python语音处理_Python学习笔记--语音处理初步
python打开音频文件(IO)
语音音量大小与响度的相关计算
语音处理最基础的部分就是如何对音频文件进行处理。
声音的物理意义:声音是一种纵波,纵波是质点的振动方向与传播方向同轴的波。如敲锣时,锣的振动方向与波的传播方向就是一致的,所以声波是纵波。纵波是波动的一种(波动分为横波和纵波)
通常情况下对声音进行采样量化之后得到了声音的“时间—振幅”信息。
Python 打开wav文件的操作
wav文件
利用python打开一个wav音频文件,然后分析wav文件的数据存储格式,有了格式之后就能很方便的进行一些信号处理的操作。Wikipedia给出的wav文件的资料如下
Waveform Audio File Format (WAVE, or more commonly known as WAV due to its filename extension - both pronounced "wave"‘)(rarely, Audio for Windows) is a Microsoft and IBM audio file format standard for storing an audio bitstream on PCs. It is an application of the Resource Interchange File Format (RIFF) bitstream format method for storing data in "chunks", and thus is also close to the 8SVX and the AIFF format used on Amiga and Macintosh computers, respectively. It is the main format used on Windows systems for raw and typically uncompressed audio. The usual bitstream encoding is the linear pulse-code modulation (LPCM) format.
音频格式资料在网上也有一些标准格式的说明,比如WAVE PCM soundfile format http://soundfile.sapp.org/doc/WaveFormat/
当然大多数情况下,很需要对信息进行筛选的能力,在使用python来处理wav文件的时候仅仅需要其中的几个操作,并不一定要每个都掌握,在需要的时候查询文档。
注意
大段的文字来叙述wav音频文件是什么并不是作为编程练习的目的,人的精力是有限的不可能同时掌握所有的知识点。一开始,就学习声音的原理,然后再验证,这些工作应该是由搞信息编码的研究者来完成,而作为一个工程师应该集中精力研究代码上的复现。不如反其道行之,读取音频文件,根据系统提供的API获得各种参数,再去查询参数的信息。编程练习要思考怎么用一般在处理音频文件的时候。有个流程就是将音频文件导入,分析波形,进行傅里叶变换之类的操作,作为数据的预处理,才可以进行下一步数值数据的处理,其实音频处理最想要的过程无非如上所述。所以正常情况下,还要知道音频文件中的数据的含义,用计算机科学的思想分析就是需要知道它的数据结构。
音频文件信息
用到了python 处理wav文件的包 wave,读取wave 信息,遍历参数
importwave as we
filename= 'child1.wav'WAVE=we.open(filename)for item inenumerate(WAVE.getparams()):print(item)
查询官方文档中对于wave.getparams()的描述
Wave_read.getparams()
Returns a namedtuple() (nchannels, sampwidth, framerate, nframes, comptype, compname), equivalent to output of the get*() methods.
输出信息(声道,采样宽度,帧速率,帧数,唯一标识,无损)

采样点的个数为 2510762,采样的频率为44100HZ,通过这两个参数可以得到声音信号的时长
每个采样点是16 bit = 2 bytes ,那么将采样点的个数 2510762*2/(1024*1024)=4.78889MB,那么这个信息就是文件大小信息。
检验一下声音波形的时间
child1.wav 4.78MB,时长56s
time = 56.93337868480726
根据上面WAVE PCM soundfile format 的资料信息查询。有一个印象:WAV文件中由以下三个部分组成:
1."RIFF" chunk descriptor 2.The "fmt" sub-chunk 3.The "data" sub-chunk 存这些信息的时候都要要有 “ID”、“大小”、“格式”,这些信息标注了数据的位置,“WAV”格式由“fmt”和“data”,两个部分组成,其中“fmt”的存储块用来存音频文件的格式,“data”的存储块用来存实际听到的声音的信息,物理上描述的振幅和时间:长度(时间)和振幅,当然人的耳朵听听见的是长度和音调。也就是说可以读取这个数组,在配合频率的信息直接画出波形图。
注意一下几点
1.一个采样点的值代表了给定时间内的音频信号,一个采样帧由适当数量的采样点组成并能构成音频信号的多个通道。
2.对于立体声信号一个采样帧有两个采样点,一个采样点对应一个声道。一个采样帧作为单一的单元传送到数/模转换器(DAC),以确保正确的信号能同时发送到各自的通道中。
3.单声道振幅数据为n*1矩阵点,立体声为n*2矩阵点,那么将来文件的信息处理通过一个矩阵来实现
WAV文件波形
为了绘制波形图,需要的参数有时间和振幅的信息,完整的步骤如下:
1.将WAV文件导入到Python的工作环境中。
2.设置参数,声音信号(时间、振幅、频率)。
3.将这些信息通过 matplotlib.pyplot提供的接口绘画出来。
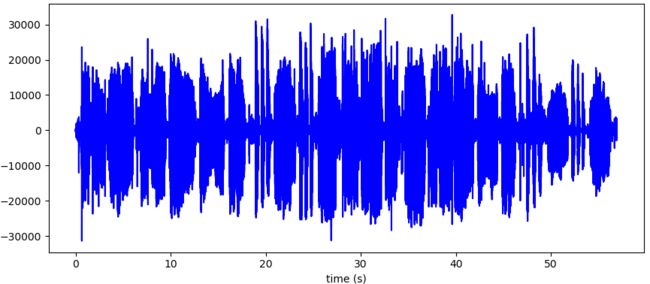
可以得到一个振幅随着时间变化的函数。
1 importwave as we2 importmatplotlib.pyplot as plt3 importnumpy as np4 from scipy.io importwavfile5
6 filename = 'child1.wav'
7 WAVE =we.open(filename)8 print('---------声音信息------------')9 for item inenumerate(WAVE.getparams()):10 print(item)11 a = WAVE.getparams().nframes #帧总数
12 f = WAVE.getparams().framerate #采样频率
13 sample_time = 1/f #采样点的时间间隔
14 time = a/f #声音信号的长度
15 sample_frequency, audio_sequence =wavfile.read(filename)16 print(audio_sequence) #声音信号每一帧的“大小”
17 x_seq =np.arange(0,time,sample_time)18
19 plt.plot(x_seq,audio_sequence,'blue')20 plt.xlabel("time (s)")21 plt.show()
WAV文件的存储格式
通过上述操作流程,了解了几个信息:
1.通过python现有包wave 可以获取wav文件几个基础信息,比如文件的声道,声音的采样宽度,帧速率,帧数,是否唯一标识,是否无损,关于WAV文件处理的入门信息,可先用几行代码获得WAV文件基本处理信息,然后将这些信息通过画图的形式绘画出来。
2.WAV文件中的时间,可以按照采样点数目,以及频率的大小获得,将来可以加窗口,进行数字信号处理上的一些操作,对声音信号作进一步的分析。
3.WAV文件中将声音信号存为n*1矩阵点或者n*2矩阵点,区分条件为是单声道还是双声道,对声音信号的研究可以转化为这个数组的研究。
声音信号的意义
常见的研究问题中,如果我们想要知道语音音量大小或者频率,即经常提到声音的物理意义:有声音的大小以及声音的频率。
a) 声音的响度
b) 声音的频率
关于语音信号,根据经验知道,只有声源发出声音超过一定的时间,或者声音够大才能被人耳感知,这个时候就需要类似一个采样窗口的概念。通过采样窗口来描述时间刻度,注意,前文提到了音频文件的采样率为$F_s$,表示麦克风每隔$1/F_s$秒,采样一个电平,如果$F_s=44100Hz$,那么表示时间间隔为$ 2.25\times 10^{-5} s$,播放N个采样点的时长为$N \times 1/F_s$,根据经验,只有这个时长超过20~40ms才能被人耳感知,也就是说需要有一定的时间上的“积分效应”。
声音的响度和能量有关,那么就可以根据上述描述,在根据精度在一定时长内采样,获得那个时刻能量。有关精度的计算和采样窗口有关,如果采样窗口为4096,窗口重叠为2048,那么采样后那个时刻的时长为$4096\times 1/F_s = 92.8ms$,时间步长(刻度或者称为精度)为 $2048 \times 1/F_s = 46.4ms $,此时声音的能量可以通过采样窗口内的振幅值的平方和描述那个时刻的能量大小:$\sum_{i=0}^{N}x^2(i)$,在经过Log的转换就是我们常见的,以DB为单位的刻度。
声音的频率即声音的周期性,只有一定时长的语音信号才具有周期性,当然在很多和音乐相关的文献中也说明了基音和泛音,大多数时候,声音的频率都是指的是基音,那么求基音的算法有很多。基音的原理主要是认为声音具有周期性,此时假设声音信号为$x(t)$,那么在加窗口采样后的那个时刻内,假设频率为$F$,那么周期为$T=1/F$,有$x(t+T)=x(t)$,此时只需要求出T即可,大多数算法都是基于以下的原理求出:
1) 信号每隔T个时刻都有一个波峰,如果考虑信号的延迟,在窗长为n的窗口内,内每隔$\tau, \tau=0,1,2,3,....,n$个延迟的采样信号为$x_{\tau}(t)$,当然$\tau$ 也不一定需要到n,$x_{\tau}(t) \times x(t)$,此时求出的波形对应的第一个波峰出现的位置,即$\tau$的取值就是基音对应的周期点的个数,周期为$T/Fs $s,此时的倒数就是频率。
2) 当然也有类似反过来的原理,$x(t+T)=x(t)$=>$x(t+T)-x(t)=0$,通过绝对值或者平方和,找到第一个零点的位置求解。
频率和帧能量求解例子
1)加窗口采样、得到帧级别的声音信号
import numpy as np
from scipy.signal import windows
# 分帧处理函数
def generate_frame_data(x, sr, win, overlap):
n_frames = 1 + int(len(x) / overlap)
y = np.zeros((win, n_frames))
x = np.pad(x, (0, n_frames * overlap + win - len(x)), 'constant', constant_values=0)
for n in range(n_frames):
y[:, n] = x[n * overlap:n * overlap + win]
time = np.arange(0, len(x)/sr,overlap/sr)
return y,time
2)短时帧能量和自相关函数
#自相关函数
def compute_acf(wave_data):
auto_corr_funtion = []
for item in wave_data:
auto_corr_funtion.append(compute_frame_acf(item))
return np.array(auto_corr_funtion)
# 计算帧能量
def compute_frame_ste(frame_data):
short_time_energy = np.sum(frame_data * frame_data, axis=0)
return short_time_energy[:-1]
3)计算频率
# 计算分帧之后的结果最大值
def comput_T0_acf(auto_corr_function):
T0 = np.argmax(auto_corr_function[:, 10:], axis=1)
return T0