第一部分anchor-base,主要包括faster rcnn、libra rcnn、retinanet、ssd和yolo一共5篇文章。
-
关于正负样本的概念:
——正样本指属于某一类别的样本;负样本指不属于某一类别的样本,如背景。
-
为什么要进行正负样本采样?
——在ROI、RPN等过程中,整个图像中正样本区域少,大部分是样本,因此要处理好正负样本不平衡问题。
对于目标检测算法,主要需要关注的是对应着真实物体的 正样本 ,在训练时会根据其loss来调整网络参数。相比之下, 负样本对应着图像的背景,如果有大量的负样本参与训练,则会淹没正样本的损失,从而降低网络收敛的效率与检测精度。
-
anchor-free和anchor-base:
——二者的区别在于是否利用anchor提取候选框
- 从anchor回归属于anchor-based类,代表如faster rcnn、retinanet、YOLOv2 v3、ssd等
- 从point回归属于anchor-free类,代表如cornernet、extremenet、centernet等
- 二者融合代表如fsaf、sface、ga-rpn等
-
anchor-based:
Two Stage:例如Faster-RCNN算法。第一级专注于proposal的提取,第二级对提取出的proposal进行分类和精确坐标回归。两级结构准确度较高,但因为第二级需要单独对每个proposal进行分类/回归,速度上就打了折扣
One Stage:例如SSD,YOLO算法。此类算法摒弃了提取proposal的过程,只用一级就完成了识别/回归,虽然速度较快但准确率远远比不上两级结构
1.two-stage
1.1 faster-RCNN

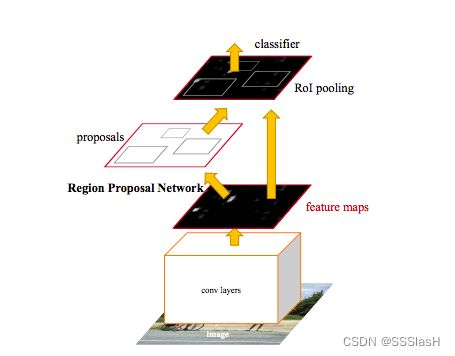
RPN结构:
rpn的作用是从图像中提取proposals,也就是预测框
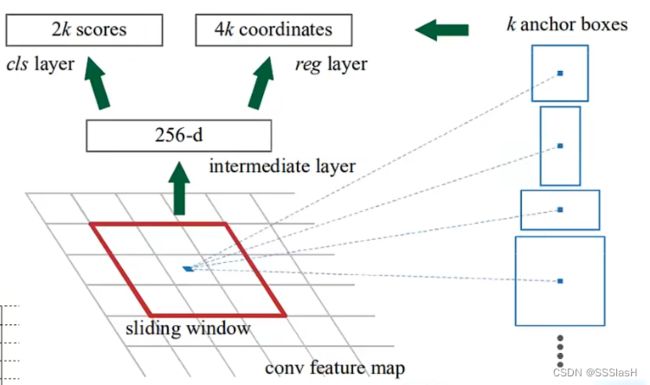

faster rcnn总体结构:
对于每个中心点(anchors)我们创建3个anchor box,也就是矩形框
anchor box:

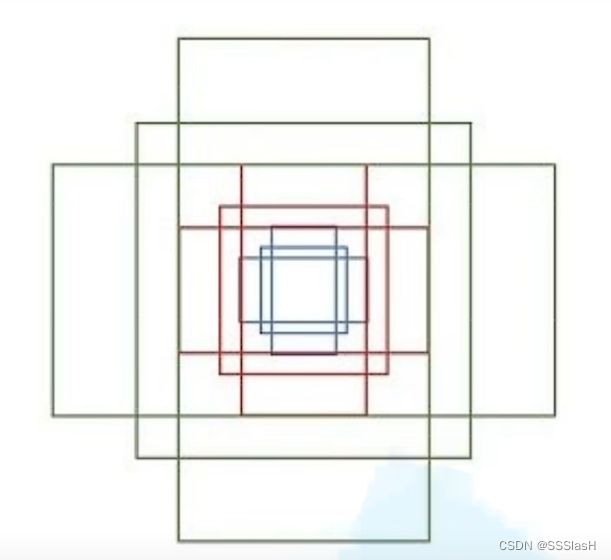
每个位置(每个滑动窗口)在原图上对应九个anchor
(1) head结构
faster rcnn包括两个head:rpn head和rcnn head。其结构如下:
RPN结构主要用于生产候选框

——use_sigmoid (_cls)= True 是否使用sigmoid来进行分类,如果False则使用softmax来分类
rcnn head:
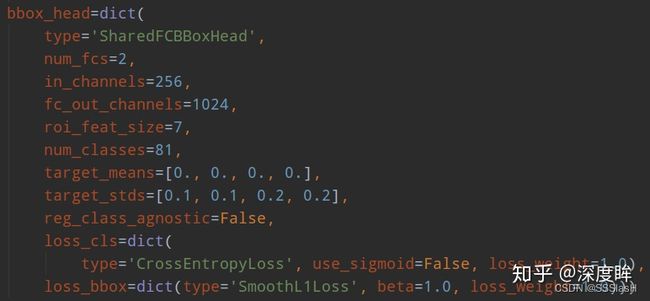
-
class-specific (class-aware )方式: 很多地方也称作class-aware的检测,是早期Faster RCNN等众多算法采用的方式。它利用每一个RoI特征回归出所有类别的bbox坐标,最后根据classification 结果索引到对应类别的box输出。
-
class-agnostic 方式: 只回归2类bounding box,即前景和背景,结合每个box在classification 网络中对应着所有类别的得分,以及检测阈值条件,就可以得到图片中所有类别的检测结果。当然,这种方式最终不同类别的检测结果,可能包含同一个前景框,但实际对精度的影响不算很大,最重要的是大幅减少了bbox回归参数量。
(2) 正负样本定义
rpn:
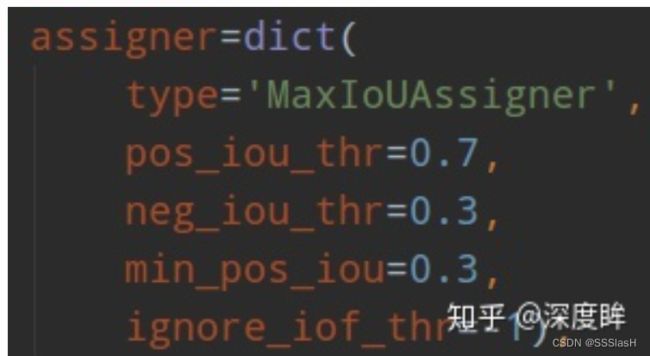
在RPN网络中,对每一个Anchor分配标签 。 正例:对于每一gt box,交并比最大的Anchor,或与任一gt box的最大交并比大于0.7。负例:与所有gt boxes交并比小于0.3。交并比在(0.3,0.7)区间的Anchor忽略。 从而保证每一个gt box都有一个Anchor与之对应。
rcnn:
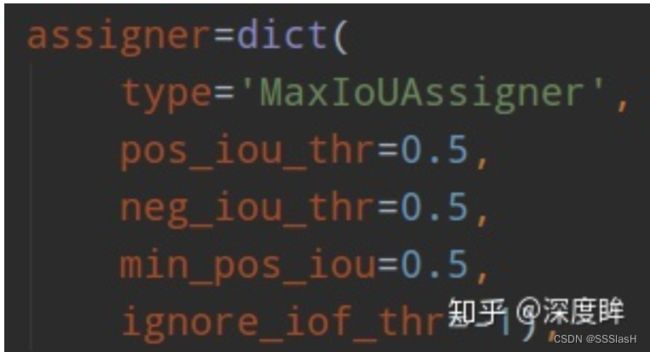
在fast rcnn中,对输出的proposal分配标签。 正例:与某一gt box交并比超过0.5。负例:与gt boxes的最大交并比在(0[或者0.1],0.5)之间
——初始化时候假设每个anchor的mask都是-1,表示都是忽略anchor
总结:
1.如果anchor和gt的最大iou低于neg_iou_thr的,那就是 负样本 ,其应该包括大量数目;
2.如果某个anchor和其中一个gt的最大iou大于pos_iou_thr,那么该anchor就负责对应的gt,定义为 正样本 ;
3.如果某个gt和所有anchor的iou中最大的iou会小于pos_iou_thr,但是大于min_pos_iou,则依然将该anchor负责对应的gt;
4.其余的anchor全部当做忽略区域,不计算梯度。
该最大分配策略,可以尽最大程度的保证每个gt都有合适的高质量anchor进行负责预测。
(3) 正负样本采样
步骤2可以区分正负和忽略样本,但是依然存在大量的正负样本不平衡问题, 解决办法可以通过正负样本采样或者loss上面一定程度解决。faster rcnn的rpn和rcnn都采用随机采样, 阈值不一样
rpn head采样器:

取256个ROI送去训练
正负样本的比例为1:1,不够的话用负样本代替
rcnn head采样器:
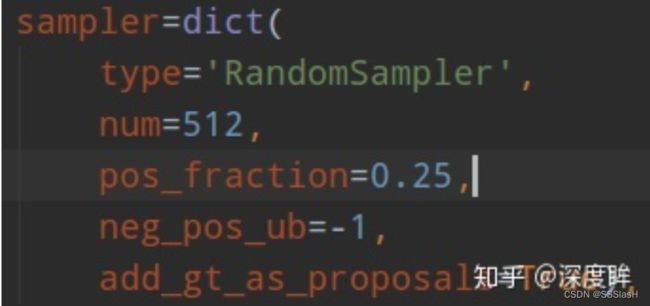
—————— 正负样本比为 1:3
add_gt_as_proposals是为了放在正样本太少而加入的; 将 gt_box 认定为一个 proposal,默认是 True
由于rcnn head的输入是rpn head的输出,在网络训练前期,rpn无法输出大量高质量样本,故为了平衡和稳定rcnn训练过程,通常会对rcnn head部分添加gt作为proposal。
loss: 由于原始faster rcnn采用的loss是ce和SmoothL1Loss,不存在loss层面解决正负样本不平衡问题 。
1.2 libra rcnn
libra主要是分析faster rcnn训练过程中的不平衡问题,并提出解决方案。 ibra rcnn的head部分和正负样本定义没有修改。仅分析 正负样本采样和平衡loss设计部分。
(1) 正负样本采样
仅修改了rcnn的采样部分:
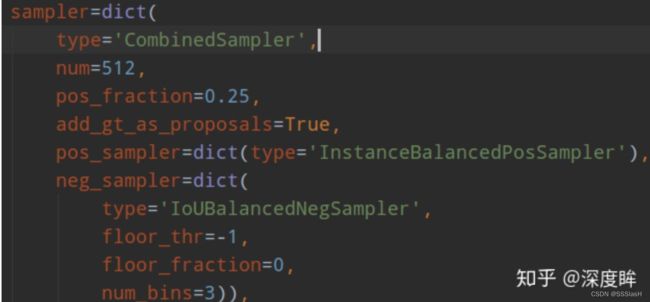
作者采用了ioubalancedNegSampler。
作者觉得当采用随机采样后,会出现难负和易负样本不平衡,导致后面性能不好 。
具体做法: 例如假设总共有1000个候选负样本(区间1:800个,区间2:120个,区间3:80个),分为3个区间,总共想取333个,那么理论上每个区间是111个,首先第一次在不同区间均匀采样,此时区间1可以采样得到111个,区间2也可以得到111个,区间3不够,所以区间三全部采样;然后不够的样本数,在剩下的(800-111)+(120-111)+0个里面随机取31个,最终补齐333个。
(2) 平衡回归loss
原始的faster rcnn的rcnn head,使用的回归loss是smooth l1

作者在smooth l1的基础上进行重新设计,得到 Balanced L1 Loss 。核心操作就是想要得到一个当样本在 |x|<1 附近产生稍微大点的梯度的函数。

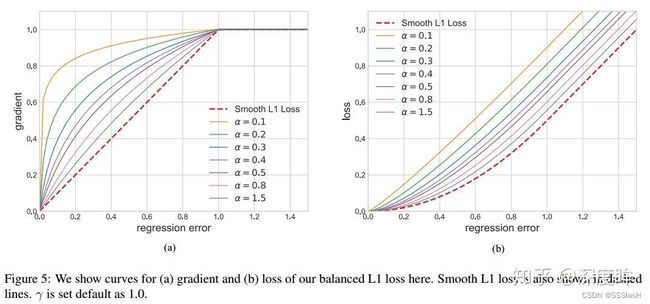
左边是梯度曲线,右边是loss曲线(默认设置α=0.5,γ=1.5或者1.0)
2.one-stage
2.1 focal loss( retinanet)
(1) head结构

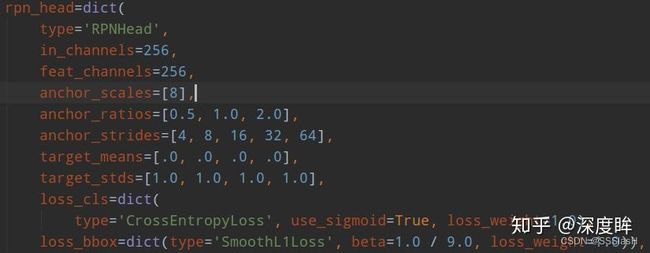
(2) 正负样本定义
retinanet是one-stage算法, 阈值定义和rpn不一样。
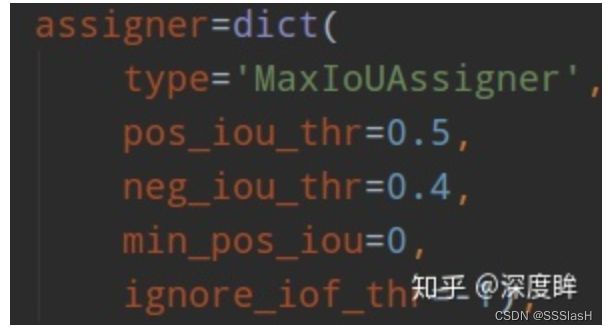
min_pos_iou=0,可以保证每个GT一定有对应的anchor负责预测。0.4以下是负样本,0.5以上且是最大Iou的anchor是正样本, 0.4~0.5之间的anchor是忽略样本。其不需要正负样本采样器,因为其是通过平衡分类loss来解决的。
(3) 平衡分类loss
FocalLoss是结构的重点,是用于处理分类分支中大量正负样本不平衡问题
*****one-stage检测算法存在严重的精度差异问题*****
————FocalLoss目的:处理正负样本不平衡+挖掘的难分样本
关于正负样本和难易样本的区分:
正负样本:事先约定一个iou的阈值,检测框与label的iou大于该阈值认为是正样本,小于则是负样本
难易样本:对于正样本中预测概率较高的说明是易分样本,负样本中预测概率较低的也是易分样本。因为这些框很容易被正确分类。但对于正样本中预测概率不高的,负样本中预测概率较高的都是难分样本,这类样本很难被正确分类。
|
预测概率/
样本类型
|
正样本
|
负样本
|
|
p较高
|
易分样本(少量)
|
难分样本(大量)
|
|
p较低
|
难分样本(少量)
|
易分样本(大量)
|
——focal loss根据交叉熵改进而来
CE loss函数:
——其中 y 为类别真实标签, p 是模型预测 的概率。
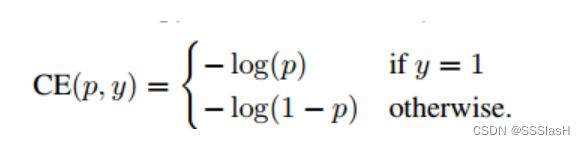 (1)
(1)
因为是二分类, p表示预测样本属于1的概率 (范围为0- 1 )
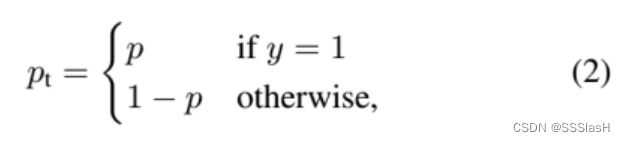
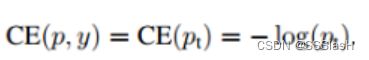
对于类别不均衡问题常用的方法是引入一个权重因子 αt ,对于类别1的使用权重 α ,对于类别-1使用权重 1-α
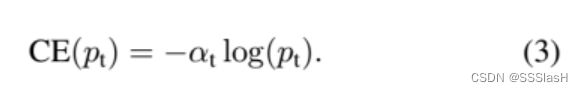
其中,  (α是一个超参数,用来平衡正负样本权重。原文中取0.75效果最好)
(α是一个超参数,用来平衡正负样本权重。原文中取0.75效果最好)
(α是一个超参数,用来平衡正负样本权重。原文中取0.75效果最好)

γ>=0;( γ的作用就是用来区分难易样本 )
γ=0的蓝色曲线就是标准的交叉熵损失;实验发现 γ取2最好

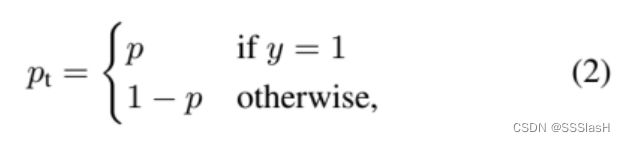
如上图,横坐标代表pt, 纵坐标表示各种样本所占的loss权重。对于正样本,我们希望p越接近1越好,也就是pt 接近1为易分正样本;对于负样本,我们希望p越接近0越好,也就是pt 接近1为易分负样本。所以不管是正样本还是负样本,我们总是希望他预测得到的pt 越大越好,这便属于易分类样本。如上图所示,pt ∈[0.6,1]就是我们预测效果比较好的样本(也就是易分样本)。

两个重要性质:
1.当Pt→0 , 那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,相比原来的loss是没有什么大的变化
2. 当γ=0的时候,focal loss就是传统的交叉熵损失。 当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍, 当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。———————— 让准确率低的样本进行主导
例:
假设pt=0.1, -log(pt)= 2.3026 ; 当γ=2时,-(1-pt) γ log(pt) = 1.8651 (loss基本不变)
假设pt=0.9, -log(pt)= 0.1054 ; 当γ=2时,-(1-pt) γ log(pt) = 0.001054 (loss缩小一百倍)
综合以上两个方面,最终应用的focal loss:
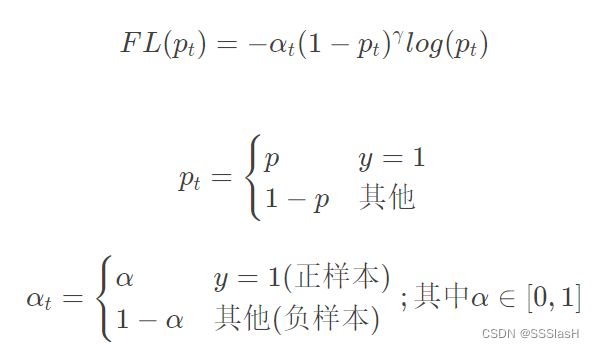
其中αt 来协调正负样本之间的平衡,  来降低简单样本的权重,使损失函数更关注困难样本。
来降低简单样本的权重,使损失函数更关注困难样本。
缺点:易受噪音干扰;需要调参
2.2 yolov2、v3
(1) head结构
yolov3也是多尺度输出,每个尺度有3个anchor。但其 和faster rcnn或者ssd也有不一样的地方,其类别预测是不考虑背景的,所以才多引入了一个confidence的概念,该分支用于区分前景和背景。
(2) 正负样本定义
yolo系列的正负样本定义原则和MaxIoUAssigner非常类似。但其有一个原则: 保证每个gt bbox一定有一个唯一的anchor进行对应,而不考虑阈值。 匹配规则就是IOU最大,选取出来的即为 正样本 。 IOU<忽略阈值(人为设定阈值) 的作为 负样本。 除了正负样本,其余的全部为 忽略样本。 对于confidence分支,其在上述MaxIoU分配原则下,还需要从负样本中划分出额外的忽略区域。 将负样本中的iou大于 忽略iou阈值 中的anchor设置为忽略区域。
最大IOU超过忽略阈值的一部分虽然不负责预测对象,但IOU较大,可以认为包含了目标的一部分,这部分不参与误差计算。
此时就区分出了正、负和忽略anchor样本,正anchor用于分类、回归分支学习,正负anchor用于confidence分支学习,忽略区域不考虑。
(3) 样本采样
通常情况下, Yolov3 所有的样本都有用到,所以采用默认的采样器PseudoSampler,不做任何的采样操作。
(4) loss
采用的是普通的bce分类Loss(目标置信度损失和目标类别损失)和smooth l1 回归loss(目标定位损失)。
2.3 ssd
ssd300的head结构如下:
(1) head结构
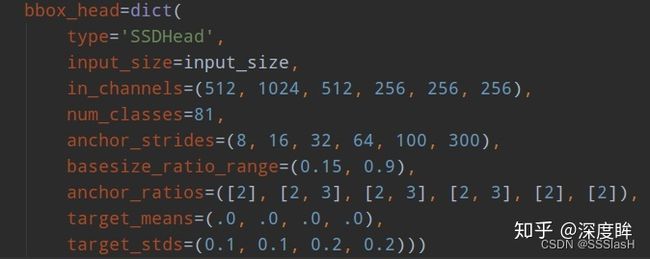
ssd一共包括6个尺度输出,每个尺度的strides由anchor_strides设置。
——在原文中,Smin=0.2,而head结构设置smin=0.15 ?
basesize_ratio_range表示正方形anchor的min_size和max_size,anchor_ratios表示每个预测层的anchor个数,以及比例( 比例在这里并未给出 )。
anchor_ratios设置与源码有些出入?
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
*****由anchor_ratios设置,第1、5、6层只有两种长宽比,因此只有四个anchor box;其余层有六个anchor box
anchor的生成过程:
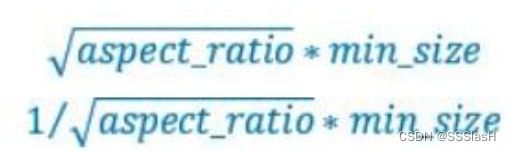

作者设计了一个公式来生成anchor的size:
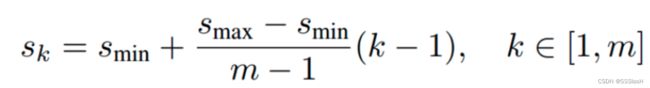
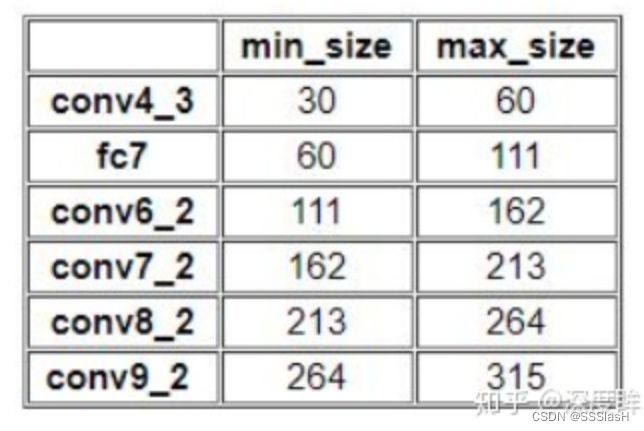
在原文中,Smin=0.2,Smax=0.9;但 第一个特征图Conv4_3 中比较特殊, Smin设置为0.1, 故第一层的Sk =0.1,输入是300,故conv4_3的min_size=300*0.1=30 , max_size=300*0.2=60
以此类推可以得到每个特征图的min_size和max_size:
(2) 正负样本定义
ssd采用的正负样本定义器依然是MaxIoUAssigner
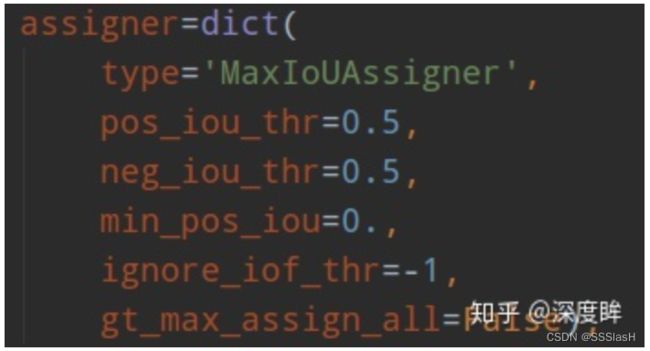
其定义anchor与gt的iou小于0.5的就全部认为是负样本,大于0.5的最大iou样本认为是正样本anchor,同时由于min_pos_iou=0以及gt_max_assign_all=False,可以发现该设置的结果是 每个gt可能和多个anchor匹配上,匹配阈值比较低,且每个gt一定会和某个anchor匹配上,不可能存在gt没有anchor匹配的情况,且没有忽略样本 。
(3) 平衡分类loss
分为两个部分:
-
定位损失( localization loss )
-
置信度损失( confidence loss )
-
定位损失计算的预测框与标注框之间的smooth l1损失;
-
置信度损失计算的是交叉熵损失;
-
整体的损失函数是定位损失和置信度损失的加权求和
由于正负样本差距较大,如果直接采用ce和smooth l1训练,效果可能不太好,样本不平衡比较严重。 作者的ce loss其实采用了ohem+ce的策略, 设置 neg_pos_ratio=3即负样本是正样本的3倍
ohem:
(在线困难样本挖掘,Online Hard Example Mining)
——————OHEM是让loss大的进行主导(适用于two-stage算法)
算法优点:
1)对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强;
2)随着数据集的增大,算法的提升更加明显(作者是通过在COCO数据集上做实验和VOC数据集做对比,因为前者的数据集更大,而且提升更明显,所以有这个结论)
参考:
-
目标检测算法 - RetinaNet - 知乎
-
目标检测正负样本区分策略和平衡策略总结(一) - 知乎
-
mmdetection之Faster RCNN注释详解 - One Blog | 文鹃阁
-
什么是anchor-based 和anchor free? - 知乎
-
目标检测中的loss - 知乎 【trick 3】Focal Loss —— 解决one-stage目标检测中正负样本不均衡的问题_满船清梦压星河HK的博客-CSDN博客_目标检测 解决正负样本不均衡
-
YOLOv3/v4/v4/x中正负样本的定义_折磨王的博客-CSDN博客_yolo 正负样本
-
CE Loss 与 BCE Loss 学习和应用 - 知乎
-
Softmax函数和Sigmoid函数的区别与联系 - 知乎
-
检测模型改进—OHEM与Focal-Loss算法总结_m_buddy的博客-CSDN博客_focal loss和ohem