Kubernetes容器网络(二):Calico网络原理
1、前置网络知识
1)、BGP
自治系统AS:在单一的技术管理下的一组路由器,而这些路由器使用一种AS内部的路由选择协议和共同的度量以确定分组在该AS内的路由,同时还使用一种AS之间的路由协议以确定在AS之间的路由
路由选择协议分为:
- 内部网关协议IGP:一个AS内使用的,如RIP、OSPF
- 外部网关协议EGP:AS之间使用的,如BGP

边界网关协议(BGP)是不同自治系统的路由器之间交换路由信息的协议,是一种外部网关协议
BGP的工作原理如下:每个自治系统的管理员要选择至少一个路由器(可以有多个)作为该自治系统的BGP发言人。一个BGP发言人与其他自治系统中的BGP发言人要交换路由信息,就要先建立TCP连接(可见BGP报文是通过TCP传送的,也就是说BGP报文是TCP报文的数据部分),然后在此连接上交换BGP报文以建立BGP会话,再利用BGP会话交换路由信息。当所有BGP发言人都相互交换网络可达性的信息后,各BGP发言人就可找到到达各个自治系统的较好路由
每个BGP发言人除必须运行BGP外,还必须运行该AS所用的内部网关协议,如RIP或OSPF。BGP所交换的网络可达性信息就是要到达某个网关所要经过的一系列AS。下图是一个BGP发言人交换路径向量的例子

BGP的特点如下:
- BGP交换路由信息的结点数量级是自治系统的数量级,要比这些自治系统中的网络数少很多
- 每个自治系统中BGP发言人(或边界路由器)的数目是很少的。这样就使得自治系统之间的路由选择不致过分复杂
- BGP支持CIDR,因此BGP的路由表也就应当包括目的网络前缀、下一跳路由器,以及到达该目的网络所要经过的各个自治系统序列
- 在BGP刚运行时,BGP的邻站交换整个BGP路由表,但以后只需在发生变化时更新有变化的部分。这样做对节省网络带宽和减少路由器的处理开销都有好处
举一个非常简单的例子帮助理解:
上图中有两个自治系统:AS1和AS2。如果这两个自治系统里的主机,要通过IP地址直接进行通信,我们就必须使用路由器把这两个自治系统连接起来
比如,AS1里面的主机10.10.0.2要访问AS2里的主机172.17.0.2的话。它发出的IP包,就会先到达自治系统AS1上的路由器Router1
而在此时,Router1的路由表里,有这样一条规则,即:目的地址是172.17.0.2的包,应该经过Router1的C接口,发往网关Router2(即:自治系统AS2上的路由器)
所以IP包就会到达Router2上,然后经过Router2的路由表,从B接口出来到达目的主机172.17.0.2
但是反过来,如果主机172.17.0.2要访问10.10.0.2,那么这个IP包,在到达Router2之后,就不知道该去哪儿了。因为在Router2的路由表里,并没有关于AS1自治系统的任何路由规则
所以这时候,网络管理员就应该给Router2也添加一条路由规则,比如:目标地址是10.10.0.2的IP包,应该经过Router2的C接口,发往网关Router1
像上面这样负责把自治系统连接在一起的路由器,就称为边界网关。它跟普通路由器的不同之处在于,它的路由表里拥有其他自治系统里的主机路由信息
假设我们现在的网络拓扑结构非常复杂,每个自治系统都有成千上万个主机、无数个路由器,甚至是由多个公司、多个网络提供商、多个自治系统组成的复合自治系统呢?这时候,如果还依靠人工来对边界网关的路由表进行配置和维护,那是绝对不现实的
在使用了BGP之后,可以认为在每个边界网关上都会运行着一个小程序,它们会将各自的路由表信息,通过TCP传输给其他的边界网关。而其他边界网关上的这个小程序,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里
所谓BGP就是在大规模网络中实现节点路由信息共享的一种协议
2)、ipip
ipip即IPv4 in IPv4,在IPv4报文的基础上再封装一个IPv4报文,是Linux原生支持的一种三层隧道
ipip隧道案例:
要使用ipip隧道,首先需要内核模块ipip.ko的支持
通过lsmod | grep ipip查看内核是否加载,若没有则用modprobe ipip加载,正常加载应该显示:
[root@aliyun ~]# modprobe ipip
[root@aliyun ~]# lsmod | grep ipip
ipip 16384 0
tunnel4 16384 1 ipip
ip_tunnel 32768 1 ipip
ipip隧道案例网络拓扑如下图:

创建两个network namespace:
[root@aliyun ~]# ip netns add ns1
[root@aliyun ~]# ip netns add ns2
创建两对veth pair,令其一端挂在某个namespace下:
[root@aliyun ~]# ip link add v1 type veth peer name v1_p
[root@aliyun ~]# ip link add v2 type veth peer name v2_p
[root@aliyun ~]# ip link set v1 netns ns1
[root@aliyun ~]# ip link set v2 netns ns2
分别给两对veth pair端点配置上IP并启用:
[root@aliyun ~]# ip addr add 10.10.10.1/24 dev v1_p
[root@aliyun ~]# ip link set v1_p up
[root@aliyun ~]# ip addr add 10.10.20.1/24 dev v2_p
[root@aliyun ~]# ip link set v2_p up
[root@aliyun ~]# ip netns exec ns1 ip addr add 10.10.10.2/24 dev v1
[root@aliyun ~]# ip netns exec ns1 ip link set v1 up
[root@aliyun ~]# ip netns exec ns2 ip addr add 10.10.20.2/24 dev v2
[root@aliyun ~]# ip netns exec ns2 ip link set v2 up
验证一下v1 ping v2,结果不通:
[root@aliyun ~]# ip netns exec ns1 ping 10.10.20.2
检查ip_forward的值:
[root@aliyun ~]# cat /proc/sys/net/ipv4/ip_forward
0
临时打开ip_forward:
[root@aliyun ~]# echo 1 > /proc/sys/net/ipv4/ip_forward
查看ns1的路由表:
[root@aliyun ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
只有一条直连路由,没有通过10.10.20.0/24网段的路由,因此手动配置一条路由:
[root@aliyun ~]# ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1
再查看路由表:
[root@aliyun ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1
同理,也给ns2配置上通往10.10.10.0/24网段的路由:
[root@aliyun ~]# ip netns exec ns2 route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.20.1
再ping一次,发现能ping通
[root@aliyun ~]# ip netns exec ns1 ping 10.10.20.2
PING 10.10.20.2 (10.10.20.2) 56(84) bytes of data.
64 bytes from 10.10.20.2: icmp_seq=1 ttl=63 time=0.042 ms
64 bytes from 10.10.20.2: icmp_seq=2 ttl=63 time=0.046 ms
64 bytes from 10.10.20.2: icmp_seq=3 ttl=63 time=0.035 ms
保证v1和v2能够通信后,再创建tunl设备,并设置为ipip隧道
在ns1上创建tunl1和ipip tunnel:
[root@aliyun ~]# ip netns exec ns1 ip tunnel add tunl1 mode ipip remote 10.10.20.2 local 10.10.10.2
[root@aliyun ~]# ip netns exec ns1 ip link set tunl1 up
[root@aliyun ~]# ip netns exec ns1 ip addr add 10.10.100.10 peer 10.10.200.10 dev tunl1
上面的命令是在ns1上创建tunl1设备,并设置隧道模式为ipip,然后设置隧道端点,用remote和local表示隧道外层IP。对应的还有隧道内层IP,用ip add xx peer xx配置
从tunl1发到tunl2的原始IP报文和经过隧道封装后的IP报文如下图:

同理,也在ns2上创建tunl2和ipip tunnel:
[root@aliyun ~]# ip netns exec ns2 ip tunnel add tunl2 mode ipip remote 10.10.10.2 local 10.10.20.2
[root@aliyun ~]# ip netns exec ns2 ip link set tunl2 up
[root@aliyun ~]# ip netns exec ns2 ip link set tunl2 up
完成上述配置,两个tunl设备端点就可以互通了
[root@aliyun ~]# ip netns exec ns1 ping 10.10.200.10
PING 10.10.200.10 (10.10.200.10) 56(84) bytes of data.
64 bytes from 10.10.200.10: icmp_seq=1 ttl=64 time=0.062 ms
64 bytes from 10.10.200.10: icmp_seq=2 ttl=64 time=0.051 ms
64 bytes from 10.10.200.10: icmp_seq=3 ttl=64 time=0.050 ms
来分析下上述案例的过程:
-
ping命令构建一个ICMP请求,ICMP报文封装在IP报文中,源IP地址和目的IP地址分别是10.10.100.10和10.10.200.10
-
由于tunl1和tunl2不在同一网段,所以要查看路由表。通过ip tunnel命令建立ipip隧道后,会自动生成一条路由规则,如下所示:
[root@aliyun ~]# ip netns exec ns1 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1 10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1 10.10.200.10 0.0.0.0 255.255.255.255 UH 0 0 0 tunl1以上路由表信息表明:去往目的地址10.10.200.10的报文直接从tunl1出去了
-
由于配置了隧道端点,数据包出了tunl1,直接到达v1。根据ipip隧道的配置,会封装上一层新的IP头,源IP地址和目的IP地址分别是10.10.10.2和10.10.20.2
-
由于v1和v2同样不在同一网段,查看路由表,发现去往10.10.20.0网段的报文从v1网卡出,去往10.10.10.1网关,即veth pair在主机上的另一端v1_p(手动配置的路由)
-
Linux打开了ip_forward,它相当于一台路由器,10.10.10.0和10.10.20.0是两条直连路由,所以直接查路由表转发,从v1_p转到v2_p上
-
根据veth pair设备的特性,数据包到达v2_p上,会直接从ns2的v2出来。内核解封装数据包,发现内层IP报文的目的IP地址是10.10.200.10,这正是自己配置的ipip隧道tunl2的地址,于是将报文交给tunl2设备。至此,tunl1的ping请求包成功到达tunl2
-
ns2上构造ICMP响应报文,并根据以上相同步骤封装和解封装数据包,直至到达tunl1,整个ping过程完成
2、Calico网络原理
1)、Calico网络方案
Calico和Flannel的host-gw模式都是纯三层网络方案,不同的是Calico使用BGP来自动地在整个集群中分发路由信息,Calico由三个部分组成:
- Calico的CNI插件:这是Calico与Kubernetes对接的部分
- Felix:它是一个DaemonSet,负责在宿主机上插入路由规则(即:写入Linux内核的FIB转发信息库),以及维护Calico所需的网络设备等工作
- BIRD:它就是BGP的客户端,专门负责在集群中分发路由规则信息
Calico工作原理如下图:

上图中,有两台宿主机:
- 宿主机Node1的IP地址是172.19.83.134,上面有一个容器A(IP地址是10.244.36.65)和容器B(IP地址是10.244.36.66),容器网段是10.244.36.64/26
- 宿主机Node2的IP地址是172.19.83.135,上面有一个容器C(IP地址是10.244.169.129)和容器D(IP地址是10.244.169.130),容器网段是10.244.169.128/26
我们来逐步分析模式下容器A访问容器C的整个过程:
1)除了对路由信息的维护方式之外,Calico与Flannel的host-gw模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备
Calico的CNI插件会为每个容器设置一个Veth Pair设备,然后把其中的一端放置在宿主机上(它的名字以cali前缀开头)
有了Veth Pair设备之后,容器A发出的IP包(目的地址IP地址是10.244.169.129)就会经过Veth Pair设备出现在宿主机上。然后,宿主机网络栈就会根据路由规则的下一跳IP地址,把它们转发给正确的网关。接下来的流程就跟Flannel host-gw模式完全一致了
2)这里最核心的下一跳路由规则,就是由Calico的Felix进程负责维护的。这些路由规则信息则是通过BGP Client也就是BIRD组件,使用BGP协议传输而来的
Node2中的BIRD组件通过BGP协议传输的消息,可以简单地理解为如下格式:
[BGP消息]
我是宿主机172.19.83.135
10.244.169.128/26网段的容器都在我这里
这些容器的下一跳地址是我
Node1的BIRD收到传输来的BGP消息,Felix会在宿主机上创建这样一条规则
[root@k8s-node1 ~]# ip route
...
10.244.169.128/26 via 172.19.83.135 dev eth0 proto bird
这条路由规则的含义是:目的IP地址属于10.244.169.128/26网段的IP包。应该经过本机的eth0设备发出去;并且,它的下一跳(next-hop)是172.19.83.135
3)一旦配置了下一跳地址,那么接下来,当IP包从网络层进入链路层封装成帧的时候,eth0设备就会使用下一跳地址对应的MAC地址,作为该数据帧的目的MAC地址。显然,这个MAC地址正是Node2的MAC地址
这样,这个数据帧就会从Node1通过宿主机的二层网络顺利到达Node2上
4)由于Calico没有使用CNI的网桥模式,Calico的CNI插件还需要在宿主机上为每个容器的Veth Pair设备配置一条路由规则,用于接收传入的IP包。宿主机Node2上容器C对应的路由规则,如下所示:
[root@k8s-node2 ~]# ip route
...
10.244.169.129 dev calibd1829b7599 scope link
即:发往10.244.169.129的IP包,应该进入calibd1829b7599设备
而Node2的内核网络栈从二层数据帧里拿到IP包后,会看到这个IP包的目的IP地址是10.244.169.129,匹配到上述路由表规则进入calibd1829b7599设备,从而进入容器C
Calico项目实际上将集群中的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过BGP协议交换路由规则。这些节点,我们称为BGP Peer
Calico维护的网络在默认配置下,是一个被称为Node-to-Node Mesh的模式。这时候,每台宿主机上的BGP Client都需要跟其他所有节点的BGP Client进行通信以便交换路由信息。但是,随着节点数量N的增加,这些连接的数量就会以 N 2 N^2 N2的规模快速增长,从而给集群本身的网络带来巨大的压力
所以,Node-to-Node Mesh模式一般推荐用在少于100个节点的集群里。而在更大规模的集群中,需要用到的是一个叫做Route Reflector的模式
在这种模式下,Calico会指定一个或几个专门的节点,来负责跟所有节点建立BGP连接从而学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则信息了
这些专门的节点就是所谓的Route Reflector节点,它们实际上扮演了中间代理的角色,从而把BGP连接的规模控制在N的数量级上
2)、IPIP模式
Calico和Flannel的host-gw模式最主要的限制就是要求集群宿主机之间是二层连通的
举个例子,假设有两台处于不同子网的宿主机Node1和Node2,对应的IP地址分别是192.168.1.2和192.168.2.2。需要注意的是,这两台机器通过路由器实现了三层转发,所以这两个IP地址之间是可以相互通信的
现在的需求还是容器A要访问容器C
按照前面的讲述,Calico会尝试在Node1上添加如下所示的一条路由规则:
[root@k8s-node1 ~]# ip route
...
10.244.169.128/26 via 192.168.2.2 dev eth0 proto bird
但是,这时候问题就来了。上面这条规则里的下一跳地址是192.168.2.2,可是它对应的Node2跟Node1却根本不在一个子网里,没办法通过二层网络把IP包发送到下一跳地址
在这种情况下,就需要使用Calico的IPIP模式,Calico的IPIP模式工作原理如下图:
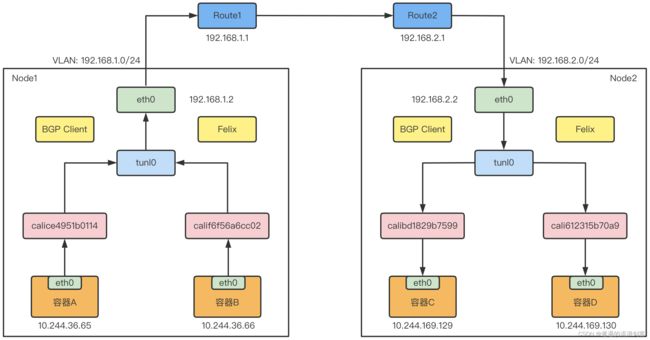
在Calico的IPIP模式下,Felix进程在Node1上添加的路由规则,会稍微不同,如下所示:
[root@k8s-node1 ~]# ip route
...
10.244.169.128/26 via 192.168.2.2 dev tunl0 proto bird onlink
可以看到,尽管这条规则的下一跳地址仍然是Node2的IP地址,但是要负责将IP包发出去的设备,变成了tunl0
Calico使用的这个tunl0设备,是一个IP隧道(IP tunnel)设备
在上面的例子中,IP包进入IP隧道设备之后,就会被Linux内核的IPIP驱动接管。IPIP驱动会将这个IP包直接封装在一个宿主机网络的IP包中,如下所示:

经过封装后的新的IP包的目的地址(Outer IP Header部分),正是原IP包的下一跳地址,即Node2的IP地址:192.168.2.2。而IP包本身,则会被直接封装成新IP包的Payload
这样,原先从容器到Node2的IP包,就被伪装成了一个从Node1到Node2的IP包
由于宿主机之间已经使用路由器配置了三层转发,也就是设置了宿主机之间的下一跳。所以这个IP包在离开Node1之后,就可以经过路由器,最终到达Node2
这时,Node2的网络内核栈会使用IPIP驱动进行解包,从而拿到原始的IP包。然后,原始IP包就会经过路由规则和Veth Pair设备到达目的容器内部
当Calico使用IPIP模式的时候,集群的网络性能会因为额外的封包和解包工作而下降。在实际测试中,Calico IPIP模式与Flannel VXLAN模式的性能大致相当
参考:
《Kubernetes网络权威指南:基础、原理与实践》
解读Kubernetes三层网络方案