顺序表和链表超详细大总结
本文章是对顺序表和链表的详细总结,包括各结构优缺点,顺序表的接口实现,单向不带头不循环链表接口实现,双向带头循环链表的接口实现。
另外还有两篇单链表的题目详解,可以加深理解:
LeetCode刷题——单链表(详细图解)
剑指Offer——环形链表问题(面试延伸证明)
记得三连哦
顺序表和链表
- 顺序表
-
- 一、顺序表的基本介绍
-
- 1.1线性表和顺序表
- 1.2物理结构和逻辑结构
- 1.3静态顺序表
- 1.4动态顺序表
- 二、顺序表的接口实现
-
- 2.1顺序表的初始化(传址和断言)
- 2.2顺序表的尾插
- 2.3顺序表的扩容
- 2.4顺序表的头插
- 2.5顺序表的尾删
- 2.6顺序表的头删
- 2.7顺序表的查找
- 2.8顺序表的指定位置插入
-
- 2.8.1替代头插
- 2.8.2代替尾插
- 2.9顺序表的指定位置删除
-
- 2.9.1替代头删
- 2.9.2代替尾删
- 2.10顺序表的销毁
- 2.11顺序表的打印
- 三、顺序表的缺点及思考
- 链表
-
- 一、链表的基本介绍及优缺点
- 二、八大链表结构
-
- ①单向带头循环链表
- ②单向带头非循环链表
- ③单向不带头循环链表
- ④单向不带头非循环链表
- ⑤双向带头循环链表
- ⑥双向带头非循环链表
- ⑦双向不带头循环链表链表
- ⑧双向不带头非循环链表
- 单链表
-
- 一、链表的基本介绍
- 二、单链表的接口实现
-
- 2.1单链表结构的定义
- 2.2单链表结点创建
- 2.3单链表的插入
-
- 2.3.1头插
- 2.3.2尾插
- 2.3.3指定位置插入
-
- 2.3.3.1在pos前插入
- 2.3.3.2在pos后插入
- 2.4单链表的删除
-
- 2.4.1头删
- 2.4.2尾删
- 2.4.3指定位置删除
- 2.5单链表的查找
- 2.6单链表的打印
- 2.7单链表的销毁
- 双向链表
-
- 一、双向链表的基本介绍
- 二、双向链表的优缺点
- 三、双向链表的接口实现
-
- 3.1双向链表的结构定义
- 3.2双向链表结点的创建
- 3.3双向链表的初始化
- 3.4双向链表的插入
-
- 3.4.1尾插
- 3.4.2头插
- 3.4.3任意位置插入
- 3.5双向链表的删除
-
- 3.5.1尾删
- 3.5.2头删
- 3.5.3任意位置删除
- 3.6双向链表的打印
- 3.7双向链表的判空
- 3.8双向链表的销毁
顺序表
一、顺序表的基本介绍
1.1线性表和顺序表
1️⃣线性表是N个具有相同特性的数据元素的有限序列。线性表不等同于顺序表,常见的线性表有:顺序表,链表,字符串,队列,栈等。都是属于线性结构。
2️⃣顺序表本质上是数组,并且存储数据是从左向右连续的。
所以顺序表是线性表的一部分。
1.2物理结构和逻辑结构
逻辑结构可以理解为我们想象的结构
而物理结构则是真实的结构。
用顺序表和链表来举例子:
逻辑结构:
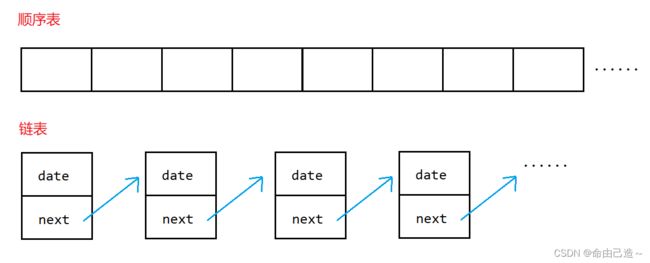
单链表的物理结构和逻辑结构是相同的,但是链表的物理结构可能是杂乱的
例如:
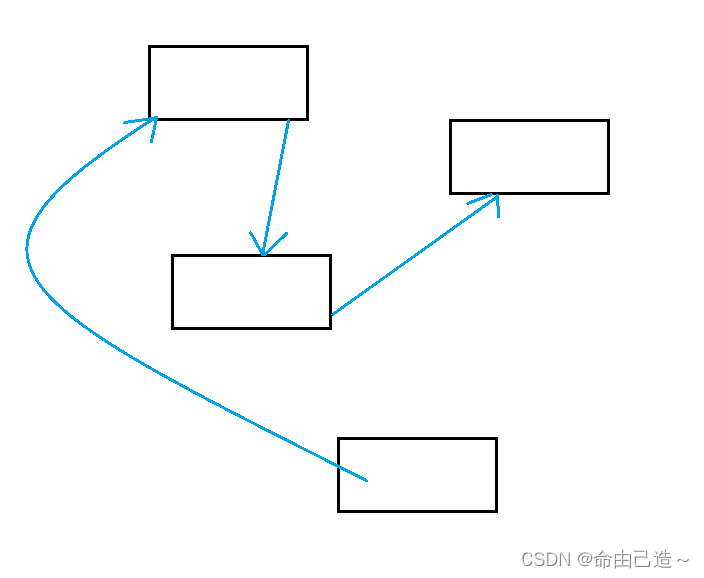
1.3静态顺序表
#define N 100
typedef int SeqDateType;//方便修改类型
typedef struct SeqList
{
SeqDateType a[N];
int size; //有效数据的个数
}SeqList;
我们可以看到他的容量是固定的,无法动态增长
所以我们实际中用的是动态顺序表。
1.4动态顺序表
typedef int SeqDateType;//方便修改类型
typedef struct SeqList
{
SeqDateType* a;
int size; //有效数据的数量
int capacity;//容量
}SeqList, SEQ;
二、顺序表的接口实现
首先创造个结构体变量:
SeqList s;
2.1顺序表的初始化(传址和断言)
void SeqListInit(SeqList* pq)
{
assert(pq);//防止空指针
pq->a = NULL;
pq->capacity = 0;
pq->size = 0;
}
这里一定要注意传的是地址
如果传的是s,那么初始化的是拷贝的结构体变量。并不会改变s本身。
那么接下来所有接口都要用传址
断言的好处:防止传进来的指针是空指针,直接结束程序,防止崩溃。
下面是不加断言和加上断言的对比:
void SeqListInit(SeqList* pq)
{
//assert(pq);//防止空指针
pq->a = NULL;
pq->capacity = 0;
pq->size = 0;
}
int main()
{
SeqList s;
SeqListInit(NULL);
return 0;
}
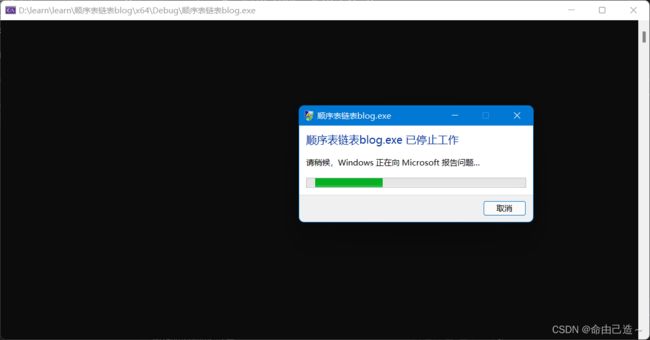
我们可以看到程序已经崩溃了,而加上断言后:
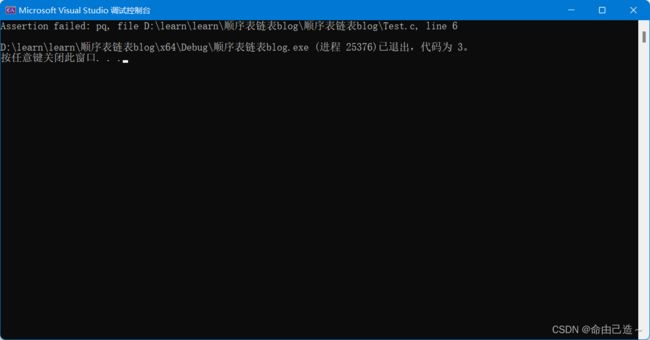
会直接结果程序并且把错误的地方返回给我们。
2.2顺序表的尾插
用张图片感受下插入的方式:
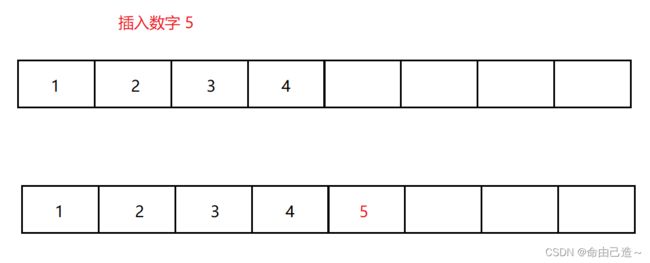
从图片我们很容易能发现问题:如果顺序表最大容量和其有效元素个数相等的时候,我们需要扩容操作
在实际中为了不造成空间浪费,我们一般一次扩容成原来2倍
而两倍又出现了问题:如果顺序表一个元素都没有,容量也为0呢?
2.3顺序表的扩容
当顺序表的容量为0就申请空间,如果不为0就扩容至两倍
void SeqCheckCapacity(SeqList* pq)
{
assert(pq);
//满了就扩容
if (pq->capacity == pq->size)
{
int newcapacity = pq->capacity == 0 ? 4 : 2 * pq->capacity;
SeqDateType** NewA = realloc(pq->a, sizeof(SeqList) * newcapacity);
//防止realloc后改变了pq原来指向的地址
if (NewA == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
pq->a = NewA;
pq->capacity = newcapacity;
}
}
}
可以发现我们没有直接在pq->a上扩容,而是先创建了NewA来指向开辟的空间
这就涉及到realloc的性质了:
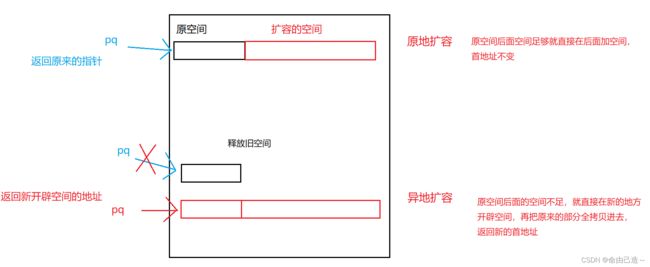
有了扩容判断就可以解决上面的问题,接下来是尾插:
void SeqListPushBack(SeqList* pq, SeqDateType x)
{
assert(pq);
SeqCheckCapacity(pq);//扩容判断
pq->a[pq->size] = x;
pq->size++;
}
2.4顺序表的头插
头插我们可以把所有元素后移一位,再把要插入的元素插到第一个位置:

void SeqListPushFront(SeqList* pq, SeqDateType x)
{
assert(pq);
SeqCheckCapacity(pq);
//从最后一个开始依次右移
int cur = pq->size - 1;
while (cur >= 0)
{
pq->a[cur + 1] = pq->a[cur];
cur--;
}
pq->a[0] = x;
pq->size++;
}
2.5顺序表的尾删
void SeqListPopBack(SeqList* pq)
{
assert(pq);
assert(pq->size > 0);//保证有数据删除
pq->size--;
}
这里直接把size减一就可以了,因为size标识的就是有效元素的个数,后边的是什么我们不关心。
这里capacity不用也改变,满了就扩容,删数据空间不变。
2.6顺序表的头删
头删比较简单,不需要考虑容量满了的问题,直接让后一个覆盖前一个就可以了
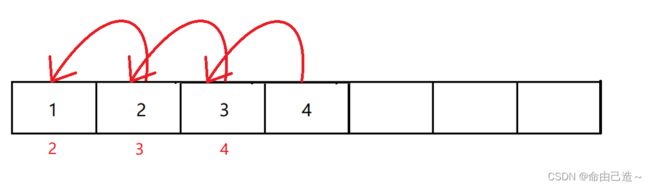
void SeqListPopFront(SeqList* pq)
{
assert(pq);
//提醒没有元素可以删除了
assert(pq->size > 0);
int cur = 0;
while (cur < pq->size - 1)
{
pq->a[cur] = pq->a[cur + 1];
cur++;
}
pq->size--;
}
2.7顺序表的查找
查找直接遍历顺序表,找到了返回下标,有多个就返回第一个x的下标,没找到返回-1
int SeqListSearch(SeqList* pq, SeqDateType x)
{
assert(pq);
int cur = 0;
while (cur < pq->size)
{
if (pq->a[cur] == x)
{
return cur;
}
cur++;
}
return -1;
}
2.8顺序表的指定位置插入
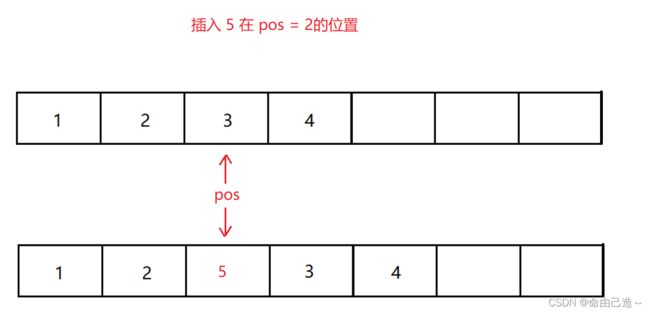
要求在任意位置插入,先判断容器是否满了, 再从pos的位置把元素向后挪动
void SeqListInsert(SeqList* pq, int pos, SeqDateType x)
{
assert(pq);
SeqCheckCapacity(pq);
int end = pq->size - 1;
while (end >= pos)
{
pq->a[end + 1] = pq->a[end];
end--;
}
pq->size++;
pq->a[pos] = x;
}
此时我们可以发现插入在任意位置的代码可以代替头插和尾插
2.8.1替代头插
void SeqListPushFront(SeqList* pq, SeqDateType x)
{
assert(pq);
int pos = 0;
SeqListInsert(pq, pos, x);
}
2.8.2代替尾插
void SeqListPushBack(SeqList* pq, SeqDateType x)
{
assert(pq);
int pos = pq->size;
SeqListInsert(pq, pos, x);
}
2.9顺序表的指定位置删除
把pos位置的删除后,把后面的元素依次往前移。
void SeqListPop(SeqList* pq, int pos)
{
assert(pq);
//保证有元素可删除
assert(pq->size > 0);
int cur = pos;
while (cur < pq->size - 1)
{
pq->a[cur] = pq->a[cur + 1];
cur++;
}
pq->size--;
}
此时我们可以发现删除在任意位置的代码可以代替头删和尾删
2.9.1替代头删
void SeqListPopFront(SeqList* pq)
{
assert(pq);
int pos = 0;
SeqListPop(pq, pos);
2.9.2代替尾删
void SeqListPopBack(SeqList* pq)
{
assert(pq);
int pos = pq->size - 1;
SeqListPop(pq, pos);
2.10顺序表的销毁
要删除开辟在堆上的空间,就用free释放,再把size和capacity重置为0
void SeqListDestory(SeqList* pq)
{
assert(pq);
free(pq->a);
pq->a = NULL;
pq->capacity = pq->size = 0;
}
2.11顺序表的打印
void SeqListPrint(SeqList* pq)
{
for (int i = 0; i < pq->size; i++)
{
printf("%d ", pq->a[i]);
}
printf("\n");
}
传址的原因:
1️⃣如果传参,会在拷贝时申请一块新的一份空间,传址的时候只有四个字节的内存,节省了空间
2️⃣保持接口的统一性(全部是传址)
三、顺序表的缺点及思考
1️⃣从中间或头部插入时间复杂度为O(N)(要挪动数据)。
2️⃣增容需要申请空间,拷贝数据,有时还要释放就空间,会产生不少的消耗,增容是有代价的。
3️⃣增容一般都是两倍增长,这样势必会有空间浪费。
那么如何解决这些问题呢?就会用到下面讲的链表了
链表
一、链表的基本介绍及优缺点
链表的大致结构如图
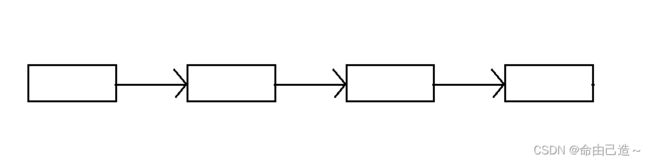
优点:1️⃣如果要插入直接申请一份空间,连在上面就可以,这样时间复杂度就为O(1)
2️⃣不会造成空间浪费
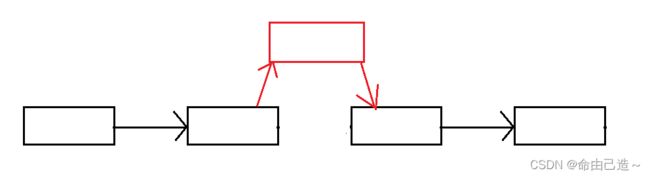
但也会造成1️⃣频繁开辟空间2️⃣不能随机访问,所以不能完全取代顺序表,两者是各有优缺点,就像货车和轿车一样,都无法取代对方。
二、八大链表结构
实际中链表的结构非常多样,以下的情况组合起来就有八种链表结构
1、单向和双向
2、带头和不带头
3、循环和非循环
用图的方式能最直观的感受
①单向带头循环链表
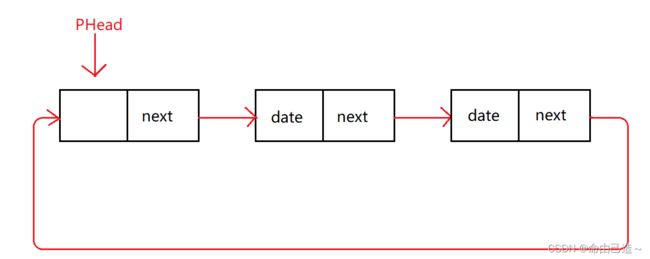
这里要注意PHead指向的结点是哨兵位,不存储任何数据,仅仅起到找到第一个有数据节点的作用。
②单向带头非循环链表
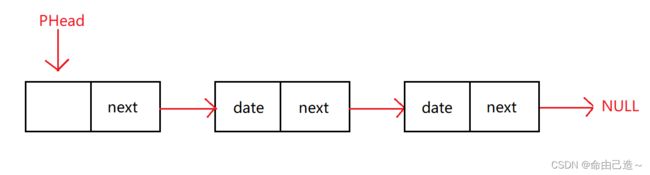
③单向不带头循环链表
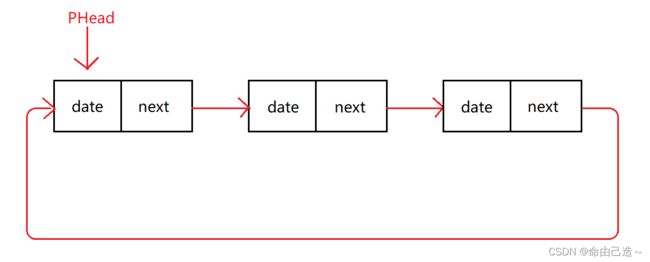
④单向不带头非循环链表
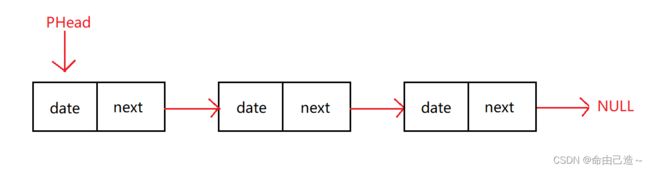
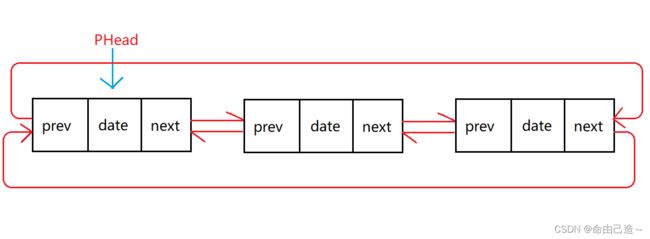
⑤双向带头循环链表
双向链表的初始状态比较特殊:
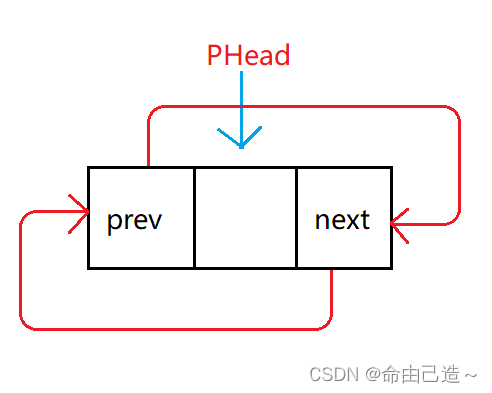
一般状态:
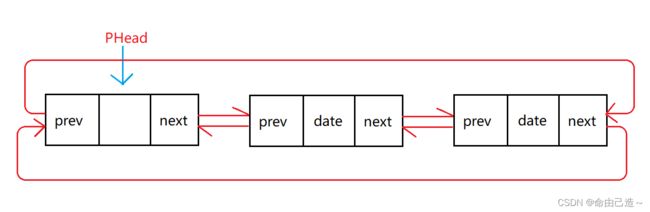
⑥双向带头非循环链表
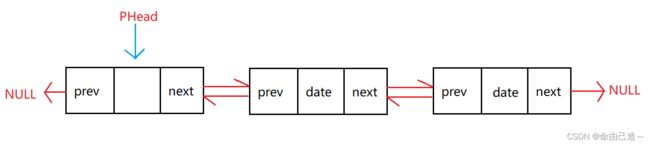
⑦双向不带头循环链表链表
⑧双向不带头非循环链表
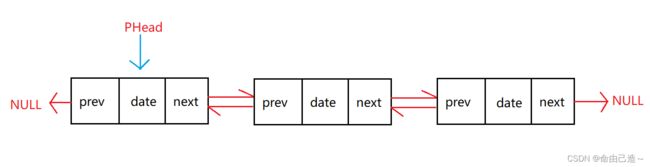
下面重点介绍单向不带头非循环链表和双向双向不带头非循环链表
单链表
一、链表的基本介绍
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
而单链表有一个指针域,双链表有两个指针域。
二、单链表的接口实现
2.1单链表结构的定义
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;//存数据
struct SListNode* next;//指向下一个结点
}SLTNode;
2.2单链表结点创建
从顺序表我们可以知道每次加数据都要申请结点,所以我们创建个申请结点的函数,需要结点就调用此函数。
SLTNode* BuySLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
return newnode;
}
2.3单链表的插入
先在主函数创建个结构体指针
SLTNode* plist = NULL;
想要操作就进行传址操作
2.3.1头插
void SListPushFront(SLTNode** pplist, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
newnode->next = *pplist;
*pplist = newnode;
}
我们知道传进来的是指向链表起始位置的指针,所以如图插入
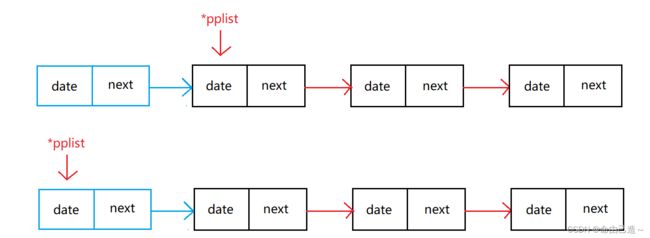
从这个图可以看出传址的重要性,如果是传值,pplist只会在拷贝的空间指向首地址,并不能改变原来的地址。
2.3.2尾插
这里我们发现要先找到尾部才能插入下一个结点
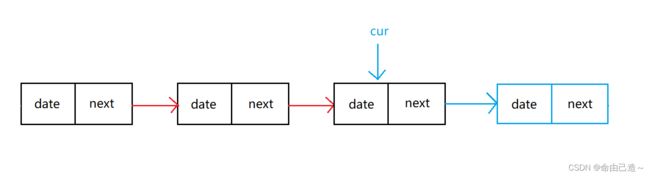
void SListPushBack(SLTNode** pplist, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
//找到尾
SLTNode* cur = *pplist;
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = newnode;
}
这代码里有个bug不知道大家看出来没有
如果此时链表一个元素都没有cur就是空指针,对cur进行操作就成了野指针!!!
所以要判断一下:
void SListPushBack(SLTNode** pplist, SLTDataType x)
{
SLTNode* newnode = BuySLTNode(x);
if (*pplist == NULL)
{
pplist = newnode;
}
else
{
//找到尾
SLTNode* cur = *pplist;
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = newnode;
}
}
2.3.3指定位置插入
2.3.3.1在pos前插入
此时我们需要找到pos前的一个结点才能够相连。
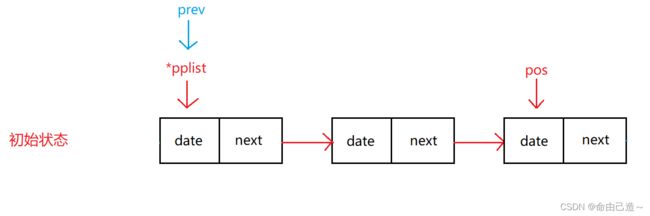
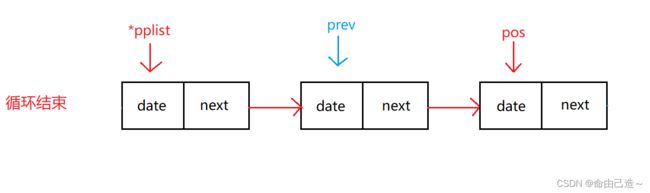
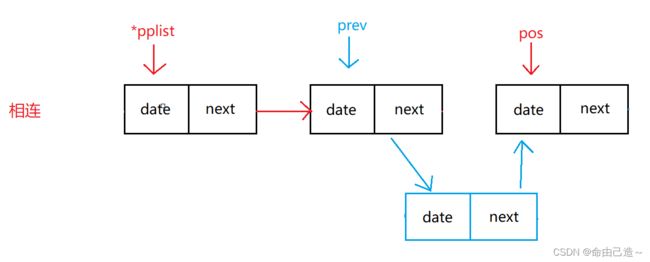
但是我们经过上面的错误可得知要先判断pos是不是首结点
void SListInsertBefore(SLTNode** pplist, SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode= BuySLTNode(x);
//在第一个位置前插
if (pos == *pplist)
{
newnode->next = *pplist;
*pplist = newnode;
}
else
{
//找到前一个结点位置
SLTNode* prev = *pplist;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
2.3.3.2在pos后插入
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
这里就不用考虑是不是最后一个了,没有影响。
2.4单链表的删除
2.4.1头删
头指针移动到第二个元素的地方,释放掉原头指针指向的结点。
void SListPopFront(SLTNode** pplist)
{
//要有元素可删
assert(*pplist);
SLTNode* next = (*pplist)->next;
free(*pplist);
*pplist = next;
}
2.4.2尾删
还是跟尾插一样要找到尾。
但是要考虑到没有结点和只有一个结点的情况
如果是多个结点,要找到尾部和尾部的前一个结点
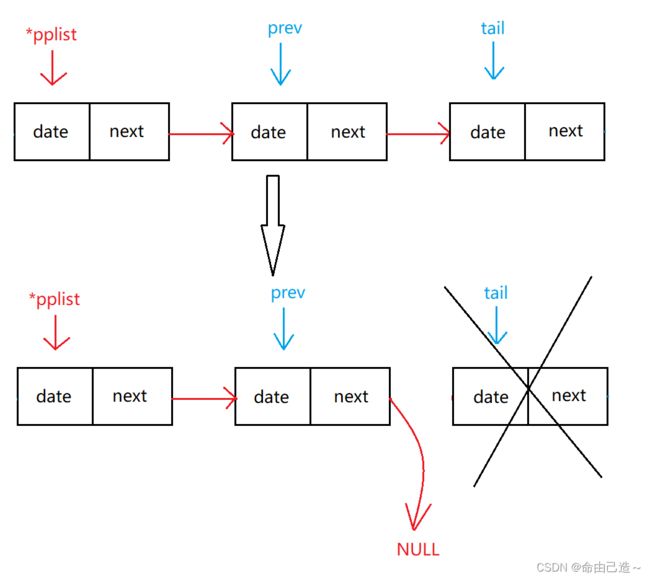
void SListPopBack(SLTNode** pplist)
{
//要有元素可删
assert(*pplist);
//只有一个结点
if ((*pplist)->next == NULL)
{
free(*pplist);
*pplist = NULL;
}
SLTNode* prev = NULL;
SLTNode* tail = *pplist;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
2.4.3指定位置删除
在指定的位置删除也是要找到删除结点的前一个结点
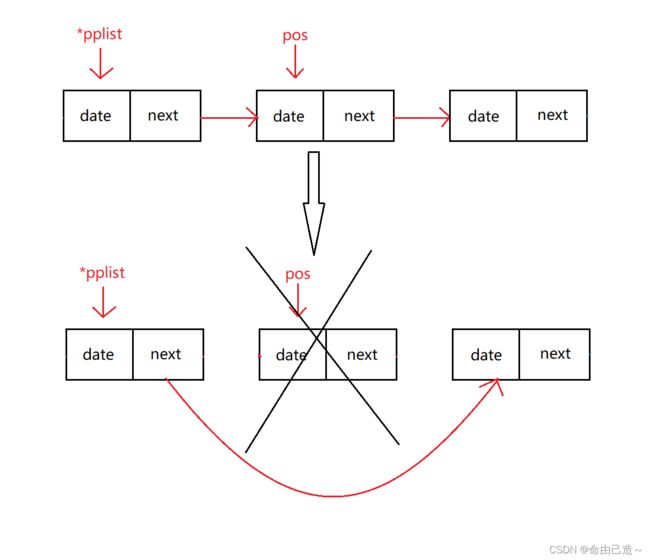
void SlistEraseCur(SLTNode** pplist, SLTNode* pos)
{
assert(pos);
//要有结点删
assert(*pplist);
//头删
if (*pplist == pos)
{
SListPopFront(*pplist);
}
else
{
SLTNode* cur = *pplist;
SLTNode* prev = NULL;
while (cur != pos)
{
prev = cur;
cur = cur->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
2.5单链表的查找
遍历找相同的结点里的数据,相同就返回对应的指针,没找到就返回NULL。
SLTNode* SListFind(SLTNode** pplist, SLTDataType x)
{
SLTNode* cur = *pplist;
//遍历链表
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2.6单链表的打印
void SListPrint(SLTNode* plist)
{
SLTNode* cur = plist;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
2.7单链表的销毁
void SListDestroy(SLTNode** pplist)
{
SLTNode* cur = *pplist;
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pplist = NULL;
}
双向链表
一、双向链表的基本介绍
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
二、双向链表的优缺点
跟单链表相比双向链表多了个可以指向前一个结点的指针,我们发现单链表在指定位置前插入结点时要遍历到前一个位置,而双向链表就不用遍历,直接用前指针就好了。虽然结构比单链表复杂,但是用起来很方便。
下面就把双向链表最复杂的结构双向带头循环链表实现一下。
三、双向链表的接口实现
3.1双向链表的结构定义
typedef int LTDateType;
typedef struct ListNode
{
struct ListNode* prev;
struct ListNode* next;
LTDateType date;
}ListNode;
3.2双向链表结点的创建
ListNode* BuyListNode(LTDateType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->next = NULL;
newnode->date = x;
newnode->prev = NULL;
return newnode;
}
3.3双向链表的初始化
因为我们要创建的是带哨兵位的双向链表,所以要创建个哨兵位。
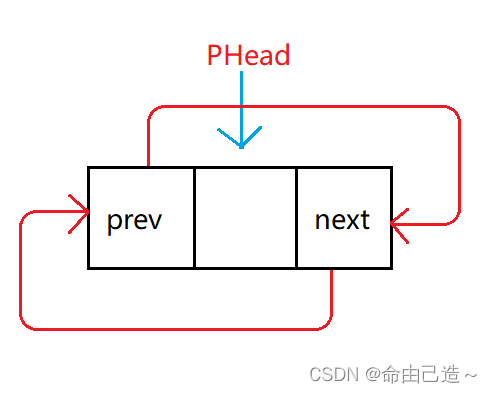
ListNode* ListInit()
{
ListNode* phead = BuyListNode(0);
phead->next = phead;
phead->prev = phead;
return phead;
}
3.4双向链表的插入
3.4.1尾插
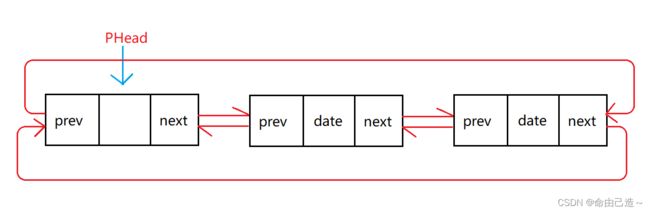
从图中可以看出尾部很好找,就是哨兵位的前驱位。
void ListPushBack(ListNode* phead, LTDateType x)
{
assert(phead);
ListNode* newnode = BuyListNode(x);
//找尾
ListNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
最后四步是为了让插入后结构还是保持原样。
3.4.2头插
其实头插跟尾插换汤不换药,实现的方式一样:
void ListPushFront(ListNode* phead, LTDateType x)
{
assert(phead);
ListNode* newnode = BuyListNode(x);
ListNode* first = phead->next;
{
newnode->next = first;
first->prev = newnode;
newnode->prev = phead;
phead->next = newnode;
}
}
3.4.3任意位置插入
把上面的头插尾插综合一下很容易能想到:
void ListInsert(ListNode* pos, LTDateType x)
{
assert(pos);
ListNode* newnode = BuyListNode(x);
struct ListNode* prev = pos->prev, *next = pos;
prev->next = newnode;
newnode->prev = prev;
newnode->next = next;
next->prev = newnode;
}
根据上面的经验,头插尾插都可以调用这个接口来代替。
3.5双向链表的删除
3.5.1尾删
尾部删除的时候要注意如果只有一个哨兵位就不做处理
void ListPopBack(ListNode* phead)
{
assert(phead);
ListNode* tail = phead->prev, * prev = tail->prev;
//不能删除哨兵位
if (tail != phead)
{
free(tail);
phead->prev = prev;
prev->next = phead;
}
}
3.5.2头删
void ListPopFront(ListNode* phead)
{
assert(phead);
ListNode* del = phead->next, * next = del->next;
//不能删哨兵位
if (del != phead)
{
free(del);
phead->next = next;
next->prev = phead;
}
}
3.5.3任意位置删除
找到目标结点的前一个和后一个连接就行。
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* prev = pos->prev, * next = pos->next;
prev->next = next;
next->prev = prev;
}
3.6双向链表的打印
void ListPrint(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->date);
cur = cur->next;
}
printf("\n");
}
3.7双向链表的判空
就是判断双向链表是不是除了哨兵位就没有节点了,空返回 1, 非空返回0.
bool ListEmpty(ListNode* phead)
{
return phead->next == phead;
}
3.8双向链表的销毁
void ListDestroy(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
ListNode* del = cur;
cur = cur->next;
free(del);
}
free(phead);
phead = NULL;
}
这里要注意最后的 phead = NULL不起作用,因为是传值操作。为了保持接口一致性,就不传址了,在销毁函数运行后手动置空。