Hive/Spark SQL使用案例
Hive/Spark SQL使用案例
-
-
- 求 TOPN:开窗函数
- 求天数:datediff() 函数
- 求每个学生的成绩都大于...系列:开窗 / 分组
- 表转置/行转列系列一:concat_ws 函数
- 表转置/行转列系列二:concat_ws 函数
- 表转置/列转行系列:explode 函数 + LATERAL VIEW
- 同组不同行对比系列:窗口函数
- 多个字段求TOPN:开窗函数
- 求...率系列
- 按照时间求累加:窗口函数(排序字段不是分区字段)
- 统计店铺的 UV 和 PV
- 大数据排序统计
- 订单量统计
- 求用户连续登陆天数
-
【关键字:Hive SQL 面试、Hive SQL 练习、Hive SQL 函数示例、Spark SQL 面试、Spark SQL 练习、Spark SQL 函数示例】
如有错误,欢迎留言指出!
# 使用 group by 时
1. select 的字段必须是 group by 的字段
2. select 聚合的字段可以不是 group by 的字段
3. having 的字段必须是 select 中的字段
# 使用 where 时
1. where 的条件中的字段可以是 select 中没出现的字段
# 开窗 sum() over() 时
1. 既有 partition by 又有 order by ,如果 order by 的字段不在 partition by 的字段中,sum 的结果是累加的效果
2. 既有 partition by 又有 order by ,如果 order by 的字段在 partition by 的字段中,sum 的结果是整个窗口的总和的效果
求 TOPN:开窗函数
需求说明
求出每个部门工资最高的前三名员工,并计算这些员工的工资占所属部门总工资的百分比
建表和数据
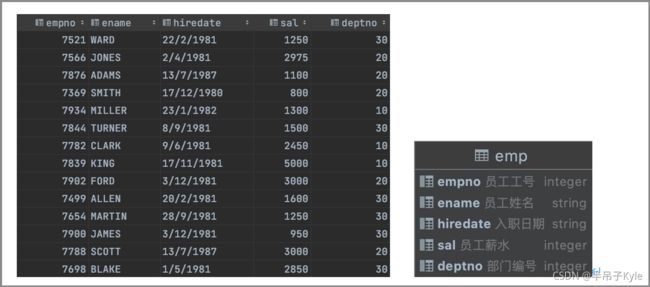
-- 创建员工表
create table if not exists emp
(
empno integer comment '员工工号',
ename string comment '员工姓名',
hiredate string comment '入职日期',
sal integer comment '员工薪水',
deptno integer comment '部门编号'
) row format delimited fields terminated by ',';
-- 模拟数据
7698,WARD,22/2/1981,1250,30
7566,JONES,2/4/1981,2975,20
7876,ADAMS,13/7/1987,1100,20
7369,SMITH,17/12/1980,800,20
7934,MILLER,23/1/1982,1300,10
7844,TURNER,8/9/1981,1500,30
7782,CLARK,9/6/1981,2450,10
7839,KING,17/11/1981,5000,10
7902,FORD,3/12/1981,3000,20
7499,ALLEN,20/2/1981,1600,30
7654,MARTIN,28/9/1981,1250,30
7900,JAMES,3/12/1981,950,30
7788,SCOTT,13/7/1987,3000,20
7698,BLAKE,1/5/1981,2850,30
解答思路
① 算比例,要使用聚合后的工资汇总,那么就需要使用子查询
② 排名,需要使用开窗函数,TOPN 则需要对排序后的结果筛选,加 where
select empno `员工工号`, sal `员工工资`, deptno `部门编号`, sal_no `部门薪资`, total_sal `部门总工资`, round(sal / total_sal, 2) `工资占部门比例`
from (
select *,
row_number() over (partition by deptno order by sal desc) sal_no,
sum(sal) over (partition by deptno) total_sal
from emp
)
where sal_no <= 3
order by deptno desc;

求天数:datediff() 函数
需求说明
该表记录了每个品牌的营销活动开始日期以及结束日期,统计出每个品牌的总营销天数
建表及数据

解题思路
① 先计算出每个活动的天数
② 将所有活动天数汇总
select brand `品牌`,
sum(datediff(enddate, startdate)) `总营销天数`
from marketing
group by brand;

求每个学生的成绩都大于…系列:开窗 / 分组
需求介绍
用一条 SQL 语句查询出每门课程都大于 80 分的学生姓名
建表及数据
create table scores(
name string comment '姓名',
subject string comment '学科',
score int comment '成绩'
) row format delimited fields terminated by ',';
kyle,语文,81
kyle,数学,75
jack,语文,76
jack,数学,90
lucy,语文,81
lucy,数学,100
lucy,英语,90
解题思路
第一种: 按照每个学生的姓名分组,然后求出分组中的最小值,如果最小值大于 80 ,该条数据符合
select name
from scores
group by name
having min(score) > 80;
第二种:开窗计算求出最小值,然后过滤最小值大于 80
select distinct (name)
from (
select name,
min(score) over (partition by name) min_score
from scores
)
where min_score > 80
group by name;
第三种:使用分析窗口函数 FIRST_VALUE 或者 LAST_VALUE 函数
select distinct (name)
from (
select name,
first_value(score) over (partition by name order by score) min_score
from scores
)
where min_score > 80;
![]()
表转置/行转列系列一:concat_ws 函数
需求介绍
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.2 1.4
1992 2.1 2.2 2.3 2.4
建表语句
create table inverse_table(
year int,
month int,
amount double
) row format delimited fields terminated by ',';
解题思路
第一种:按照 year 分组,分组后将多列拼接成一行,然后对该行提取数据,分成多行
select year,
concat_column['1'] m1,
concat_column['2'] m2,
concat_column['3'] m3,
concat_column['4'] m4
from (
select year,
str_to_map(concat_ws(',', collect_set(concat_ws(':', month, amount)))) concat_column
from inverse_table
group by year
) a;
第二种:使用 sum 函数,只过滤当前字段
select year,
sum(if(month=1,amount,0)) m1,
sum(if(month=2,amount,0)) m2,
sum(if(month=3,amount,0)) m3,
sum(if(month=4,amount,0)) m4
from inverse_table
group by year;

表转置/行转列系列二:concat_ws 函数
表和数据
| express_id | area_id | store_id | enevt_time |
|---|---|---|---|
| 1356 | a12 | x1135 | 2021-10-10 08:23:51 |
| 1356 | a12 | z1126 | 2021-10-10 13:45:23 |
| 1356 | a12 | y2345 | 2021-10-10 22:10:36 |
| 1356 | b15 | d6785 | 2021-10-11 07:03:51 |
| 1356 | b15 | d5432 | 2021-10-11 17:23:54 |
| 1357 | c12 | g1245 | 2021-10-13 07:03:51 |
| 1357 | c12 | v3421 | 2021-10-13 17:25:45 |
| 1358 | v45 | b2897 | 2021-09-13 17:25:45 |
| 1358 | v45 | m2387 | 2021-09-13 18:50:12 |
cache table express_desc
select '1356' express_id, 'a12' area_id, 'x1135' store_id, '2021-10-10 08:23:51' event_time
union
select '1356' express_id, 'a12' area_id, 'x1126' store_id, '2021-10-10 13:45:23' event_time
union
select '1356' express_id, 'a12' area_id, 'y2345' store_id, '2021-10-10 22:10:36' event_time
union
select '1356' express_id, 'b15' area_id, 'd6785' store_id, '2021-10-11 07:03:51' event_time
union
select '1356' express_id, 'b15' area_id, 'd5432' store_id, '2021-10-11 17:23:54' event_time
union
select '1357' express_id, 'c12' area_id, 'g1245' store_id, '2021-10-13 07:03:51' event_time
union
select '1357' express_id, 'c12' area_id, 'v3421' store_id, '2021-10-13 17:25:45' event_time
union
select '1358' express_id, 'v45' area_id, 'b2897' store_id, '2021-09-13 17:25:45' event_time
union
select '1358' express_id, 'v45' area_id, 'm2387' store_id, '2021-09-13 18:50:12' event_time;
需求说明
展示快递单号 express_id 的流转详情,示例:
1356 a12 1 x1135 -> 2 z1126 -> 3 y2345
需求分析
根据 express_id 和 area_id 分组,然后收集字段 store_id 并拼接成字符串
代码示例
with t1 as (
select express_id,
area_id,
store_id,
row_number() over (partition by express_id,area_id order by event_time) rn
from express_desc
)
select
express_id,
area_id,
concat_ws('->',collect_list(concat_ws(' ',rn,store_id)))
from t1
group by express_id,area_id;

表转置/列转行系列:explode 函数 + LATERAL VIEW
需求介绍
求出每个技能对应的最大的用户的年龄
表和数据
| user_id | user_name | age | skills |
|---|---|---|---|
| 1356 | kyle | 23 | Hadoop-Hive-Spark |
| 1357 | Jack | 22 | Hadoop-Hive |
| 1358 | Sam | 26 | Mysql-Oracle |
| 1359 | Lucy | 28 | Redis-Mysql |
| 1360 | Rose | 32 | Hadoop-Hive-Spark-Flink-Hbase |
| 1361 | Herry | 25 | Flink-Hbase-ClickHouse-Kafka |
| 1362 | Kelly | 27 | Spark-Flink-Hbase |
cache table user_info
select '1356' user_id, 'kyle' user_name, 23 age, 'Hadoop-Hive-Spark' skills
union
select '1357' user_id, 'Jack' user_name, 22 age, 'Hadoop-Hive' skills
union
select '1358' user_id, 'Sam' user_name, 26 age, 'Mysql-Oracle' skills
union
select '1359' user_id, 'Luc' user_name, 28 age, 'Redis-Mysql' skills
union
select '1360' user_id, 'Rose' user_name, 32 age, 'Hadoop-Hive-Spark-Flink-Hbase' skills
union
select '1361' user_id, 'Harry' user_name, 25 age, 'Flink-Hbase-ClickHouse-Kafka' skills
union
select '1362' user_id, 'Kelly' user_name, 27 age, 'Spark-Flink-Hbase' skills;
需求分析
先从 skills 字段把每个技能分割出来,然后按照 user_id 和 skills 字段分组,求出最大的年龄
with t1 as (
-- 对 skills 字段进行切割并实现列转行
select user_id,
user_name,
age,
skill
from user_info
lateral view explode(split(skills,'-')) skill_table as skill
),
t2 as (
-- 按照 skill 分组 age 排序,为了标记每个技能对应的最大的用户信息
select *,
row_number() over(partition by skill order by age desc) rn
from t1
)
select
user_id,
user_name,
age,
skill
from t2
where rn = 1;
同组不同行对比系列:窗口函数
表和数据
① 学生表:student
| sid | same | gender | class_id |
|---|---|---|---|
| 1 | Lucy | 女 | 1 |
| 2 | Gim | 女 | 1 |
| 3 | Tim | 男 | 2 |
② 课程表:course
| cid | came | teacher_id |
|---|---|---|
| 1 | 生物 | 1 |
| 2 | 体育 | 1 |
| 3 | 物理 | 2 |
③ 成绩表:score
| sid | student_id | course_id | number |
|---|---|---|---|
| 1 | 1 | 1 | 58 |
| 2 | 1 | 2 | 68 |
| 3 | 2 | 2 | 89 |
需求介绍
查询课程编号 2 的成绩比课程编号 1 课程低的所有同学的学号、姓名
解题思路
方法一:使用窗口函数,根据 sname 分组 course_id 排序,在 course_id =2 时,获取上一行比较
select sid,
sname
from (
select a.sid,
b.sname,
if(a.sid = 2, lag(a.number) over (partition by a.student_id order by a.course_id) - a.number, 0) be_res
from score a
join student b on a.student_id = b.sid)
where be_res > 0;
方法二:根据 sname 分组,对每个人的 course_id =1时和 course_id = 2 的成绩聚合计算
with t1 as(
select student_id,
sum(if(course_id=2,number,0)) as c1,
sum(if(course_id=1,number,0)) as c2
from score
group by student_id
having c1 < c2)
select sid, sname
from t1
join student
on t1.student_id = sid;
需求介绍
查询没有学全所有课的同学的学号、姓名
解题思路
计算出课程的总量、每个学生的课程的总量,然后对比
-- 如果报错,需要开启允许笛卡尔积
with t1 as (
select a.sid,a.sname,
count(course_id) as cnt1
from student a
left join score b on a.sid=b.student_id
group by a.sid,a.sname
),
t2 as (
select count(cid) as total_cnt from course
)
select
sid,sname
from t1 join t2
where cnt1 < total_cnt;
多个字段求TOPN:开窗函数
表和数据
create table t_trade
(
init_date int comment '日期',
client_id string comment '客户号',
fund_code string comment '基金产品代码',
business_flag int comment '1 卖出 2 买入',
business_balance decimal comment '交易金额'
);
需求介绍
求每日买入成交额和前十名和卖出成交额前十名的基金产品
解题思路
根据 init_date、fund_code、business_flag 分组,然后每组中的 business_balance 求和汇总
方法一:使用临时表
with t1 as (
select init_date,
fund_code,
business_flag,
sum(business_balance) sum_numeric
from t_trade
group by init_date, fund_code, business_flag
),
t2 as (
select *,
row_number() over (partition by init_date,business_flag order by sum_numeric) rn
from t1
)
select *
from t2
where rn <= 10;
方法二:直接通过子查询查询,窗口函数排序
select *
from (
select fund_code,
init_date,
business_flag,
row_number() over (partition by fund_code,business_flag order by sum_numeric desc) rn
from (
select fund_code,
init_date,
business_flag,
sum(business_balance) sum_numeric
from t_trade
group by fund_code, init_date, business_flag
)
)
where rn <= 10;
求…率系列
表和数据
create table t_trade
(
init_date int comment '日期',
client_id string comment '客户号',
fund_code string comment '基金产品代码',
business_flag int comment '1 卖出 2 买入',
business_balance decimal comment '交易金额'
);
需求介绍
求每日每个客户灭之股票的市值增长率( 市值增长率 = (当日市值 - 上日市值) / 上日市值 )
问题分析
先求出上日市值,然后计算比率
select *,
if(last_market_value != 0, (market_value - last_market_value) / last_market_value, null) as incre_rate
from (select *,
lag(market_value) over (partition by client_id,stock_code order by init_date) as last_market_value
from stock) a;
按照时间求累加:窗口函数(排序字段不是分区字段)
需求介绍
要求使用 SQL 统计出每个用户的累积访问次数,如图所示
| 用户id | 月份 | 小计 | 累计 |
|---|---|---|---|
| u01 | 2017-01 | 11 | 11 |
| u01 | 2017-02 | 12 | 23 |
| u02 | 2017-01 | 12 | 12 |
| u03 | 2017-01 | 8 | 8 |
| u04 | 2017-01 | 3 | 3 |
表和数据
| userId | visitDate | visitCount |
|---|---|---|
| u01 | 2017/1/21 | 5 |
| u02 | 2017/1/23 | 6 |
| u03 | 2017/1/22 | 8 |
| u04 | 2017/1/20 | 3 |
| u01 | 2017/1/23 | 6 |
| u01 | 2017/2/21 | 8 |
| u02 | 2017/1/23 | 6 |
| u01 | 2017/2/22 | 4 |
-- 建表
CREATE TABLE test1
(
userId string,
visitDate string,
visitCount INT
) ROW format delimited FIELDS TERMINATED BY "\t";
-- 插入数据
INSERT INTO TABLE test1
VALUES
( 'u01', '2017/1/21', 5 ), ( 'u02', '2017/1/23', 6 ), ( 'u03', '2017/1/22', 8 ), ( 'u04', '2017/1/20', 3 ), ( 'u01', '2017/1/23', 6 ), ( 'u01', '2017/2/21', 8 ), ( 'u02', '2017/1/23', 6 ), ( 'u01', '2017/2/22', 4 );
需求分析
小计的结果是分组聚合后的结果,累计的结果是小计结果之后通过开窗计算的,需要注意的两点是:
1. 开窗函数是对所有的行进行操作,所以在分组的时候,聚合的字段必须是 group by 的字段
2. 希望出现开窗累加的效果,则需要 order by 的字段不是 partition by 的字段
select userId,
visitDate,
sum_count,
sum(sum_count) over (partition by userId order by visitDate) sum_asc
from (
select userId,
visitDate,
sum(visitCount) sum_count
from (
select userId,
date_format(regexp_replace(visitDate, '/', '-'), 'yyyy-MM') visitDate,
visitCount
from test1
)
group by userId, visitDate
order by userId
);
统计店铺的 UV 和 PV
需求分析
有 50W 个店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,
访问日志存储的表名为 Visit,访客的用户 id 为 user_id,被访问的店铺名称为 shop
1. 每个店铺的 UV(访客数):同一个用户多次访问一个店铺算一次
2. 每个店铺访问次数 top3 的访客信息。输出店铺名称、访客id、访问次数:访问一次就算一次
数据和表
-- 创建表
CREATE TABLE test2 (
user_id string, shop string )
ROW format delimited FIELDS TERMINATED BY '\t';
-- 插入数据
INSERT INTO TABLE test2 VALUES
( 'u1', 'a' ), ( 'u2', 'b' ), ( 'u1', 'b' ), ( 'u1', 'a' ), ( 'u3', 'c' ), ( 'u4', 'b' ), ( 'u1', 'a' ), ( 'u2', 'c' ), ( 'u5', 'b' ), ( 'u4', 'b' ), ( 'u6', 'c' ), ( 'u2', 'c' ), ( 'u1', 'b' ), ( 'u2', 'a' ), ( 'u2', 'a' ), ( 'u3', 'a' ), ( 'u5', 'a' ), ( 'u5', 'a' ), ( 'u5', 'a');
需求分析
① 第一个需求
按照店铺分组,然后通过 user_id 去重
select
shop,
count(distinct user_id) uv
from test2
group by shop;

② 第二个需求
按照店铺和用户分组,就可以获得每个店铺的每个用户的访问次数
然后开窗排序获得每个用户的序号
前三就是序号小于等于 3 的
select shop,
user_id,
pv,
num
from (
select shop,
user_id,
pv,
row_number() over (partition by shop order by pv desc) num
from (
select shop,
user_id,
count(user_id) pv
from test2
group by shop, user_id
)
)
where num <= 3;

大数据排序统计
需求说明
有一个 5000 万的用户表(user),一个 2 亿记录的用户看电影的记录表(visit_log),根据年龄段观看电影的次数进行排序
表及数据
-- 用户表
CREATE TABLE user
(
user_id string,
name string,
age int
);
-- 记录表
CREATE TABLE visit_log
(
user_id string,
url string
);
-- 数据插入
INSERT INTO user VALUES('001','u1',10);
INSERT INTO user VALUES('002','u2',15);
INSERT INTO user VALUES('003','u3',15);
INSERT INTO user VALUES('004','u4',20);
INSERT INTO user VALUES('005','u5',25);
INSERT INTO user VALUES('006','u6',35);
INSERT INTO user VALUES('007','u7',40);
INSERT INTO user VALUES('008','u8',45);
INSERT INTO user VALUES('009','u9',50);
INSERT INTO user VALUES('0010','u10',65);
INSERT INTO visit_log VALUES('001','url1');
INSERT INTO visit_log VALUES('002','url1');
INSERT INTO visit_log VALUES('003','url2');
INSERT INTO visit_log VALUES('004','url3');
INSERT INTO visit_log VALUES('005','url3');
INSERT INTO visit_log VALUES('006','url1');
INSERT INTO visit_log VALUES('007','url5');
INSERT INTO visit_log VALUES('008','url7');
INSERT INTO visit_log VALUES('009','url5');
INSERT INTO visit_log VALUES('0010','url1');
需求分析
先对用户表的每个用户的数据划分年龄段,然后关联观影记录表,根据年龄段分组,然后统计排序
select *
from (
select age_phase,
count(u.user_id) cnt
from (
select user_id,
case
when age < 10 then '0-10'
when age >= 10 and age < 20 then '10-20'
when age >= 20 and age < 30 then '20-30'
when age >= 30 and age < 40 then '30-40'
when age >= 40 and age < 50 then '30-40'
when age >= 50 and age < 60 then '30-40'
when age >= 60 and age < 70 then '30-40'
when age >= 70 then '70以上'
end
as age_phase
from user
) u
LEFT JOIN visit_log g on g.user_id = u.user_id
group by u.age_phase
)
order by cnt desc;
订单量统计
需求说明
已知一个订单表( order )有如下字段
-- 数据样例
dt order_id user_id amount
2017-01-01,10029028,1000003251,33.57
(1) 给出 2017年每个月的订单数、用户数、总成交金额
(2) 给出2017年11月的新客数(指在11月才有第一笔订单)
表和数据
-- 表
CREATE TABLE order (
dt string, order_id string, user_id string, amount DECIMAL ( 10, 2 ) )
ROW format delimited FIELDS TERMINATED BY '\t'
-- 数据
INSERT INTO TABLE order VALUES ('2017-01-01','10029029','1000003251',33.57);
INSERT INTO TABLE order VALUES ('2017-01-01','100290288','1000003252',33.57);
INSERT INTO TABLE order VALUES ('2017-02-02','10029088','1000003251',33.57);
INSERT INTO TABLE order VALUES ('2017-02-02','100290281','1000003251',33.57);
INSERT INTO TABLE order VALUES ('2017-02-02','100290282','1000003253',33.57);
INSERT INTO TABLE order VALUES ('2017-11-02','10290282','100003253',234);
INSERT INTO TABLE order VALUES ('2018-11-02','10290284','100003243',234);
需求分析
需求一:
对日期进行处理,并按照日期分组,分别计算对应的指标
select
month,
count(order_id) order_cnt,
count(distinct user_id) user_cnt,
sum(amount) order_amout
from (
select *,
date_format(dt, 'yyyy-MM') month
from order
)
group by month
having date_format(month,'yyyy') = '2017'
order by month
![]()
需求二:
对用户进行分组,计算 2017-11 的订单数量和除 2017-11 之外的订单数量 ,如果 2017-11 的订单数量大于等于 1,除 2017-11 之外的订单数量等于 0 ,则为新用户
select sum(if(nov_vnt >= 1 and other_cnt = 0, 1, 0)) new_user_cnt
from (
select
sum(if(month = '2017-11', 1, 0)) nov_vnt,
sum(if(month != '2017-11', 1, 0)) other_cnt
from (
select *,
date_format(dt, 'yyyy-MM') month
from order
)
group by user_id
)
![]()
求用户连续登陆天数
需求说明
获取连续登陆天数超过 2 天的用户
表和数据
| user_id | user_name | login_date |
|---|---|---|
| 1356 | kyle | 2021/10/10 |
| 1356 | kyle | 2021/10/11 |
| 1356 | kyle | 2021/10/12 |
| 1357 | Rose | 2021/10/13 |
| 1358 | Susan | 2021/10/15 |
| 1356 | kyle | 2021/10/17 |
| 1359 | Sam | 2021/09/10 |
| 1360 | Jack | 2021/09/11 |
| 1360 | Jack | 2021/09/12 |
| 1361 | Lisa | 2021/09/11 |
cache table login_log as(
select '1356' user_id, 'kyle' user_name, '2021/10/10' login_date
union
select '1356' user_id, 'kyle' user_name, '2021/10/11' login_date
union
select '1356' user_id, 'kyle' user_name, '2021/10/12' login_date
union
select '1357' user_id, 'Rose' user_name, '2021/10/13' login_date
union
select '1358' user_id, 'Susan' user_name, '2021/10/15' login_date
union
select '1356' user_id, 'kyle' user_name, '2021/10/17' login_date
union
select '1359' user_id, 'Sam' user_name, '2021/09/10' login_date
union
select '1360' user_id, 'Jack' user_name, '2021/09/11' login_date
union
select '1360' user_id, 'Jack' user_name, '2021/09/12' login_date
union
select '1361' user_id, 'Lisa' user_name, '2021/09/11' login_date
);
思路分析
这个需求最大的难点是:如何知道用户是连续登陆的,如何知道用户连续登陆的断开和重新开启
ps:该需求在面试中多次被问到
我们按照用户 id 进行分组,然后根据 login_date 排序,给每条数据打上一个 row_number,然后用 login_date - row_number ,你会发现这样一个情况
如果是连续登陆的日期,减去 row_number 后是一个定值
| user_id | user_name | login_date | row_number | login_date - row_number |
|---|---|---|---|---|
| 1356 | kyle | 2021/10/10 | 1 | 2021/10/09 |
| 1356 | kyle | 2021/10/11 | 2 | 2021/10/09 |
| 1356 | kyle | 2021/10/12 | 3 | 2021/10/09 |
| 1356 | kyle | 2021/10/17 | 4 | 2021/10/13 |
| 1360 | Jack | 2021/09/11 | 1 | 2021/09/10 |
| 1360 | Jack | 2021/09/12 | 2 | 2021/09/10 |
| 1357 | Rose | 2021/10/13 | 1 | 2021/10/12 |
| 1358 | Susan | 2021/10/15 | 1 | 2021/09/14 |
| 1359 | Sam | 2021/09/10 | 1 | 2021/09/09 |
| 1361 | Lisa | 2021/09/11 | 1 | 2021/09/10 |
代码示例
with t1 as (
-- 格式化日期字段
select user_id,
user_name,
replace(login_date, '/', '-') as login_date
from login_log
)
,
t2 as (
-- 按照用户分组,根据日期排序,标记行号
select *,
row_number() over (partition by user_id order by login_date) rn
from t1
),
t3 as (
-- 获取 login_date - row_number 的结果
select user_id,
user_name,
date_sub(login_date, rn) as diff
from t2
),
t4 as (
-- 分组统计连续登陆的天数
select user_id,
user_name,
count(diff) as login_days
from t3
group by user_id, user_name, diff
)
select user_id,
user_name
from t4
where login_days >= 2;