【机器学习】集成模型方法
作者 | Salma Elshahawy, MSc.
编译 | VK
来源 | Towards Data Science
介绍
我们之前讨论了一些利用机器学习(ML)模型预测能力的常用方法。这些方法主要通过将数据分解成特定的方案来提高模型的可推广性。
然而,有更先进的方法来提高模型的性能,如集成算法。在这篇文章中,我们将讨论和比较多种集成算法的性能。所以,让我们开始吧!
集成方法旨在将多个基估计器的预测组合起来,而不是单一估计器,从而利用模型的泛化和鲁棒性。
预备知识
我将使用托管在Kaggle上的UCIML公共存储库中的toy数据集(https://www.kaggle.com/uciml/pima-indians-diabetes-database);它有九列,包括目标变量。如果你想使用,GitHub笔记本链接如下:https://github.com/salma71/blog_post/blob/master/Evaluate_ML_models_with_ensamble.ipynb。
在处理时,我使用kaggle api获取数据集。如果你在Kaggle上没有帐户,只需下载数据集,并跳过笔记本中的这一部分。
我获取数据并将其下载到google colab,确保在运行它之前生成自己的令牌。
在构建模型之前,我对数据集做了一些基本的预处理,比如插补缺失的数据,以避免错误。
我创建了两个单独的笔记本,一个用来比较前三个集成模型。第二种方法是使用MLens库实现堆叠集成。
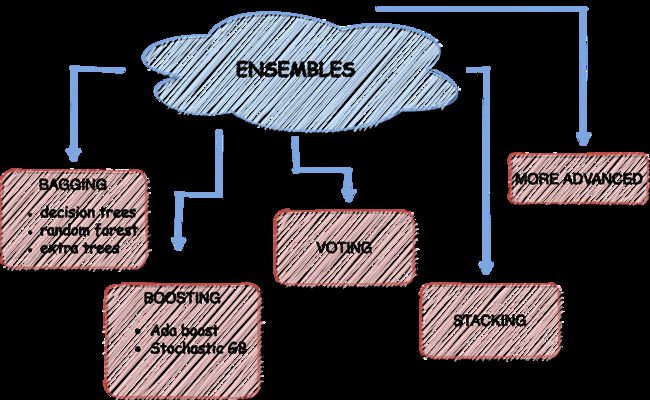
集成方法
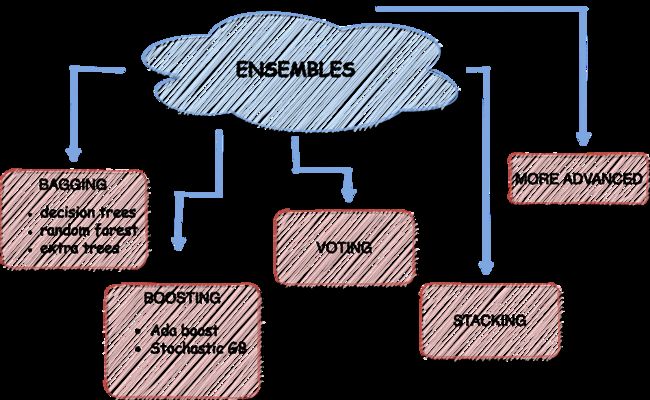
集成是建立各种模型的过程,然后将它们混合以产生更好的预测。与单个模型相比,集成能够实现更精确的预测。在ML比赛中,利用集成通常会带来优势。你可以找到CrowdFlower winners的团队采访,他们用集成赢得了比赛:https://medium.com/kaggle-blog/crowdflower-winners-interview-3rd-place-team-quartet-cead438f8918
1.Bagging — Bootstrap聚合:
Bootstrap聚合倾向于从不同的子样本构建多个模型(使用相同类型的算法),并从训练数据集中替换。
Bagging是将多个好的模型集成在一起,以减少模型的方差。

Bagging有三种类型的集成,如下所示:
1.1Bagging决策树
Bagging在产生高方差预测的算法中表现最好。在下面的示例中,我们将在sklearn库中开发BaggingClassifier和DecisionTreeClassifier的组合。
请注意,由于随机学习的性质,结果可能会有所不同!
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier()
bagging_clf = BaggingClassifier(base_estimator=tree, n_estimators=1500, random_state=42)
bagging_clf.fit(X_train, y_train)
evaluate(bagging_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[126 24]
[ 38 43]]
ACCURACY SCORE:
0.7316
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.768293 0.641791 0.731602 0.705042 0.723935
recall 0.840000 0.530864 0.731602 0.685432 0.731602
f1-score 0.802548 0.581081 0.731602 0.691814 0.724891
support 150.000000 81.000000 0.731602 231.000000 231.000000
1.2 随机森林(RF)
随机森林(RF)是一种元估计器,它在多个子样本上拟合不同的决策树分类器,并估计其平均准确率。
子样本大小是恒定的,但是如果bootstrap=True(默认),样本将被替换。
现在,让我们来尝试一下随机森林(RF)模型。RF的工作原理与bagged decision tree类类似;但是,它降低了单个分类器之间的相关性。RF只考虑每个分割特征的随机子集,而不是采用贪婪的方法来选择最佳分割点。
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=42, n_estimators=1000)
rf_clf.fit(X_train, y_train)
evaluate(rf_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[127 23]
[ 38 43]]
ACCURACY SCORE:
0.7359
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.769697 0.651515 0.735931 0.710606 0.728257
recall 0.846667 0.530864 0.735931 0.688765 0.735931
f1-score 0.806349 0.585034 0.735931 0.695692 0.728745
support 150.000000 81.000000 0.735931 231.000000 231.000000
1.3额外树(Extra trees,ET)
额外树(ET)是对Bagging的一种改进。ExtraTreesClassifier()是sklearn库中的一个类,它创建一个元估计器来拟合不同子样本的几个随机决策树(又称ET)。然后,ET计算子样本之间的平均预测。这样可以提高模型的准确率并控制过拟合。
from sklearn.ensemble import ExtraTreesClassifier
ex_tree_clf = ExtraTreesClassifier(n_estimators=1000, max_features=7, random_state=42)
ex_tree_clf.fit(X_train, y_train)
evaluate(ex_tree_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[350 0]
[ 0 187]]
ACCURACY SCORE:
1.0000
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 1.0 1.0 1.0 1.0 1.0
recall 1.0 1.0 1.0 1.0 1.0
f1-score 1.0 1.0 1.0 1.0 1.0
support 350.0 187.0 1.0 537.0 537.0
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[124 26]
[ 32 49]]
ACCURACY SCORE:
0.7489
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.794872 0.653333 0.748918 0.724103 0.745241
recall 0.826667 0.604938 0.748918 0.715802 0.748918
f1-score 0.810458 0.628205 0.748918 0.719331 0.746551
support 150.000000 81.000000 0.748918 231.000000 231.000000
2. Boosting
Boosting是另一种构建多个模型(同样来自同一类型)的技术;但是,每个模型在模型序列中修复前一个模型的预测错误。Boosting主要用于平衡有监督机器学习模型中的偏差和方差。Boosting是一种将弱学习者转化为强学习者的算法。
Boosting算法从弱估计器中建立了一个连续的基估计器,从而减小了组合估计器的偏差。
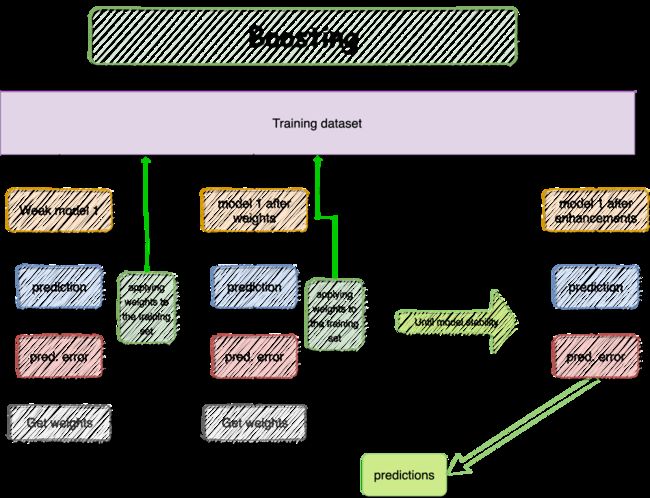
2.1 AdaBoost(AD)
AdaBoost(AD)通过分类特征来给数据集实例添加权重。这使得算法能够在构建后续模型时考虑这些特征。
from sklearn.ensemble import AdaBoostClassifier
ada_boost_clf = AdaBoostClassifier(n_estimators=30)
ada_boost_clf.fit(X_train, y_train)
evaluate(ada_boost_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[314 36]
[ 49 138]]
ACCURACY SCORE:
0.8417
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.865014 0.793103 0.841713 0.829059 0.839972
recall 0.897143 0.737968 0.841713 0.817555 0.841713
f1-score 0.880785 0.764543 0.841713 0.822664 0.840306
support 350.000000 187.000000 0.841713 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[129 21]
[ 36 45]]
ACCURACY SCORE:
0.7532
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.781818 0.681818 0.753247 0.731818 0.746753
recall 0.860000 0.555556 0.753247 0.707778 0.753247
f1-score 0.819048 0.612245 0.753247 0.715646 0.746532
support 150.000000 81.000000 0.753247 231.000000 231.000000
2.2 随机梯度增强(SGB)
随机梯度增强(SGB)是一种先进的集成算法。在每次迭代中,SGB从训练集中随机抽取一个子样本(无需替换)。然后利用子样本对基础模型(学习者)进行拟合,直到误差趋于稳定。
from sklearn.ensemble import GradientBoostingClassifier
grad_boost_clf = GradientBoostingClassifier(n_estimators=100, random_state=42)
grad_boost_clf.fit(X_train, y_train)
evaluate(grad_boost_clf, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[339 11]
[ 26 161]]
ACCURACY SCORE:
0.9311
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.928767 0.936047 0.931099 0.932407 0.931302
recall 0.968571 0.860963 0.931099 0.914767 0.931099
f1-score 0.948252 0.896936 0.931099 0.922594 0.930382
support 350.000000 187.000000 0.931099 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[126 24]
[ 37 44]]
ACCURACY SCORE:
0.7359
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.773006 0.647059 0.735931 0.710032 0.728843
recall 0.840000 0.543210 0.735931 0.691605 0.735931
f1-score 0.805112 0.590604 0.735931 0.697858 0.729895
support 150.000000 81.000000 0.735931 231.000000 231.000000
3.投票
投票是一套同样表现良好的模式,以平衡他们的弱点。投票采用三种方法进行投票程序,硬、软和加权。
硬投票-大多数的类标签预测。
软投票-预测概率之和的argmax。
加权投票-预测概率加权和的argmax。

投票很简单,也很容易实现。首先,它从数据集中创建两个独立的模型(可能更多,取决于用例)。在引入新数据时,采用投票分类器对模型进行包装,并对子模型的预测进行平均。
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
estimators = []
log_reg = LogisticRegression(solver='liblinear')
estimators.append(('Logistic', log_reg))
tree = DecisionTreeClassifier()
estimators.append(('Tree', tree))
svm_clf = SVC(gamma='scale')
estimators.append(('SVM', svm_clf))
voting = VotingClassifier(estimators=estimators)
voting.fit(X_train, y_train)
evaluate(voting, X_train, X_test, y_train, y_test)
TRAINIG RESULTS:
===============================
CONFUSION MATRIX:
[[328 22]
[ 75 112]]
ACCURACY SCORE:
0.8194
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.813896 0.835821 0.819367 0.824858 0.821531
recall 0.937143 0.598930 0.819367 0.768037 0.819367
f1-score 0.871182 0.697819 0.819367 0.784501 0.810812
support 350.000000 187.000000 0.819367 537.000000 537.000000
TESTING RESULTS:
===============================
CONFUSION MATRIX:
[[135 15]
[ 40 41]]
ACCURACY SCORE:
0.7619
CLASSIFICATION REPORT:
0 1 accuracy macro avg weighted avg
precision 0.771429 0.732143 0.761905 0.751786 0.757653
recall 0.900000 0.506173 0.761905 0.703086 0.761905
f1-score 0.830769 0.598540 0.761905 0.714655 0.749338
support 150.000000 81.000000 0.761905 231.000000 231.000000
4.堆叠
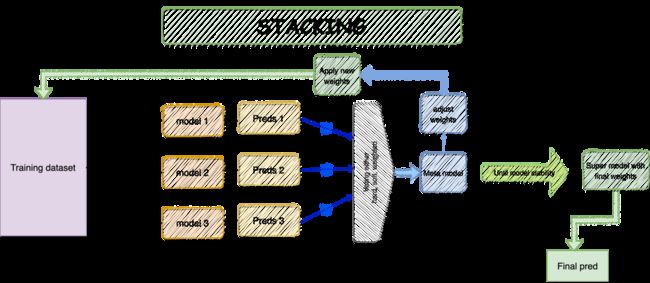
堆叠的工作原理与投票集成相同。然而,堆叠可以调整子模型预测顺序——作为元模型的输入,以提高性能。换句话说,堆叠从每个模型的算法中产生预测;随后,元模型使用这些预测作为输入(权重)来创建最终输出。
堆叠的优势在于它可以结合不同的强大的学习者,与独立的模型相比它作出精确和稳健的预测。
sklearn库在集成模块下有StackingClassifier()。但是,我将使用ML集成库实现堆叠集成。
为了在堆叠和以前的集成之间做一个公平的比较,我用10折重新计算了以前的准确率。
from mlens.ensemble import SuperLearner
# 创建基础模型列表
def get_models():
models = list()
models.append(LogisticRegression(solver='liblinear'))
models.append(DecisionTreeClassifier())
models.append(SVC(gamma='scale', probability=True))
models.append(GaussianNB())
models.append(KNeighborsClassifier())
models.append(AdaBoostClassifier())
models.append(BaggingClassifier(n_estimators=10))
models.append(RandomForestClassifier(n_estimators=10))
models.append(ExtraTreesClassifier(n_estimators=10))
return models
def get_super_learner(X):
ensemble = SuperLearner(scorer=accuracy_score,
folds = 10,
random_state=41)
model = get_models()
ensemble.add(model)
# 添加一些层
ensemble.add([LogisticRegression(), RandomForestClassifier()])
ensemble.add([LogisticRegression(), SVC()])
# 添加元模型
ensemble.add_meta(SVC())
return ensemble
# 超级学习者
ensemble = get_super_learner(X_train)
# 拟合
ensemble.fit(X_train, y_train)
# 摘要
print(ensemble.data)
# 预测
yhat = ensemble.predict(X_test)
print('Super Learner: %.3f' % (accuracy_score(y_test, yhat) * 100))
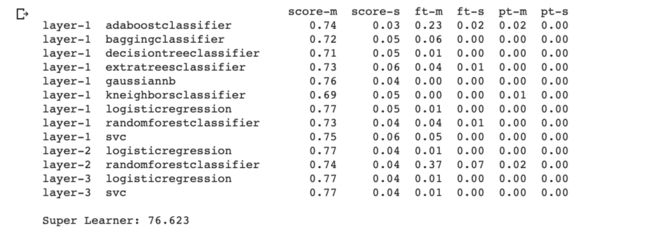
ACCURACY SCORE ON TRAIN: 83.24022346368714
ACCURACY SCORE ON TEST: 76.62337662337663
比较性能
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Bar(
x = test['Algo'],
y = test['Train'],
text = test['Train'],
textposition='auto',
name = 'Accuracy on Train set',
marker_color = 'indianred'))
fig.add_trace(go.Bar(
x = test['Algo'],
y = test['Test'],
text = test['Test'],
textposition='auto',
name = 'Accuracy on Test set',
marker_color = 'lightsalmon'))
fig.update_traces(texttemplate='%{text:.2f}')
fig.update_layout(title_text='Comprehensive comparasion between ensembles on Train and Test set')
fig.show()

如图所示,堆叠集合在测试集上表现良好,最高分类准确率为76.623%。
5.结论和收获
我们已经探索了几种类型的集成,并学习如何以正确的方式实现它们,以扩展模型的预测能力。我们还总结了一些需要考虑的要点:
堆叠算法在精度、鲁棒性等方面都有提高,具有较好的泛化能力。
当我们想要设置性能良好的模型以平衡其弱点时,可以使用投票。
Boosting是一个很好的集成方法,它只是把多个弱的学习者结合起来,得到一个强大的学习者。
当你想通过组合不同的好模型来生成方差较小的模型时,可以考虑Bagging—减少过拟合。
选择合适的组合取决于业务问题和你想要的结果。
最后,我希望这能为实现集成提供一个全面的指导。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: