NLP 自然语言处理实战
前言
自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,用于分析理解机器与人之间的交互,常用的领域有:实体识别、文本纠错、情感分析、文本分类、关键词提取、自动摘要提取等方面。
本文将从分词、词频、词向量等基础领域开始讲解自然语言处理的原理,讲解 One-Hot、TF-IDF、PageRank 等算法及 LDA、LDiA、LSA 等语义分析的原理。
介绍 Word2vec、GloVe 等常用词嵌入及 NLTK、Jieba 等分词工具的应用。
目录
一、自然语言处理的概念
二、分词器的原理及应用
三、词向量
四、文本相似度分析
五、通过主题转换进行语义分析
六、词嵌入的应用
一、自然语言处理的概念
1.1 自然语言处理的起源
语言是人类社会发展过程的产物,是最能体现人类智慧和文明的证明,也是人类与动物最大的区别。它是一种人与人交流的载体,像计算机网络一样,我们使用语言相互传递知识。在人类历史的几千年,语言不断地繁衍发展。
在计算机兴趣的近几十年,科学界正在试图不断努力,把人类的语言演变成分析数据特征的依据。在1970年,有两位美国人 Richard Bandler 和 John Grinder 因不满于传统心理学派的治疗过程冗长,及其效果常反复不定,而集合各家所长以及他们独特的创见,在美国加州大学内(NLP的发源地)利用课余时间开始研究。经过三年多的实验与练习,终于逐渐形成NLP神经语法程式学的基础架构。
随着近年来人工智能的崛起,自然语言处理(NLP)更成为一种专业分析人类语言智能工具,被应用到了多个层面:
(1)机器翻译
机器翻译是利用计算机将某一种语言文本自动翻译成另一种语言文本的方法,它基于语言规则,利用统计的统计原理进度混合计算,得出最终结果。最常见于百度翻译、金山 iciba 翻译、有道翻译、google 翻译等。
(2)自动问答
自动问答通过计算机对人提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并做出相应的回答。它利用语词提取、关键字分析、摘要分析等方式提取问题的核心主干,然后利用 NLP 分析数据选择出最合适的答案。常见的例子有在线问答 ask.com、百度知道、yahoo 回答等。
(3)语音处理
语言处理(speech processing)可以把将输入语音信号自动转换成书面文字或计算机命令,然后对任务进行操作处理。常见的应用场景有汽车的语言识别、餐厅智能点餐、机场火车站的智能预订航班、智能机器人等。
(4)情感分析
从大量文档中检索出用户的情感方向,对商品评价、服务评价等的满意进行分析,对用户进行商品服务推荐。在京东、淘宝等各大的购物平台很常用。
1.2 自然语言处理的阶段
自然语言实现一般都通过以下几个阶段:文本读取、分词、清洗、标准化、特征提取、建模。首先通过文本、新闻信息、网络爬虫等渠道获取大量的文字信息。然后利用分词工具对文本进行处理,把语句分成若干个常用的单词、短语,由于各国的语言特征有所区别,所以NLP也会有不同的库支撑。对分好的词库进行筛选,排除掉无用的符号、停用词等。再对词库进行标准化处理,比如英文单词的大小写、过去式、进行式等都需要进行标准化转换。然后进行特征提取,利用 tf-idf、word2vec 等工具包把数据转换成词向量。最后建模,利用机器学习、深度学习等成熟框架进行计算。

下面将对这几个处理流程进行逐一介绍。
二、分词器的原理及应用
| 2.1 分词器的基本原理 在自然语言处理的过程中,把切分文件是流水线的第一步,它能够把文本拆分为更小的文本块或词语片段多块信息,每块信息都可以被看成是一个元素,这此元素出现的频率可以直接被看作为文本的向量。 data='NLP stands for Natural Language Processing.' data.split() 结果 ['NLP', 'stands', 'for', 'Natural', 'Language', 'Processing.'] 你可能已经看到,直接对语句进行拆分可以会把标点符号 ‘ . ’ 也带进数组。还有一些无用的操作符 ‘. ?!’ 等,最后势必会影响输出的结果。想要实现这类最简单的数据清洗,可以使用正则表达式来解决。 data='NLP is the study of excellent communication–both with yourself, and with others.' data=re.split(r'[-\s.?,!]',data) 当想去除一些无用的停用词(例如 'a,A' )、对词库进行标准化处理(例如词干还原,把进行式 building 转化成 build,把过去式 began 转化为 begin) 还有大小写转换时,可以使用成熟的库来完成。 多国的语言都有差异,所以分词器的处理方式也有区别,下面将介绍英语单词与中文词汇比较常用的分词器 NLTK 和 Jieba 。 |
|

2.2 NLTK 库基础功能介绍
NLTK 使用 Python 程序编写,它提供了一套用于分类,标记化,词干化,标记,解析和语义推理的文本处理库,相关的模块如下。

2.2.1 分句 SentencesSegment
例如有一段文本里面包含三个句子,希望把它分成一个一个的句子。此时可以使用NLTK中的 punktsentencesegmenter。
1 sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
2 paragraph = "The first time I heard that song was in Hawaii on radio. ”+
3 "I was just a kid, and loved it very much! What a fantastic song!"
4 sentences = sent_tokenizer.tokenize(paragraph)
5 print(sentences)
运行结果
['The first time I heard that song was in Hawaii on radio.',
'I was just a kid, and loved it very much!',
'What a fantastic song!']
2.2.2 分词 WordPunctTokenizer
1 from nltk.tokenize import WordPunctTokenizer 2 sentence = "Are you old enough to remember Michael Jackson attending ”+ 3 “the Grammys with Brooke Shields and Webster sat on his lap during the show?" 4 words = WordPunctTokenizer().tokenize(sentence) 5 print(words)
运行结果
['Are', 'you', 'old', 'enough', 'to', 'remember', 'Michael', 'Jackson', 'attending',
'the', 'Grammys', 'with', 'Brooke', 'Shields', 'and', 'Webster', 'sat', 'on', 'his',
'lap', 'during', 'the', 'show', '?']
2.2.3 正则表达式 RegexpTokenizer
最简单的方法去掉一些从文档中存在的 \n \t 等符号
1 from nltk.tokenize import RegexpTokenizer 2 sentence='Thomas Jefferson began \n building \t Monticello at the age of 26.' 3 tokenizer=RegexpTokenizer(r'\w+|$[0-9.]+|\S+') 4 print(tokenizer.tokenize(sentence))
运行结果
['Thomas', 'Jefferson', 'began', 'building', 'Monticello', 'at', 'the', 'age', 'of', '26', '.']
2.2.4 分词 TreebankWordTokenizer
TreebankWordTokenizer 拥有比 WordPunctTokenizer 更强大的分词功能,它可以把 don't 等缩写词分为[ "do" , " n't " ]
1 from nltk.tokenize import TreebankWordTokenizer 2 sentence="Sorry! I don't know." 3 tokenizer=TreebankWordTokenizer() 4 print(tokenizer.tokenize(sentence))
运行结果
['Sorry', '!', 'I', 'do', "n't", 'know', '.']
2.2.5 词汇统一化
2.2.5.1 转换大小写
词汇统一化最常用的就是把大小进行统一化处理,因为很多搜索工具包都会把大小写的词汇例如 City 和 city 视为不同的两个词,所以在处理词汇时需要进行大小写转换。当中最简单直接的方法就是直接使用 str.lower() 方法。
2.2.5.2 词干还原
当单词中存在复数,过去式,进行式的时候,其词干其实是一样的,例如 gave , giving 词干都是 give 。相同的词干其实当中的意思是很接近的,通过词干还原可以压缩单词的数据,减少系统的消耗。NLTK 中提供了 3 个常用的词干还原工具:porter、lancaster、snowball ,其使用方法相类似,下面用 porter 作为例子。可以 playing boys grounded 都被完美地还原,但对 this table 等单词也会产生歧义,这是因为被原后的单词不一定合法的单词。
1 from nltk.stem import porter as pt 2 3 words = [ 'wolves', 'playing','boys','this', 'dog', 'the', 4 'beaches', 'grounded','envision','table', 'probably'] 5 stemmer=pt.PorterStemmer() 6 for word in words: 7 pt_stem = stemmer.stem(word) 8 print(pt_stem)
运行结果

2.2.5.3 词形并归
想要对相同语义词根的不同拼写形式都做出统一回复的话,那么词形归并工具就很有用,它会减少必须要回复的词的数目,即语言模型的维度。例如可以 good、goodness、better 等都归属于同一处理方式。通过wordnet.lemmatize(word,pos) 方法可指定词性,与常用的英语单词类似,n 为名词 v为动词 a为形容词等等。指定词性后还可以通过posterStemmer.stem() 还原词干。
1 stemmer=PorterStemmer()
2 wordnet=WordNetLemmatizer()
3 word1=wordnet.lemmatize('boys',pos='n')
4 print(word1)
5
6 word2=wordnet.lemmatize('goodness',pos='a')
7 word2=stemmer.stem(word2)
8 print(word2)
运行结果

2.2.6 停用词
在词库中往往会存在部分停用词,使用 nltk.corpus.stopwords 可以找到 NLTK 中包含的停用词
1 stopword=stopwords.raw('english').replace('\n',' ')
2 print(stopword)
运行结果

通过对比可以对文件中的停用词进行过滤
1 words = [ 'the', 'playing','boys','this', 'dog', 'a',]
2 stopword=stopwords.raw('english').replace('\n',' ')
3 words=[word for word in words if word not in stopword]
4 print(words)
运行结果
['playing', 'boys', 'dog']
2.2.3 把词汇扩展到 n-gram
上面例子中基本使用单个词作用分词的方式,然而很多短语例如:ice cream,make sense,look through 等都会多个单词组合使用,相同的单词在不同的短语中会有不同的意思。因此,分词也需要有 n-gram 的能力。针对这个问题 NTLK提供了 ngrams 函数,它可以按实现 2-gram、3-gram等多类型的元素划分。
1 sentence='Build the way that works best for you '+\ 2 'with support for all your go-to integrations '+\ 3 'including Slack Jira and more.' 4 words=sentence.split() 5 print(list(ngrams(words,2)))
运行结果

2.3 Jieba 库基础功能介绍
NLTK 库有着强大的分词功能,然而它并不支中文,中文无论从语法、格式、结构上都有很大的差别,下面介绍一个常用的中文库 Jieba 的基础功能。
2.3.1 分词 jieba.cut
jieba.cut 是最常用的分词方法,返回值为 generator。jieba.lcut 与 jieba.cut 类似,区别在于 jieba.lcut 直接返回 list。在数据量比较大时,jieba.cut 会更节省内存。
1 def cut(self, sentence, cut_all=False, HMM=True, 2 use_paddle=False):
- sentence 可为 unicode 、 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
- 当 cut_all 返回 bool,默认为 False。当 True 则返回全分割模式,为 False 时返回精准分割模式。
- HMM 返回 bool,默认为 True,用于控制是否使用 HMM 隐马尔可夫模型。
- use_paddle 返回 bool, 默认为 False, 用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词,同时支持词性标注。
使用例子
1 sentence='嫦娥四号着陆器地形地貌相机对玉兔二号巡视器成像' 2 word1=jieba.cut(sentence,False) 3 print(list(word1)) 4 word2=jieba.cut(sentence,True) 5 print(list(word2))
运行结果

2.3.2 搜索分词 jieba.cut_for_search
jieba.cut_for_search 与 jieba.cut 精确模式类似,只是在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,返回值为 generator。jieba.lcut_for_search 与 jieba.cut_for_search 类似,但返回值为 list。
1 def cut_for_search(self, 2 sentence: Any, 3 HMM: bool = True) -> Generator[str, Any, None]
- sentence 可为 unicode 、 UTF-8 字符串、GBK 字符串。
- HMM 返回 bool,默认为 True,用于控制是否使用 HMM 隐马尔可夫模型。
使用例子
1 word1=jieba.cut_for_search('尼康Z7II是去年底全新升级的一款全画幅微单相机',False)
2 print(list(word1))
3 word2=jieba.cut_for_search('尼康Z7II是去年底全新升级的一款全画幅微单相机',True)
4 print(list(word2))
运行结果

2.2.3 载入新词 jieba.load_userdict
通过此方法可以预先载入自定义的用词,令分词更精准。文本中一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
例如:设定 word.txt 文本
阿里云 1 n
云计算 1 n
1 word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 print(list(word1))
3 jieba.load_userdict('C://Users/Leslie/Desktop/word.txt')
4 word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
5 print(list(word2))
运行结果

2.2.4 动态调节词典
通过 jieba.add_word 和 jieba.del_word 这两个方法也可以动态地调节词典
1 def add_word(self, word, freq=None, tag=None):
jieba.add_word 可以把自定义词加入词典,当中 freq 为词频,tag 为词性。
1 def del_word(self, word):
相反,通过 jieba.del_word 可以动态删除加载的自定义词
1 word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 print(list(word1))
3 jieba.add_word('阿里云')
4 jieba.add_word('云计算')
5 word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
6 print(list(word2))
7 jieba.del_word('阿里云')
8 word3=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
9 print(list(word3))
运行结果

2.2.5 词节词频 jieba.suggest_freq
此方法可调节单个词语的词频,使其能(或不能)被分出来。注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
1 def suggest_freq(self, segment, tune=False):
下面的例子就是把 “阿里云” 这个词拆分的过程
word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
print(list(word1))
jieba.suggest_freq('阿里云',True)
word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司',False,False)
print(list(word2))
jieba.suggest_freq(('阿里','云'),True)
word3=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司',False,False)
print(list(word3))
运行结果

2.2.6 标注词性 jieba.posseg
通过 posseg.cut 可以查看标注词性,除此以外还可以 jieba.posseg.POSTokenizer 新建自定义分词器
1 words=jieba.posseg.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 for word,flag in words:
3 print(word,flag)
运行结果

2.2.7 使用 jieba 计算词频
下面例子介绍一下如何使用 jieba 计算一篇文章的词频,首先读取文章内容,进行去标点处理,然后动态加入常用词,使用 jieba.lcut 方法进行分词。最后读取停用词,把文章的分词集合进行过滤,对每个词的词频进行计算。
1 def readFile():
2 # 读取文件
3 file=open('C://Users/Leslie/Desktop/word.txt','r',102400,'utf8').read()
4 # 去标点
5 text=re.sub('[·。,\’!\"\#$%&\'()#!()*+,-./:;<=>?\@,:?¥★、….>【】[]《》?\“\”\‘\’\[\\]^_`{|}~]+'
6 ,'',file)
7 # 加入常用词
8 jieba.add_word('云计算')
9 ......
10 # 利用 Jieba 分词
11 words=jieba.lcut(text)
12 print('总词数:{0}'.format(len(words)))
13 return words
14
15 def stopWord():
16 # 读取停用词
17 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8')
18 .readlines()]
19 return stopword
20
21 def wordFrequency():
22 # 获取文章的词
23 fileWords=readFile()
24 # 获取停用词
25 stopWords=stopWord()
26 words={}
27 # 计算词频
28 for word in fileWords:
29 if word not in stopWords:
30 if word not in words:
31 words[word]=1
32 else:
33 words[word]+=1
34 print('单词数: {0}'.format(len(words)))
35 return words
36
37 if __name__=='__main__':
38 words=wordFrequency()
39 for item in words.items():
40 print(item)
运行结果

三、词向量
完成分词的工作后,在进行运算前,先要对数据进行向量化,常用的词向量有 one-hot 独热向量、 tf-idf 向量和 embedding 词嵌入等,下面将进一步介绍。
3.1 one-hot 独热向量
one-hot 独热向量是比较容易理解的一种词向量,它是把词汇表中的词的数量与词位置都进行记录,每个语句中所有信息都没有丢失,这也是 one-hot 的优点。
下面的例子先将词句按照原顺序进行分词,分词完成后,[1 0 0 0 0 0 0 0] 为第一个词 “珠穆朗玛峰”,[0 1 0 0 0 0 0 0] 为每二个词 “上”,如此类推。
然后把词组进行重排列作用测试数据 ['上', '如此', '星空', '是', '珠穆朗玛峰', '的', '的', '迷人'],查看测试数据的 one-hot 向量。
通过测试结果可以看过,one-hot 对数据进行了全面记录,测试数据中每个词出现的顺序和次数都被完整地记录下来。
1 def getWords():
2 # 对句子进行分词
3 sentence='珠穆朗玛峰上的星空是如此的迷人'
4 words=jieba.lcut(sentence)
5 print('【原始语句】:{0}'.format(sentence))
6 print('【分词数据】:{0}'.format(words))
7 return words
8
9 def getTestWords():
10 # 把词集进行重新排序后作为测试数据
11 words=getWords().copy()
12 words.sort()
13 print('【测试数据】:{0}'.format(words))
14 return words
15
16 def one_hot_test():
17 # 获取分词后数据集
18 words=getWords()
19 # 获取测试数据集
20 testWords=getTestWords()
21 size=len(words)
22 onehot_vectors=np.zeros((size,size),int)
23 # 获取测试数据 one_hot 向量
24 for i,word in enumerate(testWords):
25 onehot_vectors[i,words.index(word)]=1
26 return onehot_vectors
27
28 if __name__=='__main__':
29 print(one_hot_test())
运行结果

通过结果可以看出每一行都只会有一个为非零值,估计这也是把此方法称作 one-hot 的原因,这样看起来虽然很直观,但是也浪费了很多的数据空间。一个简单的句子已经要使用 8*8 的数组,当使用大量训练数据时,比如 500 篇 3000 字的文章,常用的文字就有2000个,常用词可能会有 18000 个,模型所要耗费的存储资源将会成指数级的提升,所以这方法的实用性比较低。
3.2 TF-IDF 向量
为了克服 one-hot 向量的弱点,设计出了一个新的向量表示方法 TF-IDF 向量。TF-IDF(term frequency–inverse document frequency) 是一种用于信息检索与数据挖掘的常用加权技术,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
TF-IDF 不再关注分词出现的顺序而是更关注其出现的频率和次数。它由 TF 和 IDF 两部分组成,TF 是统计一个词在一篇文章中的出现频次。IDF 则统计一个词在文件集中的多少个文件出现。统计后字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
3.2.1 TF 词频
TF 词频是代表词在单篇文章中出现的频率,为了更好理解 TF ,举一个例子。假如在第一篇 1000 个总词数的文章,“ 云计算 ” 这个词出现了 50 次,那 TF 为 50 / 1000 ,即 0.05 。而在第二篇有 10000 个总词数的文章,“ 云计算 ” 出现了100 次,那 TF 为 100 / 10000,即 0.01。如此类推,下面是 TF 的计算公式:
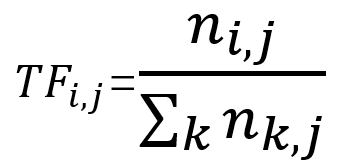
当中 ni,j 代表词 i 在文章 j 中出现的频次,而分母 nk,j 则代表文章 j 中的每个词出现的次数的总和。
3.2.2 IDF 逆文本频率
而 IDF 逆文本频率指数是代表词语在文档中的稀缺程度,它等总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到 。例如有 1000 篇文件,其中有 30 篇包含了 “向量” 这个词,那 IDF 为 log(1000 / 30),考虑到当文件不存这个词时分母会为 0,所以默认情况下会为分母加 1,即 log (1000 / 30 +1)。如此类推,下面是 IDF 的计算公式:

当中 D 代表所有文章的总数,Di 代表出现词 i 的文章数,为了避免词库中某些词在文章中没有出现过而造成分母为 0 的现象,所以把分母作加 1 处理。
3.2.3 TF-IDF 计算
TF-IDF 顾名思义就是代表 TF 与 IDF 的乘积
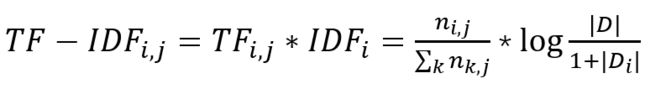
下面例子说明一下 TF-IDF 的计算方式,首先遍历文件夹里的所有文件,找到分词后进行 stopword 过滤,然后得到分词的集合 wordKeys。
根据分词集合 wordKeys 计算每篇文章中所包含的分词数量 wordsValues,在此显示一下这个分词值。
最后根据 TF-IDF 计算公式计算 TF-IDF ,显示计算结果。从计算结果可以看出,分词数量最多的值往往是负值,这里因为 IDF 计算中包含此词的文件数会跟 IDF 成反比。由于测试文件都是在网上下载关于 "云计算” 相关的论文,所以 “云计算” 这些分词的 TF-IDF 为负值。
1 # 分词集合
2 wordKeys=[]
3 # 每个分词的数量集合
4 wordValues=[]
5 # 每篇文章的词量总数
6 totalCounts=[]
7 # tdidf 值
8 tdidf = []
9
10 def readFile(filepath):
11 # 读取文件
12 file=open(filepath,'r',102400,'utf8').read()
13 # 去标点
14 text=re.sub('[·。,\’!\"\#$%&\'()#!()*+,-./:;<=>?\@,:?¥★、….>【】[]《》?\“\”\‘\’\[\\]^_`{|}~]+'
15 ,'',file)
16 # 加入常用词
17 jieba.add_word('云计算')
18 # ...
19 # 利用 Jieba 分词
20 words=jieba.lcut(text)
21 return words
22
23 def stopWord():
24 # 读取停用词
25 stopword=[line.strip() for line in open('../stopword.txt','r',1024,'utf8')
26 .readlines()]
27 stopword.append('\n')
28 stopword.append(' ')
29 stopword.append('\u200b')
30 return stopword
31
32 def getFilePath():
33 # 读取目录下所有文件路径
34 dir=os.walk('../files')
35 filePath=[]
36 for path,index,files in dir:
37 for file in files:
38 _path=os.path.join(path,file)
39 filePath.append(_path)
40 return filePath
41
42 def getKeys():
43 readData=[]
44 # 获取文件路径
45 filePath=getFilePath()
46 # 获取停用词
47 stopWords = stopWord()
48 # 读取所有文本的词
49 for file in filePath:
50 readData=readData+readFile(file)
51 # 过滤停用词
52 for word in readData:
53 if word not in stopWords and word not in wordKeys:
54 wordKeys.append(word)
55
56 def getValues():
57 # 获取文件路径集合
58 filePath=getFilePath()
59 # 行 index
60 index=0
61 for file in filePath:
62 # 行值
63 values = []
64 # 记录每个文档的分词总数
65 totalCount=0
66 # 获取分词
67 words=readFile(file)
68 # 获取每篇文章的分词数量
69 counts=Counter(words)
70 for key in wordKeys:
71 if key in counts.keys():
72 values.append(counts[key])
73 totalCount+=counts[key]
74 else:
75 values.append(0)
76 # 插入行
77 wordValues.insert(index,values)
78 totalCounts.append(totalCount)
79 index+=1
80
81 def getTFIDF():
82 list = np.array(wordValues)
83 # 分行计算
84 for index in range(0,len(wordValues)):
85 col=0
86 row=[]
87 # 分别计算 TF 值与 IDF 值
88 for value in wordValues[index]:
89 # 计算 TF 值
90 tf=value / totalCounts[index]
91 # 获取当前列的集合
92 cols=list[:,col]
93 # 计算有多少篇文档包含当前分词
94 nonzerocount=np.count_nonzero(cols)
95 # 计算 IDF
96 idf=np.log10(len(list)/(nonzerocount+1))
97 # 计算 TFIDF 把计算结果加入集合
98 row.append(tf*idf)
99 col+=1
100 # 插入行
101 tdidf.insert(index,row)
102 index+=1
103
104 if __name__=='__main__':
105 getKeys()
106 getValues()
107 # 查看过滤后每个分词在每篇文章中的数量
108 dataset=pd.DataFrame(wordValues,columns=wordKeys)
109 print(dataset.head(3))
110 # 查看计算后的 TFIDF 值
111 getTFIDF()
112 tfidfSet=pd.DataFrame(tdidf,columns=wordKeys)
113 print(tfidfSet.head(3))
运行结果

3.3 TfidfVectorizer 简介
上面例子通过 python 手动实现 TF-IDF 的计算,其实在 sklearn 中已有 TfidfVectorizer 类支持 TF-IDF 运算,它包含大量的常用方法,使计算起来变得特别简单,下面简单介绍一下。
1 class TfidfVectorizer(CountVectorizer): 2 @_deprecate_positional_args 3 def __init__(self, *, input='content', encoding='utf-8', 4 decode_error='strict', strip_accents=None, lowercase=True, 5 preprocessor=None, tokenizer=None, analyzer='word', 6 stop_words=None, token_pattern=r"(?u)\b\w\w+\b", 7 ngram_range=(1, 1), max_df=1.0, min_df=1, 8 max_features=None, vocabulary=None, binary=False, 9 dtype=np.float64, norm='l2', use_idf=True, smooth_idf=True, 10 sublinear_tf=False):
参数说明
- input:str 类型 {'filename', 'file', 'content'},输入值。 如果是'filename',序列作为参数传递给拟合器,预计为文件名列表,这需要读取原始内容进行分析; 如果是'file',序列项目必须有一个”read“的方法(类似文件的对象),被调用作为获取内存中的字节数; 也可直接输入预计为序列串,或字节数据项都预计可直接进行分析。
- encoding:str 类型,编码类型,默认为 ‘utf-8’by default
- decode_error: str 类型 {'strict', 'ignore', 'replace'} 三选一,默认为 ' strict' 表示UnicodeDecodeError将提高。 参数表示如果一个给出的字节序列包含的字符不是给定的编码,指示应该如何去做。
- strip_accents: str 类型 {'ascii', 'unicode', None} 三选一,默认为 ' None' 。在预处理步骤中去除编码规则(accents),”ASCII码“是一种快速的方法,仅适用于有一个直接的ASCII字符映射,"unicode"是一个稍慢一些的方法,None(默认)什么都不做
- lowercase: bool 类型,默认为 True,执行前把字母变为小写
- preprocessor:callable or None,默认为None,当保留令牌和”n-gram“生成步骤时,覆盖预处理(字符串变换)的阶段
- tokenizer:callable or None 默认为 default, 当保留预处理和n-gram生成步骤时,覆盖字符串令牌步骤
- analyzer:str类型 {'word', 'char'} or callable 定义特征为词(word)或n-gram字符,如果传递给它的调用被用于抽取未处理输入源文件的特征序列
- stop_words:{'english'} 或 list, 默认为 None。english,用于英语内建的停用词列表。list,该列表被假定为包含停用词,列表中的所有词都将从令牌中删除。None,不使用停用词。max_df可以被设置为范围 [0.7, 1.0) 的值,基于内部预料词频来自动检测和过滤停用词
- token_pattern:str类型,默认为 r"(?u)\\b\\w\\w+\\b"。正则表达式显示了”token“的构成,仅当analyzer == ‘word’时才被使用。两个或多个字母数字字符的正则表达式(标点符号完全被忽略,始终被视为一个标记分隔符)。
- ngram_range: tuple(min_n, max_n),默认为 (1,1)。要提取的n-gram的n-values的下限和上限范围,在min_n <= n <= max_n区间的n的全部值
- max_df: float in range [0.0, 1.0] or int, optional, 默认值为 1.0 。当构建词汇表时,严格忽略高于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
- min_df:float in range [0.0, 1.0] or int, optional, 默认为 1.0 。当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
- max_features: optional,默认为 None 。如果不为 None,构建一个词汇表,仅考虑 max_features 按语料词频排序,如果词汇表不为None,这个参数被忽略
- vocabulary:Mapping or iterable, optional 默认为 None。 一个映射(Map)(例如,字典),其中键是词条而值是在特征矩阵中索引,或词条中的迭代器。如果没有给出,词汇表被确定来自输入文件。在映射中索引不能有重复,并且不能在0到最大索引值之间有间断。
- binary:bool类型,默认为 False。 如果为 True,所有非零计数被设置为1,这对于离散概率模型是有用的,建立二元事件模型,而不是整型计数
- dtype:type,默认为 np.float 64 。通过fit_transform()或transform()返回矩阵的类型
- norm:'l1', 'l2', or None,默认为 ’l2'。范数用于标准化词条向量。None为不归一化
- use_idf:bool,默认为 True。是否 启动 inverse-document-frequency重新计算权重
- smooth_idf:bool 默认为 True。通过加1到文档频率平滑idf权重,为防止除零,加入一个额外的文档
- sublinear_tf:bool默认为 False。是否应用线性缩放TF,例如,使用1+log(tf)覆盖 tf
常用方法
- fit(self, raw_documents, y=None): 表示用数据 raw_documents 来训练模型。
- transform(selft ,raw_documents):将数据 raw_documents 使用通过学习的词汇和文档频率进行运算。通过与 fit 同用,先调用 fix,当模型训练好后,再使用 transform 方法来运算。
- fit_transform(self, raw_documents, y=None): 相当于结合了 fit 与 transform 两个方法。用 raw_documents 来训练模型,同时返回运算后的数据。
- inverse_transform(self, X):将运算后的数据转换成为原始数据。
TfidfVectorizer 模型可以直接通过 fit_transform 方法直接计算出 TF-IDF 向量,无需进行繁琐的公式运算。还可在建立模型时设置如停用词,n-gram,编码类型等多个常用的运算条件。
1 corpus = [
2 'In addition to having a row context',
3 'Usually a smaller text field',
4 'The TFIDF idea here might be calculating some rareness of words',
5 'The larger context might be the entire text column',
6 ]
7
8 def stopWord():
9 # 读取停用词
10 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8')
11 .readlines()]
12 return stopword
13
14 def tfidfVectorizerTest():
15 words=corpus
16 #建立tfidf模型
17 vertorizer=tfidfVectorizer(stop_words=stopWord(),ngram_range=(1,2))
18 #训练与运算
19 model=vertorizer.fit_transform(words)
20 #显示分词
21 print(vertorizer.vocabulary_)
22 #显示向量
23 print(model)
24
25 if __name__=='__main__':
26 tfidfVectorizerTest()
运行结果
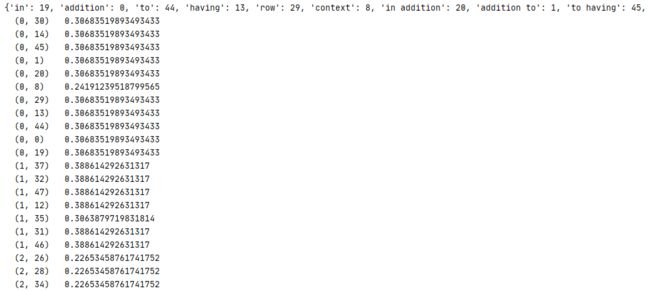
TfidfVectorizer 毕竟是针对外语单词格式所设计,所以用到中文时需要把句子转换成类似外语的格式。行利用 jieba 先进行分词,然后重新组合成句子,在每个分词后加上空格。
1 corpus = [
2 '北京冬奥会完美落下帷幕',
3 '冬奥生态内容方面的表现给用户留下深刻印象',
4 '全平台创作者参与冬奥内容创作',
5 '此次冬奥会对于中国是一次重要的里程碑时刻',
6 ]
7
8 def stopWord():
9 # 读取停用词
10 stopword=[line.strip() for line in open('C://Users/Leslie/Desktop/stopword.txt','r',1024,'utf8')
11 .readlines()]
12 return stopword
13
14 def getWord():
15 # 转换集合格式后再进行分词
16 list=[jieba.lcut(sentence) for sentence in corpus]
17 # 在每个词中添加空格符
18 word=[' '.join(word) for word in list]
19 return word
20
21 def tfidfVectorizerTest():
22 words=getWord()
23 # 打印转换格式后的分词
24 print(str.replace('格式转换:{0}\n'.format(words),',','\n\t\t'))
25 # 建立模型
26 vertorizer=tfidfVectorizer(stop_words=stopWord())
27 # 模型训练
28 model=vertorizer.fit_transform(words)
29 print('分词:{0}\n'.format(vertorizer.vocabulary_))
30 print(model)
31
32 if __name__=='__main__':
33 tfidfVectorizerTest()
运行结果

3.4 浅谈 PageRank 算法
除了 TF-IDF 算法,还有一种较为常用的 PageRank 算法。它是由 Mihalcea 与 Tarau于提出,其思想与 TF-IDF 有所区别,它是通过词之间的相邻关系构建网络,然后用迭代计算每个节点的 rank 值,排序 rank值即可得到关键词。公式如下,其中 PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合,d为damping factor用于做平滑,其原理在此暂不作详细讲解。
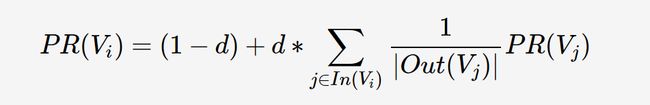
TextRank 算法与 TF-IDF 算法均严重依赖于分词结果,如果某词在分词时被切分成了两个词,那么在做关键词提取时无法将两个词黏合在一起(TextRank有部分黏合效果,但需要这两个词均为关键词)。因此是否添加标注关键词进自定义词典,将会造成准确率、召回率大相径庭。TextRank 虽然考虑到了词之间的关系,但是仍然倾向于将频繁词作为关键词,其效果并不一定优于 TF-IDF。
四、文本相似度分析
4.1 余弦相似度定义
完成分词后利用 TF-IDF 算法把分词成功转换成向量,便可以开始对向量进行计算,最常用的方法是余弦相似度计算。为了更好地理解,假设在二维空间有向量 doc1(x1,y1)和 向量doc2 (x2, y2),可以简单地理为分词 word1,word2 在 doc1 中的词频为 x1, y1,在 doc2 中的词频为 x2, y2。

根据欧几里得点积公式
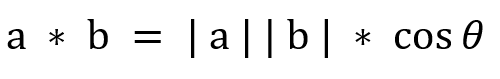
可推算出余弦相似度计算公式
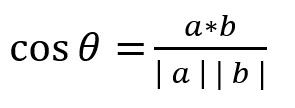
当值越大时证明相似度越高,当值越小时证明相似度越低。
在此例子中可以理解为当两个分词 word 1, word2 在 doc1 ,doc2 的词频非常接近时,两篇文章的内容被视为非常相似。
当余弦相似度为0时,相当于 doc1 只含有 word 1,而 doc2 只含有 word2,则被视作向量之间没有任何相似成分。当余弦相似度为 -1 时,则意味着方向正好相反。
现实应用中每篇文章肯定不止两个分词,根据同样道理,可以把多维度的计算公式扩展如下
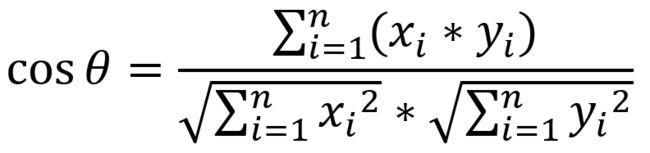
4.2 余弦相似度计算
在 sklearn.metrics.pairwise 中提供了余弦相似度计算的函数 cosine_similarity 和余弦距离计算函数 cosine_distances 可以通过简单的运算计算出余弦相信度
4.2.1 cosine_similarity 函数
1 def cosine_similarity(X, Y=None, dense_output=True):
当中 X 代表第一个对比值,Y 代表第二个对比值,若 Y 为 None 时则会对 X 输入的数组作相似性对比。
当 dense_output 为True 则无论输入是否稀疏,都将返回密集输出。若 dense_output 为 False 时,如果两个输入数组都是稀疏的,则输出是稀疏的。
1 x0=np.array([0.895,0.745]).reshape(1,-1)
2 y0=np.array([0.568,0.445]).reshape(1,-1)
3 similarity0=cosine_similarity(x0,y0)
4 print('similarity0 is:\n{0}\n'.format(similarity0))
5
6 x1=np.arange(4).reshape(2,2)
7 similarity1=cosine_similarity(x1)
8 print('similarity1 is:\n{0}\n'.format(similarity1))
9
10 x2=np.arange(10).reshape(2,5)
11 y2=np.arange(15).reshape(3,5)
12 similarity2=cosine_similarity(x2,y2)
13 print('similarity2 is:\n{0}\n'.format(similarity2))
运行结果

4.2.2 cosine_distances 函数
1 def cosine_distances(X, Y=None):
cosine_distances 用法与 cosine_similarity 类似,只是 cosine_distances 返回的是余弦的距离,余弦相似度越大,余弦距离越小
1 x0=np.array([0.895,0.745]).reshape(1,-1)
2 y0=np.array([0.568,0.445]).reshape(1,-1)
3 distances0=cosine_distances(x0,y0)
4 print('distances0 is:\n{0}\n'.format(distances0))
5
6 x1=np.arange(4).reshape(2,2)
7 distances1=cosine_distances(x1)
8 print('distances1 is:\n{0}\n'.format(distances1))
9
10 x2=np.arange(10).reshape(2,5)
11 y2=np.arange(15).reshape(3,5)
12 distances2=cosine_distances(x2,y2)
13 print('distances2 is:\n{0}\n'.format(distances2))
运行结果

4.3 文本相似度计算
根据余弦相似度,可以对 TF-IDF 向量进行比较,计算出文本之间的关联度。此原理常被广泛应用于聊天机器人,车机对话,文本自动回复等领域。先预设多个命令与回复,计算出 TF-IDF 向量,然后把输入的命令 TF-IDF 向量与预设命令的 TF-IDF 向量进行对比,找出相似度最高的命令,最后输出相关的回复。
下面以车机系统为例子,说明一下文本相似度计算的应用。command 代表多个车机的预设命令与回复数组,先通过 jieba 把中文命令转化为相关格式,对 TfidfVectorizer 模型进行训练。然后分别计算 command 预计命令的 TF-IDF 向量和 inputCommand 输入命令的 TF-IDF 向量。通过余弦相似度对比,找到相似度最高的命令,最后输出回复。
1 # 车机的命令与回复数组
2 command=[['请打开车窗','好的,车窗已打开'],
3 ['我要听陈奕迅的歌','为你播放富士山下'],
4 ['我好热','已为你把温度调到25度'],
5 ['帮我打电话给小猪猪','已帮你拨小猪猪的电话'],
6 ['现在几点钟','现在是早上10点'],
7 ['我要导航到中华广场','高德地图已打开'],
8 ['明天天气怎么样','明天天晴']
9 ]
10
11 # 利用 jieba 转换命令格式
12 def getWords():
13 comm=np.array(command)
14 list=[jieba.lcut(sentence) for sentence in comm[:,0]]
15 words=[' '.join(word) for word in list]
16 return words
17
18 # 训练 TfidfVectorizer 模型
19 def getModel():
20 words=getWords()
21 vectorizer=TfidfVectorizer()
22 model=vectorizer.fit(words)
23 print(model.vocabulary_)
24 return model
25
26 # 计算 consine 余弦相似度
27 def consine(inputCommand):
28 # 把输入命令转化为数组格式
29 sentence=jieba.lcut(inputCommand)
30 words=str.join(' ',sentence)
31 list=[]
32 list.insert(0,words)
33 # 获取训练好的 TfidfVectorizer 模型
34 model=getModel()
35 # 获取车机命令的 TF-IDF 向量
36 data0=model.transform(getWords()).toarray().reshape(len(command),-1)
37 # 获取输入命令的 TF-IDF 向量
38 data1=model.transform(list).toarray().reshape(1,-1)
39 # 余弦相似度对比
40 result=cosine_similarity(data0,data1)
41 print('相似度对比:\n{0}'.format(result))
42 return result
43
44 if __name__=='__main__':
45 comm='我要听陈奕迅的歌'
46 # 获取余弦相似度
47 result=np.array(consine(comm))
48 # 获取相似度最高的命令 index
49 argmax=result.argmax()
50 # 读取命令回复
51 data=command[argmax][1]
52 print('命令:{0}\n回复:{1}'.format(comm,data))
运行结果

五、通过主题转换进行语义分析
5.1 LSA 隐性语义分析的定义
上面的例子都是通过分词的 TF-IDF 向量以余弦相似度对比分析文本内容的相似性,其实 TF-IDF 向量不仅适用于词,还适用于多词组合的 n-gram 分析。通过多个分词的不同组合,可以揭示一篇文章的语义,核心主题等。NLP 开发人员发现一种提示词组合的算法,被称为 LSA (Latent Semantic Analysis 隐性语义分析)。
LSA 可用于文本的主题提取,挖掘文本背后的含义、数据降维等方面。例如一篇文章的分词中 “ 服务、协议、数据交换、传输对象” 占比较大的,可能与 “ 云计算 ” 主题较为接近; “ 分词、词向量、词频、相似度” 占比较大的可能与 " 自然语言开发 " 主题较为接近。在现实的搜索引擎中,普通用户所输入的关键词未必能与分词相同,通过核心主题分析,往往更容易找出相关的主题文章,这正是 LSA 语义分析的意义。
5.2 SVD 奇异值分解原理
LSA 是一种分析 TF-IDF 向量的算法,它是基于 SVD ( Singular Value Decomposition 奇异值分解 ) 技术实现的。SVD 是将矩阵分解成三个因子矩阵的算法,属于无监督学习模型,这种算法也被常用在图像分析领域。
在图像分析领域 SVD 也被称作 PCA 主成分分析,在《 Python 机器学习实战 》 系列的文章中,曾对 PCA 主成分分析作详细介绍,对此话题有兴趣的朋友可阅读《 Python 机器学习实战 —— 无监督学习 》
SVD 公式表示如下,m 为词汇中的分词数量,n 为文档数量,p为库的主题数量。通过 SVD 算法,可以把包含大量分词的文章划分成多个主题的专栏。
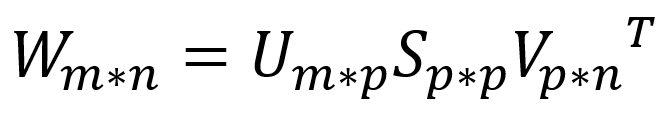
其中向量 U 是 分词-主题 矩阵,它给出分词所具有的上下文信息,代表分词与主题的相互关系,也被称为 “ 左奇异向量 ”。
向量 S 是主题奇异值的对象线方阵,例如有 6 个主题的文档库 S 值就会是一个 6*6 的矩阵。
向量 V 是 主题-文档 矩阵,它建立了新主题与文档之间的关系,也被称为 “ 右奇异向量 ”。

5.3 TruncatedSVD 模型
在 sk-learn 库中提供了sklearn.decomposition.TruncatedSVD 模型用于进行 SVD 分析。SVD 是无监督模型,通过SVD 可以把多维的数量进行主题转换实现降维,常被用于情感分析和垃圾信息处理。
1 class TruncatedSVD(TransformerMixin, BaseEstimator): 2 @_deprecate_positional_args 3 def __init__(self, n_components=2, *, algorithm="randomized", n_iter=5, 4 random_state=None, tol=0.): 5 self.algorithm = algorithm 6 self.n_components = n_components 7 self.n_iter = n_iter 8 self.random_state = random_state 9 self.tol = tol
参数说明
- algorithm:str 类型 {'arpack', 'randomized'} 之一,默认值为 “randomized”,用于选择 SVD 算法。arpack 为 SciPy中 ARPACK 包装器( "scipy.sparse.linalg.svds"); randomized 为算法由于Halko 中的随机算法(randomized)
- n_components:int 类型,默认值为 2,选择主题数量
- n_iter: int 类型,默认值为 5,运算时的迭代次数
- randow_state:int ,RandomState 实例或 None,默认值为 None。在随机初始化 svd 期间使用,传递一个 int 以获得可重现的结果多个函数调用。
- tol: float 类型,默认值为 0.0。当 algorithm 为 arpack 时使用,选择机器精度。当 algorithm 为 randomized 算法时自动忽略此设置。
转换主题时可先利用 TfidfVectorizer 将数据进行 TF-IDF 向量化,然后使用 TruncatedSVD 模型设置转换输出的主题类型数量,对主题的相关数据进行情感分析。
下面例子是从今日头条下载的资料,里面包含了财经、运动、娱乐、文化等多个主题。首先利用 jieba 进行分词,然后使用 TD-IDF 进行向量化处理,然后使用 TruncatedSVD 模型把 30000 多个分词进行主题化处理,转换成 10 个 components。
假设财经主题 finance 包含有 ['股份','银行','股票','投资','股市','黄金','市场','证券','科技','有限公司'] 等常用关键字,在 componets 中找到对应 finance 主题的关键字向量,对其进行情感分析。通过 svdVectorsDisplay()可分别显示金融主题最大正值内容和最小负值内容。
1 # 金融主题的关键字
2 finance=['股份','银行','股票','投资','股市','黄金','市场','证券','科技','有限公司']
3
4 # 利用 jieba 转换命令格式
5 def getWords():
6 file=open('C://Users/Leslie/Desktop/toutiao/news.txt','r',1024,'utf-8').read()
7 sentences=np.array(file.split('\n'))
8 # jieba 分词
9 list=[jieba.lcut(sentence) for sentence in sentences]
10 # 转换中文分词格式
11 words=[' '.join(word) for word in list]
12 return words
13
14 # 训练 TF-IDF 向量
15 def getTfidfVector():
16 tfidf = TfidfVectorizer()
17 # 获取分词
18 words=getWords()
19 # 训练模型,返回 TF-IDF 向量
20 vector=tfidf.fit_transform(words)
21 return tfidf,vector
22
23 def svdComponent():
24 # 获取 TF-IDF 向量
25 tfidf,vectors=getTfidfVector()
26 # 建立 SVD 模型
27 svd=TruncatedSVD(n_components=10,n_iter=10)
28 # 获取 TF-IDF 向量,训练 SVD 模型
29 svd=svd.fit(vectors)
30 svd_vectors=svd.transform(vectors)
31 # 显示主题
32 keys=tfidf.vocabulary_.keys()
33 # 获取相关主题的 components 向量
34 dataframeComponents=pd.DataFrame(svd.components_,columns=keys)
35 # 按照 component 5 进行相关性排序
36 dataframeVectors = pd.DataFrame(svd_vectors).sort_values(5, ascending=False).head(10)
37 svdComponentDisplay(dataframeComponents)
38 svdVectorsDisplay(dataframeVectors)
39
40 def svdComponentDisplay(dataframe):
41 # 获取与 finance 金融有关的关键词主题向量
42 topic = dataframe[finance] * 10000
43 # 显示与金融主题相关的SVD模型component主题
44 pd.options.display.max_columns = 10
45 # 打印主题向量及向量总值
46 print(topic)
47 print(topic.T.sum())
48
49 def svdVectorsDisplay(dataframe):
50 print(dataframe)
51 words=getWords()
52 # 金融主题 finance 关键字相关性语句
53 for row in dataframe.iterrows():
54 index = row[0]
55 print(words[index])
56
57 if __name__=='__main__':
58 svdComponent()
运行结果
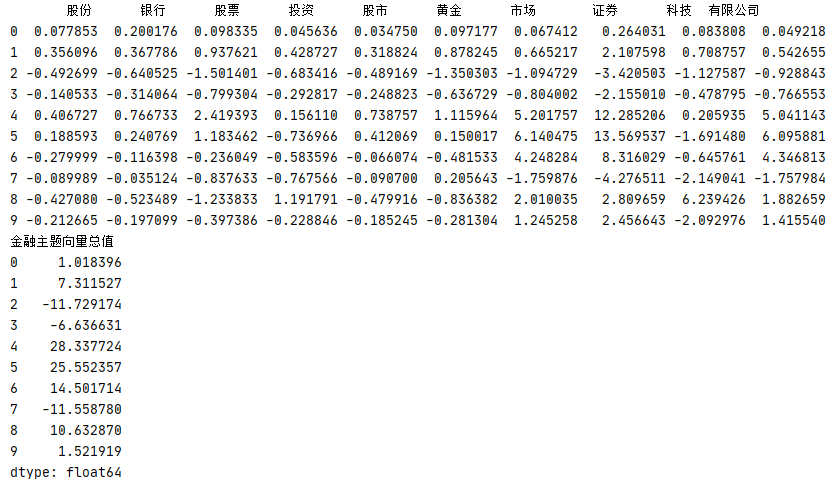
从运行结果可以看出,component 4 和 component 5 对金融主题的正向情感最高,尝试打印主题 5 正向情感前10个最大值的内容

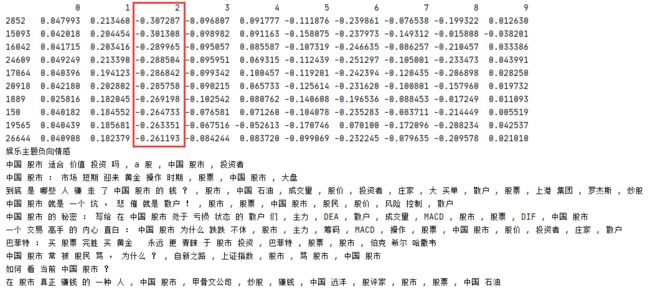
component 7 负向情感主题最高,打印主题 7 负向情感前 10 个最小值的内容,可见内容大部分是娱乐主题内容,与金融主题无关。

类似地也可以用娱乐关键字 entertainment ['电影', '范冰冰','电影节','活动','复仇者','粉丝','娱乐圈','明星'] 作为主题调用 svdComponentDisplay()方法进行数据筛选

进行主题转换后查看 component 0 的娱乐正向情感信息,可见内容基本上都是关于娱乐信息

类似地查看 component 2 娱乐负向情感数量,大部分都是关于金融类的信息
5.4 LDA 线性判别分析
线性判别分析(Linear Discriminant Analysis,简称 LDA)是一种经典的数据主题分析方法,它与 LSA 最大区别在于 LDA 属于监督学习模型,而 LSA 是无监督学习模型。LDA 的主要思想是将一个高维空间中的数据投影到一个较低维的空间中,且投影后要保证各个类别的类内方差小而类间均值差别大,这意味着同一类的高维数据投影到低维空间后相同类别会尽量聚在一起,而不同类别之间相距较远。
LDA 模型与 PCA 模型有点类似,然而最大区别在于:PCA方法寻找的是数据变化的主轴方向,从而根据主轴判别分析寻找的是用来有效分类的方向。这对样本数据的主要变化信息非常有效,然而却忽略了次要变化的信息。
而 LDA 模型是将高维样本数据投影到低维度的向量空间,根据投影后的向量进行分类判断。投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
下图就是将二维数据投影到一维直线上,里面显示出 PCA 与 LDA 投影的区别:

5.5 LinearDiscriminantAnalysis 模型
在 sklearn 库中提供了 sklearn.discriminant_analysis.LinearDiscriminantAnalysis 模型进行 LDA 线性分析。
1 class LinearDiscriminantAnalysis(LinearClassifierMixin, 2 TransformerMixin, 3 BaseEstimator): 4 def __init__(self, solver='svd', shrinkage=None, priors=None, 5 n_components=None, store_covariance=False, tol=1e-4, 6 covariance_estimator=None):
参数说明
- solver : str 类型 ['svd','lsqr',‘eigen’ ] 之一,默认为 ‘svd' ,选择LDA超平面特征矩阵使用的方法。可以选择的方法有奇异值分解"svd",最小二乘"lsqr"和特征分解"eigen"。一般来说特征数非常多的时候推荐使用svd,而特征数不多的时候推荐使用eigen。如果使用 svd,则不能指定正则化参数shrinkage进行正则化。
- shrinkage:float 类型,或 [ 'auto',' None'] 正则化参数,默认为 None 。可以增强LDA分类的泛化能力,如果仅仅只是为了降维,则一般可以忽略这个参数。"auto" 代表让算法自己决定是否正则化。也可在 [0,1] 之间的值进行交叉验证调参。该参数只在 solver 为"lsqr"和 "eigen" 时有效, 'svd' 时自动作废。
- priors :array 数组类型,默认为None。例如 [ n_class , ] ,用于定义类别权重,可以在做分类模型时指定不同类别的权重,进而影响分类模型建立。降维时一般不需要关注这个参数。
- n_components:int 类型,默认为 None ,即我们进行LDA降维时降到的维数。需要值必须小于输入数据的维度减一。
- store_covariance:bool 类型,默认为 False,是否额外计算每个类别的协方差矩阵。
- tol:float 类型,默认为 1e-4,用它指定了用于SVD算法中评判迭代收敛的阈值。
- warm_start:bool 类型,默认值为 False,当设置为True时,重用之前调用的解决方案作为初始化,否则,只需要删除前面的解决方案
- covariance_estimator:str 类型,[ 'covariance_estimator' 或 None ] 之一, 默认为None。如果不是 None,则使用 covariance_estimator 来估计协方差矩阵,而不是依赖于协方差估计器(具有潜在的收缩率)。对象应具有拟合方法和 covariance_ 属性,如 sklearn.covariance 中的估计器。如果为 None,则使用收缩率参数驱动估计值。
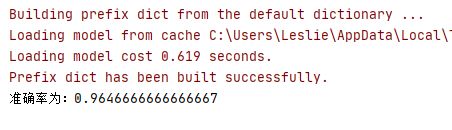
下面例子将使用 LinearDiscriminantAnalysis 模型对科技类文本和娱乐类文本进行分析,为了避免训练时间过长,所以只拿了 4000 条数据进行训练。把数据转化为 TF-IDF 向量后,使用 LDA 模型进行训练,只由只有 2 类,所以 n_components 设置为 1 即可。最后查看测试结果,准确率已经在 90% 以上。
1 # 科技、娱乐的两个文本路径
2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt',
3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt']
4 # 科技类信息标记为0,娱乐类信息标记为1
5 result = []
6
7 # 利用 jieba 转换命令格式
8 def getWords():
9 data = []
10 type = 0
11 # 获取路径中的两类文件
12 for path in paths:
13 file=open(path,'r',1024,'utf-8').read()
14 #分行读取,由于运行时间较长,所以只拿前2000条数据
15 sentences=np.array(file.split('\n'))[:2000]
16 # jieba 分词,记录分类结果
17 for sentence in sentences:
18 data.append(jieba.lcut(sentence))
19 result.append(type)
20 type+=1
21 # 转换中文分词格式
22 words=[' '.join(word) for word in data]
23 return words
24
25 # 训练 TF-IDF 向量
26 def getTfidfVector():
27 tfidf = TfidfVectorizer()
28 # 获取分词
29 words=getWords()
30 # 训练模型,返回 TF-IDF 向量
31 vector=tfidf.fit_transform(words)
32 return vector.toarray()
33
34 def ldaTest():
35 # 把 TF-IDF 向量切分为训练数据与测试数据
36 X_train,X_test,y_train,y_test=train_test_split(getTfidfVector(),result,random_state=22)
37 # 由于只是二分类,n_components 为 1 即可
38 lda=LDA(n_components=1)
39 # 训练模型
40 lda.fit(X_train,y_train)
41 # 输出准确率
42 y_model=lda.predict(X_test)
43 print('准确率为:{0}'.format(accuracy_score(y_test,y_model)))
44
45 if __name__=='__main__':
46 ldaTest()
运行结果
5.6 LDiA 隐性狄利克雷分布
隐性狄利克雷分布 ( Latent Dirichlet Allocation,简称 LDiA)与 LSA 类似也是一种无监督学习模型,但与相对于 LSA 的线性模型不同的是 LDiA 可以将文档集中每篇文档的主题按照概率分布的形式给出,从而更精确地统计出词与主题的关系。
LDiA 假设每篇文章都是由若干个主题线性混合而成的,每个主题都是由若干个分词组合而成,文章中每个主题的概率与权重以及每个分词被分配到主题的概率都满足 “ 狄利克雷概率 ” 的分布特征,估计这个也算法命名的原因。其计算公式如下:

当中 B (α)为
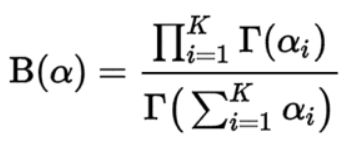
5.7 LatentDirichletAllocation 模型
在 sklearn 库中提供了 sklearn.decomposition.LatentDirichletAllocation 模型进行 LDiA 分析
1 class LatentDirichletAllocation(TransformerMixin, BaseEstimator): 2 @_deprecate_positional_args 3 def __init__(self, n_components=10, *, doc_topic_prior=None, 4 topic_word_prior=None, learning_method='batch', 5 learning_decay=.7, learning_offset=10., max_iter=10, 6 batch_size=128, evaluate_every=-1, total_samples=1e6, 7 perp_tol=1e-1, mean_change_tol=1e-3, max_doc_update_iter=100, 8 n_jobs=None, verbose=0, random_state=None):
参数说明
- n_components:int 类型,默认为 10 ,即我们进行LDA降维时降到的维数。需要值必须小于输入数据的维度减一。
- doc_topic_prior: float 类型,默认为None, 即狄利克雷概率计算公式中的 θ 参数。 如果为 None 即 θ 默认为 1/ n_components。
- topic_word_prior: float 类型,默认为None, 狄利克雷概率计算公式中的 α 参数 。如果为 None 即 α 默认为 1/ n_components。
- learning_method: str 类型 {'batch', 'online'}之一,默认为 'batch',代表用于更新_component 的方法。如果数据量非常大时 ’online' 会比 ‘batch’ 运行更快。
- learning_decay:float 类型,默认值为 0.7 ,控制学习时的速率。仅在 learning 为 "online"时有效,取值一般在 [ 0.5, 1.0] 之间
- learning_offset:float 类型,默认值为10.0,用于降低学习早期迭代的权重。仅在 learning 为 "online"时有效,取值要大于1。
- max_iter:int 类型,默认值为 10,部分求解器需要通过迭代实现,这个参数指定了模型优化的最大迭代次数。
- batch_size: int 类型,默认为128,EM 迭代算法时每次选择的文本数,仅在 learning 为 "online" 时有效
- evaluate_every: int 类型,默认为-1。影响 fit 方法的运行,为 0 或负数时不会对训练数据的模型指标。它可能帮助改善数据的收敛性,但也会影响训练的效率,或许会延长训练时间
- total_samples : int 类型, 默认为 1e6,输入的文档总数,只在方法 partial_fit() 中有效
- perp_tol:float 类型,默认为 1e-1, 指批量学习中的容忍度,仅在 evaluate_every 大于0时有效。
- mean_change_tol: float 类型,默认为 1e-3 , 即E步更新变分参数的阈值,所有变分参数更新小于阈值则E步结束,转入M步
- max_doc_update_iter: int 类型,默认为 100,即E步更新变分参数的最大迭代次数,如果E步迭代次数达到阈值,则转入M步。
- n_jobs:默认为 None,CPU 并行数。若设置为 -1 的时候,则用所有 CPU 的内核运行程序。
- verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
- random_state:随机数种子,推荐设置一个任意整数,同一个随机值,模型可以复现。
LDiA 与 LSA 相似属于无监督学习模型,常被用于情感分析与垃圾过滤等领域。下面例子将结合 LDiA 与 LDA 模型的特点,先将信息进行主题转换,把 4000 个短信转换成200个主题,再进行信息分类。
还是以上面的科技类文本和娱乐类文本作为例子,先进行 TF-IDF 向量转换,再经过 LDiA 主题转换,最后使用 LDA 进行训练测试。
1 # 科技、娱乐的两个文本路径
2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt',
3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt']
4 # 科技类信息标记为0,娱乐类信息标记为1
5 result = []
6
7 # 利用 jieba 转换命令格式
8 def getWords():
9 data = []
10 type = 0
11 # 获取路径中的两类文件
12 for path in paths:
13 file=open(path,'r',1024,'utf-8').read()
14 #分行读取,为了避免训练时间过长,只获取 4000 行数据
15 sentences=np.array(file.split('\n'))[2000:4000]
16 # jieba 分词,记录分类结果
17 for sentence in sentences:
18 data.append(jieba.lcut(sentence))
19 result.append(type)
20 type+=1
21 # 转换中文分词格式
22 words=[' '.join(word) for word in data]
23 return words
24
25 # 训练 TF-IDF 向量
26 def getLdiaVector():
27 tfidf = TfidfVectorizer()
28 # 获取分词
29 words=getWords()
30 # 训练模型,返回 TF-IDF 向量
31 vector=tfidf.fit_transform(words)
32 # 训练 LDiA 模型,转换为 200个主题
33 ldia=LDiA(n_components=200,doc_topic_prior=2e-3,topic_word_prior=1e-3,random_state=42)
34 return ldia.fit_transform(vector)
35
36 def ldaTest():
37 # 把 TF-IDF 向量切分为训练数据与测试数据
38 X_train,X_test,y_train,y_test=train_test_split(getLdiaVector(),result,random_state=22)
39 # 由于只是二分类,n_components 为 1 即可
40 lda=LDA(n_components=1)
41 # 训练模型
42 lda.fit(X_train,y_train)
43 # 输出准确率
44 y_model=lda.predict(X_test)
45 print('准确率为:{0}'.format(accuracy_score(y_test,y_model)))
46
47 if __name__=='__main__':
48 ldaTest()
运行结果
虽然准确率只有 87%,远远不如直接使用 LDA 模型,但 LDiA 模型依然可以帮助用户从一个小型的训练集中泛化出模型,处理不同词的组合。
六、词嵌入的应用
至今为止,文章的代码都是使用 sk-learn 机器学习作为基础的,其实自然语言处理在 Tensonflow 深度学习中应用更广。下面将从基础知识入手,介绍 NLP 在深度学习的应用。
6.1 词嵌入原理
在机器学习中会利用 TF-IDF 等向量进行计算,而在Tensorflow 中常用词嵌入的方式进行计算。获取词嵌入的方式有两种,一种是通过词向量进行模型训练学习得来。另一种通过预训练模型把预先计算好词嵌入,然后将其加入模型中,也称为预训练词嵌入。常用的预训练词嵌入有 Word2doc、GloVe、Doc2vec 等。
Tensorflow 中准备 Embedding 层进行词嵌入,相比起传统的 one-hot 编码,它提供了低维度高密集型的词向量,其主要参数如下,其中最常用到的是 input_dim,output_dim,input_length 这3个参数,input_dim 是代表最大可插入的分词个数据,output_dim 是代表对分词特征分析的维度,这个参数需要根据分词数量而定,input_length 是限制单个测试对象的最大分词数量,若单个测试对象超出此单词数系统将会自动截取。
1 @keras_export('keras.layers.Embedding')
2 class Embedding(Layer):
3 def __init__(self,
4 input_dim,
5 output_dim,
6 embeddings_initializer='uniform',
7 embeddings_regularizer=None,
8 activity_regularizer=None,
9 embeddings_constraint=None,
10 mask_zero=False,
11 input_length=None,
12 **kwargs):
参数说明:
- input_dim:int 类型,大或等于0 的整数,代表作为特征的分词个数
- output_dim:int 类型,大于0的整数,代表全连接嵌入的维度
- embeddings_initializer: 嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。可参考keras.initializers
- embeddings_regularizer: 嵌入矩阵的正则项,为Regularizer对象
- embeddings_constraint: 嵌入矩阵的约束项,为Constraints对象
- mask_zero:bool 类型,默认为 False,用于确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为|vocabulary| + 2。
- input_length:int 类型,默认为 None,限制每个插入对象最大单词数量。每行数据不足此数量会自动加入0 作为补充,超过此数据会截断后面的值。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
要使用 Embedding 层首先要对数据进行一下转换,例如上面例子的中文分词原来为下面格式

现在需要把文本转换为编码的格式,然后才能作为 Embedding 的输入数据

下面的例子继续使用科技、娱乐两类文档作为测试数据。先利用 jieba 作分词处理,然后调用 getEncode 方法进行自编码,把中文单词字符串转换成数字编码,再建立 Model 使用 Embedding 嵌入词进行测试。注意通过词嵌入后需要进行 Flatten 拉直后再进行计算。
在此例子中使用了 10000 个单词,由于是短文本,所以把 input_length设置为 10 个单词,而且只通过一个 Dense 层,准确率已经达到 90 % 以上。
1 # 科技、娱乐的两个文本路径
2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt',
3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt']
4 # 科技类信息标记为0,娱乐类信息标记为1
5 result = []
6 # 最大单词数
7 max_features=10000
8 # 单个语句最大的词数量限制
9 maxlen=10
10
11 # 利用 jieba 转换命令格式
12 def getWords():
13 data = []
14 type = 0
15 # 获取路径中的两类文件
16 for path in paths:
17 file=open(path,'r',1024,'utf-8').read()
18 #分行读取,读取前 5000 行数据
19 sentences=np.array(file.split('\n'))[:5000]
20 # jieba 分词,记录分类结果
21 for sentence in sentences:
22 data.append(jieba.lcut(sentence))
23 result.append(type)
24 type+=1
25 return data
26
27 # 自编码
28 def getEncode():
29 # 获取所有分词
30 sentences=getWords()
31 encode=list()
32 words= {}
33 index=0
34 # 循环所有句子
35 for sentence in sentences:
36 array = []
37 # 把分词转换成编码
38 for key in sentence:
39 if key not in words:
40 words[key]=index
41 index+=1
42 array.append(words[key])
43 # 记录每个句子的编码
44 encode.append(array)
45 # 返回自编码
46 return encode
47
48 # Model
49 def getModel():
50 model=Sequential()
51 model.add(Embedding(max_features,20,input_length=maxlen))
52 model.add(Flatten())
53 model.add(Dense(1,activation='sigmoid'))
54 model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
55 model.summary()
56 return model
57
58 def test():
59 model=getModel()
60 # 获取句子的编码
61 encodes=getEncode()
62 X_train,X_test,y_train,y_test=train_test_split(encodes,np.array(result),random_state=22)
63 X_train=preprocessing.sequence.pad_sequences(X_train,maxlen=maxlen)
64 X_test=preprocessing.sequence.pad_sequences(X_test,maxlen=maxlen)
65 # 输出准确率
66 history=model.fit(X_train,y_train,epochs=20,batch_size=500)
67 print(history)
68 model.fit(X_test,y_test)
69
70 if __name__=='__main__':
71 test()
运行结果
上面例子中的词嵌入都是通过词频统计计算出来了,而了 21 世纪初 Bengio 等人提出一种新算法 NNLM(Nerual Network Language Model),就是通过无监督学习的方式预先计算出一个低维词向量,然后把向量直接加载 Embedding 层,这样就可以大大减小的模型的训练时间与语料搜集的难度。最常见的预训练词嵌入有 Word2vec 和 GloVe。
6.2 Word2vec 原理与应用
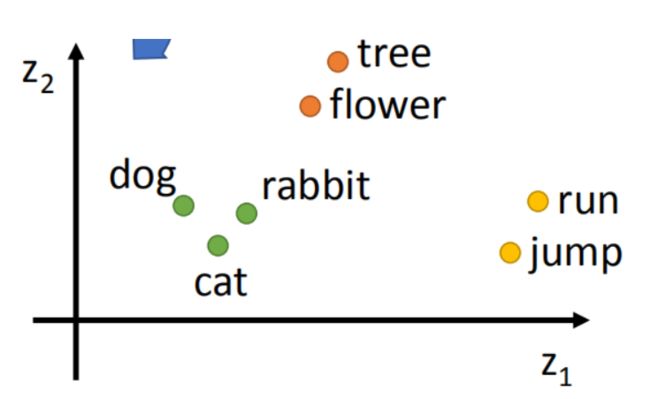
Word2vec 同 Google 的 Tomas Mikolov 于 2013 年研发,它是通过无监督学习训练而成,因此训练数据不需要人工组织、结构化和标注,这对于 NLP 来说可以说是非常完美。Word2vec 与其他词向量相似,以向量来衡量词语之间的相似性以及相邻的词汇是否相识,这是基于语言学的“距离相似性” 原理。“距离相似性” 可以用词向量的几何关系可以代表这些词的关系,用两个词之前的距离长短来衡量词之间的关系。如果把词向量的多维关系转化为二维映射或者会更容易理解,如下图 dog 、cat、rabbit 的相对更为接近,所以被是认为有一定的关系。
6.2.1 Word2vec 模型
在 gensim 库中,包含了最常用的 gensim.models.word2vec.Word2Vec 模型。在使用 Word2vec 模型前,首先要对模型进行预训练,由于各国有不同的文化差异,所以需要准备不同的语料库,词料库信息越全面,训练出来的模型准确性就会越高。
1 class Word2Vec(utils.SaveLoad): 2 def __init__( 3 self, sentences=None, corpus_file=None, vector_size=100, alpha=0.025, window=5, min_count=5, 4 max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001, 5 sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=hash, epochs=5, null_word=0, 6 trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH, 7 compute_loss=False, callbacks=(),comment=None, max_final_vocab=None, shrink_windows=True, 8 )
参数说明
- sentences: iterable 或 optional 默认为 None ,以此参数导入要训练的语料,它是一个可迭代对象。由于语料库往往比较大,导入时建议使用 Text8Corpus 、LineSentence
- corpus_file: str 类型,可以直接输入 LineSentence 文件路径来导入要训练的语料,以此参数代替 sentences 可以提升读入效率。sentences 和 corpus_file 必需填入一个,否则系统会报错
- vector_size:int 类型,默认值为 100,表示训练后输出向量的维度
- alpha:float类型,默认值为 0.025,表示初始学习率
- window:int 类型,默认为 5,表示句子中当前和预测单词之间的最大距离,取词窗口大小
- min_count:int 类型,默认为 5 ,表示文档中总频率低于此值的单词会被忽略,如果文档总词数低于此值系统将会被错
- max_vocab_size:int 类型,默认为 None ,表示构建词汇表最大数,词汇大于这个数按照频率排序,去除频率低的词汇
- sample:float 类型,默认为 1e-3 ,表示高频词进行随机下采样的阈值,范围是(0, 1e-5)
- seed :int 类型,默认为1 ,向量初始化的随机数种子
- workers:int 类型,默认为3,同时运行的 的 CPU 数
- min_alpha:float 类型,默认为 0.0001, 随着学习进行,学习率线性下降到这个最小数
- sg :int 类型,默认为 0,训练时算法选择 0 为 skip-gram, 1 为 CBOW
- hs : int 类型,默认为 0,当 hs为 0 并且 negative 参数不为零j时,用负采样,为一时 使用 softmax
- negative:int 类型,默认为 5,使用负采样,大于 0 是使用负采样, 负数值就会进行增加噪音词
- ns_exponent:float 类型,默认为 0.75 ,表示负采样指数,确定负采样抽样形式:1.0:完全按比例抽,0.0 对所有词均等采样,负值对低频词更多的采样。
- cbow_mean:int 类型,默认为 1,用于选择 CBOW 的计算方式。 0 代表使用上下文单词向量的总和,1 表示使用均值; 只有使用 CBOW 算法时适用,skip-gram 时忽略此参数
- hashfxn:表达式函数,默认为 hash 希函数,用于随机初始化权重,以提高训练的可重复性。
- epoch :int 类型,默认为 5 ,代表迭代次数
- null_word: 默认为 0 空填充数据
- trim_rule:表达式函数,默认为 None ,代表词汇修剪规则,指定某些词语是否应保留在词汇表中,默认是词频小于 min_count 则丢弃,可以是自己定义规则
- sorted_vocab :int 类型,默认为1 ,表示排序规则,1 代表按照降序排列,0 表示不排序;实现方法:gensim.models.word2vec.Word2VecVocab.sort_vocab()
- batch_words:int 类型,默认为 10000 ,表示每批次最大的词数量,大于10000 cython 会进行截断
- compute_loss:bool 类型,默认为 False, 是否保存损失函数值,False 为不保存,True 就会保存
- callbacks : 表示式函数,默认为(),表示在训练期间的特定阶段执行的回调序列 gensim.models.callbacks.CallbackAny2Vec
- max_final_vocab:默认为None 通过自动选择匹配的 min_count 将词汇限制为目标词汇大小,如果 min_count 有参数就用给定的数值
- shrink_window: bool 类型,默认为 True,4.1 版本新参数,若为 True,始终在窗口最左侧 [1,‘window’] 作为参数对上下文单词的距离进行位置权重计算,若为 Flase 则以中间项为标准进行计算。
训练 Word2vec 训练前先要做好准备,在 Index of /zhwiki/latest/ 网上可以找到最新的中文语料库,可以根据需求下载。由于下载的是 *.bz2 的压缩文件,而包含简体/繁体多种字型。所以读取时首先利用 WikiCorpu 要对文件进行解压,由于中文单词与国外有所区别,所以完成解压后,需要利用 jieba 进行分词处理,处理期间可通过 zhconv 把繁体字转换成简体字,完成转换后保存数据。
格式转换后可开始对 Word2Vec 模型进行预训练,由于数据量通常比较大,建议完成预训练后使用 Word2Vec.save (path) 方法保存模型,方便下次直接使用 Word2Vec.load(path) 重新加载。路径最好通过 os.path 生成,直接写入绝对路径容易报错。
1 # 定议下载后压缩文件的路径,解压转换为简体的新文本路径 2 wikipath = 'E://Tools/words/word2vec/zhwiki-latest-pages-articles.xml.bz2' 3 filepath = 'E://Tools/words/word2vec/wiki.simple.txt' 4 modelpath = 'E://Python_Projects/ANN/venv/word2ver_wiki_cn.model' 5 6 if __name__=='__main__': 7 convert() 8 saveModel() 9 10 def saveModel(): 11 # 通过 os.path 获取路径避免引起LineSentence路径错误 12 sentencesPath = os.path.abspath(filepath) 13 modelPath = os.path.abspath(modelpath) 14 # 生成逐行读取对象 LineSentence 15 sentences = LineSentence(sentencesPath) 16 # 建议 word2vec 对象进行学习 17 model = Word2Vec(sentences, window=8, min_count=5, workers=10) 18 # 保存模型 19 model.save(modelPath) 20 21 def convert(): 22 # 定义写入文件对象 23 write=open(filepath,'w',10240,'utf-8') 24 # 读取 bz2 压缩文件 25 wiki = WikiCorpus(wikipath) 26 # 分行读取 27 for sentences in wiki.get_texts(): 28 data='' 29 # 分句读取 30 for sentence in sentences: 31 # 把繁体字转换为简体字 32 simpleSentence=zhconv.convert(sentence,'zh-cn') 33 # 通过 jieba 进行分词 34 for word in jieba.lcut(simpleSentence): 35 data+=word+' ' 36 # 换行 37 data+='\n' 38 # 写入文件 39 write.write(data)
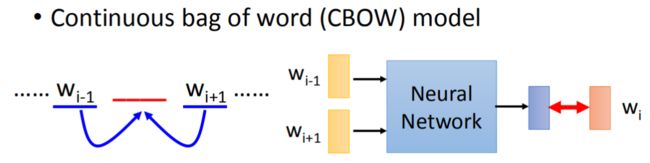
训练 Word2vec 有两种方法 Skip-gram 方法和 CBOW(continuous bag-of-words)连续词袋,可以通过 sg 参数选择算法,0 为 skip-gram, 1 为 CBOW,默认使用 skip- gram
Skip-gram 算法是通过输入单词预测周边的词
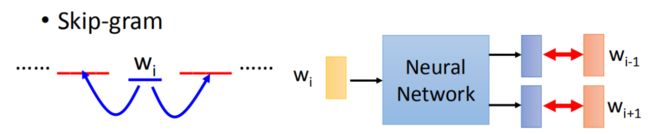
CBOW 算法则是基于邻近的词预测目标词
6.2.2 KeyedVectors 词向量的常用方法
完成 Word2Vec 模型的预训练后,可以通过 Word2Vec.load(path) 重新加载训练好的模型, 通过 Word2Vec.wv 可获取训练后的词向量对象 KeyedVectors。
KeyedVectors 词向量对象有下面几种常用的方法
6.2.2.1 获取 keyedVectors 向量值
通过 wv.vectors 可以获取模型的全局向量,通过 wv [ '向量名‘ ] 可以获取对应的向量,由于 vector_size 默认维度是100,所以每个向量也是一个 1 * 100 的数组 。
1 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model')
2 model=Word2Vec.load(modelPath)
3 print( model.wv[ '朱元璋' ])
运行结果

若要进行组合向量查询,可直接通过向量叠加完成,例如若要查询 “唐朝的名诗及其作者” 等可以通过下面的等式完成
vector= wv['唐朝']+wv['诗人‘]+wv[’作品']
若发现结果中不仅包含有诗人和作品,还有其他朝代等信息,即可通过减法排除
vector= wv['唐朝']+wv['诗人‘]+wv[’作品']-wv['朝代']
6.2.2.2 向量相邻词 most_similar
方法 wv. most_similar( positive=None, negative=None, topn=10)可根据给定的向量查询其相邻的词,其中 positive 是代表捕捉相关的向量词组合,topn是默认返回前10个词,negative 是代表要排除的向量词。从例子中可以看,以 “唐朝” 查询到的大多都是不同的朝代。但排除 “朝代”关系后,显示的变成唐朝人物 “罗弘信” 等,地区 “魏州” 等信息。选择了“唐朝”和 ”皇帝“ 再排除 “朝代” 信息后,还有会有 “唐玄宗”,“唐高宗”,“武则天” 等皇帝信息。
1 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model')
2 model=Word2Vec.load(modelPath)
3
4 list0=model.wv.most_similar(positive=['唐朝'],topn=10)
5 print(list0)
6 list1=model.wv.most_similar(positive=['唐朝'],negative=['朝代'],topn=10)
7 print(list1)
8 list2=model.wv.most_similar(positive=['唐朝','皇帝'],topn=10)
9 print(list2)
运行结果

6.2.2.3 检测不相关词 doesnt_match
通过 wv.doesnt_match(words) 可监测多个词组合中不相关的词,例如通过 wv.doesnt_match(['唐朝','李世民','诗词','计算机']),系统会测试出 计算机
6.2.2.4 余弦相似度计算 most_similar
通过 wv.most_similarity(w1,w2) 可以计算出给定两个词之间的余弦相似充,例如通过 wv.similarity('唐太宗','李世民'),计算出的相邻度为 0.78733486
6.2.2.5 词频查询 expandos
在 gensim 4.0 以上版本,系统已用 wv.expandos 代替 wv. vocab,可以通过此属性可查询每个分词的数量等信息
6.2.3 Word2Vec 在 Embedding 层的应用
在模型的 Embedding 层中,可以使用预训练的 word2vec 使用提升模型的准确性。通过 https://www.cluebenchmarks.com/ 网站下载分类测试数据,里面有 16 大类的今日头条APP里面的文档。以 paths 数组记录不同类型的文本路径,利用 jieba 进行分词处理,然后调用 getWord()把分词进行编码处理,处理后的分词及编码记录在 dict 全局变量 words 中。再通过 getEmbedding() 方法,把预训练后的分量加入入 Embedding 层。把该层的 trainable 设置为 False ,让训练时数据不会影响 word2vec 的向量值。最后进行模型测试,可以看到简单的三层模型测试数据准确率可达到 80% 以上,已经相当不错了。
1 # 科技、娱乐、文学等16类文本路径
2 paths=['C://Users/Leslie/Desktop/toutiao/news_finance.txt',
3 'C://Users/Leslie/Desktop/toutiao/news_entertainment.txt',
4 'C://Users/Leslie/Desktop/toutiao/news_culture.txt',
5 ..........]
6 # 记录类型标记 0,1,2,3...
7 result = []
8 # 记录分词与其对应编码
9 words = {}
10 # 定义 maxlen 超过100个截取
11 maxlen=100
12 # 定义向量主题数
13 vector_size=100
14
15 # 利用 jieba 转换命令格式
16 def getWords():
17 data = []
18 type = 0
19 # 获取路径中的16类文件
20 for path in paths:
21 file=open(path,'r',1024,'utf-8').read()
22 #分行读取
23 sentences=np.array(file.split('\n'))[:5000]
24 # jieba 分词,记录分类结果
25 for sentence in sentences:
26 data.append(jieba.lcut(sentence))
27 result.append(type)
28 type+=1
29 return data
30
31 # 自编码
32 def getEncode():
33 # 获取所有分词
34 sentences=getWords()
35 encode=list()
36 index=0
37 # 循环所有句子
38 for sentence in sentences:
39 array = []
40 # 把分词转换成编码
41 for key in sentence:
42 if key not in words:
43 words[key]=index
44 index+=1
45 array.append(words[key])
46 # 记录每个句子的编码
47 encode.append(array)
48 # 返回自编码
49 return encode
50
51 # 获取word2vec中对应的向量生成 Embedding 数组
52 def getEmbedding():
53 # 加载训练好的 word2vec 模型
54 modelPath=os.path.abspath('E://Python_Projects/ANN/venv/word2ver_wiki_cn.model')
55 model=Word2Vec.load(modelPath)
56 # 向量初始化
57 embedding=np.zeros((len(words), vector_size))
58 # 若word2vec有此分词则加载此向量,若没有则设置为0
59 for key,value in words.items():
60 if model.wv.__contains__(key):
61 embedding[value]=model.wv.get_vector(key)
62 return embedding
63
64 # 生成Model
65 def getModel():
66 model=Sequential()
67 model.add(Embedding(len(words),vector_size,input_length=maxlen))
68 model.add(Flatten())
69 model.add(Dense(500,activation='relu'))
70 model.add(Dense(100,activation='relu'))
71 model.add(Dense(3,activation='sigmoid'))
72 model.compile(optimizer=optimizers.Adam(0.003),
73 loss=losses.sparse_categorical_crossentropy,
74 metrics=['acc'])
75 model.summary()
76 return model
77
78 def test():
79 # 获取句子的分词编码
80 encodes=getEncode()
81 # 获取模型
82 model=getModel()
83 # 在 Embedding 层加入预训练好的 word2vec 模型
84 model.layers[0].set_weights([getEmbedding()])
85 # 训练时不修改 word2vec 模型中的向量
86 model.layers[0].trainable=False
87 # 分拆训练数据与测试数据
88 X_train,X_test,y_train,y_test=train_test_split(encodes,np.array(result),random_state=60)
89 X_train=preprocessing.sequence.pad_sequences(X_train,maxlen=maxlen)
90 X_test=preprocessing.sequence.pad_sequences(X_test,maxlen=maxlen)
91 # 输出准确率
92 callback= keras.callbacks.TensorBoard(log_dir='logs')
93 history=model.fit(X_train,y_train,epochs=20,batch_size=500,callbacks=callback)
94 print(history)
95 model.fit(X_test,y_test)
96
97 if __name__=='__main__':
98 test()
运行结果

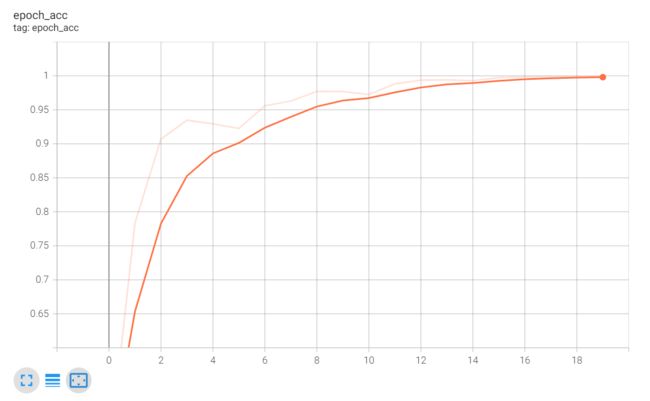
Tensorborad 准确率
6.3 GloVe 词嵌入
除了 Word2Vec 库,另一个常用的库就是 GloVe(Global Vectors for Word Representation),它是由斯坦福大学研究人员在 2014 年开发的。这种嵌入方法基于全词频统计的方式对分词进行了全局矩阵因式分解,它可以直接把单词表达成实数向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
GloVe 库的应用与 Word2Vec 类似,可以直接通过网络下载语料库,对 GloVe 进行预训练,然后保存模型,再把从 Embedding 层注入预训练好的向量,对数量进行测试。若要在 window 10 或以上版本中使用 Glove,建议使用 glove_python 包,首先必须先安装 GCC (可通过 Homebrew 下载对应版本)和 Visual Studio Build Tool 14 以上版本,然后通过 pip install glove_python 执行安装(也可链接 GitHub:glove_python-0.1.0-cp37-cp37m-win_amd64.zip 直接下载安装包)。
GloVe 常用方法如下
1 #准备数据集
2 sentense = [['摘要','人工智能','AI','开发'],['我们','是','机器人'],......]
3 corpus_model = Corpus()
4 corpus_model.fit(sentense, window=10)
5 #训练
6 glove = Glove(no_components=100, learning_rate=0.05)
7 glove.fit(corpus_model.matrix, epochs=10,
8 no_threads=1, verbose=True)
9 glove.add_dictionary(corpus_model.dictionary)
10 #模型保存
11 glove.save('glove.model')
12 glove = Glove.load('glove.model')
13 #语料保存
14 corpus_model.save('corpus.model')
15 corpus_model = Corpus.load('corpus.model')
完成训练后,使用 Glove.load() 就可以重新加载,然后把向量加载到 Embedding 层,使用方式与 Word2Vec 非常类似,在此就不再做重复介绍。
利用 gensim.scripts.glove2word2vec 还可以把 glove 向量转化为 Word2Vec 向量使用
1 # 用于转换并加载glove预训练词向量 2 from gensim.test.utils import datapath, get_tmpfile 3 from gensim.models import KeyedVectors 4 # 将glove转换为word2vec 5 from gensim.scripts.glove2word2vec import glove2word2vec 6 7 path='文件夹路径' 8 glove_file=datapath(os.path.join(path, "glove.txt")) 9 word2vec_file=get_tmpfile(os.path.join(path,"word2vec.txt")) 10 glove2word2vec(glove_file, word2vec_file)
本章总结
本文介绍了 NLP 自然语言处理的理论与实现方法,以 One-Hot、TF-IDF、PageRank 为基础的算法,讲述 LDA、LDiA、LSA 等语义分析的原理。介绍 Jieba 分词工具的中文文本中的应用,以及Word2Vec、GloVe 等预训练模型。
其实本文讲述的 NLP 在 Embedding 中的应用只是冰山一角,自然语言处理在循环神经网络 RNN 中才能真正发挥其优势。在下篇文章 《 TensorFlow 2.0 深度学习实战 —— 循环神经网络 RNN 》 会从实用的角度更深入地介绍 NLP 的应用场景,敬请留意。
希望本篇文章对相关的开发人员有所帮助,由于时间仓促,错漏之处敬请点评。
对 .Python 开发有兴趣的朋友欢迎加入QQ群:790518786 共同探讨 !
对 JAVA 开发有兴趣的朋友欢迎加入QQ群:174850571 共同探讨!
对 .NET 开发有兴趣的朋友欢迎加入QQ群:162338858 共同探讨 !
AI人功智能相关文章
Python 机器学习实战 —— 监督学习(上)
Python 机器学习实战 —— 监督学习(下)
Python 机器学习实战 —— 无监督学习(上)
Python 机器学习实战 —— 无监督学习(下)
Tensorflow 2.0 深度学习实战——介绍损失函数、优化器、激活函数、多层感知机的实现原理
TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
NLP 自然语言处理实战