selenium中文文档_贝程学院:Selenium与DOM
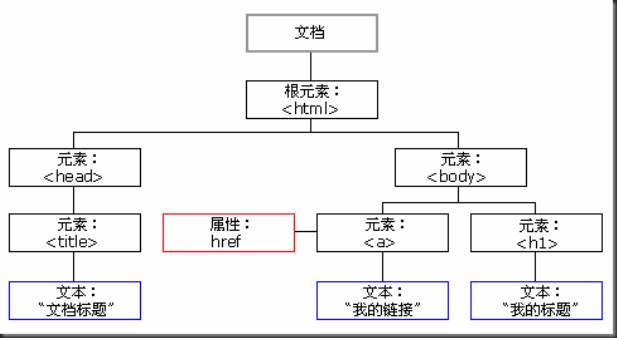
一.为什么学习DOM
Selenium需要定位页面元素,而DOM 代表了整个 HTML 文档的结构,使用 DOM对象可以访问 DOM 中的节点。 WebDriver甚至可以通过执行任意的返回值为 DOM 对象的 JavaScript 语句来查找元素,所熟悉DOM对于Selenium处理页面元素来说如虎添翼。
二.什么是DOM
DOM是Document Object Model文档对象模型的缩写。根据W3C DOM规范,DOM是一种与浏览器,平台,语言无关的接口,使得你可以访问页面其他的标准组件。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中导航寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。HTML DOM是HTML Document Object Model(文档对象模型)的缩写,HTML DOM则是专门适用与HTML/XHTML的文档对象模型。熟悉软件开发的人员可以将HTML DOM理解为网页的API。它将网页中的各个元素都看作一个个对象,从而使网页中的元素也可以被计算机语言获取或者编辑。 例如JavaScript就可以利用HTMLDOM动态的修改网页。“W3C的文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。W3CDOM标准被分为 3 个不同的部分:核心 DOM - 针对任何结构化文档的标准模型;XML DOM - 针对 XML 文档的标准模型;HTML DOM - 针对 HTML 文档的标准模型。 DOM将HTML和XML文档映射成一个由不同节点组成的树型机构。俗称DOM树。每种节点都对应于文档中的信息或标记,节点有自己的属性和方法,并和其他节点存在某种关系,节点之间的关系构成了节点层次。
三.初识HTMLDOM
因为python没有很直观的处理HTML DOM的库,为了便于学习所以我们用javascript来进行解析处理,本部分学习用js代码来完成。HTML DOM 是 W3C 标准(是 HTML 文档对象模型的英文缩写,Document Object Model for HTML)。它定义了用于 HTML 的一系列标准的对象,以及访问和处理 HTML 文档的标准方法。通过 DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。HTML DOM 独立于平台和编程语言,它可被任何编程语言诸如 Java、JavaScript 和 Python使用。
下面是HTML源码:
HTML DOM学习
DOM构成
DOM树结构:
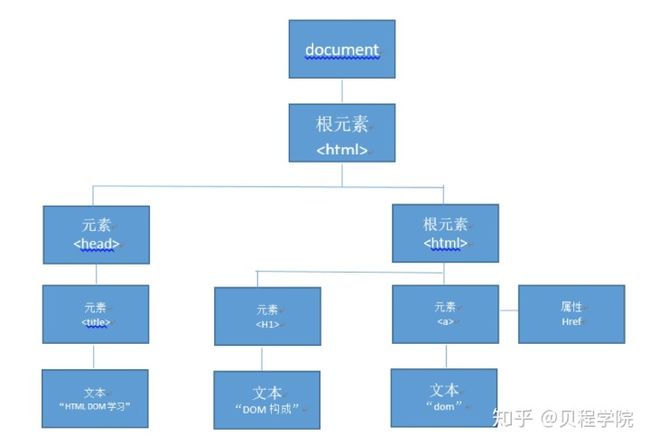
- DOM模型将整个文档HTML文档看成一个树形结构,并用document对象表示该文档。每个载入浏览器的HTML文档都会成为Document对象。Document对象使我们可以从脚本中对HTML页面中的所有元素进行访问。
- DOM规定文档中的每个成分都是一个节点(Node):
- 文档节点(Document):代表整个文档
- 元素节点(Element):文档中的一个标记
- 文本节点(Text):标记中的文本
- 属性节点(Attr):代表一个属性,元素才有属性
当浏览器载入HTML文档时,浏览器解释其代码,按照html的载入顺序在内存中创建这些对象,对象创建完毕后浏览器为这些对象提供了专供javascript脚本可用的可选属性,方法和处理程序。通过这些属性,方法,处理程序,web开发人员很好的完成相应功能的实现。
四.HTMLDOM节点
在DOM中,html文档各个节点被视为各种类型的Node对象,每个Node对象都有自己的属性和方法,利用这些属性和方法可以通过遍历整个文档,由于HTML的复杂性,DOM定义了nodeType来表示节点的类型。
在W3C DOM中,每个容器,独立的元素或者文本块都可以被看作是一个节点,其对应的节点存在父子关系,同时该节点树遵循HTML的结构化本质,如元素包括
元素,他们有分别包含了不同的节点。在HTMLdom中有六种不同的节点类型:
HTML DOM树中有元素节点,属性节点,文本节点分别介绍:
A. 元素节点
在HTML文档中,各个HTML元素如
等构成了文档结构模型的一个个节点对象,在节点树中又构成了一个个节点,元素可以包含其他元素,例如HTML列表标签生成的列表元素,包含- ,例如html代码:
- Coffee
- Tea
- Milk
B. 文本节点
在节点树中,元素节点构成了树的枝干,而文本节点则构成了树的树叶,
郭靖知道师父虽然摔下,并不碍事,但欧阳锋若乘势追击,后着可凌厉之极,叫道:“看招!”左腿微屈,右掌划了个圆圈,平推出去,正是降龙十八掌中的“亢龙有悔”。
,在html中文本是包含在元素节点内部的,如上面这段文字就是包含在元素内。
C. 属性节点
HTML文档中袁术都有一些属性,这些属性准确的便于开发人员操作。如:
你好,世界!
,这里class=dom就是属性节点。
从上面的描述可以看出来节点树中的节点彼此拥有层级关系,节点之间的关系可以使用类似人类家族关系的形式描述。如在HTML文档中,可以把html标签看作是body标签的父元素;相对的,body标签也就是html标签的子元素;而做为body标签同级的head标签两都之者的关系为兄弟(姐妹)关系。在dom中父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
- 在节点树中,顶端节点被称为根(root)
- 每个节点都有父节点、除了根(它没有父节点)
- 一个节点可拥有任意数量的子
- 同胞是拥有相同父节点的节点
五.HTML DOM操作
在Web自动化测试开发中达到控制页面元素,执行相应操作行为的目的,了解HTMLDOM是很有必要的,我们用JavaScript来用代码操作DOM是因为DOM接口是标准的,另外是因为可以了解更多的代码细节。JavaScript操作DOM一般有以下4种操作;
- 更新: 更新该DOM节点的内容,相当于更新了该DOM节点表示的HTML内容;
- 遍历: 遍历该DOM节点下的字节点,以便进行进一步操作;
- 添加: 在该DOM节点下新增一个子节点,相当于动态增加了一个HTML节点;
- 删除: 将该节点从HTML中删除,相当于删掉了该DOM节点内容以及它包含的所有子节点
JavaScript实现的DOM接口一般有:
1. Document属性
A. document.title //设置文档标题等价于HTML的title标签
B. document.bgColor //设置页面背景色
C. document.fgColor //设置前景色(文本颜色)
D. document.linkColor //未点击过的链接颜色
E. document.alinkColor //激活链接(焦点在此链接上)的颜色
F. document.vlinkColor //已点击过的链接颜色
G. document.URL //设置URL属性从而在同一窗口打开另一网页
H. document.fileCreatedDate //文件建立日期,只读属性
I. document.fileModifiedDate //文件修改日期,只读属性
J. document.charset //设置字符集 简体中文:gb2312
K. document.fileSize //文件大小,只读属性
L. document.cookie //设置和读出cookie
2. Document常用对象方法
A. document.write() //动态向页面写入内容
B. document.createElement(Tag) //创建一个html标签对象
C. document.getElementById(ID) //获得指定ID值的对象 /
D. document.getElementsByName(Name) //获得指定Name值的对象
E. document.body.appendChild(oTag)
3. 获取HTML元素
A. getElementByID(id):通过对元素的ID访问,这是DOM访问页面元素的方法.
实例:
dom操作
我是第一个P
我是第二个P
测试
技术解释:如果id在元素中不是唯一的,那么获得的将是第一个ID,window.onload是在DOM文档树加载完和所有文件加载完之后执行一个函数,也就是自己触发该函数。
B. getElementsByName(name):仅用于input ,radio checkbox等元素,返回名字为name的元素数组
实例:
dom操作
我是第一个P
我是第二个P
测试
/>
C. getElementsByTagName(tagname):返回具有tagname的元素列表数组.处理大的DOM结构会用到它,
实例:获取页面所有DIV元素
div 1
div 2
4 .操作DOM 元素
A. document.createElement(eName):创建一个节点
DOM操作
第一段
第二段
B. appendChild(node):向当前对象追加节点
实例:
DOM操作
第一段
第二段
C. removeChild(childreference):移除当前节点的子节点,并返回节点
实例:
dom操作
父亲
儿子
姑娘
D. cloneNode(deepBoolean):复制并返回当前的复制节点,由于复制了原节点的id属性,所以在document树中要改ID属性,以确保ID唯一性.
E. insertBefore(newElment,targetElement) 插入新的节点。在当前节点插入一个新节点,如果targetElement为null,那新节点为最后节点.
实例:
insertBefore()函数
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
5. DOM Element常用属性
A. childeNodes 返回所有子节点对象
实例:
返回节点文本
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
B. innerHTML:这是一个标准,但它并不是DOM
实例:
修改元素
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
C. style:这是一个极其重要的属性,可以获取并修改每个单独的样式.
实例:
设置属性
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
D. 节点
firstChild:返回第一个子节点;lastChild :返回最后一个子节点:parentNode :返回父节点的对象;nextSibling :返回下一个兄弟节点的对象;previousSibling 返回前一个兄弟节点的对象; 元素节点可以用数组元素childNodes[0]来获取,和他等同的功能的属性,且更加语义化,可以用firstChild,lastChild等属性。假设我们需要目标元素节点下的所有子元素中的第一个子元素可以这样做:目标元素节点下的子元素节点数组.firstChild 这句代码等价于目标元素节点下的子元素节点数组[0];目标元素节点.childNodes[0] 这句代码等价于 目标元素节点.firstChild;与此类推当我们需要目标元素节点下的所有子元素节点中的最后一个元素我们可以这样做:目标元素节点下的子元素节点数组.lastChild 这句代码等价于 目标元素节点下的子元素节点数组[目标元素节点下的子元素节点数组.length-1]目标元素节点.childNodes[目标元素节点.childNodes.length-1]=目标元素节点.lastChild;从上面的描述中,发现firstChild属性和lastChild属性更加的语义化,而且代码更加的简洁,方便我们记忆;
E. nodeName 返回节点的HTML标记名称,使用英文的大写字母。
作用:如果我们想改变一个文本节点的值,那就是用DOM提供的nodeValue属性,它是用来得到(和设置)一个文本节点的值;
实例:
hello world!
我们获取的p是一个元素节点,
元素本身的nodeValue值是一个null值,而且最重要的是nodeValue属性是用来获取文本节点的值的。所以输出:null.。这个是一个技术细节,也是一个小知识点.需要注意。正确的获取
标签里面文本的做法是获取
标签下文本节点的节点值。
代码如下: 这里
标签代表一个元素节点
hello world!
六.初识XMLDOM
XML ( eXtensible Markup Language )语言是一种可扩展的标记语言。其中的可扩展是相对HTML来说的。因为XML标签没有被预定义,需要用户自行定义标签。通过此种标记,计算机之间可以处理包含各种信息的文章等。XML设计用来传送及携带数据信息,不用来表现或展示数据,所以XML用途的焦点是它说明数据是什么,以及携带数据信息。而HTML语言则用来表现数据。下面自定义一个xml文件来存储书信息:
<书架>
<书出版社="浙江出版社">
<名字>诛仙
<作者>萧鼎
<价格>32.00
<出版日期>2007年
<书出版社="文艺出版社">
<名字>笑傲江湖
<作者>金庸
<价格>50.00
<书出版社="人邮出版社">
<名字>selenium自动化测试
<作者>威链优创
<价格>50.00
XML 文档的第一行是一个 XML 声明,这是文件的可选部分,它将文件识别为XML文件,该XML文件表示书架上有三本书,并把每本书标识出出版社,名称,作者,价格。在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可以分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其他标签描述其他数据,以此来实现数据关系的描述。在上个实例中书名,作者,价格都是自定义标签,如果你喜欢你可以把所有的标签名字都改成英文也可以。
通过前面的知识我们了解DOM是一种树结构,XML文档结构就是类似倒长的树型结构
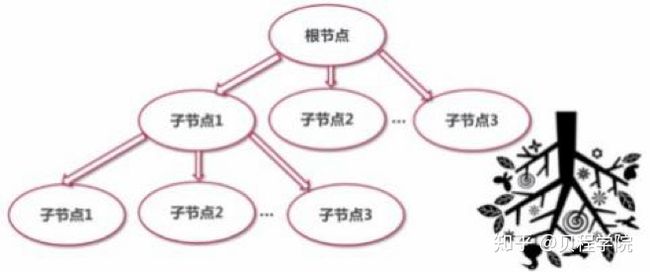
XML语法
一个XML文件分为如下6部分内容:文档声明,元素 ,属性,注释 ,CDATA区、特殊字符,处理指令(processing instruction)。
1. XML文档声明
XML声明语句一般是这样,放在XML文档的第一行 ,version 指文档符合XML1.0规范 ;encoding指文档字符编码,比如”GB2312”或者”UTF-8” ;还有参数standalone指文档定义是否独立使用 ,standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
2. XML元素
A. XML文档必须有且只有一个根元素
- 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标记要放在所有其他元素的起始标记之前
- 跟元素的结束标记要放在所有其他元素的结束标记之后
B. XML元素指的是XML文件中出现的标签,标签都是成对出现分为开始和结束标签
C. (命名规范: XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守以下规范:
- 区分大小写,例如元素name和元素Name是两个不同的元素
- 不能以数字或下划线”_”开头
- 元素内不能包含空格
- 名称中间不能包含冒号(:)
- 可以使用中文
3. XML属性
Tom
- A. 属性值用双引号(”)或单引号(’)分隔,如果属性值中有单引号,则用双引号分隔;如果有双引号,则用单引号分隔。属性值中有单引号或者双引号用转义字符处理,也可以用HTML 字符实体< >: &等。
- B. 一个元素可以有多个属性,它的基本格式为:<元素名 属性名1="属性值1" 属性名2="属性值2">
- C. 特定的属性名称在同一个元素标记中只能出现一次
- D. 属性值不能包括<,>,&,如果一定要包含,也要使用HTML实体字符
4. XML-注释
XML的注释类语法:
- A. 注释内容不要出现--
- B. 不要把注释放在标记中间;
- C. 注释不能嵌套
- D. 可以在除标记以外的任何地方放注释
5. XMLCDATA节
在XML中CDATA被声明不应被解析成标签的文本,其中可以使用特殊字符,包括大于号,小于号和双引号。CDATA段通过来设置,所有在中间的内容都被当做原始字符,而不会进行字符转义。如实际应用中通过XML文件发送图片,就需要用CDATA节来处理。文件本质上是字符串,在底层都是用二进制传输。根据原理通过XML文件将一幅图片的二进制字符串传递过去,然后可以解析成一幅图片。由于字符串就会包含大量的<,>,&或者“等一些特殊的不合法的字符,引擎解析会报错。为了不让图内容用引擎解析执行,而是做为原始内容处理,要用到CDATA节。
语法如下:
......
]]>
6. XML处理指令
处理指令,简称PI(processing instruction)。处理指令用来指示解析引擎如何解析XML文件,看下面一个例子:比如可以使用CSS样式表来修饰XML文件,编写test.css如下:
name{
font-size:60px;
font-weight:bold;
color:red;
}
sex{
font-size:60px;
font-weight:bold;
color:red;
}
age{
font-size:60px;
font-weight:bold;
color:red;
}
我们在xml文件中使用处理指令引入这个CSS文件,如下:
郭靖
男
16
黄蓉
女
21
再用浏览器打开这个xml文件,会发现浏览器解析出一个带样式的视图,而不再是单纯的目录树了。
七.Python和DOM
在python标准库中支持DOM操作的模块是xml.dom,xml文档数据通过xml.dom模块的方法解析为dom树结构后,就可以调用dom规范中定义的方法和属性来访问XML数据。需要注意,这些方法都是DOM规范中规定的,不是xml.dom模块规定的,xml.dom只是实现了这些操作xml数据的接口。
1. XMLDOM接口
A. Document接口:
Document代表整个XML文档,实际上这是XML文档树的根,同时提供了对数据初始访问的入口。
- 1) Document.documentElement:Document对象的根元素。
- 2) Document.createElement(tagName):建立并返回一个新元素节点,但要加入的节点树中,需使用insertBefore() 或append Child()方法。
- 3) document.createTextNode(data):以参数传入的数据建立并返回一个文本节点,但未加入到节点树中。
- 4) document.createComment(data):以参数传入的数据建立并返回一个注释节点,但未加入到节点树中。
- 5) document.createProcessingInstruction(target, data)
- 6) document. createAttribute(name):建立并返回一个属性节点,但要关联到一个元素节点,需要使用方法setAttributeNode()。
- 7) document.createAttributeNS(namespaceURI, qualifiedName)
- 8) Document.getElementsByTagName(tagName):在所有后代节点中查找指定tagname的元素节点,返回子元素到列表,注意是列表。
- 9) Document.getElementsByTagNameNS(namespaceURI, localName)
B. Node接口
XML文档的所有组件都可以看作是Node对象。
- 1) Node.nodeType:用一个整数表示Node对象的类型。该属性为只读。
- 2) Node.parentNode: 当前对象的双亲对象,对于Document对象该属性为None,对于Attr对象总是None。 该属性只读。
- 3) Node.attributes: 包含的属性对象,只有节点对象的类型为元素是才有实际的值。该属性只读。
- 4) Node.previousSibling: 与当前节点同属一个双亲节点的前一个紧邻的节点。对于第一个节点,该属性为
- 5) None:该属性只读。
- 6) Node.nextSibling:与当前节点同属一个双亲节点的后一个紧邻的节点。对于最后一个节点,该属性为None。 该属性只读。
- 7) Node.childNodes:一个包含当前节点的子节点的列表。该属性只读。
- 8) Node.firstChild: 第一个子节点,可以是None。 该属性只读。
- 9) Node.lastChild:最后一个子节点,可以是None。 该属性只读。
- 10) Node.localName:本地标签名称,完整名称中如有冒号,则为冒号之后的部分,否则为完整名称。该属性为字符串。
- 11) Node.prefix:名称前缀,完整名称中如有冒号,则为冒号之前的部分,否则为空。该属性为字符串,或None。
- 12) Node.namespaceURI:与元素关联的命名空间,为一字符串或None。该属性只读。
- 13) Node.nodeName:对于元素节点,等同于tagName;对于属性节点,等同于name。该节点只读。
- 14) Node.nodeValue:与nodeName类似,对于不同类型的节点,有不同的含义。该属性只读。
- 15) Node.hasAttributes():如果节点包含有属性,返回True。
- 16) Node.hasChildNodes():如果节点包含子节点,返回True。
- 17) Node.isSameNode(other):如果指定的节点对象引用的就是本节点,该方法返回True。
- 18) Node.append Child(newChild):在当前节点的最后一个子节点后增加一个新的子节点。该方法将返回新子节点。
- 19) Node.insertBefore(newChild, refChild): 在指定的子节点前插入一个新的节点,如果参照的节点为None,新节点将插入到子节点列表的末尾。该方法返回新子节点。
- 20) Node.removeChild(oldChild):删除一个子节点,该方法执行成功后返回被删除的节点,应适用unlink()方法释放被删除节点占用的内存。
- 21) Node.replaceChild(newChild, oldChild):用一个新的节点替换一个已经存在的子节点。
- 22) Node.normalize():将邻接的文本节点(textNode)连接为单个文本实例,以简化对文本的处理。
- 23) Node.cloneNode(deep):克隆当前节点,设置deep表示克隆所有的子节点。该方法返回克隆节点。
C. Element接口
- 1) Element是Node的子类,nodeType值为1。
- 2) Element.tagName:元素类型名称。
- 3) Element.getElementsByTagName (tagName):与Document类相同。
- 4) Element.getElementsByTagNameNS(namespaceURI, localName)
- 5) Element.hasAttribute(name)
- 6) Element.hasAttributeNS(namespaceURI, localName)
- 7) Element.getAttribute(name):
- 8) Element.getAttributeNode(attrname):返回属性节点。
- 9) Element.getAttributeNS(namespaceURI, localName)
- 10) Element.getAttributeNodeNS(namespaceURI, localName)
- 11) Element.removeAttribute(name)
- 12) Element.removeAttributeNode(oldAttr)
- 13) Element.removeAttributeNS(namespaceURI, localName)
- 14) Element.setAttribute(name, value)
- 15) Element.setAttributeNode(newAttr)
- 16) Element.setAttributeNodeNS(newAttr)
- 17) Element.setAttributeNS(namespaceURI, qname, value)
D. Text接口
- 1) Text接口表示XML文档中的文本,它不存在子节点。如果支持XML扩展,CDATA标记中的文本将被保存在CDATASection对象中。Text节点到nodeType值为3。
- 2) Text.data:节点的文本字符串。
2. XML实例
创建XML文件如下:
郭靖
30
降龙十八掌
黄蓉
20
打狗棒法
A. 获得标签属性
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml") #打开xml文档
root = dom.documentElement #得到xml文档对象
print("nodeName:", root.nodeName) #每一个结点都有它的nodeName,nodeValue,nodeType属性
print("nodeValue:", root.nodeValue) #nodeValue是结点的值,只对文本结点有效
print("nodeType:", root.nodeType)
print("ELEMENT_NODE:", root.ELEMENT_NODE)
技术解释:xml.dom.minidom.parse()得到一个dom对象,它的第一个元素应该是employees,root = dom.documentElement得到文档根元素,也就是得到了employees, 每一个结点都有它的nodeName,nodeValue,nodeType属性。nodeName为结点名字。nodeValue是结点的值,只对文本结点有效。nodeType是结点的类型,现在有以下几种:
- 'ATTRIBUTE_NODE'
- 'CDATA_SECTION_NODE'
- 'COMMENT_NODE'
- 'DOCUMENT_FRAGMENT_NODE'
- 'DOCUMENT_NODE'
- 'DOCUMENT_TYPE_NODE'
- 'ELEMENT_NODE'
- 'ENTITY_NODE'
- 'ENTITY_REFERENCE_NODE'
- 'NOTATION_NODE'
- 'PROCESSING_INSTRUCTION_NODE'
- 'TEXT_NODE'
B. 获得子标签
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml")
root = dom.documentElement
children = root.getElementsByTagName('employee')
print(len(children))
children_brother = children[1]
print(children_brother.nodeName)
print(children_brother.nodeValue)
技术解释:访问子元素、子结点的方法很多,对于知道元素名字的子元素,可以使用getElementsByTagName方法,如读取empolyee子元素代码是root.getElementsByTagName('employee')
还有getElementsByTagName是返回一个元素列表,该XML文档中有两个empolyee节点,所以children返回的是2个值,然后打印第二个节点的节点名字和节点属性。
C. 获得标签属性值
实例:
dom = xml.dom.minidom.parse(r"employees.xml")
root = dom.documentElement
children= root.getElementsByTagName('employee')
item = children[0]
print(item.getAttribute("id"))
item = children[1]
print(item.getAttribute("id"))
技术解释:一个元素有属性,那么可以使用getAttribute方法,参数是XML节点的属性,在本例中的属性为id。
D. 解析xml,获得每个子节点的值
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml")
root = dom.documentElement
employees = root.getElementsByTagName("employee")
for employee in employees:
print(" ------------------------------------------- ")
print(employee.nodeName)
nameNode = employee.getElementsByTagName("name")[0]
print(nameNode.nodeName + " : " + nameNode.childNodes[0].nodeValue)
sillNode = employee.getElementsByTagName("skill")[0]
print(sillNode.nodeName + " : " + sillNode.childNodes[0].nodeValue)
ageNode = employee.getElementsByTagName("age")[0]
print(ageNode.nodeName + " : " + ageNode.childNodes[0].nodeValue)
print(" ------------------------------------------- ")
运行结果:
-------------------------------------------
employee
name : 郭靖
skill : 降龙十八掌
age : 30
-------------------------------------------
employee
name : 黄蓉
skill : 打狗棒法
age : 20
-------------------------------------------
技术解释:使用parse()或createDocument()返回的为DOM对象,使用DOM的documentElement属性可以获得Root Element,DOM为树形结构,包含许多的nodes,其中element是node的一种,可以包含子elements,textNode也是node的一种,是最终的子节点;每个node都有nodeName,nodeValue,nodeType属性,nodeValue是结点的值,只对textNode有效。
E. 为XML添加节点
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r"C:employees.xml")
root = dom.documentElement
employee = dom.createElement('employee')
employee.setAttribute('id', '003')
root.appendChild(employee)
nameE = dom.createElement('name')
nameT = dom.createTextNode('芮伟 ')
nameE.appendChild(nameT)
employee.appendChild(nameE)
skillE = dom.createElement('skill')
skillT = dom.createTextNode('四照神功')
skillE.appendChild(skillT)
employee.appendChild(skillE)
ageE = dom.createElement('age')
ageT = dom.createTextNode('17')
ageE.appendChild(ageT)
employee.appendChild(ageE)
print(dom.toxml())
技术解释:dom是树结构,包括叶子结点(不包含其它结点的结点,如文本结点)和非叶子结点(包含其它结点的结点,如元素结点)的生成,然后就需要利用结点对象本身的appendChild()或insertBefore()方法将各个结点根据在树中的位置连起来,串成一棵树,其中dom.createElement()生成元素节点,dom.createTextNode生成文本节点,setAttribute设置节点属性。
- Coffee
- Tea
- Milk
B. 文本节点
在节点树中,元素节点构成了树的枝干,而文本节点则构成了树的树叶,
郭靖知道师父虽然摔下,并不碍事,但欧阳锋若乘势追击,后着可凌厉之极,叫道:“看招!”左腿微屈,右掌划了个圆圈,平推出去,正是降龙十八掌中的“亢龙有悔”。
,在html中文本是包含在元素节点内部的,如上面这段文字就是包含在元素内。
C. 属性节点
HTML文档中袁术都有一些属性,这些属性准确的便于开发人员操作。如:
你好,世界!
,这里class=dom就是属性节点。
从上面的描述可以看出来节点树中的节点彼此拥有层级关系,节点之间的关系可以使用类似人类家族关系的形式描述。如在HTML文档中,可以把html标签看作是body标签的父元素;相对的,body标签也就是html标签的子元素;而做为body标签同级的head标签两都之者的关系为兄弟(姐妹)关系。在dom中父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
- 在节点树中,顶端节点被称为根(root)
- 每个节点都有父节点、除了根(它没有父节点)
- 一个节点可拥有任意数量的子
- 同胞是拥有相同父节点的节点
五.HTML DOM操作
在Web自动化测试开发中达到控制页面元素,执行相应操作行为的目的,了解HTMLDOM是很有必要的,我们用JavaScript来用代码操作DOM是因为DOM接口是标准的,另外是因为可以了解更多的代码细节。JavaScript操作DOM一般有以下4种操作;
- 更新: 更新该DOM节点的内容,相当于更新了该DOM节点表示的HTML内容;
- 遍历: 遍历该DOM节点下的字节点,以便进行进一步操作;
- 添加: 在该DOM节点下新增一个子节点,相当于动态增加了一个HTML节点;
- 删除: 将该节点从HTML中删除,相当于删掉了该DOM节点内容以及它包含的所有子节点
JavaScript实现的DOM接口一般有:
1. Document属性
A. document.title //设置文档标题等价于HTML的title标签
B. document.bgColor //设置页面背景色
C. document.fgColor //设置前景色(文本颜色)
D. document.linkColor //未点击过的链接颜色
E. document.alinkColor //激活链接(焦点在此链接上)的颜色
F. document.vlinkColor //已点击过的链接颜色
G. document.URL //设置URL属性从而在同一窗口打开另一网页
H. document.fileCreatedDate //文件建立日期,只读属性
I. document.fileModifiedDate //文件修改日期,只读属性
J. document.charset //设置字符集 简体中文:gb2312
K. document.fileSize //文件大小,只读属性
L. document.cookie //设置和读出cookie2. Document常用对象方法
A. document.write() //动态向页面写入内容
B. document.createElement(Tag) //创建一个html标签对象
C. document.getElementById(ID) //获得指定ID值的对象 /
D. document.getElementsByName(Name) //获得指定Name值的对象
E. document.body.appendChild(oTag)3. 获取HTML元素
A. getElementByID(id):通过对元素的ID访问,这是DOM访问页面元素的方法.实例:
dom操作
我是第一个P
我是第二个P
测试
技术解释:如果id在元素中不是唯一的,那么获得的将是第一个ID,window.onload是在DOM文档树加载完和所有文件加载完之后执行一个函数,也就是自己触发该函数。
B. getElementsByName(name):仅用于input ,radio checkbox等元素,返回名字为name的元素数组实例:
dom操作
我是第一个P
我是第二个P
测试
/>
C. getElementsByTagName(tagname):返回具有tagname的元素列表数组.处理大的DOM结构会用到它,实例:获取页面所有DIV元素
div 1
div 2
4 .操作DOM 元素
A. document.createElement(eName):创建一个节点
DOM操作
第一段
第二段
B. appendChild(node):向当前对象追加节点
实例:
DOM操作
第一段
第二段
C. removeChild(childreference):移除当前节点的子节点,并返回节点
实例:
dom操作
父亲
儿子
姑娘
D. cloneNode(deepBoolean):复制并返回当前的复制节点,由于复制了原节点的id属性,所以在document树中要改ID属性,以确保ID唯一性.
E. insertBefore(newElment,targetElement) 插入新的节点。在当前节点插入一个新节点,如果targetElement为null,那新节点为最后节点.
实例:
insertBefore()函数
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
5. DOM Element常用属性
A. childeNodes 返回所有子节点对象
实例:
返回节点文本
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
B. innerHTML:这是一个标准,但它并不是DOM
实例:
修改元素
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
C. style:这是一个极其重要的属性,可以获取并修改每个单独的样式.
实例:
设置属性
- 复仇者联盟
- 正义联盟
- x战警
- 光照会
D. 节点
firstChild:返回第一个子节点;lastChild :返回最后一个子节点:parentNode :返回父节点的对象;nextSibling :返回下一个兄弟节点的对象;previousSibling 返回前一个兄弟节点的对象; 元素节点可以用数组元素childNodes[0]来获取,和他等同的功能的属性,且更加语义化,可以用firstChild,lastChild等属性。假设我们需要目标元素节点下的所有子元素中的第一个子元素可以这样做:目标元素节点下的子元素节点数组.firstChild 这句代码等价于目标元素节点下的子元素节点数组[0];目标元素节点.childNodes[0] 这句代码等价于 目标元素节点.firstChild;与此类推当我们需要目标元素节点下的所有子元素节点中的最后一个元素我们可以这样做:目标元素节点下的子元素节点数组.lastChild 这句代码等价于 目标元素节点下的子元素节点数组[目标元素节点下的子元素节点数组.length-1]目标元素节点.childNodes[目标元素节点.childNodes.length-1]=目标元素节点.lastChild;从上面的描述中,发现firstChild属性和lastChild属性更加的语义化,而且代码更加的简洁,方便我们记忆;
E. nodeName 返回节点的HTML标记名称,使用英文的大写字母。
作用:如果我们想改变一个文本节点的值,那就是用DOM提供的nodeValue属性,它是用来得到(和设置)一个文本节点的值;
实例:
hello world!
我们获取的p是一个元素节点,
元素本身的nodeValue值是一个null值,而且最重要的是nodeValue属性是用来获取文本节点的值的。所以输出:null.。这个是一个技术细节,也是一个小知识点.需要注意。正确的获取
标签里面文本的做法是获取
标签下文本节点的节点值。
代码如下: 这里
标签代表一个元素节点
hello world!
六.初识XMLDOM
XML ( eXtensible Markup Language )语言是一种可扩展的标记语言。其中的可扩展是相对HTML来说的。因为XML标签没有被预定义,需要用户自行定义标签。通过此种标记,计算机之间可以处理包含各种信息的文章等。XML设计用来传送及携带数据信息,不用来表现或展示数据,所以XML用途的焦点是它说明数据是什么,以及携带数据信息。而HTML语言则用来表现数据。下面自定义一个xml文件来存储书信息:
<书架>
<书出版社="浙江出版社">
<名字>诛仙
<作者>萧鼎
<价格>32.00
<出版日期>2007年
<书出版社="文艺出版社">
<名字>笑傲江湖
<作者>金庸
<价格>50.00
<书出版社="人邮出版社">
<名字>selenium自动化测试
<作者>威链优创
<价格>50.00
XML 文档的第一行是一个 XML 声明,这是文件的可选部分,它将文件识别为XML文件,该XML文件表示书架上有三本书,并把每本书标识出出版社,名称,作者,价格。在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可以分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其他标签描述其他数据,以此来实现数据关系的描述。在上个实例中书名,作者,价格都是自定义标签,如果你喜欢你可以把所有的标签名字都改成英文也可以。
通过前面的知识我们了解DOM是一种树结构,XML文档结构就是类似倒长的树型结构
XML语法
一个XML文件分为如下6部分内容:文档声明,元素 ,属性,注释 ,CDATA区、特殊字符,处理指令(processing instruction)。
1. XML文档声明
XML声明语句一般是这样,放在XML文档的第一行 ,version 指文档符合XML1.0规范 ;encoding指文档字符编码,比如”GB2312”或者”UTF-8” ;还有参数standalone指文档定义是否独立使用 ,standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
2. XML元素
A. XML文档必须有且只有一个根元素
- 根元素是一个完全包括文档中其他所有元素的元素
- 根元素的起始标记要放在所有其他元素的起始标记之前
- 跟元素的结束标记要放在所有其他元素的结束标记之后
B. XML元素指的是XML文件中出现的标签,标签都是成对出现分为开始和结束标签
C. (命名规范: XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守以下规范:
- 区分大小写,例如元素name和元素Name是两个不同的元素
- 不能以数字或下划线”_”开头
- 元素内不能包含空格
- 名称中间不能包含冒号(:)
- 可以使用中文
3. XML属性
Tom
- A. 属性值用双引号(”)或单引号(’)分隔,如果属性值中有单引号,则用双引号分隔;如果有双引号,则用单引号分隔。属性值中有单引号或者双引号用转义字符处理,也可以用HTML 字符实体< >: &等。
- B. 一个元素可以有多个属性,它的基本格式为:<元素名 属性名1="属性值1" 属性名2="属性值2">
- C. 特定的属性名称在同一个元素标记中只能出现一次
- D. 属性值不能包括<,>,&,如果一定要包含,也要使用HTML实体字符
4. XML-注释
XML的注释类语法:
- A. 注释内容不要出现--
- B. 不要把注释放在标记中间;
- C. 注释不能嵌套
- D. 可以在除标记以外的任何地方放注释
5. XMLCDATA节
在XML中CDATA被声明不应被解析成标签的文本,其中可以使用特殊字符,包括大于号,小于号和双引号。CDATA段通过来设置,所有在中间的内容都被当做原始字符,而不会进行字符转义。如实际应用中通过XML文件发送图片,就需要用CDATA节来处理。文件本质上是字符串,在底层都是用二进制传输。根据原理通过XML文件将一幅图片的二进制字符串传递过去,然后可以解析成一幅图片。由于字符串就会包含大量的<,>,&或者“等一些特殊的不合法的字符,引擎解析会报错。为了不让图内容用引擎解析执行,而是做为原始内容处理,要用到CDATA节。
语法如下:
......
]]>
6. XML处理指令
处理指令,简称PI(processing instruction)。处理指令用来指示解析引擎如何解析XML文件,看下面一个例子:比如可以使用CSS样式表来修饰XML文件,编写test.css如下:
name{
font-size:60px;
font-weight:bold;
color:red;
}
sex{
font-size:60px;
font-weight:bold;
color:red;
}
age{
font-size:60px;
font-weight:bold;
color:red;
}我们在xml文件中使用处理指令引入这个CSS文件,如下:
郭靖
男
16
黄蓉
女
21
再用浏览器打开这个xml文件,会发现浏览器解析出一个带样式的视图,而不再是单纯的目录树了。
七.Python和DOM
在python标准库中支持DOM操作的模块是xml.dom,xml文档数据通过xml.dom模块的方法解析为dom树结构后,就可以调用dom规范中定义的方法和属性来访问XML数据。需要注意,这些方法都是DOM规范中规定的,不是xml.dom模块规定的,xml.dom只是实现了这些操作xml数据的接口。
1. XMLDOM接口
A. Document接口:
Document代表整个XML文档,实际上这是XML文档树的根,同时提供了对数据初始访问的入口。
- 1) Document.documentElement:Document对象的根元素。
- 2) Document.createElement(tagName):建立并返回一个新元素节点,但要加入的节点树中,需使用insertBefore() 或append Child()方法。
- 3) document.createTextNode(data):以参数传入的数据建立并返回一个文本节点,但未加入到节点树中。
- 4) document.createComment(data):以参数传入的数据建立并返回一个注释节点,但未加入到节点树中。
- 5) document.createProcessingInstruction(target, data)
- 6) document. createAttribute(name):建立并返回一个属性节点,但要关联到一个元素节点,需要使用方法setAttributeNode()。
- 7) document.createAttributeNS(namespaceURI, qualifiedName)
- 8) Document.getElementsByTagName(tagName):在所有后代节点中查找指定tagname的元素节点,返回子元素到列表,注意是列表。
- 9) Document.getElementsByTagNameNS(namespaceURI, localName)
B. Node接口
XML文档的所有组件都可以看作是Node对象。
- 1) Node.nodeType:用一个整数表示Node对象的类型。该属性为只读。
- 2) Node.parentNode: 当前对象的双亲对象,对于Document对象该属性为None,对于Attr对象总是None。 该属性只读。
- 3) Node.attributes: 包含的属性对象,只有节点对象的类型为元素是才有实际的值。该属性只读。
- 4) Node.previousSibling: 与当前节点同属一个双亲节点的前一个紧邻的节点。对于第一个节点,该属性为
- 5) None:该属性只读。
- 6) Node.nextSibling:与当前节点同属一个双亲节点的后一个紧邻的节点。对于最后一个节点,该属性为None。 该属性只读。
- 7) Node.childNodes:一个包含当前节点的子节点的列表。该属性只读。
- 8) Node.firstChild: 第一个子节点,可以是None。 该属性只读。
- 9) Node.lastChild:最后一个子节点,可以是None。 该属性只读。
- 10) Node.localName:本地标签名称,完整名称中如有冒号,则为冒号之后的部分,否则为完整名称。该属性为字符串。
- 11) Node.prefix:名称前缀,完整名称中如有冒号,则为冒号之前的部分,否则为空。该属性为字符串,或None。
- 12) Node.namespaceURI:与元素关联的命名空间,为一字符串或None。该属性只读。
- 13) Node.nodeName:对于元素节点,等同于tagName;对于属性节点,等同于name。该节点只读。
- 14) Node.nodeValue:与nodeName类似,对于不同类型的节点,有不同的含义。该属性只读。
- 15) Node.hasAttributes():如果节点包含有属性,返回True。
- 16) Node.hasChildNodes():如果节点包含子节点,返回True。
- 17) Node.isSameNode(other):如果指定的节点对象引用的就是本节点,该方法返回True。
- 18) Node.append Child(newChild):在当前节点的最后一个子节点后增加一个新的子节点。该方法将返回新子节点。
- 19) Node.insertBefore(newChild, refChild): 在指定的子节点前插入一个新的节点,如果参照的节点为None,新节点将插入到子节点列表的末尾。该方法返回新子节点。
- 20) Node.removeChild(oldChild):删除一个子节点,该方法执行成功后返回被删除的节点,应适用unlink()方法释放被删除节点占用的内存。
- 21) Node.replaceChild(newChild, oldChild):用一个新的节点替换一个已经存在的子节点。
- 22) Node.normalize():将邻接的文本节点(textNode)连接为单个文本实例,以简化对文本的处理。
- 23) Node.cloneNode(deep):克隆当前节点,设置deep表示克隆所有的子节点。该方法返回克隆节点。
C. Element接口
- 1) Element是Node的子类,nodeType值为1。
- 2) Element.tagName:元素类型名称。
- 3) Element.getElementsByTagName (tagName):与Document类相同。
- 4) Element.getElementsByTagNameNS(namespaceURI, localName)
- 5) Element.hasAttribute(name)
- 6) Element.hasAttributeNS(namespaceURI, localName)
- 7) Element.getAttribute(name):
- 8) Element.getAttributeNode(attrname):返回属性节点。
- 9) Element.getAttributeNS(namespaceURI, localName)
- 10) Element.getAttributeNodeNS(namespaceURI, localName)
- 11) Element.removeAttribute(name)
- 12) Element.removeAttributeNode(oldAttr)
- 13) Element.removeAttributeNS(namespaceURI, localName)
- 14) Element.setAttribute(name, value)
- 15) Element.setAttributeNode(newAttr)
- 16) Element.setAttributeNodeNS(newAttr)
- 17) Element.setAttributeNS(namespaceURI, qname, value)
D. Text接口
- 1) Text接口表示XML文档中的文本,它不存在子节点。如果支持XML扩展,CDATA标记中的文本将被保存在CDATASection对象中。Text节点到nodeType值为3。
- 2) Text.data:节点的文本字符串。
2. XML实例
创建XML文件如下:
郭靖
30
降龙十八掌
黄蓉
20
打狗棒法
A. 获得标签属性
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml") #打开xml文档
root = dom.documentElement #得到xml文档对象
print("nodeName:", root.nodeName) #每一个结点都有它的nodeName,nodeValue,nodeType属性
print("nodeValue:", root.nodeValue) #nodeValue是结点的值,只对文本结点有效
print("nodeType:", root.nodeType)
print("ELEMENT_NODE:", root.ELEMENT_NODE)技术解释:xml.dom.minidom.parse()得到一个dom对象,它的第一个元素应该是employees,root = dom.documentElement得到文档根元素,也就是得到了employees, 每一个结点都有它的nodeName,nodeValue,nodeType属性。nodeName为结点名字。nodeValue是结点的值,只对文本结点有效。nodeType是结点的类型,现在有以下几种:
- 'ATTRIBUTE_NODE'
- 'CDATA_SECTION_NODE'
- 'COMMENT_NODE'
- 'DOCUMENT_FRAGMENT_NODE'
- 'DOCUMENT_NODE'
- 'DOCUMENT_TYPE_NODE'
- 'ELEMENT_NODE'
- 'ENTITY_NODE'
- 'ENTITY_REFERENCE_NODE'
- 'NOTATION_NODE'
- 'PROCESSING_INSTRUCTION_NODE'
- 'TEXT_NODE'
B. 获得子标签
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml")
root = dom.documentElement
children = root.getElementsByTagName('employee')
print(len(children))
children_brother = children[1]
print(children_brother.nodeName)
print(children_brother.nodeValue)技术解释:访问子元素、子结点的方法很多,对于知道元素名字的子元素,可以使用getElementsByTagName方法,如读取empolyee子元素代码是root.getElementsByTagName('employee')
还有getElementsByTagName是返回一个元素列表,该XML文档中有两个empolyee节点,所以children返回的是2个值,然后打印第二个节点的节点名字和节点属性。
C. 获得标签属性值
实例:
dom = xml.dom.minidom.parse(r"employees.xml")
root = dom.documentElement
children= root.getElementsByTagName('employee')
item = children[0]
print(item.getAttribute("id"))
item = children[1]
print(item.getAttribute("id"))技术解释:一个元素有属性,那么可以使用getAttribute方法,参数是XML节点的属性,在本例中
D. 解析xml,获得每个子节点的值
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r" employees.xml")
root = dom.documentElement
employees = root.getElementsByTagName("employee")
for employee in employees:
print(" ------------------------------------------- ")
print(employee.nodeName)
nameNode = employee.getElementsByTagName("name")[0]
print(nameNode.nodeName + " : " + nameNode.childNodes[0].nodeValue)
sillNode = employee.getElementsByTagName("skill")[0]
print(sillNode.nodeName + " : " + sillNode.childNodes[0].nodeValue)
ageNode = employee.getElementsByTagName("age")[0]
print(ageNode.nodeName + " : " + ageNode.childNodes[0].nodeValue)
print(" ------------------------------------------- ")运行结果:
-------------------------------------------
employee
name : 郭靖
skill : 降龙十八掌
age : 30
-------------------------------------------
employee
name : 黄蓉
skill : 打狗棒法
age : 20
-------------------------------------------
技术解释:使用parse()或createDocument()返回的为DOM对象,使用DOM的documentElement属性可以获得Root Element,DOM为树形结构,包含许多的nodes,其中element是node的一种,可以包含子elements,textNode也是node的一种,是最终的子节点;每个node都有nodeName,nodeValue,nodeType属性,nodeValue是结点的值,只对textNode有效。
E. 为XML添加节点
实例:
import xml.dom.minidom
dom = xml.dom.minidom.parse(r"C:employees.xml")
root = dom.documentElement
employee = dom.createElement('employee')
employee.setAttribute('id', '003')
root.appendChild(employee)
nameE = dom.createElement('name')
nameT = dom.createTextNode('芮伟 ')
nameE.appendChild(nameT)
employee.appendChild(nameE)
skillE = dom.createElement('skill')
skillT = dom.createTextNode('四照神功')
skillE.appendChild(skillT)
employee.appendChild(skillE)
ageE = dom.createElement('age')
ageT = dom.createTextNode('17')
ageE.appendChild(ageT)
employee.appendChild(ageE)
print(dom.toxml())技术解释:dom是树结构,包括叶子结点(不包含其它结点的结点,如文本结点)和非叶子结点(包含其它结点的结点,如元素结点)的生成,然后就需要利用结点对象本身的appendChild()或insertBefore()方法将各个结点根据在树中的位置连起来,串成一棵树,其中dom.createElement()生成元素节点,dom.createTextNode生成文本节点,setAttribute设置节点属性。