轻量型模型之总结(mobilenet,shufflenet,ghostnet)
在介绍这些模型前,首先我们了解一下分组卷积的概念。
分组卷积
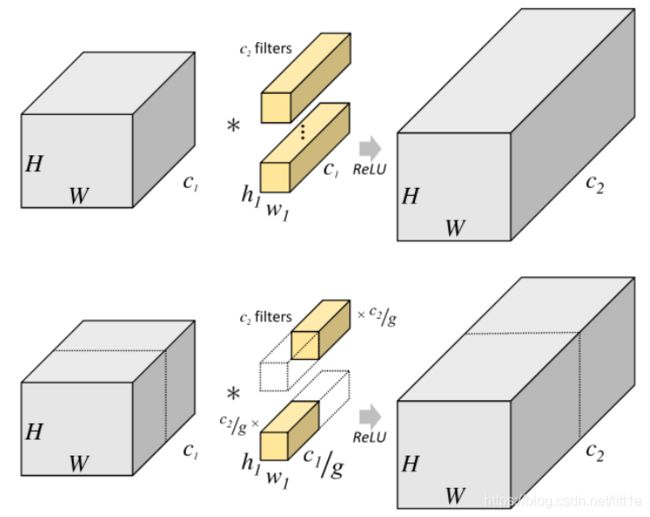
上图表示普通卷积操作,即输入 H × W × C 1 H\times W\times C1 H×W×C1经过 C 1 × H 1 × W 1 × C 2 C1\times H1\times W1\times C2 C1×H1×W1×C2的卷积核,卷积成 H × W × C 2 H\times W\times C2 H×W×C2的feature map。其参数量是: C 1 × H 1 × W 1 × C 2 C1\times H1\times W1\times C2 C1×H1×W1×C2;
FLOPS: H × W × C 1 × C 2 × H 1 × H 2 H\times W\times C1\times C2\times H1\times H2 H×W×C1×C2×H1×H2
下图表示分组卷积,将通道按输入分成g组,每组输入尺寸是 H × W × C 1 g H\times W\times \frac {C1}{g} H×W×gC1,对应的卷积核 H 1 × W 1 × C 1 g × C 2 g H1\times W1\times \frac {C1}{g} \times \frac {C2}{g} H1×W1×gC1×gC2,每组的输出尺寸是 H × W × C 2 g H\times W\times \frac {C2}{g} H×W×gC2,将每组输出concate就可以获得最终输出 H × W × C 2 H\times W\times C2 H×W×C2。
分组卷积的参数量: H 1 × W 1 × C 1 g × C 2 g × g H1\times W1\times \frac {C1}{g} \times \frac {C2}{g} \times g H1×W1×gC1×gC2×g
Shufflenet v1
mobilenet采用了depthwise convolution以及dense pointwise convolution进行特征提取,其中depthwise是特殊的分组卷积(g=channel),为了弥补通道间交流的损失,模型中出现了大量的dense pointwise convolution,占据了大量的计算量。为了解决这个问题,shufflenet在1×1的pointwise conv中也采用了group conv的方式,对其分组来降低计算量,同时,为了弥补跨通道信息损失,shufflenet提出了channel shuffle,通过均匀打乱通道,使得信息在不同通道间流通。
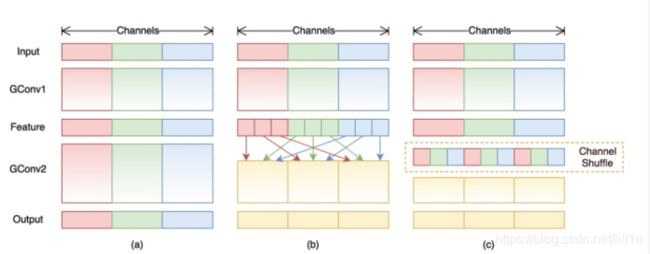
下面是pytorch实现channel shuffle 的代码。
def shuffle_channels(x, groups):
"""shuffle channels of a 4-D Tensor"""
batch_size, channels, height, width = x.size()
assert channels % groups == 0
channels_per_group = channels // groups
# split into groups
x = x.view(batch_size, groups, channels_per_group,
height, width)
# transpose 1, 2 axis
x = x.transpose(1, 2).contiguous()
# reshape into orignal
x = x.view(batch_size, channels, height, width)
return x
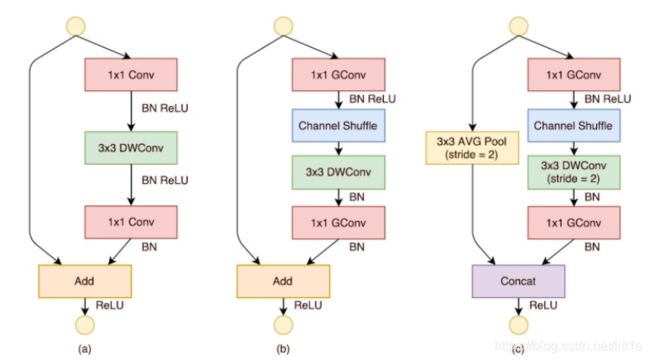
下图是shufflenet v1的基本单元,a是mobilenetv1,b是shufflenet采用了1×1的分组卷积降低计算量并结合channel shuffle提供跨通道信息交流的桥梁。
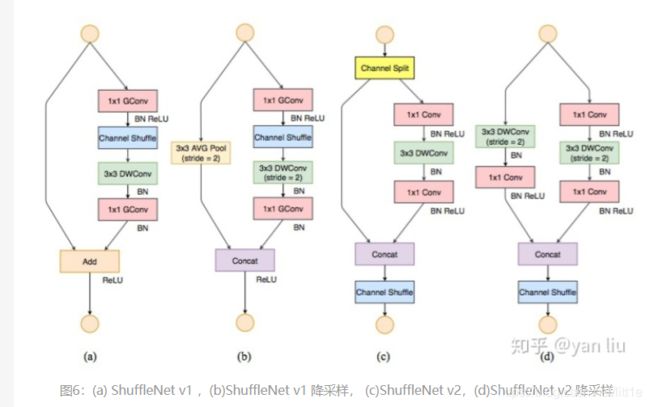
Shufflenet v2
shufflenetv2分析了flops不能作为衡量模型计算量的唯一标准,内存读写,GPU并行性,文件IO等也应该考虑进去。作者从内存访问代价(Memory Access Cost,MAC)和GPU并行性的方向分析了网络应该怎么设计才能进一步减少运行时间,直接的提高模型的效率。
总结一下,在设计高性能网络时,我们要尽可能做到:
G1). 使用输入通道和输出通道相同的卷积操作;
G2). 谨慎使用分组卷积;
G3). 减少网络分支数;
G4). 减少element-wise操作。
mobilenet v1
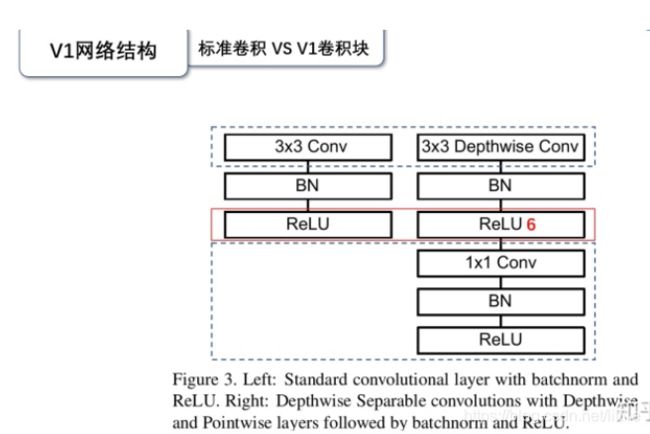
从上图可以看到,Mobile v1的基本模块采用了depthwise conv+pointwise conv降低计算复杂度。其重要贡献就是引入了深度可分离卷积。
mobilenet v2
经过大量实验发现,mobilenetv1容易训练出空卷积核。作者发现是relu叛变了。
作者发现将经过relu激活后的输入映射到高维,再利用逆矩阵回复,其结果发生了很大变化。

从上图可以看出,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
Linear bottleneck
为了降低relu对结果的影响,作者提出了linear bottleneck作为模型的基本模块。作者通过实验分析了低维relu回造成信息流失,所以我们首先对输入进行升维操作,即利用1×1卷积升维(激活relu6),然后再depthwise conv提取特征(激活relu6),最后pointwise conv降维(linear)。
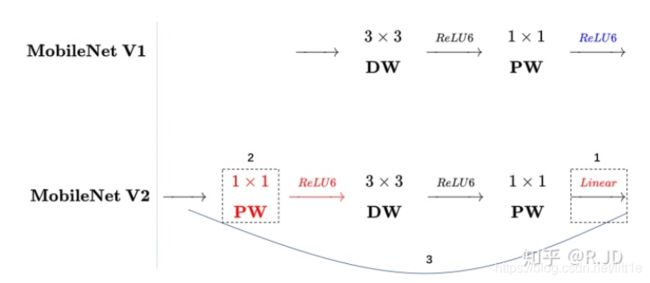
mobilenetv3
mobilenetv3主要是通过NAS搜索出来的,其变化主要包括:
0.网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好)
1.引入MobileNetV1的深度可分离卷积
2.引入MobileNetV2的具有线性瓶颈的倒残差结构
3.引入基于squeeze and excitation结构的轻量级注意力模型(SE)
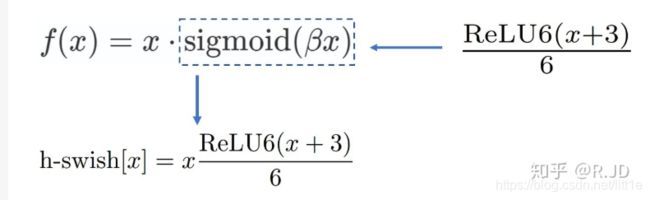
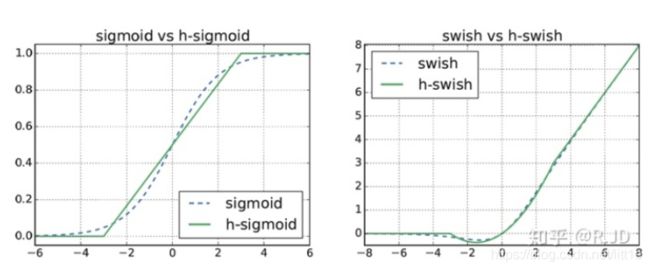
4.使用了一种新的激活函数h-swish(x)
5.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt
6.修改了MobileNetV2网络端部最后阶段
h-swish
Ghostnet
在一个训练好的深度神经网络中,通常会包含丰富甚至冗余的特征图,以保证对输入数据有全面的理解。如下图所示,在ResNet-50中,将经过第一个残差块处理后的特征图拿出来,三个相似的特征图对示例用相同颜色的框注释。 该对中的一个特征图可以通过廉价操作(用扳手表示)将另一特征图变换而获得,可以认为其中一个特征图是另一个的“幻影”。因为,本文提出并非所有特征图都要用卷积操作来得到,“幻影”特征图可以用更廉价的操作来生成。

ghost module
作者认为传统卷积提取的特征图中存在大量冗余特征,这些特征可以通过简单计算量低的操作获得。作者通过1×1的卷积获得primary conv features,再将primary conv features当作输入经过depthwise conv生成cheap conv features。下面给出pytorch的实现代码
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]